0202性能分析-索引-MySQL
1 索引语法
-
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name(index_column_name,...);- Index_name:规范为
idx_表名_字段名...
- Index_name:规范为
-
查看索引
SHOW INDEX FROM table_name; -
删除索引
DROP INDEX index_name ON table_name;
按照下列要求,创建索引:
- name字段为姓名字段,该字段值可能重复,为该字段创建索引;
- phone手机号字段值,要求非空且唯一,为该字段创建唯一索引;
- 为profession、age、status创建联合索引;
- 为email索引建立合适的索引来提升查询效率。
首先查看下表tb_user1当前索引,如下图1-2所示:

name字段建立常规索引,sql如下:
CREATE INDEX idx_tb_user1_name ON tb_user1(name);
给字段phone创建唯一索引,sql如下:
CREATE UNIQUE INDEX idx_tb_user1_phone ON tb_user1(phone);
为profession、age、status创建联合索引,sql如下:
CREATE INDEX idx_tb_user1_pro_age_sta ON tb_user1(profession, age, phone);
- 联合索引字段顺序由讲究
- seq_in_index:该索引(联合索引)字段顺序
为提高查询效率,为email字段建立常规索引,sql如下:
CREATE INDEX idx_tb_user1_email ON tb_user1(email);
在此查看tb_user1表中的索引如下图1-3所示:

删除idx_tb_user1_email索引,sql如下:
DROP INDEX idx_tb_user1_email ON tb_user1;
2 性能分析
2.1 查看执行频次
通过如下命令,可以查看当前数据库INSERT,UPDATE,DELETE,SELECT的访问频次
SHOW GLOBAL|SESSION STATUS LIKE 'Com_______'
如下图2.1-1所示:

-
Com后面跟7个下划线
-
通过该指令确认当前数据库是查询为主还是增、删或者改为主,然后针对不同类型做相应的优化。
2.2 慢查询日志
MySQL慢查询日志是MySQL数据库的一项功能,用于记录执行时间超过预设阈值的查询语句。慢查询日志可以帮助你识别数据库性能瓶颈和优化查询语句。
要启用MySQL慢查询日志,你可以按照以下步骤进行操作:
-
打开MySQL配置文件(通常是my.cnf或my.ini)。你可以在MySQL的安装目录中找到该文件。
-
在配置文件中找到
[mysqld]部分,如果不存在,请添加该部分。 -
在
[mysqld]部分下添加或修改以下行,以启用慢查询日志:slow_query_log = 1 // 启用慢查询日志 slow_query_log_file = /path/to/slow-query.log // 慢查询日志文件的路径和名称 long_query_time = 1 // 查询执行时间超过多少秒将被记录到慢查询日志中注意,你需要根据实际情况设置适当的路径和时间阈值。
-
保存并关闭配置文件。
-
重启MySQL服务器,以使配置更改生效。
现在,MySQL将开始记录执行时间超过指定阈值的查询语句到慢查询日志文件中。你可以使用任何文本编辑器打开日志文件以查看其中的查询语句和执行时间。
另外,你也可以使用MySQL提供的工具来分析慢查询日志,例如mysqldumpslow和pt-query-digest。这些工具可以帮助你解析慢查询日志文件并生成汇总报告,以便更好地理解数据库性能问题。
需要注意的是,启用慢查询日志会对系统性能产生一定的影响,因为它需要记录大量查询信息。因此,在生产环境中,你可能需要谨慎使用慢查询日志功能,并根据需要进行开关控制。
示例:
Time Id Command Argument
# Time: 2023-06-12T00:28:49.903565Z
# User@Host: root[root] @ [172.17.0.1] Id: 8
# Query_time: 2.961605 Lock_time: 0.000026 Rows_sent: 1 Rows_examined: 0
use gaogzhen;
SET timestamp=1686529726;
select count(*) from tb_sku;
- 记录当前时间、登录用户、主机、查询用时、加锁时间、查询那个数据库、时间、执行语句等
- 慢查询日志一般在开发测试环境中使用,生成环境慎用。
2.3 profile
MySQL的profile是一种功能,用于分析查询的性能和资源消耗情况。通过启用profile,你可以获得关于每个查询的详细信息,包括执行时间、扫描的行数、使用的临时表等等。这对于优化查询和发现潜在的性能问题非常有用。
要使用MySQL的profile功能,你可以按照以下步骤进行操作:
-
打开MySQL客户端,以管理员或具有适当权限的用户身份登录到MySQL服务器。
-
在执行查询之前,使用以下命令启用profile功能:
SET profiling = 1;这将启用profile功能,并将性能信息记录到MySQL服务器的内存中。
-
执行你想要分析的查询语句。
-
当查询完成后,使用以下命令查看profile结果:
SHOW PROFILES;这将显示所有执行过的查询的列表,包括每个查询的标识符和执行时间。
示例截图如下图2.3-1所示:

-
选择你想要查看详细信息的查询,使用以下命令查看该查询的profile结果:
SHOW PROFILE FOR QUERY <query_id>;将
\<query_id>替换为你要查看的查询的标识符。
-
这将显示该查询的详细profile结果,包括每个阶段的耗时、扫描的行数、使用的临时表等。
注意,使用完profile功能后,应使用以下命令禁用profile功能,以避免对性能产生额外的开销:
SET profiling = 0;
MySQL的profile功能对于优化查询和发现性能问题非常有用,但在生产环境中使用时应谨慎,以避免对系统性能造成过大的影响。
2.4 explain
2.4.1 概述
EXPLAIN是MySQL提供的一个关键字,用于分析查询语句的执行计划。通过EXPLAIN,你可以获取关于查询语句的详细信息,包括查询的表、使用的索引、连接类型、扫描行数等等。这些信息对于优化查询和理解查询性能非常有帮助。
要使用EXPLAIN,你可以按照以下步骤进行操作:
-
打开MySQL客户端,以管理员或具有适当权限的用户身份登录到MySQL服务器。
-
在客户端中,使用以下语法来执行EXPLAIN并分析查询语句:
EXPLAIN your_query;将"your_query"替换为你要分析的查询语句。
-
执行上述命令后,MySQL将返回一个关于查询执行计划的结果集,包含多列的信息,如下所示:
- id: 查询的唯一标识符,用于区分不同的查询。
- select_type: 查询类型,包括简单查询、联接查询、子查询等。
- table: 查询涉及的表名。
- partitions: 查询涉及的分区。
- type: 表访问的类型,如全表扫描、索引扫描等。
- possible_keys: 可能使用的索引。
- key: 实际使用的索引。
- key_len: 使用的索引长度。
- ref: 列与索引之间的关联。
- rows: 预计扫描的行数。
- filtered: 通过条件过滤的行占比。
- Extra: 其他额外的信息,如是否使用了临时表、使用的排序方式等。
这些列提供了关于查询执行计划的详细信息,你可以根据这些信息来优化查询语句,例如选择更合适的索引、优化连接方式等。
通过使用EXPLAIN,你可以更好地理解查询语句的执行方式,并进行性能优化。这对于大型数据库和复杂查询尤为重要。
示例有student,course,student_course三张表,学生表与课程表直接通过学生选课表多对多关联。
2.4.2 重点解析
- id :select 查询的序列号,表示查询中执行select子句或者操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行);
示例:
-
查看所有学生选课情况执行计划
- sql语句
explain select s.*, c.* from student s, course c, student_course sc where s.id = sc.studentid and sc.courseid = c.id;- 查询结果
- id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE s ALL PRIMARY 4 100.00
1 SIMPLE sc ALL fk_courseid,fk_studentid 6 33.33 Using where; Using join buffer (hash join)
1 SIMPLE c eq_ref PRIMARY PRIMARY 4 gaogzhen.sc.courseid 1 100.00
-
查询选修了MYSQL课程的学生信息(子查询)
-
explain select * from student s where s.id in (select studentid from student_course sc where sc.courseid = (select id FROM course c where c.NAME = 'MYSQL') ); -
id select_type table
1 PRIMARY
1 PRIMARY s
2 MATERIALIZED sc
3 SUBQUERY c
-
-
type: 表示连接类型,性能有好到差的连接类型为NULL、system、const、eq_ref、ref、range、index、all。
-
优化原则尽量向前优化;
-
NULL:不访问任何表,比如
select 1; -
system:使用系统表;
-
const:使用主键或者唯一索引;

-
ref:使用非唯一索引;

-
All:全表扫描,性能很低。
结语
如果小伙伴什么问题或者指教,欢迎交流。
❓QQ:806797785
参考链接:
[1]MySQL数据库视频[CP/OL].2020-04-16.p74-78.
相关文章:
0202性能分析-索引-MySQL
1 索引语法 创建索引 CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name(index_column_name,...);Index_name:规范为idx_表名_字段名... 查看索引 SHOW INDEX FROM table_name;删除索引 DROP INDEX index_name ON table_name;按照下列要求,创建…...
Play wright自动化测试工具该如何更加完美地使用
目录 1.1 拦截网络请求 1.2 pytest 管理用例 1.3 PO模型 1.4 API 和 UI 自动化测试融合 1.5 数据驱动 1.6 动态挑选用例执行 1.6 Allure测试报告 1.7 持续集成 1.1 拦截网络请求 网络拦截: 无响应 pass 中止 route.abort("aborted") 放行 route…...

