C++map和set
目录:
- 什么是关联式容器?
- 键值对
- 树形结构的关联式容器
- set的概念
- multiset的使用
- pair和make_pair
- map的概念
- 用“[]”实现统计水果的次数
- multimap的使用
什么是关联式容器?
在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。那关联式容器又是什么呢?其实关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高。
键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
树形结构的关联式容器
根据应用场景的不同,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列。
set的概念
定义: set是关联容器,也就是按照一定次序存储元素的容器
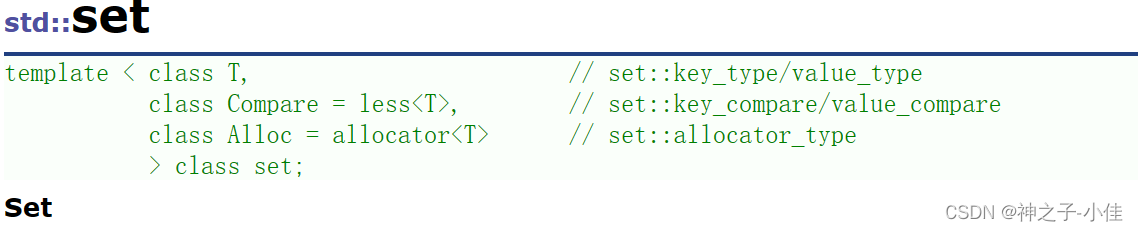
T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
Compare:set中元素默认按照小于来比较
Alloc:set中元素空间的管理方式,使用STL提供的空间配置器管理
我们可以通过cplusplus网站查到set的一些成员函数:
网站点击进入
代码实现一个set:
#include<iostream>
#include<set>
using namespace std;void test_set1()
{set<int> s;s.insert(3);s.insert(1);s.insert(4);s.insert(7);s.insert(2);s.insert(1);//排序+去重auto it = s.begin();//关联式容器的迭代器 it//set<int>::iterator it =s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;//auto pos = s.find(3);auto pos = find(s.begin(), s.end(), 3);//算法里的find也能查找,因为find写的是一个模板,底层是迭代器实现的,但是效率不高if (pos != s.end()){s.erase(pos);//找到pos删除}//s.erase(1) << endl;//给值删除cout << s.erase(1) << endl;//对于基于值的版本,该函数返回擦除的元素数量 cout << s.erase(3) << endl;//对于基于值的版本,该函数返回擦除的元素数量 for (auto e : s){cout << e << " ";} cout << endl;
}
int main()
{test_set1();return 0;
}
输出结果:

第一行结果:通过运行我们看到第一行的输出结果是按照升序排序并且数据不重复,我们插入(insert)的是两个1,输出一个1,说明set底层按照二叉搜索树走中序进行了排序并且还去重。
第二行结果:为了方便我们也可以用范围for来输出结果,因为范围for的底层也是迭代器实现的。
erase删除元素的时候,函数会返回擦除的元素数量,0表示找到pos位置的元素并删除了,1表示pos没有去找还在,元素是直接删除的。

