Grounded Language-Image Pre-training(论文翻译)
文章目录
- Grounded Language-Image Pre-training
- 摘要
- 1.介绍
- 2.相关工作
- 3.方法
- 3.1统一构建
- 3.2.语言感知深度融合
- 3.3.使用可扩展的语义丰富数据进行预训练
- 4.迁移到既定的基准
- 4.1.COCO上的zero-shot和监督迁移学习
- 4.2.LVIS上的zero-shot 迁移学习
- 4.3.Flickr30K实体上的 phrase grounding
- 4.4 分析
- 5 开放目标检测
- 5.1数据的有效性
- 5.2.一个模型适应所有任务
- 6 结论
Grounded Language-Image Pre-training
摘要
本文提出了一个基于的语言-图像预训练(GLIP)模型学习对象级,语言感知,语义丰富的视觉表示。GLIP将目标检测和phrase grounding统一起来进行预训练。统一带来两个好处:1)它允许GLIP从检测和grounding data两者学习以改进这两个任务并引导良好的grounding模型; 2)GLIP可以利用大量的图像-文本对通过自训练的方式生成grounding边界框,使得学习到的表示语义更加丰富。在我们的实验中,我们在27百万 grounding数据上预训练GLIP,其中包括3 百万人类注释和24 百万网络抓取的图像-文本对。学习的表示表现出强大的zero-shot和few-shot性能,可转移到各种对象级识别任务。1)当在COCO和LVIS上直接评估时(在预训练期间没有在COCO中看到任何图像),GLIP分别达到49.8 AP和26.9 AP,超过了许多监督基线。 2)在COCO上进行微调后,GLIP在val上达到60.8 AP,在test-dev上达到61.5 AP,超过了之前的SoTA。3)当转移到13个下游对象检测任务时,1-shot的GLIP可与全监督动态头相媲美。代码发布于https://github.com/microsoft/GLIP。
1.介绍
视觉识别模型通常被训练来预测一组固定的预定对象类别,这限制了它们在现实世界应用中的可用性,因为需要额外的标记数据来推广到新的视觉概念和领域。CLIP [45]表明,可以在大量原始图像-文本对上有效地学习图像级视觉表示。由于配对文本包含比任何预定义概念池更广泛的视觉概念集,因此预训练的CLIP模型在语义上非常丰富,可以在 zero-shot 下轻松地迁移到下游的图像分类和文本图像检索任务中。然而,为了获得图像的细粒度理解,如许多任务所需,例如目标检测[36,49],分割[7,40],人体姿势估计[54,63],场景理解[16,30,64],动作识别[20],视觉语言理解[8,32 - 35,41,53,55,70,73],非常需要对象级视觉表示。
在本文中,我们表明,phrase grounding,这是一个任务,确定短语中的句子和对象(或区域)之间的细粒度的对应关系,在图像中,是一个有效的和可扩展的预训练任务学习对象级,语言感知,语义丰富的视觉表示,并提出grounding语言图像预训练(GLIP)。我们的方法统一phrase grounding和目标检测任务,目标检测可以被视为phrase grounding上下文无关的,而phrase grounding可以被视为一个上下文相关的目标检测任务。我们强调我们的主要贡献如下:
通过将目标检测重新表述为phrase grounding来统一检测和grounding。
改变了检测模型的输入:不仅输入图像,还输入 text prompt(包含检测任务的所有候选类别)。例如,COCO目标检测任务的 text prompt 是由80个COCO对象类别名组成的文本字符串,如图2(左)所示。通过将 object classification logits 替换为 word-region alignment 分数(例如视觉region和文本token的点积),任何 object detection 模型都可以转换为 grounding 模型,如图2(右)所示。与仅在最后点积操作融合视觉和语言的CLIP不同,GLIP利用跨模态融合操作,具有了深度的跨模态融合的能力。如图2(中)所示,对于学习高质量的语言感知视觉表示和实现上级的迁移学习性能至关重要。检测和grounding的统一还允许我们使用两种类型的数据进行预训练,并使两项任务都受益。在检测方面,由于groundong数据,视觉概念池得到了显着丰富。在groundong方面,检测数据引入了更多的边界框注释,并帮助训练新的SoTA短语基础模型。
利用海量图像-文本数据扩展视觉概念。
给定 grounding 模型(teacher),可以自动生成大量图像-文本对数据的 grounding boxes 来扩充GLIP预训练数据,其中 noun phrases 由NLP解析器检测,图3为两个 boxes 的示例,teacher模型可以定位到困难的概念,如注射器、疫苗、美丽的加勒比海绿松石,甚至抽象的单词(视图)。在这种语义丰富的数据上训练可以生成语义丰富的student模型。相比之下,关于缩放检测数据的先前工作简单地不能预测教师模型的预定义词汇表之外的概念[77]。在这项研究中,我们表明,这种扩大grounding数据的简单策略在经验上是有效的,带来了巨大的改进LVIS和13下游检测任务,特别是在罕见类别(第4.2节和第5节)。当预训练的GLIPL模型在COCO上进行微调时,它在COCO 2017val上达到了60.8 AP,在测试开发上达到了61.5,超过了当前的公共SoTA模型[10,65],这些模型以各种方法扩大了对象检测数据。
GLIP迁移学习: one model for all GLIP 可以有效的迁移到各种任务中,而只需要很少甚至不需要额外的人工标注。此外,当特定于任务的标注数据可用时,也不必微调整个模型,只需微调特定于任务的 prompt embedding,同时冻结模型参数。

