Langchain-ChatGLM:基于本地知识库问答
文章目录
- ChatGLM与Langchain简介
- ChatGLM-6B简介
- ChatGLM-6B是什么
- ChatGLM-6B具备的能力
- ChatGLM-6B具备的应用
- Langchain简介
- Langchain是什么
- Langchain的核心模块
- Langchain的应用场景
- ChatGLM与Langchain项目介绍
- 知识库问答实现步骤
- ChatGLM与Langchain项目特点
- 项目主体结构
- 项目效果优化方向
- 项目后续开发计划
- ChatGLM与Langchain项目实战过程
- 实战(一)
- 实战(二)
项目地址:https://github.com/imClumsyPanda/langchain-ChatGLM
ChatGLM与Langchain简介
ChatGLM-6B简介
ChatGLM-6B是什么
ChatGLM-6B地址:https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B 是⼀个开源的、⽀持中英双语的
对话语⾔模型,基于 General Language
Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
更新 v1.1 版本 checkpoint, 训练数据增加英⽂
指令微调数据以平衡中英⽂数据⽐例,解决英
⽂回答中夹杂中⽂词语的现象。
ChatGLM-6B具备的能力
- 自我认知(可以对自己进行介绍,优点缺点等)
- 提纲写作(比如:帮我写一个介绍ChatGLM的博客提纲)
- 文案写作(根据一段话来生成一段文案)
- 信息抽取(抽取一段文本的人物,时间,地点等实体信息)
- 角色扮演(指定ChatGLM为一个角色,进行对话)
ChatGLM-6B具备的应用
大语言模型通常基于通识知识进行训练的,而在
⾯向某些领域的具体场景时,常常需要借助模型微调或提示
词⼯程提升语言模型应用效果:
常见的场景如:
- 垂直领域知识的特定任务(金融领域,法律领域)
- 基于垂直领域知识库的问答
模型微调与提示词工程的区别:
模型微调:针对预训练好的语言模型,在特定任务的数据集上进行进一步的微调训练,需要有标记好的特定任务的数据。
提示工程:核心是设计自然语言提示或指定,引导模型完成特定任务,适合需要明确输出的任务。
Langchain简介
Langchain是什么
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。他主要拥有 3个能力:
- 可以调用LLM模型
- 可以将 LLM 模型与外部数据源进行连接
- 允许与 LLM 模型进行交互
Langchain的核心模块
