2.2 搭建Spark开发环境
一、Spark开发环境准备工作
由于Spark仅仅是一种计算框架,不负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。
安装Spark集群前,需要安装Hadoop环境
软件 版本
Linux系统 CentOS7.9版本
Hadoop 3.3.4版本
JDK 1.8版本 (jdk8u231)
Spark 3.3.2版本
二、了解Spark的部署模式
(一)Standalone模式
Standalone模式被称为集群单机模式。该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
(二)Mesos模式
Mesos模式被称为Spark on Mesos模式。Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
(三)Yarn模式
Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
三、搭建Spark单机版环境
(一)前提是安装配置好了JDK
查看JDK版本
(二)下载、安装与配置Spark
1、下载Spark安装包
官网下载页面:https://spark.apache.org/downloads.html
下载链接:https://www.apache.org/dyn/closer.lua/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
下载到本地
2、将Spark安装包上传到虚拟机
将Spark安装包上传到ied虚拟机/opt目录
3、将Spark安装包解压到指定目录
执行命令:tar -zxvf spark-3.3.2-bin-hadoop3.tgz -C /usr/local
查看解压之后的spark目录
4、配置Spark环境变量
执行vim /etc/profile
export SPARK_HOME=/usr/local/spark-3.3.2-bin-hadoop3
export PATH= S P A R K H O M E / b i n : SPARK_HOME/bin: SPARKHOME/bin:SPARK_HOME/sbin:$PATH
1
2
存盘退出,执行命令:source /etc/profile,让环境配置生效
(三)使用Spark单机版环境
1、使用SparkPi来计算Pi的值
执行命令:run-example SparkPi 2 (其中参数2是指两个并行度)
查看计算结果:Pi is roughly 3.1412357061785308
2、使用Scala版本Spark-Shell
Spark-Shell是一个强大的交互式数据分析工具,初学者可以很好的使用它来学习相关API,用户可以在命令行下使用Scala编写Spark程序,并且每当输入一条语句,Spark-Shell就会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),Spark-Shell支持Scala和Python。
命令格式:spark-shell --master
–master表示指定当前连接的Master节点
用于指定Spark的运行模式
参数名称 相关说明
local 使用一个Worker线程本地化运行Spark
local[] 本地运行Spark,工作线程数量与本机CPU逻辑核心数量相同
local[N] 使用N个Worker线程本地化运行Spark
spark://host:port Standalone模式下,连接到指定的Spark集群,默认端口7077
yarn-client 以客户端模式连接Yarn集群,集群位置可在HADOOP_CONF_DIR环境变量中配置
yarn-cluster 以集群模式连接Yarn集群,集群位置可在HADOOP_CONF_DIR 环境变量中配置
mesos://host:port 连接到指定的Mesos集群。默认接口是5050
执行spark-shell命令,相当于执行spark-shell --master local[]命令,启动Scala版的Spark-Shell
访问Spark的Web UI界面 - http://ied:4040
注意:Spark 3.3.2使用的Scala版本其实是2.12.15
利用print函数输出了一条信息
计算1 + 2 + 3 + …… + 100
输出字符直角三角形
打印九九表
执行:quit命令,退出Spark Shell交互式环境
3、使用Python版本Spark-Shell
执行pyspark命令启动Python版的Spark-Shell
执行命令:yum -y install python3
执行命令:pyspark
输出一条信息,进行加法运算,然后退出交互式环境
4、初识弹性分布式数据集RDD
Spark 中的RDD (Resilient Distributed Dataset) 就是一个不可变的分布式对象集合。每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。用户可以使用两种方法创建RDD:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(比如list 和set)。
演示利用集合创建RDD
在/home目录下创建test.txt文件
例1、创建一个RDD
在pyspark命令行,执行命令:lines = sc.textFile(‘/home/test.txt’)
创建出来后,RDD 支持两种类型的操作: 转化操作(transformation) 和行动操作(action)。转化操作会由一个RDD 生成一个新的RDD。另一方面,行动操作会对RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如HDFS)中。
例2、调用转化操作filter()
