搜索在计算机中的地位十分重要
无论是在内部系统还是在外部的互联网站上,都少不了检索系统。数据是为了用户而服务。计算机在采集数据,处理数据,存储数据之后,各种客户端的操作pc机或者是移动嵌入式设备都可以很好的获取数据,得到 想要的数据服务。
检索分为SQL过滤查询和全文检索。数据都是放在数据库里,数据库里的数据量太大,要检索到精准的数据是需要很好的用户体验。用户对响应时长要求特别严格,最好控制在一定的响应时间内。SQL查询是普通的字段过滤,一般在没有走全表扫描的情况下都是性能较好的数据查询方式。全文检索的实现方式是在数据库设计的时候就有这些模块,比如MySQL的全文检索。之后在市面上有公司开发了成型的开源产品,比如Lucene等。 学过luncene框架, 能就是论事。在银行工作的时候有接触过es框架,到现在也没仔细去弄懂。每个人的学习能力不一样,有的工程师削尖了脑袋要去专研每个技术。 是在学习Java开发框架的时候接触过Lucene框架, 跟着源码敲了一遍那个搜索引擎。对于那种根据分词查询数据的方式有深刻的映像,但是并不是每个系统都是要使用全文检索分词搜索。
按需开发,意思就是根据需求进行商业开发。以用户体验为中心,金钱盈利为目的。没有谁在为 做无用功,得到与失去,不要去说,也说不准。像普通的字段搜索看起来十分简单,其实就是很简单。但是如果遇到数据量大的情况,或者是用户不会使用系统的情况下,都是有问题的。像百度,Google,搜什么就有什么,这就是全文检索。
搜索,依赖于搜索引擎。搜索引擎的建立是十分困难的事情。以 现在的水平理解的搜索, 能说个大概。 做Java 开发7年时间,虽然没有写过搜索引擎,但是没有经验的同学可以去尝试着实践下。做任何系统都是需要构建bs架构或者是cs架构,cs架构是client-server架构。
在操作系统中有客户端软件开发包,bs架构是broswer-server架构,在所有的数据操作都是在浏览器中实现,把浏览器当做一个子系统,子系统上面又有很多应用程序... bs架构是特殊的cs架构。
在大学学习计算机编程开发,首选的语言是C++。那种语言是写客户端软件, 也是学的很纠结,以为没有很好的效果。大三休学的时候学习了Java,接触全文检索,学习了前端页面的设计开发,后台数据库的建立。到现在有更多的想法和思考。爬虫的建立,爬虫是怎么从网站上爬数据,用户是怎么在网站上面搜索数据。
大学毕业之后对于搜索引擎的理解画了个草图
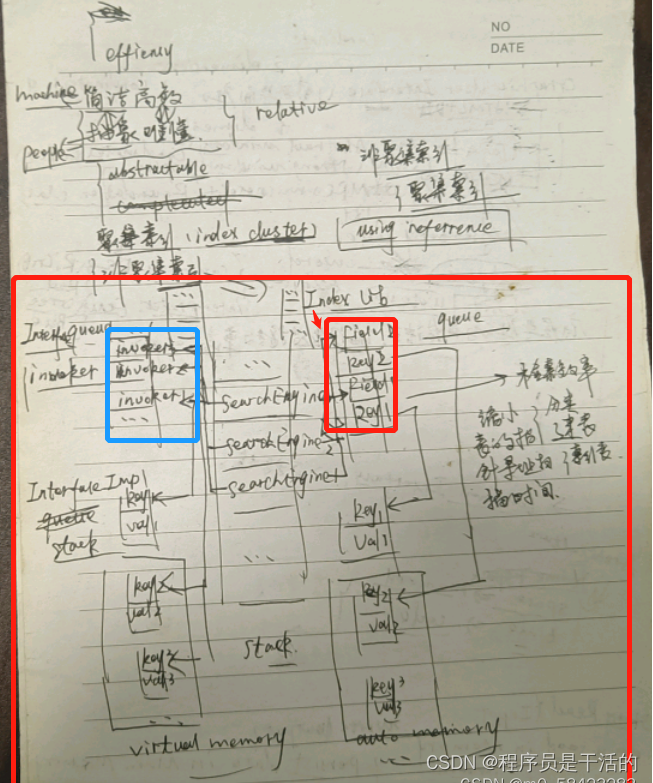
像 爬虫

