【C++ Primer Plus】第四章:复合类型
文章目录
- 4.1 数组
- C++11数组初始化的方法
- 4.2 字符串
- **cin是如何确定已完成字符串输入呢?**
- **如何每次读取一行字符串输入?**
- **面向行的输入:getline()**
- **面向行的输入:get( )**
- **为什么推荐使用get( ),而不是getline( )呢?**
- **如果读取到空行怎么办?**
- 4.3 string
- string类的拼接与复制
- 如何计算字符串长度?
- 原始字符串
- 4.4 结构体
- 4.5共用体
- 4.6枚举
- 枚举值的取值范围
- 4.7指针
- 指针与自由存储空间
- 指针的危险
- 使用new来分配内存
- 使用delete释放内存
- new关键字的意义
- 使用new创建动态数组
- 数组与指针
- 指针小结:
- 指针与字符串
- 自动存储,静态存储与动态存储
- 自动存储
- 静态存储
- 动态存储
- 4.8数组的替代品
- vector:
- array:
- 总结
4.1 数组
数组(array)是一种数据格式,能够存储多个同类型的值;
要创建数组,可使用声明语句。数组声明应指出以下三点:
- 存储在每个元素中的值的类型;
- 数组名;
- 数组中的元素数。
typeName arrayName[arraySize];
arraySize不能是变量,变量的值是在程序运行时设置的。稍后将介绍如何使用new运算符来避开这种闲置;
只有在定义数组时才能使用初始化,此后就不能使用了,也不能将一个数组赋给另一个数组:
int card[4] = {3,6,8,10};//okay
int hand[4];
hand[4] = {5,6,7,8};//not allowed
hand = cards;//not allowed
初始化数组时,提供的值可以少于数组的元素数目,编译器会将剩下的全部赋值为零;
C++11数组初始化的方法
- 首先,初始化数组时,可省略等号(=):
double k[4] {1.0,2.0};
- 其次,可不在大括号内包含任何东西,这将把所有元素都设置为零:
double k[4]{};
- 第三,列表初始化禁止缩窄转换;
4.2 字符串
char dog[8] = {'b','e','a','u','x',' ','I','I'};
char cat[8] = {'b','e','a','u','x','I','I','\0'};
这两个数组都是char数组,但只有第二个数组是字符串;
在cat数组示例中,将数组初始化为字符串的工作看上去冗长乏味——使用大量单引号,且必须记住加上空字符。不必担心,有一种更好的、将字符数组初始化为字符串的方法—只需使用一个用引号括起的字符串即可,这种字符串被称为字符串常量(string constant)或字符串字面值(string literal),如下所示:
char bird[11] ="Mr.Cheeps";
char fish[] ="Bubbles";
用引号括起的字符串隐式地包括结尾的空字符,因此不用显式地包括它;
char sh = 'S';//字符常量(如'S')是字符串编码的简写表示,该语句将83赋给sh;
char sh = "S";//“S"表示的是字符S和\0组成的字符串;事实上,”S"表示的是该字符串所在的内存地址。因此,这条语句实际上试图将一个内存地址赋值为sh.但是由于地址在C++中是一种独立的类型,因此编译器不允许这种不合理的做法;
有时候,字符串很长,无法放到一行中。C++允许拼接字符串字面值,即将两个用引号括起的字符串合并为一个。事实上,任何两个由空白(空格、制表符和换行符)分隔的字符串常量都将自动拼接成一个。
因此,下面所有的输出语句都是等效的:
cout<<"I had give my right arm to be " " a great violinist."<<endl;
cout<<"I had give my right arm to be a great violinist."<<endl;
cout<<"I had give my right ar"
"m to be a great violinist."<<endl;
注意,拼接时不会在被连接的字符串之间添加空格,第二个字符串的第一个字符将紧跟在第一个字符串的最后一个字符(不考虑\0)后面。第一个字符串中的\0字符将被第二个字符串的第一个字符取代。
sizeof运算符指出整个数组的长度:15字节,但strlen( )函数返回的是存储在数组中的字符串的长度,而不是数组本身的长度。另外,strlen( )只计算可见的字符,而不把空字符计算在内。
cin是如何确定已完成字符串输入呢?
由于不能通过键盘输入空字符,因此cin需要用别的方法来确定字符串的结尾位置。cin使用空白(空格、制表符和换行符)来确定字符串的结束位置,这意味着cin在获取字符数组输入时只读取一个单词。读取该单词后,cin将该字符串放到数组中,并自动在结尾添加空字符。
如何每次读取一行字符串输入?
每次读取一个单词通常不是最好的选择。例如,假设程序要求用户输入城市名,用户输入New York。您希望程序读取并存储完整的城市名,而不仅仅是New或Sao。要将整条短语而不是一个单词作为字符串输入,需要采用另一种字符串读取方法。具体地说,需要采用面向行而不是面向单词的方法。
幸运的是,istream中的类(如cin)提供了一些面向行的类成员函数:getline( )和get( )。这两个函数都读取一行输入,直到到达换行符。然而,随后getline( )将丢弃换行符,而get( )将换行符保留在输入序列中。
getline( )函数读取整行,它使用通过回车键输入的换行符来确定输入结尾。要调用这种方法,可以使用cin.getline( )。该函数有两个参数。第一个参数是用来存储输入行的数组的名称,第二个参数是要读取的字符数。如果这个参数为20,则函数最多读取19个字符,余下的空间用于存储自动在结尾处添加的空字符。getline( )成员函数在读取指定数目的字符或遇到换行符时停止读取。
cin.getline(charr,20)
这种句点表示法表明,函数getline( )是istream类的一个类方法(还记得吗,cin是一个istream对象)。正如前面指出的,第一个参数是目标数组;第二个参数数组长度,getline( )使用它来避免超越数组的边界。
下面是将一行输入读取到string对象中的代码:
getline(cin,str);
那么,为何一个getline( )是istream的类方法,而另一个不是呢?
在引入string类之前很久,C++就有istream类。因此istream的设计考虑到了诸如double和int等基本C++数据类型,但没有考虑string类型,所以istream类中,有处理double、int和其他基本类型的类方法,但没有处理string对象的类方法。
istream类有另一个名为get( )的成员函数,该函数有几种变体。其中一种变体的工作方式与getline( )类似,它们接
受的参数相同,解释参数的方式也相同,并且都读取到行尾。但get并不再读取并丢弃换行符,而是将其留在输入队列中。假设我们连续两次调用get( ):
cin.get(name,ArSize);
cin.get(dessert,ArSize);
由于第一次调用后,换行符将留在输入队列中,因此第二次调用时看到的第一个字符便是换行符。因此get( )认为已到达行尾,而没有发现任何可读取的内容。如果不借助于帮助,get( )将不能跨过该换行符。
幸运的是,get( )有另一种变体。使用不带任何参数的cin.get( )调用可读取下一个字符(即使是换行符),因此可以用它来处理换行符,为读取下一行输入做好准备。也就是说,可以采用下面的调用序列:
cin.get(name,ArSize);
cin.get();
cin.get(dessert,ArSize);
另一种使用get( )的方式是将两个类成员函数拼接起来(合并),如下所示:
cin.get(name,ArSize).get();
之所以可以这样做,是由于cin.get(name,ArSize)返回一个cin对象,该对象随后将被用来调用get( )函数。同样,下面的语句将把输入中连续的两行分别读入到数组name1和name2 中,其效果与两次调用cin.getline( )相同:
cin.getline(name1,ArSize).getline(name2,ArSize);
为什么推荐使用get( ),而不是getline( )呢?
首先,老式实现没有getline( )。
其次,get( )使输入更仔细。例如,假设用get( )将一行读入数组中。如何知道停止读取的原因是由于已经读取了整行,而不是由于数组已填满呢?查看下一个输入字符,如果是换行符,说明已读取了整行;否则,说明该行中还有其他输入。
如果读取到空行怎么办?
当getline( )或get( )读取空行时,将发生什么情况?最初的做法是,下一条输入语句将在前一条getline( )或get( )结束读取的位置开始读取;但当前的做法是,当get( )(不是getline( ))读取空行后将设置失效位(failbit)。这意味着接下来的输入将被阻断,但可以用下面的命令来恢复输入:
cin.cleanr();
另一个潜在的问题是,输入字符串可能比分配的空间长。如果输入行包含的字符数比指定的多,则getline( )和get( )将把余下的字符留在输入队列中,而getline( )还会设置失效位,并关闭后面的输入。
4.3 string
string类的拼接与复制
strcpy(charr1,charr2);//将charr2的内容复制到charr1里面
strcat(charr1,charr2);//将charr2拼接到charr1的后面
str3 = str1 + str2;
如何计算字符串长度?
str1.size();//类成员函数
// 函数strlen( )从数组的第一个元素开始计算字节数,直到遇到空字符。在这个例子中,在数组末尾的几个字节后才遇到
// 空字符。对于未被初始化的数据,第一个空字符的出现位置是随机的,因此您在运行该程序时,得到的数组长度很可能与此不同。
strlen(str1);//普通函数传入类对象
原始字符串
C++11新增的另一种类型是原始(raw)字符串。在原始字符串中,字符表示的就是自己,例如,序列\n不表示换行符,而表示两个常规字符—斜杠和n,因此在屏幕上显示时,将显示这两个字符。另一个例子是,可在字符串中使用",而无需像程序清单4.8中那样使用繁琐的"。当然,既然可在字符串字面量包含",就不能再使用它来表示字符串的开头和末尾。因此,原始字符串将"(和)"用作定界符,并使用前缀R来标识原始字符串:
cout<<R"(Jim"King")"<<endl;
如果要在原始字符串中包含)",该如何办呢?
编译器见到第一个)"时,会不会认为字符串到此结束?会的。
但原始字符串语法允许您在表示字符串开头的"和(之间添加其他字符,这意味着表示字符串结尾的"和)之间也必须包含这些字符。因此,使用R"+*(标识原始字符串的开头时,必须使用)+*"标识原始字符串的结尾。
cout<<R"+*("(who is he?)",she said.)+*"<<endl;
因此,上面的语句:
“(who is he?)”,she said.
4.4 结构体
与C结构struct不同,C++结构除了成员变量之外,还可以有成员函数。
结构中的位字段
与C语言一样,C++也允许指定占用特定位数的结构成员,这使得创建与某个硬件设备上的寄存器对应的数据结构非常方便。字段的类型应为整型或枚举(稍后将介绍),接下来是冒号,冒号后面是一个数字,它指定了使用的位数。可以使用没有名称的字段来提供间距。每个成员都被称为位字段(bit field)。下面是一个例子:
struct torgle{unsigned int SN : 4;unsigned int : 4;bool goodin : 1;bool goodTorgle : 1;
}
位字段通常用在低级编程中。此部分只做了解即可;
4.5共用体
共用体(union)是一种数据格式,它能够存储不同的数据类型,但只能同时存储其中的一种类型。也就是说,结构可以同时存储int、long和double,共用体只能存储int、long或double。共用体的句法与结构相似,但含义不同。例如,请看下面的声明:
union one4all{int int_val;long long_val;double double_val;
}
可以使用one4all变量来存储int、long或double,条件是在不同的时间进行:
one4all pail;
pail.int_val = 15;//store an int
cout<<pail.int_val;
pail.double_val = 1.38;//store a double,int value is lost;
cout<<pail.double_val;
因此,pail有时可以是int变量,而有时又可以是double变量。成员名称标识了变量的容量。由于共用体每次只能存储一个值,因此它必须有足够的空间来存储最大的成员,所以,共用体的长度为其最大成员的长度。
共用体的用途之一是,当数据项使用两种或更多种格式(但不会同时使用)时,可节省空间。
例如,假设管理一个小商品目录,其中有一些商品的ID为整数,而另一些的ID为字符串。在这种情况下,可以这样做:
struct widget{char brand[20];int type;union id{long id_num;char id_char[20];}id_val;
}
匿名共用体(anonymous union)没有名称,其成员将成为位于相同地址处的变量。显然,每次只有一个成员是当前的成员:
struct widget{char brand[20];int type;union {long id_num;char id_char[20];};
};
由于共用体是匿名的,因此id_num和id_char被视为prize的两个成员,它们的地址相同,所以不需要中间标识符id_val。程序员负责确定当前哪个成员是活动的。
共用体常用于(但并非只能用于)节省内存。当前,系统的内存多达数GB甚至数TB,好像没有必要节省内存,但并非所有的C++程序都是为这样的系统编写的。C++还用于嵌入式系统编程,如控制烤箱、MP3播放器或火星漫步者的处理器。对这些应用程序来说,内存可能非常宝贵。另外,共用体常用于操作系统数据结构或硬件数据结构。
4.6枚举
C++的enum工具提供了另一种创建符号常量的方式,这种方式可以代替const。使用enum的句法与使用结构相似。例如,请看下面的语句:
enum spectrum{red,orange,yellow,green,blue,violet,indigo,ultraviolet};spectrum band;
band = blue;//valid;
band = 2000;//invalid;//spectrum变量受到限制,只有8个可能的值为获得最大限度的可移植性,应将把非enum值赋给enum变量视为错误。
这条语句完成两项工作。
- 让spectrum成为新类型的名称;spectrum被称为枚举(enumeration),就像struct变量被称为结构一样。
- 将red、orange、yellow等作为符号常量,它们对应整数值0~7。这些常量叫作枚举量(enumerator)。
在默认情况下,将整数值赋给枚举量,第一个枚举量的值为0,第二个枚举量的值为1,依次类推。可以通过显式地指定整数值来覆盖默认值。
对于枚举,只定义了赋值运算符。具体地说,没有为枚举定义算术运算.
枚举量是整型,可被提升为int类型,但int类型不能自动转换为枚举类型:
int color = blue;
band = 3;//不合法
color = 3+red;
band = orange+red;//非法,没有为枚举定义运算符+,但用于算术表达式中时,被视为1+0,但是类型为int,因此不能赋值。
band = spectrum(3);//合法
设置枚举量的值:
可以使用赋值运算符来显式地设置枚举量的值:
enum bits{one = 1 , two = 2, four = 4, eight = 8};
enum bigstep{first, second = 100,thired};//0,100,101
enum {zero,null = 0,one,numero_uno = 1};//可以创建多个值相同的枚举量;
