深度学习-第T11周——优化器对比实验
深度学习-第T11周——优化器对比实验
- 深度学习-第T11周——优化器对比实验
- 一、前言
- 二、我的环境
- 三、前期工作
- 1、导入数据集
- 2、查看图片数目
- 3、查看数据
- 四、数据预处理
- 1、 加载数据
- 1、设置图片格式
- 2、划分训练集
- 3、划分验证集
- 4、查看标签
- 2、数据可视化
- 3、检查数据
- 4、配置数据集
- 五、搭建CNN网络
- 六、训练模型
- 七、模型评估
- 1、Loss和Acc图
- 2、模型评估
- 八、总结
深度学习-第T11周——优化器对比实验
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.5
- 编译器:colab在线编译
- 深度学习环境:Tensorflow
三、前期工作
1、导入数据集
导入数据集,这里使用k同学的数据集,共17个分类。
import os, PIL, pathlib
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
import matplotlib.pyplot as pltdata_dir = "/content/drive/MyDrive/Training_Camp_DL/TensorFlow/CNN/48-data"
print(type(data_dir))
data_dir = pathlib.Path(data_dir)
print(type(data_dir))
这段代码将字符串类型的 data_dir 转换为了 pathlib.Path 类型的对象。pathlib 是 Python3.4 中新增的模块,用于处理文件路径。
通过 Path 对象,可以方便地操作文件和目录,如创建、删除、移动、复制等。
在这里,我们使用 pathlib.Path() 函数将 data_dir 转换为路径对象,这样可以更加方便地进行文件路径的操作和读写等操作。
2、查看图片数目
image_count = len(list(data_dir.glob("*/*.jpg")))
print("图片数目:", image_count)获取指定目录下所有子文件夹中 jpg 格式的文件数量,并将其存储在变量 image_count 中。
data_dir 是一个路径变量,表示需要计算的目标文件夹的路径。
glob() 方法可以返回匹配指定模式(通配符)的文件列表,该方法的参数 “/.jpg” 表示匹配所有子文件夹下以 .jpg 结尾的文件。
list() 方法将 glob() 方法返回的生成器转换为列表,方便进行数量统计。最后,len() 方法计算列表中元素的数量,就得到了指定目录下 jpg 格式文件的总数。
所以,这行代码的作用就是计算指定目录下 jpg 格式文件的数量。

3、查看数据
roses = list(data_dir.glob("Jennifer Lawrence/*.jpg"))
print(type(roses), roses)
PIL.Image.open(str(roses[0]))