一般的java IDE的debug是这样设计

爬虫是怎么在网站上爬数据,为什么 能爬网站的数据。现在的web浏览器都支持HTML标签编辑的网页,HTML标签页是dom元素。每个DOM元素都是一个实体对象,在数据库中体现的就是dom元素实体对象表。Dom元素表里存放的就是网页标签所承载的基础数据和一些基本属性。每当一个网站上面的标签包裹的数据发生变化,就要触发数据写write事件,即 WriteEventListener,更新索引库里的索引数据,和文档库里的文档数据。这种数据更新同步方式叫做即时同步方式,是的数据库里的数据和索引库里的数据保持一致性。用户查询数据的时候总能查到最新的数据,用户查数据都是走索引库再走文档库,这样性能更好。
至于怎么构建dom元素数据库,怎么构建dom元素索引库。那些都是商业库,需要开发注册维护,就像 在某个地方开商店一样,需要办理很多手续。
当时学习操作lucene 框架架构方式是通过AOP的方式实现数据同步。数据同步是文档库和索引库的同步操作方式。文档库存放的是Document 文档对象,索引库存放的是字段对象 Field 。字段对象 分为索引文档号和经历过分词器分词之后的关键字集合。中文分词器是Analyzer 堆中文的语句进行分词。
中文的分词器对中文语句的此法进行分析。中文的语句分为 主+谓+宾+定+状+补 . 分词器分为标准的国际分词器和中国大陆简体的中文分词器。原理十分相似,实词和虚词需要区分。实词是名词,虚词是冠词,语气词,称谓词,形容词,状态词,补语词,谓语词 。分词器分析网站上面的文章关键字,中文摘要,具体的文章正文内容。分词器的分词结果生成关键字和文档索引组装成的字段 Field 对象。字段对象集合 fieldList 放在lucene 索引库中。文档库中存放大量的文档对象,文档Document 与 字段 Field 对象的索引表中的文档索引关联。
用户在前端使用日用语句在lucene搜索引擎中搜索数据集合的过程十分复杂。简单的过程可以分为
- 查询语句词的录入接收。
- 后台对中文查询语句分词,抽取关键字形成关键字集合。
- 使用关键字集合在lucene索引库 中的关键字进行匹配,匹配成功会有文档集合 documentList 。
- 文档集合返回给业务逻辑层 service . 使用高亮器hlighter 对文档中的存在的关键词高亮。
- 文档集合的返回通过评分对象 score 综合得分排序。
- 命中文档的得分 score 有默认的得分规则和自定义得分规则。
数据同步在企业项目中使用很多。平安集团的hrx人力资源管理系统使用Elasticsearch 搜索引擎搜索数据。Lucene 和 Elasticsearch 两种引擎搜索数据的方式都是全文检索。全文检索在数据库软件中普遍存在。企业的IDE 开发环境有搜索框的地方或许会有全文检索的影子。软件和应用程序系统都有数据。检索方式分为通过表单的方式和一个表单输入框的方式。一个表单输入框的输入方式面向的用户是大众化的互联网网名。Java 的web信息系统安全新能和开发维护团队有保障,使用sql 查询语句查找数据的方式限制用户量。内部系统的用户量分为内部用户和外围用户。使用sql查询语句查询数据使用全文检索索引库和文档库。数据查询是否全表还是走索引表有用户自定义,系统默认,AI 算法相应的操作模式。
数据同步索引库和文档库中的数据。同步平安银行ES库和PJ 库中的数据。开发任务涉及到项目不同版本发布的同步数据代码。数据量大小和性能问题对于开发工程师是更高级别的操作。保证数据的正确性,代码的质量高低。项目组之间的工程师都会相互借阅不同开发分支的代码。每个开发都会有不同的编写代码的方式。
Elasticsearch 搜索原理和Lucene 类似。每个企业采用的技术架构选型不尽相同。
相关文章:
搜索在计算机中的地位十分重要
无论是在内部系统还是在外部的互联网站上,都少不了检索系统。数据是为了用户而服务。计算机在采集数据,处理数据,存储数据之后,各种客户端的操作pc机或者是移动嵌入式设备都可以很好的获取数据,得到 想要的数据服务。 …...