执行命令:sparkLines = lines.filter(lambda line: ‘spark’ in line)
例3、调用行动操作first()
执行命令:sparkLines.first()
转化操作和行动操作的区别在于Spark 计算RDD 的方式不同。虽然你可以在任何时候定义新的RDD,但Spark 只会惰性计算这些RDD。它们只有第一次在一个行动操作中用到时,才会真正计算。这种策略刚开始看起来可能会显得有些奇怪,不过在大数据领域是很有道理的。比如,看看例2 和例3,我们以一个文本文件定义了数据,然后把其中包含spark的行筛选出来。如果Spark 在我们运行lines = sc.textFile(…) 时就把文件中所有的行都读取并存储起来,就会消耗很多存储空间,而我们马上就要筛选掉其中的很多数据。相反, 一旦Spark 了解了完整的转化操作链之后,它就可以只计算求结果时真正需要的数据。事实上,在行动操作first() 中,Spark 只需要扫描文件直到找到第一个匹配的行为止,而不需要读取整个文件。
如果要显示全部包含spark的行,执行命令:sparkLines.collect()
同样的任务,在Scala的Spark Shell里完成
补充练习:利用Spark RDD实现词频统计
在spark-shell里完成
在pyspark里完成
但是执行wc1.collect()就会报错,目前没有解决问题。
四、搭建Spark Standalone集群
(一)Spark Standalone架构
Spark Standalone模式为经典的Master/Slave(主/从)架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。可以在向Spark集群提交应用程序时使用–deploy-mode参数指定提交方式。
1、client提交方式
当提交方式为client时,运行架构如下图所示
集群的主节点称为Master节点,在集群启动时会在主节点启动一个名为Master的守护进程,类似YARN集群的ResourceManager;从节点称为Worker节点,在集群启动时会在各个从节点上启动一个名为Worker的守护进程,类似YARN集群的NodeManager。
Spark在执行应用程序的过程中会启动Driver和Executor两种JVM进程。
Driver为主控进程,负责执行应用程序的main()方法,创建SparkContext对象(负责与Spark集群进行交互),提交Spark作业,并将作业转化为Task(一个作业由多个Task任务组成),然后在各个Executor进程间对Task进行调度和监控。通常用SparkContext代表Driver。在上图的架构中,Spark会在客户端启动一个名为SparkSubmit的进程,Driver程序则运行于该进程。
Executor为应用程序运行在Worker节点上的一个进程,由Worker进程启动,负责执行具体的Task,并存储数据在内存或磁盘上。每个应用程序都有各自独立的一个或多个Executor进程。在Spark Standalone模式和Spark on YARN模式中,Executor进程的名称为CoarseGrainedExecutorBackend,类似运行MapReduce程序所产生的YarnChild进程,并且同时与Worker、Driver都有通信。
2、cluster提交方式
当提交方式为cluster时,运行架构如下图所示
Standalone cluster提交方式提交应用程序后,客户端仍然会产生一个名为SparkSubmit的进程,但是该进程会在应用程序提交给集群之后就立即退出。当应用程序运行时,Master会在集群中选择一个Worker进程启动一个名为DriverWrapper的子进程,该子进程即为Driver进程,所起的作用相当于YARN集群的ApplicationMaster角色,类似MapReduce程序运行时所产生的MRAppMaster进程。
(二)Spark集群拓扑
1、集群拓扑
一个主节点,两个从节点
2、集群角色分配
Spark Standalone模式的集群搭建需要在集群的每个节点都安装Spark,集群角色分配如下表所示。
节点 角色
master Master
slave1 Worker
slave2 Worker
(三)前提条件:安装配置了分布式Hadoop环境
启动hadoop集群
访问Hadoop WebUI界面
(四)在master虚拟机上安装配置Spark
1、将spark安装包上传到master虚拟机
进入/opt目录,查看上传的spark安装包
2、将spark安装包解压到指定目录
执行命令:tar -zxvf spark-3.3.2-bin-hadoop3.tgz -C /usr/local
3、配置spark环境变量
执行命令:vim /etc/profile
export SPARK_HOME=/usr/local/spark-3.3.2-bin-hadoop3
export PATH= S P A R K H O M E / b i n : SPARK_HOME/bin: SPARKHOME/bin:SPARK_HOME/sbin:$PATH
存盘退出后,执行命令:source /etc/profile,让配置生效
查看spark安装目录(bin、sbin和conf三个目录很重要)
4、编辑spark环境配置文件
进入spark配置目录后,执行命令:cp spark-env.sh.template spark-env.sh与vim spark-env.sh
添加三行语句
export JAVA_HOME=/usr/local/jdk1.8.0_231
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
JAVA_HOME:指定JAVA_HOME的路径。若集群中每个节点在/etc/profile文件中都配置了JAVA_HOME,则该选项可以省略,Spark集群启动时会自动读取。为了防止出错,建议此处将该选项配置上。
