手动计算校正年龄、性别后的标准化死亡率 (SMR)
分析队列人群有无死亡人数超额,通常应用标准人群死亡率来校正,即刻观察到中的实际死亡数(D)与定一个标准的死亡人数(E),D与E之比称为死亡比(standarized Mortality ratio,SMR). 标准化死亡率 (SMR) 是观察到的病例与预期病例的比率。

今天我们介绍一下怎么通过手动计算校正年龄、性别后的标准化死亡率 (SMR)。 我们先导入R包和数据,也不能算完全手动,还是需要用到survival包。
library(survival)
bc<-read.csv("E:/r/test/smr1.csv",sep=',',header=TRUE)
head(bc,6)
## sex age entry_date status futime
## 1 male 11213.45 1985/2/26 1 2750.988
## 2 female 6681.62 1994/3/1 0 1981.679
## 3 male 10411.76 1992/6/6 0 2979.385
## 4 female 10665.13 1985/9/22 0 2576.967
## 5 male 19065.91 1986/11/2 0 4993.524
## 6 male 10154.70 1993/4/23 0 1821.558
这是一个很简单的数据,sex为性别,age是年龄,entry_date为诊断也就是进入这个队列的时间,status为结局变量,futime为生存时间。(公众号回复:SMR1可以获得该数据) 先处理一下生存时间
bc$entry_date<-as.Date(bc$entry_date)
我们首先要算出它的haz, 每人年的平均人口死亡率(d/(pyrs),其中d是死亡人数,pyrs是人年),可以通过survival包的survexp函数计算。sex这个指标不能少,如果全是女的也要设置.
bc$risk1 <- -log(survexp(futime ~ 1, data = bc, rmap = list(year = entry_date, age = age, sex = sex), cohort = FALSE, conditional = TRUE))
survexp函数中选项还有一个费率表,就是用来调整生成的预测概率的,可以理解为校正功能。 survival函数自带了3个survexp.us, survexp.usr和survexp.mn. survexp.usr就是1940年至2014年按年龄、性别和种族划分的美国人口。这里有黑人和白人的数据集,我这里只取白人的
survexp.uswhite <- survexp.usr[,,"white",]
head(survexp.uswhite ,6)
## Rate table with dimension(s): age sex year
## , , year = 1940
##
## sex
## age male female
## 0 1.350207e-04 1.057536e-04
## 1 1.336591e-05 1.185314e-05
## 2 7.264935e-06 6.029907e-06
## 3 5.206865e-06 4.411492e-06
## 4 4.192119e-06 3.506694e-06
## 5 3.780843e-06 3.013293e-06
##
## , , year = 1941
##
## sex
## age male female
## 0 1.300527e-04 1.017030e-04
## 1 1.260761e-05 1.118577e-05
## 2 6.919267e-06 5.733727e-06
## 3 4.976544e-06 4.208639e-06
## 4 4.019425e-06 3.345001e-06
## 5 3.624615e-06 2.879024e-06
##
## , , year = 1942
##
如果你想算某个地方的生存率,可以使用当地人口普查数据,这里我们把费率表加进去。