Langchain的核心模块如下:
- Modules:支持的模型类型和集成,如:openai,huggingface等;
- Prompt:提示词管理、优化和序列化,支持各种自定义模板;
- Memory:内存管理(在链/代理调用之间持续存在的状态);
- Indexes:索引管理,方便加载、查询和更新外部数据;
- Agents:代理,是一个链,可以决定和执行操作,并观察结果,直到指令完成;
- Callbacks:回调,允许记录和流式传输任何链的中间步骤,方便观察、调试和评估。
Agents代理执行过程如下:
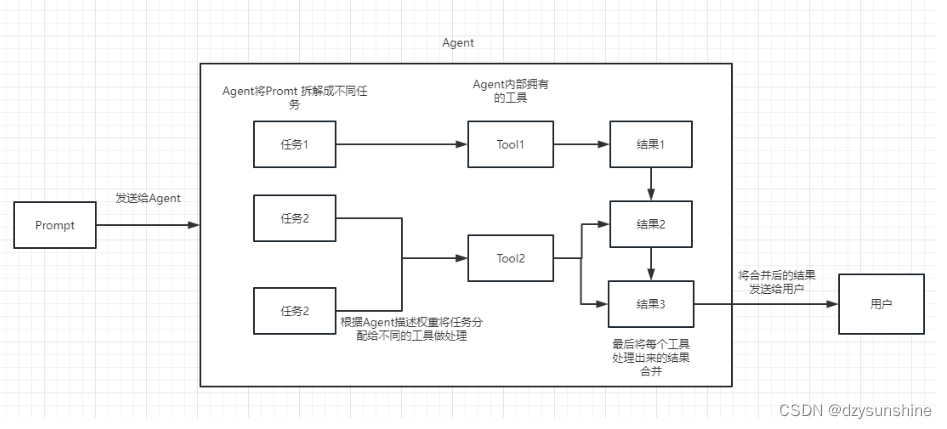
Langchain的应用场景
- 文档问答
- 个人助理
- 查询表格
- 与API交互
- 信息提取
- 文档总结
ChatGLM与Langchain项目介绍
知识库问答实现步骤
基于Langchain思想实现基于本地知识库的问答应用。实现过程如下:
1、加载文件
2、读取文本
3、文本分割
4、文本向量化
5、问句向量化
6、在文本向量中匹配出与问句向量最相似的top k个
7、匹配出的文本作为上下文和问题一起添加到prompt中
8、提交给LLM生成回答。
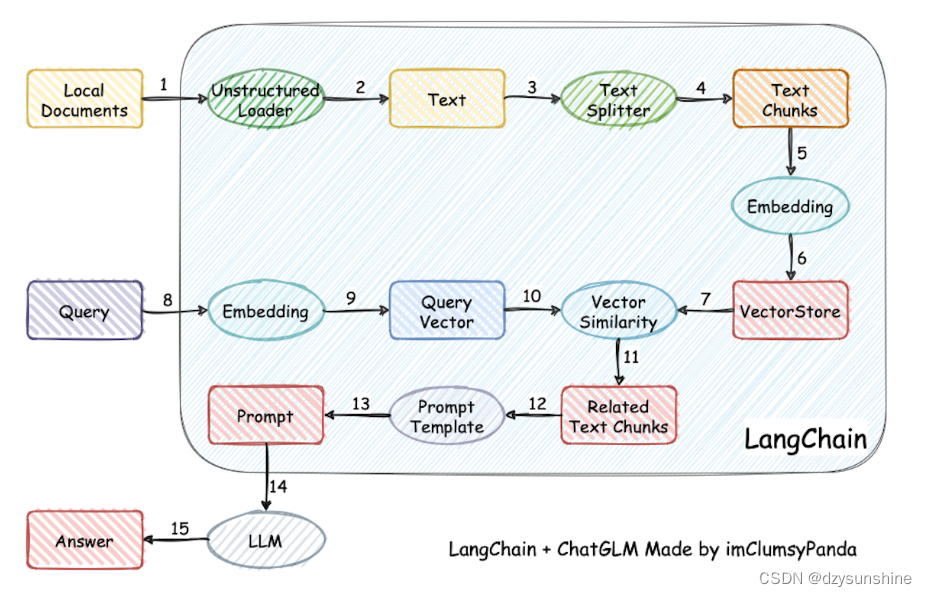
还有另一个版本(本质是一样的)
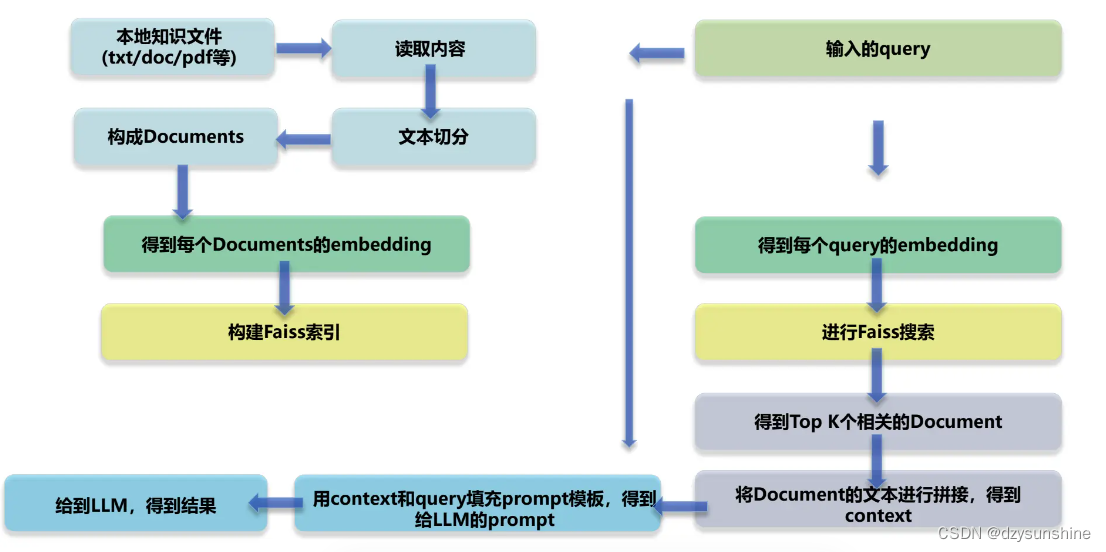
ChatGLM与Langchain项目特点
- 依托 ChatGLM 等开源模型实现, 可离线部署
- 基于 langchain 实现,可快速实现接入多种数据源
- 在分句、文档读取等方面,针对中文使用场景优化
- 支持pdf、 txt、 md、 docx等⽂件类型接⼊,具备命令行demo、 webui 和 vue 前端。
项目主体结构
- models: llm的接⼝类与实现类,针对开源模型提供流式输出⽀持。
- loader: 文档加载器的实现类。
- textsplitter: 文本切分的实现类。
- chains: 工作链路实现,如 chains/local_doc_qa 实现了基于本地⽂档的问答实现。
- content:用于存储上传的原始⽂件。
- vector_store:用于存储向量库⽂件,即本地知识库本体。
- configs:配置文件存储。
项目效果优化方向
- 模型微调:一个是对embedding模型的基于垂直领域的数据进行微调;一个是对LLM模型及进行基于垂直领域的微调;
- 文档加工:一种是使用更好的文档拆分的方式(如项目中已经集成的达摩院的语义识别的模型及进行拆分);一种是改进填充的方式,判断中心句上下文的句子是否和中心句相关,仅添加相关度高的句子;另一种是文本分段后,对每段分别及进行总结,基于总结内容语义及进行匹配;