图2.检测和grounding的统一框架。与预测每个检测到的对象的分类类的经典对象检测模型不同,我们通过将每个区域/框与文本提示中的短语对齐来将检测重新表述为grounding任务。GLIP联合训练图像编码器和语言编码器以预测区域和单词的正确配对。我们进一步添加跨模态深度融合,以早期融合来自两种模态的信息,并学习语言感知的视觉表示。

图3.GLIP的预测。GLIP可以定位罕见的实体、带有属性的短语,甚至是抽象的单词
2.相关工作
标准的目标检测系统被训练来定位在人群标记数据集中预定义的一组固定的对象类,例如COCO [37],OpenImages(OI)[30],Objects365 [50]和Visual Genome(VG)[28],其中包含不超过2,000个对象类。这种人工注释的数据扩大规模的成本很高[59]。GLIP提出了一个负担得起的解决方案,通过重新制定一个phrase grounding(字到区域匹配)的问题,目标检测,从而使grounding和大量的图像文本配对数据的使用。虽然我们当前的实现是建立在动态头(DyHead)[10]上,但我们的统一公式可以推广到任何对象检测系统[4,6,9,10,10,36,48,49,76]。
最近,有一种趋势,开发视觉和语言的方法来解决视觉识别问题,其中视觉模型的训练自由形式的语言监督。例如,CLIP [45]和ALIGN [21]对数十万或数千万的图像-文本对执行跨模态对比学习,并且可以直接执行open vocabulary图像分类。通过将来自CLIP/ALIGN模型的知识提取到两阶段检测器中,提出ViLD [14]来zero-shot目标检测。或者,MDETR [23]在现有的多模态数据集上训练端到端模型,这些数据集在文本中的短语和图像中的对象之间具有显式对齐。我们的GLIP继承了这一系列研究的语义丰富和语言感知属性,实现了SoTA对象检测性能,并显着提高了下游检测任务的可转移性。
本文重点研究了用于目标检测的域转移学习。我们的目标是构建一个预先训练好的模型,以零次或少量的方式无缝地转移到各种任务和领域。我们的设置不同于zero-shot检测[1,12,14,46,47,68],其中一些类别被定义为不可见/罕见,并且不存在于训练集中。我们期望GLIP在稀有类别上表现良好(第4.2节),但我们没有明确地从训练集中排除任何类别,因为基础数据在语义上非常丰富,我们期望它们覆盖许多稀有类别。这类似于开放词汇表对象检测[68]中的设置,该设置期望原始图像-文本数据覆盖许多罕见的类别。一系列的工作确定建立一个开放世界的对象建议框模块,可以提出任何新的对象在测试时的关键挑战[22,25,60,74,75]; GLIP提供了一个新的视角:该模型不需要从开集中提出每一个可能的新对象;相反,它只需要提出文本提示中提到的对象,因为检测分支以该提示为条件。
除了稀有类别的性能之外,我们还考虑了现实场景中的迁移成本,即,如何以最少的数据量、培训预算和部署成本实现最佳性能(第5节)。特别是,我们表明GLIP支持提示调整[31],这与完全微调的性能相匹配,但只调整了一小部分模型参数。我们还提出了一个新的发现,在目标检测中,提示调整是最有效的模型与深度视觉语言融合,如GLIP,而浅融合模型的效果要差得多。这与最近的研究工作形成了鲜明的对比,这些研究只针对像CLIP这样的浅融合视觉语言模型进行提示调整。
3.方法
从概念上讲,目标检测和phrase grounding有很大的相似性。它们都试图定位对象并将其与语义概念对齐。这种协同作用促使我们将经典的目标检测任务转换为grounding问题,并提出一个统一的公式(第3.1节)。我们进一步提出在图像和文本之间添加深度融合,使检测模型具有语言感知能力,从而成为一个强大的grounding模型(第3.2节)。通过重构和深度融合,我们可以在可扩展和语义丰富的grounding数据上预训练GLIP(第3.3节)。
3.1统一构建
背景:物体检测。典型的检测模型将输入图像送到视觉编码器EncI中,CNN [18,56]或Transformer [39,67,69]作为主干,并提取区域/框特征O,如图2所示(底部)。每个区域/框特征被送到两个预测头,即,分别用分类损失Lcls和定位损失Lloc训练的边界框分类器C和边界框回归器R:

在两阶段检测器中,使用具有RPN损失Lrpn的单独区域提议网络(RPN)来区分前景和背景并细化锚。由于Lrpn不使用对象类的语义信息,我们将其合并到本地化损失Lloc中。在单级检测器中,定位损耗Lloc也可能包含中心度损耗[57]。边界框分类器C通常是简单的线性层,并且分类损失Lcls可以写为:

其中,O ∈ RN×d是输入图像的对象/区域/框特征,W ∈ Rc×d是框分类器C的权重矩阵,Scls ∈ RN×c是输出分类logits,T ∈ {0,1}N×c是从经典多对1匹配[9,36,48,49]或二分匈牙利匹配[4,10,76]计算的区域和类之间的目标匹配。损失(S; T)通常是两级探测器的交叉熵损失和一级探测器的焦点损失[36]。
**目标检测 作为 phrase grounding.**我们没有将每个区域/框分类为c类,而是将检测重新定义为grounding任务,通过将每个区域与文本提示中的短语进行grounding/对齐(参见图2)。如何为检测任务设计文本提示?给定对象类[人、自行车、汽车、…牙刷],一种简单的方法是Prompt =“Detect:人、自行车、汽车……、牙刷”,其中每个类名是要grounding的候选短语。人们可以通过提供这些类的更具表达性的描述和/或通过利用预先训练的语言模型的偏好来设计更好的提示。例如,当预训练的BERT模型[11]用于初始化我们的语言编码器EncL时,提示“person.自行车。车。…牙刷”比上面描述的更人性化的提示效果更好。我们将在5.2节讨论提示设计。
在grounding模型中,我们计算图像区域和提示中的单词之间的对齐分数:
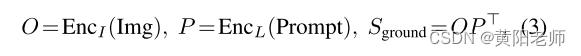
其中P ∈ RM×d是来自语言编码器的上下文单词/令牌特征,并且起到与(2)中的权重矩阵W类似的作用,如图2(右)所示。由图像编码器EncI和语言编码器EncL组成的基础模型通过最小化(1)和(2)中定义的损失来端到端地训练,其中用(3)中的区域词对齐分数Srund简单地替换(2)中的分类logits Scls。
然而,在(2)中,我们现在有Logits S地面∈ RN×M和目标T ∈ {0,1}N×c。(子)单词标记M的数量总是大于文本提示中的短语c的数量,原因有四个:1)一些短语包含多个单词,例如,“红绿灯”; 2)一些单字短语被拆分成多个(子)字标记,例如,“牙刷”到“牙齿#”和“#刷”; 3)一些是添加的令牌,例如“Detect:”,“,”,语言模型中的特殊令牌,以及4)在令牌化序列的末尾添加[NoObj]令牌。当损失是(焦点)二进制S形损失(我们在第4节和第5节中使用的损失)时,我们通过使所有子词正匹配(如果短语是正匹配)将原始目标矩阵T ∈ {0,1}N×c扩展到T ∈ {0,1}N×M,并且所有添加的标记都与所有图像特征负匹配。有了这个变化,损失(接地; T)保持不变。在推理过程中,我们平均令牌概率作为短语概率。
检测与grounding等效通过上述重构,我们可以将任何检测模型转换为grounding模型,并且两个视图,即检测和grounding在理论上对于训练和推理都是等效的。我们也从经验上验证了这一点:具有Swin-Tiny骨架的SoTA DyHead检测器[10]在我们的重新配制之前和之后在COCO val 2017上提供相同的性能。讨论内容请参见附录。通过重构,预训练的短语grounding模型可以直接应用于任何对象检测任务,这要归功于语言编码器的自由形式输入。这使得有可能将我们的GLIP模型以zero-shot方式转移到任意检测任务。
相关工作我们的grounding公式受到MDETR [23]的启发,并且我们的grounding损耗与MDETR的细粒度对比损耗具有相同的精神。我们比MDETR更进一步,找到一种有效的方法来重新制定检测grounding和一个简单的统一的检测和grounding任务的损失。我们的grounding模型也类似于zero-shot检测的模型[1,14,46,47,75]。Bansal等人的开创性工作[1]通过使用预训练的Glove词嵌入[43]作为短语特征P ∈ Rc×d,使检测模型能够进行zero-shot检测,如果以(3)的形式编写。最近,从预训练的深度语言模型中提取的短语特征被引入到开放词汇检测中[68]。GLIP与zero-shot检测的不同之处在于,GLIP提供了检测和grounding的统一视图,并且实现了两个关键成分,即,语言感知深度融合和与图像-文本数据的放大,如下面将要描述的。
3.2.语言感知深度融合
在(3)中,图像和文本由单独的编码器编码,并且仅在最后融合以计算对准分数。我们称这种模型为后融合模型。在视觉语言文献[8,23,32,33,35,41,53,55,73]中,视觉和语言特征的深度融合对于学习phrase grounding模型是必要的。我们在图像和语言编码器之间引入深度融合,它在最后几个编码层中融合图像和文本信息,如图2(中)所示。具体地说,当我们使用DyHead [10]作为图像编码器,BERT [11]作为文本编码器时,深度融合编码器是:

其中L是DyHead [10]中DyHeadModules的数量,BERTLayer是预训练BERT之上新添加的BERT层,O 0表示来自视觉主干的视觉特征,P0表示来自语言主干(BERT)的令牌特征。通过跨模态多头注意模块(X-MHA)(4)实现跨模态通信,随后是单模态融合并在(5)和(6)中更新。在没有添加上下文向量(用于视觉模态的Oi t2 i和用于语言模态的Pi t2 t)的情况下,模型被简化为后期融合模型。
在跨模态多头注意模块(XMHA)(4)中,每个头部通过关注另一模态来计算一个模态的上下文向量:

其中{W(符号,I),W(符号,L):symbol ∈ {q,v,out}}是可训练参数,分别与Multi-Head SelfAttention [58]中的查询、值和输出线性层的作用类似。
深度融合编码器(4)-(6)带来两个益处。1)它改善了phrase grounding性能。2)它使学习的视觉特征具有语言感知性,因此模型的预测以文本提示为条件。这对于实现一个模型服务于所有下游检测任务的目标至关重要(见5.2节)。
3.3.使用可扩展的语义丰富数据进行预训练
大量的研究致力于收集语义丰富、数量庞大的检测数据。然而,人类注释已被证明是昂贵且有限的[15,30]。先前的工作试图以自我训练的方式扩大规模[77]。他们使用教师(预先训练的检测器)从原始图像中预测边界框,并生成伪检测标签来训练学生模型。但是生成的数据在概念池的大小方面仍然是有限的,因为教师只能预测在现有数据集上构建的概念池中定义的标签。相比之下,我们的模型可以在检测和更重要的phrase grounding数据上进行训练。我们表明,phrase grounding数据可以提供丰富的语义,以促进本地化,并可以在一个自我训练的方式扩大。
首先,grounding数据覆盖了比现有检测数据大得多的视觉概念词汇表。最大的尝试在扩大检测词汇仍然覆盖不超过2,000个类别[15,28]。有了grounding数据,我们扩展了词汇表,几乎涵盖了grounding标题中出现的任何概念。例如,Flickr 30 K [44]包含44,518个唯一短语,而VG Caption [28]包含110,689个唯一短语,数量级大于检测数据的词汇表。我们在第4.4节中提供了一项实证研究,表明0.8Mgrounding数据比额外的2 M检测数据在检测稀有类别方面带来了更大的改进。
此外,我们展示了一种获得语义丰富数据的有希望的途径,而不是按比例增加检测数据:放大grounding数据。我们使用一种简单的方法,灵感来自自我训练。我们首先用(人类注释)检测和接地数据预训练教师GLIP。然后,我们使用这个教师模型来预测网络收集的图像-文本数据的框,其中名词短语由NLP解析器检测[2]。最后,用黄金数据和生成的伪grounding数据训练学生模型。如图3所示,教师能够为语义丰富的实体生成准确的框。
为什么学生模型可能优于教师模型?虽然在自我训练文献[77]中的讨论仍然很活跃,但在视觉基础的背景下,我们认为教师模型正在利用语言背景和语言概括能力来准确地理解它可能不知道的概念。例如,在图3中,教师可能无法直接识别某些概念,如疫苗和绿松石,如果它们不存在于黄金数据中。然而,丰富的语言背景,如句法结构,可以提供强有力的指导教师模型执行“有根据的猜测”。如果模型能定位一个小的细胞,则该模型能定位疫苗;如果它能找到加勒比海,它就能定位绿松石。当我们训练学生模型时,教师模型的“有根据的猜测”变成了“监督信号”,使学生模型能够学习疫苗和绿松石的概念。
4.迁移到既定的基准
经过预训练后,GLIP可以轻松地应用于grounding和检测任务。我们在三个已建立的基准测试中显示出强大的直接域转移性能:1)MS-COCO对象检测(COCO)[37],包含80个常见对象类别; 2)LVIS [15]覆盖超过1000个对象类别; 3)Flickr 30 K [44],用于短语grounding。我们训练GLIP的5个变体(表1)来消融其三个核心技术:1)统一grounding损耗; 2)语言感知的深度融合; 3)以及使用两种类型的数据进行预训练。实施细节见附录。