总结:
- 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
- set中插入元素时,只需要插入value即可,不需要构造键值对。
- set中的元素不可以重复(因此可以使用set进行去重)。
- 使用set的迭代器遍历set中的元素,可以得到有序序列
- set中的元素默认按照小于来比较
- set中查找某个元素,时间复杂度为:(O)logN,也就是说查找一千个元素找10次、一百万个元素找20次、10亿个元素才找30次左右
- set中的元素不允许修改(为什么?)
- set中的底层使用二叉搜索树(红黑树)来实现的,并且左右两边比较均衡,因为二叉搜索树有退化成单支的情况,所以准确来说底层是平衡二叉搜索树来实现的
multiset的使用
定义: multiset是按照特定顺序存储元素的容器,其中元素是可以重复的。
代码实现:
void test_set2()
{multiset<int> s;//multiset允许冗余,排序s.insert(3);s.insert(3);s.insert(3);s.insert(1);s.insert(4);s.insert(3);s.insert(7);s.insert(3);s.insert(2);s.insert(1);auto it = s.begin();//关联式容器的迭代器 it
//set<int>::iterator it =s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;auto pos = s.find(3);//multiset从第一个3开始查找while (pos != s.end()){cout << *pos << " ";++pos;}cout << endl;
}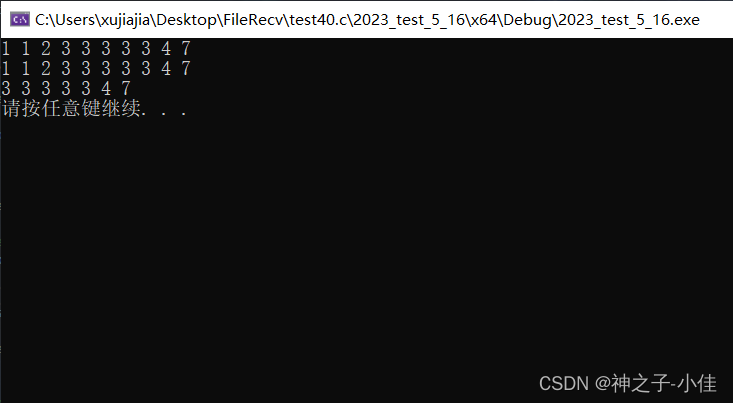
从上面的运行结果我们不难看出multiset支持键值冗余,可以排序,我们用find查找的时候只需要找到第一个3往后面走(pos++)就能找到所有的3。
总结:
- multiset中再底层中存储的是<value, value>的键值对
- mtltiset的插入接口中只需要插入即可
- 与set的区别是,multiset中的元素可以重复,set是中value是唯一的
- 使用迭代器对multiset中的元素进行遍历,可以得到有序的序列
- multiset中的元素不能修改
- 在multiset中找某个元素,时间复杂度为:O(logN)
- multiset的作用:可以对元素进行排序
lower_bound、upper_bound和equal_range的使用:
lower_bound(val):返回一个指向当前 set 容器中第一个大于或等于 val 的元素的双向迭代器。如果 set 容器用 const 限定,则该方法返回的是 const 类型的双向迭代器。
upper_bound(val):返回一个指向当前 set 容器中第一个大于 val 的元素的迭代器。如果 set 容器用 const 限定,则该方法返回的是 const 类型的双向迭代器。
equal_range:返回一个区域的边界,该区域包含容器中等效于 val 的所有元素。由于 set 容器中的所有元素都是唯一的,因此返回的范围最多包含一个元素。
#include<iostream>
using namespace std;
#include<set>
int main()
{set<int> myset;//定义一个名为myset的关联式容器set<int>::iterator itlow, itup;for (int i = 1; i < 10; i++)myset.insert(i * 10);//itlow = myset.lower_bound(30);itlow = myset.lower_bound(35);//>=itup = myset.upper_bound(60);//>myset.erase(itlow, itup);//迭代给的区间是左闭右开cout << "myset contains:";for (set<int>::iterator it = myset.begin(); it != myset.end(); ++it)//查询或者遍历set中的元素时,可以用到iterator迭代器cout << ' ' << *it;cout << '\n';return 0;
}
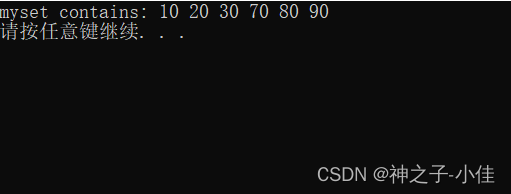
我们给的是下限val是35,上限是val60,那么会删除[40-70)的值域,区间是左闭右开,也就是删除40、50和60。
#include <set>
#include<iostream>
using namespace std;
int main()
{std::set<int> myset;for (int i = 1; i <= 5; i++) myset.insert(i * 10); // myset: 10 20 30 40 50std::pair<std::set<int>::const_iterator, std::set<int>::const_iterator> ret;ret = myset.equal_range(30);std::cout << "the lower bound points to: " << *ret.first << '\n';std::cout << "the upper bound points to: " << *ret.second << '\n';return 0;
}
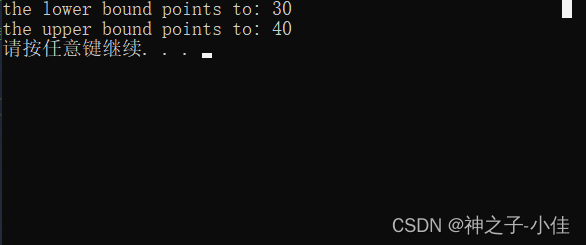
这里我们用到了pair,下面会讲pair的用法,该函数返回一对,其成员first是范围的下限(与 lower_bound 相同),second 是上限(与 upper_bound 相同)。因此,equal_range只需要设定一个val就可以了,那么这个set也可以说是指向元素的双向迭代器类型。
pair和make_pair
pair:此类将一对值耦合在一起,这些值可能属于不同类型的:因为pair的底层是struct实现的,不是class,所以可以直接使用pair的成员变量first和second ,也就是说当一个函数需要返回2个数据的时候,这2个数据可以是不同类型,可以选择pair。
简单实现一下:
#include<iostream>
#include<set>
using namespace std;
int main()
{//pair对象pair<int, double> p1;p1.first = 1;p1.second = 2.5;cout << p1.first << ' ' << p1.second << endl;return 0;}

