PyTorch 提示和技巧:从张量到神经网络

张量和梯度
我们将深入探讨使用 PyTorch 构建自己的神经网络必须了解的 2 个基本概念:张量和梯度。
张量
张量是 PyTorch 中的中央数据单元。它们是类似于数组的数据结构,在功能和属性方面与 Numpy 数组非常相似。它们之间最重要的区别是 PyTorch 张量可以在 GPU 的设备上运行以加速计算。

# 使用Tensor对象创建了一个 3x3 形状的未初始化张量。
import torch
tensor_uninitialized = torch.Tensor(3, 3)
tensor_uninitialized
"""
tensor([[1.7676e-35, 0.0000e+00, 3.9236e-44],[0.0000e+00, nan, 0.0000e+00],[1.3733e-14, 1.2102e+25, 1.6992e-07]])
"""
# 我们还可以创建用零、一或随机值填充的张量。
tensor_rand = torch.rand(3, 3)
tensor_rand
"""
tensor([[0.6398, 0.3471, 0.6329],[0.4517, 0.2253, 0.8022],[0.9537, 0.1698, 0.5718]])
"""
就像 Numpy 数组一样,PyTorch 允许我们在张量之间执行数学运算,同样的 Numpy 数组中的其他常见操作,如索引和切片,也可以使用 PyTorch 中的张量来实现。
# 数学运算
x = torch.Tensor([[1, 2, 3],[4, 5, 6]])
tensor_add = torch.add(x, x)
"""
tensor([[ 2., 4., 6.],[ 8., 10., 12.]])
"""
梯度📉
假设有 2 个参数 a 和 b ,梯度是一个参数相对于另一个参数的偏导数。导数告诉你当你稍微改变其他一些量时,给定量会发生多少变化。在神经网络中,梯度是损失函数相对于模型权重的偏导数。我们只想找到带来损失函数梯度最低的权重。

PyTorch 使用torch库中的Autograd包来跟踪张量上的操作。
# 01. 默认情况下,张量没有关联的梯度。
tensor= torch.Tensor([[1, 2, 3],[4, 5, 6]])
tensor.requires_grad
"""
False
"""
# 02. 可以通过调用requires_grad_函数在张量上启用跟踪历史记录。
tensor.requires_grad_()
"""
tensor([[1., 2., 3.],[4., 5., 6.]], requires_grad=True)
"""
# 03. 但是目前该 Tensor 还没有梯度
print(tensor.grad)
"""
None
"""
# 04. 现在,让我们创建一个等于前一个张量中元素均值的新张量,以计算张量相对于新张量的梯度。
mean_tensor = tensor.mean()
mean_tensor
"""
tensor(3.5000, grad_fn=<MeanBackward0>)
"""
# 05. 要计算梯度,我们需要显式执行调用backward()函数的反向传播。
mean_tensor.backward()
print(tensor.grad)
"""
tensor([[0.1667, 0.1667, 0.1667],[0.1667, 0.1667, 0.1667]])
"""
使用 PyTorch 的神经网络
我们可以将神经网络定义为扩展 torch.nn.Module 类的 Python 类。在这个类中,我们必须定义 2 个基本方法:
init()是类的构造函数。在这里,我们必须定义构成我们网络的层。forward()是我们定义网络结构以及各层连接方式的地方。这个函数接受一个输入,代表模型将被训练的特征。我将向你展示如何构建可用于分类问题的简单卷积神经网络并在 MNIST 数据集上训练它。