bc$risk2 <- -log(survexp(futime ~ 1, data = bc, rmap = list(year = entry_date, age = age, sex = sex), cohort = FALSE, ratetable = survexp.uswhite , conditional = TRUE))
head(bc,6)
## sex age entry_date status futime risk1 risk2
## 1 male 11213.45 1985-02-26 1 2750.988 0.017979337 0.015404330
## 2 female 6681.62 1994-03-01 0 1981.679 0.002648331 0.002482978
## 3 male 10411.76 1992-06-06 0 2979.385 0.015381638 0.013551117
## 4 female 10665.13 1985-09-22 0 2576.967 0.006089193 0.005058961
## 5 male 19065.91 1986-11-02 0 4993.524 0.186826509 0.175753223
## 6 male 10154.70 1993-04-23 0 1821.558 0.008510061 0.007464535
可以看到,加入费率表的概率和不加的是不一样的。算出了预测概率后我们就可以进一步计算了。
O <- sum(bc$status)
E <- sum(bc$risk2)
O;
## [1] 46
E
## [1] 6.74174
可以得到O为46,E为6.74.SMR等于O/E
SMR <- O/E
SMR
## [1] 6.823164
接下来计算可信区间,先设置一下alpha
alpha = 0.05
接下来计算可信区间,公式是固定的,直接放进去就可以了
SMR.lo <- O/E * (1 - 1/9/O - qnorm(1 - alpha/2)/3/sqrt(O))^3
SMR.up <- (O + 1)/E * (1 - 1/9/(O + 1) + qnorm(1 - alpha/2)/3/sqrt(O + 1))^3
SMR.lo
## [1] 4.994967
SMR.up
## [1] 9.101355
这样全部结果就计算出来啦,计算结果我们使用survexp.fr包来验证一下
library(survexp.fr)
attach(bc)
bc$entry_date<-as.Date(bc$entry_date)
SMR(futime, status, age, sex, entry_date,ratetable =survexp.uswhite)
## $O
## [1] 46
##
## $E
## [1] 6.74174
##
## $SMR.classic
## $SMR.classic$SMR
## [1] 6.823164
##
## $SMR.classic$SMR.lo
## [1] 4.994967
##
## $SMR.classic$SMR.up
## [1] 9.101355
##
## $SMR.classic$p.value
## [1] 0
##
##
## $SMR.poisson
## $SMR.poisson$SMR
## [1] 6.823164
##
## $SMR.poisson$SMR.lo
## [1] 5.110733
##
## $SMR.poisson$SMR.up
## [1] 9.109373
##
## $SMR.poisson$p.value
## [1] 8.903473e-39
两者算得一模一样。
相关文章:
手动计算校正年龄、性别后的标准化死亡率 (SMR)
分析队列人群有无死亡人数超额,通常应用标准人群死亡率来校正,即刻观察到中的实际死亡数(D)与定一个标准的死亡人数(E),D与E之比称为死亡比(standarized Mortality ratio,…...