make_pair:模板类型可以从传递给的参数隐式推导,如果包含不同类型的其他对象是隐式可转换的,则可以从包含不同类型的其他对象构造对象(利用make_pair创建新的pair对象)
简单实现一下:
#include<iostream>
#include<set>
using namespace std;
int main()
{pair<int, double> p1;p1 = make_pair(1, 1.5);cout << p1.first << " " << p1.second << endl;int a = 10;string m = "loquot";pair<int, string> newObj;newObj = make_pair(a, m);cout << newObj.first << ' ' << newObj.second << endl;system("pause");return 0;
}

map的概念
定义:map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
实现map并统计出水果的次数:
#include<iostream>
#include<map>
#include<set>
#include<string>
using namespace std;
int main()
{map<string, string> dict;//定义一个字典dict.insert(pair<string, string>("排序", "sort"));dict.insert(pair<string, string>("左边", "left"));dict.insert(pair<string, string>("右边", "right"));dict.insert(make_pair("字符串", "string"));dict["迭代器"] = "iterator";//插入+修改dict["insert"];//插入dict.insert(pair<string, string>("左边", "***"));//插入失败,搜索树只compare keydict["insert"] = "插入";//修改cout << dict["左边"] << endl;//查找 //key在就是查找,不在就是插入//map<string, string>::iterator it = dict.begin();dict.insert(make_pair("字符串", "string"));auto it = dict.begin();//while (it != dict.end()) //{ // //cout<<(*it).first <<" "<<(*it).second<< endl;// //pair不支持流插入,struct类型没有访问限定符,可以直接获取it的元素// cout << it->first<<":" << it->second << endl;// //类型是结构体的时候,第一个箭头返回的是数据的指针,第二个箭头访问这个值,两个箭头不好看,编译器做了处理省略了一个箭头// ++it;//} //统计次数for (const auto& kv : dict){//dict的每一个值是pair,pair里的每一个值是string,不加引用就是string的拷贝构造,代价太大cout << kv.first << ":" << kv.second << endl;//*it的元素赋值给了kv}string arr[] = { "苹果","西瓜","香蕉","草莓","苹果","西瓜","苹果","苹果","西瓜","苹果","香蕉","苹果","香蕉" };map<string, int> countMap;//map<string,int>::iterator it=countMap;
//for (auto& e : arr){auto it = countMap.find(e);//查找水果if (it == countMap.end())//没有{countMap.insert(make_pair(e, 1));}else {it->second++;//次数加加}}for (const auto& kv : countMap){//dict的每一个值是pair,pair里的每一个值是string,不加引用就是string的拷贝构造,代价太大cout << kv.first << ":" << kv.second << endl;//*it的元素赋值给了kv}return 0;}
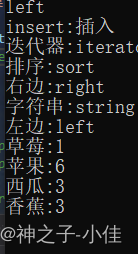
map中方括号[]的功能有三点:
1.插入
2.修改
3.查找
用“[]”实现统计水果的次数
#include<iostream>
#include<map>
#include<set>
#include<string>
using namespace std;
int main()
{map<string, string> dict;//定义一个字典auto it = dict.begin();//统计次数for (const auto& kv : dict){//dict的每一个值是pair,pair里的每一个值是string,不加引用就是string的拷贝构造,代价太大cout << kv.first << ":" << kv.second << endl;//*it的元素赋值给了kv}string arr[] = { "苹果","西瓜","香蕉","草莓","苹果","西瓜","苹果","苹果","西瓜","苹果","香蕉","苹果","香蕉" };map<string, int> countMap;
//用方括号也能实现统计次数
for (auto& e : arr)
{countMap[e]++;
}
for (const auto& kv : countMap)
{cout << kv.first << ":" << kv.second << endl;//*it的元素赋值给了kv}cout << endl;return 0;
}

