Python面试高频100题【11~15题】
Python面试必知100例。收集整理了目前Python岗位常见的面试题,希望大家通过学习理解相关知识点。下面介绍的是11~15道题。
十一、请介绍下Python中单下划线与双下划线区别
在Python中,单下划线和双下划线主要用于命名变量和方法,而它们具有不同的含义。
- 单下划线 _ :
- 单下划线开头(例如 _var)是一种约定,用来指示这个名称是供内部使用的。它告诉读代码的人该变量或者方法主要被用于类或模块的内部,尽管Python并不会真正地阻止你在外部访问它。
class MyClass:def __init__(self):self._internal_var = 10def internal_method(self):passobj = MyClass()
print(obj._internal_var) # 可以访问,但是应该避免这么做- 双下划线 __ :
- 双下划线开头(例如 __var)表示这个变量或方法不仅仅是用于内部,Python会对其进行名称修饰(name mangling),用来避免命名冲突。这意味着类定义中以双下划线开头的名称如 __var 实际上会被改写为 _classname__var。
class MyClass:def __init__(self):self.__internal_var = 10obj = MyClass()
print(obj.__internal_var) # 这会引发AttributeError错误
print(obj._MyClass__internal_var) # 这样可以访问双下划线开头和结尾的变量(例如 var)是特殊变量,它们有特殊的含义,这些变量通常被称为"魔术"变量或方法。比如 init、str 等。
class MyClass:def __init__(self, value):self.value = valuedef __str__(self):return f"MyClass with value {self.value}"obj = MyClass(10)
print(obj) # 输出:MyClass with value 10十二、一个服务器有4GB的内存,怎么去读取5GB 的数据?
当需要处理的数据集大于可用内存时,我们不能一次性将所有数据加载到内存中。但我们可以使用一些策略来处理这种情况:
- 分块处理(Chunking):这种方法涉及到将数据分割成小块,每次只读取一部分到内存中进行处理。例如,如果你正在处理一个大文件,你可以使用Python的文件读取方法,如read(size)或readline(),每次只读取一部分数据。
- 流处理(Streaming):如果数据可以按照某种顺序处理,你可以使用流处理,也就是一次处理一个数据项,然后丢弃它,再处理下一个。这种方式常常用于处理日志文件或网络流等。
- 使用内存映射文件:内存映射文件是一种将文件的一部分或全部映射到内存空间的技术,使得这部分文件能够像内存一样被访问。Python的mmap模块提供了这种功能。但需要注意的是,这种方法适用于随机访问文件,不适合顺序读取大文件。
- 使用分布式计算:如果数据非常大,而且不能在单机上处理,那么可以考虑使用分布式计算框架,如Hadoop或Spark,将数据分布在多个机器上进行处理。
十三、如何对列表中的元素进行去重?
在Python中,对列表进行去重的一个常见方法是使用set数据结构,然后再转回到list。因为在set中,所有元素都是唯一的。以下是一个简单的代码示例:
def remove_duplicates(lst):return list(set(lst))original_list = [1, 2, 2, 3, 4, 4, 5, 6, 6, 7, 8, 8, 9]
print(remove_duplicates(original_list)) # 输出:[1, 2, 3, 4, 5, 6, 7, 8, 9]需要注意的是,使用set进行去重会丢失原始列表的顺序。如果你希望保留元素的顺序,你可以使用dict从Python 3.7开始,字典保持了插入顺序,所以我们可以通过将列表元素作为字典的键来达到去重且保持顺序的效果。
def remove_duplicates_keep_order(lst):return list(dict.fromkeys(lst))original_list = [1, 2, 2, 3, 4, 4, 5, 6, 6, 7, 8, 8, 9]
print(remove_duplicates_keep_order(original_list)) # 输出:[1, 2, 3, 4, 5, 6, 7, 8, 9]十四、如果列表里面的元素是字典,怎么对列表里面的元素进行去重?
在Python中,列表的元素如果是字典的话,通常情况下不能直接进行去重,因为字典是不可哈希的(unhashable),不能被用作集合(set)或字典的键。但我们可以通过一些其他的方法来去重。
- 使用json序列化:我们可以先将字典转化为JSON字符串,然后添加到集合(set)中,因为集合会自动去重。然后再将去重后的JSON字符串转回字典。
import json# 列表中的元素是字典
list_of_dicts = [{"a": 1, "b": 2}, {"a": 1, "b": 2}, {"a": 3, "b": 4}]# 初始化一个空集合来存储json字符串
json_set = set()# 遍历列表中的每个字典
for d in list_of_dicts:# 将字典转化为排序后的json字符串,然后添加到集合中json_set.add(json.dumps(d, sort_keys=True))# 初始化一个空列表来存储去重后的字典
unique_dicts = []# 遍历集合中的每个json字符串
for i in json_set:# 将json字符串转回字典,然后添加到列表中unique_dicts.append(json.loads(i))print(unique_dicts)- 使用元组作为键:
# 列表中的元素是字典
list_of_dicts = [{"a": 1, "b": 2}, {"a": 1, "b": 2}, {"a": 3, "b": 4}]# 初始化一个空集合来存储元组
tuple_set = set()# 遍历列表中的每个字典
for d in list_of_dicts:# 将字典的键值对排序后转化为元组,然后添加到集合中tuple_set.add(tuple(sorted(d.items())))# 初始化一个空列表来存储去重后的字典
unique_dicts = []# 遍历集合中的每个元组
for t in tuple_set:# 将元组转回字典,然后添加到列表中unique_dicts.append(dict(t))print(unique_dicts)十五、请列举一些正则相关的用法
正则表达式是处理字符串的强大工具,它可以用于匹配、查找、替换特定模式的字符串。Python中的re模块提供了正则表达式相关的操作。
以下是一些基本的正则表达式的使用方法:
- 查找匹配的字符串:**re.search()**函数会在字符串中搜索匹配正则表达式的第一个位置,并返回一个匹配对象,如果没有找到匹配的则返回None。
import reresult = re.search('Python', 'I love Python')
if result:print("Match found")
else:print("Match not found")- 查找所有匹配的字符串:**re.findall()**函数会返回一个列表,包含字符串中所有匹配正则表达式的部分。
import reresult = re.findall('a', 'I am a Python developer')
print(result) # 输出:['a', 'a', 'a']- 替换匹配的字符串:**re.sub()**函数会将字符串中匹配正则表达式的部分替换为指定的字符串。
import reresult = re.sub('Python', 'Java', 'I am a Python developer')
print(result) # 输出:'I am a Java developer'- 分割字符串:**re.split()**函数可以按照正则表达式匹配的部分来分割字符串。
import reresult = re.split('\s', 'I am a Python developer')
print(result) # 输出:['I', 'am', 'a', 'Python', 'developer']- 编译正则表达式:如果你有一个正则表达式需要重复使用,那么可以使用**re.compile()**来提前编译这个正则表达式,这样可以提高效率。
import repattern = re.compile('Python')
result = pattern.search('I love Python')
print(result.group()) # 输出:'Python'以上都是一些基本的用法,实际上正则表达式的功能远不止于此,它有很多的匹配模式和特殊序列可以用于处理复杂的字符串匹配和操作。
关注我,后续题目不断更新中
相关文章:

Python面试高频100题【11~15题】
Python面试必知100例。收集整理了目前Python岗位常见的面试题,希望大家通过学习理解相关知识点。下面介绍的是11~15道题。 十一、请介绍下Python中单下划线与双下划线区别 在Python中,单下划线和双下划线主要用于命名变量和方法,而它们具有不…...
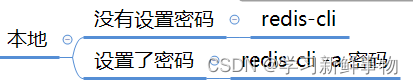
Linux下Redis 存储
命令使用 目录 命令使用 RDB持久化 AOF持久化 yum安装 [rootlocalhost ~]# yum -y install redis 已加载插件:fastestmirror Loading mirror speeds from cached hostfile* c7-media: * epel: ftp.yz.yamagata-u.ac.jpvim到文件etc/redis.conf 取消注释requirep…...
QML 快速上手3 - QuickControl2
目录 QuickControl2简介风格设置control 配置文件图像浏览器案例component 组件报错问题StackViewSwipeView QuickControl2 简介 quickcontrol 用于快速构建风格化的用户界面 它包括了以下几个预制的组件风格 Default QT 默认风格Universal windows 桌面风格Material 谷歌推…...
QT Creator写一个简单的电压电流显示器
前言 本文主要涉及上位机对接收的串口数据处理,LCD Number控件的使用。之前的一篇写一个简单的LED控制主要是串口发出数据,这里再看一下怎么接收数据处理数据,这样基本就对串口上位机有简单的认识了。 LCD Number显示时间 这一小节通过用一…...

