7. user-Agent破解反爬机制
文章目录
- 1. 为什么要设置反爬机制
- 2. 服务器如何区分浏览器访问和爬虫访问
- 3. 反爬虫机制
- 4. User-Agent是什么
- 5. 如何查询网页的User-Agent
- 6. user-agent信息解析
- 7. 爬虫程序user-agent和浏览器user-agent的区别
- 8. 代码查看爬虫程序的user-agent
- 9. 在代码中加入请求头信息
1. 为什么要设置反爬机制
普通用户通过浏览器访问网站。
爬虫是靠程序代码来访问网站。
爬虫程序可能会篡改资源信息。
爬虫程序会引发短时间内的访问激增。
导致服务器压力过大。
为了提高安全性,因此绝大多数网站都实施了反爬措施,对爬虫程序进行拦截。
【总结】
设置反爬机制是为了保护网站的数据和资源不被恶意爬虫或者机器人滥用和攻击。
恶意爬虫或机器人可能会对网站造成严重的影响,如消耗网站的带宽和服务器资源、盗取网站的数据、影响网站的正常运行等。
因此,为了保护网站的安全和稳定性,设置反爬机制是必要的。
同时,反爬机制也可以防止竞争对手通过爬虫获取网站的商业机密和竞争优势。
2. 服务器如何区分浏览器访问和爬虫访问
服务器可以通过多种方式来识别是人手动访问网站还是爬虫程序访问网站。
-
User-Agent:每个浏览器或爬虫程序都有一个User-Agent标识,服务器可以通过检查User-Agent来判断访问者是人还是爬虫程序。
-
IP地址:服务器可以通过检查访问者的IP地址来判断是否是爬虫程序。一些爬虫程序使用大量的IP地址进行访问,而人类用户通常只使用一个或几个IP地址。
-
访问频率:爬虫程序通常会以非常高的频率访问网站,而人类用户通常不会如此频繁地访问网站。服务器可以通过检查访问频率来判断是否是爬虫程序。
-
访问行为:爬虫程序通常会按照一定的规律进行访问,例如按照页面顺序进行访问或者按照特定的关键词进行搜索。服务器可以通过检查访问行为来判断是否是爬虫程序。
3. 反爬虫机制
所谓上有政策,下有对策。
服务器可以通过多种方式来识别是人手动访问网站还是爬虫程序访问网站,但是一些高级的爬虫程序可以模拟人类用户的行为,使得服务器难以区分。
Python的反爬虫机制主要包括以下几种:
-
User-Agent检测:有些网站会检测请求头中的User-Agent字段,如果发现是Python的默认User-Agent,就会拒绝访问。解决方法是在请求头中添加一个随机的User-Agent。
-
IP封禁:有些网站会根据IP地址来限制访问频率或者直接封禁IP。解决方法是使用代理IP或者使用分布式爬虫。
-
验证码识别:有些网站会在登录或者访问频率过高时出现验证码,需要手动输入才能继续访问。解决方法是使用第三方验证码识别服务或者手动输入验证码。
-
访问频率限制:有些网站会限制同一IP或同一用户的访问频率,如果超过一定次数就会拒绝访问。解决方法是控制访问频率或者使用分布式爬虫。
-
动态页面爬取:有些网站使用了动态页面技术,需要使用Selenium等工具模拟浏览器行为才能爬取。
4. User-Agent是什么
User-Agent是一个HTTP头部字段,用于标识发送HTTP请求的客户端应用程序或设备的信息。
它通常包含了操作系统、浏览器、设备类型、应用程序版本等信息,以便服务器能够根据这些信息来优化响应内容或提供适当的服务。
例如,网站可以根据User-Agent识别访问者使用的设备类型和浏览器版本,从而提供适合的网页布局和功能。
User[ˈjuːzə]:用户。
Agent[ˈeɪdʒənt]:代理人。
User-Agent用户代理,简称UA。
无论是浏览器发出的请求,还是爬虫发出的请求,都会包含请求头。
请求头里有一个非常重要的信息,User-Agent。
5. 如何查询网页的User-Agent
-
打开360浏览器。
-
按【F12】打开开发者工具。
-
点击【网络】选项卡。
-
点击【全部】选项卡。
-
【Ctrl+R】刷新网页。
-
点击【名称】下方的内容。
-
点击【标头】。
-
向下滑动鼠标,找到【请求标头】。