首先,我们必须导入torch和我们需要的所有模块。可以创建我们的模型了。
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np# CNN 由 2 个卷积层组成,后面是一个全局平均池化层。最后,我们有 2 个全连接层和一个softmax来获得最终的输出概率。class My_CNN(nn.Module):def __init__(self):super(My_CNN, self).__init__()self.conv1 = nn.Conv2d(1, 64, kernel_size=(3, 3), padding=1)self.conv2 = nn.Conv2d(64, 64, kernel_size=(3, 3), padding=1)self.avg_pool = nn.AvgPool2d(28)self.fc1 = nn.Linear(64, 64)self.fc2 = nn.Linear(64, 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.relu(self.conv2(x))x = self.avg_pool(x)x = x.view(-1, 64)x = F.relu(self.fc1(x))x = self.fc2(x)x = F.softmax(x)return x
其次,加载数据集,直接从 PyTorch 检索 MNIST 数据集,并使用 PyTorch 实用程序将数据集拆分为训练集和验证集。
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torch.utils.data.sampler import SubsetRandomSampler
mnist = MNIST("data", download=True, train=True)
## create training and validation split
split = int(0.8 * len(mnist))
index_list = list(range(len(mnist)))
train_idx, valid_idx = index_list[:split], index_list[split:]
## create sampler objects using SubsetRandomSampler
train = SubsetRandomSampler(train_idx)
valid = SubsetRandomSampler(valid_idx)# 使用DataLoader创建迭代器对象,它提供了使用多处理 worker 并行批处理、随机播放和加载数据的能力。
train_loader = DataLoader(mnist, batch_size=256, sampler=train)
valid_loader = DataLoader(mnist, batch_size=256, sampler=valid)现在我们拥有了开始训练模型的所有要素。然后再定义损失函数和优化器,Adam将用作优化器,交叉熵用作损失函数。
model = My_CNN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_function = nn.CrossEntropyLoss()最后开始训练,所有 PyTorch 训练循环都将经过每个 epoch 和每个DataPoint(在训练DataLoader 对象中)。
epochs = 10
for epoch in range(epochs):train_loss, valid_loss = [], []for data, target in train_loader:# forward propagation outputs = model(data)# loss calculationloss = loss_function(outputs, target)# backward propagationoptimizer.zero_grad()loss.backward()# weights optimizationoptimizer.step()train_loss.append(loss.item())for data, target in valid_loader:outputs = model(data)loss = los_function(outputs, target)valid_loss.append(loss.item())print('Epoch: {}, training loss: {}, validation loss: {}'.format(epoch, np.mean(train_loss), np.mean(valid_loss)))
在验证阶段,我们必须像在训练阶段所做的那样循环验证集中的数据。不同之处在于我们不需要对梯度进行反向传播。
with torch.no_grad():correct = 0total = 0for data, target in valid_loader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()
print('Validation set Accuracy: {} %'.format(100 * correct / total))就是这样!现在你已准备好构建自己的神经网络。你可以尝试通过增加模型复杂性向网络添加更多层来获得更好的性能。
请关注博主,一起玩转人工智能及深度学习。
相关文章:
PyTorch 提示和技巧:从张量到神经网络
张量和梯度 我们将深入探讨使用 PyTorch 构建自己的神经网络必须了解的 2 个基本概念:张量和梯度。 张量 张量是 PyTorch 中的中央数据单元。它们是类似于数组的数据结构,在功能和属性方面与 Numpy 数组非常相似。它们之间最重要的区别是 PyTorch 张量…...

第五期:字符串的一些有意思的操作
文章目录 1. 替换空格2. 字符串的左旋转3. 答案代码3.1 替换空格3.2 字符串的左旋转 PS:每道题解题方法不唯一,欢迎讨论!每道题后都有解析帮助你分析做题,答案在最下面,关注博主每天持续更新。 1. 替换空格 题目描述 请…...
20230608)
使用Anaconda3结合vscode来实现django项目的建立(绝好的介绍)20230608
问题:如何使用Anaconda3结合vscode来实现django项目的建立? 回答: 知识背景 Anaconda3的安装包默认会安装最新版本的Python解释器。如果您想在安装时指定Python解释器的版本,您需要下载对应版本的Anaconda3。例如,如果您想使用Python 3.7&…...
【软件测试】软件测试的基本概念和开发模型
1. 前言 在进行软件测试的学习之前,我们要了解软件测试一些基本概念. 这些基本概念将帮助我们更加明确工作的目标以及软件测试到底要做什么. 2. 软件测试的基本概念 软件测试的基本概念有3个,分别是需求,测试用例和BUG. 2.1 需求 这里的需求还可以分为 用户需求和软件需求,用户…...