GLIP-T (A) 基于SoTA检测模型,Dynamic Head [10],我们的词区域对齐损失代替了分类损失。它基于Swin-Tiny主干,并在O365(Objects 365 [50])上进行了预训练,O365包含0.66M图像和365个类别。如3.1节所述,该模型可以被视为一个强大的经典zero-shot 检测模型[1],完全依赖于语言编码器来推广新概念。
GLIP-T (B) 通过语言感知深度融合进行增强,但仅在O365上进行预训练。
GLIP-T © 在1)O365和2)GoldG上进行了预训练,0.8M人类注释的黄金grounding数据由MDETR [23]策划,包括Flickr30K,VG Caption [28]和GQA [19]。我们已经从数据集中删除了COCO图像。旨在验证grounding数据的有效性。
GLIP-T 基于Swin-Tiny主干,并根据以下数据进行预训练:1)0365,2)如GLIP-T(C)中的GoldG,以及3)Cap 4 M,从具有由GLIP-T(C)生成的框的网络收集的4 M图像-文本对。我们还对现有的图像标题数据集进行了实验:CC(3 M数据的概念字幕)[51]和SBU(1 M数据)[42]。我们发现CC+SBU GLIP-T在COCO上的表现略好于Cap 4 M GLIP-T,但在其他数据集上略差。为了简单起见,我们在COCO上报告了两个版本,但在其他任务中只报告了Cap 4 M模型。我们在附录中给出了完整的结果。
GLIP-L 基于Swin-Large并经过以下训练:1)四个OD(266 M数据),4个检测数据集,包括Objects 365,OpenImages [27],Visual Genome(不包括COCO图像)[28]和ImageNetBoxes [29]; 2)GLIP-T(C)中的GoldG; 3)CC 12 M +SBU,从网络上采集24 M图文数据,生成框。
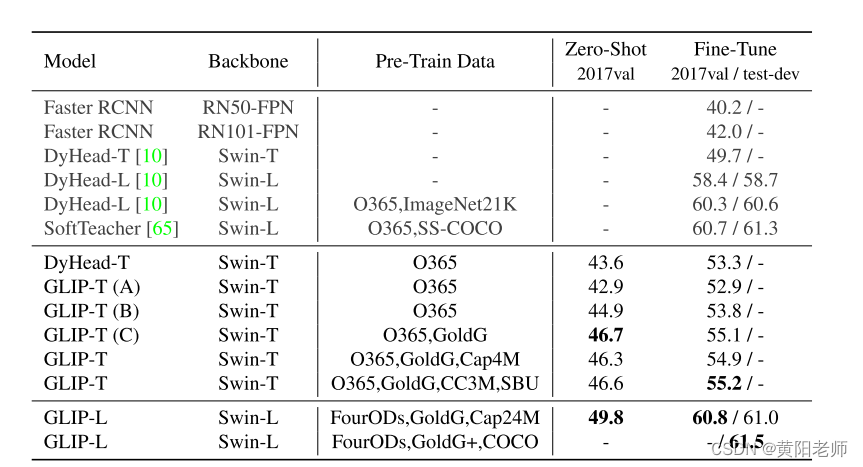
表2.COCO上的zero-shot转移和微调。GLIP在没有看到来自COCO数据集的任何图像的情况下,可以实现与先前的监督模型(例如:Zero-Shot下的GLIP-T与在微调下faster -RCNN)。当在COCO上进行充分微调时,GLIP-L的性能超过了SoTA。
4.1.COCO上的zero-shot和监督迁移学习
我们在MS-COCO上进行实验,以评估模型对常见类别的迁移能力。我们在两种设置下进行评估:1)zero-shot转移,和2)监督转移,其中我们使用标准设置微调预训练模型。对于微调设置,我们还测试了GLIP-L模型的性能,其中我们将COCO图像包含在预训练数据中(最后一行)。具体来说,我们将完整的GoldG+接地数据和COCO train 2017添加到预训练数据中。请注意,部分COCO 2017 val图像存在于GoldG+ [23]中。因此,我们只报告该模型的测试开发性能。更多详情请参见附录。
我们引入一个额外的基线:DyHead在Objects365上预训练。我们发现COCO 80类别在Objects365中完全覆盖。因此,我们可以以“zero-shot”的方式评估在Objects365上训练的DyHead:在推理过程中,我们将模型限制为仅从COCO 80类进行预测,而不是从365类进行预测。我们列出标准COCO检测模型供参考。我们还列出了两个用额外数据预训练的最先进的模型。
结果是出现在表2。总的来说,GLIP模型实现zero-shot和监督表现强劲。Zero-shot GLIP模型对手或超越的监督模式。最好的GLIP-T达到46.7,超过了faster-RCNN;GLIP-L达到49.8,超过了DyHead-T。在监督环境下,最好GLIP-T带来改进的标准DyHead (55.2 vs 49.7)。Swin-Large骨干,GLIP-L超过当前SoTA可可,达到60.8 test-dev 2017 val和61.5,之前没有一些SoTA[65]等模型,混合,标签平滑或soft-NMS。
我们分析了GLIP的zero-shot性能,并发现三个影响因素:Objects 365和COCO之间的紧密领域重叠,深度融合和基础数据。由于Objects 365覆盖了COCO中的所有类别,O365预训练的DyHead-T表现强劲,达到43.6AP;将模型重新表示为grounding模型,我们观察到轻微的性能下降(GLIP-T(A));增加深度融合使性能提高2AP(GLIP-T(B));最大的贡献者是grounding数据,利用该数据GLIP-T(C)达到46.7的zero-sho。虽然图像-文本数据的添加对COCO带来了轻微的改进或没有改进(GLIP-T v.GLIP-T(C)),我们发现它在推广到罕见的类,因为我们在LVIS实验中显示。
4.2.LVIS上的zero-shot 迁移学习
我们评估该模型的能力,以识别不同的和罕见的对象LVIS在零次设置。我们报告了MDETR中引入的包含5,000张图像的MiniVal以及MDETR中引入的包含5,000张图像的完整值MiniVal以及完整验证集v1.0。请参见附录中的评估详细信息。
结果示于表3中。我们列出了在LVIS的注释数据上训练的三个监督模型。GLIP在所有类别上都表现出强大的零次性能。GLIP-T与监督MDETR相当,而GLIPL的性能远远优于监督RFS。使用grounding数据的好处是显而易见的。Gold接地数据比MiniVal APr提高了4.2个点(型号C与型号模型B)。添加图像-文本数据进一步将性能提高了3.1个点。我们的结论是,grounding数据的语义丰富性显着帮助模型识别罕见的对象。