-
【请求标头】的最后一项信息就是【user-agent】
-
将整个【user-agent】复制到文件(doc或txt或py文件等等都可以)来备用。

6. user-agent信息解析
user-agent中包含许多信息,用户使用的操作系统、CPU类型、浏览器版本等等。
【复制的user-agent内容如下】
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE
【user-agent信息解析如下】
操作系统:Windows NT 10.0
- CPU 架构:WOW64
- 浏览器内核:AppleWebKit/537.36
- 浏览器类型:Chrome
- 浏览器版本:108.0.5359.95
- 浏览器标识:Safari/537.36
- 来源:QIHU 360SE解析
在每次浏览器发送请求的时候,UA字符串都会被发送到服务器上。
服务器会根据UA信息,显示不同的网页排版,以适应不同的用户浏览器。
同时,服务器还可以通过UA信息,侦察客户端的请求是否安全。
判断请求访问的是爬虫程序还是普通用户。
7. 爬虫程序user-agent和浏览器user-agent的区别
爬虫程序里的user-agent和浏览器里的user-agent的主要不同在于:
-
目的不同:浏览器的user-agent是为了告诉服务器它所使用的浏览器类型和版本,以便服务器能够返回适合该浏览器的网页内容;而爬虫程序的user-agent是为了模拟浏览器行为,以便获取网页内容。
-
内容不同:浏览器的user-agent通常包含浏览器类型、版本、操作系统类型和版本等信息;而爬虫程序的user-agent通常只包含爬虫程序的名称和版本号等信息。
-
格式不同:浏览器的user-agent通常是一个字符串,包含多个信息,格式比较复杂;而爬虫程序的user-agent通常是一个简单的字符串,格式比较简单。
8. 代码查看爬虫程序的user-agent
我们通过一个测试网站来查看爬虫程序的user-agent的包含的信息。
【测试网站】
url = "http://httpbin.org/get"
【代码示例】
# 1.导入库
# requests是第三方库,作用是发送发送GET、POST、PUT、DELETE等请求
import requests# 2.要访问的url
url = "http://httpbin.org/get"# 3.发送请求,并把响应结果赋值给变量r
r = requests.get(url) # 输出r的文本信息
print(r.text)
【终端输出】
{"args": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.26.0", "X-Amzn-Trace-Id": "Root=1-6482e247-021e317204e5813568df0582"}, "origin": "112.113.185.64", "url": "http://httpbin.org/get"
}
上面输出的结果就爬虫程序里包含的user-agent。
观察输出结果,看到打印出来的 User-Agent的信息标志的是python-requests/2.26.0。
信息里没有操作系统,也没有浏览器版本。
所以我们通过上面的代码访问网页,服务器是能识别出是爬虫代码在访问,而不是人工在访问。
这样的User-Agent会被反爬机制轻易拦截。
既然爬虫程序是因为User-Agent被识别出来的。
那解决这个问题,我们只需要把爬虫的User-Agent伪装成浏览器请求头里的User-Agent即可。
狼怎么伪装成羊呢?
狼可以用毛皮或其他材料制作成羊的外表。
披着羊皮的狼,和爬虫程序加入请求头信息(User-Agent)就是一个道理。
9. 在代码中加入请求头信息
requests库的get方法提供了headers参数。
headers:请求头。
headers参数的类型是字典。
headers参数的类型是字典。
headers参数的类型是字典。
作用是接收自定义的请求头。
【初学者可以这样构建请求头信息】
- 先构建一个字典
header = {}
header是变量名。
{}表示字典。
- 在大括号中间输入【回车】,输入
'':''字符,准备好字典的框架。
header = {'':''
}
这里添加引号是因为这里字典的键和值都是字符串类型。
- 填充字典的键和值。
header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) +\AppleWebKit/537.36 (KHTML, like Gecko)+\Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'
}
user-agent是字典的键。
后面的具体信息作为值。
因为请求头字符多,字典格式很多初学者掌握的不熟练,复制请求头信息时太容易出错了。
初学者用上面的方法可以避免出错。
然后在requests发送请求时将请求头信息及header变量作为值传递给get函数的参数headers。
r = requests.get(url,headers = header )
headers是get函数的参数,是不可以换成其他名字的。
header是存储请求头信息的变量名,名字你可以自己命名。
【测试加入请求头的user-agent】
# 1.导入库
# requests是第三方库,作用是发送发送GET、POST、PUT、DELETE等请求
import requests# 2.要访问的url,这个是测试网址
url = "http://httpbin.org/get"# 3. 浏览器的请求头信息
header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) +\AppleWebKit/537.36 (KHTML, like Gecko)+\Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'
}# 4.发送请求,并把响应结果赋值给变量r
r = requests.get(url, headers= header ) # 5. 输出r的文本信息
print(r.text)
【终端输出】
{"args": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE", "X-Amzn-Trace-Id": "Root=1-648348bd-2aadd11662bf3bad3c052f78"}, "origin": "112.113.185.64", "url": "http://httpbin.org/get"
}
大家观察输出结果。
【添加 "User-Agent"访问网页服务器识别的 "User-Agent"是下面这样的】
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE”,
【没有 "User-Agent"访问网页服务器识别的 "User-Agent"是下面这样的】
“User-Agent”: “python-requests/2.26.0”
我们发现通过添加User-Agent我们将爬虫程序的请求头伪装成功了。
添加一个字典变量,我们成功的将狼伪装成了羊。
下面,我们以访问百度网页为例,写一个带请求头的访问网页代码。
【代码示例】
# 1.导入库
# requests是第三方库,作用是发送发送GET、POST、PUT、DELETE等请求
import requests# 2.要访问的url
url = 'https://www.baidu.com/'# 3. 浏览器的请求头信息
header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) +\AppleWebKit/537.36 (KHTML, like Gecko) +\Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'
}# 4.发送请求,并把响应结果赋值给变量r
r = requests.get(url, headers= header ) # 5.输出Response对象的status_code属性
print(r.status_code)# 6. 查看r的类型
print(type(r))
【终端输出】
200
<class 'requests.models.Response'>
200表示访问网页成功。
<class 'requests.models.Response'>表示返回的r是一个requests.models类的响应对象。
相关文章:
7. user-Agent破解反爬机制
文章目录 1. 为什么要设置反爬机制2. 服务器如何区分浏览器访问和爬虫访问3. 反爬虫机制4. User-Agent是什么5. 如何查询网页的User-Agent6. user-agent信息解析7. 爬虫程序user-agent和浏览器user-agent的区别8. 代码查看爬虫程序的user-agent9. 在代码中加入请求头信息 1. 为…...

