论文笔记--Deep contextualized word representations
论文笔记--Deep contextualized word representations
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 BiLM(Bidirectional Language Model)
- 3.2 ELMo
- 3.3 将ELMo用于NLP监督任务
- 4. 文章亮点
- 5. 原文传送门
1. 文章简介
- 标题:Deep contextualized word representations
- 作者:Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer
- 日期:2018
- 期刊:arxiv preprint
2. 文章概括
文章提出了一种语言模型的预训练方法ELMo(Embeddings from Language Models)。与传统仅仅使用最顶层隐藏层的神经网络不同,ELMo将所有biLM隐藏层信息通过线性层汇总,从而使得模型同时将高级特征和低级特征输入到模型输出阶段。ELMo在文章实验的所有NLP任务上均达到或超过了SOTA。
3 文章重点技术
3.1 BiLM(Bidirectional Language Model)
给定序列 ( t 1 , … , t N ) (t_1, \dots, t_N) (t1,…,tN),前向语言模型(生成式)基于当前时刻前的token计算当前时刻的token概率,即在时刻 t t t,给定 ( t 1 , … t k − 1 ) (t_1, \dots t_{k-1}) (t1,…tk−1),计算 p ( t 1 , … , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , … , t k − 1 ) . p(t_1,\dots, t_N) = \prod_{k=1}^N p(t_k|t_1, \dots, t_{k-1}). p(t1,…,tN)=k=1∏Np(tk∣t1,…,tk−1).
后向语言模型则相反,即通过当前时刻之后的token预测当前时刻token的概率 p ( t 1 , … , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , … , t N ) . p(t_1,\dots, t_N) = \prod_{k=1}^N p(t_k|t_{k+1}, \dots, t_N). p(t1,…,tN)=k=1∏Np(tk∣tk+1,…,tN).
双向语言模型(biLM)将上述二者结合,最大对数似然 ∑ k = 1 N log p ( t k ∣ t 1 , … , t k − 1 ; Θ x , Θ ⃗ L S T M , Θ s ) + log p ( t k ∣ t k + 1 , … , t N ; Θ x , Θ ← L S T M , Θ s ) \sum_{k=1}^N \log p(t_k|t_1, \dots, t_{k-1};\Theta_x, \vec{\Theta}_{LSTM}, \Theta_s) +\hspace{.3cm} \\\log p(t_k|t_{k+1}, \dots, t_N;\Theta_x, \overleftarrow{\Theta}_{LSTM}, \Theta_s) k=1∑Nlogp(tk∣t1,…,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,…,tN;Θx,ΘLSTM,Θs),其中 Θ x \Theta_x Θx表示token的表征参数, Θ s \Theta_s Θs表示Softmax层的参数, Θ → L S T M , Θ ← L S T M \overrightarrow{\Theta}_{LSTM}, \overleftarrow{\Theta}_{LSTM} ΘLSTM,ΘLSTM分别表示前向和后向LSTM的参数。
3.2 ELMo
对于任意token t k t_k tk,L层的biLM会计算 R k = { h k , j L M ∣ j = 0 , … , L } R_k = \{\boldsymbol{h}_{k,j}^{LM}|j=0,\dots, L\} Rk={hk,jLM∣j=0,…,L},其中 h k , 0 L M {h}_{k,0}^{LM} hk,0LM表示token层, h k , j L M = [ h → k , j L M ; h ← k , j L M ] \boldsymbol{h}_{k,j}^{LM}=[\overrightarrow{\boldsymbol{h}}_{k,j}^{LM};\overleftarrow{\boldsymbol{h}}_{k,j}^{LM}] hk,jLM=[hk,jLM;hk,jLM]表示每一个LSTM层。
最终ELMo通过线性层将所有层的信息汇总: E L M o k t a s k = E ( R k ; Θ t a s k ) = γ t a s k ∑ j = 0 L s j t a s k ELMo_k^{task} = E(R_k;\Theta^{task})=\gamma^{task} \sum_{j=0}^L s_j^{task} ELMoktask=E(Rk;Θtask)=γtaskj=0∑Lsjtask,其中 s j t a s k s_j^{task} sjtask为softmax权重, γ t a s k \gamma^{task} γtask为标量参数,可以将ELMo向量放缩。
文章通过数值实验表明,高层和底层捕获到的信息有所区别,不同的下游任务可能用到高层或底层的特征:高层信息可用于依赖分析等语义分析任务,底层信息可用于POS等语法分析任务。从而文章选择将每一层的信息结合,一起输送给模型。
3.3 将ELMo用于NLP监督任务
给定NLP的监督任务,我们先不考虑标签,直接将biLM在数据集上训练,得到每个token的 E L M o k t a s k ELMo_k^{task} ELMoktask。然后冻结biLM的权重,将每个token的 x k x_k xk(通过字符CNN得到)连同 E L M o k t a s k ELMo_k^{task} ELMoktask一起输入到监督模型(RNN,CNN等),进行训练。此外,文章提出在输出阶段也可增加 E L M o k t a s k ELMo_k^{task} ELMoktask,即将 [ h k ; E L M o k t a s k ] [h_k; ELMo_k^{task}] [hk;ELMoktask]传入softmax层
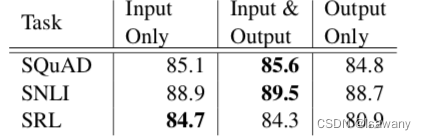
文章测试了将ELMo向量放入不同阶段的效果,如下表所示,将ELMo同时增加到输入和输出阶段的表现最好。
4. 文章亮点
文章提出了将bi-LSTM预训练向量用于NLP下游任务的方法,此外,文章通过线性层将biLM的所有层信息全部汇总,通过高级特征+低级特征共同完成训练。ELMo模型在多个任务上实现了SOTA,且显著提升了下游任务的收敛速率。
5. 原文传送门
Deep contextualized word representations
相关文章:
论文笔记--Deep contextualized word representations
论文笔记--Deep contextualized word representations 1. 文章简介2. 文章概括3 文章重点技术3.1 BiLM(Bidirectional Language Model)3.2 ELMo3.3 将ELMo用于NLP监督任务 4. 文章亮点5. 原文传送门 1. 文章简介 标题:Deep contextualized word representations作者…...

