【Java/大数据】Kafka简介
Kafka简介
- Kafka概念
- 关键功能
- 应用场景
- Kafka的原理
- Kafka 的消息模型
- 早期的队列模型
- 发布-订阅模型
- Producer、Consumer、Broker、Topic、Partition
- Partition
- offset
- ISR
- Consumer Group
- leader选举
- Controller leader
- Partition leader
- producer 的写入流程
- 多副本机制
- replicas的同步时机
- 好处
- kafka的优化
- 吞吐量
- zookeeper在kafka中的作用
- Broker注册
- Topic注册
- 生产者负载均衡
- 消费者负载均衡
- 分区 与 消费者 的关系
- 消息 消费进度Offset 记录
- 消费者注册
- kafka对消息的保证
- Kafka 如何保证消息的消费顺序
- Kafka 如何保证消息不丢失
- 生产者丢失消息的情况
- 消费者丢失消息的情况
- Kafka 弄丢了消息
- Kafka 如何保证消息不重复消费
- kafka和rabbitMq的对比
- Kafka实战:在Spring Boot 程序中使用 Kafka 作为消息队列
- 1.创建项目
- 2.配置kafka
- 3.创建要发送的消息实体类
- 4.创建发送消息的生产者
- 5.创建消费消息的消费者
- 6.创建一个 Rest Controller
- 7.测试
主要内容是kafka的原理和使用
参考https://www.cnblogs.com/answerThe/p/11267454.html
Kafka概念
Kafka 是一个分布式流式处理平台
关键功能
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 容错的持久方式存储记录消息流:Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
- 流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
应用场景
- 消息队列:建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
- 数据处理: 构建实时的流数据处理程序来转换或处理数据流。
Kafka的原理
Kafka 的消息模型
早期的队列模型
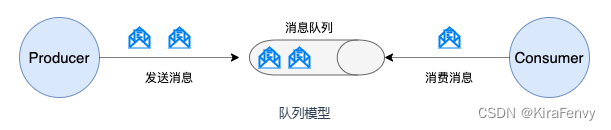