四、数据预处理
1、 加载数据
1、设置图片格式
batch_size = 16
img_height = 336
img_width = 336
2、划分训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split = 0.2,subset = 'training',seed = 12,image_size = (img_height, img_width),batch_size = batch_size
)
这行代码使用 TensorFlow 读取指定路径下的图片文件,并生成一个 tf.data.Dataset 对象,用于模型的训练和评估。
具体来说,tf.keras.preprocessing.image_dataset_from_directory() 函数从指定目录中读取图像数据,并自动对其进行标准化和预处理。该函数有以下参数:
directory:指定图像文件所在目录的路径;
seed:用于随机划分数据集的种子;
image_size:指定图像缩放后的尺寸;
batch_size:指定批次中图像的数量。
通过这些参数,函数将指定目录中的图像按照指定大小预处理后,随机划分为训练集和验证集。最终,生成的 tf.data.Dataset 对象包含了划分好的数据集,可以用于后续的模型训练和验证。
需要注意的是,这里的 img_height 和 img_width 变量应该提前定义,并且应该与实际图像的尺寸相对应。同时,batch_size 也应该根据硬件设备的性能合理调整,以充分利用 GPU/CPU 的计算资源。
3、划分验证集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split = 0.2,subset = "validation",seed = 12,image_size = (img_height, img_width),batch_size = batch_size
)这段代码和上一段代码类似,使用 TensorFlow 的 keras.preprocessing.image_dataset_from_directory() 函数从指定的目录中读取图像数据集,并将其划分为训练集和验证集。
其中,data_dir 指定数据集目录的路径,validation_split 表示从数据集中划分出多少比例的数据作为验证集,subset 参数指定为 “validation” 则表示从数据集的 20% 中选择作为验证集,其余 80% 作为训练集。seed 是一个随机种子,用于生成可重复的随机数。image_size 参数指定输出图像的大小,batch_size 表示每批次加载的图像数量。
该函数返回一个 tf.data.Dataset 对象,代表了整个数据集(包含训练集和验证集)。可以使用 train_ds 和 val_ds 两个对象分别表示训练集和验证集。
不过两段代码的 subset 参数值不同,一个是 “training”,一个是 “validation”。
因此,在含有交叉验证或者验证集的深度学习训练过程中,需要定义两个数据集对象 train_ds 和 val_ds。我们已经定义了包含训练集和验证集的数据集对象 train_ds,可以省略这段代码,无需重复定义 val_ds 对象。只要确保最终的训练过程中,两个数据集对象都能够被正确地使用即可。
如果你没有定义 val_ds 对象,可以使用这段代码来创建一个验证数据集对象,用于模型训练和评估,从而提高模型性能。
4、查看标签
class_names = train_ds.class_names
class_names
train_ds.class_names 是一个属性,它是通过数据集对象 train_ds 中的类别信息自动生成的一个包含类别名称的列表。