多模态深度学习:定义、示例、应用
人类使用五种感官来体验和解读周围的世界。我们的五种感官从五个不同的来源和五种不同的方式捕捉信息。模态是指某事发生、经历或捕捉的方式。 人脑由可以同时处理多种模式的神经网络组成。想象一下进行对话——您大脑的神经网络处理多模式输入(音频、视觉、文本、…...

基于ZCU106平台部署Vitis AI 1.2/2.5开发套件【Vivado+Vitis+Petalinux2020/2022】
Vitis AI是 Xilinx 的开发平台,适用于在 Xilinx 硬件平台(包括边缘设备和 Alveo 卡)上进行人工智能算法推理部署。它由优化的IP、工具、库、模型和示例设计组成。Vitis AI以高效易用为设计理念,可在 Xilinx FPGA 和 ACAP 上充分发…...
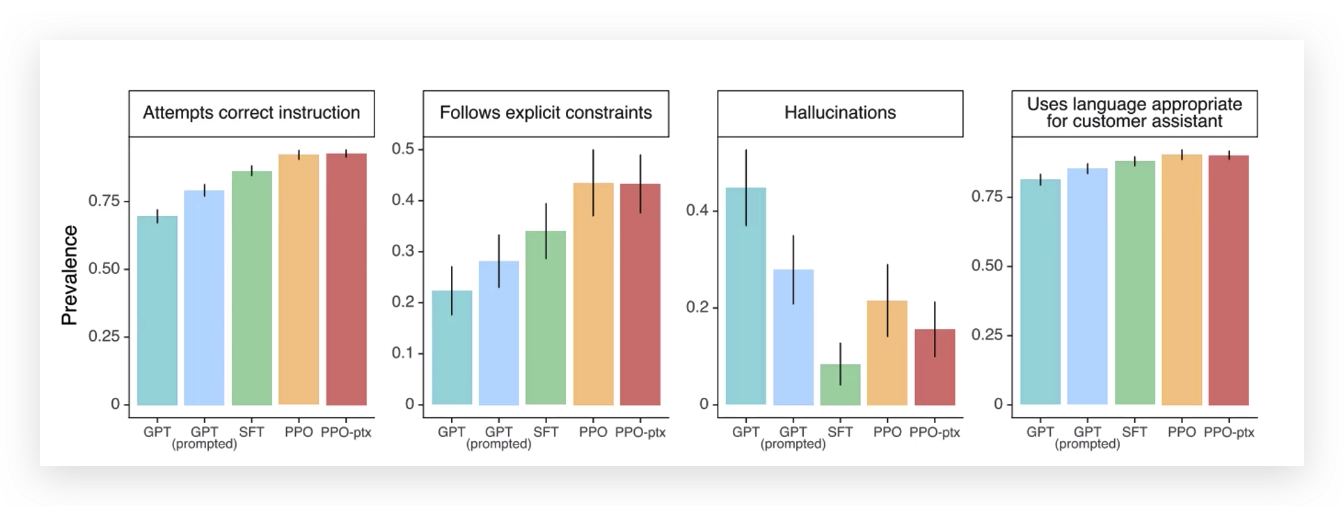
ChatGPT原理简介
承接上文GPT前2代版本简介 GPT3的基本思想 GPT2没有引起多大轰动,真正改变NLP格局的是第三代版本。 GPT3训练的数据包罗万象,上通天文下知地理,所以它会胡说八道,会说的贼离谱,比如让你穿越到唐代跟李白对诗,不在一…...
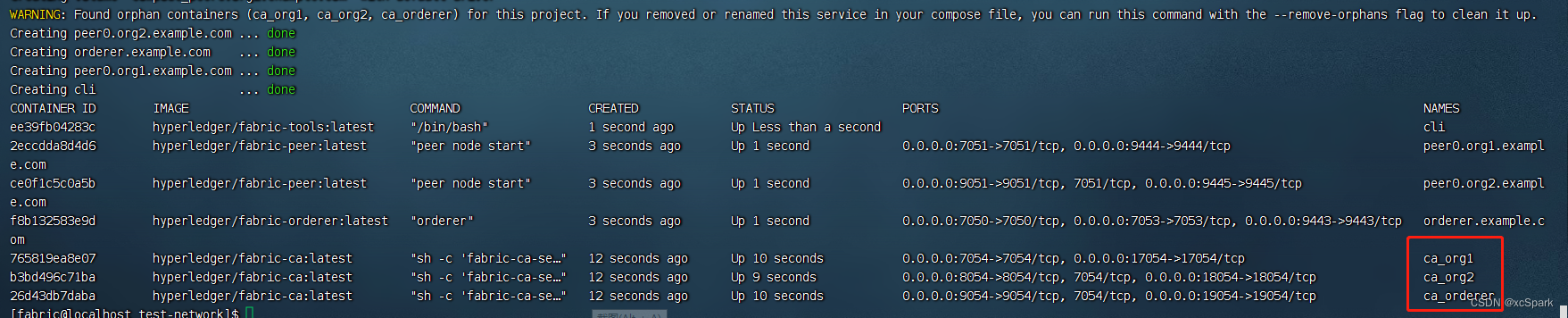
从0搭建Hyperledger Fabric2.5环境
Hyperledger Fabric 2.5环境搭建 一.Linux环境准备 # root登录 yum -y install git curl docker docker-compose tree yum -y install autoconf autotools-dev automake m4 perl yum -y install libtool autoreconf -ivf # 安装jq相关包 cd /opt git clone --recursive https…...