使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。 比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
假如我们存在这样一种情况:我们需要将生产者产生的消息分发给多个消费者,并且每个消费者都能接收到完整的消息内容。这种情况,队列模型就不好解决了。
发布-订阅模型

发布订阅模型(Pub-Sub) 使用主题(Topic) 作为消息通信载体,类似于广播模式;发布者发布一条消息,该消息通过主题传递给所有的订阅者,在一条消息广播之后才订阅的用户则是收不到该条消息的。
在发布 - 订阅模型中,如果只有一个订阅者,那它和队列模型就基本是一样的了。所以说,发布 - 订阅模型在功能层面上是可以兼容队列模型的。
Producer、Consumer、Broker、Topic、Partition
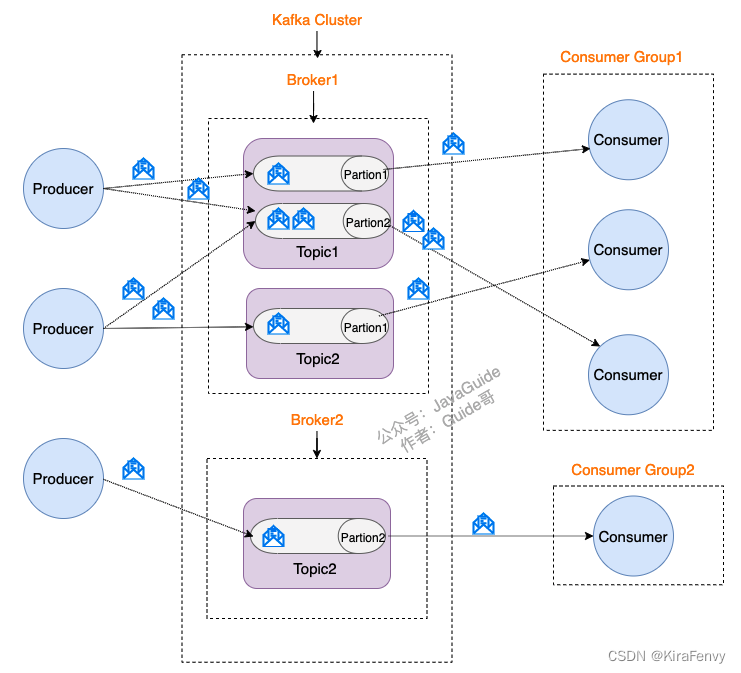
- Producer(生产者) : 产生消息的一方。
- Consumer(消费者) : 消费消息的一方,每个 Consumer 实例归属于一个 Consumer Group
- Broker(代理) : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
- Topic(主题) : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
- Partition(分区) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。
Partition
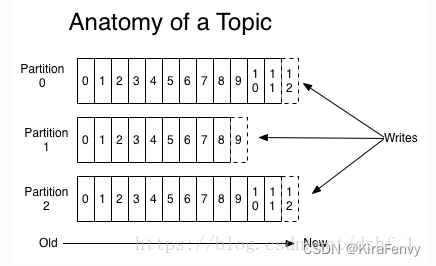
partition可以看作一个有序的队列,里面的数据是储存在硬盘中的,追加式的。partition的作用就是提供分布式的扩展,一个topic可以有许多partions,多个partition可以并行处理数据,所以可以处理相当量的数据。只有partition的leader才会进行读写操作,folower仅进行复制,客户端是感知不到的。
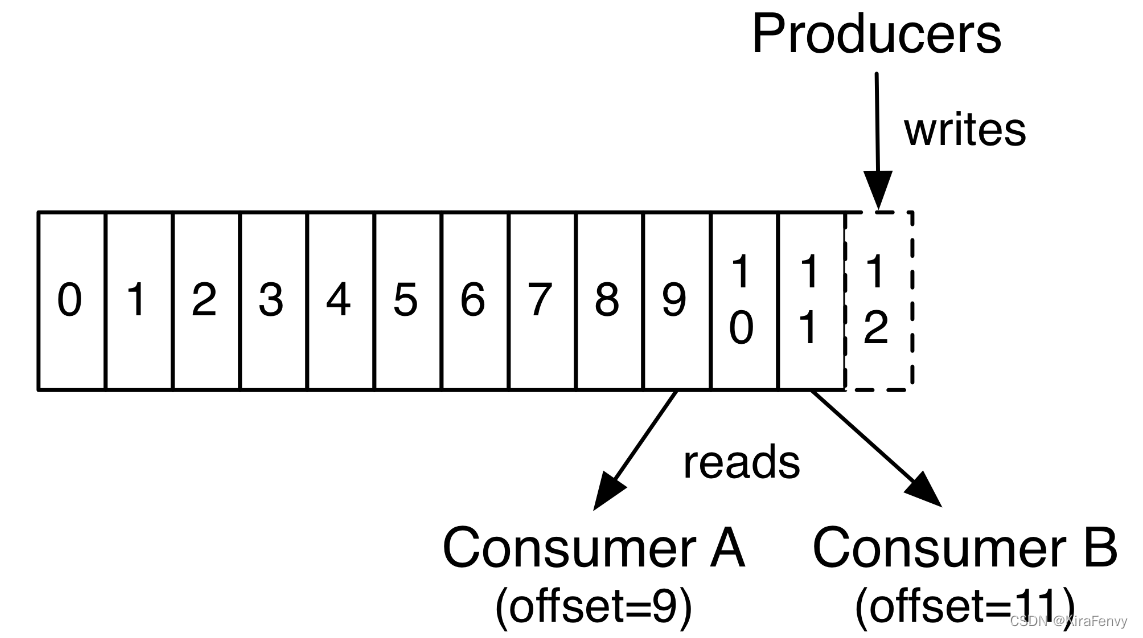
offset
每一条数据都有一个offset,是每一条数据在该partition中的唯一标识。各个consumer控制和设置其在该partition下消费到offset位置,这样下次可以以该offset位置开始进行消费。