SPARK_MASTER_HOST:指定集群主节点(master)的主机名,此处为master。
SPARK_MASTER_PORT:指定Master节点的访问端口,默认为7077。
存盘退出,执行命令:source spark-env.sh,让配置生效
5、创建slaves文件,添加从节点
执行命令:vim slaves,添加两个从节点主机名
(五)在slave1虚拟机上安装配置Spark
1、把master虚拟机上安装的spark分发给slave1虚拟机
执行命令:scp -r S P A R K H O M E r o o t @ s l a v e 1 : SPARK_HOME root@slave1: SPARKHOMEroot@slave1:SPARK_HOME
2、将master虚拟机上环境变量配置文件分发到slave1虚拟机
在master虚拟机上,执行命令:scp /etc/profile root@slave1:/etc/profile
在slave1虚拟机上,执行命令:source /etc/profile,让环境配置生效
3、在slave1虚拟机上让spark环境配置文件生效
在slave1虚拟机上,进入spark配置目录,执行命令:source spark-env.sh
(六)在slave2虚拟机上安装配置Spark
1、把master虚拟机上安装的spark分发给slave2虚拟机
执行命令:scp -r S P A R K H O M E r o o t @ s l a v e 2 : SPARK_HOME root@slave2: SPARKHOMEroot@slave2:SPARK_HOME
2、将master虚拟机上环境变量配置文件分发到slave2虚拟机
在master虚拟机上,执行命令:scp /etc/profile root@slave2:/etc/profile
在slave2虚拟机上,执行命令:source /etc/profile,让环境配置生效
3、在slave2虚拟机上让spark环境配置文件生效
在slave2虚拟机上,进入spark配置目录,执行命令:source spark-env.sh
(七)启动Spark Standalone集群
Spark Standalone集群使用Spark自带的资源调度框架,但一般我们把数据保存在HDFS上,用HDFS做数据持久化,所以Hadoop还是需要配置,但是可以只配置HDFS相关的,而Hadoop YARN不需要配置。启动Spark Standalone集群,不需要启动YARN服务,因为Spark会使用自带的资源调度框架。
1、启动hadoop的dfs服务
在master虚拟机上执行命令:start-dfs.sh
2、启动Spark集群
执行命令:start-all.sh
查看start-all.sh的源码启动Master与Worker的命令
Start Master
“${SPARK_HOME}/sbin”/start-master.sh
Start Worker
s"${SPARK_HOME}/sbin"/start-slaves.sh
可以看到,当执行start-all.sh命令时,会分别执行start-master.sh命令启动Master,执行start-slaves.sh命令启动Worker。
注意,若spark-evn.sh中配置了SPARK_MASTER_HOST属性,则必须在该属性指定的主机上启动Spark集群,否则会启动不成功;若没有配置SPARK_MASTER_HOST属性,则可以在任意节点上启动Spark集群,当前执行启动命令的节点即为Master节点。
启动完毕后,分别在各节点执行jps命令,查看启动的进程。若在master节点存在Master进程,slave1节点存在Worker进程,slave2节点存在Worker进程,则说明集群启动成功。
查看master节点进程
查看slave1节点进程
查看slave2节点进程
(八)访问Spark的WebUI
在浏览器里访问http://master:8080
在浏览器访问http://slave1:8081
在浏览器访问http://slave2:8081
如果要用IP地址来访问,得用浮动IP地址,不能用私有IP地址
用私有IP地址访问是不行的 - http://192.168.1.101:8080/
用浮动IP地址来访问才可以 - 192.168.218.181
查看私有云上虚拟机的配置
(九)启动Scala版Spark Shell
执行命令:spark-shell --master spark://master:7077 (注意–master,两个-不能少)
在/opt目录里执行命令:vim test.txt
在HDFS上创建park目录,将test.txt上传到HDFS的/park目录
读取HDFS上的文件,创建RDD,执行命令:val rdd = sc.textFile(“hdfs://master:9000/park/test.txt”)(说明:val rdd = sc.textFile(“/park/test.txt”)读取的依然是HDFS上的文件,绝对不是本地文件)
收集rdd的数据,执行命令:rdd.collect
进行词频统计,按单词个数降序排列,执行命令:val wordcount = rdd.flatMap(.split(" ")).map((, 1)).reduceByKey(_ + ).sortBy(._2, false)与`wordcount.collect.foreach(println)
(十)提交Spark应用程序
1、提交语法格式
Spark提供了一个客户端应用程序提交工具spark-submit,使用该工具可以将编写好的Spark应用程序提交到Spark集群。
spark-submit的使用格式如下:$ bin/spark-submit [options] [app options]
options表示传递给spark-submit的控制参数;