- 借助不同模型的能力:在 text2sql、text2cpyher 场景下
需要产生代码时,可借助不同
模型能力。
项目后续开发计划
- 扩充数据源:增加库表、图谱、网页等数据接入;
- 知识库管理:完善知识库中增删改查功能,并支持更多向量库类型;
- 扩充文本划分方式:针对中文场景,提供更多文本划分与上下文扩充方式;
- 探索Agent应用:利用开源LLM探索Agent的实现与应用。
参考:https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
ChatGLM与Langchain项目实战过程
实战(一)
https://github.com/imClumsyPanda/langchain-ChatGLM
由于之前已经对ChatGLM进行过部署,所以考虑可以直接在原有环境中安装新的所需的包即可,同样也可以使用之前下载好的模型文件:ChatGLM部署
但看了下requirements.txt文件后还有不少需要安装的包,索性直接新建一个python3.8.13的环境(模型文件还是可以用的)
conda create -n langchain python==3.8.13
拉取项目
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
进入目录
cd langchain-ChatGLM
安装requirements.txt
conda activate langchain
pip install -r requirements.txt
当前环境支持装langchain的最高版本是0.0.166,无法安装0.0.174,就先装下0.0.166试下。
修改配置文件路径:
vi configs/model_config.py
将chatglm-6b的路径设置成自己的。
“chatglm-6b”: {
“name”: “chatglm-6b”,
“pretrained_model_name”: “/data/sim_chatgpt/chatglm-6b”,
“local_model_path”: None,
“provides”: “ChatGLM”
修改要运行的代码文件:webui.py,
vi webui.py
将最后launch函数中的share设置为True,inbrowser设置为True。
执行webui.py文件
python webui.py
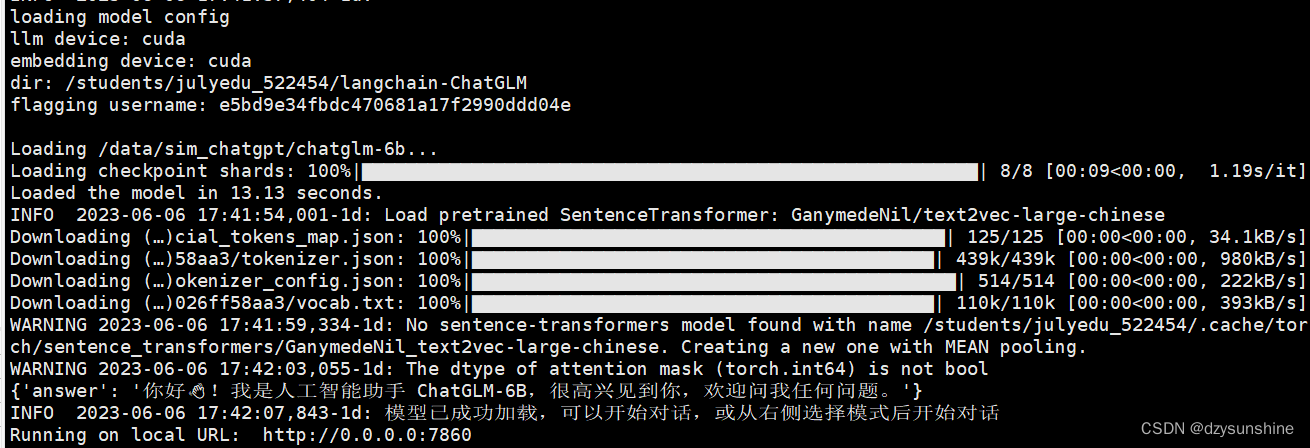
可能是网络问题,无法创建一个公用链接。可以进行云服务器和本地端口的映射,参考:https://www.cnblogs.com/monologuesmw/p/14465117.html