总结:
- map中的的元素是键值对
- map中的key是唯一的,并且不能修改
- 默认按照小于的方式对key进行比较
- map中的元素如果用迭代器去遍历,可以得到一个有序的序列
- map的底层为平衡搜索树(红黑树),查找效率比较高 O ( l o g 2 N ) O(log_2 N) O(log2N)
- 支持[]操作符,operator[]中实际进行插入查找
multimap的使用
定义:multimap是多重映射是关联容器,用于存储由键值和映射值的组合形成的元素,遵循特定顺序,并且多个元素可以具有等效的键,和multiset一样支持冗余。
#include<iostream>
#include<map>
#include<set>
#include<string>
using namespace std;
int main()
{multimap<string, string> dict;dict.insert(make_pair("left", "左边"));dict.insert(make_pair("left", "剩余"));dict.insert(make_pair("string", "字符串"));dict.insert(make_pair("left", "xxx"));for (const auto& kv :dict){cout << kv.first << ":" << kv.second << endl; }string arr[] = { "苹果","西瓜","香蕉","草莓","苹果","西瓜","苹果","苹果","西瓜","苹果","香蕉","苹果","香蕉" };multimap<string, int> countMap;//map<string,int>::iterator it=countMap;for (auto& e : arr){auto it = countMap.find(e);//查找水果if (it == countMap.end())//没有{countMap.insert(make_pair(e, 1));}else{it->second++;//次数加加}}for (const auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;//*it的元素赋值给了kv}cout << endl;system("pause");return 0;}