【MySQL高级篇笔记-性能分析工具的使用 (中) 】
此笔记为尚硅谷MySQL高级篇部分内容 目录 一、数据库服务器的优化步骤 二、查看系统性能参数 三、统计SQL的查询成本:last_query_cost 四、定位执行慢的 SQL:慢查询日志 1、开启慢查询日志参数 2、查看慢查询数目 3、慢查询日志分析工具…...

大学生数学建模题论文
大学生数学建模题论文篇1 浅论高中数学建模与教学设想 论文关键词:数学建模 数学 应用意识 数学建模教学 论文摘要:为增强学生应用数学的意识,切实培养学生解决实际问题的能力,分析了高中数学建模的必要性,并通过对高中…...

论文阅读 —— 滤波激光SLAM
文章目录 FAST-LIO2FAST-LIOIMUR2LIVER3LIVEEKFLINS退化摘要第一句 FAST-LIO2 摘要: 本文介绍了FAST-LIO2:一种快速、稳健、通用的激光雷达惯性里程计框架。 FAST-LIO2建立在高效紧耦合迭代卡尔曼滤波器的基础上,有两个关键的新颖之处&#…...

JavaScript键盘事件
目录 一、keydown:按下键盘上的任意键时触发。 二、keyup:释放键盘上的任意键时触发。 三、keypress:在按下并释放能够产生字符的键时触发(不包括功能键等)。 四、input:在文本输入框或可编辑元素的内容…...

opengl灯光基础:2.1 光照基础知识
光照: 光照以不同的方式影响着我们看到的世界,有时甚至是以很戏剧化的方式。当手电筒照射在物体上时,我们希望物体朝向光线的一侧看起来更亮。我们所居住的地球上的点,在中午朝向太阳时候被照得很亮,但随着地球的自转…...
大屏时代:引领信息可视化的新潮流
在信息时代的浪潮下,数据已经成为推动各行各业发展的重要动力。然而,海量的数据如何快速、直观地呈现给用户,成为了一个亟待解决的难题。在这样的背景下,可视化大屏应运而生,以其出色的表现力和交互性成为信息展示的佼…...
ChatGTP全景图 | 背景+技术篇
引言:人类以为的丰功伟绩,不过是开端的开端……我们在未来100年取得的技术进步,将远超我们从控制火种到发明车轮以来所取得的一切成就。——By Sam Altman 说明:ChatGPT发布后,我第一时间体验了它的对话、翻译、编程、…...