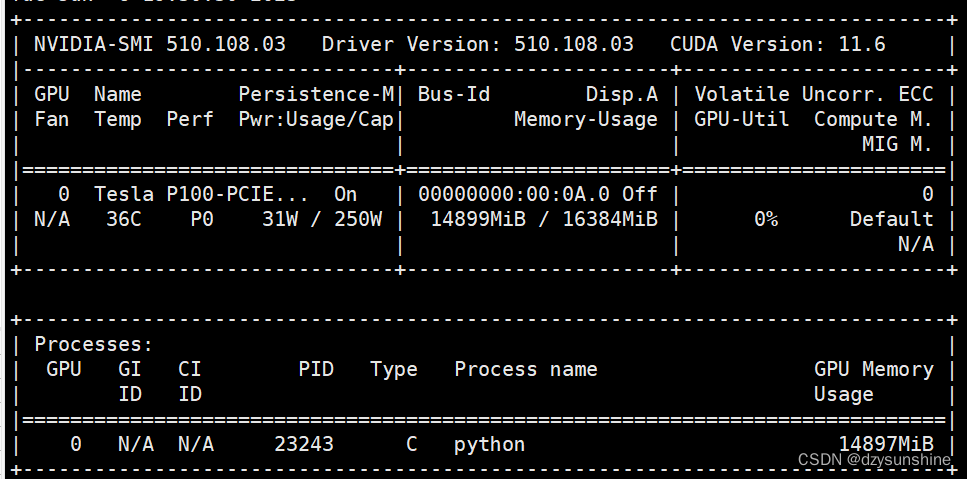
对应输出:
占用显存情况:大约15个G
实战(二)
待更…
相关文章:
Langchain-ChatGLM:基于本地知识库问答
文章目录 ChatGLM与Langchain简介ChatGLM-6B简介ChatGLM-6B是什么ChatGLM-6B具备的能力ChatGLM-6B具备的应用 Langchain简介Langchain是什么Langchain的核心模块Langchain的应用场景 ChatGLM与Langchain项目介绍知识库问答实现步骤ChatGLM与Langchain项目特点 项目主体结构项目…...

