【Sqlite3】maraidb和sqlite3部分命令操作区别
maraidb和sqlite3部分命令操作区别记录
1.安装sqlite3
在实现我的视频点播系统项目时,我尝试封装了两种数据库的调用逻辑
- mysql(maraidb)
- sqlite3
这里封装sqlite3的原因是,sqlite3主要针对的就是嵌入式数据库,其性能可能不如mysql,但是就好在可以带着走。安装也很方便,内存占用相对于mariadb来说也降低了很多。
教程:安装maraidb
在上面的博客中,安装maraidb需要很多步骤,还需要修改配置文件中的默认字符集为UTF8。
而安装sqlite3就要多方便有方便了,而且sqlite3默认采用的就是uft8字符集,完全不需要修改!
sudo yum install sqlite-devel
就这一行命令就搞定了!
sqlite3 --version #查看当前安装的版本
安装完成后,可以看看sqlite3的版本(如果没有安装,执行这个命令会告知 command not found)
[root@1c2261732150:~]# sqlite3 --version
3.26.0 2018-12-01 12:34:55 bf8c1b2b7a5960c282e543b9c293686dccff272512d08865f4600fb58238alt1
2.基本操作的区别
如下列出一些基本操作在mariadb命令行中,和在sqlite3命令行中的区别
为了方便,注释中m指代mysql,s指代sqlite3
show databases; -- 查看所有数据库 mariadb
.database -- 查看当前数据库 sqlite3use db_name; -- 进入数据库 m
.open db_name.db; -- 提供.db文件的路径,进入数据库 sshow tables; -- 查看数据库中所有表 m
.tables -- 查看数据库中所有表 squit -- 退出数据库命令行 m
.quit -- 退出数据库命令行 s
这便是基础操作的一些区别,更深入的操作我暂时还没有学到。
其中进入数据库的操作就能看出来sqlite的特性,只要有这个.db文件,你就可以很轻松的在另外一个主机上恢复之前的数据(或者进行备份),这也是带着走的体现。
3.创建表
mysql和sqlite3所支持的数据类型也有区别
| sqlite3数据类型 | 描述 |
|---|---|
| NULL | 值是一个 NULL 值。 |
| INTEGER | 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中。 |
| REAL | 值是一个浮点值,存储为 8 字节的 IEEE 浮点数字。 |
| TEXT | 值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储。 |
| BLOB | 值是一个 blob 数据,完全根据它的输入存储。 |
在sqlite3中,没有varchar类型。但我们依旧可以使用TEST(8)来限制字符串类型的长度
以我的视频点播项目所用数据库为例,以下是mariadb创建数据表的sql语句
create table tb_video(id VARCHAR(8) NOT NULL DEFAULT (substring(UUID(), 1, 8)) comment '视频id',name VARCHAR(50) comment '视频标题',info text comment '视频简介',video VARCHAR(255) comment '视频链接',cover VARCHAR(255) comment '视频封面链接',insert_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP comment '视频创建时间'
);
在这里我采用了mariadb自带的uuid函数来生成uuid字符串,并使用substring函数截取了uuid前8位的内容,作为视频的唯一id
而如果想让mariadb来保证id字段唯一,可以使用如下命令进行约束
create table tb_video(id VARCHAR(8) NOT NULL DEFAULT (substring(UUID(), 1, 8)) comment '视频id',name VARCHAR(50) comment '视频标题',info text comment '视频简介',video VARCHAR(255) comment '视频链接',cover VARCHAR(255) comment '视频封面链接',insert_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP comment '视频创建时间',UNIQUE (id)
);
以下是sqlite3的操作,sqlite3中并不支持comment对字段进行注释。
这里要想让id字段唯一,直接在字段类型后面跟着UNIQUE就可以了
-- sqlite3中不支持uuid函数,所以需要用randomblob函数生成一个随机数,再用hex转成16进制作为视频的id
-- sqlite3默认的时间是utc,所以需要用datetime函数将其转化为东八区的时间
CREATE TABLE IF NOT EXISTS tb_video(id TEXT(8) UNIQUE NOT NULL DEFAULT (lower((hex(randomblob(4))))),name TEXT NOT NULL,info TEXT,video TEXT NOT NULL,cover TEXT NOT NULL,insert_time TIMESTAMP DEFAULT (datetime('now', '+8 hours'))
);
4.插入删除数据
在我项目所用字段中,二者插入/删除数据的操作完全相同,这里就不记录了
-- 删除表
drop table tb_video;
-- 插入数据
insert into tb_video (name, info, video, cover) values ('名字1','说明信息1','test1','testc1');
-- 查看所有字段
select * from tb_video;
select * from tb_video where id='45f78a68';
-- 删除数据
delete from tb_video where id = 'D81382A8';
5.使用cpp操作的时候
- mysql必须要进行init,此时就需要指定目标数据库了
- 而sqlite3并不需要进行数据库的连接操作,我们就可以实现在cpp中进行数据库的创建、数据表的创建等操作。
c语言操作sqlite3的方法,可以查看菜鸟教程。上面的用例很详细(虽然没有写注释,但还是能看懂的)我就不写博客了~
5.1 查询时的回调
这里只对select命令操作进行说明,在sqlite3中,所有命令都是用下面这个函数来执行的
SQLITE_API int sqlite3_exec(sqlite3*, /* An open database */const char *sql, /* SQL to be evaluated */int (*callback)(void*,int,char**,char**), /* Callback function */void *, /* 1st argument to callback */char **errmsg /* Error msg written here */
);
如果你执行的是插入、更新等等sql语句,sqlite_callback函数不会被调用(我测试过了)。目前我只发现select语句会调用这个callback函数。
比如我的数据库tb_video中有如下两行数据
df65c8c5|名字1|说明信息1|test1|testc1|2023-05-04 16:57:10
80cd3f51|名字1|说明信息1|test1|testc1|2023-05-04 19:02:05
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>// 每当有结果返回的时候,用这个函数来处理结果
// 第一个参数可以从sqlite3_exec中主动传入
// argc 是结果的行数(二维数组行数)
// argv 是存放数据的二维数组
// azColName 是存放字段名称的二维数组
static int callback(void *NotUsed, int argc, char **argv, char **azColName)
{int i;for (i = 0; i < argc; i++){printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");}printf("\n");return 0;
}
// sqlite3数据库打开测试
void SqliteTest()