其中,zero和null都为0,one和umero_uno都为1。在C++早期的版本中,只能将int值(或提升为int的值)赋给枚举量,但这种限制取消了,因此可以使用long甚至long long类型的值。
枚举值的取值范围
最初,对于枚举来说,只有声明中指出的那些值是有效的。然而,C++现在通过强制类型转换,增加了可赋给枚举变量的合法值。每个枚举都有取值范围(range),通过强制类型转换,可以将取值范围中的任何整数值赋给枚举变量,即使这个值不是枚举值。例如,假设bits和myflag的定义如下:
enum bits{one = 1, two = 2,four = 4,eight = 8};
bits myflag;
//则下面的代码是合法的
myflag = bits(6);//其中6不是枚举值,但它位于枚举定义的取值范围内。
取值范围的定义如下。首先,要找出上限,需要知道枚举量的最大值。找到大于这个最大值的、最小的2的幂,将它减去1,得到的便是取值范围的上限。例如,前面定义的bigstep的最大值枚举值是101。在2的幂中,比这个数大的最小值为128,因此取值范围的上限为127。要计算下限,需要知道枚举量的最小值。如果它不小于0,则取值范围的下限为0;否则,采用与寻找上限方式相同的方式,但加上负号。例如,如果最小的枚举量为−6,而比它小的、最大的2的幂是−8(加上负号),因此下限为−7。
4.7指针
指针与自由存储空间
计算机程序在存储数据时必须跟踪的3种基本属性。为了方便,这里再次列出了这些属性:
- 信息存储在何处
- 存储的值是多少
- 存储的信息是什么类型
您使用过一种策略来达到上述目的:定义一个简单变量。声明语句指出了值的类型和符号名,还让程序为值分配内存,并在内部跟踪该内存单元。下面来看一看另一种策略,它在开发C++类时非常重要。这种策略以指针为基础,指针是一个变量,其存储的是值的地址,而不是值本身。
在讨论指针之前,我们先看一看如何找到常规变量的地址。只需对变量应用地址运算符(&),就可以获得它的位置;例如,如果home是一个变量,则&home是它的地址。
指针与C++基本原理
面向对象编程与传统的过程性编程的区别在于,OOP强调的是在运行阶段(而不是编译阶段)进行决策。运行阶段指的是程序正在运行时,编译阶段指的是编译器将程序组合起来时。运行阶段决策就好比度假时,选择参观哪些景点取决于天气和当时的心情;而编译阶段决策更像不管在什么条件下,都坚持预先设定的日程安排。
运行阶段决策提供了灵活性,可以根据当时的情况进行调整。例如,考虑为数组分配内存的情况。传统的方法是声明一个数组。要在C++中声明数组,必须指定数组的长度。因此,数组长度在程序编译时就设定好了;这就是编译阶段决策。您可能认为,在80%的情况下,一个包含20个元素的数组足够了,但程序有时需要处理200个元素。为了安全起见,使用了一个包含200个元素的数组。这样,程序在大多数情况下都浪费了内存。OOP通过将这样的决策推迟到运行阶段进行,使程序更灵活。在程序运行后,可以这次告诉它只需要20个元素,而还可以下次告诉它需要205个元素。总之,使用OOP时,您可能在运行阶段确定数组的长度。为使用这种方法,语言必须允
许在程序运行时创建数组。稍后您看会到,C++采用的方法是,使用关键字new请求正确数量的内存以及使用指针来跟踪新分配的内存的位置。在运行阶段做决策并非OOP独有的,但使用C++编写这样的代码比使用C语言简单。
处理存储数据的新策略刚好相反,将地址视为指定的量,而将值视为派生量。一种特殊类型的变量—指针用于存储值的地址。因此,指针名表示的是地址。*运算符被称为间接值(indirect velue)或解除引用(dereferencing)运算符,将其应用于指针,可以得到该地址处存储的值。
//如何去声明一个指针变量?int *P_updates;
-
//这表明 *P_updates 的类型为int由于*运算符被用于指针,因此p_updates变量本身必须是指针。我们说p_updates指向int类型,我们还说p_updates的类型是指向int的指针,或int*。可以这样说,p_updates是指针(地址),而*p_updates是int,而不是指针int *ptr;//这强调的是:*ptr是一个int类型的值。
int* ptr;//这强调的是:int*是一种类型——指向int的指针。//事实上在哪里添加空格对于编译器来讲是没有区别的。int *p1,p2;//表示声明创建一个指针p1和一个int变量p2;int*是一种复合类型。
double * tax_ptr;
char * str;
尽管它们都是指针,却是不同类型的指针。和数组一样,指针都是基于其他类型的。
虽然tax_ptr和str指向两种长度不同的数据类型,但这两个变量本身的长度通常是相同的。也就是说,char的地址与double的地址的长度相同,这就好比1016可能是超市的街道地址,而1024可以是小村庄的街道地址一样。地址的长度或值既不能指示关于变量的长度或类型的任何信息,也不能指示该地址上有什么建筑物。一般来说,地址需要2个还是4个字节,取决于计算机系统(有些系统可能需要更大的地址,系统可以针对不同的类型使用不同长度的地址)。
指针的危险
在C++中创建指针时,计算机将分配用来存储地址的内存,但不会分配用来存储指针所指向的数据的内存。为数据提供空间是一个独立的步骤,忽略这一步无疑是自找麻烦,如下所示:
long * fellow;
*fellow = 223333;
fellow确实是一个指针,但它指向哪里呢?上述代码没有将地址赋给fellow。那么223323将被放在哪里呢?我们不知道。由于fellow没有被初始化,它可能有任何值。不管值是什么,程序都将它解释为存储223323的地址。如果fellow的值碰巧为1200,计算机将把数据放在地址1200上,即使这恰巧是程序代码的地址。fellow指向的地方很可能并不是所要存储223323的地方。这种错误可能会导致一些最隐匿、最难以跟踪的bug。
🌟 一定要在对指针应用解除引用运算符(*)之前,将指针初始化为一个确定的、适当的地址。
使用new来分配内存
程序员要告诉new,需要为哪种数据类型分配内存;new将找到一个长度正确的内存块,并返回该内存块的地址。程序员的责任是将该地址赋给一个指针。下面是一个这样的示例:
int *pn = new int;//方法一
typename * pointer_name = new typeName;int higgens;
int * pt = &higgens;//方案二
new int告诉程序,需要适合存储int的内存。new运算符根据类型来确定需要多少字节的内存。然后,它找到这样的内存,并返回其地址。接下来,将地址赋给pn,pn是被声明为指向int的指针。现在,pn是地址,而*pn是存储在那里的值。
地址本身只指出了对象存储地址的开始,而没有指出其类型(使用的字节数)。
对于指针,需要指出的另一点是,new分配的内存块通常与常规变量声明分配的内存块不同。变量nights和pd的值都存储在被称为栈(stack)的内存区域中,而new从被称为堆(heap)或自由存储区(free store)的内存区域分配内存。
在C++中,值为0的指针被称为空指针(null pointer)。C++确保空指针不会指向有效的数据,因此它常被用来表示运算符或函数失败(如果成功,它们将返回一个有用的指针)。
使用delete释放内存
delete运算符,它使得在使用完内存后,能够将其归还给内存池,这是通向最有效地使用内存的关键一
步。归还或释放(free)的内存可供程序的其他部分使用。使用delete时,后面要加上指向内存块的指针(这些内存块最初是用new分配的):
int *ps = new int;
delete ps;
这将释放ps指向的内存,但不会删除指针ps本身。可以将ps重新指向另一个新分配的内存块。一定要配对地使用new和delete;否则将发生内存泄漏。也就是说,被分配的内存再也无法使用了。但是不要重复释放内存。
注意,使用delete的关键在于,将它用于new分配的内存。这并不意味着要使用用于new的指针,而是用于new的地址:
int *ps = new int;//开辟内存
int *pq = ps;//设置第二个指针指向同一块内存
delete pq;//释放该内存
一般来说,不要创建两个指向同一个内存块的指针,因为这将增加错误地删除同一个内存块两次的可能性。但稍后您会看到,对于返回指针的函数,使用另一个指针确实有道理。