app jar表示提交的程序JAR包(或Python脚本文件)所在位置;
app options表示jar程序需要传递的参数,例如main()方法中需要传递的参数。
2、spark-submit常用参数
除了–master参数外,spark-submit还提供了一些控制资源使用和运行时环境的参数。
参数 描述
–master Master节点的连接地址,取值为spark://host:port、mesos://host:port、yarn、k8s://https://host:port 或 local(默认为local[*])
–deploy-mode 提交方式,取值为client或cluster。client表示在本地客户端启动Driver程序,cluster表示在集群内部的工作节点上启动Driver程序,默认为client
–class 应用程序的主类(Java或Scala程序)
–name 应用程序名称,会在Spark Web UI中显示
–jars 应用依赖的第三方JAR包列表,以逗号分隔
–files 需要放到应用工作目录中的文件列表,以逗号分隔。此参数一般用来放需要分发到各节点的数据文件
–conf 设置任意的SparkConf配置属性,格式为“属性名=属性值”
–properties-file 加载外部包含键值对的属性文件。如果不指定,就默认读取Spark安装目录下的conf/spark-defaults.conf 文件中的配置
–driver-memory Driver进程使用的内存量,例如512MB或1GB,单位不区分大小写,默认为1GB
–executor-memory 每个Executor进程所使用的内存量。例如512MB或1GB,单位不区分大小写,默认为1GB
–driver-cores Driver进程使用的CPU核心数,仅在集群模式中使用,默认为1
-executor-cores 每个Executor进程所使用的CPU核心数,默认为1
num-executors Executor进程数量,默认为2。如果开启动态分配,那么初始Executor的数量至少是此参数配置的数量。需要注意的是,此参数仅在Spark On YARN模式中使用
3、案例演示 - 提交Spark自带的圆周率计算程序
进入Spark安装目录
(1)Standalone模式,采用client提交方式
执行下述命令,将Spark自带的求圆周率的程序提交到集群
bin/spark-submit
–class org.apache.spark.examples.SparkPi
–master spark://master:7077
./examples/jars/spark-examples_2.12-3.3.2.jar
提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回控制台查看输出信息,出现了“Pi is roughly 3.1424157120785603”,说明Pi值已经被计算完毕。
上述命令中的–master参数指定了Master节点的连接地址。该参数根据不同的Spark集群模式,其取值也有所不同,常用取值如下表所示。
取值 描述
spark://host:port Standalone模式下的Master节点的连接地址,默认端口为7077
yarn 连接到YARN集群。若YARN中没有指定ResourceManager的启动地址,则需要在ResourceManager所在的节点上进行应用程序的提交,否则将因找不到ResourceManager而提交失败
local 运行本地模式,使用1个CPU核心
local [N] 运行本地模式,使用N个CPU核心。例如,local[2]表示使用两个CPU核心运行程序
local[] 运行本地模式,尽可能使用最多的CPU核心
若不添加–master参数,则默认使用本地模式local[]运行。
(2)Standalone模式,采用cluster提交方式
在Standalone模式下,将Spark自带的圆周率计算程序提交到集群,并且设置Driver进程使用内存为512MB,每个Executor进程使用内存为1GB,每个Executor进程所使用的CPU核心数为2,提交方式为cluster(Driver进程运行在集群的工作节点中),执行命令如下:
bin/spark-submit
–master spark://master:7077
–deploy-mode cluster
–class org.apache.spark.examples.SparkPi
–driver-memory 512m
–executor-memory 1g
–executor-cores 2
./examples/jars/spark-examples_2.12-3.3.2.jar
当然可以写成一行
bin/spark-submit --master spark://master:7077 --deploy-mode cluster --class org.apache.spark.SparkPi --driver-memory 512m --executor-memory 1g --executor-cores 2 ./examples/jars/spark-examples_2.12-3.3.2.jar
1
执行命令后,看到State of driver-20230406114733-0000 is RUNNING,就表明运行成功~,否则会显示State of driver-20230406114733-0000 is FAILED
在Spark WebUI界面上查看运行结果,访问http://master:8080
单击圈红的Worker超链接 - worker-20230406114652-192.168.1.102-36708
注意:必须把私有IP地址改成主机名slave1或者对应的浮动IP地址
单击stdout超链接,可以查看到Pi的计算结果
(十一)停止Spark集群服务
在master节点执行命令:stop-all.sh
相关文章:

2.2 搭建Spark开发环境
一、Spark开发环境准备工作 由于Spark仅仅是一种计算框架,不负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。 安装Spark集群前…...

webpack指定输出资源的路径和名称
如图,在前面的章节我们打包后的文件默认都输出到了dist目录下,无论是图片、还是js都在同一级别目录,这里目前处理的资源比较少,如果资源一多,所有的资源都在同一级目录,看起来很费劲。 那么这节就介绍一下…...

Spring事务四
spring 事务的隔离级别 当多个事务同时访问数据库中的同一数据时,可能会出现数据不一致的情况,为了避免这种情况发生,就需要使用事务隔离机制。Spring框架中定义了5种事务隔离级别,分别为: DEFAULT(默认隔…...
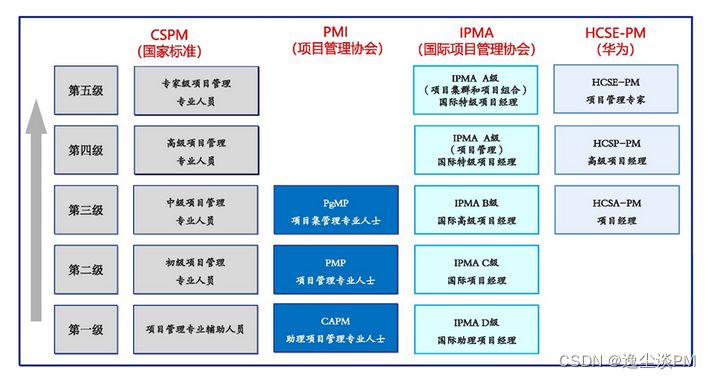
项目管理专业人员能力评价等级证书(CSPM)的级别介绍
2021年10月,中共中央、国务院发布的《国家标准化发展纲要》明确提出构建多层次从业人员培养培训体系,开展专业人才培养培训和国家质量基础设施综合教育。建立健全人才的职业能力评价和激励机制。由中国标准化协会(CAS)组织开展的项…...
)
设计模式-创建型模式(单例、工厂、建造、原型)
Concept-概念前置 设计模式:软件设计中普遍存在(反复出现)的各种问题,所提出的解决方案。 面向对象三大特性:封装、继承、多态。 面向对象设计的SOLID原则: (1)开放封闭原则&#…...
用饭店来形象比喻线程池的工作原理
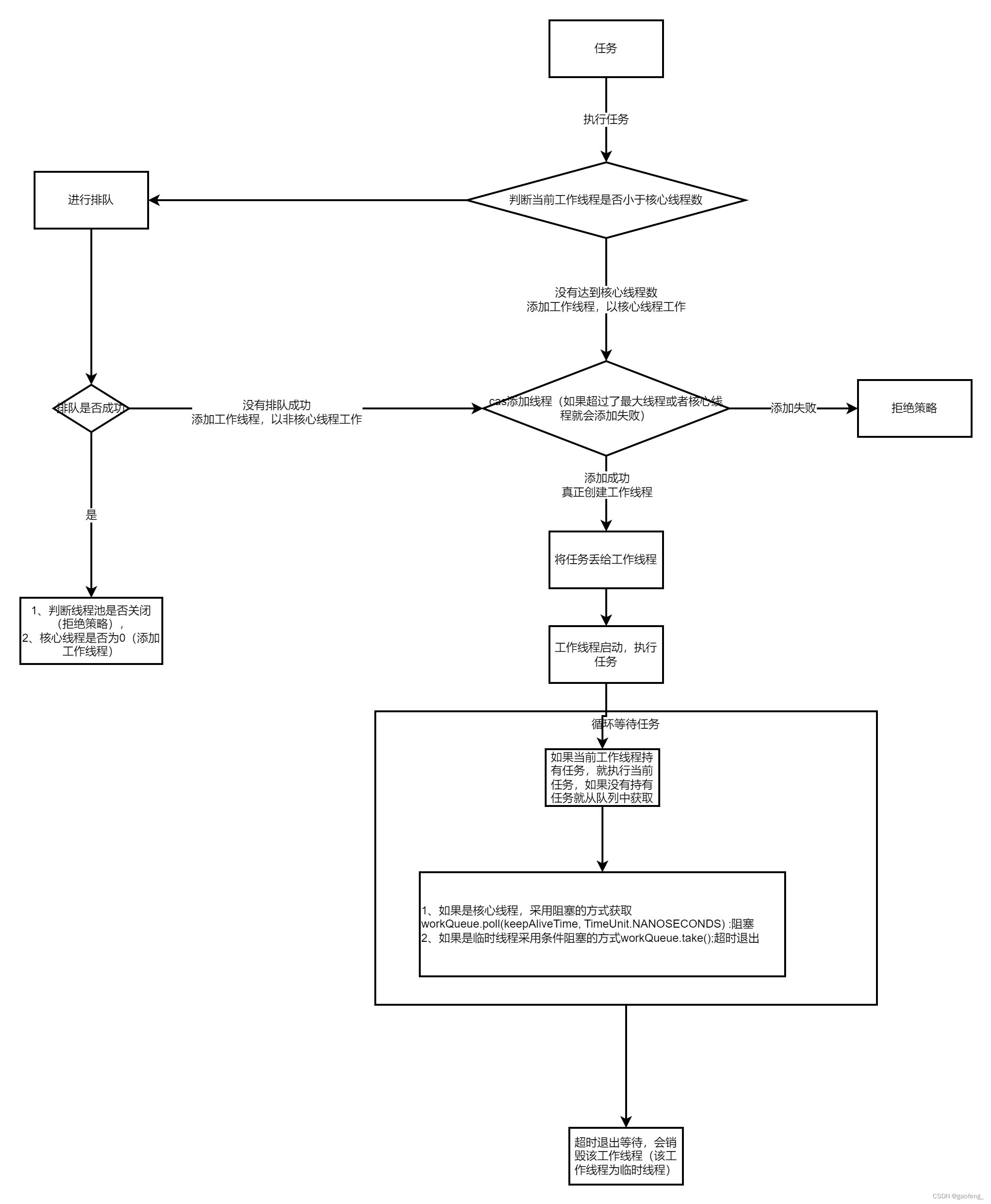
一、线程池解决的问题? 使用线程池主要解决在程序中频繁创建和销毁线程导致的资源浪费,线程池可以维护一定量的线程来执行所需要的任务,维护的线程也可以重复使用。 二、用形象的饭店来解释工作原理 线程池就相当于一家饭店, 任…...