在创建数据集对象 train_ds 时,你可以通过 class_names 参数手动指定类别名称,也可以根据图像文件夹的目录结构自动推断出来。
例如,假设你有一个包含猫和狗两种类别的图像数据集,其中猫类别的图像存储在 “cat” 文件夹中,狗类别的图像存储在 “dog” 文件夹中,
那么当你使用 keras.preprocessing.image_dataset_from_directory() 函数加载数据集时,会自动将 “cat” 和 “dog” 文件夹作为两个不同的类别,
并将它们的名称存储在 train_ds.class_names 属性中。
执行该代码后,你就可以在控制台或者输出窗口中看到包含数据集中所有类别名称的列表。这些名称通常是按照字母顺序排列的
因此,train_ds.class_names 属性可以让你方便地查看数据集中所有的类别名称,以便后续的模型训练、预测和评估等任务。
如果你要对数据集进行多类别分类,则需要根据 train_ds.class_names 的元素个数设置输出层的神经元数量,并将每个类别与一个唯一的整数标签相关联。

2、数据可视化
plt.figure(figsize = (20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[np.argmax(labels[i])]) #返回当前处理的图像所代表的类别的索引。plt.axis("off")
train_ds.take(1) 是一个方法调用,它返回一个数据集对象 train_ds 中的子集,其中包含了 take() 方法参数指定的数量的样本。
在这个例子中,take(1) 意味着我们从 train_ds 数据集中获取一批包含一个样本的数据块。
因此,for images, labels in train_ds.take(1): 的作用是遍历这个包含一个样本的数据块,并将其中的图像张量和标签张量依次赋值给变量 images 和 labels。具体来说,
它的执行过程如下:
从 train_ds 数据集中获取一批大小为 1 的数据块。
遍历这个数据块,每次获取一个图像张量和一个标签张量。
将当前图像张量赋值给变量 images,将当前标签张量赋值给变量 labels。
执行 for 循环中的代码块,即对当前图像张量和标签张量进行处理。
plt.imshow() 函数是 Matplotlib 库中用于显示图像的函数,它接受一个数组或张量作为输入,并在窗口中显示对应的图像。
在这个代码中,images[i] 表示从训练集中获取的第 i 个图像张量。由于 images 是一个包含多个图像的张量列表,因此使用 images[i] 可以获取其中的一个图像。
由于 imshow() 函数需要输入的数组或张量的类型是整型或浮点型,而从数据集中获取的图像张量通常是浮点型张量,因此需要将其转换为整型张量,以便进行显示。
这里使用了 .numpy().astype(“uint8”) 操作来将图像张量转换为整型张量(uint8 表示无符号8位整数),然后将结果传递给 plt.imshow() 函数进行显示。
因此,plt.imshow(images[i].numpy().astype(“uint8”)) 的作用是在 Matplotlib 窗口中显示训练集中的第 i 个图像。
你可以通过改变 i 的值来显示不同的图像,例如 i = 0 表示显示训练集中的第一张图像。
plt.axis(“off”) 是 Matplotlib 库中的一个函数调用,它用于控制图像显示时的坐标轴是否可见。
具体来说,当参数为 “off” 时,图像的坐标轴会被关闭,不会显示在图像周围。这个函数通常在 plt.imshow() 函数之后调用,以便在显示图像时去掉多余的细节信息,仅仅显示图像本身。