前端需要的技能
语言: 1,熟练掌握html5,css3,javascript,ajax 2,掌握PHP、java、python中至少一种web开发语言 3,库/框架:MooTools,YUI,Angular,jQuery,Dojo. 4,UI框架:BootStrap,Founda…...
)
Qt——Qt控件之基于模型的项目视图组-QTreeView树形视图控件的使用总结(Qt仿word标题列表的实现)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C++语言开发基础总结》 《从0到1学习嵌入式Linux开发》...

spring boot框架步骤
目录 1. 创建一个新的Spring Boot项目2. 添加所需的依赖3. 编写应用程序代码4. 配置应用程序5. 运行应用程序6. 编写和运行测试7. 部署应用程序 总结 当使用Spring Boot框架开发应用程序时,以下是一些详细的步骤: 1. 创建一个新的Spring Boot项目 使用…...

动态创建select
1.动态创建select function createSelect(){ var mySelect document.createElement("select"); mySelect.id "mySelect"; document.body.appendChild(mySelect); } 2.添加选项option function addOption(){ //根据id查找对象, var objdoc…...
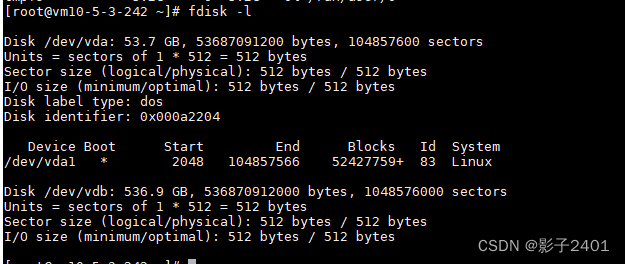
linux-centos7操作系统查看系统未挂载的磁盘,挂载磁盘
linux-centos7操作系统查看系统未挂载的磁盘,挂载磁盘 查看当前磁盘空间 根目录 / 下也只有44G,其他目录只有10几G,正式环境肯定不够用 df -h查看硬盘数量和分区情况 fdisk -l查看到/dev/vdb 有500多G了 将/dev/vdb在分出一个区使用 第一步:编辑分区。执行命令fdisk …...
STM32软件定时器
目录 什么是定时器? 软件定时器优缺点 软件定时器原理 软件定时器相关配置 单次定时器和周期定时器 软件定时器相关 API 函数 1. 创建软件定时器 2. 开启软件定时器 3. 停止软件定时器 4. 复位软件定时器 5. 更改软件定时器定时时间 实操 cubeMX配置 …...

[论文阅读] (30)李沐老师视频学习——3.研究的艺术·讲好故事和论点
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期…...

Java中List、Set、Map的区别和实现方式
Java中List、Set、Map的区别和实现方式 List List 是一个有序的集合,即元素按照插入的顺序进行排序,可以有重复的元素。因为是有序的,所以可以根据下标来获取元素或者遍历整个集合内的元素。常用的实现类包括 ArrayList 和 LinkedList。 A…...
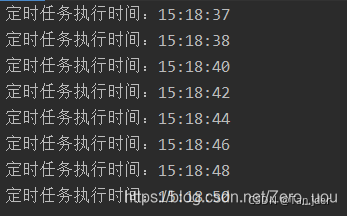
@EnableScheduling和@Scheduled注解详解fixedrate和fixeddelay的区别
一、pom.xml中导入必要的依赖: <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.1.RELEASE</version></parent><dependencies><…...