new关键字的意义
通常,对于大型数据(如数组、字符串和结构),应使用new,这正是new的用武之地。例如,假设要编写一个程
序,它是否需要数组取决于运行时用户提供的信息。如果通过声明来创建数组,则在程序被编译时将为它分配内存空间。不管程序最终是否使用数组,数组都在那里,它占用了内存。在编译时给数组分配内存被称为静态联编(static binding),意味着数组是在编译时加入到程序中的。但使用new时,如果在运行阶段需要数组,则创建它;如果不需要,则不创建。还可以在程序运行时选择数组的长度。这被称为动态联编(dynamic binding),意味着数组是在程序运行时创建的。这种数组叫作动态数组(dynamic array)。使用静态联编时,必须在编写程序时指定数组的长度;使用动态联编时,程序将在运行时确定数组的长度。
使用new创建动态数组
int *psome = new int [10]type_name * pointer_name = new type_name [num_elements];//如何跟踪这10个元素?
//完全可以将psome当做数组名 psome[0],psome[1]
new运算符返回第一个元素的地址。当程序使用完new分配的内存块时,应使用delete释放它们。然而对于用new创建的数组而言,应当这样释放:
delete [] psome;
方括号告诉数组,应当释放整个数组,而不仅仅是指针指向的元素。
请注意delete和指针之间的方括号。如果使用new时,不带方括号,则使用delete时,也不应带方括号。如果使用new时带方括号,则使用delete时也应带方括号。
int *pt = new int;
short * ps = new short [500];
delete []pt;
delete ps;
总之,使用new和delete时,应遵守以下规则:
- 不要使用delete来释放不是new分配的内存。
- 不要使用delete释放同一个内存块两次。
- 如果使用new [ ]为数组分配内存,则应使用delete [ ]来释放。
- 如果使用new [ ]为一个实体分配内存,则应使用delete(没有方括号)来释放。
- 对空指针应用delete是安全的。
数组与指针
#include <iostream>
#include <climits>
using namespace std;int main() {int *a = new int[3];a[0] = 3;a[1] = 1;a[2] = 2;cout << "原来的数组是:" << endl;cout << a[0] << " " << a[1] << " " << a[2] << endl;cout << "偏移后的数组是:" << endl;a = a + 1;cout << a[0] << " " << a[1] << " " << a[2] << endl;cout << "二次偏移后的数组是:" << endl;a ++;cout << a[0] << " " << a[1] << " " << a[2] << endl;return 0;
}
输出如下:
原来的数组是:3 1 2
偏移后的数组是:1 2 0
二次偏移后的数组是:2 0 2119321413
将整数变量加1后,其值将增加1;但将指针变量加1后,增加的量等于它指向的类型的字节数。将指向double的指针加1后,如果系统对double使用8个字节存储,则数值将增加8;将指向short的指针加1后,如果系统对short使用2个字节存储,则指针值将增加2。
将指针变量加1后,其增加的值等于指向的类型占用的字节数。
stacks[1] 相当于 *(shacks+1)区别一:可以修改指针的值,而数组名是常量;区别二对数组应用sizeof运算符得到的是数组的长度,而对指针应用sizeof得到的是指针的长度,即使指针指向的是一个数组
数组的地址:
对数组取地址时,数组名也不会被解释为其地址。等等,数组名难道不被解释为数组的地址吗?
不完全如此:数组名被解释为其第一个元素的地址,而对数组名应用地址运算符时,得到的是整个数组的地址:
short tell[10];
cout<<tell<<endl;//&tell[0]
cout<<&tell<<endl;
从数字上说,这两个地址相同;但从概念上说,&tell[0](即tell)是一个2字节内存块的地址,而&tell是一个20字节内存块的地址。因此,表达式tell + 1将地址值加2,而表达式&tell+2将地址加20。换句话说,tell是一个short指针(* short),而&tell是一个这样的指针,即指向包含20个元素的short数组(short (*) [20]).
前面有关&tell的类型描述是如何来的呢?首先,您可以这样声明和初始化这种指针:
short (*pas)[20] = &tell;
如果省略括号,优先级规则将使得pas先与[20]结合,导致pas是一个short指针数组,它包含20个元素,因此括号是必不可少的。其次,如果要描述变量的类型,可将声明中的变量名删除。因此,pas的类型为short () [20]。另外,由于pas被设置为&tell,因此pas与tell等价,所以(*pas) [0]为tell数组的第一个元素。
指针小结:
- 声明:
typename * pointerName;
- 给指针赋值:应将内存地址赋给指针
double * pn;
- 对指针解除引用:*运算符
- 区分指针和指针所指向的值:如果pt是指向int的指针,则*pt不是指向int的指针,而是完全等同于一个int类型的变量。pt才是指针。
- 数组名:在多数情况下,C++将数组名视为数组的第一个元素的地址。
- 指针算术:C++允许将指针和整数相加。加1的结果等于原来的地址值加上指向的对象占用的总字节数。还可以将一个指针减去另一个指针,获得两个指针的差。后一种运算将得到一个整数,仅当两个指针指向同一个数
组(也可以指向超出结尾的一个位置)时,这种运算才有意义;这将得到两个元素的间隔。 - 数组的动态联编和静态联编:使用数组声明来创建数组时,将采用静态联编,即数组的长度在编译时设置;使用new[]运算符创建数组时,将采用动态联编,即将在运行时为数组分配空间,其长度也在运行时设置。使用完这种数组之后,应使用delete[]释放其占用的内存。
- 数组表示法和指针表示法:stacks[1] 相当于 *(shacks+1)
指针与字符串
char flower[10] = "rose";
cout<<flowe<<"s are red"<<endl;
数组名是第一个元素的地址,因此cout语句中的flower是包含字符r的char元素的地址。cout对象认为char的地址是字符串的地址,因此它打印该地址处的字符,然后继续打印后面的字符,直到遇到空字符(\0)为止。总之,如果给cout提供一个字符的地址,则它将从该字符开始打印,直到遇到空字符为止。
这里的关键不在于flower是数组名,而在于flower是一个char的地址。这意味着可以将指向char的指针变量作为cout的参数,因为它也是char的地址。当然,该指针指向字符串的开头,稍后将核实这一点。
前面的cout语句中最后一部分的情况如何呢?如果flower是字符串第一个字符的地址,则表达式“s are red\n”是什么呢?为了与cout对字符串输出的处理保持一致,这个用引号括起的字符串也应当是一个地址。在C++中,用引号括起的字符串像数组名一样,也是第一个元素的地址。上述代码不会将整个字符串发送给cout,而只是发送该字符串的地址。这意味着对于数组中的字符串、用引号括起的字符串常量以及指针所描述的字符串,处理的方式是一样的,都将传递它们的地址。与逐个传递字符串中的所有字符相比,这样做的工作量确实要少。
🏹在cout和多数C++表达式中,char数组名、char指针以及用引号括起的字符串常量都被解释为字符串第一个字符的地址。
一般来说,如果给cout提供一个指针,它将打印地址。但如果指针的类型为char *,则cout将显示指向的字符串.
ps = new char[strlen(animal)+1];//一种分配空间的好方法
char food[20] = "carrots";
strcpy(food,"flan");
