Hbase
java客户端
导入maven依赖
| XML |
获取hbase的连接,list出所有的表
| Java |
获取到所有的命名空间
| Java |
创建一个命名空间
| Java |
创建带有多列族的表
| Java |
向表中添加数据
| Java |
get表中的数据
| Java |
scan表中的数据
| Java |
删除一行数据
| Java |
原理加强
数据存储
行式存储
传统的行式数据库将一个个完整的数据行存储在数据页中
列式存储
列式数据库是将同一个数据列的各个值存放在一起
| 传统行式数据库的特性如下: 列式数据库的特性如下: |
列族式存储
列族式存储是一种非关系型数据库存储方式,按列而非行组织数据。它的数据模型是面向列的,即把数据按照列族的方式组织,将属于同一列族的数据存储在一起。每个列族都有一个唯一的标识符,一般通过列族名称来表示。它具有高效的写入和查询性能,能够支持极大规模的数据
- 如果一个表有多个列族, 每个列族下只有一列, 那么就等同于列式存储。
- 如果一个表只有一个列族, 该列族下有多个列, 那么就等同于行式存储.
hbase的存储路径:
在conf目录下的hbase-site.xml文件中配置了数据存储的路径在hdfs上
| XML |
region
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。
Region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。
region的分配
一个表中可以包含一个或多个Region。
每个Region只能被一个RS(RegionServer)提供服务,RS可以同时服务多个Region,来自不同RS上的Region组合成表格的整体逻辑视图。
regionServer其实是hbase的服务,部署在一台物理服务器上,region有一点像关系型数据的分区,数据存放在region中,当然region下面还有很多结构,确切来说数据存放在memstore和hfile中。我们访问hbase的时候,先去hbase 系统表查找定位这条记录属于哪个region,然后定位到这个region属于哪个服务器,然后就到哪个服务器里面查找对应region中的数据
Memstore Flush流程
flus流程分为三个阶段:
- prepare阶段:遍历当前 Region中所有的 MemStore ,将 MemStore 中当前数据集 CellSkpiListSet 做一个快照 snapshot;然后再新建一个 CellSkipListSet。后期写入的数据都会写入新的 CellSkipListSet 中。prepare 阶段需要加一把 updataLock 对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此锁持有时间很短
- flush阶段:遍历所有 MemStore,将 prepare 阶段生成的snapshot 持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘 IO 操作,因此相对耗时
- commit阶段:遍历所有 MemStore,将flush阶段生成的临时文件移动到指定的 ColumnFamily 目录下,针对 HFile生成对应的 StoreFile 和 Reader,把 StoreFile 添加到 HStore 的 storefiles 列表中,最后再清空 prepare 阶段生成的 snapshot快照
Compact 合并机制
hbase中的合并机制分为自动合并和手动合并
自动合并:
- minor compaction 小合并
- major compacton 大合并
minor compaction(小合并)
将 Store 中多个 HFile 合并为一个相对较大的 HFile 过程中会选取一些小的、相邻的 StoreFile 将他们合并成一个更大的 StoreFile,对于超过 TTL 的数据、更新的数据、删除的数据仅仅只是做了标记,并没有进行物理删除。一次 minor compaction 过后,storeFile会变得更少并且更大,这种合并的触发频率很高
小合并的触发方式:
memstore flush会产生HFile文件,文件越来越多就需要compact.每次执行完Flush操作之后,都会对当前Store中的文件数进行判断,一旦文件数大于配置3,就会触发compaction。compaction都是以Store为单位进行的,而在Flush触发条件下,整个Region的所有Store都会执行compact
后台线程周期性检查
检查周期可配置:
hbase.server.thread.wakefrequency/默认10000毫秒)*hbase.server.compactchecker.interval.multiplier/默认1000
CompactionChecker大概是2hrs 46mins 40sec 执行一次
| XML |
major compaction(大合并)
合并 Store 中所有的 HFile 为一个 HFile,将所有的 StoreFile 合并成为一个 StoreFile,这个过程中还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空间时间手动触发。一般是可以手动控制进行合并,防止出现在业务高峰期。
| XML |
手动合并
一般来讲,手动触发compaction通常是为了执行major compaction,一般有这些情况需要手动触发合并是因为很多业务担心自动maior compaction影响读写性能,因此会选择低峰期手动触发也有可能是用户在执行完alter操作之后希望立刻生效,执行手动触发maiorcompaction:
造数据
| Shell |
| Shell |
region的拆分
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,已达到负载均衡 , 这也是HBase的一个优点
1region的拆分策略
1. ConstantSizeRegionSplitPolicy:0.94版本前,HBase region的默认切分策略
| 当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。 但是在生产线上这种切分策略却有相当大的弊端(切分策略对于大表和小表没有明显的区分):
|
2. IncreasingToUpperBoundRegionSplitPolicy:0.94版本~2.0版本默认切分策略
| 总体看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大的store大小大于设置阈值就会触发切分。 但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系. region split阈值的计算公式是:
例如:
特点
|
3. SteppingSplitPolicy:2.0版本默认切分策略
| 相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些 region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系
这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。 |
4. KeyPrefixRegionSplitPolicy
| 根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中 |
5. DelimitedKeyPrefixRegionSplitPolicy
| 保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。 按照分隔符进行切分,而KeyPrefixRegionSplitPolicy是按照指定位数切分 |
6. BusyRegionSplitPolicy
| 按照一定的策略判断Region是不是Busy状态,如果是即进行切分 如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个 |
7. DisabledRegionSplitPolicy:不启用自动拆分, 需要指定手动拆分
手动合并拆分egion
手动合并
| Shell |
手动拆分
| Shell |
bulkLoad实现批量导入
bulkloader : 一个用于批量快速导入数据到hbase的工具/方法
用于已经存在一批巨量静态数据的情况!如果不用bulkloader工具,则只能用rpc请求,一条一条地通过rpc提交给regionserver去插入,效率极其低下
相比较于直接写HBase,BulkLoad主要是绕过了写WAL日志这一步,还有写Memstore和Flush到磁盘,从理论上来分析性能会比Put快!
BulkLoad实战示例1:importTsv工具
原理:
Importtsv是hbase自带的一个 csv文件--》HFile文件 的工具,它能将csv文件转成HFile文件,并发送给regionserver。它的本质,是内置的一个将csv文件转成hfile文件的mr程序!
案例演示:
| Shell |
| ImportTsv命令的参数说明如下: -Dimporttsv.skip.bad.lines=false - 若遇到无效行则失败 -Dimporttsv.separator=, - 使用特定分隔符,默认是tab也就是\t -Dimporttsv.timestamp=currentTimeAsLong - 使用导入时的时间戳 -Dimporttsv.mapper.class=my.Mapper - 使用用户自定义Mapper类替换TsvImporterMapper -Dmapreduce.job.name=jobName - 对导入使用特定mapreduce作业名 -Dcreate.table=no - 避免创建表,注:如设为为no,目标表必须存在于HBase中 -Dno.strict=true - 忽略HBase表列族检查。默认为false -Dimporttsv.bulk.output=/user/yarn/output 作业的输出目录 |
示例演示:
| Plain Text |
相关文章:

Hbase
java客户端 导入maven依赖 XML<dependencies> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.6</version> </dependency>…...
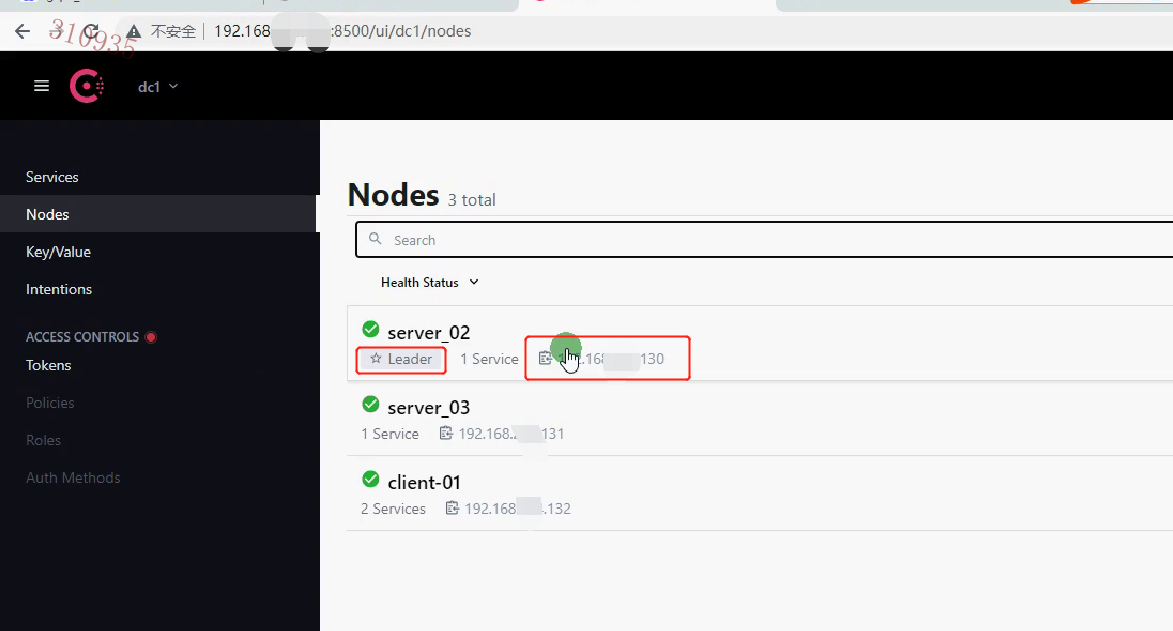
[golang 微服务] 5. 微服务服务发现介绍,安装以及consul的使用,Consul集群
一.服务发现介绍 引入 上一节讲解了使用 gRPC创建微服务,客户端的一个接口可能需要调用 N个服务,而不同服务可能存在 不同的服务器,这时,客户端就必须知道所有服务的 网络位置(ipport),来进行连接服务器操作,如下图所示: 以往的做…...