3、检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break

4、配置数据集
##2.3、配置数据集
AUTOTUNE = tf.data.AUTOTUNE
"""
定义 AUTOTUNE 常量
这个常量的作用是指定 TensorFlow 数据管道读取数据时使用的线程个数,使得数据读取可以尽可能地并行化,提升数据读取效率。
具体来说,AUTOTUNE 的取值会根据系统资源和硬件配置等因素自动调节。"""def train_preprocessing(image, label):return (image / 255.0, label)"""这个函数的作用是对输入的图像数据进行预处理操作,其中 image 表示输入的原始图像数据,label 表示对应的标签信息。
函数体内的操作是把原始图像数据除以 255,使其数值归一化到 0 和 1 之间。
函数返回一个元组 (image / 255.0, label),其中第一个元素是经过处理后的图像数据,第二个元素是对应的标签信息。
"""#归一化处理train_ds = train_ds.cache().shuffle(1000).map(train_preprocessing).prefetch(buffer_size = AUTOTUNE)
val_ds = val_ds.cache().shuffle(1000).map(train_preprocessing).prefetch(buffer_size = AUTOTUNE)
AUTOTUNE 是 TensorFlow 的一个常量,它的值取决于当前硬件配置和运行环境。
它表示 TensorFlow 数据处理流程中可以自动选择最优化参数(例如 GPU 处理数量等)的范围,在不同的硬件配置下可能会有不同的取值。
在这个代码片段中,AUTOTUNE 的作用是为数据集的预处理过程提供了一个启发式的缓冲大小,以便更好地平衡内存使用和计算速度。
train_preprocessing 函数定义了对输入图像数据进行预处理的操作,其中 image 表示输入的原始图像数据,label 表示对应的标签信息。函数体内的操作是将原始图像数据除以 255,使其数值归一化到 0 和 1 之间。函数返回一个元组 (image / 255.0, label),其中第一个元素是经过处理后的图像数据,第二个元素是对应的标签信息。
接下来,训练数据集 train_ds 和验证数据集 val_ds 进行了一系列操作。首先使用 cache() 方法对数据集进行缓存,然后使用 shuffle(1000) 方法随机打乱数据集中的样本,接着使用 map(train_preprocessing) 方法对每个样本应用 train_preprocessing 函数进行预处理,最后使用 prefetch(buffer_size = AUTOTUNE) 方法预取数据以提高训练的效率。
五、搭建CNN网络
from tensorflow.keras.layers import BatchNormalization
#from tensorflow.keras.models import Modeldef create_model(optimizer = 'adam'):vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights = 'imagenet', include_top = False, input_shape = (img_width, img_height, 3), pooling = 'avg')for layer in vgg16_base_model.layers:layer.trainable = FalseX = vgg16_base_model.outputX = Dense(170, activation = 'relu')(X)X = BatchNormalization()(X)X = Dropout(0.5)(X)output = Dense(len(class_names), activation = 'softmax')(X)vgg16_model = Model(inputs = vgg16_base_model.input, outputs = output)vgg16_model.compile(optimizer = optimizer,loss = 'sparse_categorical_crossentropy',metrics = ['accuracy'])return vgg16_modelmodel1 = create_model(optimizer = tf.keras.optimizers.Adam())
model2 = create_model(optimizer = tf.keras.optimizers.SGD())
model2.summary()
首先,从 tensorflow.keras.layers 模块导入了 BatchNormalization 层。注释掉的那行代码导入了 Model 类,但在代码中并没有使用到。
接下来,定义了一个名为 create_model 的函数,该函数接受一个参数 optimizer(默认为 ‘adam’)。函数内部首先使用 tf.keras.applications.vgg16.VGG16 加载了预训练的 VGG16 模型,其中 weights = ‘imagenet’ 表示使用 ImageNet 数据集的预训练权重,include_top = False 表示不包含顶层的全连接层,input_shape 设置输入图像的形状,pooling = ‘avg’ 表示使用平均池化。
然后,对 VGG16 模型的所有层进行循环遍历,将每一层的 trainable 属性设置为 False,即冻结预训练参数,使它们在训练过程中保持不变。
接下来,将 VGG16 模型的输出作为输入,并经过一系列的神经网络层进行特征提取和分类。首先是全连接层 Dense(170, activation = ‘relu’),然后是批归一化层 BatchNormalization(),最后是丢弃层 Dropout(0.5),用于防止过拟合。
最后一层是输出层 Dense(len(class_names), activation = ‘softmax’),其中 len(class_names) 是类别的数量,根据具体情况进行设置,激活函数使用 softmax。
接下来,使用 Model 函数创建了一个新的模型 vgg16_model,指定了输入和输出。这里的 vgg16_base_model.input 表示 VGG16 模型的输入,output 表示上述神经网络层的输出。
然后,使用 compile 方法编译了模型,指定了优化器、损失函数和评估指标。优化器根据传入的参数进行选择,如果没有指定,默认为 Adam 优化器。损失函数使用稀疏分类交叉熵,评估指标为准确率。
最后,函数返回创建的模型。
接下来,通过调用 create_model 函数分别创建了两个模型 model1 和 model2,分别使用了 Adam 优化器和 SGD 优化器。最后调用 model2.summary() 打印了 model2 的模型摘要信息。