{sqlite3 *db;// 数据库指针char *zErrMsg = 0;std::string sql;int ret;// 打开数据库文件if (sqlite3_open("test.db", &db)){fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));exit(0);}else{fprintf(stderr, "Opened database successfully\n");}sql = "select * from tb_video;";// 执行sql语句ret = sqlite3_exec(db, sql.c_str(), callback, 0, &zErrMsg);if (ret != SQLITE_OK){fprintf(stderr, "SQL error: %s\n", zErrMsg);sqlite3_free(zErrMsg);}else{fprintf(stdout, "SQL successfully\n");}sqlite3_close(db);
}
用这个函数来查询,会打印如下的结果。从这个结果中,就能推测出callback函数4个参数分别的作用,已经在代码的注释中说明了。
Opened database successfully
id = df65c8c5
name = 名字1
info = 说明信息1
video = test1
cover = testc1
insert_time = 2023-05-04 16:57:10id = 80cd3f51
name = 名字1
info = 说明信息1
video = test1
cover = testc1
insert_time = 2023-05-04 19:02:05其中,第四个参数是给callback函数传入的第一个入参。
5.2 通过回调插入数据到Json字符串
我的视频点播项目在查询的时候,需要将结果保存为json字符串,如果使用mysql的c++操作,就可以直接在遍历结果的二维数组时,将结果放入到Json::Value中
// 查询所有-输出所有视频信息(视频列表)bool SelectAll(Json::Value *video_s){#define SELET_ALL "select * from %s;"std::string sql;sql.resize(512);sprintf((char*)sql.c_str(),SELET_ALL,_video_table.c_str());// 这里加锁是为了保证结果集能被正常报错(并不是防止修改原子性问题,mysql本身就已经维护了原子性)// 下方执行语句后,如果不保存结果集 而又执行一次搜索语句,之前搜索的结果就会丢失// 加锁是为了保证同一时间只有一个执行流在进行查询操作,避免结果集丢失_mutex.lock();// 语句执行失败了if (!MysqlQuery(_mysql, sql)) {_mutex.unlock();_log.error("Video SelectAll","query failed");return false;}// 保存结果集到本地MYSQL_RES *res = mysql_store_result(_mysql);if (res == nullptr) {_mutex.unlock();_log.error("Video SelectAll","mysql store result failed");return false;}// 遍历结果集,存到json中int num_rows = mysql_num_rows(res);//获取结果集的行数for (int i = 0; i < num_rows; i++) {MYSQL_ROW row = mysql_fetch_row(res);//获取每一行的列数Json::Value video;video["id"] = row[0];video["name"] = row[1];video["info"] = row[2];video["video"] = row[3];video["cover"] = row[4];video["insert_time"] = row[5]; //mysql中存放的就是可读时间 (其实存时间戳更好)//json listvideo_s->append(video);}mysql_free_result(res);//释放结果集_mutex.unlock();_log.info("Video SelectAll","select all finished");return true;}
而在sqlite3中,就需要使用callback函数的第一个参数来进行json字符串的保存;这里因为sqlite3会给我们返回字段名字,我们就可以直接用字段明作为json的字段名,将参数作为json字段的对应参数。更省事了!
static int callback(void *json_videos, int argc, char **argv, char **azColName)
{Json::Value* video_s = (Json::Value*)json_videos;//转为原本的类型Json::Value video;//单个视频for (int i = 0; i < argc; i++){video[azColName[i]] = argv[i] ? argv[i] : "NULL";//存入数据printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");}printf("\n");video_s->append(video);//插入到json数组中return 0;
}
在主函数中,创建一个Json::Value对象,将其强转为void*的指针,传给callback函数
// 查询Json::Value videos;sql = "select * from tb_video;";// 执行sql语句ret = sqlite3_exec(db, sql.c_str(), callback, (void*)&videos, &zErrMsg);if (ret != SQLITE_OK){fprintf(stderr, "SQL error: %s\n", zErrMsg);sqlite3_free(zErrMsg);}else{fprintf(stdout, "Table created successfully\n");}sqlite3_close(db);std::string json_str;vod::JsonUtil::Serialize(videos,&json_str);std::cout << json_str << std::endl;
编译执行,最终打印的json字符串如下(完整代码见 Github)
[{"cover" : "testc1","id" : "df65c8c5","info" : "\u8bf4\u660e\u4fe1\u606f1","insert_time" : "2023-05-04 16:57:10","name" : "\u540d\u5b571","video" : "test1"},{"cover" : "testc1","id" : "80cd3f51","info" : "\u8bf4\u660e\u4fe1\u606f1","insert_time" : "2023-05-04 19:02:05","name" : "\u540d\u5b571","video" : "test1"}
]
5.3 对表的查询
除了使用sqlite3_exec针对数据库进行操作,还可以用下面这个函数,对指定的表进行查询
int sqlite3_get_table(sqlite3* db, /* 数据库连接 */const char *zSql, /* 查询语句 */char ***pazResult, /* 查询结果 */int *pnRow, /* 查询结果的行数 */int *pnColumn, /* 查询结果的列数 */char **pzErrmsg /* 错误信息 */
);
参数说明如下,这里就比较类似mysql的查询函数了,其会给我们返回结果集,以及结果的行数、列数,让我们自己遍历进行操作。
db: 数据库连接对象,是已经打开的数据库连接。zSql: 执行的 SQL 查询语句。pazResult: 一个 char 类型的指针数组(二维,每一行是一个指针,指向一个字符串),用于存储查询结果。每个元素都指向一个表示每行数据的字符串数组。最后一个元素为 NULL。pnRow: 用于存储查询结果的行数。pnColumn: 用于存储查询结果的列数。pzErrmsg: 用于存储错误信息。
sqlite3_get_table 函数执行查询语句时,结果集中的每个单元格都被解释为一个字符串。查询结果将被存储在指针数组 pazResult 中,每行数据占用一个字符串数组(除了最后一个元素为 NULL)。表格的第一行包含列名,后面的每行则为查询结果中的一条记录。
sqlite3_get_table 函数的作用是执行一条 SQL 查询语句,并将其结果存储在一个表格中,以便后续处理和分析。
调用完毕这个函数,处理完结果集后,需要调用如下函数释放结果集。