各个consumer的offset位置默认是在某一个broker当中的topic中保存的(为防止该broker宕掉无法获取offset信息,可以配置在每个broker中都进行保存,配置文件中配置)
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
ISR
先来看几个概念
1、AR(Assigned Repllicas)一个partition的所有副本(就是replica,不区分leader或follower)
2、ISR(In-Sync Replicas)能够和 leader 保持同步的 follower + leader本身 组成的集合。
3、OSR(Out-Sync Relipcas)不能和 leader 保持同步的 follower 集合
4、公式:AR = ISR + OSR
ISR 的核心就是:动态调整
总结:Kafka采用的就是一种完全同步的方案,而ISR是基于完全同步的一种优化机制。
Consumer Group
Kafka中的消费组(Consumer Group)是一种机制,用于管理多个消费者之间的关系。消费组允许多个消费者同时消费Kafka主题中的消息,并且每个消费者可以负责消费一个或多个分区。
引入消费组,有以下优点:
- 提升整体消费能力:通过增加消费者数量,可以提升整体消费能力。在分区数固定的前提下,当消费者数量大于分区数时,部分消费者将无法分配到分区,但仍然可以加入消费组,从其他消费者那里获取消息,从而提高整体消费效率。
- 支持点对点模式和发布订阅模式:通过消费组,Kafka可以同时支持点对点模式和发布订阅模式。在点对点模式下,生产者将消息发送到队列,消费者从队列中获取消息。在发布订阅模式下,主题可以看作是消息传递的中介,生产者将消息发布到主题上,而消费者从主题中订阅消息。
- 实现伸缩性:通过增减消费者数量,可以提升或降低整体消费的能力。当需要处理更多消息时,可以增加更多的消费者;而当处理消息的需求减少时,可以减少消费者数量。
- 实现负载均衡:在消费组内,Kafka会自动实现负载均衡。Kafka会根据每个消费者的处理能力,将消息分配给不同的消费者,确保每个消费者都能充分利用其处理能力,从而提高整体处理效率。
leader选举
kafka集群中有2个种leader,一种是broker的leader即controller leader,还有一种就是partition的leader,下面介绍一下2种leader的选举大致流程。
Controller leader
