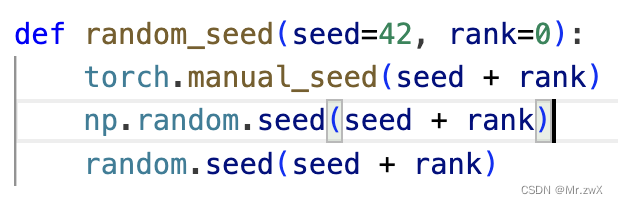
【随机种子初始化】一个神经网络模型初始化的大坑
1 问题起因和经过
半年前写了一个模型,取得了不错的效果(简称项目文件1),于是整理了一番代码,保存为了一个新的项目(简称项目文件2)。半年后的今天,我重新训练这个整理过的模型,即项目文件2,没有修改任何的超参数,并且保持完全一致的随机种子,但是始终无法完全复现出半年前项目文件1跑出来的结果(按道理来说,随机种子控制好后,整个训练过程都应该能够复现,第一个epoch的accuracy就应该对上)。我找到项目文件1,跑了跑,能复现之前的训练结果。并且,分别训练项目文件1和2的模型,都能重复自己的训练结果,而两个项目文件的结果无法对上。
花了半天的时间反复仔细检查数据集和训练超参数的设置后,也没能看出项目文件2有什么毛病。非常奇怪,为什么同样的模型、配置、服务器、随机种子,在不同的项目文件中出现不同的结果?!实在想不通。
于是,决定动手debug看看问题出在了哪里。
我发现第一个epoch的结果就对不上,所以我猜测问题出在了模型的初始化上,那初始化与什么相关呢?很自然地,我把问题聚焦在了随机种子上,是不是没有有效固定住随机性?所以我将两个项目文件构建model后的参数打印出来看了看,发现,完全不同!
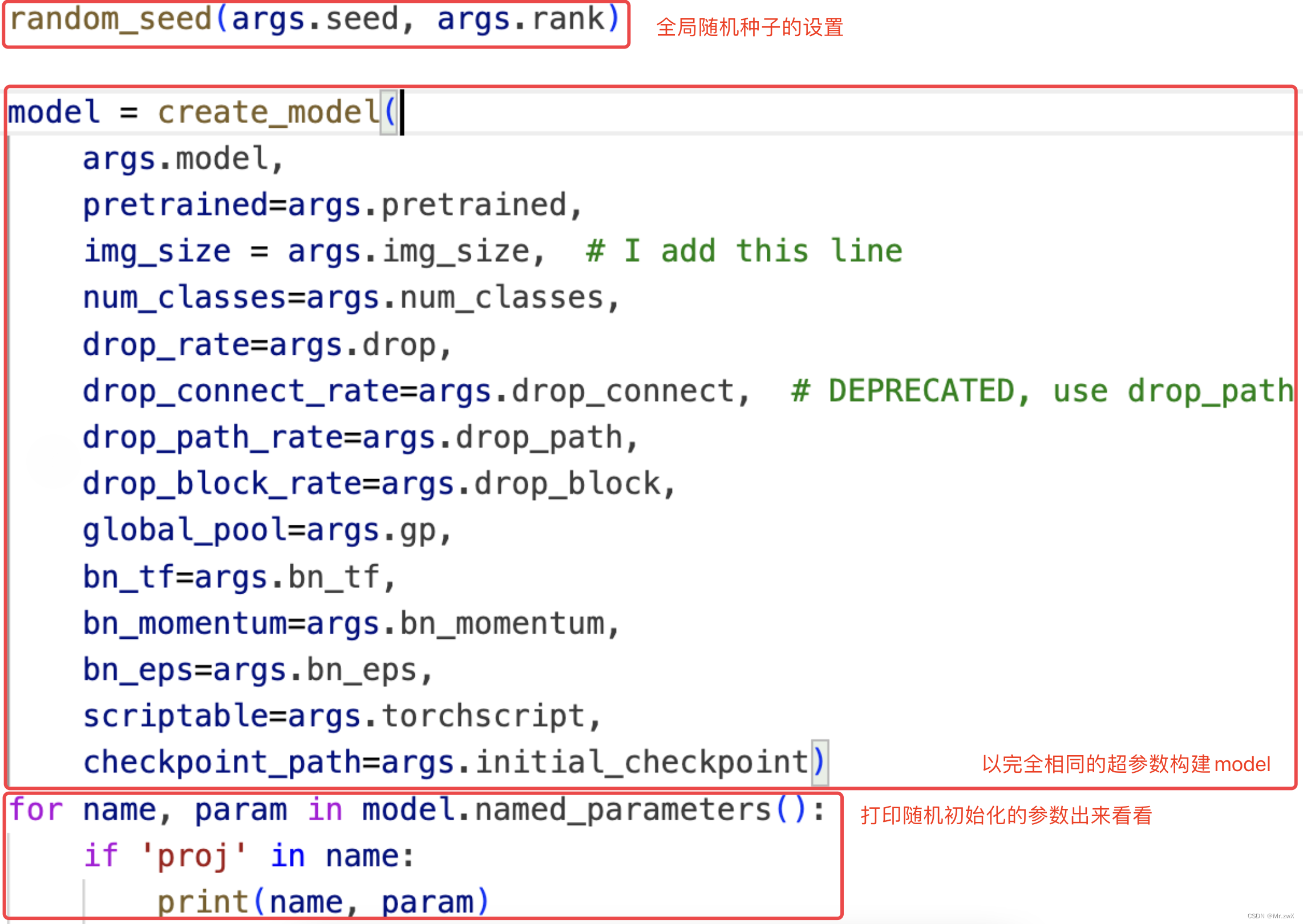
项目文件1中的部分打印结果:

项目文件2中的部分打印结果:

很明显地说明了一件事:同样的随机种子,在这两个项目文件中,产生了完全不一样的初始化值! 这个结果是违背我的常识的,为什么会出现这样的情况?
于是,我 猜测是不是因为两个项目在同一服务器上发生了未知的冲突,所以我copy了一份项目文件1为项目文件3,然后跑项目文件3的初始化结果,发现和项目文件1的初始化结果一致,居然没问题!?那这个项目文件2怎么回事,凭空出现了不同的初始化值?
排除了项目冲突这个猜想后,我把视野放在了模型本身上。我试着print(model)进行观察,发现项目文件2相比项目文件1的模型架构多了一些参数,这些参数是我当初在整理代码并补充新算法时补充定义的(比如:self.gamma = Parameter(torch.randn((1, self.num_heads, 1, 1)))),但是后面并没有真正用上这个参数。
于是,我又有了一个新的猜想:是不是因为多出来的这些新定义的参数,导致在同一随机种子的设置下,仍然出现不一致的初始化行为?
顺着这个思路,我给项目文件1做了如下简单的尝试:直接给模型架构多定义一个模块,但无需使用它,看看初始化是否受影响。 这里我简单加了个nn.Linear()进去。
代码解释如下,原本的架构为:
class Attention(Module):"""Obtained from timm: github.com:rwightman/pytorch-image-models"""def __init__(self, dim, num_heads=8, attention_dropout=0.1, projection_dropout=0.1):super().__init__()self.num_heads = num_headshead_dim = dim // self.num_headsself.scale = head_dim ** -0.5self.qkv = Linear(dim, dim * 3, bias=False)self.attn_drop = Dropout(attention_dropout)self.proj = Linear(dim, dim)self.proj_drop = Dropout(projection_dropout)self.relu = ReLU()self.eps = 1e-8self.alpha = Parameter(torch.ones(1, self.num_heads, 1, 1), requires_grad=False)self.alpha.data.fill_(1.0)def forward(self, x):B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]...
我在init函数中多定义一行线性层后为:
class Attention(Module):"""Obtained from timm: github.com:rwightman/pytorch-image-models"""def __init__(self, dim, num_heads=8, attention_dropout=0.1, projection_dropout=0.1):super().__init__()self.num_heads = num_headshead_dim = dim // self.num_headsself.scale = head_dim ** -0.5self.qkv = Linear(dim, dim * 3, bias=False)self.attn_drop = Dropout(attention_dropout)self.proj = Linear(dim, dim)self.proj_drop = Dropout(projection_dropout)self.relu = ReLU()self.eps = 1e-8self.alpha = Parameter(torch.ones(1, self.num_heads, 1, 1), requires_grad=False)self.alpha.data.fill_(1.0)self.linear = Linear(dim, dim) # 这里是新加的模块,但是无需使用def forward(self, x):B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]...
于是,打印初始化参数得到:

初始化的结果仍然改变了!!! 看来果然是模型架构的不一致性导致了随机种子“失效”。
2 总结上述问题
两个项目文件,看似模型、超参数、数据集、随机种子、服务器完全一致时,发现训练时两者无法保持完全一致,并且进一步发现两个项目文件在初始化模型参数时就不一致了。
而单独地重复训练每一个项目文件,都能重复自身的结果。
直观感觉就是随机种子并没有有效地作用到另一个项目上,是一个很奇怪的问题,有点违背常识。
3 总结解决方案
训练过程不一致是表象,实际上是模型初始化就不一致了。
如果想要用随机种子控制模型初始化参数完全一致,就必须保证模型的架构完全一致! 但凡在model类的init函数里多定义一个无用参数比如Linear,都会改变整个初始化结果,从而影响后面的训练进程(应该是很微小的影响,但是对于我们复现项目时扣细节来说,会放大这个影响)。
4 可能的解释
咨询了一些遇到过这个问题的同学,大概有如下的可能的解释:在模型的定义中加入了新的模块后,不管是否真正使用,都会影响初始化(已控制了随机种子)。因为加入了新的模块后,整个初始化的顺序会发生改变,于是就乱套了。随机种子只能保证你调用后生成的随机数列是一样的,而在构建模型时的调用顺序,是会随着模型架构的改变而改变的。
相关文章:
【随机种子初始化】一个神经网络模型初始化的大坑
1 问题起因和经过 半年前写了一个模型,取得了不错的效果(简称项目文件1),于是整理了一番代码,保存为了一个新的项目(简称项目文件2)。半年后的今天,我重新训练这个整理过的模型&…...
翻过那座山——Gitlab流水线任务疑难之编译有子模块的项目指南
📢欢迎点赞 :👍 收藏 ⭐留言 📝 如有错误敬请指正,赐人玫瑰,手留余香!📢本文作者:由webmote 原创📢作者格言:新的征程,我们面对的不是…...

手机照片删除后如何恢复
在如今移动互联网和智能手机时代,拍摄照片已经成为了人们常见的一种生活方式,尤其是通过手机拍摄照片已经成为了许多人记录生活点滴、分享经验和表达情感等的必备工具。但是,随着手机照片量的激增,意外删除手机中珍贵照片的事件也…...
SpringBoot 线上服务假死,CPU 内存正常,什么情况?
背景 开发小伙伴都知道线上服务挂掉,基本都是因为cpu或者内存不足,出现GC频繁OOM之类的情况。本篇文章区别以上的情况给小伙伴们带来不一样的服务挂掉。 还记得哔哩哔哩713事故中那场诡计多端的0吗? 图片 对就是这个0,和本次事…...

kotlin从入门到精通之内置类型
基本类型 声明变量 val(value的简写)用来声明一个不可变的变量,这种变量在初始赋值之后就再也不能重新赋值,对应Java中的final变量。 var(variable的简写)用来声明一个可变的变量,这种变量在初始…...

实战指南:使用Spring Boot实现消息的发送和接收
当涉及到消息发送和接收的场景时,可以使用Spring Boot和消息中间件RabbitMQ来实现。下面是一个简单的示例代码,展示了如何在Spring Boot应用程序中创建消息发送者和接收者,并发送和接收一条消息。 首先,你需要进行以下准备工作 确…...

常用的数据结构——栈
目录 1、入栈 2、出栈 3、获取栈顶的元素 4、从栈中查找元素 栈是一种常见的数据结构,栈的特点是后进先出,就像我们叠盘子,拿走上面的盘子才能拿到下一个。java中的栈java.util.Stack是通过java.util.Vector实现的,所以底层都…...
C++完成淄博烧烤节管理系统
背景: 这次我们结合今年淄博烧烤做一个餐厅管理系统,具体需求如下,我们选择的是餐饮商家信息管理 问题描述: 淄博烧烤今年大火,“进淄赶烤”是大家最想干的事情,淄博烧烤大火特火的原因,火的…...