char **pazResult; /* 二维指针数组,存储查询结果 */
int nRow = 0, nColumn = 0;/* 获得查询结果的行数和列数 */
sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);
// 遍历处理结果集
// ....
sqlite3_free_table(pazResult);// 处理完毕结果集后释放
5.3.1 错误示例
如下是一个示例的错误代码!
char **pazResult; /* 二维指针数组,存储查询结果 *//* 获得查询结果的行数和列数 */int nRow = 0, nColumn = 0,index=0;sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);std::cout << nRow << " " << nColumn << std::endl;for (int i = 0; i < nRow; i++){for (int j = 0; j < nColumn; j++){printf("%-8s : %-8s\n", pazResult[j],pazResult[i][j]);}}sqlite3_free_table(pazResult);
编译不会出错,但是执行的时候,直接会出现段错误
Opened database successfully
2 6
Segmentation fault
这是因为我们的pazResult只是一个二级指针,我们并没有给他初始化为多少行多少列的模式,导致最终++的时候,会出现访问错位的情况。
如果改成下面这样的打印
cout << pazResult[j] << endl;cout << "--" << endl;cout << pazResult[i][j] << endl;cout << "---" << endl;
打印的结果就是这样的,合计是在遍历每一个字符串!
id
--
i
---
name
--
d
---
info
-----
video
-----
cover
-----
insert_time
--
后面重复的就省略掉了
为什么不行呢?这是因为pazResult实际上的结构是这样的
id
name
info
video
cover
insert_time
df65c8c5
名字1
说明信息1
test1
testc1
2023-05-04 16:57:10
使用pazResult[i][j]进行访问:
- 当i是0的时候,访问的是
id字符串 - 此时
j就变成id字符串里面的下标了 - 而
nColumn远大于id字符串的长度(id只有两个字符,而在我这里nColumn=6) - 所以就出现了段错误
Segmentation fault!
我还是学艺不精呀!🤣
5.3.2 正确操作
正确的办法应该是这样的
Json::Value videos;char **pazResult; /* 二维指针数组,存储查询结果 *//* 获得查询结果的行数和列数 */int nRow = 0, nColumn = 0,index=0;sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);std::cout << nRow <<" " << nColumn << std::endl;index = nColumn;//从第二列开始,跳过第一行(第一行都是字段名)for (int i = 0; i < nRow; i++){for (int j = 0; j < nColumn; j++){// 前nColumn个数据都是字段名,所以可以用 pazResult[j] 来打印printf("%-8s : %-8s\n", pazResult[j],pazResult[index]);index++;}}sqlite3_free_table(pazResult);
成功打印出了数据库中两行的数据
Opened database successfully
2 6
id : df65c8c5
name : 名字1
info : 说明信息1
video : test1
cover : testc1
insert_time : 2023-05-04 16:57:10
id : da6d27be
name : 名字2
info : 说明信息2
video : test2
cover : testc2
insert_time : 2023-05-04 19:59:38
和从数据库命令行中读取到的结果相同
sqlite> select * from tb_video;
df65c8c5|名字1|说明信息1|test1|testc1|2023-05-04 16:57:10
da6d27be|名字2|说明信息2|test2|testc2|2023-05-04 19:59:38
最终的完整代码如下
void SqliteTest()
{sqlite3 *db; // 数据库指针char *zErrMsg = 0;std::string sql;int ret;// 打开数据库文件if (sqlite3_open("test.db", &db)){fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));exit(0);}else{fprintf(stderr, "Opened database successfully\n");}// 查询Json::Value videos;char **pazResult; /* 二维指针数组,存储查询结果 *//* 获得查询结果的行数和列数 */int nRow = 0, nColumn = 0;sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);std::cout << nRow <<" " << nColumn << std::endl;int index = nColumn;//从第二列开始,跳过第一行(第一行都是字段名)for (int i = 0; i < nRow; i++){Json::Value video;for (int j = 0; j < nColumn; j++){// 前nColumn个数据都是字段名,所以可以用 pazResult[j] 来打印// printf("%-8s : %-8s\n", pazResult[j],pazResult[index]);video[pazResult[j]] = pazResult[index] ?pazResult[index] : "NULL"; // 存入数据index++;}// json listvideos.append(video);}std::string json_str;vod::JsonUtil::Serialize(videos, &json_str);std::cout << json_str << std::endl;sqlite3_free_table(pazResult);sqlite3_close(db);
}
完整输出如下,json字符串内的数据是正确的!
Opened database successfully
2 6
[{"cover" : "testc1","id" : "df65c8c5","info" : "\u8bf4\u660e\u4fe1\u606f1","insert_time" : "2023-05-04 16:57:10","name" : "\u540d\u5b571","video" : "test1"},{"cover" : "testc2","id" : "da6d27be","info" : "\u8bf4\u660e\u4fe1\u606f2","insert_time" : "2023-05-04 19:59:38","name" : "\u540d\u5b572","video" : "test2"}
]
sqlite3在返回数据的时候也会给我们返回表中的字段名。我们可以将json字段的key设置成字段名,这样就实现了字段的统一
个人认为,为了避免出现同一value而key不同的情况,最好是将应用层和数据库中的字段统一。否则出现二义性问题不好排查。特别是当一个表中的字段较多的时候。
结语
需要注意的是,二者只是适用范围的区别,并没有孰强孰弱的差距。
以下是gpt3.5对二者区别的总结:
SQLite3 和 MySQL 都是流行的关系型数据库管理系统,但它们有不同的用途和设计重点。
- SQLite3 的主要目标是作为嵌入式数据库使用,包括在移动设备和桌面应用程序中,也可以作为轻量级数据库使用。相比之下,MySQL 的主要重点是支持大型企业级应用程序和高负载服务器。
- SQLite3 是一个服务器不需要客户端的完全独立的自包含数据库,MySQL 是一个客户端/服务器模型的数据库,需要一个专用的服务器端。
- SQLite3 支持 SQL-92 标准的基本功能,而 MySQL 支持更广泛的 SQL 标准以及许多扩展功能。
- SQLite3 的数据存储在单个文件中,而 MySQL 的数据通常存储在多个文件或分布式系统中。
就记录这么多吧!
相关文章:

【Sqlite3】maraidb和sqlite3部分命令操作区别
maraidb和sqlite3部分命令操作区别记录 1.安装sqlite3 在实现我的视频点播系统项目时,我尝试封装了两种数据库的调用逻辑 mysql(maraidb)sqlite3 这里封装sqlite3的原因是,sqlite3主要针对的就是嵌入式数据库,其性能…...

Linux中新建用户使用sudo问题
文章目录 sudo问题 sudo问题 sudo:权限提示指令,当使用sudo这条指令时,会将普通用户的权限提升为root权限 但是在命令行新建用户,这个用户使用sudo指令对一条指令提权是用不了的 这个用户没有在sudoers file这个文件中ÿ…...
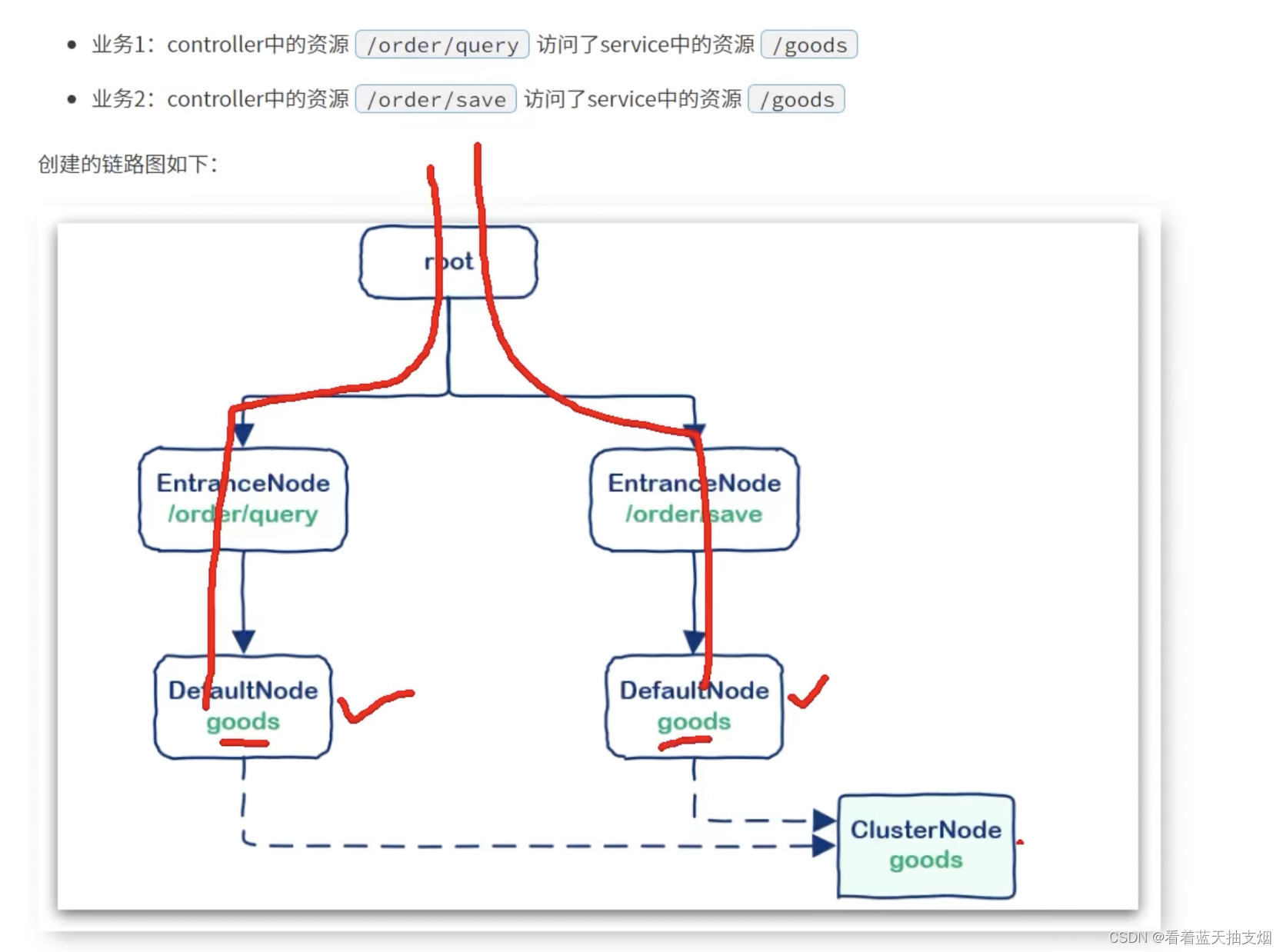
Sentinel源码分析-ProceesorSlotChain调用链及树状资源节点
Sentinel 实现流控,隔离,降级等功能,本质要做两件事: 数据统计: 统计某个资源的访问数据(QPS,RT(响应时间),异常比例)等信息规则判断: 判断流控规…...