GO学习笔记之表达式
GO学习笔记之表达式 保留字运算符优先级二元运算符位运算符自增指针 保留字 Go语言仅25个保留关键字(keyword),这是最常见的宣传语,虽不是主流语言中最少的,但也确实体现了Go语法规则的简洁性。保留关键字不能用作常量…...

005Mybatis返回值(ResultMap 一对多,多对多)
属性 id 应该总是指定一个或多个可以唯一标识结果的属性。 虽然,即使不指定这个属性,MyBatis 仍然可以工作,但是会产生严重的性能问题。 只需要指定可以唯一标识结果的最少属性。显然,你可以选择主键(复合主键也可以…...

把玩数据在内存中的存储
前言:时光如梭💦,今天到了C语言进阶啦😎,基础知识我们已经有了初步认识, 是时候该拔高拔高自己了😼。 目标:掌握浮点数在内存的存储,整形在内存的存储。 鸡汤:…...

Nginx运行原理与基本配置文件讲解
文章目录 Nginx基本运行原理Nginx的基本配置文件serverlocationroot 与 alias 的区别server 和 location 中的 rootnginx欢迎页 本文参考文章Nginx相关文章 Nginx基本运行原理 Nginx的进程是使用经典的「Master-Worker」模型,Nginx在启动后,会有一个master进程和多个…...