【数据结构】哈希应用
目录 一、位图 1、位图概念 2、位图实现 2.1、位图结构 2.2、比特位置1 2.3、比特位置0 2.4、检测位图中比特位 3、位图例题 3.1、找到只出现一次的整数 3.2、找到两个文件交集 3.3、找到出现次数不超过2次的所有整数 二、布隆过滤器 1、布隆过滤器提出 2、布隆过…...
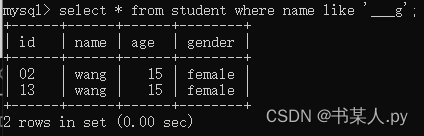
【 Python 全栈开发 - WEB开发篇 - 31 】where条件查询
文章目录 一、where条件查询1.关系运算符查询2.IN关键字查询3.BETWEEN AND关键字查询4.空值查询5.AND关键字查询6.OR关键字查询7.LIKE关键字查询普通字符串含有%通配的字符串含有_通配的字符串 一、where条件查询 MySQL 的 where 条件查询是指在查询数据时,通过 wh…...

Android系统的Ashmem匿名共享内存子系统分析(5)- 实现共享的原理
声明 其实对于Android系统的Ashmem匿名共享内存系统早就有分析的想法,记得2019年6、7月份Mr.Deng离职期间约定一起对其进行研究的,但因为我个人问题没能实施这个计划,留下些许遗憾…文中参考了很多书籍及博客内容,可能涉及的比较…...

谈一谈冷门的C语言爬虫
C语言可以用来编写爬虫程序,但是相对于其他编程语言,C语言的爬虫开发可能会更加复杂和繁琐。因为C语言本身并没有提供现成的爬虫框架和库,需要自己编写网络请求、HTML解析等功能。 不过,如果你对C语言比较熟悉,也可以…...