六、训练模型
NO_EPOCHS = 50
history_model1 = model1.fit(train_ds, epochs = NO_EPOCHS, verbose = 1, validation_data = val_ds)
history_model2 = model2.fit(train_ds, epochs = NO_EPOCHS, verbose = 1, validation_data = val_ds)
使用 fit 方法训练了 model1 和 model2 模型,并将训练过程中的指标记录在 history_model1 和 history_model2 中。
参数 train_ds 是训练数据集,epochs 指定训练轮数,verbose 控制是否打印训练过程中的日志信息(这里设置为 1,表示打印日志),validation_data 是验证数据集,用于在每个训练轮结束后评估模型性能。

七、模型评估
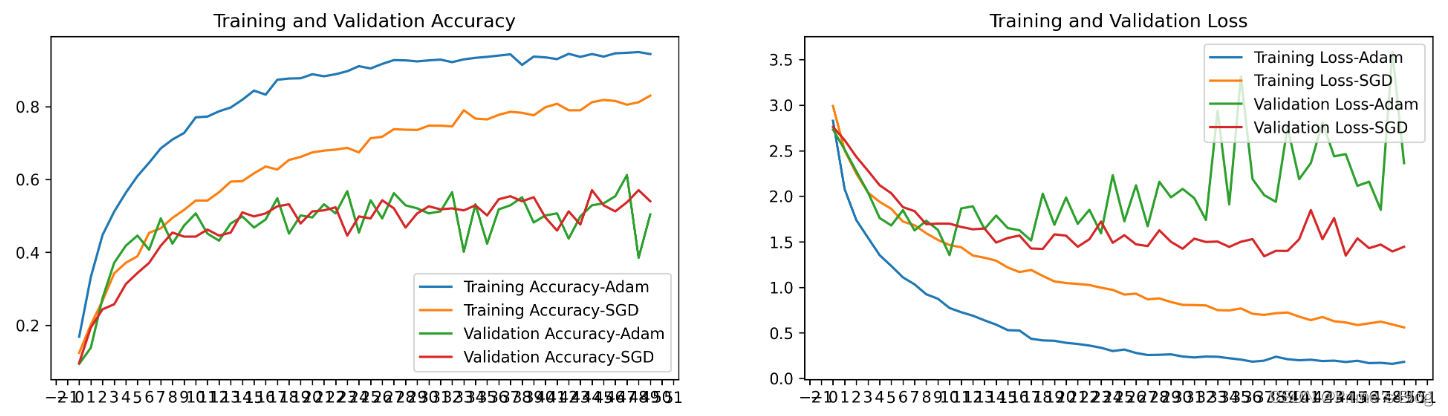
1、Loss和Acc图
from matplotlib.ticker import MultipleLocator
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300 #分辨率acc1 = history_model1.history['accuracy']
acc2 = history_model2.history['accuracy']
val_acc1 = history_model1.history['val_accuracy']
val_acc2 = history_model2.history['val_accuracy']loss1 = history_model1.history['loss']
loss2 = history_model2.history['loss']
val_loss1 = history_model1.history['val_loss']
val_loss2 = history_model2.history['val_loss']epochs_range = range(len(acc1))
plt.figure(figsize = (16, 4))
plt.subplot(1, 2, 1)plt.plot(epochs_range, acc1, label = 'Training Accuracy-Adam')
plt.plot(epochs_range, acc2, label = 'Training Accuracy-SGD')
plt.plot(epochs_range, val_acc1, label = 'Validation Accuracy-Adam')
plt.plot(epochs_range, val_acc2, label = 'Validation Accuracy-SGD')
plt.legend(loc = 'lower right')
plt.title('Training and Validation Accuracy')
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss1, label = 'Training Loss-Adam')
plt.plot(epochs_range, loss2, label = 'Training Loss-SGD')
plt.plot(epochs_range, val_loss1, label = 'Validation Loss-Adam')
plt.plot(epochs_range, val_loss2, label = 'Validation Loss-SGD')
plt.legend(loc = 'upper right')
plt.title('Training and Validation Loss')
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))plt.show()
2、模型评估
def test_accuracy_report(model):score = model.evaluate(val_ds, verbose = 0)print('Loss function; %s, accuracy:' % score[0], score[1])print('model1:')
test_accuracy_report(model1)
print('model2:')
test_accuracy_report(model2)
'''

八、总结
通过本次实验,学会了进行对比实验,可以比较不同优化器在训练过程中的性能表现,可视化训练过程的损失曲线和准确率等指标。这是一项非常重要的技能,在研究论文中,我们可以通过这些优化方法可以提高工作量。
相关文章:
深度学习-第T11周——优化器对比实验
深度学习-第T11周——优化器对比实验 深度学习-第T11周——优化器对比实验一、前言二、我的环境三、前期工作1、导入数据集2、查看图片数目3、查看数据 四、数据预处理1、 加载数据1、设置图片格式2、划分训练集3、划分验证集4、查看标签 2、数据可视化3、检查数据4、配置数据集…...
基于Dlib的疲劳检测系统
需要源码的朋友可以私信我 基于Dlib的疲劳检测系统 1、设计背景及要求2、系统分析3、系统设计3.1功能结构图3.2基于EAR、MAR和HPE算法的疲劳检测3.2.1基于EAR算法的眨眼检测3.2.2基于MAR算法的哈欠检测3.3.3基于HPE算法的点头检测 4、系统实现与调试4.1初步实现4.2具体实现过程…...