设计模式十 适配器模式
适配器模式 适配器模式是一种结构型设计模式。作用:当接口无法和类匹配到一起工作时,通过适配器将接口变换成可以和类匹配到一起的接口。(注:适配器模式主要解决接口兼容性问题) 适配器的优点与缺点: 优…...
1.6 初探JdbcTemplate操作
一、JdbcTemplate案例演示 1、创建数据库与表 (1)创建数据库 执行命令:CREATE DATABASE simonshop DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; 或者利用菜单方式创建数据库 - simonshop 打开数据库simonshop &#x…...
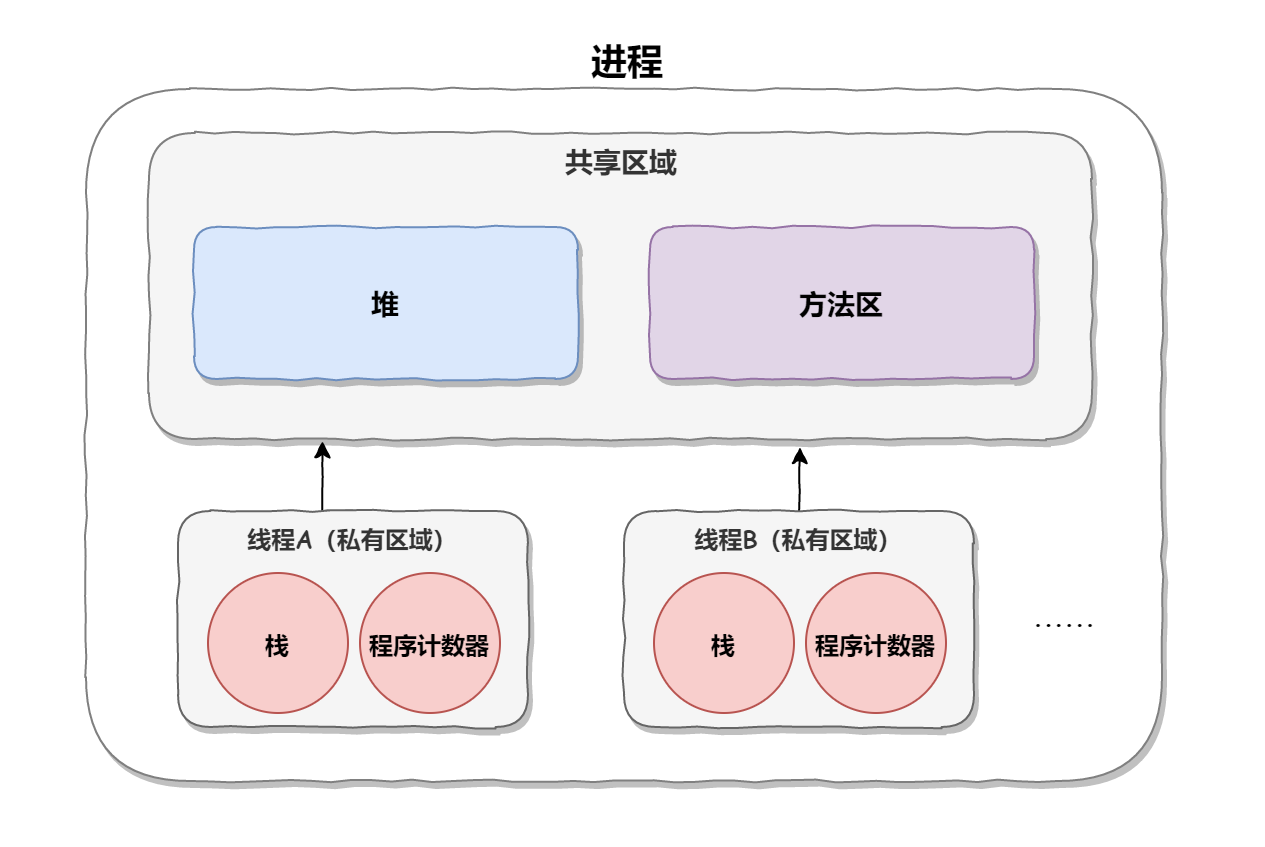
为什么要用线程池?
线程池是一种管理和复用线程资源的机制,它由一个线程池管理器和一组工作线程组成。线程池管理器负责创建和销毁线程池,以及管理线程池中的工作线程。工作线程则负责执行具体的任务。 线程池的主要作用是管理和复用线程资源,避免了线程的频繁…...