springboot 连接 kafka集群(kafka版本 2.13-3.4.0)
springboot 连接 kafka集群 一、环境搭建1.1 springboot 环境1.2 kafka 依赖 二、 kafka 配置类2.1 发布者2.1.1 配置2.1.2 构建发布者类2.1.3 发布消息 2.2 消费者2.2.1 配置2.2.2 构建消费者类2.2.3 进行消息消费 一、环境搭建 1.1 springboot 环境 JDK 11 Maven 3.8.x spr…...
Nacos配置中心使用(Spring Cloud版)
目标 向项目中集成Nacos配置。原项目是一个SpringBoot项目。这里假设我们无法修改原有项目的SpringBoot版本。 注意 在不动SpringBoot版本的前提下,根据SpringBoot的版本,确定Spring Cloud和Nacos版本。Nacos版本其实就是Spring Cloud Alibaba版本。在…...
STM32F407硬件I2C实现MPU6050通讯(CUBEIDE)
STM32F407硬件I2C实现MPU6050通讯 文章目录 STM32F407硬件I2C实现MPU6050通讯cubeide设置写操作与读操作函数实现复位,读取温度,角度等函数封装mpu6050.cmpu6050.h代码分析 DMP移植1.修改头文件路径为自己的头文件路径2.修改I2C读写函数为自己mcu平台的读…...
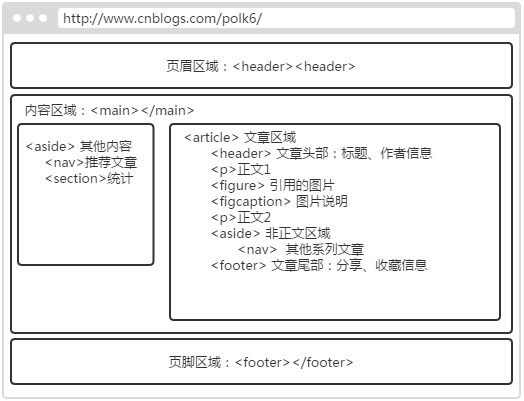
HTML5 语义元素(一)页面结构
本篇主要介绍HTML5增加的语义元素中关于页面结构方面的,包含: <article>、<aside>、<figure>、<figcaption>、<footer>、<header>、<main>、<nav>、<section>等元素。 目录 1. 语义元素介绍 1.…...
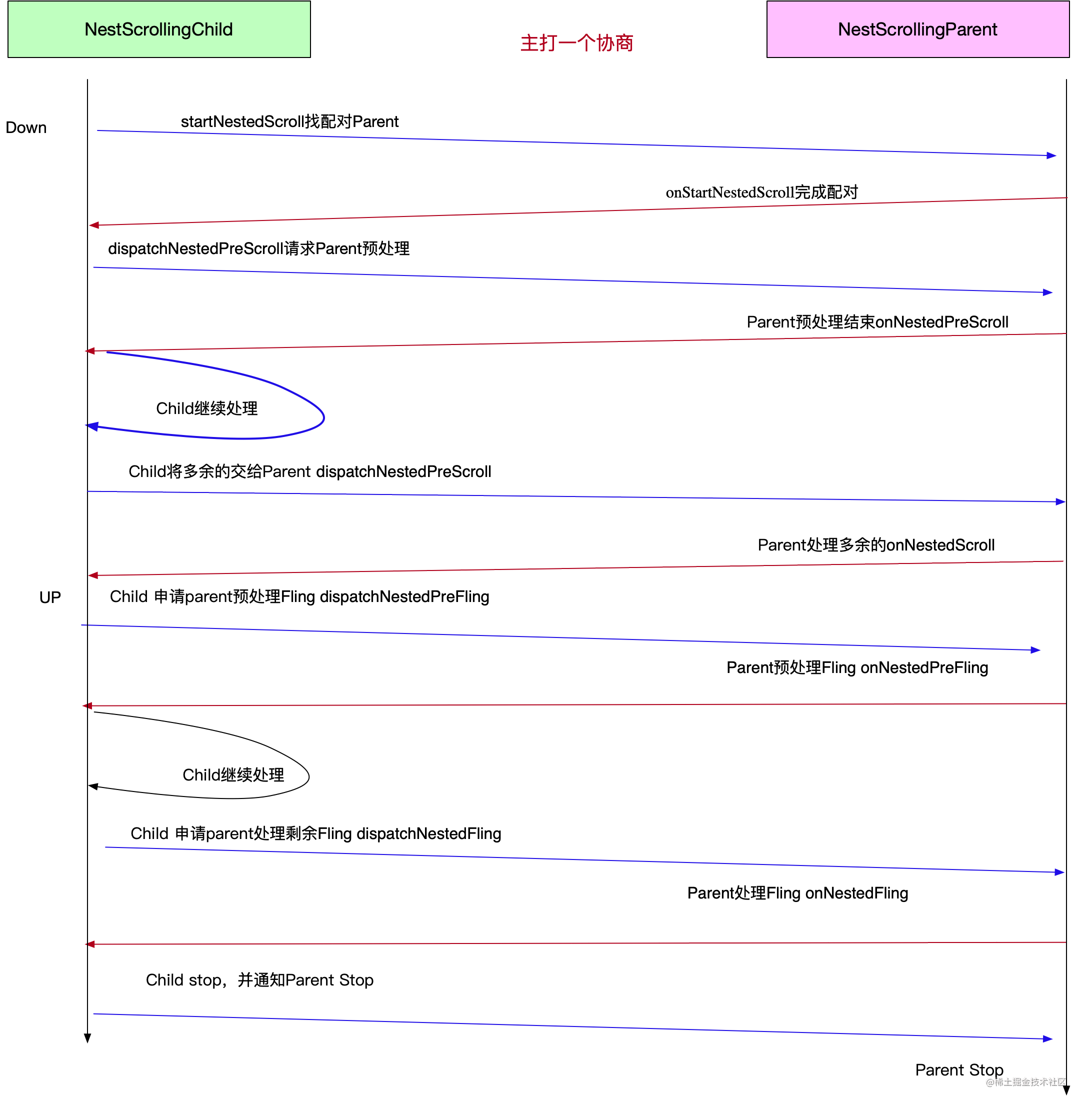
嵌套滚动实践:onInterceptTouchEvent与NestedScrolling【实用为准】
嵌套滚动:内外两层均可滚动,比如上半部分是一个有限的列表,下半部分是WebView,在内层上半部分展示到底的时候,外部父布局整体滚动内部View,将底部WevView拉起来,滚动到顶部之后再将滚动交给内部…...
Redis入门 - 5种基本数据类型
原文首更地址,阅读效果更佳! Redis入门 - 5种基本数据类型 | CoderMast编程桅杆https://www.codermast.com/database/redis/five-base-datatype.html 说明 在我们平常的业务中基本只会使用到Redis的基本数据类型(String、List、Hash、Set、…...
mybatis-plus用法(一)
MyBatis-plus 是一款 Mybatis 增强工具,用于简化开发,提高效率。下文使用缩写 mp来简化表示 MyBatis-plus,本文主要介绍 mp 整合 Spring Boot 的使用。 (5条消息) mybatis-plus用法(二)_渣娃工程师的博客-CSDN博客 1…...