数据可视化学习笔记:Python实现汽车品牌销售量矩形树图
引言 本文将介绍如何使用 Python 和 Pyecharts 库创建一个汽车品牌销售量的矩形树图。我们将使用 Pandas 读取 CSV 文件数据,然后对数据进行处理、封装,最后将数据可视化为矩形树图。 准备工作 首先,我们需要先安装好相关库: PandasPyecharts可以使用 pip 命令进行安装:…...
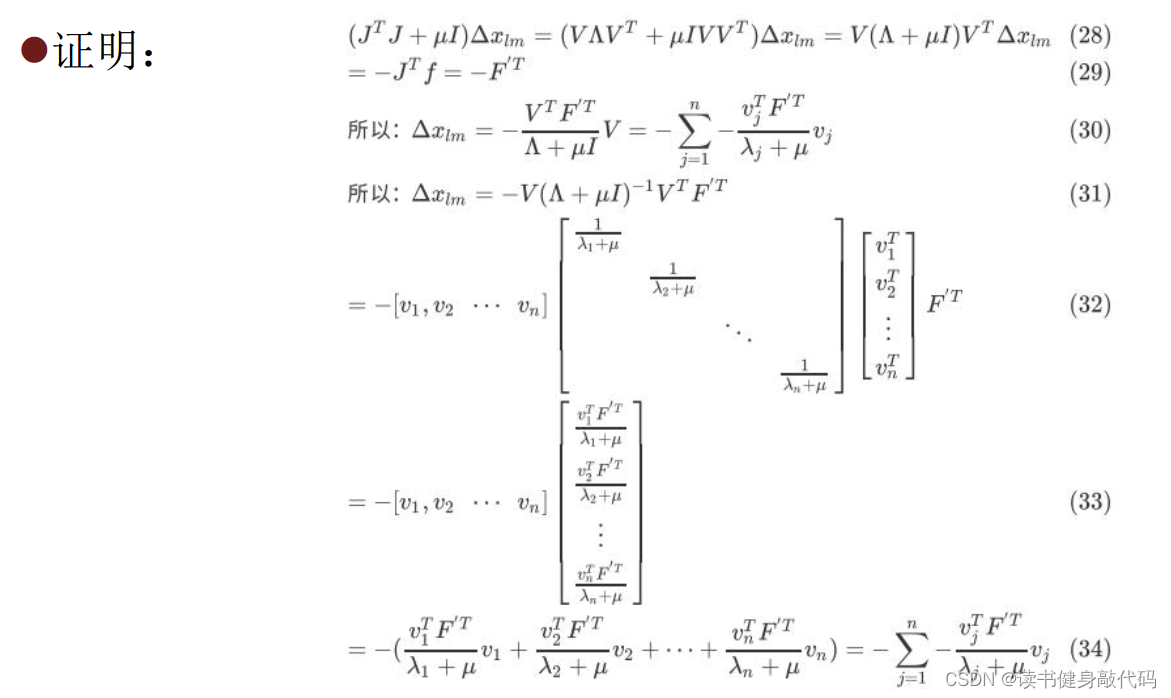
【深蓝学院】手写VIO第3章--基于优化的 IMU 与视觉信息融合--作业
0. 题目 1. T1 T1.1 绘制阻尼因子曲线 将尝试次数和lambda保存为csv,绘制成曲线如下图 iter, lambda 1, 0.002000 2, 0.008000 3, 0.064000 4, 1.024000 5, 32.768000 6, 2097.152000 7, 699.050667 8, 1398.101333 9, 5592.405333 10, 1864.135111 11, 1242.7567…...

企业级信息系统开发讲课笔记4.11 Spring Boot中Spring MVC的整合支持
文章目录 零、学习目标一、Spring MVC 自动配置(一)自动配置概述(二)Spring Boot整合Spring MVC 的自动化配置功能特性 二、Spring MVC 功能拓展实现(一)创建Spring Boot项目 - SpringMvcDemo2021ÿ…...

chatgpt赋能python:Python安装EGG——一个简单的指南
Python安装EGG——一个简单的指南 如果你使用Python有一段时间了,你可能会遇到需要安装扩展包(Package)的情况。在Python中,这些扩展包的文件格式通常是.egg(Easy Installable GZip)。在本文中,…...

Web前端-React学习
React基础 React 概述 React 是一个用于构建用户界面的JavaScript库。 用户界面: HTML页面(前端) React主要用来写HTML页面, 或构建Web应用 如果从MVC的角度来看,React仅仅是视图层(V),也就…...

【Rust项目实战】sensleak,扫描 Git 仓库中的敏感信息
github仓库:https://github.com/open-rust-initiative/sensleak-rs Rust是一门神奇的编程语言,它提供了内存安全、零成本抽象、并发安全等特性,使开发人员能够编写高性能、高抽象和安全的代码。 这是我用rust开发的第一个工作,希望…...

搭建一个定制版New Bing吧
项目介绍 项目地址:https://github.com/adams549659584/go-proxy-bingai 引用项目简介:用 Vue3 和 Go 搭建的微软 New Bing 演示站点,拥有一致的 UI 体验,支持 ChatGPT 提示词,国内可用,国内可用ÿ…...

使用AIGC工具提升论文阅读效率
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…...