基于状态的维护(CBM)如何推动设备效率提高?
基于状态的维护(Condition-Based Maintenance,CBM)是一种先进的维护策略,通过实时监测和分析设备的状态数据,预测设备故障并采取相应的维护措施。CBM基于数据驱动的方法,能够提高设备的可用性、降低维修成本…...
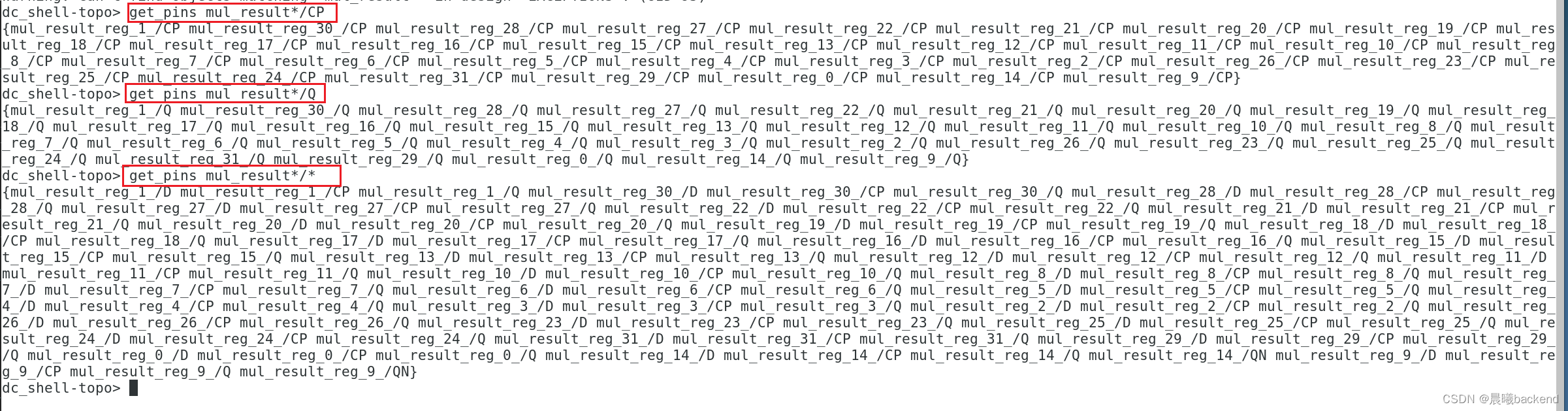
DC LAB8SDC约束四种时序路径分析
DC LAB 1.启动DC2.读入设计3. 查看所有违例的约束报告3.1 report_constraint -all_violators (alias rc)3.2 view report_constraint -all_violators -verbose -significant_digits 4 (打印详细报告) 4.查看时序报告 report_timing -significant_digits 45. 约束组合逻辑(adr_i…...

学生考试作弊检测系统 yolov8
学生考试作弊检测系统采用yolov8网络模型人工智能技术,学生考试作弊检测系统过在考场中安装监控设备,对学生的作弊行为进行实时监测。当学生出现作弊行为时,学生考试作弊检测系统将自动识别并记录信息。YOLOv8 算法的核心特性和改动可以归结为…...

【基于容器的部署、扩展和管理】 3.2 基于容器的应用程序部署和升级
往期回顾: 第一章:【云原生概念和技术】 第二章:【容器化应用程序设计和开发】 第三章:【3.1 容器编排系统和Kubernetes集群的构建】 3.2 基于容器的应用程序部署和升级 3.2 基于容器的应用程序部署和升级 3.2 基于容器的应用程…...