源码安装包管理
1. 源码包基本概述 在linux环境下面安装源码包是比较常见的, 早期运维管理工作中,大部分软件都是通过源码安装的。那么安装一个源码包,是需要我们自己把源代码编译成二进制的可执行文件。 源码包的编译用到了linux系统里的编译器,通常源码包…...

Vue|获取表单数据
在Vue中获取表单数据有多种方式,具体取决于你使用的是哪种表单元素和你的需求。 1. 单个表单元素: 如果你只需要获取单个表单元素的值,可以使用v-model指令将表单元素的值绑定到Vue实例的一个属性上。例如: <input type&quo…...
微信小程序入门学习02-TDesign中的自定义组件
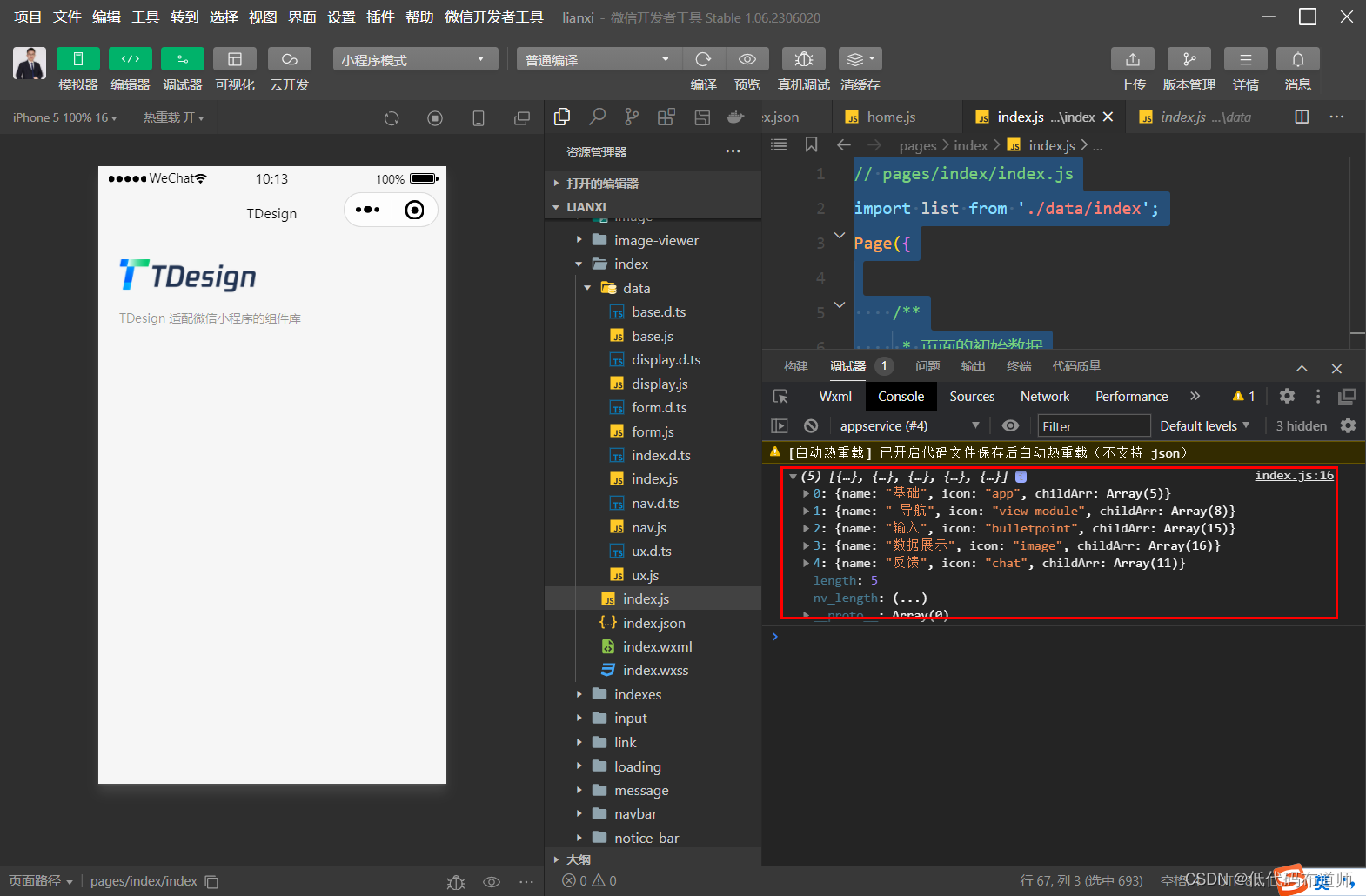
目录 1 显示文本2 自定义组件3 变量定义4 值绑定总结 我们上一篇讲解了TDesign模板的基本用法,如何开始阅读模板。本篇我们讲解一下自定义组件的用法。 1 显示文本 官方模板在顶部除了显示图片外,还显示了一段文字介绍。文字是嵌套在容器组件里…...