3.Nginx+Tomcat负载均衡和动静分离群集
文章目录 NginxTomcat负载均衡和动静分离群集Nginx作用实验七层反向代理nginx动静分离四层反向代理负载均衡 NginxTomcat负载均衡和动静分离群集 Nginx是-款非常优秀的HTTP服务器软件 支持高达50 000个并发连接数的响应拥有强大的静态资源处理能力运行稳定内存、CPU等系统资源…...
数据结构与算法之树结构
目录 为什么要使用树结构树结构基本概念树的种类树的存储与表示常见的一些树的应用场景为什么要使用树结构 线性结构中不论是数组还是链表,他们都存在着诟病;比如查找某个数必须从头开始查,消耗较多的时间。使用树结构,在插入和查找的性能上相对都会比线性结构要好 树结构…...

【python】 用来将对象持久化的 pickle 模块
pickle 模块可以对一个 Python 对象的二进制进行序列化和反序列化。说白了,就是它能够实现任意对象与二进制直接的相互转化,也可以实现对象与文本之间的相互转化。 比如,我程序里有一个 python 对象,我想把它存到磁盘里ÿ…...

【博客654】prometheus配置抓取保护以防止压力过载
prometheus抓取保护配置以防止压力过载 场景 担心您的应用程序指标可能突然激增,以及指标突然激增导致prometheus压力过载 就像生活中的许多事情一样,标签要有节制。当带有用户 ID 或电子邮件地址的标签被添加到指标时,虽然它不太可能结束…...

Backtrader官方中文文档:第十三章Observers观察者
本文档参考backtrader官方文档,是官方文档的完整中文翻译,可作为backtrader中文教程、backtrader中文参考手册、backtrader中文开发手册、backtrader入门资料使用。 本章包含 backtrader 官方Observers章节全部内容,入口 : https://backtrader.com/docu/observers-and-sta…...