three.js通过CubeTexture加载环境贴图,和RGBELoader加载器加载hdr环境贴图
一、使用CubeTexture进行环境贴图 1.CubeTexture使用介绍 Three.js中可以通过使用CubeTexture进行环境贴图,CubeTexture需要将6张图片(正面、反面、上下左右)包装成一个立方体纹理。下面是一个简单的例子: 首先需要加载六张贴图…...
pycharm中Terminal输入sqlite3,出现无法将sqlite项识别为cmdlet**的解决方法
前提:本机上已安装sqlite3,安装详见:pycharm社区版中安装配置sqlite3_Sunshine_0426的博客-CSDN博客 问题: cmd命令行中或pycharm中Terminal行输入sqlite3 db.sqlite3命令后,出现“无法将“sqlite3”项识别为 cmdlet…...
VSCode 安装配置教程详解包含c++环境配置方法
vscode安装教程及c环境配置详解 vscode下载安装下载C扩展插件VScode C环境配置配置环境变量检查 MinGW 安装配置编译器:配置构建任务检查是否安装了编译器配置完毕 vscode下载安装 地址:官网下载地址 直接打开下载好的.exe文件进行安装即可࿰…...
)
Baumer工业相机堡盟工业相机如何通过BGAPISDK将图像放大缩小显示(C#)
Baumer工业相机堡盟工业相机如何通过BGAPISDK将图像放大缩小显示(C#) Baumer工业相机Baumer工业相机BGAPISDK和图像放大缩小的技术背景Baumer工业相机通过BGAPISDK将相机图像图像放大缩小功能1.引用合适的类文件2.通过BGAPISDK将相机图像图像放大缩小功能…...

8.1 PowerBI系列之DAX函数专题-进阶-解决列排序对计算的影响
需求 下列矩阵中,在月份列不按照原始数据的month_no排列时,能正确计算销售额占比,但是当月份按照month_no排序时就会出错,需要解决这个问题。 实现 month % divide([amount],calculate([amount],all(date[month desc]))) //排…...
Java的第十二篇文章——集合
目录 第十二章 集合 学习目标 1. 集合框架的由来 2. 集合框架的继承体系 3. Collection接口 3.1 Collection接口的常用方法 4. Iterator接口 4.1 Iterator接口的抽象方法 4.2 获取迭代器接口实现类 4.3 迭代器的实现原理 4.4 并发修改异常 4.5 集合存储自定义对象并…...