表3.zero-shot转移到LVIS。当不使用LVIS数据时,GLIP-T/L优于强监督基线(以灰色显示)。grounding数据带来了很大的改善。

表4.Flickr 30 K实体上的短语grounding性能。GLIP-L在测试R@1上比之前的SoTA高出2.8分。
4.3.Flickr30K实体上的 phrase grounding
我们评估了模型在Flickr30K实体上以自然语言接地实体的能力[44]。Flickr30K包含在grounding数据中,因此我们在预训练后直接评估模型,如MDETR [23]所示。我们使用MDETR中指定的任意盒协议。结果示于表4中。我们评估了三个版本的GLIP与不同的预训练数据。我们列出了SoTA接地模型MDETR的性能。MDETR在GoldG+上训练,包含1.3M数据(GoldG是GoldG+的子集,不包括COCO图像)。
采用GoldG的GLIP-T(第3行)实现了与采用GoldG+的MDETR相似的性能,这可能是由于引入了Swin Transformer、DyHead模块和深度融合。更有趣的是,检测数据的添加有助于接地(第4行对第5行)。3),再次显示了两项任务的协同作用和我们统一损失的有效性。图像-文本数据也有帮助(第5行与4).最后,按比例放大(GLIP-L)可以实现87.1 Recall@1,比之前的SoTA高出2.8个点。
4.4 分析
在本节中,我们通过在不同数据源上预训练GLIP-T来进行消融研究(表5)。我们回答了两个研究问题。首先,我们的方法假设使用检测数据集来引导模型。一个自然的问题是,当与不同的检测数据配对时 ,grounding数据是否会带来改进。我们发现,添加接地数据带来了与不同检测数据一致的改善(行1-6)。
其次,我们已经证明了常见和罕见类别的grounding数据的有效性。一个正交方向是通过包括更多图像和类别来放大检测数据(第3.3节)。我们打算提供一个经验的比较按比例放大检测数据和grounding数据。我们提出了用4个公共检测数据集(第8行)训练的GLIP,作为用人类注释扩展检测数据的极端尝试。该模型总共使用266万个检测数据进行训练,对齐的词汇表超过1,500个类别。然而,它仍然落后于LVIS的COCO和APr上的第6行,其中第6行仅使用0.66M检测数据和0.8M黄金grounding数据进行训练。添加图像-文本数据进一步扩大了LVIS APr差距(20.8与15.0)。我们得出结论,grounding数据确实更语义丰富,是一个有前途的替代扩大检测数据。
5 开放目标检测
为了评估GLIP在不同现实任务中的可转移性,我们策划了一个“野外目标检测”(ODinW)设置。我们在Roboflow 5上选择了13个公共数据集,每个数据集都需要不同的本地化技能。许多数据集都是针对特定的应用目的设计的,以模拟真实世界的部署场景。例如,EgoHands需要定位人的手;坑洞涉及检测道路上的洞; ThermalDogsandPeople涉及在红外图像中识别狗和人。详情请参阅附录。
我们证明,GLIP促进转移到这样不同的任务。(1)GLIP带来了很高的数据效率,达到了相同的性能,与基线相比,特定于任务的数据明显减少(第5.1节)。(2)GLIP支持新的域转移策略:在适应新任务时,我们可以简单地改变文本提示,而保持整个基础模型不变。这大大降低了部署成本,因为它允许一个集中式模型服务于各种下游任务(第5.2节)。
5.1数据的有效性
我们改变了特定于任务的注释数据的数量,从零次(没有提供数据)到X次(每个类别至少提供X个示例[24,62,66]),再到使用训练集中的所有数据。我们根据提供的数据对模型进行微调,并对所有模型使用相同的超参数。每个数据集都带有预先指定的类别名称。由于GLIP是语言感知的,我们发现用更具描述性的语言重写一些预先指定的名称是有益的(参见5.2节的讨论)。我们与在Objects 365上预训练的SoTA检测器DyHead-T进行比较。我们使用标准的COCO训练的DyHead-T进行测试,发现它具有类似的性能。为了简单起见,我们只报告前者。我们还试验了缩放余弦相似性方法[61],但发现它的性能略低于香草方法,因此我们仅报告后者。完整的统计数据请参见附录,包括X射线实验的三次独立运行。
结果示于图4中。我们发现,统一的接地重新表述,深度融合,接地数据和模型放大都有助于提高数据效率(从底部红线(Dyhead-T)到上部紫线(GLIP-L))。因此,GLIP表现出变革性的数据效率。零次GLIP-T优于5次DyHead-T,而一次GLIP-L与完全监督的DyHead-T竞争。
我们在图5中进一步绘制了GLIP变体在5个不同数据集上的零次性能。我们发现,grounding数据的引入在测试新概念的某些任务上带来了显着的改进,例如,在Pothole和EgoHands上,没有grounding数据的模型(A和B)表现得很糟糕,而有grounding数据的模型(C)则轻松超越了它们。
5.2.一个模型适应所有任务
随着神经网络模型的规模越来越大,如何降低部署成本成为研究热点。最近关于语言模型[52],图像分类[72]和对象检测[61]的工作已经探索了将预训练模型适应新的领域,但只改变最少的参数。这样的设置通常被表示为线性探测[26]、即时调整[72]或高效任务适配器[13]。我们的目标是让单个模型服务于各种任务,每个任务只向预训练模型添加一些特定于任务的参数或不添加参数。这降低了培训和存储成本。在本节中,我们将根据部署效率的度量来评估模型
手动提示的微调由于GLIP执行语言软件本地化,即,GLIP的输出很大程度上取决于语言输入,我们提出了GLIP进行任务转移的有效方法:对于任何新的类别,用户可以在文本提示中使用富有表现力的描述,添加属性或语言上下文,以注入领域知识并帮助GLIP转移。例如,在图6的左手侧,模型未能定位新颖实体“黄貂鱼”的所有出现。但是,通过将属性添加到提示符,即,“扁平和圆形”,该模型成功地定位了所有出现的弦线。通过这个简单的提示更改,我们将黄貂鱼的AP 50从4.6提高到9.7。这类似于GPT-3 [3]中的提示设计技术,并且实际上很有吸引力,因为它不需要注释数据或模型重新训练。详情请参阅附录。