c语言的预处理和编译
预处理 文件包含 当预处理器发现#include指令时,会查看后面的文件名并把文件的内容包含到当前文件中 两种写法 尖括号:引用的是编译器的库路径里面的头文件。 双引号:引用的是程序目录中相对路径中的头文件,如果找不到再去上面…...
网络安全必学 SQL 注入
1.1 .Sql 注入攻击原理 SQL 注入漏洞可以说是在企业运营中会遇到的最具破坏性的漏洞之一,它也是目前被利用得最多的漏洞。要学会如何防御 SQL 注入,首先我们要学习它的原理。 针对 SQL 注入的攻击行为可描述为通过在用户可控参数中注入 SQL 语法&#x…...

Docker基础知识详解
✅作者简介:热爱Java后端开发的一名学习者,大家可以跟我一起讨论各种问题喔。 🍎个人主页:Hhzzy99 🍊个人信条:坚持就是胜利! 💞当前专栏:文章 🥭本文内容&am…...

腾讯、阿里入选首批“双柜台证券”,港股市场迎盛夏升温?
6月5日,香港交易所发布公告,将于6月19日在香港证券市场推出“港币-人民币双柜台模式”,当日确定有21只证券指定为双柜台证券。同时,港交所还表示,在双柜台模式推出前,更多证券或会被接纳并加入双…...

CentOS7 使用Docker 安装MySQL
CentOS7 使用Docker 安装MySQL Docker的相关知识本篇不会再概述,有疑惑的同学请自行查找相关知识。本篇只是介绍如何在CentOS7下使用Docker安装相应的镜像。 可登陆Docker官网 https://docs.docker.com 之后可以跟着官方的步骤进行安装。 clipboard.png 具体安装过…...

注解和反射复习
注解 注解:给程序和人看的,被程序读取,jdk5.0引用 内置注解 override:修饰方法,方法声明和重写父类方法, Deprecated:修饰,不推荐使用 suppressWarnings用来抑制编译时的警告,必须添加一个或多个参数s…...

RocketMQ的demo代码
下面是一个使用Java实现的RocketMQ示例代码,用于发送和消费消息: 首先,您需要下载并安装RocketMQ,并启动NameServer和Broker。 接下来,您可以使用以下示例代码来发送和消费消息: Producer.java文件&…...
)
C++ 连接、操作postgreSQL(基于libpq库)
C++ 连接postgreSQL(基于libpq库) 1.环境2.数据库操作2.1. c++ 连接数据库2.2. c++ 删除数据库属性表内容2.3. c++ 插入数据库属性表内容2.4 c++ 关闭数据库1.环境 使用libpq库来链接postgresql数据库,主要用到的头文件是这个: #include "libpq-fe.h"2.数据库操…...

Node.js技术简介及其在Web开发中的应用
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,使得JavaScript能够在服务器端运行。Node.js采用事件驱动、非阻塞I/O模型,能够处理大量并发请求,非常适合处理I/O密集型的应用程序。本文将介绍Node.js的特点、优势以及在Web开发中的应…...

时间序列分析:原理与MATLAB实现
2023年9月数学建模国赛期间提供ABCDE题思路加Matlab代码,专栏链接(赛前一个月恢复源码199,欢迎大家订阅):http://t.csdn.cn/Um9Zd 目录 1. 时间序列分析简介 2. 自回归模型(AR) 2.1. 参数估计 2.2. MATLAB实现...
,0,1),字段名 或者 if(isnull(字段名),1,0),字段名)
mysql排序之if(isnull(字段名),0,1),字段名 或者 if(isnull(字段名),1,0),字段名
mysql排序之if(isnull(字段名),0,1),字段名 或者 if(isnull(字段名),1,0),字段名 默认情况下,MySQL将null算作最小值。如果想要手动指定null的顺序,可以这样处理: 将null强制放在最前 //null, null, 1,2,3,4(默认就是这样&#…...