计算机专业学习的核心是什么?
既然是学习CS,那么在这里,我粗浅的把计算机编程领域的知识分为三个部分: 基础知识 特定领域知识 框架和开发技能 基础知识是指不管从事任何方向的软件工程师都应该掌握的,比如数据结构、算法、操作系统。 特定领域知识就是你…...

基于springboot地方旅游系统的设计与实现
摘 要 本次设计内容是基于Springboot的旅游系统的设计与实现,采用B/S三层架构分别是Web表现层、Service业务层、Dao数据访问层,并使用Springboot,MyBatis二大框架整合开发服务器端,前端使用vue,elementUI技术&…...

一些学习资料链接
组件化和CocoaPods iOS 组件化的三种方案_迷曳的博客-CSDN博客 CocoaPods 私有化 iOS组件化----Pod私有库创建及使用 - 简书 CocoaPods1.9.1和1.8 使用 出现CDN: trunk URL couldnt be downloaded: - 简书 cocoapod制作私有库repo - 简书 【ios开发】 上传更新本地项目到…...

Webpack打包图片-JS-Vue
1 Webpack打包图片 2 Webpack打包JS代码 3 Babel和babel-loader 5 resolve模块解析 4 Webpack打包Vue webpack5打包 的过程: 在webpack的配置文件里面编写rules,type类型有多种,每个都有自己的作用,想要把小内存的图片转成bas…...