打印金字塔图案总结
那么好了好了,宝子们,今天给大家总结一下“打印金字塔图案”,来吧,开始整活!⛳️ 最近在牛客网上刷题,遇到了这个打印类型的题目,我想总结一下,然后分享给大家。 一、正向金字塔 …...

SQL语句的执行顺序
1、SQL语句的一般执行顺序 1 from 找表 2 on 关联条件帅选 3 join 关联表操作 4 where 条件筛选 5 group by 进行分组 6 avg,sum… 执行函数 7 having 分组后筛选 8 select …...

Debian 版本代号与《玩具总动员》
作为最受欢迎的 Linux 发行版之一,Debian 是许多其他发行版的基础,许多非常受欢迎的 Linux 发行版,例如 Ubuntu、Knoppix、PureOS 、Tails、Armbian 以及 Raspbian,都基于 Debian。 经过近 20 个月的开发,2023 年 6 月…...

TypeScript 第一章
欢迎来到 TypeScript 学习!本章将为您介绍 TypeScript 的基础知识。 TypeScript 是 JavaScript 的一个超集,它提供了静态类型检查、类、接口等特性,使得编写大型应用程序变得更加容易和可维护。TypeScript 编写的代码可以被编译成 JavaScript…...
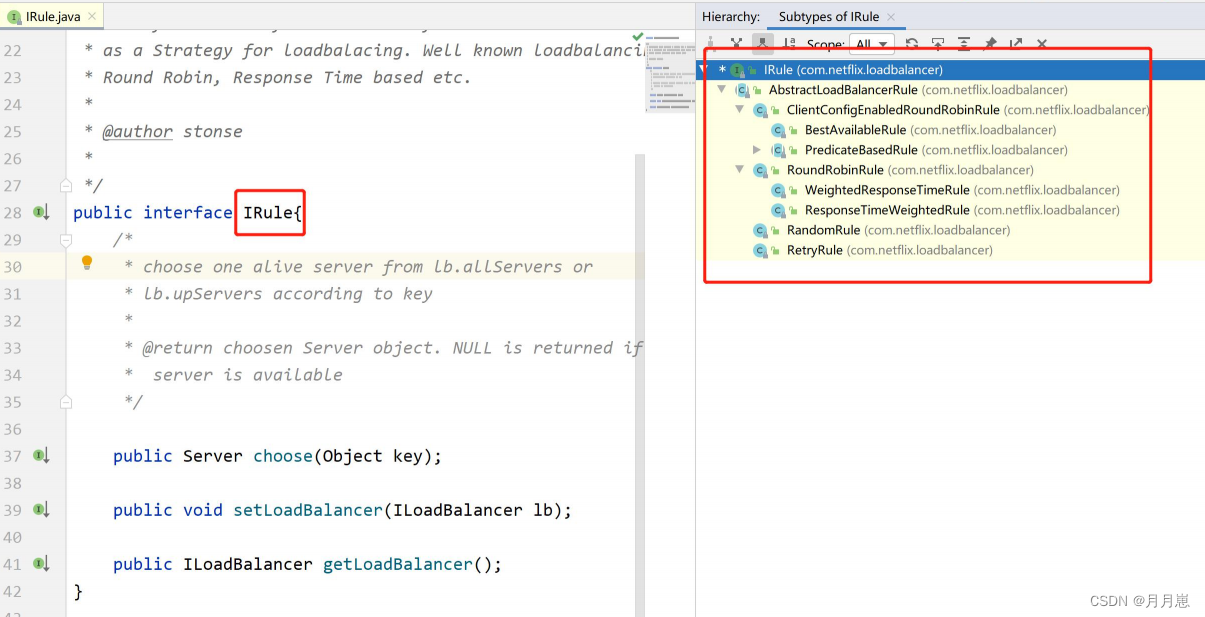
【SpringCloud入门】-- Ribbon入门
1.什么是Ribbon? Ribbon就是netflix公司的一个开源项目,主要功能是提供客户端负载均衡算法和服务调用。Ribbon客户端组件提供了完善的配置项,如连接超时,重试等等。Ribbon作为服务消费者的负载均衡器,有两种使用方式&…...