openGauss5 企业版之SQL语法和数据结构
文章目录 1.openGauss SQL 语法2. 数据类型2.1数值类型2.2 布尔类型2.3 字符类型2.4 二进制类型2.5日期/时间类型2.6 几何类型2.7 网络地址类型2.8 位串类型2.9 文本搜索类型2.10 UUID数据类型2.11 JSON/JSONB类型2.11 HLL数据类型2.12 范围类型2.13 索引2.14 对象标识符类型2.…...
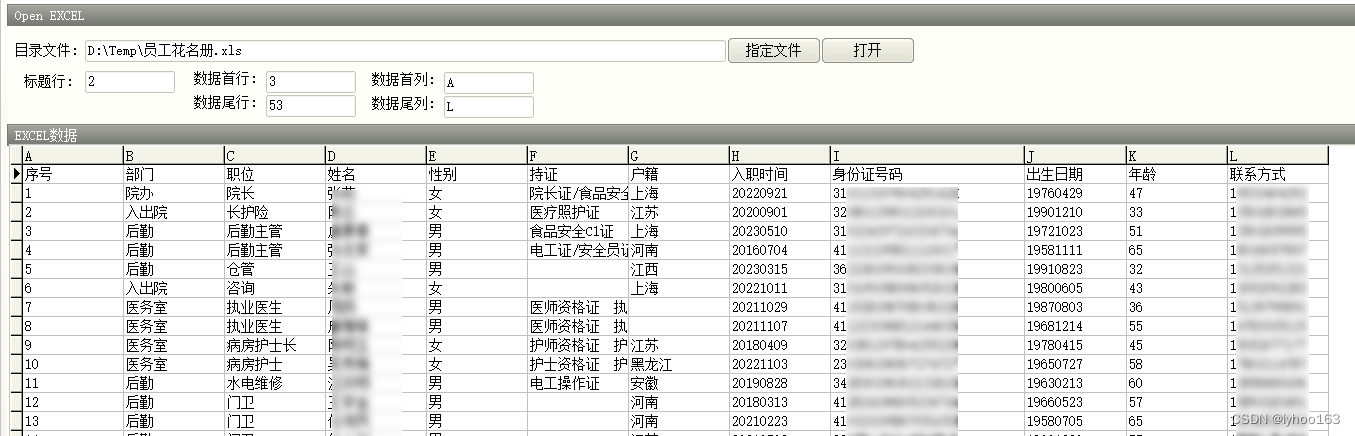
TClientDataSet 模拟 EXCEL表
日常处理数据时,经常需要,从EXCEL表格中,批量导入数据,通过 XLSReadWriteII编程,会很快导入。 但是,客户提供的EXCEL表的字段,数据格式,字段的排序,有很大的区别。因此&a…...

Hazel游戏引擎(012)GLFW窗口事件
文中若有代码、术语等错误,欢迎指正 文章目录 前言如何确定GLFW窗口事件的回调函数参数Application接收事件回调流程原项目流程(12345)自己写的简单Demo与流程(123) 前言 此节目的 为了完成008计划窗口事件的接收glfw窗口事件以及回调部分 此节要完成 使用glfw函数…...

Nenu算法复习第六章
目录 补充知识点 1160: 6001 第几天? 1161: 6002 时间格式转换 1162: 6003 星期几? 1163: 6004 18岁生日、 补充知识点 闰年的判断方法: 能被四整除但是不能一百整除或者能被400整除 例题: 题目描述 经常会有人问你怎么判断闰年&…...

知识付费社群:最好的知识传播方式
知识付费是一种网络内容付费方式,它让知识传播者通过网络以付费的方式向社会大众或特定平台传递知识、技能和智力资源。 知识付费传播的成功离不开用户,他们是核心节点,也是受众和粉丝的重要组成部分。用户不仅可以生产和传播知识࿰…...
局域网内不同网段的设备互相连接设置
目录 介绍1、打开网络连接,找到本地网络->属性->ipv4->属性->高级:2、在高级设置页面,我们添加一个IP,这个IP和板子在一个网段,我这里设置的是192.168.253.101:3、设置完成即可生效,…...
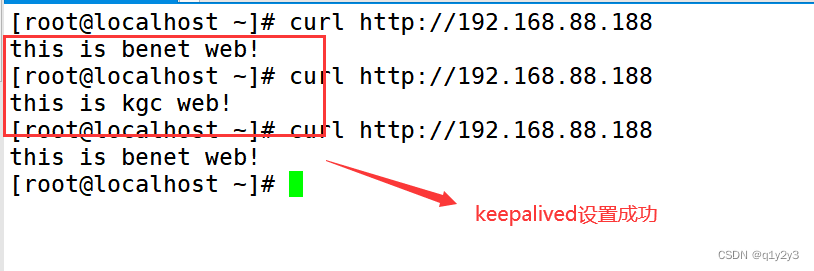
LVS+Keepalived 群集
目录 一、keepalived概述 1.keepalived工作原理 2.keepalived体系主要模块及其作用 3.判断服务器主备,及如何配置浮动IP 二、keepalived的抢占与非抢占模式 三、部署LVSkeepalived 1.配置负载调度器(主备相同) 1.1配置keepalived&…...

windows系统cmd命令设置别名,并添加到环境变量
众所周知,Linux 命令很强大,使用起来也很方便,但是想在 windows 系统上使用 Linux 命令有些困难,要么下载第三方终端工具,要么就是安装一系列命令环境。 作为一个前端开发,其实可以全局安装一下 npm 命令行…...