我心中的TOP1编程语言
目录 一、评选最佳编程语言时需要考虑哪些标准 (一)易用性 (二)执行效率 (三)语言功能特性 (四)工具生态环境 (五)开发者社区 二、不同编程语言的优点…...
)
Linux工具之gdb(含移植到arm-linux系统)
文章目录 文件目录结构移植ncurses库移植gdb移植到arm板调试测试 linux主机:ubuntu-18.04 交叉编译器:arm-buildroot-linux-gnueabihf 开发板kernel:Linux 5.4.0-150-generic x86_64 开发板:100ASK_STM32MP157_PRO开发板 arm-…...

DolphinScheduler
参考 Apache DolphinScheduler v1.3.9 使用手册 内置组件 masterserverworkserverzookeepertask queuealertapiui 设计 去中心化设计 通过zk选举 UI功能 队列管理 Yarn调度器的资源队列 用户管理 租户对应的是Linux系统用户,是Worker执行任务使用的用户 用户…...
10大白帽黑客专用的 Linux 操作系统
平时在影视里见到的黑客都是一顿操作猛如虎,到底他们用的都是啥系统呢? 今天给大家分享十个白帽黑客专用的Linux操作系统。 ▍1. Kali Linux Kali Linux是最著名的Linux发行版,用于道德黑客和渗透测试。Kali Linux由Offensive Security开发&…...

Golang每日一练(leetDay0099) 单词规律I\II Word Pattern
目录 290. 单词规律 Word Pattern 🌟 291. 单词规律 II Word Pattern ii 🌟🌟 🌟 每日一练刷题专栏 🌟 Rust每日一练 专栏 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日一练 专栏 …...
linux_centos7.9/ubuntu20.04_下载镜像及百度网盘分享链接
1、镜像下载站点 网易开源镜像:http://mirrors.163.com/ 搜狐开源镜像:http://mirrors.sohu.com/ 阿里开源镜像:https://developer.aliyun.com/mirror/ 首都在线科技股份有限公司:http://mirrors.yun-idc.com/ 常州贝特康姆软件技…...
Reqable HTTP一站式开发+调试工具(小黄鸟作者另一力作、小黄鸟完美替代品)
本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删!Reqable HTTP一站式开发+调试工具(小黄鸟作者另一力作、小黄鸟替代品) 环境 win10pixel4Android13概览 …...

Yacc 与 Lex 快速入门
Yacc 与 Lex 快速入门 简介: Lex 和 Yacc 是 UNIX 两个非常重要的、功能强大的工具。事实上, 如果你熟练掌握 Lex 和 Yacc 的话,它们的强大功能使创建 FORTRAN 和 C 的编译器如同儿戏。本文详细的讨论了编写自己的语言和编译器所 用到的这两…...
:从Unix开源开发学习应对大型复杂项目开发)
【开源与项目实战:开源实战】80 | 开源实战二(下):从Unix开源开发学习应对大型复杂项目开发
上两节课,我们分别从代码编写、研发管理的角度,学习了如何应对大型复杂软件开发。在研发管理这一部分,我们又讲到比较重要的几点,它们分别是编码规范、单元测试、持续重构和 Code Review。其中,前三点在专栏的理论部分…...
【单周期CPU】LoongArch | 立即数扩展模块Ext | 32位算术逻辑运算单元(ALU)
前言:本章内容主要是演示在vivado下利用Verilog语言进行单周期简易CPU的设计。一步一步自己实现模型机的设计。本章先介绍单周期简易CPU中基本组合逻辑部件的设计。 💻环境:一台内存4GB以上,装有64位Windows操作系统和Vivado 201…...

Python实现数据结构的基础操作
目录 一、列表(List) 二、字典(Dictionary) 三、集合(Set) 四、链表的实现 五、队列和栈 数据结构是计算机科学中非常重要的概念,它用于存储和组织数据以便有效地进行操作。Python作为一种…...

20230624----重返学习-vue-响应式处理思路-仿源码
day-098-ninety-eight-20230624-vue-响应式处理思路-仿源码 vue vue大体概念 Vue是渐进式框架 所谓渐进式框架,就是把一套全面的框架设计体系,拆分成为多个框架,项目中需要用到那些需求,再导入对应的框架,以此来保证…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...