华为OD机试真题 Java 实现【递增字符串】【2023Q1 200分】,附详细解题思路
一、题目描述 定义字符串完全由“A’和B"组成,当然也可以全是"A"或全是"B。如果字符串从前往后都是以字典序排列的,那么我们称之为严格递增字符串。 给出一个字符串5,允许修改字符串中的任意字符,即可以将任何的"A"修改成"B,也可以将…...
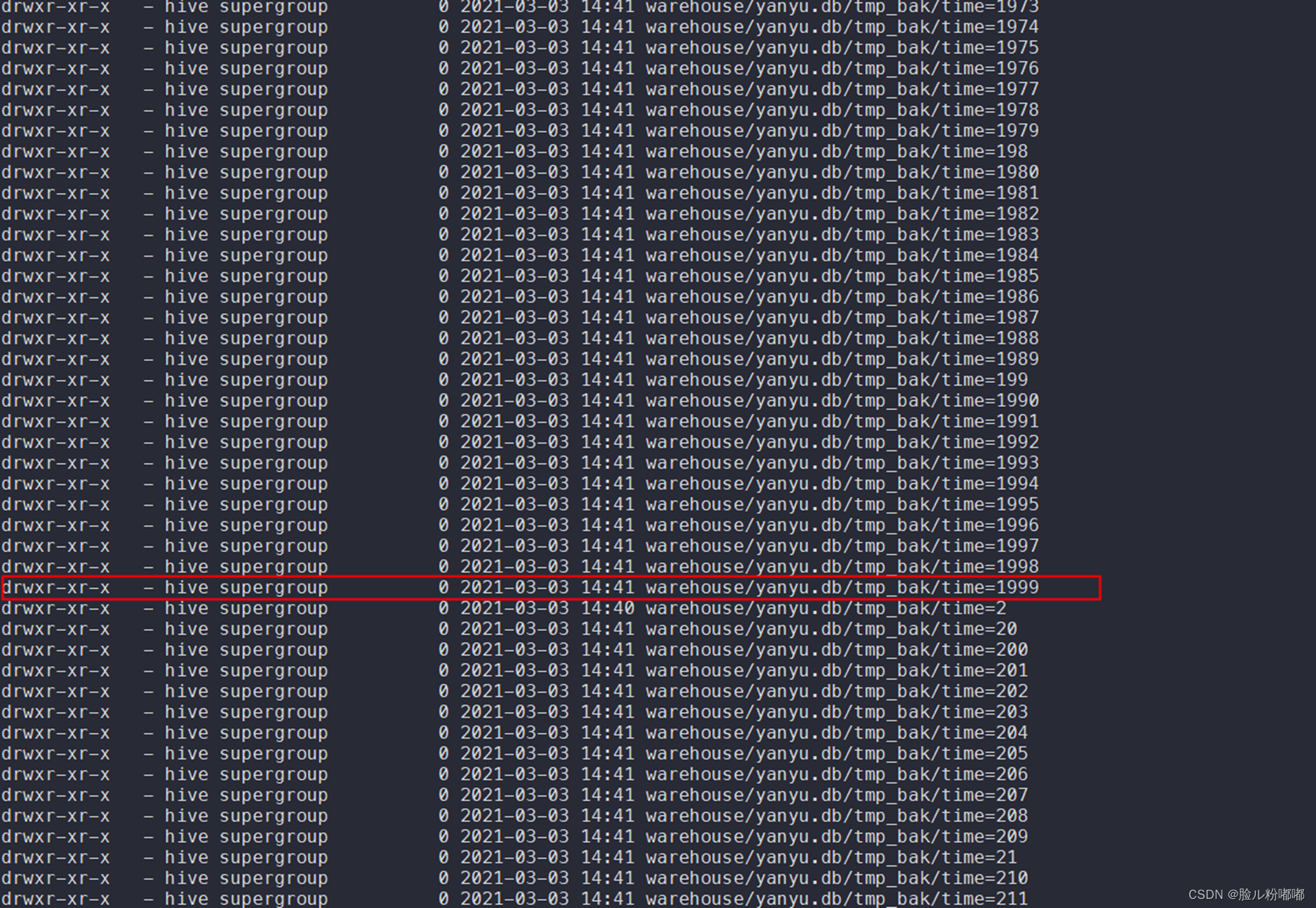
合并文件解决HiveServer2内存溢出方案
一、文件过多导致HiveServer2内存溢出 1.1查看表文件个数 desc formatted yanyu.tmp• 表文件数量为6522102 1.2查看表文件信息 hadoop fs -ls warehouse/yanyu.db/tmp• 分区为string 类型的time字段,分了2001个区。 1.3.查看某个分区下的文件个数为10000个 …...