Java组合模式:构建多层次公司组织架构
在现实生活中,常常会遇到用树形结构组织的一些场景,比如国家省市,学校班级,文件目录,分级导航菜单,以及典型的公司组织架构,整个层次结构自顶向下呈现一颗倒置的树。这种树形结构在面向对象的世…...
Langchain-ChatGLM:基于本地知识库问答
文章目录 ChatGLM与Langchain简介ChatGLM-6B简介ChatGLM-6B是什么ChatGLM-6B具备的能力ChatGLM-6B具备的应用 Langchain简介Langchain是什么Langchain的核心模块Langchain的应用场景 ChatGLM与Langchain项目介绍知识库问答实现步骤ChatGLM与Langchain项目特点 项目主体结构项目…...

设计模式十 适配器模式
适配器模式 适配器模式是一种结构型设计模式。作用:当接口无法和类匹配到一起工作时,通过适配器将接口变换成可以和类匹配到一起的接口。(注:适配器模式主要解决接口兼容性问题) 适配器的优点与缺点: 优…...
1.6 初探JdbcTemplate操作
一、JdbcTemplate案例演示 1、创建数据库与表 (1)创建数据库 执行命令:CREATE DATABASE simonshop DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; 或者利用菜单方式创建数据库 - simonshop 打开数据库simonshop &#x…...
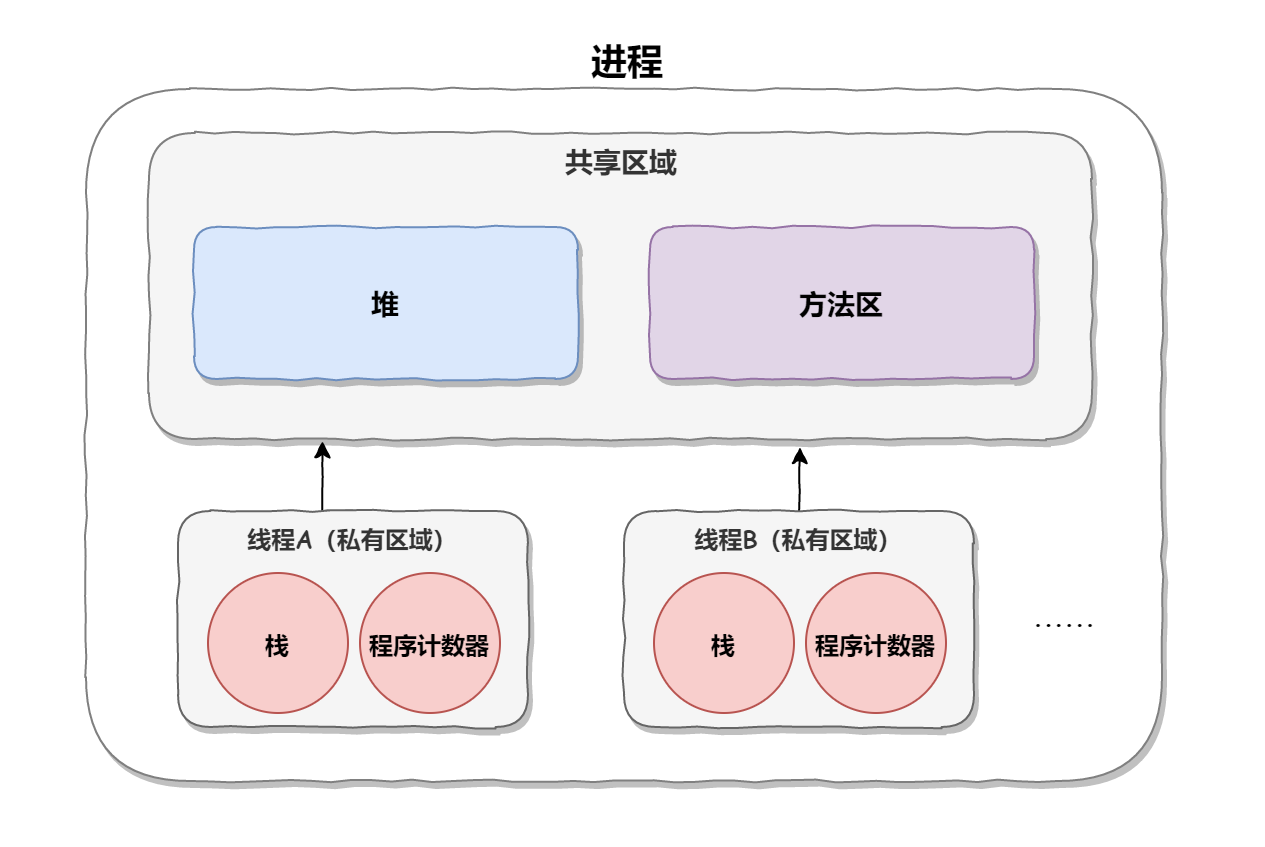
为什么要用线程池?
线程池是一种管理和复用线程资源的机制,它由一个线程池管理器和一组工作线程组成。线程池管理器负责创建和销毁线程池,以及管理线程池中的工作线程。工作线程则负责执行具体的任务。 线程池的主要作用是管理和复用线程资源,避免了线程的频繁…...

c语言的预处理和编译
预处理 文件包含 当预处理器发现#include指令时,会查看后面的文件名并把文件的内容包含到当前文件中 两种写法 尖括号:引用的是编译器的库路径里面的头文件。 双引号:引用的是程序目录中相对路径中的头文件,如果找不到再去上面…...
网络安全必学 SQL 注入
1.1 .Sql 注入攻击原理 SQL 注入漏洞可以说是在企业运营中会遇到的最具破坏性的漏洞之一,它也是目前被利用得最多的漏洞。要学会如何防御 SQL 注入,首先我们要学习它的原理。 针对 SQL 注入的攻击行为可描述为通过在用户可控参数中注入 SQL 语法&#x…...