本周大新闻|Vision Pro头显重磅发布;苹果收购AR厂商Mira
本周XR大新闻,上周Quest 3发布之后,本周苹果MR头显Vision Pro正式发布,也是本周AR/VR新闻的重头戏。 AR方面,苹果发布VST头显Vision Pro(虽然本质是台VR,但以AR场景为核心)以及visionOS&…...

在Spring Boot微服务使用JedisCluster操作Redis集群String字符串
记录:449 场景:在Spring Boot微服务使用JedisCluster操作Redis集群的String字符串数据类型。 版本:JDK 1.8,Spring Boot 2.6.3,redis-6.2.5,jedis-3.7.1。 1.微服务中配置Redis信息 1.1在pom.xml添加依赖 pom.xml文件: <…...
5.1 合并数据
5.1 合并数据 5.1.1 堆叠合并数据1、横向堆叠 concat()2、纵向堆叠 concat()和append() 5.1.2 主键合并数据 merge()和join()5.1.3 重叠合并数据 combine_first() 5.1.1 堆叠合并数据 堆叠就是简单地把两个表拼在一起,也被称作轴向连接、绑定或连接。依照连接轴的方…...

华为OD机试真题 JavaScript 实现【求解立方根】【牛客练习题】
一、题目描述 计算一个浮点数的立方根,不使用库函数。保留一位小数。 数据范围:∣val∣≤20 。 二、输入描述 待求解参数,为double类型(一个实数) 三、输出描述 输出参数的立方根。保留一位小数。 四、解题思路…...
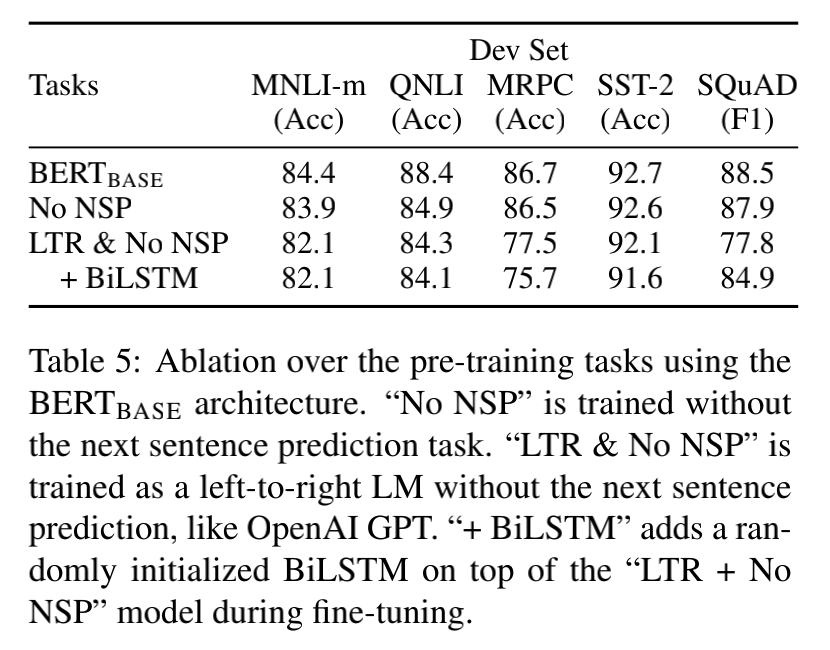
初探BERTPre-trainSelf-supervise
初探Bert 因为一次偶然的原因,自己有再次对Bert有了一个更深层地了解,特别是对预训练这个概念,首先说明,自己是看了李宏毅老师的讲解,这里只是尝试进行简单的总结复述并加一些自己的看法。 说Bert之前不得不说现在的…...