通过结果我们看到使用multimap也能很好的统计出水果出现的次数,因为muitmap支持键值冗余,我们使用的成员函数find会先查找此类水果有没有出现,有就加加次数不会再反复insert,没有我没再insert然后再加加次数。
相关文章:
C++map和set
目录: 什么是关联式容器?键值对树形结构的关联式容器 set的概念multiset的使用pair和make_pair map的概念用“[]”实现统计水果的次数 multimap的使用 什么是关联式容器? 在初阶阶段,我们已经接触过STL中的部分容器,比…...
python接口测试之测试报告
在本文章中,主要使用jenkins和编写的自动化测试代码,来生成漂亮的测试报告,关于什么是CI这些我就不详细的介绍了,这里我们主要是实战为主。 首先搭建java的环境,这个这里不做介绍。搭建好java的环境后,在h…...
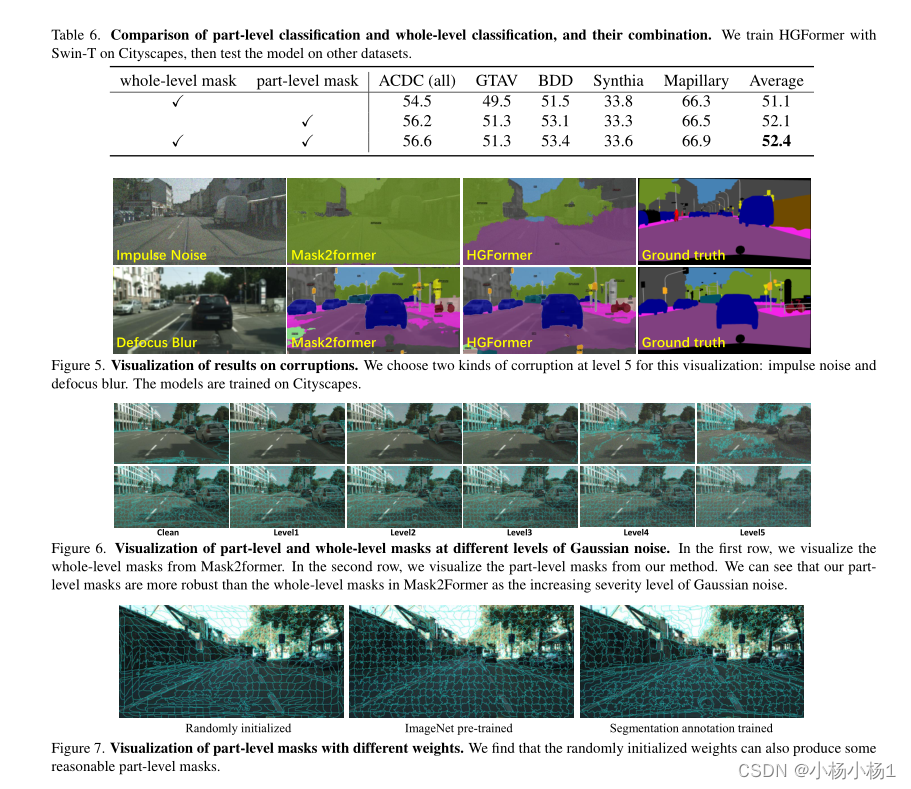
HGFormer:用于领域广义语义分割的层级式分组Transformer
文章目录 HGFormer: Hierarchical Grouping Transformer for Domain Generalized Semantic Segmentation摘要本文方法实验结果 HGFormer: Hierarchical Grouping Transformer for Domain Generalized Semantic Segmentation 摘要 目前的语义分割模型在独立同分布条件下取得了…...
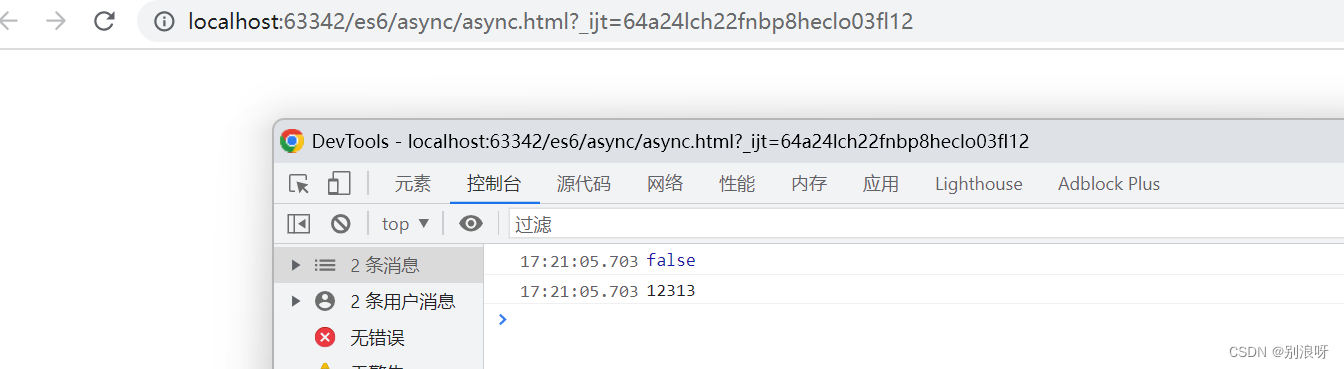
async函数用法
目录 1.概念 2.本质 3.语法 4.特点 5.async基本使用 6.async里的await普通函数返回值 7.async里的await Promise函数成功返回值 8.async里的await Promise函数失败返回值 9.解决async里的await Promise函数失败后不执行下面内容 1.概念 真正意义上解决异步回调的问题&am…...

简谈软件版本周期 | Alpha、Beta、RC、Stable版本之间的区别
目录 💌 引言 ⭕ 软件版本周期 🛠️ 软件开发期 ⚖️ 软件完成期 💰 商业软件版本 💌 引言 定义好版本号,对于产品的版本发布与持续更新很重要;但是对于版本怎么定义,规则如何确定&#x…...
VS2022发布独立部署的.net程序
.net core支持依赖框架部署和独立部署两种方式,之前学习时是在VSCode中使用dotnet命令发布的。但是在VS2022中却不知道该如何设置。以获取PDF文件使用字体的项目为例,VS2022中默认编译的是依赖框架部署方式(编译的结果如下图所示)…...