Docker基础知识详解
✅作者简介:热爱Java后端开发的一名学习者,大家可以跟我一起讨论各种问题喔。 🍎个人主页:Hhzzy99 🍊个人信条:坚持就是胜利! 💞当前专栏:文章 🥭本文内容&am…...

腾讯、阿里入选首批“双柜台证券”,港股市场迎盛夏升温?
6月5日,香港交易所发布公告,将于6月19日在香港证券市场推出“港币-人民币双柜台模式”,当日确定有21只证券指定为双柜台证券。同时,港交所还表示,在双柜台模式推出前,更多证券或会被接纳并加入双…...

CentOS7 使用Docker 安装MySQL
CentOS7 使用Docker 安装MySQL Docker的相关知识本篇不会再概述,有疑惑的同学请自行查找相关知识。本篇只是介绍如何在CentOS7下使用Docker安装相应的镜像。 可登陆Docker官网 https://docs.docker.com 之后可以跟着官方的步骤进行安装。 clipboard.png 具体安装过…...

注解和反射复习
注解 注解:给程序和人看的,被程序读取,jdk5.0引用 内置注解 override:修饰方法,方法声明和重写父类方法, Deprecated:修饰,不推荐使用 suppressWarnings用来抑制编译时的警告,必须添加一个或多个参数s…...

RocketMQ的demo代码
下面是一个使用Java实现的RocketMQ示例代码,用于发送和消费消息: 首先,您需要下载并安装RocketMQ,并启动NameServer和Broker。 接下来,您可以使用以下示例代码来发送和消费消息: Producer.java文件&…...
)
C++ 连接、操作postgreSQL(基于libpq库)
C++ 连接postgreSQL(基于libpq库) 1.环境2.数据库操作2.1. c++ 连接数据库2.2. c++ 删除数据库属性表内容2.3. c++ 插入数据库属性表内容2.4 c++ 关闭数据库1.环境 使用libpq库来链接postgresql数据库,主要用到的头文件是这个: #include "libpq-fe.h"2.数据库操…...

Node.js技术简介及其在Web开发中的应用
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,使得JavaScript能够在服务器端运行。Node.js采用事件驱动、非阻塞I/O模型,能够处理大量并发请求,非常适合处理I/O密集型的应用程序。本文将介绍Node.js的特点、优势以及在Web开发中的应…...

时间序列分析:原理与MATLAB实现
2023年9月数学建模国赛期间提供ABCDE题思路加Matlab代码,专栏链接(赛前一个月恢复源码199,欢迎大家订阅):http://t.csdn.cn/Um9Zd 目录 1. 时间序列分析简介 2. 自回归模型(AR) 2.1. 参数估计 2.2. MATLAB实现...
,0,1),字段名 或者 if(isnull(字段名),1,0),字段名)
mysql排序之if(isnull(字段名),0,1),字段名 或者 if(isnull(字段名),1,0),字段名
mysql排序之if(isnull(字段名),0,1),字段名 或者 if(isnull(字段名),1,0),字段名 默认情况下,MySQL将null算作最小值。如果想要手动指定null的顺序,可以这样处理: 将null强制放在最前 //null, null, 1,2,3,4(默认就是这样&#…...