【linux kernel】linux media子系统分析之media控制器设备
文章目录 一、抽象媒体设备模型二、媒体设备三、Entity四、Interfaces五、Pad六、Link七、Media图遍历八、使用计数和电源处理九、link设置十、Pipeline和Media流十一、链接验证十二、媒体控制器设备的分配器API 本文基于linux内核 4.19.4,抽象媒体设备模型框架的相…...
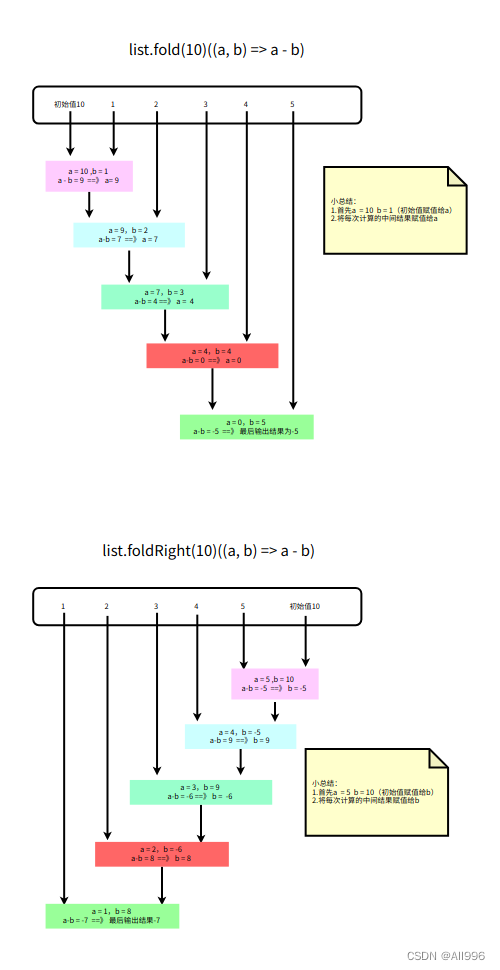
Scala--03
第6章 面向对象 Scala 的面向对象思想和Java 的面向对象思想和概念是一致的。 Scala 中语法和 Java 不同,补充了更多的功能。 6.1类和对象详解 6.1.1组成结构 构造函数: 在创建对象的时候给属性赋值 成员变量: 成员方法(函数) 局部变量 代码块 6.1.2构造器…...

【MongoDB】--MongoDB高级功能
目录 一、前言二、聚合管道aggregate1、示例说明2、具体代码实现一、前言 这里主要记录mongodb一些高级功能使用,如聚合。 二、聚合管道aggregate 聚合操作将来自多个文档的值组合在一起,并且可以对分组数据执行各种操作以返回单个结果,主要用于处理数据(诸如统计平均值,…...