算法leetcode|54. 螺旋矩阵(rust重拳出击)
文章目录 54. 螺旋矩阵:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java:每次循环移动一步:每次循环完成一个顺时针:…...
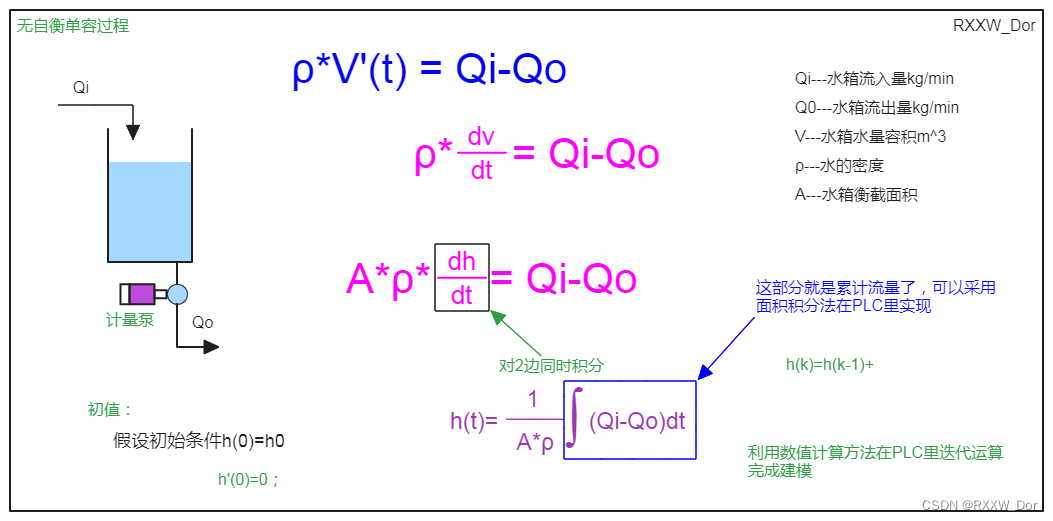
单容水箱建模(自衡单容水箱+无自衡单容水箱)
自衡单容水箱Simulink建模和PLC源代码请参看下面文章链接: 单容双容水箱建模(simulink仿真+PLC代码)_RXXW_Dor的博客-CSDN博客PLC通过伯努利方程近似计算水箱流量详细内容请参看下面的文章博客PLC通过伯努利方程近似计算水箱流量(FC)_怎么用伯努利方程求某水位流量_RXXW_Dor的…...
分享Python7个爬虫小案例(附源码)
本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。注:若涉及到版权或隐私问题,请及时联系我删除即可。 1.使用正则表达式和文件操作爬取并保存“某吧”某帖子…...

我用ChatGPT写2023高考语文作文(一):全国甲卷
2023年 全国甲卷 适用地区:广西、贵州、四川、西藏 人们因技术发展得以更好地掌控时间,但也有人因此成了时间的仆人。 这句话引发了你怎样的联想与思考?请写一篇文章。 要求:选准角度,确定立意,明确文体&am…...

