【GPT LLM】跟着论文学习gpt
GPT1开山之作:Improving language understanding by generative pre-training

本文提出了gpt1,即使用无标签的数据对模型先进行训练,让模型学习能够适应各个任务的通用表示;后使用小部分 task-aware的数据对模型进行微调,可以在各个task上实现更强大的功能。
设计框架
分为两块,pre-train和fine-tune,使用transformer模型的解码器部分。
第一阶段:Unsupervised pre-training
预测连续的k个词的下一个词的概率,本质就是最大似然估计,让模型下一个输出的单词的最大概率的输出是真实样本的下一个单词的 u i u_i ui。后面的元素不会看,只看前k个元素,这就和transformer的解码器极为相似。

第二阶段:Supervised fine-tuning
训练下游的task的数据集拥有以下形式的数据:假设每句话中有m个单词,输入序列 { x 1 , x 2 , . . . , x m } \{x^1,x^2,...,x^m\} {x1,x2,...,xm} 和一个标签 y y y(忧下游任务决定)。
在这个阶段,作者定义了两个优化函数,L1保证句子的连贯性,L2保证下游任务的准确率。

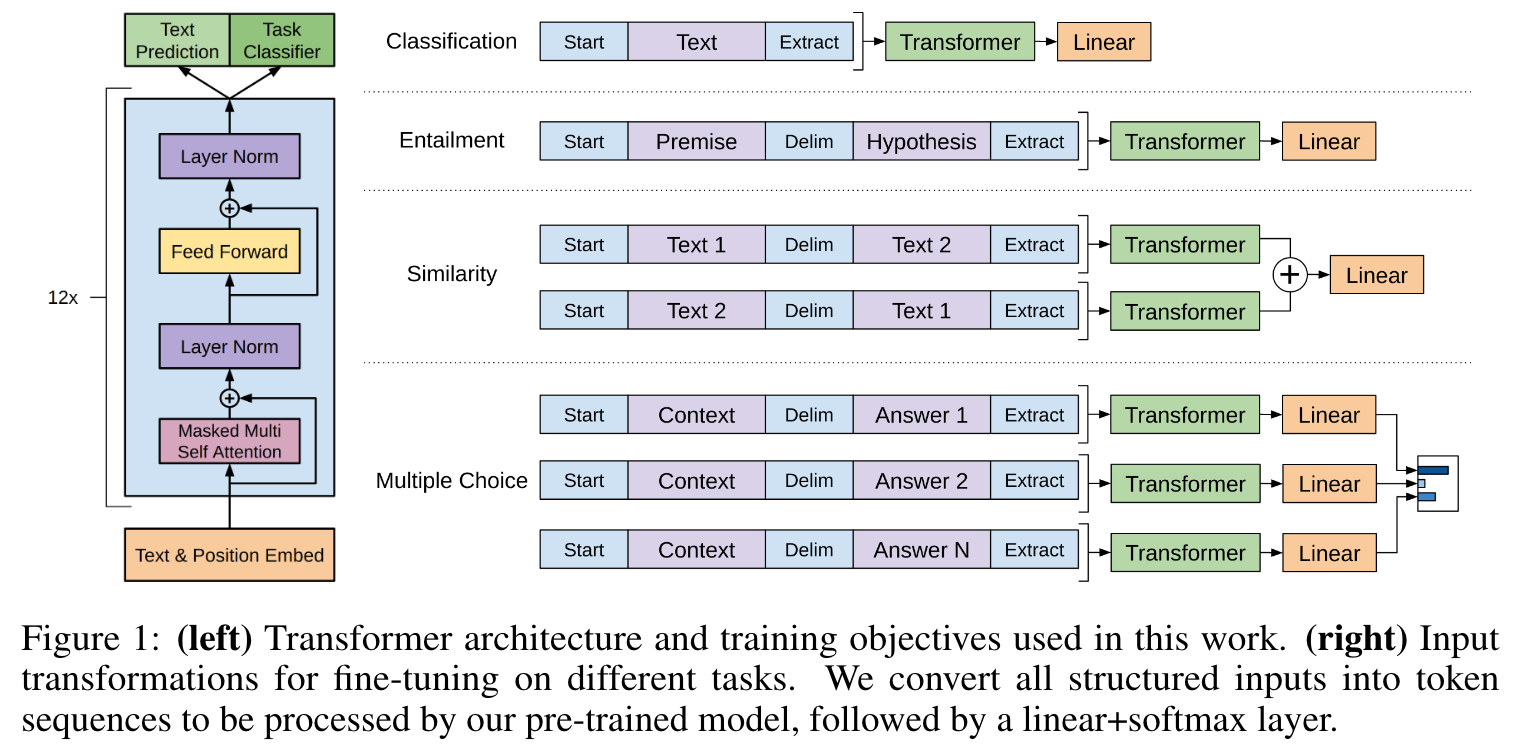
下游任务
针对不同的下游任务,制定了不同的训练方案,其完整的内部框架结构如下:
复现代码
一个十分简易的复现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import copyimport torch.nn.functional as F# accepts input in [ batch x channels x shape ] format
class Attention(nn.Module):def __init__(self, in_channels, heads, dropout=None):assert in_channels % heads == 0super().__init__()self.in_channels = in_channelsself.heads = headsself.dropout = dropoutdef forward(self, queries, keys, values, mask=None):attention = torch.bmm(queries, keys.permute(0,2,1)) / self.in_channels**0.5if mask is not None:attention = attention.masked_fill(mask, -1e9)attention = F.softmax(attention, dim=-1)if self.dropout is not None:attention = F.dropout(attention, self.dropout)output = torch.bmm(attention, values)return output# adds positional encodings
class PositionalEncoding(nn.Module):def forward(self, input_):_, channels, length = input_.shapenumerator = torch.arange(length, dtype=torch.float)denominator = 1e-4 ** (2 * torch.arange(channels, dtype=torch.float) / channels)positional_encodings = torch.sin(torch.ger(denominator, numerator))return input_ + positional_encodingsclass EncoderLayer(nn.Module):def __init__(self, in_channels, heads, dropout=None):super().