strcpy(food."a picnic basket filled with many goodies")
在这种情况下,函数将字符串中剩余的部分复制到数组后面的内存字节中,这可能会覆盖程序正在使用的其他内存。要避免这种问题,请使用strncpy( )。该函数还接受第3个参数—要复制的最大字符数。然而,要注意的是,如果该函数在到达字符串结尾之前,目标内存已经用完,则它将不会添加空字符。因此,应该这样使用该函数:
strncpy(food."a picnic basket filled with many goodies",19);
food[19] = '\0';
这样最多将19个字符复制到数组中,然后将最后一个元素设置成空字符。如果该字符串少于19个字符,则strncpy( )将在复制完该字符串之后加上空字符,以标记该字符串的结尾。
有时,C++新手在指定结构成员时,搞不清楚何时应使用句点运算符,何时应使用箭头运算符。规则非常简单。如果结构标识符是结构名,则使用句点运算符;如果标识符是指向结构的指针,则使用箭头运算符。
自动存储,静态存储与动态存储
#include <iostream>
#include <cstring>
using namespace std;
char *getname();int main() {char *name;name = getname();cout << name << "at" << (int *)name << endl;delete [] name;
}char *getname() {char temp[80];cout << "Enter your name:";cin >> temp;char *pn = new char[strlen(temp)];strcpy(pn, temp);return pn;
}
根据用于分配内存的方法,C++有3种管理数据内存的方式:自动存储、静态存储和动态存储(有时也叫作自由存储空间或堆)。在存在时间的长短方面,以这3种方式分配的数据对象各不相同。下面简要地介绍每种类型(C++11新增了第四种类型—线程存储)。
自动存储
在函数内部定义的常规变量使用自动存储空间,被称为自动变量(automatic variable),这意味着它们在所属的函数被调用时自动产生,在该函数结束时消亡。例如,程序清单4.22中的temp数组仅当getname( )函数活动时存在。当程序控制权回到main( )时,temp使用的内存将自动被释放。如果getname( )返回temp的地址,则main( )中的name指针指向的内存将很快得到重新使用。这就是在getname( )中使用new的原因之一。
实际上,自动变量是一个局部变量,其作用域为包含它的代码块。代码块是被包含在花括号中的一段代码。到目前为止,我们使用的所有代码块都是整个函数。然而,在下一章将会看到,函数内也可以有代码块。如果在其中的某个代码块定义了一个变量,则该变量仅在程序执行该代码块中的代码时存在。自动变量通常存储在栈中。这意味着执行代码块时,其中的变量将依次加入到栈中,而在离开代码块时,将按相反的顺序释放这些变量,这被称为后进先出(LIFO)。因此,在程序执行过程中,栈将不断地增大和缩小。
静态存储
静态存储是整个程序执行期间都存在的存储方式。使变量成为静态的方式有两种:
- 一种是在函数外面定义它;
- 另一种是在声明变量时使用关键字static:
自动存储和静态存储的关键在于:这些方法严格地限制了变量的寿命。变量可能存在于程序的整个生命周期(静态变量),也可能只是在特定函数被执行时存在(自动变量)。
动态存储
new和delete运算符提供了一种比自动变量和静态变量更灵活的方法。它们管理了一个内存池,这在C++中被称为自由存储空间(free store)或堆(heap)。该内存池同用于静态变量和自动变量的内存是分开的。上述表明,new和delete让您能够在一个函数中分配内存,而在另一个函数中释放它。因此,数据的生命周期不完全受程序或函数的生存时间控制。与使用常规变量相比,使用new和delete让程序员对程序如何使用内存有更大的控制权。然而,内存管理也更复杂了。在栈中,自动添加和删除机制使得占用的内存总是连续的,但new和delete的相互影响可能导致占用的自由存储区不连续,这使得跟踪新分配内存的位置更困难。
栈、堆和内存泄漏
如果使用new运算符在自由存储空间(或堆)上创建变量后,没有调用delete,将发生什么情况呢?
如果没有调用delete,则即使包含指针的内存由于作用域规则和对象生命周期的原因而被释放,在自由存储空间上动态分配的变量或结构也将继续存在。实际上,将会无法访问自由存储空间中的结构,因为指向这些内存的指针无效。这将导致内存泄漏。
被泄漏的内存将在程序的整个生命周期内都不可使用;这些内存被分配出去,但无法收回。极端情况(不过不常见)是,内存泄漏可能会非常严重,以致于应用程序可用的内存被耗尽,出现内存耗尽错误,导致程序崩溃。另外,这种泄漏还会给一些操作系统或在相同的内存空间中运行的应用程序带来负面影响,导致它们崩溃。
即使是最好的程序员和软件公司,也可能导致内存泄漏。要避免内存泄漏,最好是养成
这样一种习惯,即同时使用new和delete运算符,在自由存储空间上动态分配内存,随后便释
放它。C++智能指针有助于自动完成这种任务。
4.8数组的替代品
vector:
vector<typeName> vt(n_elem);
array:
array<typeName,n_elem> arr;
a1[-2] = 20.2; 相当于 *(a1 - 2) = 20.2,这表示找到a1指向的地方,向前移两个double元素,并将20.2存储到目的地。也就是说,将信息存储到数组的外面。与C语言一样,C++也不检查这种超界错误。所以说数组是不安全的。
vector和array对象能够禁止这种行为吗?不能。
但是,如果使用成员函数at(),就能够在运行期间捕获非法索引,而程序默认中断。
总结
- 数组、结构和指针是C++的3种复合类型。数组可以在一个数据对象中存储多个同种类型的值。通过使用索引或下标,可以访问数组中各个元素。
- 结构可以将多个不同类型的值存储在同一个数据对象中,可以使用成员关系运算符(.)来访问其中的成员。使用结构的第一步是创建结构模板,它定义结构存储了哪些成员。模板的名称将成为新类型的标识符,然后就可以声明这种类型的结构变量。
- 共用体可以存储一个值,但是这个值可以是不同的类型,成员名指出了使用的模式。
- 指针是被设计用来存储地址的变量。我们说,指针指向它存储的地址。指针声明指出了指针指向的对象的类型。对指针应用解除引用运算符,将得到指针指向的位置中的值。
- 字符串是以空字符为结尾的一系列字符。字符串可用引号括起的字符串常量表示,其中隐式包含了结尾的空字符。可以将字符串存储在char数组中,可以用被初始化为指向字符串的char指针表示字符串。函数strlen( )返回字符串的长度,其中不包括空字符。函数strcpy( )将字符串从一个位置复制到另一个位置。在使用这些函数时,应当包含头文件cstring或string.h。
- 头文件string支持的C++ string类提供了另一种对用户更友好的字符串处理方法。具体地说,string对象将根据要存储的字符串自动调整其大小,用户可以使用赋值运算符来复制字符串。
- new运算符允许在程序运行时为数据对象请求内存。该运算符返回获得内存的地址,可以将这个地址赋给一个指针,程序将只能使用该指针来访问这块内存。如果数据对象是简单变量,则可以使用解除引用运算符(*)来获得其值;如果数据对象是数组,则可以像使用数组名那样使用指针来访问元素;如果数据对象是结构,则可以用指针解除引用运算符(->)来访问其成员。
- 指针和数组紧密相关。如果ar是数组名,则表达式ar[i]被解释为*(ar + i),其中数组名被解释为数组第一个元素的地址。这样,数组名的作用和指针相同。反过来,可以使用数组表示法,通过指针名来访问new分配的数组中的元素。
- 运算符new和delete允许显式控制何时给数据对象分配内存,何时将内存归还给内存池。自动变量是在函数中声明的变量,而静态变量是在函数外部或者使用关键字static声明的变量,这两种变量都不太灵活。自动变量在程序执行到其所属的代码块(通常是函数定义)时产生,在离开该代码块时终止。静态变量在整个程序周期内都存在。
相关文章:

【C++ Primer Plus】第四章:复合类型
文章目录4.1 数组C11数组初始化的方法4.2 字符串**cin是如何确定已完成字符串输入呢?****如何每次读取一行字符串输入?****面向行的输入:getline()****面向行的输入:get( )****为什么推荐使用get( ),而不是getline( )呢…...

做外贸,你不能不懂的外贸流程知识
报关是履行海关进出境手续的必要环节之一,涉及两大类:进出境运输工具、物品和货物。由于性质不同,报关手续也有些不同。今天我就为大家详细介绍一下进出口报关的流程,包括出口货物报关的流程,随报关单提交的运费和商业单据&#x…...

日本机载激光雷达测深进展(一)日本启动测量90%沿岸水深项目
海洋地图项目利用航空测深绘制日本90%沿海20m以浅区域,是日本海道协会(JHA)和日本财团的一个联合项目。 迄今为止,只有不到2%的日本沿海水域得到了测绘,严重拖累了在海洋事故、防灾减灾、篮碳以及生物多样性保护等领域…...

MySQL数据库调优————创建索引的原则和索引失效及解决方案
创建索引的原则 建议创建索引的场景 select语句,频繁作为where条件的字段update/delete语句的where条件需要分组、排序的字段distinct所使用的字段字段的值有唯一性约束对于多表查询,联接字段应创建索引,且类型无比保持一致 避免隐式转换 …...
设计师都在看的全球设计网站,你居然还不知道!
设计师需要拥有无限的创意和熟练的技巧,并且对行业的前景和客户的心理有一定的了解。要能达到“陌生化”之前,肯定是有知识储备,专业能力的前提要求,以及创新能力。 今天为大家整理了多个优秀全球设计网站,这些博客内…...