(二)Liunx下ElasticSearch快速搭建
1.下载安装 1)环境准备: 操作系统:centos7 es版本:8.8.1 jdk:17 es与jdk等兼容支持查看 2)下载安装包上传到服务器,官网地址 https://www.elastic.co/cn/downloads/elasticsearch 3)解压文件…...
神经网络编程基础
目录 1、二分类(Binary Classification) 2、逻辑回归(Logistic Regression) 3、逻辑回归的代价函数(Logistic Regression Cost Function) 4、梯度下降法(Gradient Descent) 5、使用计算图求导数 6、逻辑回归中的梯度下降&…...

Power Automate调用Azure Foundry智能体
Power Automate调用Azure Foundry智能体一、创建Foundry智能体二、发送HTTP请求,调用Foundry智能体三、拓展一、创建Foundry智能体 先从创建开始吧 填好,然后直接审阅并创建就行了。一个资源下可以创建多个项目 转到资源 转到门户 这里有API密钥&…...

KG与LLM:大模型时代的智能规划
这些文章给出的“推荐思路”可以浓缩成一句话 先用 Planner 产出 subgoal dependency acceptance criteria。再让 Router 判断每个子任务该走 向量RAG、KG、数据库还是工具。对需要关系、多跳、时序、因果的问题,用 KG / event graph 做结构化检索,而…...

Claude集成Spring Boot全链路实践:从零搭建智能API网关的7步标准化流程
更多请点击: https://intelliparadigm.com 第一章:Claude集成Spring Boot全链路实践:从零搭建智能API网关的7步标准化流程 环境准备与依赖声明 确保 JDK 17、Maven 3.8 和 Spring Boot 3.2.x 基础环境就绪。在 pom.xml 中引入 Claude 官方…...

基于Puppeteer的网页结构化检查工具:原理、实现与优化
1. 项目概述:一个面向开发者的网页内容检查与结构化工具最近在折腾一个很有意思的小项目,起因是团队里经常需要从各种网页上抓取信息,然后手动整理成结构化的数据。比如,产品经理丢过来一个竞品网站链接,让你分析一下他…...

为什么你的ChatGPT生成帖文零互动?揭秘Instagram 2024算法对AI内容的3重隐性过滤机制
更多请点击: https://intelliparadigm.com 第一章:为什么你的ChatGPT生成帖文零互动?揭秘Instagram 2024算法对AI内容的3重隐性过滤机制 Instagram 2024年Q2核心算法更新引入了「人类意图验证层(HIVL)」,该…...

JPlag代码抄袭检测工具:如何高效识别17种编程语言的代码抄袭行为
JPlag代码抄袭检测工具:如何高效识别17种编程语言的代码抄袭行为 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag …...

【无人机】基于动态反演和扩展状态观测器的无人机鲁棒姿态控制研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 完整代码获取 定制创新 论文复现点击:Matlab科研工作室🍊个人信条:格物致知,完整Matlab…...

CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案
CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 宏基因组研究正经历着从短读长测序到长读长技术的深刻变…...
·面经深度解析)
前端八股文面经大全:上海威派格前端实习(2026-05-07)·面经深度解析
前言 大家好,我是木斯佳。 相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的“增删改查”岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的…...

在自动化客服场景中利用Taotoken实现多模型智能路由
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服场景中利用Taotoken实现多模型智能路由 对于构建智能客服系统的产品团队而言,核心挑战之一是如何在保证服…...