当broker启动的时候,都会创建KafkaController对象,但是集群中只能有一个leader对外提供服务,这些每个节点上的KafkaController会在指定的zookeeper路径下创建临时节点,只有第一个成功创建的节点的KafkaController才可以成为leader,其余的都是follower。当leader故障后,所有的follower会收到通知,再次竞争在该路径下创建节点从而选举新的leader
Partition leader
由controller leader执行
- 从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合
- 调用配置的分区选择算法选择分区的leader
如何处理所有Replica都不工作?
在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某个Partition的所有Replica都宕机了,就无法保证数据不丢失了。这种情况下有两种可行的方案:
- 等待ISR中的任一个Replica“活”过来,并且选它作为Leader(等待时间短)
- 选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader(不是ISR中的Replica,不能保证一致性,不保证已经包含了所有已commit的消息)
producer 的写入流程
- producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
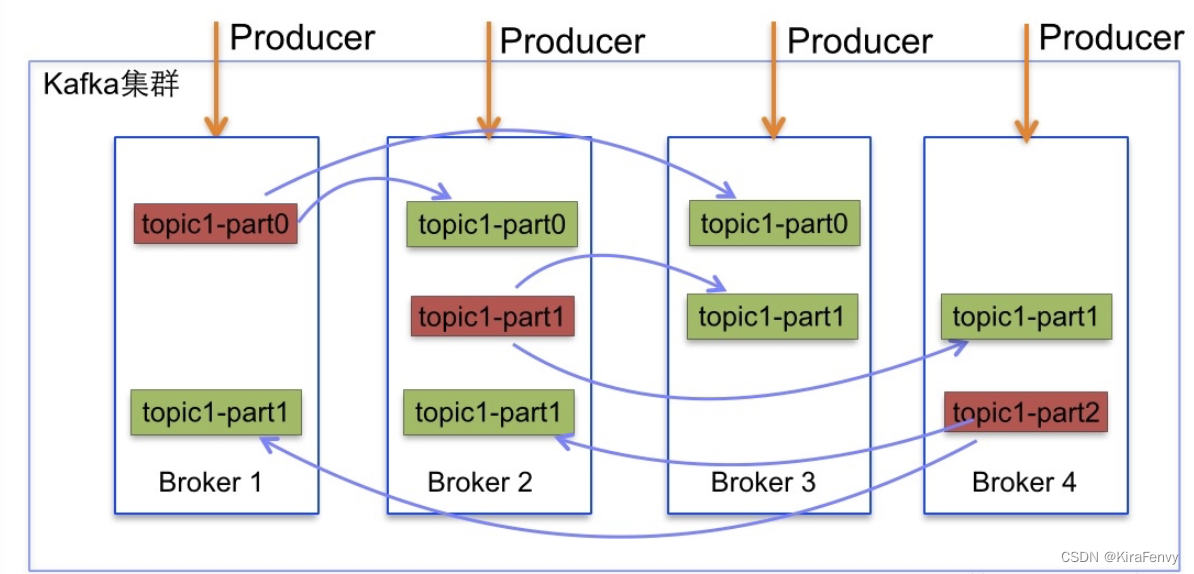
多副本机制
Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
replicas的同步时机
假如有N个replicas,其中一个replica为leader,其他都为follower,leader处理partition的所有读写请求,于此同时,follower会被动定期的去复制leader上的数据。
好处
Kafka 的多分区(Partition)以及多副本(Replica)机制的好处:
Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
kafka的优化
吞吐量
因为kafka的数据都是存储在硬盘中,甚至有的公司将kafka其作为数据库使用,既然数据是基于硬盘的,那么为何kafka还是能够拥有如此高的吞吐量呢?
1)硬盘的索引功能。二分查找法。
分区:找到响应的分区
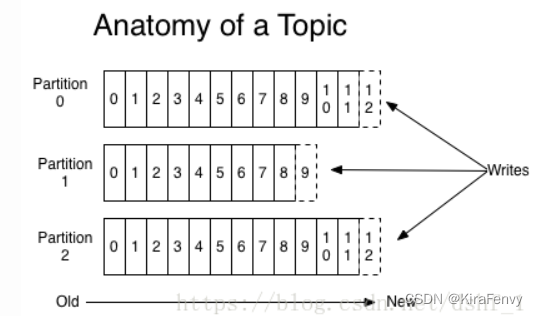