5-网络初识——封装和分用
目录 1.数据封装的过程 2.数据分用的过程 PS:网络数据传输的基本流程(以QQ为例,A给B发送一个hello): 一、发送方: 二、接收方: 不同的协议层对数据包有不同的称谓,在传输层叫做…...

机器学习——特征工程
对于机器学习特征工程的知识,你是怎样理解“特征” 在机器学习中,特征(Feature)是指从原始数据中提取出来的、用于训练和测试机器学习模型的各种属性、变量或特点。特征可以是任何类型的数据,例如数字、文本、图像、音…...

ubuntu安装搜狗输入法,图文详解+踩坑解决
搜狗输入法已支持Ubuntu16.04、18.04、19.10、20.04、20.10,本教程系统是基于ubuntu18.04 一、添加中文语言支持 系统设置—>区域和语言—>管理已安装的语言—>在“语言”tab下—>点击“添加或删除语言”。 弹出“已安装语言”窗口,勾选中文…...

docker 数据持久化
目录 一、将本地目录直接映射到容器里(运行成容器时候进行映射) 二、数据卷模式 1、创建数据卷 2、查看数据卷列表,有哪些数据卷 3、查看某个数据卷 4、容器目录挂载到数据卷 5、数据卷的优势:多个容器共享一个数据卷 默认…...

Pytest运行指定的case,这个方法真的很高效……
Pytest运行指定的case 在测试工作中,当我们写了较多的cases时,如果每次都要全部运行一遍,无疑是很浪费时间的,而且效率低下。 但是有一种方法可以帮助你快速地运行指定的测试用例,提高测试效率,那就是使用…...

操作系统复习2.3.4-进程同步问题
生产者-消费者 系统中有一组生产者进程和一组消费者进程 两者共享一个初始为空,大小为n的缓冲区 缓冲区没满,生产者才能放入 缓冲区没空,消费者才能取出 互斥地访问缓冲区 互斥要在同步之后,不然会导致想要同步,但由…...
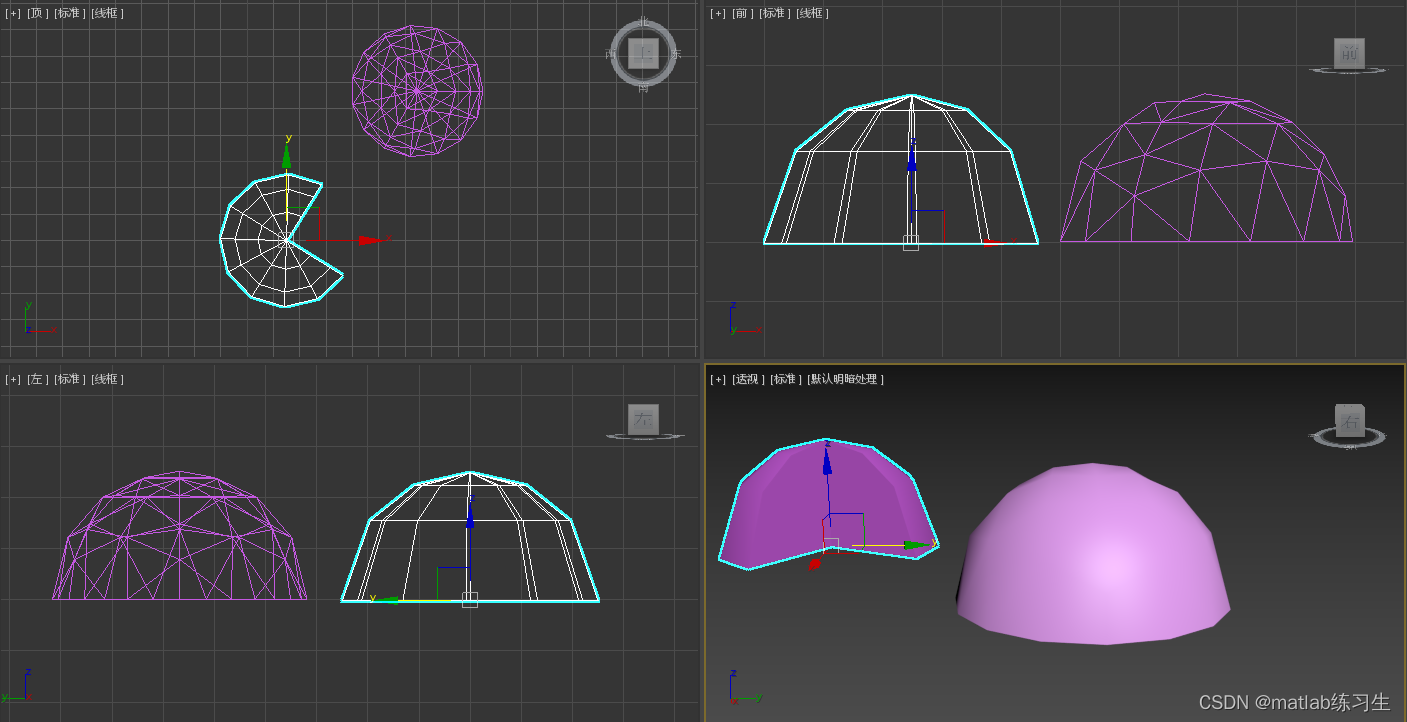
3ds MAX 基本体建模,长方体、圆柱体和球体
3ds MAX基本页面如下: 生成新的几何体在右侧: 选择生成的对象类型即可,以下为例子: 1、长方体建模 选择建立的对象类型为长方形 在 任意一个窗口绘制,鼠标滑动 这里选择左上角的俯视图 松开鼠标后,可以…...