c++ modbusTCP
//Modbus TCP是一种基于TCP/IP协议的Modbus协议,它允许Modbus协议通过以太网进行通信。 //在C中,可以使用第三方库来实现Modbus TCP通信,例如libmodbus和QModbus。 //使用libmodbus库实现Modbus TCP通信的示例代码如下: //c #incl…...
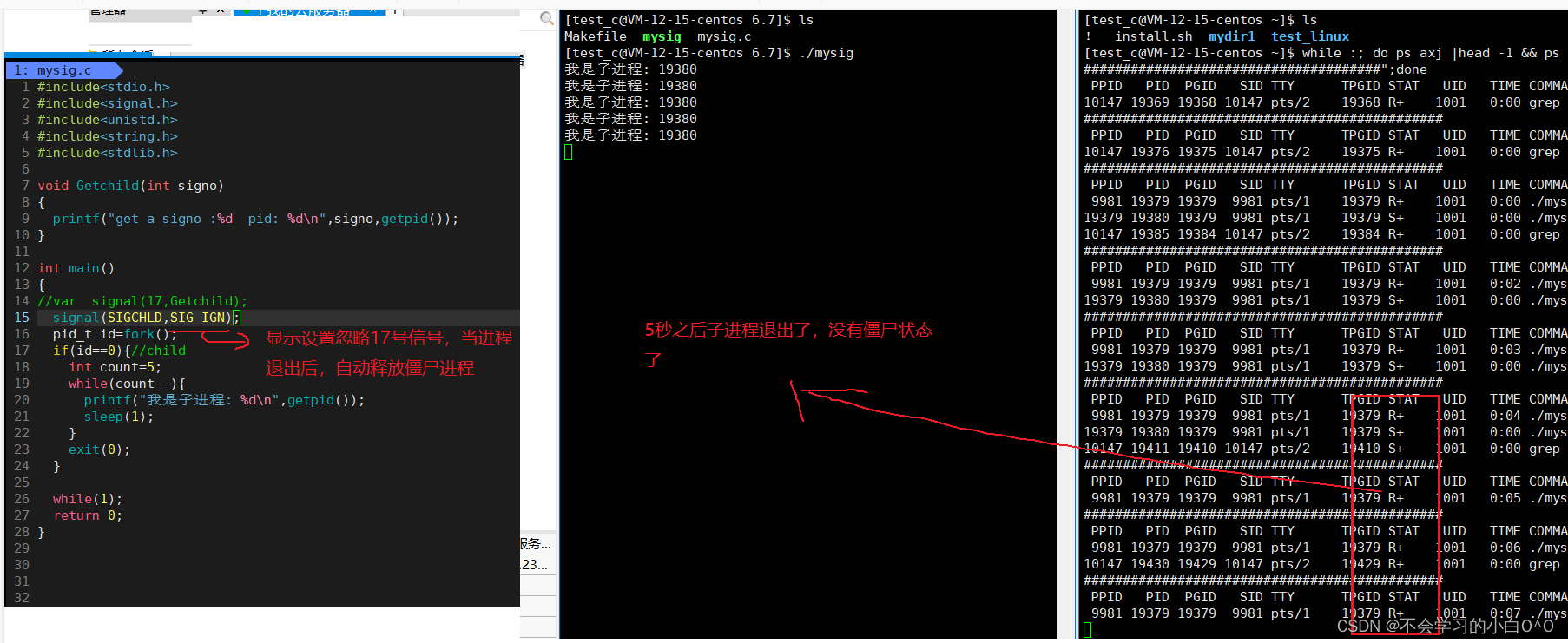
linux(信号结尾)
目录: 1.可重入函数 2.volatile关键字 3.SIGCHLD信号 -------------------------------------------------------------------------------------------------------------------------------- 1.可重入函数----------用来描述一个函数的特点的 1.在单进程当中也存…...
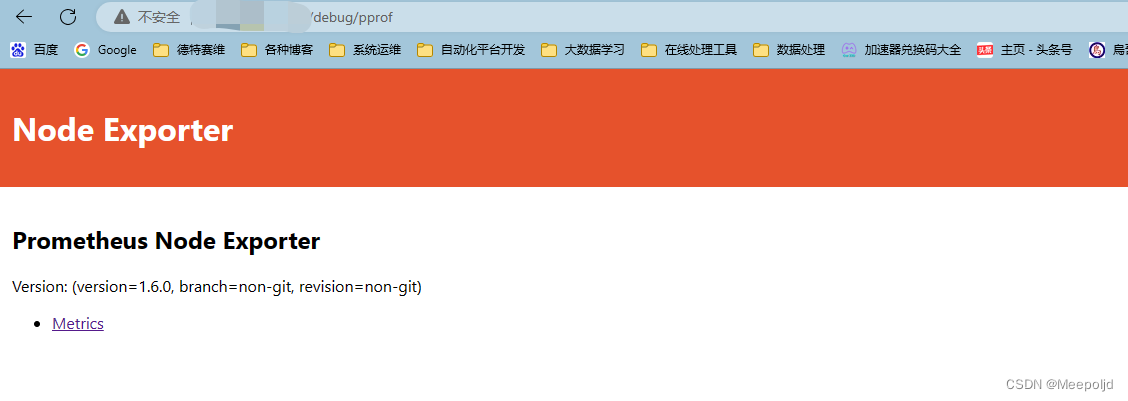
【漏洞修复】node-exporter被检测出来pprof调试信息泄露漏洞
node-exporter被检测出来pprof调试信息泄露漏洞 说在前面解决方法结语 说在前面 惯例开篇吐槽,有些二五仔习惯搞点自研的安全扫描工具,然后加点DIY元素,他也不管扫的准不准,就要给你报个高中危的漏洞,然后就要去修复&…...