分段:根据文件segment的命名可以确认要查找的offset或timestamp在哪个文件中。
稀疏索引:快速确定要找的offset在哪个内存地址的附近。
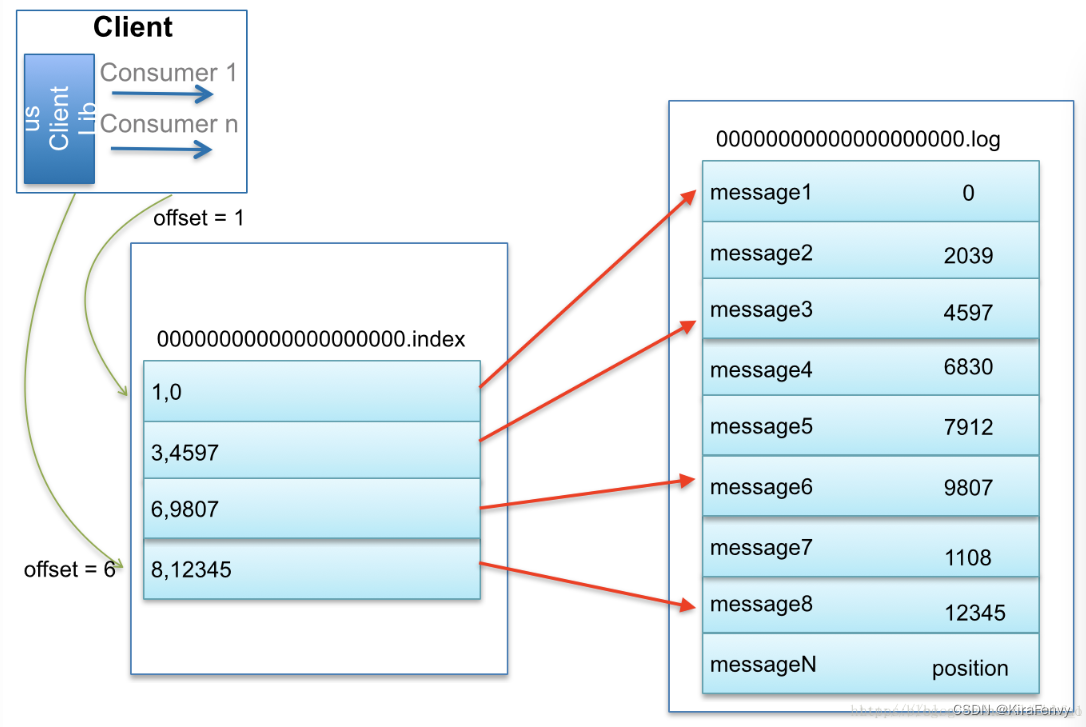
2)I/O优化
普通程序I/O需要把Disk中的信息复制到系统环境内存(步骤1),再复制到kafka应用环境内存(步骤2),然后步骤3,步骤4到Socket通过网络发出,重复复制文本,I/O消耗大。
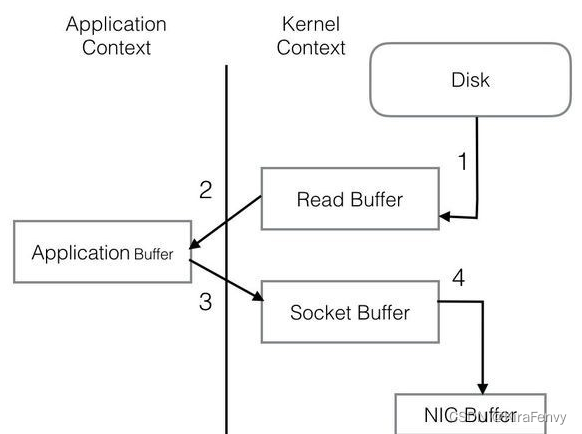
kafka的I/O:
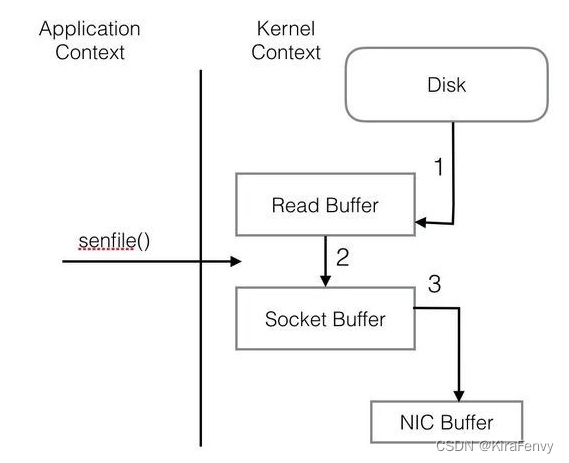
zookeeper在kafka中的作用
kafka默认在zk中的节点层级结构:
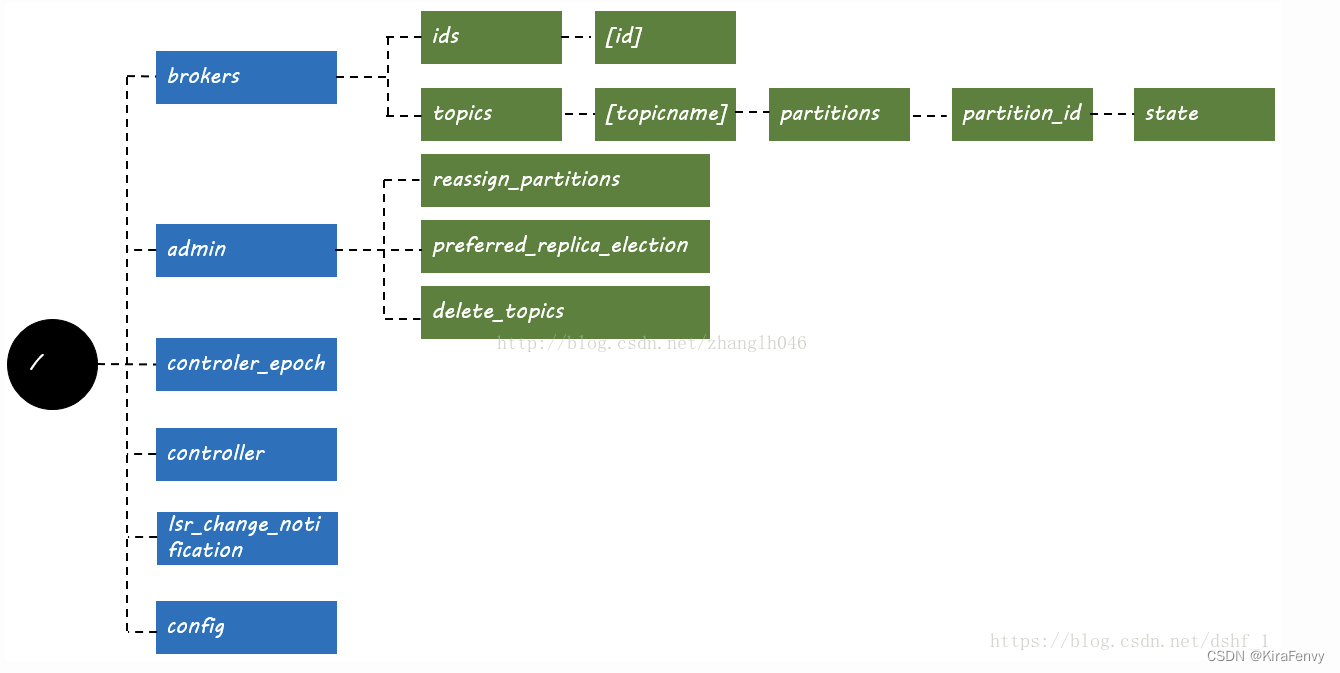
参考https://www.jianshu.com/p/a036405f989c
Broker注册
Broker是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper。
每个Broker就会将自己的IP地址和端口信息记录到该节点中去。
每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 /brokers/ids 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
Topic注册
在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1
生产者负载均衡
由于同一个Topic消息会被分区并将其分布在多个Broker上,因此,生产者需要将消息合理地发送到这些分布式的Broker上,那么如何实现生产者的负载均衡,Kafka支持传统的四层负载均衡,也支持Zookeeper方式实现负载均衡。
上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。
对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
消费者负载均衡
与生产者类似,Kafka中的消费者同样需要进行负载均衡来实现多个消费者合理地从对应的Broker服务器上接收消息,每个消费者分组包含若干消费者,每条消息都只会发送给分组中的一个消费者,不同的消费者分组消费自己特定的Topic下面的消息,互不干扰。
分区 与 消费者 的关系