Rust每日一练(Leetday0026) 最小覆盖子串、组合、子集
目录 76. 最小覆盖子串 Minimum Window Substring 🌟🌟🌟 77. 组合 Combinations 🌟🌟 78. 子集 Subsets 🌟🌟 🌟 每日一练刷题专栏 🌟 Rust每日一练 专栏 Gola…...

c# 从零到精通-ArrayList-Hashtable的操作
c# 从零到精通-ArrayList-Hashtable的操作 1、ArrayList的操作 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Collections; namespace Test11 { class Program { static void Main(string[] args) { ArrayList list …...

pnpm带来了什么
首先 pnpm 和 npm yarn 一样是包管理工具,他解决了npm 和 yarn 存在的一些问题 npm3之前每个依赖都是一层嵌套一层的,每个依赖里都有node_modules 用来存放依赖所需的依赖包导致重复下载的依赖包很多,一层层嵌套,嵌套很深&#x…...
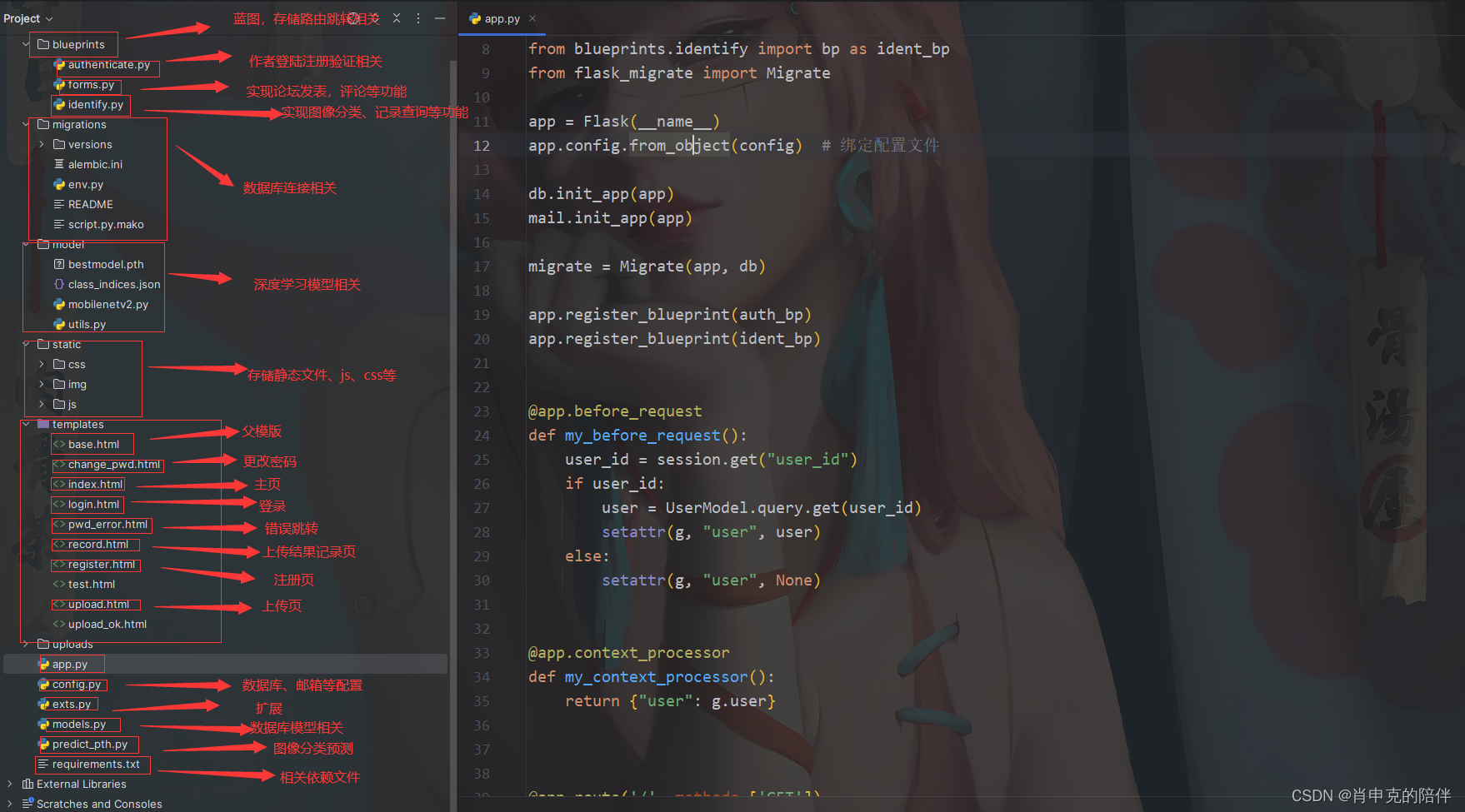
图像分类模型嵌入flask中开发PythonWeb项目
图像分类模型嵌入flask中开发PythonWeb项目 图像分类是一种常见的计算机视觉任务,它的目的是将输入的图像分配到预定义的类别中,如猫、狗、花等。图像分类模型是一种基于深度学习的模型,它可以利用大量的图像数据来学习图像的特征和类别之间…...
GIT安装教程(入门)
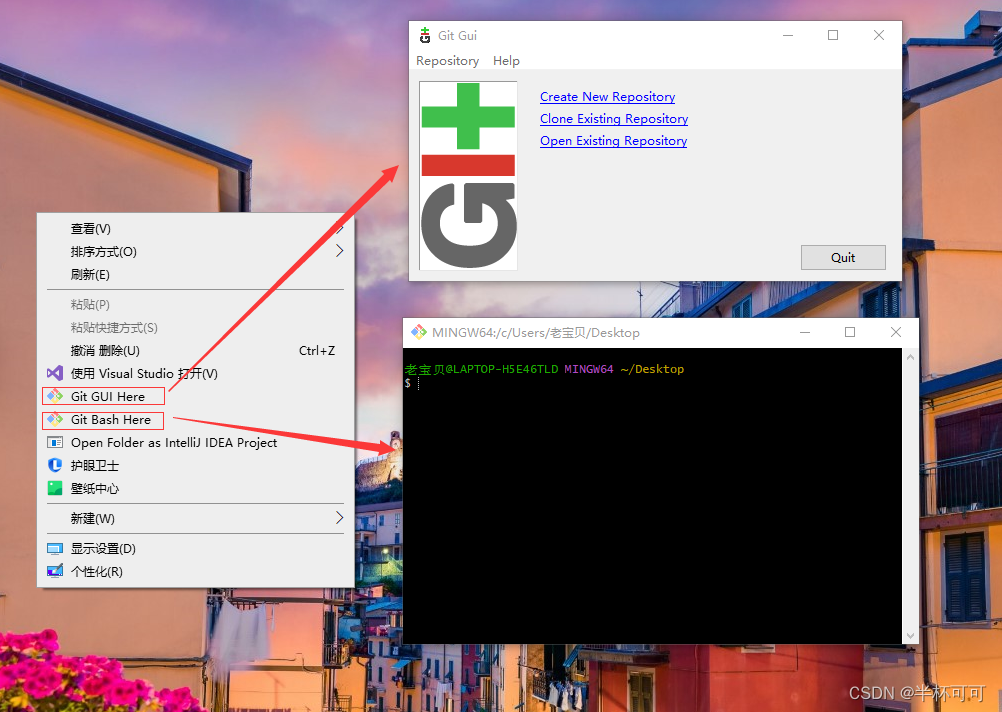
目录 前言 Git作者 官网 GIT优点 GIT缺点 为什么要使用 Git 下载以及安装步骤 一、官网下载 二、GIT安装步骤 1、安装get程序 2、许可声明 3、选择安装路径 4、选择git组件 5、创建菜单名称 6、 git文件默认编辑器 7、设置新存储库中初始分支的名称 8、调整Pa…...