docker 镜像制作 与 CI/CD
目录 镜像到底是什么? 使用docker创建镜像 步骤: 1、编辑Dockerfile(Dockerfile是docker制作镜像的配方文件) 2、编辑requirements.txt文件 3、编辑app.py文件,我们的程序文件 4、生成镜像文件 5、查看生成的镜…...
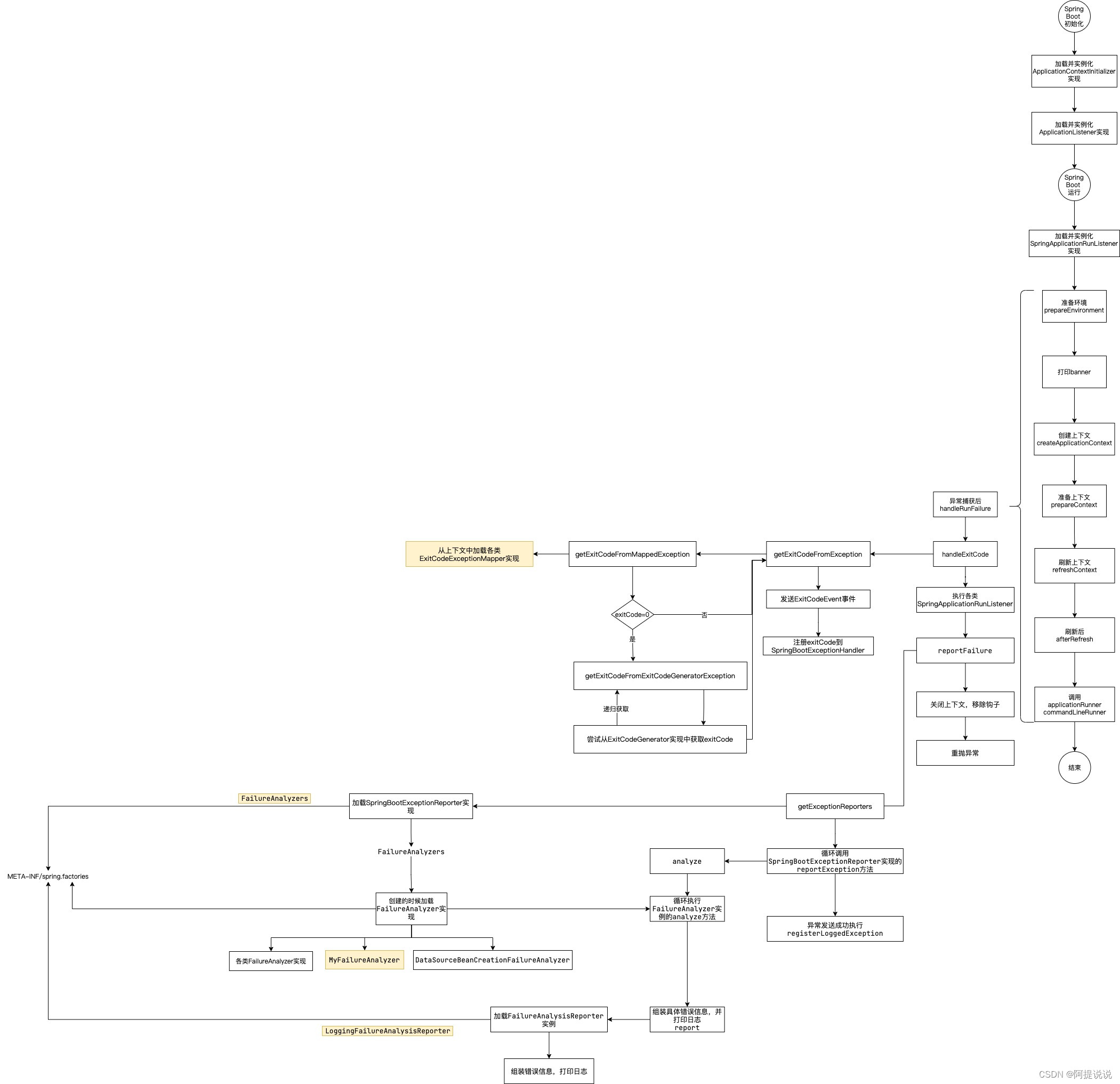
Spring Boot 异常报告器解析
基于Spring Boot 3.1.0 系列文章 Spring Boot 源码阅读初始化环境搭建Spring Boot 框架整体启动流程详解Spring Boot 系统初始化器详解Spring Boot 监听器详解Spring Boot banner详解Spring Boot 属性配置解析Spring Boot 属性加载原理解析Spring Boot 异常报告器解析 创建自定…...

瑞亚太空活动公司RSA与英国国防与安全加速器达成量子项目合作
(图片来源:网络) 瑞亚太空活动公司(RSA)与英国国防与安全加速器(DASA)签署了合作协议,主要开发名为“无限交换”的可操纵量子真空的技术项目。这是RSA在英国签订的第一份合同&…...

Shapley值法介绍及实例计算
Shapley值法介绍及实例计算 为解决多个局中人在合作过程中因利益分配而产生矛盾的问题,属于合作博弈领域。应用 Shapley 值的一大优势是按照成员对联盟的边际贡献率将利益进行分配,即成员 i 所分得的利益等于该成员为他所参与联盟创造的边际利益的平均值…...
不用手动改 package.json 的版本号
“为什么package.json 里的版本还是原来的,有没有更新?”,这个时候我意识到,我们完全没有必要在每次发布的时候还特意去关注这个仓库的版本号,只要在发布打tag的时候同步一下即可 node.js 部分,我们得有一个…...