Ficus 第二弹,突破限制器的 Markdown 编辑管理软件!
大家好,我们是 ggG 团队,我们开发的 markdown 笔记管理软件 Ficus Beta 版本正式发布了。详情可以见我们官网,也可以来我们仓库查看。 相对于 Alpha 版本(可以在我们之前的博客中查看),主要有 3 点明显的提…...
基于Springboot+vue+协同过滤+前后端分离+鲜花商城推荐系统(用户,多商户,管理员)+全套视频教程
基于Springbootvue协同过滤前后端分离鲜花商城推荐系统(用户,多商户,管理员)(毕业论文11000字以上,共33页,程序代码,MySQL数据库) 代码下载: 链接:https://pan.baidu.com/s/1mf2rsB_g1DutFEXH0bPCdA 提取码:8888 【运行环境】Idea JDK1.8 Maven MySQL…...
MixQuery系列(一):多数据源混合查询引擎调研
背景 存储情况 当前的存储引擎可谓百花齐放,层出不穷。为什么会这样了?因为不存在One for all的存储,不同的存储总有不同的存储的优劣和适用场景。因此,在实际的业务场景中,不同特点的数据会存储到不同的存储引擎里。 业务挑战 然而异构的存储和数据源,却给分析查询带…...
d2l学习——第一章Introduction
x.0 环境配置 使用d2l库,安装如下: conda create --name d2l python3.9 -y conda activate d2lpip install torch1.12.0 torchvision0.13.0 pip install d2l1.0.0b0mkdir d2l-en && cd d2l-en curl https://d2l.ai/d2l-en.zip -o d2l-en.zip u…...