全志V3S嵌入式驱动开发(触摸屏驱动)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 所谓的触摸屏,其实就是在普通的lcd屏幕之上,再加一层屏而已。这个屏是透明的,这样客户就可以看到下面lcd屏幕的…...

死信队列详解
什么是死信队列? 在消息队列中,执行异步任务时,通常是将消息生产者发布的消息存储在队列中,由消费者从队列中获取并处理这些消息。但是,在某些情况下,消息可能无法正常地被处理和消耗,例如&…...
:北京卷I)
我用ChatGPT写2023高考语文作文(五):北京卷I
2023年 北京卷 I 适用地区:北京 “续航”一词,原指连续航行,今天在使用中被赋予了新的含义,如为青春续航、科技为经济发展续航等。 请以“续航”为题目,写一篇议论文。 要求:论点明确,论据充实&…...
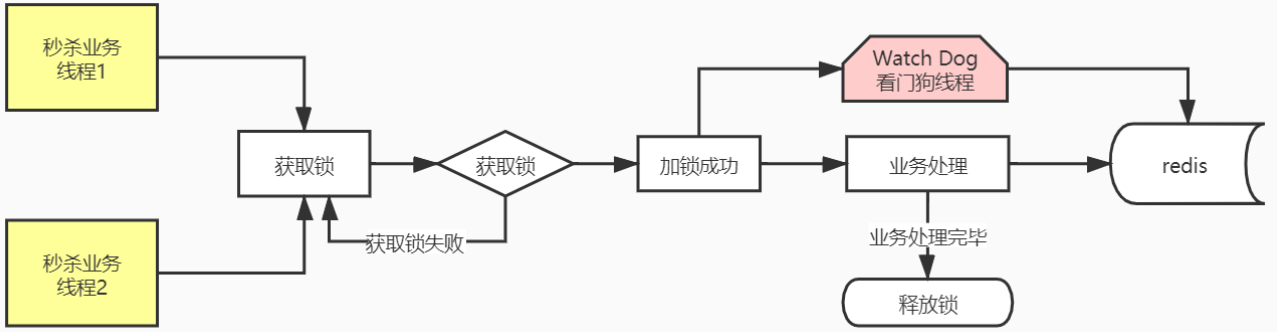
《微服务实战》 第二十八章 分布式锁框架-Redisson
前言 Redisson 在基于 NIO 的 Netty 框架上,充分的利⽤了 Redis 键值数据库提供的⼀系列优势,在Java 实⽤⼯具包中常⽤接⼝的基础上,为使⽤者提供了⼀系列具有分布式特性的常⽤⼯具类。使得原本作为协调单机多线程并发程序的⼯具包获得了协调…...