Jmeter 实现 grpc服务 压测
一、Jmeter安装与配置 网上有很多安装与配置文章,在此不做赘述 二、Jmeter gRPC Request 插件安装 插件下载地址:JMeter Plugins :: JMeter-Plugins.org 将下载文件解压后放到Jmeter安装目录下 /lib/ext 然后在终端输入Jmeter即可打开 Jmeter GUI界面…...
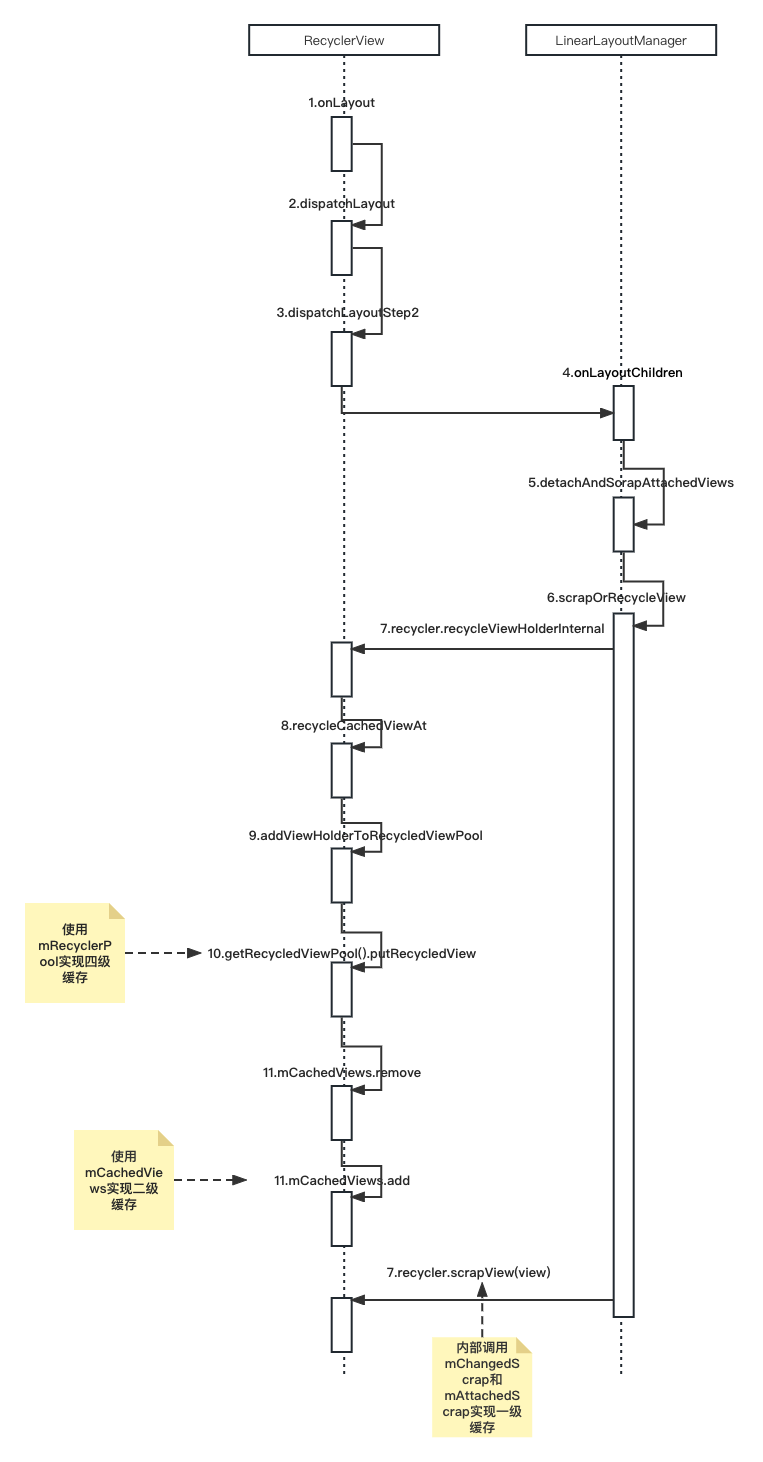
深入源码分析RecyclerView缓存复用原理
文章目录 前言四级缓存 源码分析缓存一级缓存(mChangedScrap和mChangedScrap)二级缓存(mCachedViews)三级缓存(ViewCacheExtension)四级缓存(mRecyclerPool)缓存池mRecyclerPool结构…...

内网隧道代理技术(一)之内网隧道代理概述
内网隧道代理技术 内网转发 在渗透测试中,当我们获得了外网服务器(如web服务器,ftp服务器,mali服务器等等)的一定权限后发现这台服务器可以直接或者间接的访问内网。此时渗透测试进入后渗透阶段,一般情况…...

设计图形用户界面的原则
1) 一般性原则:界面要具有一致性、常用操作要有快捷方式、 提供简单的错误处理、对操作人员的重要操作要有信息反馈、操作可 逆、设计良好的联机帮助、合理划分并高效地使用显示屏、保证信息 显示方式与数据输入方式的协调一致 2) 颜色的使用:颜色…...

1:操作系统导论
1.1操作系统的定义 •Anoperatingsystemactsanintermediarybetweenuserofacomputerandthecomputer hardware. ◦ 操作系统充当计算机⽤⼾和计算机硬件之间的中介 •Thepurposeofanoperatingsystemistoprovideanenvironmentinwhichausercanexecute programsinaconvenientandeff…...

什么是微软的 Application Framework?
我是荔园微风,作为一名在IT界整整25年的老兵,今天来看一下什么是微软的 Application Framework? 到底什么是 Application Framework? 还没有真正掌握任何一套Application Framework的使用之前,就来研究这个真的不是很…...

一个关于宏定义的问题,我和ChatGPT、NewBing、Google Bard、文心一言 居然全军覆没?
文章目录 一、问题重述二、AI 解题2.1 ChatGPT2.2 NewBing2.3 Google Bard2.4 文心一言2.5 小结 一、问题重述 今天在问答模块回答了一道问题,要睡觉的时候,又去看了一眼,发现回答错了。 问题描述:下面的z的值是多少。 #define…...