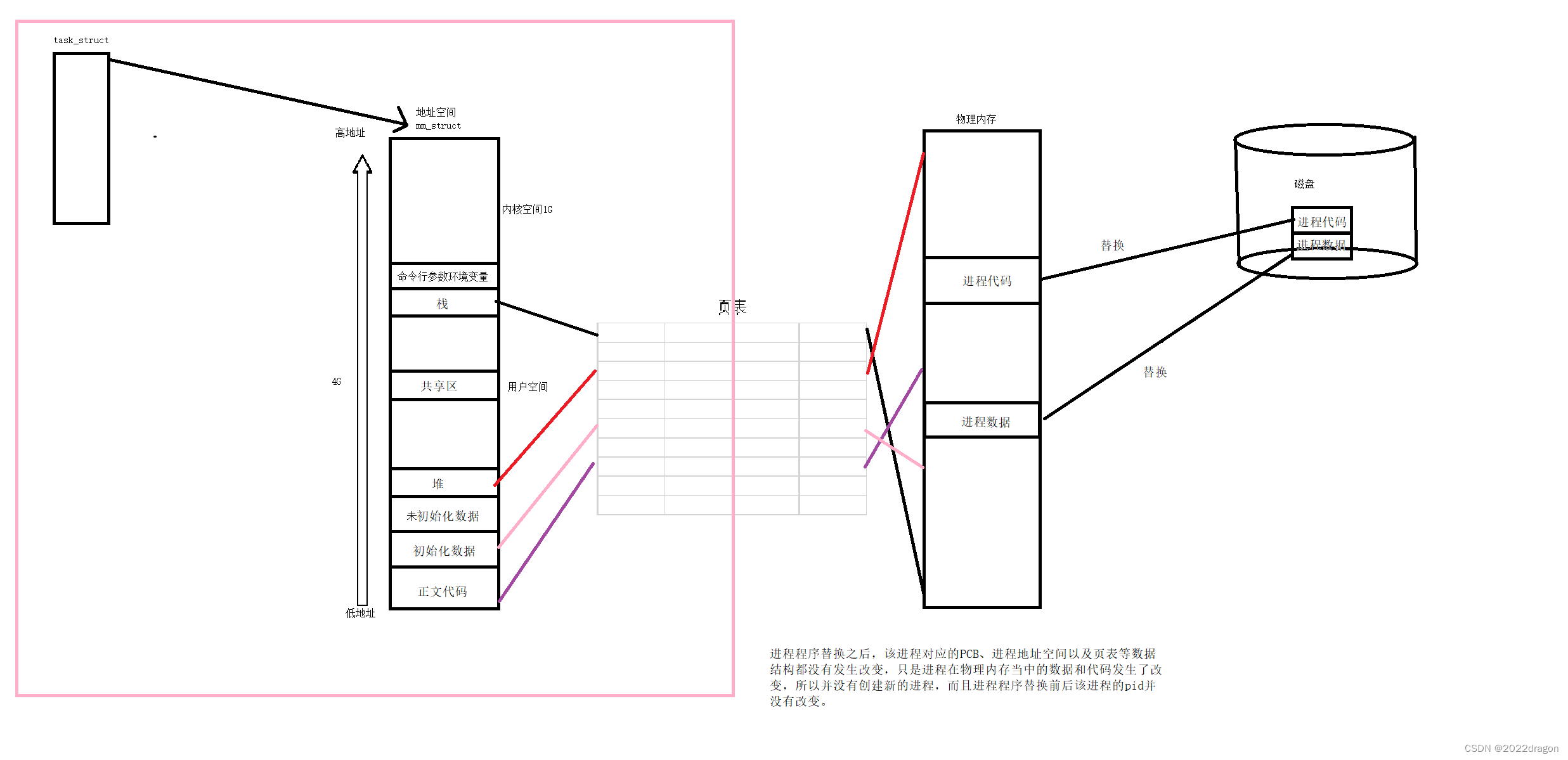
进程控制(Linux)
进程控制 fork 在Linux中,fork函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。 返回值: 在子进程中返回0,父进程中返回子进程的PID,子进程创建失败返回-1。 …...
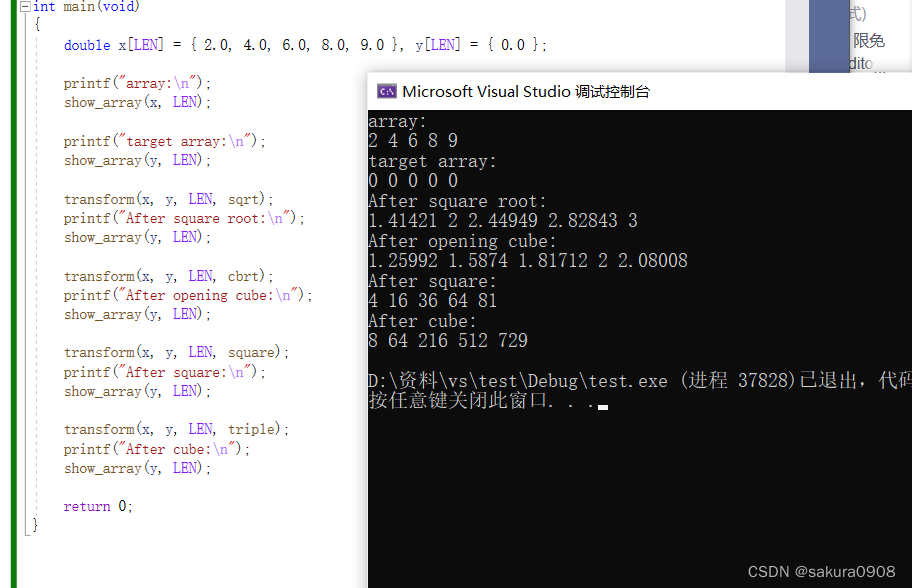
C Primer Plus第十四章编程练习答案
学完C语言之后,我就去阅读《C Primer Plus》这本经典的C语言书籍,对每一章的编程练习题都做了相关的解答,仅仅代表着我个人的解答思路,如有错误,请各位大佬帮忙点出! 由于使用的是命令行参数常用于linux系…...
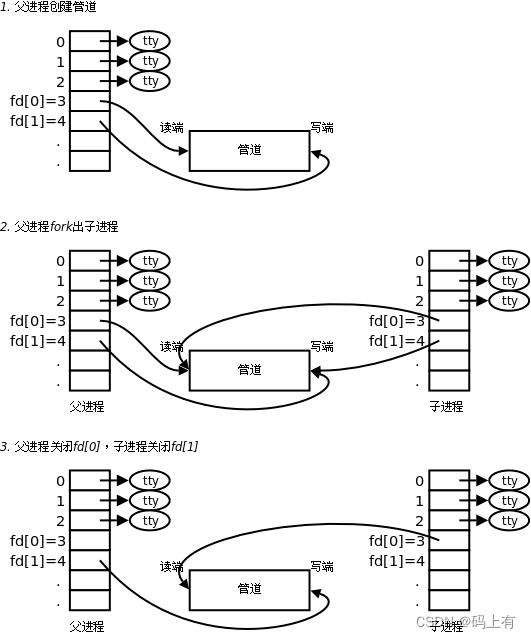
又名管道和无名管道
一、进程间通信(IPC,InterProcess Communication) 概念:就是进程和进程之间交换信息。 常用通信方式 无名管道(pipe) 有名管道 (fifo) 信号(signal) 共…...