__init__()self.in_channels = in_channelsself.heads = headsself.produce_qkv = nn.Linear(in_channels, 3*in_channels)self.attention = Attention(in_channels, heads, dropout)self.linear = nn.Linear(in_channels, in_channels)def forward(self, inputs):qkv = self.produce_qkv(inputs)queries, keys, values = qkv.split(self.in_channels, -1)attention = self.attention(queries, keys, values)outputs = F.layer_norm(attention + inputs, (self.in_channels,))outputs = F.layer_norm(self.linear(outputs) + outputs, (self.in_channels,))return outputs class DecoderLayer(nn.Module):def __init__(self, in_channels, heads, dropout=None):super().__init__()self.in_channels = in_channelsself.heads = headsself.produce_qkv = nn.Linear(in_channels, 3*in_channels)self.produce_kv = nn.Linear(in_channels, 2*in_channels)self.masked_attention = Attention(in_channels, heads, dropout)self.attention = Attention(in_channels, heads, dropout)self.linear = nn.Linear(in_channels, in_channels)def forward(self, inputs, outputs):qkv = self.produce_qkv(outputs)queries, keys, values = qkv.split(self.in_channels, -1)n = inputs.shape[1]mask = torch.tril(torch.ones((n, n), dtype=torch.uint8))attention = self.masked_attention(queries, keys, values, mask)outputs = F.layer_norm(attention + outputs, (self.in_channels,))kv = self.produce_kv(inputs)keys, values = kv.split(self.in_channels, -1)attention = self.attention(outputs, keys, values)outputs = F.layer_norm(attention + outputs, (self.in_channels,))outputs = F.layer_norm(self.linear(outputs) + outputs, (self.in_channels,))return outputsif __name__ == '__main__':print("Running...")test_in = torch.rand([3,4,5])encoder = EncoderLayer(5, 1)test_out = encoder(test_in) # torch.Size([3, 4, 5])assert test_out.shape == (3, 4, 5)print("encoder passed")decoder = DecoderLayer(5, 1) # 这就是gpt模型test_mask = torch.tril(torch.ones((4, 4), dtype=torch.uint8))test_out = decoder(test_in, test_in)assert test_out.shape == (3, 4, 5) # torch.Size([3, 4, 5])print("decoder passed")
GPT2
相关文章:
【GPT LLM】跟着论文学习gpt
GPT1开山之作:Improving language understanding by generative pre-training 本文提出了gpt1,即使用无标签的数据对模型先进行训练,让模型学习能够适应各个任务的通用表示;后使用小部分 task-aware的数据对模型进行微调ÿ…...

【玩转Docker小鲸鱼叭】Docker容器常用命令大全
在 Docker 核心概念理解 一文中,我们知道 Docker容器 其实就是一个轻量级的沙盒,应用运行在不同的容器中从而实现隔离效果。容器的创建和运行是以镜像为基础的,容器可以被创建、销毁、启动和停止等。本文将介绍下容器的这些常用操作命令。 1、…...