智能学习 | MATLAB实现GWO-SVM多输入单输出回归预测(灰狼算法优化支持向量机)
智能学习 | MATLAB实现GWO-SVM多输入单输出回归预测(灰狼算法优化支持向量机) 目录 智能学习 | MATLAB实现GWO-SVM多输入单输出回归预测(灰狼算法优化支持向量机)预测效果基本介绍模型原理程序设计参考资料预测效果 基本介绍 Matlab实现GWO-SVM灰狼算法优化支持向量机的多输…...
java方法
文章目录 一、java方法总结 一、java方法 在前面几个章节中我们经常使用到 System.out.println(),那么它是什么呢? println() 是一个方法。 System 是系统类。 out 是标准输出对象。这句话的用法是调用系统类 System 中的标准输出对象 out 中的方法 pr…...

用AG9311芯片DIY一个多功能Type-C扩展坞:从原理图到PCB布局的保姆级指南
用AG9311芯片DIY多功能Type-C扩展坞:从原理图到PCB布局全解析 Type-C扩展坞早已成为现代数字生活的必需品,但市面上成品往往价格高昂或功能单一。对于硬件爱好者而言,自己动手打造一款多功能扩展坞不仅能节省成本,更能深度掌握高速…...

旭雷禹鼎遥控器F21-E2B-8起重机天车行车电动葫芦工业无线遥控器
旭雷禹鼎遥控器F21-E2B-8起重机天车行车电动葫芦工业无线遥控器起重机工业无线遥控器的兼容性极强,可适配各类型号、不同吨位的起重机,无需大规模改造设备,大幅降低企业升级成本。无论是桥式起重机、门式起重机,还是塔式起重机、悬…...
)
告别繁琐配置:Jprotobuf注解驱动序列化实战(新手友好)
1. 为什么选择Jprotobuf注解方案 如果你正在用Java开发需要频繁序列化数据的应用,比如缓存系统、微服务通信或者游戏服务器,肯定遇到过这样的纠结:用JSON虽然方便但性能差体积大,用Protobuf性能好但配置太麻烦。我去年做电商订单系…...

DocX入门指南:如何在不安装Word的情况下快速创建第一个Word文档
DocX入门指南:如何在不安装Word的情况下快速创建第一个Word文档 【免费下载链接】DocX Fast and easy to use .NET library that creates or modifies Microsoft Word files without installing Word. 项目地址: https://gitcode.com/gh_mirrors/doc/DocX Do…...

本地部署AI代码解释器:基于大模型的对话式编程实践指南
1. 项目概述:当本地代码解释器遇上大模型最近在折腾一个挺有意思的项目,叫local-code-interpreter。这名字听起来有点学术,但说白了,它就是一个能让你在自己电脑上,通过自然语言对话来编写、执行和调试代码的“智能助手…...

从微信小程序转战uniapp,我总结的路由跳转对照表与迁移心得
从微信小程序到Uniapp:路由跳转深度迁移指南与实战避坑 第一次在Uniapp项目里看到uni.navigateTo这个API时,我下意识地以为它和微信小程序的wx.navigateTo完全一样——直到某个深夜,测试同学突然报告说iOS设备上连续跳转7个页面后应用直接闪退…...

统一AI编程助手配置:使用agent-anatomy提升开发效率与一致性
1. 项目概述:一个配置文件夹,统一所有AI编程助手如果你和我一样,日常开发中会同时使用Claude Code、Cursor、GitHub Copilot等多个AI编程助手,那你一定也经历过同样的烦恼:每个助手都需要自己独立的配置文件。今天要介…...

B站视频转文字终极指南:3分钟学会用bili2text智能提取视频内容
B站视频转文字终极指南:3分钟学会用bili2text智能提取视频内容 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为手动整理B站视频内容而烦恼吗…...

Sunshine游戏串流服务器:打造你的个人云端游戏平台
Sunshine游戏串流服务器:打造你的个人云端游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏?Sunshine游戏串流服务器是你…...
)
服务器卡死别慌!手把手教你读懂NMI watchdog的soft lockup报错信息(附CentOS 7排查流程)
服务器卡死应急指南:NMI watchdog与soft lockup实战排查手册 凌晨三点,机房告警铃声大作,监控大屏上某台核心服务器的CPU使用率突然飙升至100%并持续不降。登录系统后,dmesg中赫然出现NMI watchdog: BUG: soft lockup - CPU#2 stu…...