华为OD机试真题 Java 实现【递增字符串】【2023Q1 200分】,附详细解题思路
一、题目描述 定义字符串完全由“A’和B"组成,当然也可以全是"A"或全是"B。如果字符串从前往后都是以字典序排列的,那么我们称之为严格递增字符串。 给出一个字符串5,允许修改字符串中的任意字符,即可以将任何的"A"修改成"B,也可以将…...
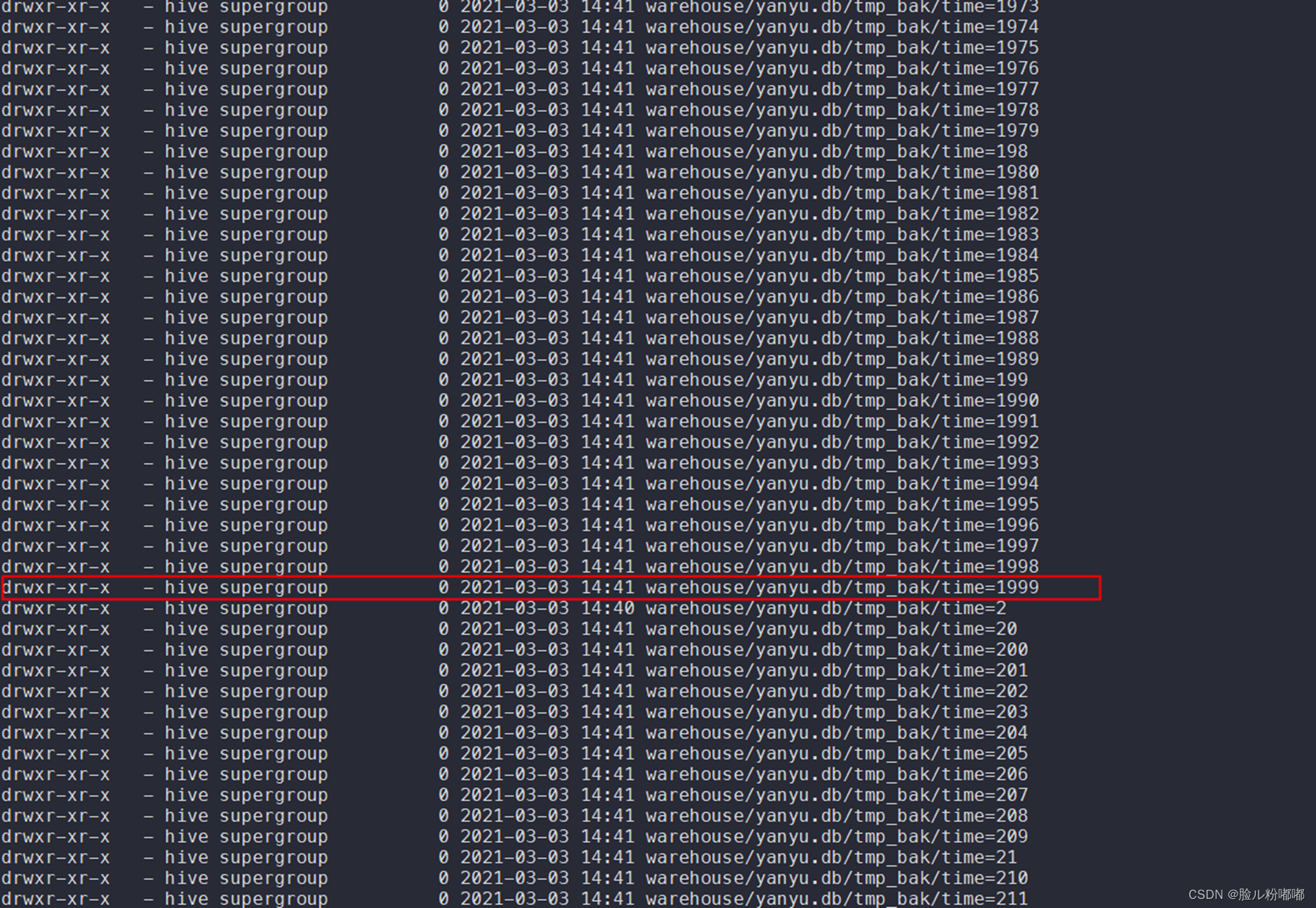
合并文件解决HiveServer2内存溢出方案
一、文件过多导致HiveServer2内存溢出 1.1查看表文件个数 desc formatted yanyu.tmp• 表文件数量为6522102 1.2查看表文件信息 hadoop fs -ls warehouse/yanyu.db/tmp• 分区为string 类型的time字段,分了2001个区。 1.3.查看某个分区下的文件个数为10000个 …...

韧性数据安全体系缘起与三个目标 |CEO专栏
今年4月,美创科技在数据安全领域的新探索——“韧性”数据安全防护体系框架正式发布亮相。 为帮您更深入了解“韧性数据安全”,我们特别推出专栏“构建适应性进化的韧性数据安全体系”,CEO柳遵梁亲自执笔,进行系列解读分享。 首期…...