专项练习11
目录 一、选择题 1、执行下列选项的程序,输出结果不是Window对象的是() 2、以下哪些代码执行后 i 的值为10: 二、编程题 1、判断 val1 和 val2 是否完全等同 2、统计字符串中每个字符的出现频率,返回一个 Object&…...
)
ASP.NET+SQL通用作业批改系统设计(源代码+论文)
随着网络高速地融入当今现代人的生活,学校对网络技术的应用也在不断地提高。学校的教学任务十分复杂,工作也很繁琐,在教学任务中,作业的批改也是一个很重要的环节。为了提高老师工作效率,减轻教师的工作强度,提高作业批改的灵活性,《通用作业批改系统》的诞生可以说是事在…...

基于深度学习的高精度打电话检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度打电话检测识别系统可用于日常生活中或野外来检测与定位打电话目标,利用深度学习算法可实现图片、视频、摄像头等方式的打电话目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检…...

Vue搭建智能文本检索视频界面
前言 随着人工智能技术的发展,智能文本检索已经成为了一种非常流行的技术。在视频领域中,智能文本检索技术可以帮助用户快速找到自己需要的视频片段,提高用户的观看体验。本文将介绍如何使用Vue框架搭建一个智能文本检索视频界面,…...

软考A计划-系统集成项目管理工程师-一般补充知识-中
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例点击跳转>软考全系列 👉关于作者 专注于Android/Unity和各种游戏开发技巧ÿ…...
springboot-内置Tomcat
一、springboot的特性之一 基于springboot的特性 自动装配Configuretion 注解 二、springboot内置Tomcat步骤 直接看SpringApplication方法的代码块 总纲: 1、在SpringApplication.run 初始化了一个上下文ConfigurableApplicationContext configurableApplica…...
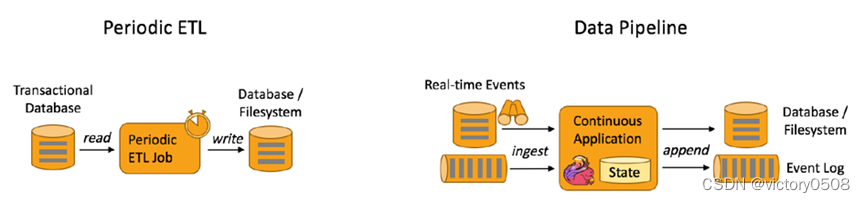
Flink流批一体计算(2):Flink关键特性
目录 Flink关键特性 流式处理 丰富的状态管理 丰富的时间语义支持 Data pipeline 容错机制 Flink SQL CEP in SQL Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各…...

2023软件工程中各种图在现代企业级开发中的使用频率
概览 系统流程图 ✔ 数据流图 不常用 ER图 ✔ 状态转换图 ✔ Warnier图 不常用 IPO图 不常用 Petri网 不常用 层次方框图 不常用 层次图 a.k.a. H图 ✔ 1,层次图描绘软件的层次结构.层层次方框图描绘的是数据结构。 2,层次图的方框表示模块或子模块。层次方框图的方框表示数据结…...

macOS Big Sur 11.7.8 (20G1351) 正式版 ISO、PKG、DMG、IPSW 下载
macOS Big Sur 11.7.8 (20G1351) 正式版 ISO、PKG、DMG、IPSW 下载 本站下载的 macOS 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也支持在 Window…...

【C++案例】一个项目掌握C++基础-通讯录管理系统
文章目录 1、系统需求2、菜单功能3、退出功能4、添加联系人4.1 设计联系人结构体4.2 设计通讯录结构体4.3 main函数中创建通讯录4.4 封装添加联系人函数4.5 测试添加联系人功能 5、显示联系人5.1 封装显示联系人函数5.2 测试显示联系人功能 6、删除联系人6.1 封装检测联系人是否…...

Triton教程 --- 动态批处理
Triton教程 — 动态批处理 Triton系列教程: 快速开始利用Triton部署你自己的模型Triton架构模型仓库存储代理模型设置优化动态批处理 Triton 提供了动态批处理功能,将多个请求组合在一起执行同一模型以提供更大的吞吐量。 默认情况下,只有当每个输入在…...
)
Python的并行(持续更新)
0. 参考: 《Python并行编程 中文版》https://python-parallel-programmning-cookbook.readthedocs.io/zh_CN/latest/index.html 1. 线程和进程: 进程可以包含多个并行运行的线程;通常,操作系统创建和管理线程比进程更省CPU资源&am…...

chatgpt赋能python:Python实现Fibonacci数列
Python实现Fibonacci数列 Fibonacci数列是一个非常经典的数列,定义如下: F ( 0 ) 0 , F ( 1 ) 1 F(0)0, F(1)1 F(0)0,F(1)1 F ( n ) F ( n − 1 ) F ( n − 2 ) F(n)F(n-1)F(n-2) F(n)F(n−1)F(n−2) 也就是说,第n个数等于前两个数之和…...