图6.ODinW中Aquarium数据集的手动提示调优示例。给定一个有表情的提示(“扁平和圆形”),零镜头GLIP可以更好地检测到新的实体“黄貂鱼”。

提示微调我们进一步考虑这样的设置,即我们可以访问特定于任务的训练数据,但希望调整最少的参数以便于部署。对于经典检测模型,Wang et al.[61]报告“线性探测”的有效性(即,仅训练箱回归和分类头)。GLIP也可以是“线性探测”,我们只微调盒头和区域之间的投影层和提示嵌入。由于语言感知的深度融合,GLIP支持更强大但仍然有效的传输策略:提示调谐[31,52]。对于GLIP,由于每个检测任务仅具有一个语言提示(例如,坑洞提示可以是“检测坑洞”。对于所有图像),我们首先从语言主干中获得提示嵌入P0,然后丢弃语言主干并仅微调P0作为特定于任务的输入(第3.2节)。
我们在三种设置下评估模型的性能(图7):线性探测、即时调整(仅适用于GLIP)和全模型调整。对于DyHeadT,提示调优不适用,因为传统的对象检测模型不能接受语言输入;线性探测和全模型调谐之间差距很大。GLIP-T(A)没有语言感知的深度融合;因此,快速调谐和线性调谐实现了类似的性能,并且明显滞后于全模型调谐。然而,对于GLIP-T和GLIP-L,即时调谐几乎匹配全调谐结果,而不改变任何接地模型参数。有趣的是,随着模型和数据大小的增长,全模型调优和即时调优之间差距变得越来越小(GLIP-L与GLIP-T),与NLP文献中的结果相呼应[38]。
6 结论
GLIP统一了对象检测和短语基础任务,以学习对象级别,语言感知和语义丰富的视觉表示。经过预训练后,GLIP在完善的基准测试和13个下游任务的零射击和微调设置上显示出令人鼓舞的结果。我们留下一个详细的研究如何GLIP规模与文本图像数据的大小,以未来的工作。
致谢
相关文章:
Grounded Language-Image Pre-training(论文翻译)
文章目录 Grounded Language-Image Pre-training摘要1.介绍2.相关工作3.方法3.1统一构建3.2.语言感知深度融合3.3.使用可扩展的语义丰富数据进行预训练 4.迁移到既定的基准4.1.COCO上的zero-shot和监督迁移学习4.2.LVIS上的zero-shot 迁移学习4.3.Flickr30K实体上的 phrase gro…...
)
设计模式-行为型模式(模板方法、策略、观察者、迭代器、责任链、命令、状态、备忘录、访问者、中介者、解释器)
行为型模式:专注于对象之间的 协作 及如何通过彼此之间的交互来完成任务。行为型模式通常集中在描述对象之间的 责任 分配和 通信 机制,并提供了一些优雅解决特定问题的方案。 模板方法模式(Template Method Pattern)策略模式(Strategy Pattern)观察者模…...

全面探讨 Spring Boot 的自动装配机制
Spring Boot 是一个基于 Spring 框架的快速开发脚手架,它通过自动配置机制帮助我们快速搭建应用程序,从而减少了我们的配置量和开发成本。自动装配是 Spring Boot 的核心特点之一,它可以减少项目的依赖,简化配置文件,提…...

河道水位监测:河道水位监测用什么设备
中国地形复杂,气候多样,导致水资源分布不均,洪涝和干旱等问题时有发生。同时,人类活动也对水资源造成了很大压力,工业和农业用水增加,河道水位下降,生态环境受到威胁。因此,对河道水…...

嵌入式系统中u-boot和bootloader到底有什么区别
嵌入式软件工程师都听说过 u-boot 和 bootloader,但很多工程师依然不知道他们到底是啥。 今天就来简单讲讲 u-boot 和 bootloader 的内容以及区别。 Bootloader Bootloader从字面上来看就是启动加载的意思。用过电脑的都知道,windows开机时会首先加载…...
)
实验14:20211030 1+X 中级实操考试(id:2498)
实验14:20211030 1X 中级实操考试(id:2498) 一、项目背景说明二、表结构三、步骤【5 分】步骤 1:项目准备【5 分】步骤 2:完成实体类 Member【10 分】步骤 3:完成实体类 Goods【10 分】步骤 4&a…...
(字符串 ) 剑指 Offer 58 - II. 左旋转字符串 ——【Leetcode每日一题】
❓剑指 Offer 58 - II. 左旋转字符串 难度:简单 字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的…...

EPICS编程
提纲 1) 为什么在EPICS上编程 2)构建系统特性:假设基本理解Unix Make 3)在libCom中可用的工具 1) 为什么在EPICS上编程 1、社区标准:EPICS合作者知道和明白EPICS结构 2、在很多操作系统之间代码移值性…...

17:00面试,还没10分钟就出来了,问的实在是太...
从外包出来,没想到死在另一家厂子 自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到8月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有个兄弟内推我去…...

docker都有那些工具,及工具面试题
docker介绍 Docker 是一种开源的容器化平台,可以帮助开发者将应用程序和依赖项打包到轻量级的容器中,然后部署到任何基于 Linux 的操作系统中。使用 Docker 可以大大简化开发、部署和管理应用程序的过程,使其更加快速、灵活和可靠。 Docker…...

LAMP网站应用架构
LAMP 一、LAMP概述1、各组件的主要作用2、构建LAMP各组件的安装顺序 二、编译安装Apache httpd服务1、关闭防火墙,将安装Apache所需软件包传到/opt目录下2.安装环境依赖包3.配置软件模块4.编译及安装5.优化配置文件路径,并把httpd服务的可执行程序文件放…...
(纯虚函数))
C++虚函数virtual(动态多态)(纯虚函数)
怎么判断函数是虚函数还是普通函数? 用VS,在调用对象的方法的地方。。按altg ,如果他跳转到正确的函数,那也就意味着他是编译时可以确定的。。。 但是如果他跳到了这个调用对象的基类的函数,那么也就意味着他是一个运行…...

【Java 接口】接口(Interface)的定义,implements关键字,接口实现方法案例
博主:_LJaXi Or 東方幻想郷 专栏: Java | 从入门到入坟 专属:六月一日 | 儿童节 Java 接口 接口简介 🎃接口的定义 🧧接口实现类名定义 🎁接口实现类小案例 🎈后话 🎰 接口简介 &…...
解决Vmware上的kali找不到virtualbox上的靶机的问题
解决kali找不到靶场ip问题的完整方法 1.配置靶机2.配置kali的虚拟网络3.配置kali中的eth0网络 1.配置靶机 靶机部署在Virtualbox上对其进行网络配置,选择连接方式为仅主机(Host-Only)网络。 2.配置kali的虚拟网络 在编辑中选择虚拟网络配…...