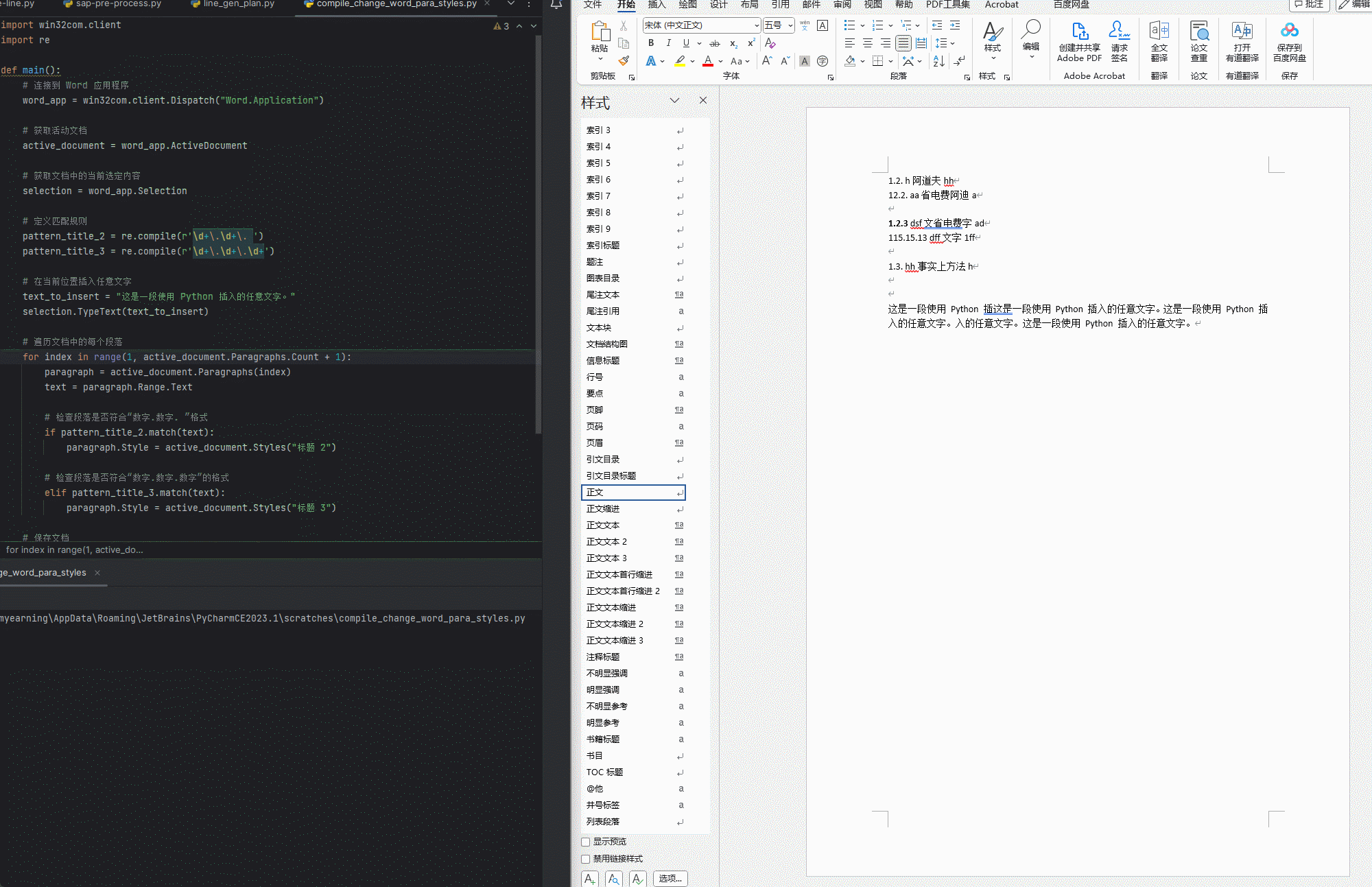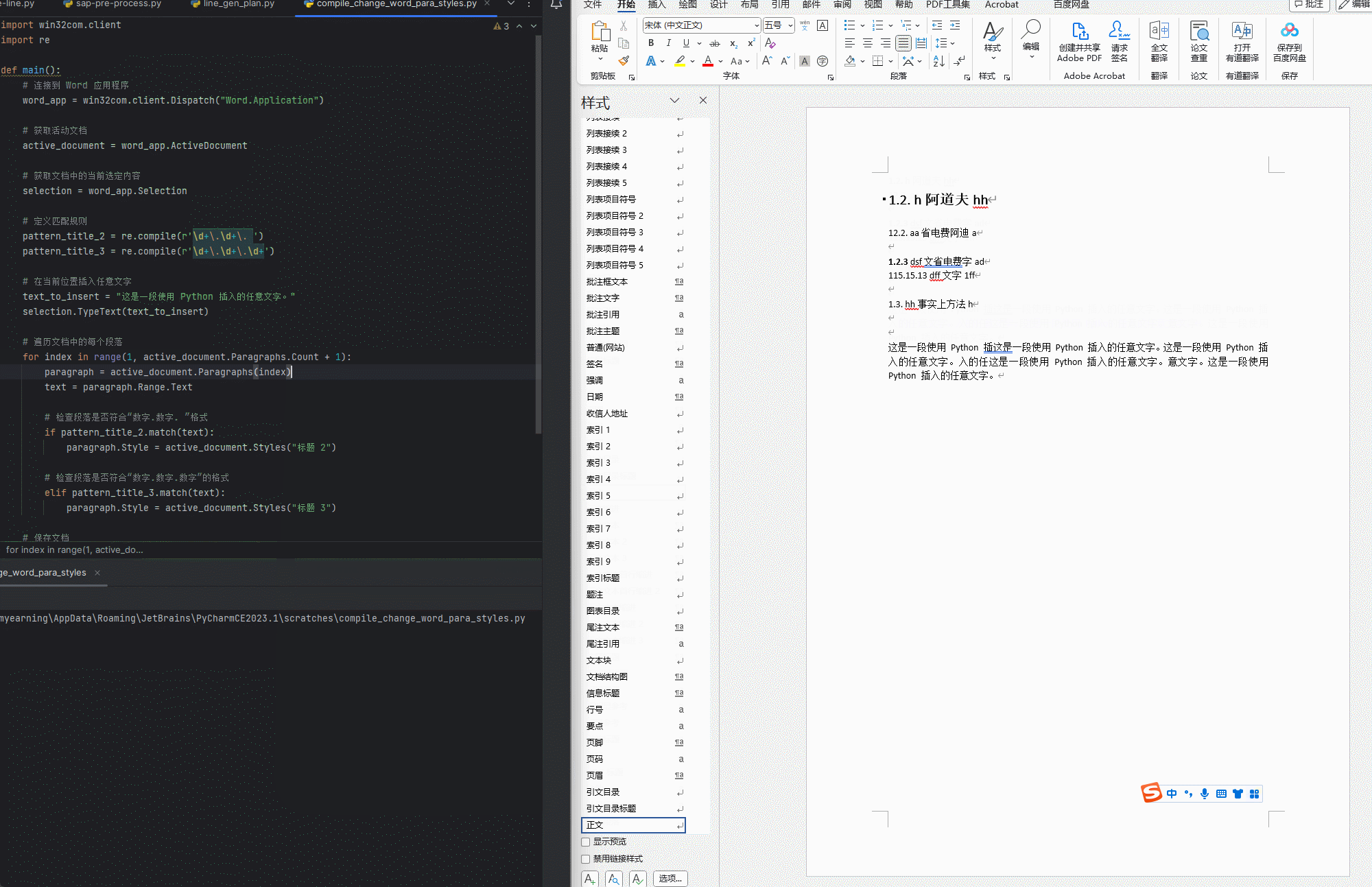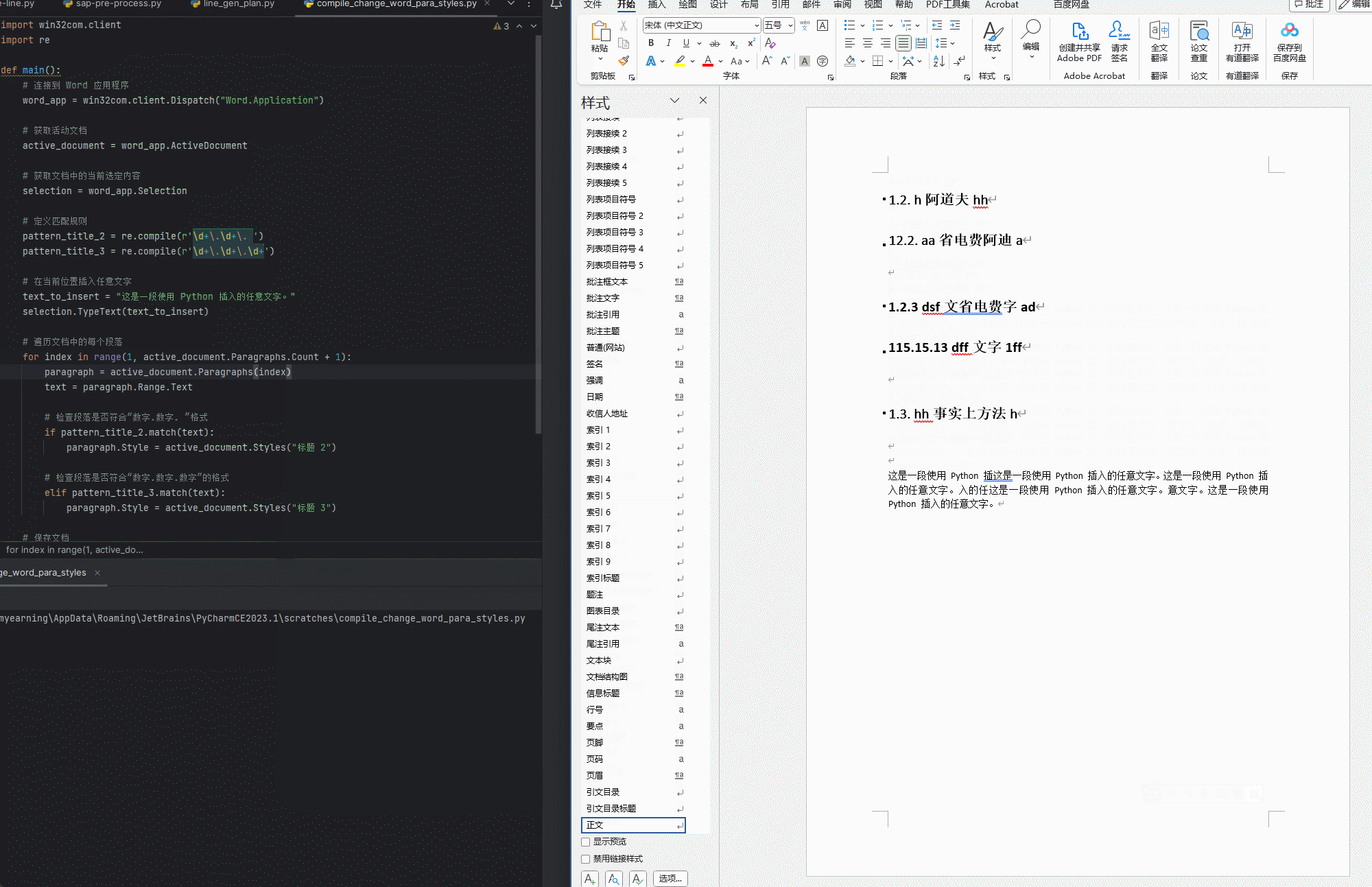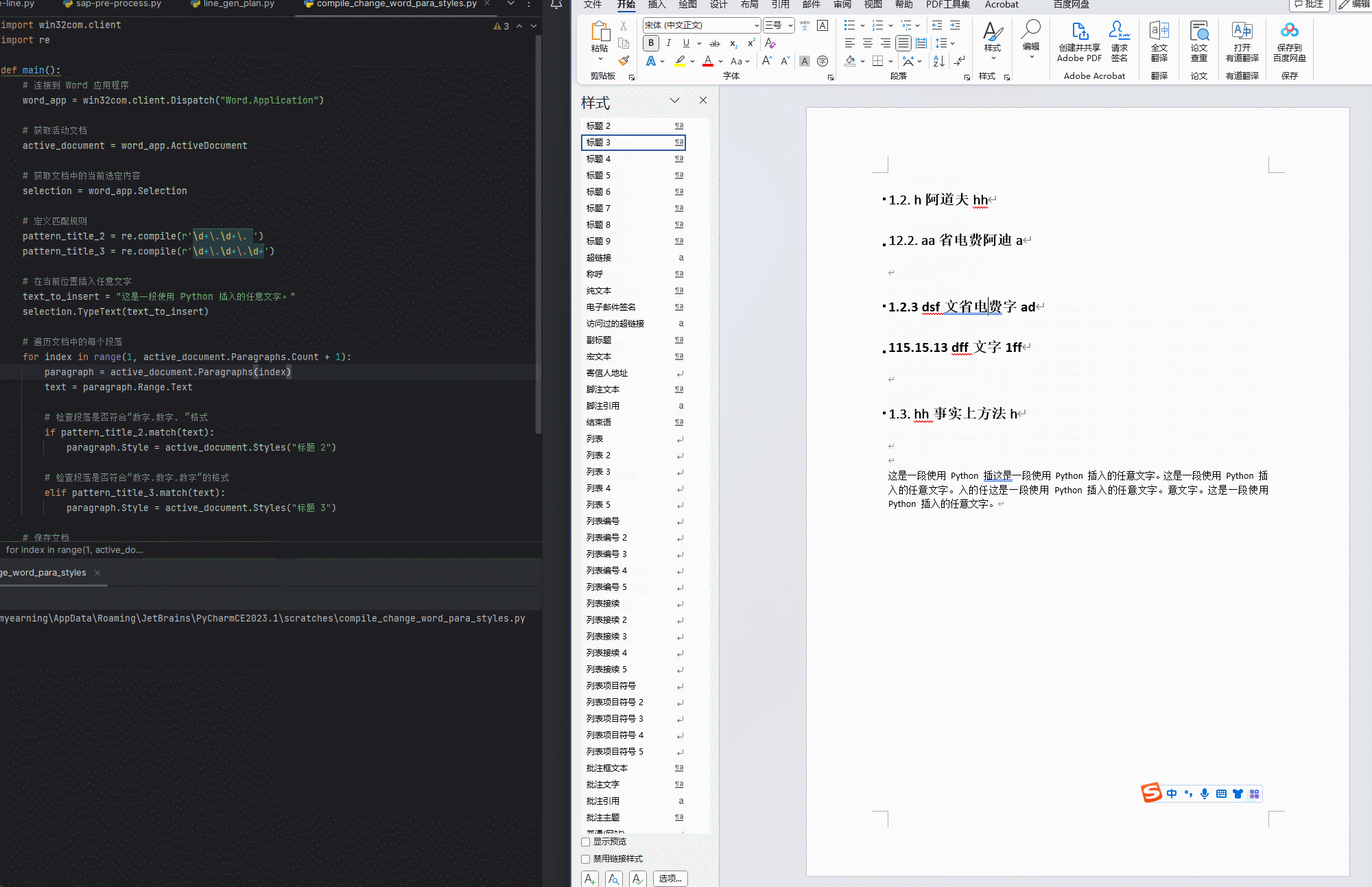
【python】【Word】用正则表达式匹配正文中的标题(未使用样式)并通过win32com指定相应样式
标题的格式 二级标题: 数字.数字. 文字 三级标题:数字.数字.数字 文字 python代码 使用方法 只保留一个需要应用的WORD文档运行程序,逐行匹配 使用效果 代码 import win32com.client import redef compile_change_Word_titlestyle():#…...