局部搜索,变邻域搜索算法
目录 局部搜索 02 变邻域搜索算法 局部搜索 1.1 局部搜索是什么玩意儿? 官方一点:局部搜索是解决优化问题的一种启发式算法。对于某些计算起来非常复杂的优化问题,比如各种NP-难问题,要找到最优解需要的时间随问题规模呈指数增长,因此诞生了各种启发式算法来退而求其次…...

软件工程实训——第一天
第一天 前后分离 前端:android 后端:springbootmbatis-plus 高心星 软件工程的思维来开发项目 问题定义 可行性研究 需求分析 概要设计 详细设计 编码 测试 维护 需求分析 1.用户的信息管理 2.新增支出 3.新增收入 4.支出统计 5.收入…...
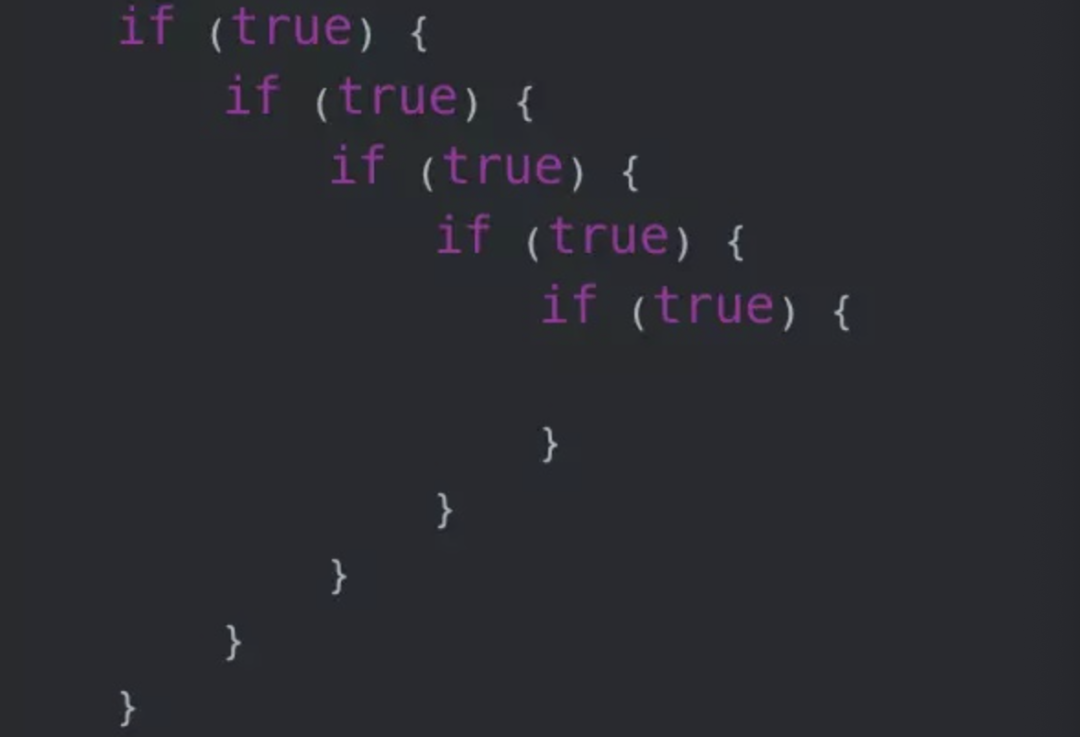
嵌入式C语言中if/else如何优化详解
观点一(灵剑): 前期迭代懒得优化,来一个需求,加一个if,久而久之,就串成了一座金字塔。 当代码已经复杂到难以维护的程度之后,只能狠下心重构优化。那,有什么方案可以优雅…...