搭建个人博客
个人网站用处有很多,可以写博客来记录学习过程中的各种事,不管是新知识还是踩坑记录,写完就丢在网站上,方便日后复习,也可以共享给他人,让其他人避免踩雷。 当然也不仅限于技术性的文章,生活中有…...
)
JavaScript进阶(下)
# JavaScript 进阶 - 第3天笔记 > 了解构造函数原型对象的语法特征,掌握 JavaScript 中面向对象编程的实现方式,基于面向对象编程思想实现 DOM 操作的封装。 - 了解面向对象编程的一般特征 - 掌握基于构造函数原型对象的逻辑封装 - 掌握基于原型对…...
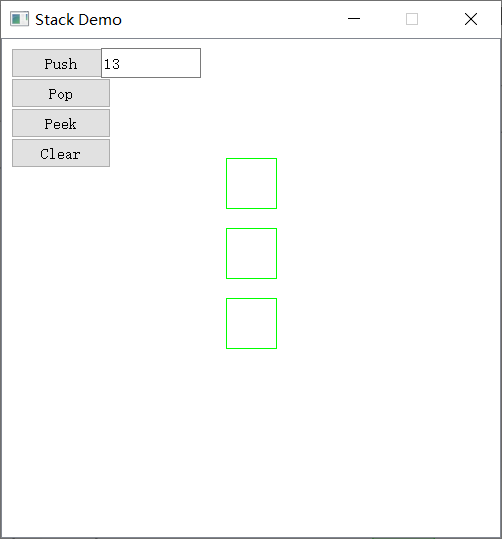
基于PyQt5的图形化界面开发——堆栈动画演示
目录 0. 前言1. 了解堆栈2.代码实现3. 演示效果其他PyQt5文章 0. 前言 本文使用 PyQt5制作图形化界面演示数据结构中的堆栈操作 操作系统:Windows10 专业版 开发环境:Pycahrm Comunity 2022.3 Python解释器版本:Python3.8 第三方库&…...

2023 年第三届长三角高校数学建模竞赛赛题浅析
为了更好地让大家本次长三角比赛选题,我将对本次比赛的题目进行简要浅析。数模模型通常分为优化、预测、评价三类,而本次数学题目就正好对应着A、B、C分别为优化、预测、评价。整体难度不大,主要难点在于A题的优化以及B、C的数据收集。稍后&a…...

sqlite3免费加密开源项目sqlcipher简单使用
一、概述 使用sqlite3的免费版本是不支持加密的。为了能使用上加密sqlite3,有一个免费的开源项目sqlcipher提供了免费和付费的加密sqlite功能。我们当然选择免费的版本啦。 官方网站: https://www.zetetic.net/sqlcipher/open-source/ 文档目录&#…...