在linux 上安装 NFS服务器软件
在 Ubuntu Linux 中创建 NFS 文件系统通常需要完成以下步骤: 安装 NFS 服务器软件。您可以在终端上使用以下命令来安装所需的软件包。sudo apt-get update sudo apt-get install nfs-kernel-server创建要共享的目录。例如,您可以创建一个名为 /var/nfs/shared 的目录。sudo m…...
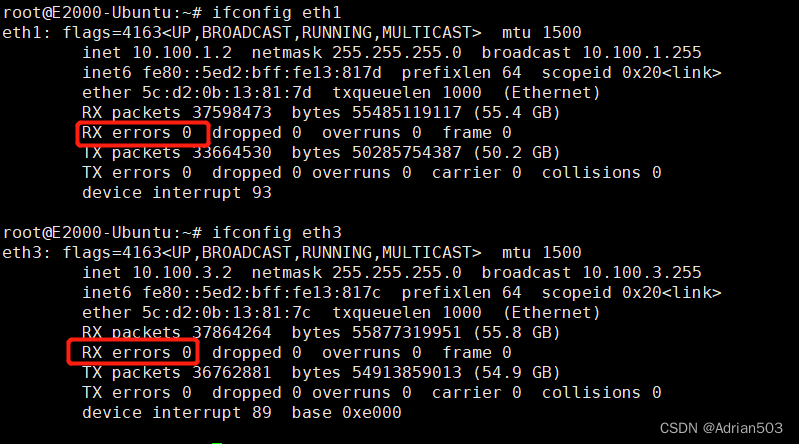
网卡中的Ring buffer -- 解决 rx_resource_errors 丢包
1、软硬件环境 硬件: 飞腾E2000Q 平台 软件: linux 4.19.246 2、问题现象 网卡在高速收包的过程中,出现 rx error , 细查是 rx_resource_errors 如下: rootE2000-Ubuntu:~# ifconfig eth1 eth1: flags4163<UP,BROADCAST,RU…...
)
六月九号补题日记:Codeforces Round 877 (Div. 2)
专注是不够的,很重要的一方面在于细节,关注细节:精细和专注才是成功的重点!!! A 题意:给你一堆数字,说这一堆数字是由最初的两个数字相减得到的,让你求出两个数字其中一…...

python基础选择题,高中适用
1. 下面哪个是 Python 的注释符号? A. // B. # C. /* D. ; 答案:B 2. 下面哪个是 Python 的赋值运算符? A. B. C. ! D. > 答案:A 3. 下面哪个是 Python 的逻辑运算符? A. && B. || C. ! D. & 答…...
Linux 面试题-(腾讯,百度,美团,滴滴)
Linux 面试题-(腾讯,百度,美团,滴滴) 分析日志t.log(访问量),将各个ip 地址截取,并统计出现次数,并按从大到小排序(腾讯) http://192.168.200.10/index1.html http://192.168.200.10/index2.html http://192.168.200.20/index1.html http://192.168.20…...

DDD--战略设计步骤
在领域驱动设计(Domain-Driven Design,DDD)中,战略设计是指在系统的整体层面上考虑领域模型的组织和架构。下面是一些战略设计的详细步骤: 确定限界上下文(Bounded Context):首先&a…...
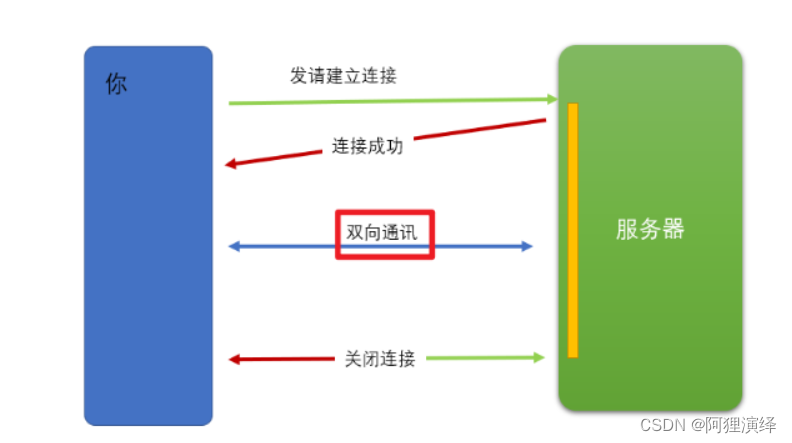
Web Scoket简述
Web Socket 简介 初次接触 Web Socket 的人,我们已经有了 HTTP 协议,为什么还需要另一个协议?它能带来什么好处? 因为 HTTP 协议有一个缺陷:通信只能由客户端发起。http基于请求响应实现。 (准确来说HTTP…...