【LSTM】读取时间序列数据 | 时间序列数据的小批量划分方法
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。当序列过长而不能被模型一次性全部处理时,我们希望能拆分这样的序列以便模型方便读取。 Q:怎样随机生成一个具有n个时间步的mini batch的特征和标签? A&…...
K8s in Action 阅读笔记——【12】Securing the Kubernetes API server
K8s in Action 阅读笔记——【12】Securing the Kubernetes API server 12.1 Understanding authentication 在上一章中,我们提到API服务器可以配置一个或多个认证插件(授权插件也是同样的情况)。当API服务器接收到一个请求时,它…...
爆肝整理,3个月从功能进阶自动化测试,一跃成测试卷王...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 首先先了解自动化…...

在Docker环境中安装Hadoop cluster 实验报告三
在Docker环境中安装Hadoop cluster 实验报告三 1个namenode, 3个datanodes 班 级:物联网2303 学 号:231040700302 姓 名:杜子健 (30%) 安装过程 ContainersHadoop 1.1 Containers 创建与配置 (1)拉取稳定镜像…...

在ubuntu上为nodejs后端服务接入taotoken多模型api的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 上为 Node.js 后端服务接入 Taotoken 多模型 API 的步骤 为后端服务集成大模型能力是现代应用开发的常见需求。如果你在…...

MIKE IO 终极指南:Python高效处理MIKE水文数据的完整教程
MIKE IO 终极指南:Python高效处理MIKE水文数据的完整教程 【免费下载链接】mikeio Read, write and manipulate dfs0, dfs1, dfs2, dfs3, dfsu and mesh files. 项目地址: https://gitcode.com/gh_mirrors/mi/mikeio MIKE IO 是DHI集团推出的专业Python开源库…...

思源宋体完全指南:7种字体样式免费商用,打造专业中文排版
思源宋体完全指南:7种字体样式免费商用,打造专业中文排版 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为设计项目寻找既专业又免费的中文字体而烦恼吗&a…...

基于 4SAPI 的企业文档智能处理系统:效率提升 20 倍,信息提取准确率 95%
前言 在数字化转型的今天,企业积累了海量的非结构化文档数据,包括合同、财务报表、技术手册、产品说明书、会议纪要、法律文件等。这些文档中蕴含着企业最核心的知识和资产,但传统的人工文档处理模式已经成为企业数字化的最大瓶颈࿱…...

SoC设计中虚拟原型技术与TLM建模实践
1. 虚拟原型技术概述在SoC设计领域,虚拟原型技术(Virtual Prototyping)已经成为现代芯片开发流程中不可或缺的关键环节。这项技术的核心价值在于,它能够在RTL级硬件设计完成之前,就为软件团队提供一个可执行的硬件抽象模型。作为一名经历过多…...

从Kaggle竞赛到现实应用:聊聊ResNet18在驾驶安全监控中的潜力与局限
从Kaggle竞赛到现实应用:ResNet18在驾驶安全监控中的潜力与局限 当计算机视觉技术走出实验室,真正进入驾驶安全监控这样的关键场景时,我们需要思考的远不止模型在测试集上的准确率。ResNet18作为轻量级深度网络的代表,其在Kaggle竞…...

ClawSpark:一键部署私有AI智能体,实现本地化智能助手
1. 项目概述:ClawSpark,一键部署的私有AI智能体如果你和我一样,对AI智能体(Agent)的潜力感到兴奋,但又对将个人数据、工作流程乃至核心业务逻辑完全托付给云端API心存疑虑,那么ClawSpark的出现&…...

构建自动化编译系统:Makefile递归遍历与智能目录生成实践
1. 为什么需要自动化编译系统 如果你曾经维护过一个包含几十个源文件的中大型C/C项目,肯定经历过这样的痛苦:每次新增一个源文件,都要手动修改Makefile;项目结构调整时,编译规则需要全部重写;不同模块之间的…...

为什么你的Windows桌面总是乱糟糟?NoFences免费桌面分区终极解决方案
为什么你的Windows桌面总是乱糟糟?NoFences免费桌面分区终极解决方案 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱无章的桌面图标而烦恼吗ÿ…...