接口测试 —— 接口测试定义
1、接口测试概念 (重点) 接口测试是测试系统组件间接口的一种测试,它界于单元测试与系统测试中间。 接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。 测试的重点是要检查数据的交换,传递和控制管理过…...
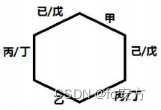
2015 年一月联考逻辑真题
2015 年一月联考逻辑真题 真题(2015-26) 26.晴朗的夜晚我们可以看到满天星斗,其中有些是自身发光的恒星,有些是自身不发光但可以反射附近恒星光的行星。恒星尽管遥远,但是有些可以被现有的光学望远镜“看到”。和恒星不…...
基于GD32的定时器不完全详解--定时、级联
SysTick 定时器 SysTick 是一个 24 位的倒计数定时器,当计到 0 时,将从 RELOAD 寄存器中自动重装载定时初值。只要不把它在 SysTick 控制及状态寄存器中的使能位清除, 就永不停息。 该定时器的介绍在MCU的手册中一般不会介绍,因为…...
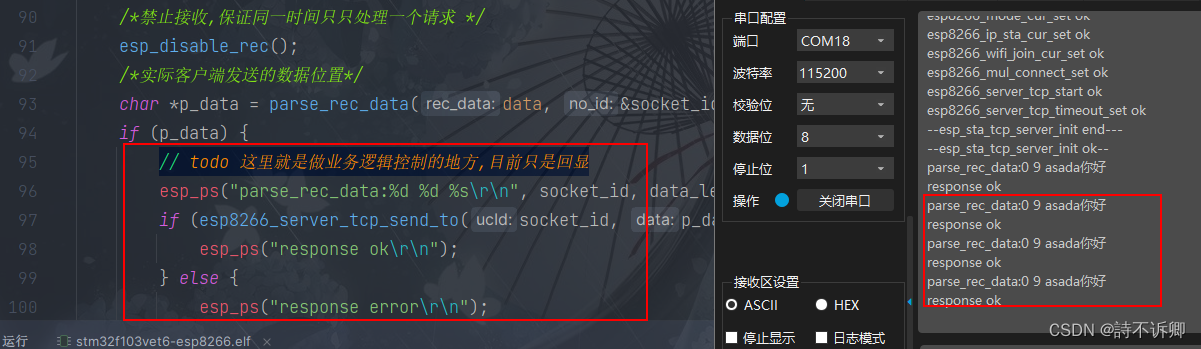
Clion开发STM32之ESP8266系列(四)
前言 上一篇: Clion开发STM32之ESP8266系列(三) 本篇主要内容 实现esp8266需要实现的函数串口3中断函数的自定义(这里没有使用HAL提供的)封装esp8266服务端的代码和测试 正文 主要修改部分 核心配置头文件(添加一些宏定义) sys_core_conf.h文件中…...
降本增效,StarRocks 在同程旅行的实践
作者:周涛 同程旅行数据中心大数据研发工程师 同程旅行是中国在线旅游行业的创新者和市场领导者。作为一家一站式平台,同程旅行致力于满足用户旅游需求,秉持 "让旅行更简单、更快乐" 的使命,主要通过包括微信小程序、AP…...

INTP型人格适合选择哪些专业?
INTP人格内倾理性人格、具有强烈的好奇心、创造性和独立性的特点。他们善于独立思考和寻找问题的本质,并对抽象的想法和理论感兴趣。 INTP人格的人具有很强的逻辑思维和分析能力,他们的思维方式非常系统,追求完美和准确。因此他们适合选择需…...

【LeetCode热题100】打卡第16天:组合总和
文章目录 组合总和⛅前言🔒题目🔑题解 组合总和 ⛅前言 大家好,我是知识汲取者,欢迎来到我的LeetCode热题100刷题专栏! 精选 100 道力扣(LeetCode)上最热门的题目,适合初识算法与数…...

tinkerCAD案例:1.戒子环
基本戒指 在本课中,您将学习使用圆柱形状制作戒指。来吧! 说明 将圆柱体拖动到工作平面上并使其成为孔。 圆柱体应缩放以适合其制造手指。 在本例中,我们将使用 17mm 作为直径,但请根据您的需要随意调整尺寸。 将“圆柱”形状拖…...
RPC接口测试技术-Tcp 协议的接口测试
【摘要】 首先明确 Tcp 的概念,针对 Tcp 协议进行接口测试,是指基于 Tcp 协议的上层协议比如 Http ,串口,网口, Socket 等。这些协议与 Http 测试方法类似(具体查看接口自动化测试章节)…...

MyBatis Plus基本用法-SpringBoot框架
依赖 使用 Mybatis Plus 框架时,需要添加以下依赖: <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>latest-version</version> </dependency…...
指针--指针变量的定义和初始化
存放变量的地址需要一种特殊类型的变量,这种特殊的数据类型就是指针(Pointer)。 具有指针类型的变量,称为指针变量,它时专门用于存储变量的地址值和变量。 其定义形式如下: 类型关键字 * 指针变量名&#x…...
Web基本概念
一、前言 World Wide Web的简称,是一个由许多互相链接的超文本组成的系统,通过互联网访问 (为用户提供信息) 静态网页 仅适用于不能经常更改内容的网页; 动态网页 网络编程技术创建的页面;通过在传统的静态…...
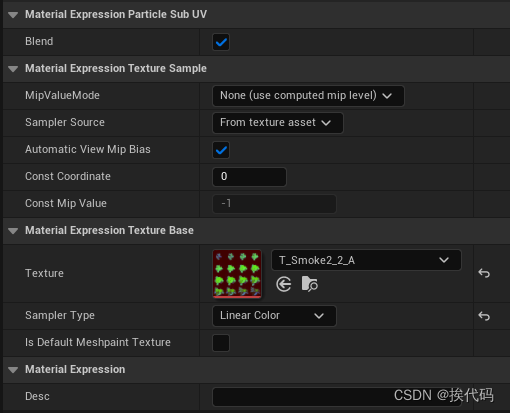
Niagara—— Texture Sample 与 Particle Subuv 区别
目录 一,Texture Sample 二,Particle Subuv 一,Texture Sample 此节点是最基本的采样节点,依据UV坐标来采样Texture; MipValueMode,设置采样的Mipmap Level; None,根据当前Texture…...