c++:缺省参数,函数重载
今天介绍的是cpp中的缺省参数以及函数重载的知识。 首先我们先看看缺省参数: 缺省参数 缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实 参则采用该形参的缺省值,否则使用指定的实参。 例如&#…...
深度学习算法面试常问问题(二)
X86和ARM架构在深度学习侧的区别? X86和ARM架构分别应用于PC端和低功耗嵌入式设备,X86指令集很复杂,一条很长的指令就可以完成很多功能;而ARM指令集很精简,需要几条精简的短指令完成很多功能。 影响模型推理速度的因…...

美国CPC认证是什么?儿童玩具亚马逊CPC认证审核有哪些问题?
很多卖家都有遭遇listing下架,被要求提供CPC认证报告。这是因为亚马逊有时会加强对儿童产品的审查。本文带大家对CPC认证进行一个全面了解。什么是CPC认证?CPC认证,全称ChildrensProductCertification.是认可实验室,根据产品不同适…...

恭喜! SelectDB 五位开发者成为 Apache Doris 新晋 PMC 成员和 Committer!
近期,通过 Apache Doris 项目管理委员会的推荐与投票,Apache Doris 社区正式迎来了 2 位新晋 PMC 成员 和 8 位新晋 Committer 的加入。值得关注的是,2 位新晋 PMC 成员均来自 SelectDB,分别是衣国垒(yiguolei…...
数据库面试题
第一范式(1NF) 第一范式是指数据库的每一列都是不可分割的基本数据项,而下面这样的就存在可分割的情况: 学生(姓名,电话号码) 电话号码实际上包括了家用座机电话和移动电话,因此它…...

[USACO2022-DEC-Bronze] T2 Feeding the Cows 题解
一、题目描述Farmer John has N (1≤N≤10^5) cows, the breed of each being either a Guernsey or a Holstein. They have lined up horizontally with the cows occupying positions labeled from 1…N.Farmer John 有 N(1≤N≤105)头奶牛,…...

Unity法线贴图原理理解(为什么存在切线空间?存的值是什么?)
Unity法线贴图原理理解(为什么存在切线空间?存的值是什么?)写在前面1、为什么用法线贴图?2、用什么存法线?3、法线向量为什么存在切线空间?法线贴图存得是什么?4、法线贴图为什么会偏蓝…...
【JavaWeb】传输层协议——UDP + TCP
目录 UDP协议 UDP协议结构 UDP的特点 TCP协议 TCP协议结构 TCP的特点 TCP的十个核心机制 确认应答 超时重传 连接管理 滑动窗口 流量控制 阻塞控制 延迟应答 捎带应答 粘包问题 异常处理 UDP协议 UDP协议结构 源端口:存储的是发送方的端口号。 目的…...

C++ 中是用来修饰:内置类型变量、自定义对象、成员函数、返回值、函数参数
const 是 constant 的缩写,本意是不变的,不易改变的意思。在 C 中是用来修饰内置类型变量,自定义对象,成员函数,返回值,函数参数。 一. const修饰 普通类型的变量 const int a 7; int b a; // 正确 …...

av 146 002
61. 一个新的敏捷项目经理正试图确定团队该如何执行一个发布计划的进度。哪种工具可以更深入地了解团队的进展? A. 发布计划系统 B. 产品路线图。 C. 看板。 D. 燃尽图 62. 你的项目发起人找到你,让你知道他正在考虑给你项目中的一位高级工程师颁发1000美元的现…...