操作系统复习4.1.0-文件管理结构
定义 一组有意义的信息的集合 属性 文件名、标识符、类型、位置、大小、创建时间、上次修改时间、文件所有者信息、保护信息 操作系统向上提供的功能 创建文件、删除文件、读文件、写文件、打开文件、关闭文件 这6个都是系统调用 创建文件 创建文件时调用Create系统调用…...
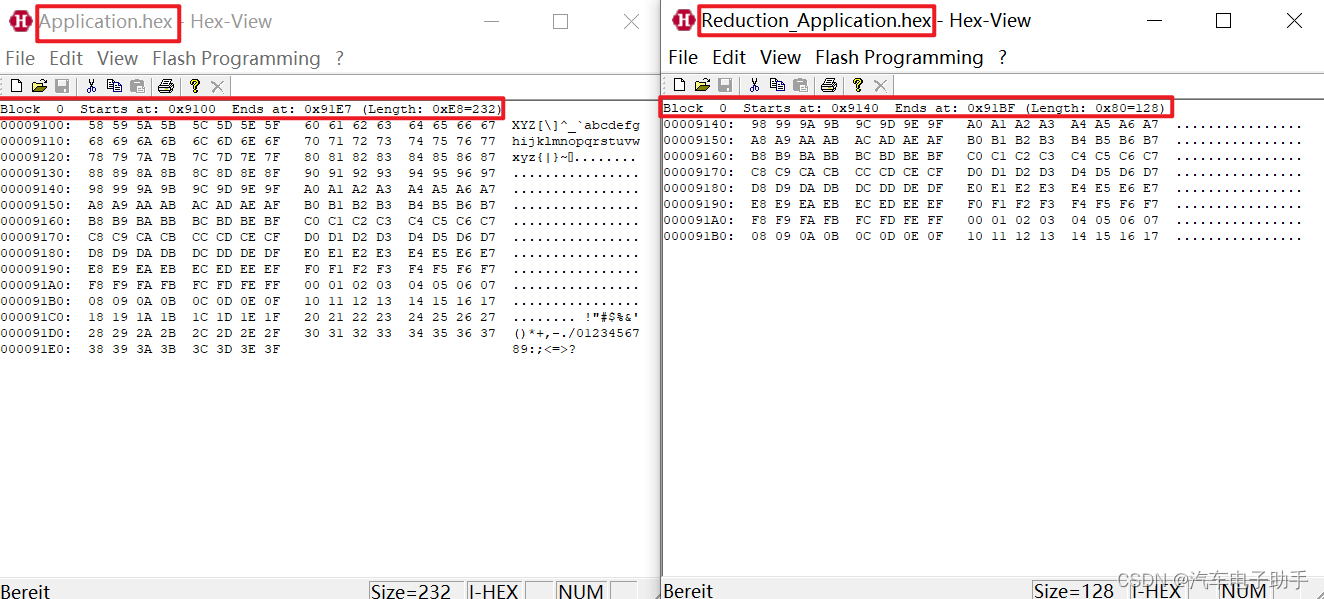
【嵌入式烧录/刷写文件】-2.6-剪切/保留Intel Hex文件中指定地址范围内的数据
案例背景: 有如下一段HEX文件,保留地址范围0x9140-0x91BF内的数据,删除地址范围0x9140-0x91BF外的数据。 :2091000058595A5B5C5D5E5F606162636465666768696A6B6C6D6E6F70717273747576775F :2091200078797A7B7C7D7E7F808182838485868788898A…...
)
JavaScript表单事件(下篇)
目录 八、keydown: 当用户按下键盘上的任意键时触发。 九、keyup: 当用户释放键盘上的键时触发。 十、keypress: 当用户按下键盘上的字符键时触发。 十一、focusin: 当表单元素或其子元素获得焦点时触发。 十二、focusout: 当表单元素或其子元素失去焦点时触发。 十三、c…...
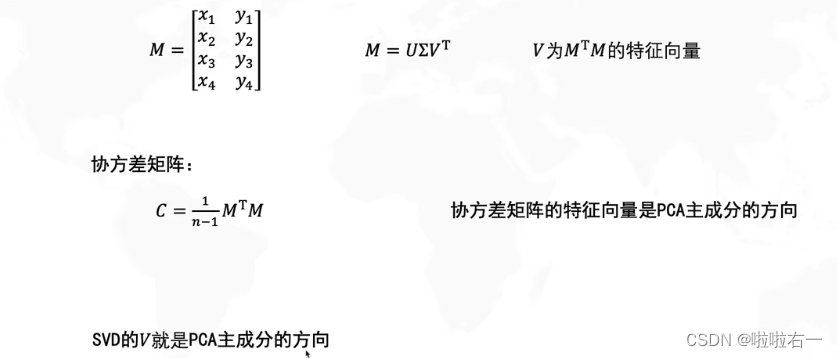
机器学习 | SVD奇异值分解
本文整理自哔哩哔哩视频:什么是奇异值分解SVD–SVD如何分解时空矩阵 📚奇异值分解是什么? M是原始矩阵,它可以是任意的矩阵,奇异值分解就是将它分解为三个矩阵相乘。U和V是方阵,∑是不规则矩阵,…...