查看MySQL服务器是否启用了SSL连接,并且查看ssl证书是否存在
文章目录 一、查看MySQL服务器是否启用了SSL连接 1.登录MySQL服务器 2.查看SSL配置 二、查看证书是否存在 前言 查看MySQL服务器是否启用了SSL连接,并且查看ssl证书是否存在 一、查看MySQL服务器是否启用了SSL连接 1.登录MySQL服务器 在Linux终端中…...

华为OD机试真题 Java 实现【表示数字】【牛客练习题】
一、题目描述 将一个字符串中所有的整数前后加上符号“*”,其他字符保持不变。连续的数字视为一个整数。 数据范围:字符串长度满足1≤n≤100 。 二、输入描述 输入一个字符串。 三、输出描述 字符中所有出现的数字前后加上符号“*”,其他字符保持不变。 四、解题思路…...

使用Python进行接口性能测试:从入门到高级
前言: 在今天的网络世界中,接口性能测试越来越重要。良好的接口性能可以确保我们的应用程序可以在各种网络条件下,保持流畅、稳定和高效。Python,作为一种广泛使用的编程语言,为进行接口性能测试提供了强大而灵活的工…...

sed编辑器
文章目录 一.sed命令基础1.sed概念2.sed的工作流程3.命令格式4.sed命令的常用选项5.sed命令的操作符 二.sed命令的打印功能1.打印文本文件内容1.1 格式1.2 默认打印方式 2.指定行打印2.1 指定行号打印2.2 只打印文件的行数2.3 即打印文件的行号也打印文件的内容2.4 即显示行也显…...
:稀疏表示)
深入理解深度学习——正则化(Regularization):稀疏表示
分类目录:《深入理解深度学习》总目录 另一种策略是惩罚神经网络中的激活单元,稀疏化激活单元。这种策略间接地对模型参数施加了复杂惩罚。我们已经在《深入理解深度学习——正则化(Regularization):参数范数惩罚》中讨…...

【Android】分别用JAVA和Kotlin实现横向扫描的动画效果
Android 横向扫描的动画可以通过使用 ViewPropertyAnimator 和 ObjectAnimator 来实现。 首先,在 XML 布局文件中创建一个 ImageView,并设置其宽度为 0dp,高度为 match_parent。然后,创建一个横向的渐变色 Drawable,并…...

抖音批量下载解决方案:模块化架构与智能降级策略
抖音批量下载解决方案:模块化架构与智能降级策略 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖…...

LeetCode 88:合并两个有序数组 | 双指针从后向前求解
LeetCode 88:合并两个有序数组 | 双指针从后向前求解 引言 合并两个有序数组(Merge Sorted Array)是 LeetCode 第 88 题,难度为 Easy,但却是双指针法应用的经典案例。题目要求将两个已排序的数组 nums1 和 nums2 合并…...

Orbit存储系统完全指南:SQLite、IndexedDB与Firestore三大方案深度解析
Orbit存储系统完全指南:SQLite、IndexedDB与Firestore三大方案深度解析 【免费下载链接】orbit Experimental spaced repetition platform for exploring ideas in memory augmentation and programmable attention 项目地址: https://gitcode.com/gh_mirrors/orb…...

eLabFTW深度解析:开源电子实验记录本的技术架构与实战应用
eLabFTW深度解析:开源电子实验记录本的技术架构与实战应用 【免费下载链接】elabftw :notebook: eLabFTW is the most popular open source electronic lab notebook for research labs. 项目地址: https://gitcode.com/gh_mirrors/el/elabftw eLabFTW作为最…...

CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算
CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算 【免费下载链接】ops-sparse 本项目是CANN提供的高性能稀疏矩阵计算的算子库,专注于优化稀疏矩阵的计算效率。 项目地址: https://gitcode.com/cann/ops-sparse 在高性能计算领域…...

Twemoji跨平台表情统一渲染方案:构建一致性用户体验的核心技术
Twemoji跨平台表情统一渲染方案:构建一致性用户体验的核心技术 【免费下载链接】twemoji Emoji for everyone. 项目地址: https://gitcode.com/gh_mirrors/twe/twemoji Twemoji作为一款基于Unicode标准的开源表情解决方案,为开发者和产品经理提供…...
)
Linux 进程从入门到实战(一)
.个人主页:晓风飞专栏:数据结构|Linux|C语言路漫漫其修远兮,吾将上下而求索文章目录进程为什么要存在内存??操作系统进程什么是进程?PCB(进程控制块)操作系统如何管理进程࿱…...

2026年5月19日OpenBSD 7.9发布:多架构更新、内核创新,安全与性能双提升!
2026年5月19日,开源操作系统OpenBSD 7.9正式发布,作为第60个版本,它带来内核与用户空间多层面更新,预计在开源社区持续发挥重要作用。平台支持全面扩展arm64架构新增Rockchip RK3588与RK3576芯片支持,amd64平台MAXCPUs…...

Cursor AI助手功能扩展技术实现:5步实现永久免费使用的完整方案
Cursor AI助手功能扩展技术实现:5步实现永久免费使用的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...
)
2026年主流一键生成论文工具全攻略(含免费额度说明)
以下是当前学术圈口碑 TOP 的6 款 AI 写论文工具,覆盖从选题、开题到降重、答辩的论文全流程,剔除冗余工具,每款均附分步骤实操指南场景适配技巧,重点突出中文论文适配性,新手也能快速上手,效率翻倍。一、全…...