从拉灯呼叫到闭环处理:安灯管理软件操作流程能解决哪些场景痛点?一套安灯管理软件操作流程实战
在制造工厂的生产现场,异常就像不速之客,总在最忙的时候敲门。设备突然停机、物料没送到位、质量出现批量不良……这些异常发生后,最让人头疼的往往不是问题本身,而是处理问题的过程。工人发现设备停了,扯着嗓子喊班长…...

JMeter接口断言实战:从响应匹配到业务逻辑校验
1. 断言不是“加个勾就完事”的装饰品,而是接口测试的判决书很多人第一次在JMeter里点开“添加 → 断言 → 响应断言”,填上一个“包含文本:success”,跑完看绿色小对勾亮了,就以为测试通过了——结果上线后接口明明返…...

向量化智能矩阵系统的语义坍塌:当10万条内容同时找“相似“,为什么你的数据库扛不住?
摘要:智能矩阵系统从"关键词匹配"进化到"语义匹配"之后,遇到了一个被严重低估的性能瓶颈——向量检索的语义坍塌。本文从向量数据库原理、ANN近似最近邻算法、HNSW图索引、向量量化技术四个底层技术出发,拆解向量化智能矩…...

【仅剩72小时】ElevenLabs希腊文语音v2.4.1热更新前瞻:首次支持Cypriot方言变体,附迁移兼容性速查表
更多请点击: https://codechina.net 第一章:ElevenLabs希腊文语音v2.4.1热更新核心概览 ElevenLabs v2.4.1 版本针对希腊文(Greek)语音合成能力进行了深度热更新,显著提升了音素对齐精度、语调自然度及方言兼容性。本…...

基于springboot2+vue2的纺织品企业财务管理系统
1. 获取地址 https://fifteen.xiaobias.com/source/198 2. 项目简介 本项目为一套基于 Spring Boot Vue 的纺织品企业财务管理系统。系统服务于企业内部员工、财务人员及管理员,旨在实现企业财务流程的信息化管理。主要功能涵盖: 员工报销申请与审核…...

ElevenLabs支持闽南语吗?福建话语音合成实测:从API调用到音色克隆的7步通关手册
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs福建话语音支持现状与能力边界 ElevenLabs 目前尚未在官方语音模型库中提供对福建话(含闽南语、闽东语等分支)的原生支持。其公开文档与 API 文档均未列出任何以“Fuj…...

6款优质降AIGC平台 降痕效果拉满
写论文时不断攀升的AIGC率让人焦虑不已?别担心,这里整理了6款高效实用的降AIGC工具,堪称应对AI痕迹问题的"得力助手"。它们能有效识别并消除AI生成特征,降痕能力出众,助你轻松通过查重审核,彻底摆…...

article-extractor项目架构解析:模块化设计与可扩展性指南
article-extractor项目架构解析:模块化设计与可扩展性指南 【免费下载链接】article-extractor To extract main article from given URL with Node.js 项目地址: https://gitcode.com/gh_mirrors/ar/article-extractor article-extractor是一个强大的Node.j…...

前 DeepMind 研究员反思:评测,而非算力或数据,才是下一阶段的瓶颈
一线后训练研究员的技术随笔与动态评测管线启示当你还在为某项主流基准的分数微涨而讨论时,模型可能已悄悄学会“只说真话但战略性隐瞒”。前 Google DeepMind 高级研究员 Lun Wang 在近期的技术长文中抛出一个反直觉观察:如果下一代大模型跨进了全新的能…...

百度网盘全自动化实录:Hermes Agent + bb-browser
缘起:今天风暴了一下,准备实践一下Hermes自动售卖数字产品实现自动变现的MVP,谁知道刚开始就卡在了操作百度网盘,要么被反爬,要么靠之前开发的computer use for win截图点坐标像瞎子摸象。最后换了条路——用 bb-brows…...