chatgpt赋能python:Python取值:介绍
Python取值:介绍 Python是一种非常流行的高级编程语言,适用于各种任务,包括数据科学、机器学习、Web开发和自动化。它被广泛使用,因为它易于学习、易于使用、易于阅读和易于维护。Python中的取值对于程序员来说是一个极其有用的工…...

2025年终极指南:PlayIntegrityFix让你的Root设备完美通过Google认证
2025年终极指南:PlayIntegrityFix让你的Root设备完美通过Google认证 【免费下载链接】PlayIntegrityFix Fix Play Integrity (and SafetyNet) verdicts. 项目地址: https://gitcode.com/GitHub_Trending/pl/PlayIntegrityFix 还在为Root后的Android设备无法正…...

Hotkey Detective:3分钟找出Windows热键冲突的终极指南
Hotkey Detective:3分钟找出Windows热键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否遇…...

华硕笔记本性能控制终极指南:用GHelper告别臃肿,拥抱高效
华硕笔记本性能控制终极指南:用GHelper告别臃肿,拥抱高效 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivoboo…...

MobileSAM深度解析:轻量化图像分割架构揭秘与实战应用
MobileSAM深度解析:轻量化图像分割架构揭秘与实战应用 【免费下载链接】MobileSAM This is the official code for MobileSAM project that makes SAM lightweight for mobile applications and beyond! 项目地址: https://gitcode.com/gh_mirrors/mo/MobileSAM …...

大麦网自动抢票神器:5分钟配置,告别抢票焦虑的终极指南
大麦网自动抢票神器:5分钟配置,告别抢票焦虑的终极指南 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 还在为心仪演唱会门票…...

基于AM62x核心板的微电网智能化改造:异构多核驱动与边缘计算实践
1. 项目概述:当嵌入式核心板遇上微电网最近在做一个挺有意思的项目,客户想把他们园区里那套老旧的微电网系统给“智能化”一下。原来的系统,说白了就是一堆继电器、PLC和工控机攒起来的,数据采集靠串口,控制逻辑写在梯…...

Keil A51汇编器INCDIR参数分隔符问题解析
1. 问题现象与背景解析 最近在使用Keil C51开发工具链中的A51汇编器时,遇到了一个看似简单却令人困惑的报错。当执行以下命令时: A51 ASAMPLE.A51 PRINT(ASAMPLE.LST) INCDIR(H1;H2)系统抛出了致命错误: A51 FATAL ERROR -LINE: C:…...

通过Taotoken模型广场对比不同模型在代码生成任务上的效果与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken模型广场对比不同模型在代码生成任务上的效果与成本 对于开发者而言,选择合适的代码生成模型需要在效果、…...

深度解析抖音直播回放下载架构设计:从FLV流捕获到多线程存储优化
深度解析抖音直播回放下载架构设计:从FLV流捕获到多线程存储优化 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...

Finch微服务部署:基于Finagle的生产环境最佳实践
Finch微服务部署:基于Finagle的生产环境最佳实践 【免费下载链接】finch Scala combinator library for building Finagle HTTP services 项目地址: https://gitcode.com/gh_mirrors/fin/finch Finch是一个基于Scala的组合器库,专为构建Finagle H…...