【服务器数据恢复】断电导致RAID无法找到存储设备的数据恢复案例
服务器数据恢复环境: HP EVA存储,6块SAS硬盘组建的raid5磁盘阵列。上层操作系统是WINDOWS SERVER。该存储为公司内部文件服务器使用。 服务器故障&分析: 在遭遇两次意外断电后,设备重启时raid提示“无法找到存储设备”。管理员…...
Windows上不可或缺的5款宝藏软件,工作效率拉满!
职场小白与大牛的区别:小白需要耗费大半天琢磨的事情,而大牛可以只花5分钟就能处理。 “牛人”,即拥有过人之处,专业、经验、技术等等,学会灵活运用高效率的工具也是关键的一点。工具找得好,运用得快&#…...
链表内指定区间反转
题目: 将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转,要求时间复杂度 O(n),空间复杂度 O(1)。 例如: 给出的链表为 1→2→3→4→5→NULL,m2,n4 返回 1→4→3→2→5→NULL 数据范围ÿ…...

终极D2DX指南:让《暗黑破坏神2》在现代电脑上焕发新生
终极D2DX指南:让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经典…...

2026春招爆款!年薪40-200万!小白也能入行的智能体开发,收藏这篇超全学习指南!
本文详细介绍了智能体(Agent)的概念、核心能力及工作流程,分析了为何智能体开发成为2026年春招热门岗位,薪资可达40-200万。文章强调其转型门槛低、学习周期短,适合小白入行。同时,提供了智能体开发的核心技…...

Python爬虫实战:手把手教你如何采集开源许可证 FAQ 文章归档!
㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~ ㊙️本期爬虫难度指数:⭐⭐ (中级) 🉐福利: 一次订阅后,专栏内的所有文章…...

3步掌握清华PPT模板:终极方案解决学术演示设计难题
3步掌握清华PPT模板:终极方案解决学术演示设计难题 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为学术汇报PPT设计而苦恼吗?每次准备答辩、会议或教学演示,你都要…...
)
告别Hello World!手把手教你用OllyDBG修改exe程序字符串(附完整操作截图)
逆向工程第一课:用OllyDBG实战修改程序字符串全流程 刚接触逆向工程的新手往往会被各种复杂工具和概念吓退。今天我们从最基础的字符串修改入手,用OllyDBG带你完成第一个逆向实战。不同于简单的"Hello World"打印,这次我们要直接修…...

从零到一:手把手教你完成Matlab R2020a的下载、安装与激活【避坑指南】
1. 准备工作:下载与系统检查 第一次安装Matlab的朋友们可能会被复杂的流程吓到,但别担心,跟着我的步骤走绝对没问题。我去年给实验室十几台电脑装过R2020a版本,踩过的坑比你们见过的都多。首先咱们得准备好安装包,这里…...

保姆级对比:ESP32 vs ESP8266,在ROS Melodic/Noetic下谁的WiFi通信更稳?实测代码分享
ESP32与ESP8266在ROS环境下的WiFi通信深度评测:从硬件差异到实战优化 1. 硬件架构与性能基准 当我们将ESP32和ESP8266这两款WiFi模块置于ROS机器人开发环境中对比时,首先需要理解它们的硬件设计差异如何影响实际性能表现。ESP32采用双核Xtensa LX6架构&a…...

Blender 3MF插件:终极3D打印工作流解决方案
Blender 3MF插件:终极3D打印工作流解决方案 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 在3D打印的世界里,你是否曾为文件格式转换而头疼&…...
中国医学科学院阜外医院放射科赵世华教授等团队:连续心肌纤维化评估预测肥厚型心肌病患者预后)
JACC Cardiovasc Imaging(IF=15.2)中国医学科学院阜外医院放射科赵世华教授等团队:连续心肌纤维化评估预测肥厚型心肌病患者预后
01文献学习今天分享的文献是由中国医学科学院阜外医院放射科赵世华教授等团队于2026年2月在《JACC: Cardiovascular Imaging》(中科院1区top,IF15.2)上发表的研究“Serial Myocardial Fibrosis Assessments Predict Outcomes in Patients Wit…...

支付钱包启动器:架构设计与工程实践全解析
1. 项目概述:一个面向开发者的支付钱包启动器 最近在和一些做独立开发的朋友聊天,发现大家在做项目时,但凡涉及到支付、钱包这类功能,都挺头疼的。不是对接流程繁琐,就是安全风险高,要么就是代码耦合度太强…...