gitlab Can‘t update,dev has no tracked branch
代码仓库迁移到gitlab后本地更改仓库地址后 拉取代码报错: Can’t update,dev has no tracked branch: 解决办法: 在当前项目的目录下运行命令: git branch -u git dev --set-upstream-toorigin/dev第一个dev是本地分支名字&…...

sql批量操作
SQl: 1,在某一字段后批量增加内容:UPDATE 表名 SET 字段 CONCAT(字段,要增加的内容) 例:UPDATE b8_niuniu_permission SET game_ids CONCAT(game_ids,,3) (或者后面可以加where条件) 2,批量修改某一字段…...

数据库监控与调优【九】—— 索引数据结构
索引数据结构-B-Tree索引、Hash索引、空间索引、全文索引 二叉树查找 对于相同深度的节点,左侧的节点总是比右侧的节点小。在搜索时,如果要搜索的值key大于根节点(图中6),就会在右侧子树里查找;key小于根…...

哈工大计算机网络传输层详解之:流水线机制与滑动窗口协议
哈工大计算机网络传输层详解之:流水线机制与滑动窗口协议 哈工大计算机网络课程传输层协议详解之:可靠数据传输的基本原理哈工大计算机网络课程传输层协议详解之:TCP协议哈工大计算机网络课程传输层协议详解之:拥塞控制原理剖析 …...
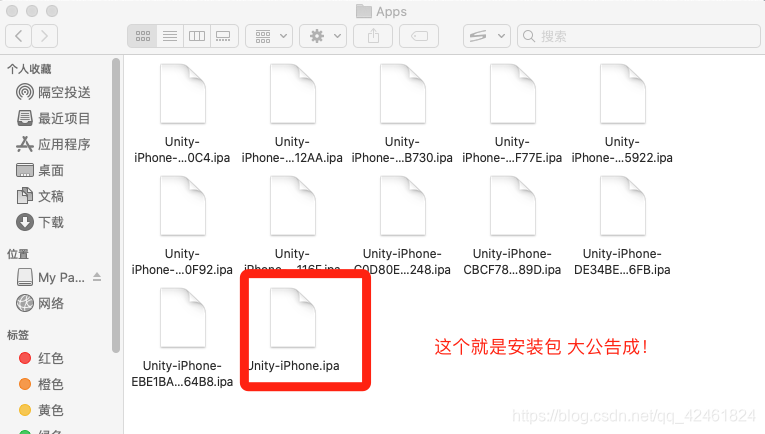
Unity Mac最新打苹果包流程
作者介绍:铸梦xy。IT公司技术合伙人,IT高级讲师,资深Unity架构师,铸梦之路系列课程创始人。 IOS详细打包流程1.申请APPID2.申请开发证书3.创建描述文件 IOS详细打包流程 1.申请AppID 2.创建证书 3.申请配置文件(又名描…...

【MySQL数据库 | 第二十篇】explain执行计划
目录 前言: explain: 语法: 总结: 前言: 上一篇我们介绍了从时间角度分析MySQL语句执行效率的三大工具:SQL执行频率,慢日志查询,profile。但是这三个方法也只是在时间角度粗略的…...

学Python能做哪些副业?我一般不告诉别人!建议存好
前两天一个朋友找到我吐槽,说工资一发交完房租水电,啥也不剩,搞不懂朋友圈里那些天天吃喝玩乐的同龄人钱都是哪来的?确实如此,刚毕业的大学生工资起薪都很低,在高消费、高租金的城市,别说存钱&a…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

【DeepSeek事件驱动架构实战指南】:20年架构师亲授5大核心陷阱与避坑清单
更多请点击: https://kaifayun.com 第一章:DeepSeek事件驱动架构全景认知 DeepSeek事件驱动架构(Event-Driven Architecture, EDA)并非单一技术组件的堆叠,而是一种以事件为第一公民、强调松耦合与异步协作的系统设计…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...