小红书用户画像 | 小红书数据平台
小红书的用户画像是小红书品牌营销的必备技能,也是小红书推广种草的一个重要前提。通过对小红书用户画像进行分析,对品牌进行精准营销,实现更高的流量转化。 2022小红书粉丝人群画像 千瓜数据在2022年发布的千瓜活跃用户画像趋势报告中分析了…...
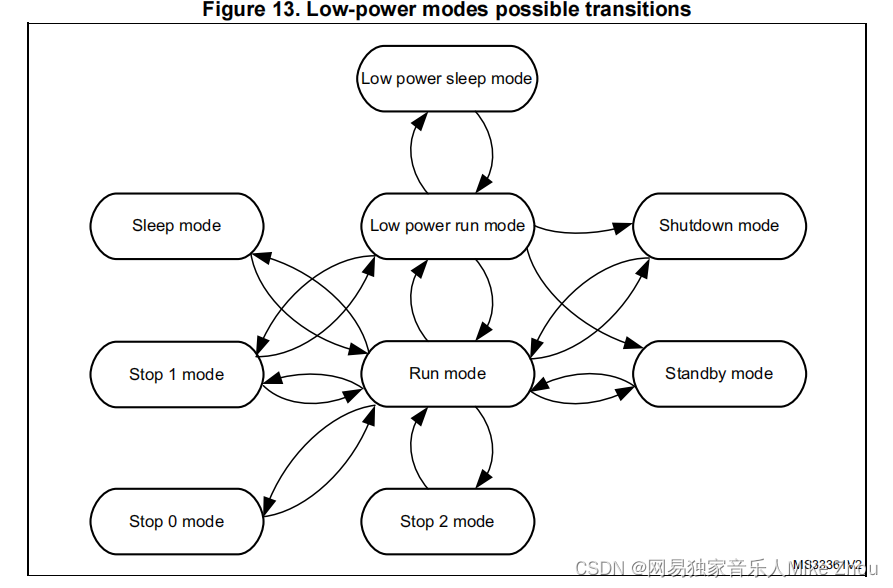
【STM32笔记】低功耗模式下GPIO、外设、时钟省电配置避坑
【STM32笔记】低功耗模式下GPIO、外设、时钟省电配置避坑 前文: blog.csdn.net/weixin_53403301/article/details/128216064 【STM32笔记】HAL库低功耗模式配置(ADC唤醒无法使用、低功耗模式无法烧录解决方案) blog.csdn.net/weixin_534033…...

Linux内存分区(swap)
目录 1、使用物理分区创建内存交换分区 2、使用文件创建内存交换文件 当硬件的设备资源充足的话,那么swap是不会被我们的系统所使用到的,所以swap会被利用到的时刻通常就是物理内存不足的情况 我们知道CPU所读取的数据都来自于内存,那么当…...

第六章——抽样分布
文章目录1、统计量的定义2、常用的统计量3、经验分布函数4、正态总体常用统计量的分布4.1、卡方分布4.1.1、卡方分布的定义4.1.2、卡方分布的性质4.2、t分布4.2.1、t分布的定义4.2.2、t分布的性质4.3、F分布4.3.1、F分布的定义4.3.2、F分布的性质5、正态总体的样本均值与样本方…...
蓝桥云课-声网编程赛(声网编程竞赛7月专场)题解
比赛题目快速链接:https://www.lanqiao.cn/contests/lqENT02/challenges/ 让时钟转起来(考点:css:transform) // index.js function main() {// 题解前理解一个东西:// 时针每过一小时,转30 原…...

OpenClaw 2.6.4 一键部署教程|零代码零基础无需命令快速上手
OpenClaw 是一款可以在本地运行的智能操作工具,能够通过自然语言指令完成电脑自动化操作,无需复杂配置即可快速使用。本文为 Windows 10/11 64 位系统提供完整的一键部署流程,帮助用户快速搭建属于自己的本地智能工具。 适配系统:…...

避坑指南:LabVIEW做3D模型旋转动画时,90%的人会忽略的‘添加对象及引用’模式
LabVIEW 3D模型旋转动画深度解析:从"乱跑"到精准控制的进阶指南 在LabVIEW中创建3D模型旋转动画时,许多开发者都会遇到一个令人困惑的现象:明明只想让模型旋转,结果整个坐标系也跟着"翩翩起舞"。这种看似简单…...

Cursor AI 编程助手配置优化:一键安装与自定义指南
1. 项目概述:为什么需要一套现成的 Cursor 配置?如果你和我一样,是 Cursor 的重度用户,那么你肯定经历过这样的阶段:刚上手时,觉得这个 AI 驱动的 IDE 简直是神器,但随着项目越来越复杂…...

别再只盯着密钥了!深入ESP32 eFuse,看懂flash加密背后的硬件安全逻辑
别再只盯着密钥了!深入ESP32 eFuse,看懂flash加密背后的硬件安全逻辑 当你在ESP32项目中使用flash加密功能时,是否曾疑惑过:为什么简单地烧录几个eFuse位就能实现固件保护?那些看似神秘的DISABLE_DL_DECRYPT、FLASH_CR…...

你的密码正在裸奔!一张RTX 5090,1小时破解60%的MD5密码
网络安全文章 文章目录 网络安全文章前言一、卡巴斯基到底做了什么?1.1 测试环境1.2 测试结果 二、为什么MD5这么脆弱?2.1 MD5设计初衷就不是用来存密码的2.2 MD5 vs bcrypt vs Argon2 对比 三、真实案例:算力平台租卡破解有多便宜࿱…...
)
Abaqus 6.12 保姆级教程:手把手教你搞定悬臂梁的动力学仿真(附阻尼设置与结果动画)
Abaqus 6.12 悬臂梁动力学仿真全流程实战:从阻尼优化到动画渲染 悬臂梁作为结构动力学分析的经典案例,在机械振动、建筑抗震等领域具有广泛的应用价值。本文将基于Abaqus 6.12平台,通过一个完整的动力学仿真案例,深入解析从模型建…...
全量上线及直连 API 体验指南)
AI 绘图新进展:GPTimage2 系列(含 4K 超清版)全量上线及直连 API 体验指南
随着 AIGC(人工智能生成内容)技术的快速迭代,近期备受关注的 GPTimage2 系列模型已全量上线。作为 AI 绘图领域的新晋生力军,GPTimage2 在图像生成质量、细节刻画上展现出了极强的竞争力。特别值得一提的是,本次不仅上…...

告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境
告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境 当你的笔记本风扇开始像喷气发动机一样轰鸣,而PySpark脚本才处理到第3万条数据时,就该考虑换个战场了。去年我用一台16GB内存的MacBook Pro分析800万条电商日志&…...

降AI提示词大全!10个prompt让AI输出人类味+嘎嘎降AI兜底!
降AI提示词大全!10个prompt让AI输出人类味嘎嘎降AI兜底! 用 ChatGPT、DeepSeek、Kimi、豆包写论文最大的痛是:写得快但被检测判 AI、改起来比自己写还累。其实在写作环节就能预防一部分 AI 痕迹,靠的是会写降 AI 提示词。 这篇先给…...

别再乱用STOP模式了!STM32L4三种STOP模式深度对比与选型实战
STM32L4低功耗设计实战:STOP模式选型与能效优化全解析 在物联网终端设备与便携式仪器开发中,每微安电流的节省都直接关系到产品的市场竞争力。最近为一个农业传感器项目做方案评审时,发现团队在STOP模式选择上存在严重误区——工程师们习惯性…...