韧性数据安全体系缘起与三个目标 |CEO专栏
今年4月,美创科技在数据安全领域的新探索——“韧性”数据安全防护体系框架正式发布亮相。 为帮您更深入了解“韧性数据安全”,我们特别推出专栏“构建适应性进化的韧性数据安全体系”,CEO柳遵梁亲自执笔,进行系列解读分享。 首期…...

华为OD机试真题 Java 实现【火车进站】【牛客练习题】
一、题目描述 给定一个正整数N代表火车数量,0<N<10,接下来输入火车入站的序列,一共N辆火车,每辆火车以数字1-9编号,火车站只有一个方向进出,同时停靠在火车站的列车中,只有后进站的出站了,先进站的才能出站。 要求输出所有火车出站的方案,以字典序排序输出。 …...

c#快速入门(下)
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析2 目录 👉🏻Inline和lambda委托和lambda 👉…...
)
农业电商服务系统(10078)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

2026最新免费在线去水印软件推荐:性能对比与选择指南
在2026年,处理视频和图片水印已经成为内容创作者和日常用户的常见需求。无论是社交媒体截图、下载的素材,还是自己录制的视频,水印往往会影响最终的呈现效果。那么,免费在线去水印软件哪个好?不同工具间的优缺点对比如…...

LeetCode 15:三数之和 | 双指针法详解与进阶应用
LeetCode 15:三数之和 | 双指针法详解与进阶应用 引言 三数之和(3Sum)是 LeetCode 中一道经典的高频面试题,编号为 15,属于 Medium 难度范畴。这道题的核心要求是在一个整数数组中找出所有不重复的三元组,使…...

通过 API 实时监听企业微信外部群变更事件并同步本地数据库
能力介绍 在企业微信外部群的协同管理中,群聊的名称修改、群主变更、新成员加入或老成员退群等状态变更,往往无法仅靠主动拉取来感知。该能力通过配置接收事件服务器(Callback),利用标准的 HTTP POST 请求实时接收企微…...

标准化封装国产电源:钡特电源 VB50-24S24LD 与金升阳 URB2424LD-50WR3 同属工业高可靠
在工业电子系统设计中,工业 DC-DC 电源模块作为核心供电单元,其标准化程度、稳定性及适配性直接影响设备整体可靠性与研发效率。钡特电源 VB50-24S24LD 与金升阳 URB2424LD-50WR3 作为 50W 级国产工业 DC-DC 代表产品,均采用国际标准封装引脚…...

聊一聊5家软件许可优化公司,哪个更适合你?
做软件资产管理的朋友应该都有同感:软件许可这事儿,水太深了。尤其这几年大厂审计越来越狠,一不小心就是几百万的罚单。所以很多公司开始找专门做软件许可优化的服务商。今天聊聊5家比较有代表性的:、Flexera、Snow、Anglepoint和…...

MapReduce数据倾斜解决方案
前言 在MapReduce生产环境中,数据倾斜是最常见也最致命的性能杀手。一个看似完美的分布式程序,可能因为某个ReduceTask处理的数据量远超其他任务,导致整个作业卡死数小时甚至失败。本文将从倾斜现象识别、根因分析、六大解决方案到实战案例&…...

Emacs-which-key排序与分页功能详解:高效管理大量快捷键的完整指南
Emacs-which-key排序与分页功能详解:高效管理大量快捷键的完整指南 【免费下载链接】emacs-which-key Emacs package that displays available keybindings in popup 项目地址: https://gitcode.com/gh_mirrors/em/emacs-which-key Emacs-which-key是Emacs编…...

JetBrains IDE试用期重置终极指南:轻松解决IDE过期问题
JetBrains IDE试用期重置终极指南:轻松解决IDE过期问题 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经遇到过这样的困扰:正在专注编码时,突然弹出的"试用期已结…...

遥测数据定义的生产级落地规范指南
在分布式架构与微服务体系中,将 Tracing(链路)、Metrics(指标)、Logs(日志)三种遥测数据有机构建为“三位一体” (3D Observability) 的可观测性网络,是保障系统高可用性的基石。 以…...