2026年精选5大小程序定制开发排行榜:赋能数字化转型新体验
导读:随着2026年企业数字化转型加速推进,小程序定制开发作为核心工具,正成为各行各业提升运营效率与用户互动的重要载体。本次深度测评聚焦当前市场中技术实力突出、服务能力全面的五家专业服务商,通过多维度剖析,为寻…...

从 CDS 到服务契约,读懂 ABAP Cloud 的 Model-Driven Architecture
很多做 RAP 的同学,在 ADT 里第一次同时创建 CDS view entity、behavior definition、service definition、service binding 的时候,直觉往往是,为什么对象一下子变这么多。等项目真正推进到发票、销售订单、主数据维护、审批动作、事件集成这些场景,就会慢慢体会到,这套做…...

告别网盘限速!3步搞定百度网盘高速下载秘籍
告别网盘限速!3步搞定百度网盘高速下载秘籍 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的龟速下载而烦恼吗?每次看到那几十KB/s的速…...

Claude 4.6 Opus 算力升级:中小企业 AI 混合部署最佳实践
2026 年 5 月,随着 SpaceX 与 Anthropic 算力合作的正式落地,Claude 4.6 Opus 的服务稳定性和并发处理能力得到了质的提升,同时 Anthropic 维持了 Claude Pro 用户免费使用 Opus 的权益不变,dd.zzmax.cn 已整理了针对中小企业的 C…...

芯片功能验证的范式革新:从约束随机到目标驱动的智能场景生成
1. 功能验证的十字路口:我们为何陷入困境?在芯片设计这个行当里摸爬滚打了十几年,我亲眼见证了功能验证从一个相对简单的环节,演变成如今整个设计流程中最耗时、最昂贵、也最令人头疼的瓶颈。这感觉就像你精心设计了一辆跑车&…...

报名CSGO/steam游戏搬砖项目前,这些内幕一定要了解
我相信大多数人都经常困惑于一件事,那就是每当想交钱报名某个项目的时候,却发现网上做这个项目的团队很多,一家比一家会吹,一家比一家牛B,着实很难抉择到底选哪家。生怕报名了后迎接自己的就是一个深不见底的黑洞&…...

Cursor AI编辑器离线资源库:解决网络依赖,实现内网与定制化开发
1. 项目概述:一个AI代码编辑器的离线资源库最近在折腾Cursor这个AI代码编辑器,发现它确实能极大提升开发效率。但有个问题一直困扰着不少开发者:它的AI功能高度依赖网络,一旦网络环境不佳,或者你想在特定场景下&#x…...

AI插件系统开发指南:从架构设计到生态构建
1. 项目概述:一个为TrapicAI生态注入活力的插件系统最近在折腾AI应用开发,特别是围绕一些开源大模型框架做二次开发时,总感觉缺了点什么。很多框架功能强大,但“开箱即用”的体验和针对特定场景的深度定制能力之间,往往…...

Anthropic研究院议程:不止做AI大模型,更要定义AI时代的全球规则
当大模型竞赛进入白热化,多数科技公司都在比拼参数、速度、模型能力时,OpenAI竞品Anthropic走出了一条完全不同的路。 近期,Anthropic 正式公布 Anthropic Institute(Anthropic研究院)全新研究议程,不再只埋头做模型研发,而是站在行业顶层视角,深度拆解AI对经济、安全、…...

为什么你的AI测试总在“伪自动化”?SITS 2026的3层认知跃迁:从用例驱动→意图驱动→反馈演化
AI原生测试方法革新:SITS 2026自动化测试新思路 更多请点击: https://intelliparadigm.com 第一章:为什么你的AI测试总在“伪自动化”? “伪自动化”是当前AI工程实践中最隐蔽的效率陷阱——表面看测试脚本在运行,日…...