如何在食品行业运用IPD?
食品是我国重要的民生产业之一,是保障和满足人民群众不断增长消费需求的重要支撑。食品指各种供人食用或者饮用的成品和原料以及按照传统既是食品又是药品的物品,包括加工食品,半成品和未加工食品,不包括烟草或只作药品用的物质。…...

如何用pandas进行条件分组计算?
Pandas提供了强大的分组聚合功能,可以轻松进行条件分组计算和统计。本文通过一个例子,展示如何使用Pandas的.groupby()和.agg()方法进行条件分组计算。 准备数据 假设有这样一个字典数据: dict { 姓名: [张三,李四,王五&#x…...

tomcat如何调优,涉及哪些参数?
Tomcat是一个流行的开源Java Servlet容器,用于部署和管理Java Web应用程序。调优Tomcat可以提高性能、并发处理能力和稳定性。以下是一些常见的Tomcat调优参数和技巧: 1.调整内存参数: -Xms:指定Tomcat启动时的初始堆内存大小。 -…...

OpenIPC固件构建与君正T31平台刷机实战指南
OpenIPC固件构建与君正T31平台刷机实战指南 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware OpenIPC是一个基于Buildroot的开源IP摄像头固件项目,为海思、君正、全…...

代码转图片怎么实现:代码高亮卡片生成方法
最近在做文章后台时,我遇到一个很实际的问题:编辑器里的代码块虽然能正常显示,但要拿去做分享图、封面图或者文档配图时就不太合适了。 一开始我试过手动截图,但这种方式效率低,而且样式不统一。代码只要改一行&#x…...

揭秘HunterPie:如何用现代化覆盖层技术革新《怪物猎人:世界》体验
揭秘HunterPie:如何用现代化覆盖层技术革新《怪物猎人:世界》体验 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_m…...

本地待办清单的革命:为什么My-TODOs让数据隐私与高效任务管理完美融合?
本地待办清单的革命:为什么My-TODOs让数据隐私与高效任务管理完美融合? 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 在云端存储成为主流的今天…...

当大模型认不出一个具体名字:MiniMax 回答失灵,问题未必只在模型本身
当大模型认不出一个具体名字:MiniMax 回答失灵,问题未必只在模型本身 围绕“为什么 MiniMax 大模型无法识别马嘉祺是谁”的一次能力拆解:真正暴露的,往往是知识覆盖、检索策略与风控边界的耦合问题 直接回答 先给结论。 如果 Mi…...

Windows Defender 彻底移除工具:专业级系统安全组件管理解决方案
Windows Defender 彻底移除工具:专业级系统安全组件管理解决方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_m…...

LaTeX2Word-Equation:打破学术写作中的公式壁垒
LaTeX2Word-Equation:打破学术写作中的公式壁垒 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 在学术研究和教育工作中,…...

基于Vue 3与JSON数据构建MBTI运势生成器:前端实战开发指南
1. 项目概述:当MBTI遇上运势,一个技术驱动的趣味应用最近在GitHub上看到一个挺有意思的项目,叫“mbti-fortune”,作者是leilei926524-tech。光看名字,你可能会觉得这又是一个简单的星座运势或者性格测试的变种。但作为…...

DAY 4.链表中环的入口节点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、链表中环的入口节点二、代码实现2.结论总结前言 一、链表中环的入口节点 思路:使用快慢指针,都从头节点出发,快指针一次…...

Keil5 C51与MDK合并安装避坑全记录:从下载、配置到成功破解
Keil5 C51与MDK合并安装实战指南:从零开始到完美运行 作为一名长期从事嵌入式开发的工程师,我深知Keil在单片机开发领域的地位。无论是经典的51单片机还是功能强大的STM32,Keil都能提供专业的开发环境。但官方将C51和MDK版本分开的做法确实给…...