SOLIDWORKS PDM Professional中的Add-ins
实现COM接口IEdmAddIn5的DLLs:IEdmAddIn5 Interface - 2019 - SOLIDWORKS API Help。通过“Add-in特性”对话框添加到文件库中:Administrate Add-ins Dialog Box - 2019 - SOLIDWORKS API Help通知SOLIDWORKS PDM Professional 用户操作: 将Add-in添加到…...

干货 | 郭晓雷:数智安全监管机制研究与思考
作者:郭晓雷本文约4300字,建议阅读8分钟 本文报告的主要内容关于数据安全,从学术或者技术的角度,更多地认为人工智能是数据处理的新技术,其应用会产生更加丰富的数据处理活动场景。 郭晓雷:今天报告的主要内…...
)
告别繁琐配置:Jprotobuf注解驱动序列化实战(新手友好)
1. 为什么选择Jprotobuf注解方案 如果你正在用Java开发需要频繁序列化数据的应用,比如缓存系统、微服务通信或者游戏服务器,肯定遇到过这样的纠结:用JSON虽然方便但性能差体积大,用Protobuf性能好但配置太麻烦。我去年做电商订单系…...
那些鲜为人知的“前世今生”)
从多媒体到HPC:聊聊IBM GPFS(Spectrum Scale)那些鲜为人知的“前世今生”
从多媒体到HPC:IBM GPFS的技术进化与商业智慧 1993年,当第一代数字视频编辑系统还在为处理480p分辨率视频而焦头烂额时,IBM实验室里的一组工程师正在解决一个更根本的问题——如何让多个工作站同时高效访问同一组视频素材。这个看似简单的需求…...
)
Nature级研究启动前必做这5步:Perplexity智能检索校准清单(20年顶刊审稿人压箱底工作流)
更多请点击: https://intelliparadigm.com 第一章:Nature级研究启动前的智能检索认知革命 在高影响力科研项目(如 Nature、Science 级别)立项初期,传统关键词检索已无法应对跨学科文献爆炸、语义歧义与隐性知识关联等…...

Cron表达式智能解析与生成工具:提升定时任务开发效率
1. 项目概述:一个为Cron表达式减负的智能助手 如果你是一名运维工程师、后端开发者,或者任何需要与定时任务打交道的人,那么你一定对Cron表达式又爱又恨。爱的是它那套简洁而强大的语法,能精准地定义“每月的第一个星期一的凌晨3…...

量子信号处理技术及其在离子阱系统中的应用
1. 量子信号处理技术概述量子信号处理(Quantum Signal Processing, QSP)是近年来量子计算领域涌现的一项基础性技术,它通过精心设计的量子比特旋转序列,实现对量子数据的系统性多项式变换。这项技术的核心价值在于,它为…...

构建个人知识管理系统:基于技能树与间隔重复的学习框架
1. 项目概述:构建个人专属的“人类技能树” 最近在折腾一个挺有意思的项目,我把它叫做“人类技能树”。这名字听起来有点科幻,但内核其实很朴素:我们每个人从小到大,从学校到职场,都在不断地学习各种技能&a…...

2026年5月PLC厂家:十大品牌专业评测解决工厂自动化选型难
摘要当制造业加速迈向智能化和柔性生产,PLC作为工业自动化的核心控制单元,其选型直接决定了产线效率、系统稳定性与长期运营成本。然而,面对众多品牌在技术路线、开放程度、生态兼容性上的显著分化,决策者常陷入“性能与成本如何平…...

基于WebSocket的Web即时通讯后端架构设计与实战部署指南
1. 项目概述:一个面向开发者的Web即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个稳定、可控且能深度定制的即时通讯模块。市面上成熟的IM SDK很多,但要么是黑盒,出了问题排查困难;要么是功能臃肿࿰…...

共享屏幕怎么弄 共享屏幕用什么工具好
共享屏幕怎么弄?不管是异地办公同步方案、远程协助操作设备,还是和朋友分享游戏画面,都离不开共享屏幕的需求。共享屏幕怎么弄才不麻烦、不卡顿?其实答案很简单,无界趣连2.0就能轻松搞定,不用复杂设置&…...

为OpenClaw智能体工作流配置持久化的大模型服务支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置持久化的大模型服务支持 在构建基于OpenClaw的智能体工作流时,一个稳定、可靠的后端大模型…...