C# new与malloc
目录 C# new与malloc C# new与malloc的区别 C# new关键字底层做的操作 C# new与malloc new关键字: new关键字在C#中用于实例化对象,并为其分配内存。它是面向对象编程的基本操作之一。使用new关键字可以在托管堆上分配内存,同时调用对象的构…...

微软MFC技术简明介绍
我是荔园微风,作为一名在IT界整整25年的老兵,今天来看一下微软MFC技术简明介绍 Visual C 与 MFC 微软公司于1992年上半年推出了C/C 7.0 产品时初次向世人介绍了MFC 1.0,这个产品包含了20,000行C原始代码,60个以上的Windows相关类…...
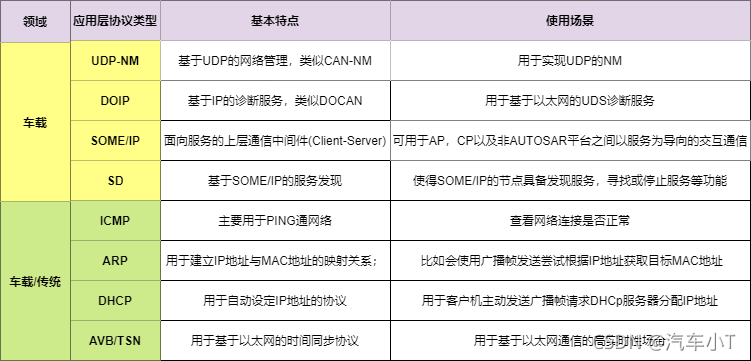
汽车电子Autosar之车载以太网
前言 近些年来,随着为了让汽车更加安全、智能、环保等,一系列的高级辅助驾驶功能喷涌而出。未来满足这些需求,就对传统的电子电器架构带来了严峻的考验,需要越来越多的电子部件参与信息交互,导致对网络传输速率&#x…...

MSP430_C语言例程注释详
本章选择了一些简单的C语言程序例题,这些程序的结构简单,编程技巧不多,题目虽然 简单,但是非常适合入门单片机的学习者学习MSP430单片机的C 语言编程。 如下列出了C语言例题运行的MSP430F149实验板硬件资源环境,熟悉…...

OpenClaw定时任务详解:GLM-4.7-Flash每日自动生成工作报告
OpenClaw定时任务详解:GLM-4.7-Flash每日自动生成工作报告 1. 为什么需要自动化日报系统 上周三晚上11点,我盯着空白的周报文档发呆——明明这周完成了3个需求迭代和2次跨部门协作,却怎么都想不起具体细节。翻遍Git记录、邮件和会议纪要才勉…...

告别笨重线性电源!用TL494打造高效BUCK模块,给你的老旧设备供电或做充电器
用TL494打造高效BUCK模块:老设备供电与智能充电的终极解决方案 老旧实验室设备嗡嗡作响的线性电源,不仅效率低下,发热严重,还占据宝贵的工作台空间。而一块基于TL494的高效BUCK模块,可以彻底改变这一局面。本文将带你…...

VeraCrypt实战指南:从取证入门到加密容器构建
1. VeraCrypt初探:数字取证中的"保险箱" 第一次接触VeraCrypt是在去年的网络安全竞赛上。当时有个加密容器文件摆在面前,队友急得直挠头:"这玩意儿怎么打开?"我盯着那个看似普通的文件,突然意识到…...

51单片机外部中断实战:电平与边沿触发的按键检测优化方案
1. 51单片机外部中断基础入门 第一次接触51单片机外部中断时,我完全被那些专业术语搞晕了。什么电平触发、边沿触发,听起来就像天书一样。但实际用起来才发现,这其实是单片机最实用的功能之一。想象一下,你正在用单片机做一个智能…...

Joy-Con Toolkit:突破官方限制的任天堂手柄全能控制工具
Joy-Con Toolkit:突破官方限制的任天堂手柄全能控制工具 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 重新定义手柄控制:从消费级到开发级的跨越 Joy-Con控制器作为任天堂Switch的核心…...

Visual C++运行时组件故障解决完全指南:从问题定位到能力提升
Visual C运行时组件故障解决完全指南:从问题定位到能力提升 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行时组件(Microsof…...
)
FOC算法中SIMULINK常用模块解析:从坐标变换到SVPWM(实践指南)
1. FOC算法与SIMULINK模块概述 第一次接触FOC(磁场定向控制)算法时,我被那些复杂的坐标变换搞得晕头转向。直到在SIMULINK里亲手搭建了完整的控制环路,才真正理解每个模块的作用。FOC算法的核心思想,简单来说就是把三相…...

终极美化指南:foobar2000如何通过foobox-cn打造你的专属音乐空间?
终极美化指南:foobar2000如何通过foobox-cn打造你的专属音乐空间? 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn 厌倦了千篇一律的音乐播放器界面?想让你的音乐体…...

白帽 SEO 与网站分析数据的关系是什么
<h3 id"seo">白帽 SEO 与网站分析数据的关系是什么</h3> <p>在当今互联网时代,搜索引擎优化(SEO)已经成为了每个网站提升流量和品牌知名度的关键因素。而在众多的SEO策略中,白帽SEO(White…...
)
VINS-Mono跑EUROC数据集后,如何用evo工具包进行轨迹精度评估与可视化(附完整命令)
VINS-Mono轨迹精度评估实战:从EUROC数据集到evo工具包全流程解析 在完成VINS-Mono算法在EUROC数据集上的运行后,如何科学评估其轨迹精度成为算法优化和论文撰写的关键环节。本文将深入讲解使用evo工具包进行定量分析的完整流程,涵盖指标计算、…...