Shell脚本工程化:great.sh框架解决运维脚本可维护性难题
1. 项目概述:一个被低估的Shell脚本构建框架如果你和我一样,常年混迹在运维、DevOps或者后端开发领域,那么对Shell脚本的感情一定是复杂的。一方面,它是我们最趁手的“瑞士军刀”,从服务器初始化、日志分析到自动化部署…...

自建团队协作平台TeamClaw:从架构设计到部署运维全指南
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫teamclaw,仓库地址是teamclawai/teamclaw。乍一看这个名字,可能有点摸不着头脑,但深入了解一下,你会发现它瞄准的是一个非常具体且高频的痛点:团…...

Marko导入导出完全指南:掌握模块化组件的终极导入导出机制
Marko导入导出完全指南:掌握模块化组件的终极导入导出机制 【免费下载链接】marko A declarative, HTML-based language that makes building web apps fun 项目地址: https://gitcode.com/gh_mirrors/ma/marko Marko是一款声明式、基于HTML的语言࿰…...

React Native Actions Sheet源码解析:深入理解其架构与实现原理
React Native Actions Sheet源码解析:深入理解其架构与实现原理 【免费下载链接】react-native-actions-sheet A Cross Platform(Android, iOS & Web) ActionSheet with a flexible api, native performance for react native. Create anything you want inside…...

《蔚蓝档案》鼠标指针主题:从设计到安装的完整桌面美化指南
1. 项目概述:为你的桌面注入《蔚蓝档案》的学园气息如果你和我一样,既是《蔚蓝档案》的玩家,又是个喜欢折腾桌面美化的爱好者,那么今天分享的这个项目绝对会让你眼前一亮。它不是什么复杂的软件,而是一套精心制作的Win…...

专业级macOS歌词同步方案:LyricsX核心功能深度解析
专业级macOS歌词同步方案:LyricsX核心功能深度解析 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的专业级歌词同步工具,通过智能歌词…...

SmartNIC如何优化AI流水线与网络计算卸载
1. SmartNIC与AI流水线的联姻:网络计算卸载的技术革命 在分布式AI推理场景中,我们常常遇到一个令人头疼的现象:当GPU计算单元满载运行时,CPU利用率也常常飙升至90%以上。这种资源争用并非来自模型推理本身,而是源于那些…...
)
3dmax动画期末作业全流程分享(附技术细节+避坑指南)
前言:期末将至,相信很多学习3dmax的小伙伴都在为动画期末作业发愁——从创意构思到建模、动画制作,再到渲染输出,每一步都可能遇到各种问题。本次就结合我的期末作业实践,详细分享从前期准备到成品交付的完整流程&…...

高速SerDes设计中BER预测的智能应力输入方法
1. 高速串行链路设计中的BER预测挑战在当今高速数字系统设计中,SerDes(串行器/解串器)技术已成为主流接口方案,数据传输速率已突破10Gbps大关。随着速率提升,信号完整性(SI)问题日益突出,其中误码率(BER)预…...

模块二-数据选择与索引——08. 条件筛选
08. 条件筛选 1. 概述 条件筛选是数据分析中最常用的操作之一。通过布尔表达式,可以快速筛选出满足特定条件的数据行,实现数据过滤、异常检测、子集提取等功能。 import pandas as pd import numpy as np# 创建示例数据 np.random.seed(42) df pd.DataF…...