开环模块化多电平换流器仿真(MMC)N=6
模型简介: 运行环境MATLAB2021a 开环模块化多电平换流器仿真(MMC)N=6,连接负载,采用载波移相调制。 可以得到换流器输出N+1=7电平的相电压波形。可考虑线路阻抗。 子模块采用半桥结…...
java springboot整合MyBatis联合查询
前面文章 java springboot整合MyBatis做数据库查询操作写了springboot整合MyBatis的方法 并演示了基础查询的语法 根据id查 那么 我们这次来演示联合查询 我们staff 表 内容如下 每条数据 对应的都有一个departmentid 这是 department部门表的外键id department表内容如下 如…...
windows2022证书配置.docx
Windows证书的配置 要求两台主机,一台作为域,一台进入域 按要求来选择角色服务 确认之后安装 安装完以后配置证书服务 选择服务 按要求配置 注:此处不用域用户登陆无法使用企业CA 按要求来 创建新的私钥 这几处检查无误后默认即可 有效期…...
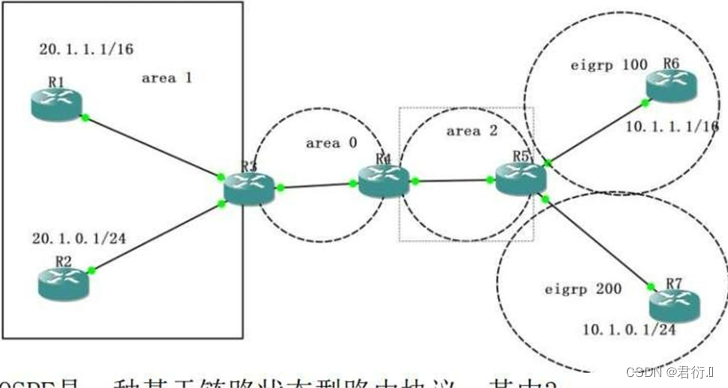
HCIP网络笔记分享——IA回顾及OSPF协议
第一部分 HCIA回顾1、网络基础2、动态路由协议3、路由认证4、路由控制(AD metric ) 一、知识巩固二、场景模拟1、获取IP地址1.1 DHCP --- 动态主机配置协议1.1.1 DHCP客户端1.1.2 DHCP服务器1.1.3 DHCP客户端1.1.4 DHCP服务器 2、打开浏览器3、路由器进行…...
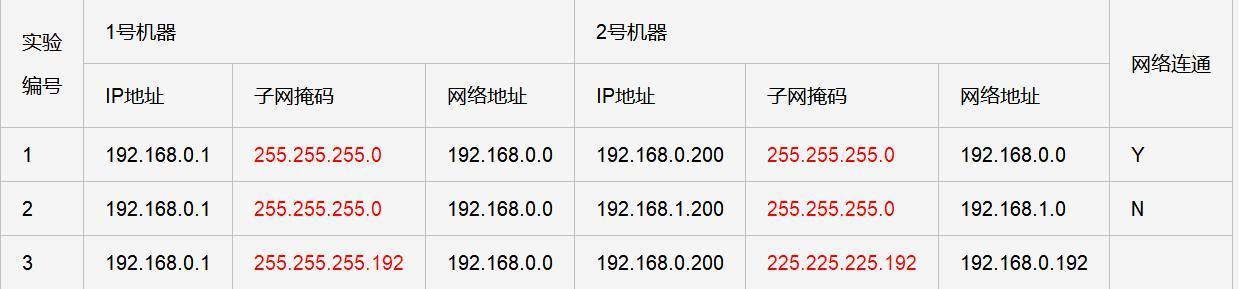
网络:IP地址、子网掩码、网络地址、广播地址、网段、网关
目录 一、IP地址 二、子网掩码 三、网络地址 四、广播地址 五、网段 六、网关 七、IP地址、子网掩码、网络地址、广指地址、网殷、网关的关系 参考链接 一、IP地址 IP地址是因特网协议(IP)中使用的一种数字标识符,用于唯一地标识网络…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...