在Kafka中,规定了每个消息分区 只能被同组的一个消费者进行消费,因此,需要在 Zookeeper 上记录 消息分区 与 Consumer 之间的关系
消息 消费进度Offset 记录
定时地将分区消息的消费进度Offset记录到Zookeeper上
消费者注册
消费者服务器在初始化启动时加入消费者分组的步骤如下:
-
注册到消费者分组。每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点,例如/consumers/[group_id]/ids/[consumer_id],完成节点创建后,消费者就会将自己订阅的Topic信息写入该临时节点。
-
对 消费者分组 中的 消费者 的变化注册监听。每个 消费者 都需要关注所属 消费者分组 中其他消费者服务器的变化情况,即对/consumers/[group_id]/ids节点注册子节点变化的Watcher监听,一旦发现消费者新增或减少,就触发消费者的负载均衡。
-
对Broker服务器变化注册监听。消费者需要对/broker/ids/[0-N]中的节点进行监听,如果发现Broker服务器列表发生变化,那么就根据具体情况来决定是否需要进行消费者负载均衡。
-
进行消费者负载均衡。为了让同一个Topic下不同分区的消息尽量均衡地被多个 消费者 消费而进行 消费者 与 消息 分区分配的过程,通常,对于一个消费者分组,如果组内的消费者服务器发生变更或Broker服务器发生变更,会发出消费者负载均衡。
kafka对消息的保证
Kafka 如何保证消息的消费顺序
我们在使用消息队列的过程中经常有业务场景需要严格保证消息的消费顺序,比如我们同时发了 2 个消息,这 2 个消息对应的操作分别对应的数据库操作是:
- 更改用户会员等级。
- 根据会员等级计算订单价格。
假如这两条消息的消费顺序不一样造成的最终结果就会截然不同。
我们知道 Kafka 中 Partition(分区)是真正保存消息的地方,我们发送的消息都被放在了这里。而我们的 Partition(分区) 又存在于 Topic(主题) 这个概念中,并且我们可以给特定 Topic 指定多个 Partition。
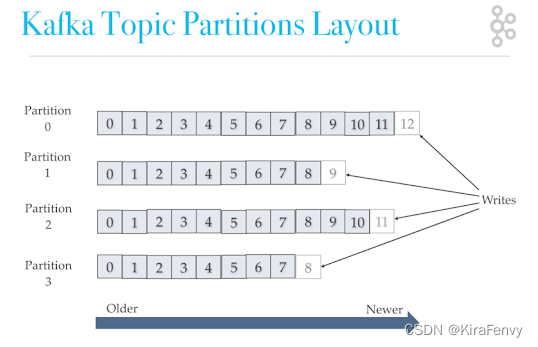
每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。 Kafka 只能为我们保证 Partition(分区) 中的消息有序。
消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。
Kafka 通过偏移量(offset)来保证消息在分区内的顺序性。
所以,我们就有一种很简单的保证消息消费顺序的方法:1 个 Topic 只对应一个 Partition。这样当然可以解决问题,但是破坏了 Kafka 的设计初衷。
Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id 来作为 key 。
总结一下,对于如何保证 Kafka 中消息消费的顺序,有了下面两种方法:
- 1 个 Topic 只对应一个 Partition。
- (推荐)发送消息的时候指定 key/Partition。
Kafka 如何保证消息不丢失
生产者丢失消息的情况
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
所以,我们不能默认在调用send方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();
if (sendResult.getRecordMetadata() != null) {logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendResult.getProducerRecord().value().toString());
}
但是一般不推荐这么做!可以采用为其添加回调函数的形式,示例代码如下:
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!另外这里推荐为 Producer 的retries (重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了
消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
Kafka 弄丢了消息
暂略
Kafka 如何保证消息不重复消费
kafka 出现消息重复消费的原因:
- 服务端侧已经消费的数据没有成功提交 offset(根本原因)。
- Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
解决方案:
- 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
- 将 enable.auto.commit 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:什么时候提交 offset 合适?
- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
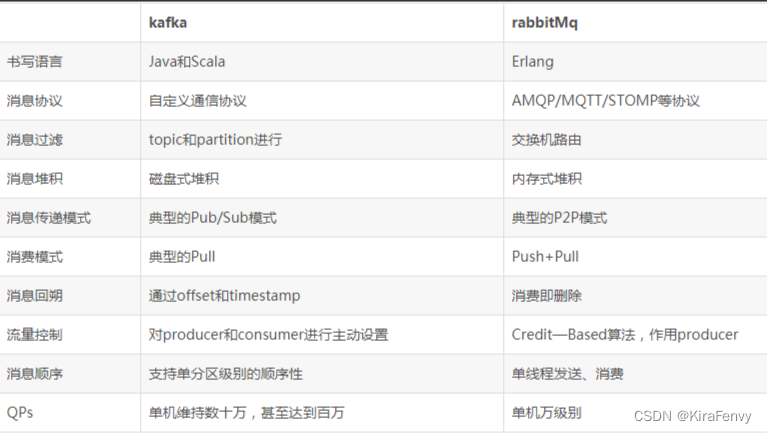
kafka和rabbitMq的对比
Kafka实战:在Spring Boot 程序中使用 Kafka 作为消息队列
1.创建项目
直接通过Spring 官方提供的 Spring Initializr 创建或者直接使用 IDEA 创建皆可。
2.配置kafka
通过 application.yml 配置文件配置 Kafka 基本信息
server:port:9090spring:kafka:consumer:bootstrap-servers:localhost:9092# 配置消费者消息offset是否自动重置(消费者重连会能够接收最开始的消息)auto-offset-reset:earliestproducer:bootstrap-servers:localhost:9092# 发送的对象信息变为json格式value-serializer:org.springframework.kafka.support.serializer.JsonSerializer
kafka:topic:my-topic:my-topicmy-topic2:my-topic2
Kafka 额外配置类KafkaConfig.java:
package cn.javaguide.springbootkafka01sendobjects.config;import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.support.converter.RecordMessageConverter;
import org.springframework.kafka.support.converter.StringJsonMessageConverter;/*** @author shuang.kou*/
@Configuration
publicclass KafkaConfig {@Value("${kafka.topic.my-topic}")String myTopic;@Value("${kafka.topic.my-topic2}")String myTopic2;/*** JSON消息转换器*/@Beanpublic RecordMessageConverter jsonConverter() {returnnew StringJsonMessageConverter();}/*** 通过注入一个 NewTopic 类型的 Bean 来创建 topic,如果 topic 已存在,则会忽略。*/@Beanpublic NewTopic myTopic() {returnnew NewTopic(myTopic, 2, (short) 1);}@Beanpublic NewTopic myTopic2() {returnnew NewTopic(myTopic2, 1, (short) 1);}
}
当我们到了这一步之后,你就可以试着运行项目了,运行成功后你会发现 Spring Boot 会为你创建两个topic:
my-topic: partition 数为 2, replica 数为 1
my-topic2:partition 数为 1, replica 数为 1
命令
kafka-topics --describe --zookeeper zoo1:2181
或者直接通过IDEA 提供的 Kafka 可视化管理插件-Kafkalytic 来查看
3.创建要发送的消息实体类
package cn.javaguide.springbootkafka01sendobjects.entity;publicclass Book {private Long id;private String name;public Book() {}public Book(Long id, String name) {this.id = id;this.name = name;}省略 getter/setter以及 toString方法
}4.创建发送消息的生产者
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;@Service
publicclass BookProducerService {privatestaticfinal Logger logger = LoggerFactory.getLogger(BookProducerService.class);privatefinal KafkaTemplate<String, Object> kafkaTemplate;public BookProducerService(KafkaTemplate<String, Object> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}public void sendMessage(String topic, Object o) {kafkaTemplate.send(topic, o);}
}
我们使用Kafka 提供的 KafkaTemplate 调用 send()方法出入要发往的topic和消息内容即可很方便的完成消息的发送:
kafkaTemplate.send(topic, o);
如果我们想要知道消息发送的结果的话,sendMessage方法这样写:
public void sendMessage(String topic, Object o) {try {SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();if (sendResult.getRecordMetadata() != null) {logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendResult.getProducerRecord().value().toString());}} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}}
但是这种属于同步的发送方式并不推荐,没有利用到 Future对象的特性。
KafkaTemplate 调用 send()方法实际上返回的是ListenableFuture 对象。
send()方法源码如下:
@Overridepublic ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {ProducerRecord<K, V> producerRecord = new ProducerRecord<>(topic, data);return doSend(producerRecord);}
ListenableFuture 是Spring提供了继承自Future 的接口。
ListenableFuture方法源码如下:
publicinterface ListenableFuture<T> extends Future<T> {void addCallback(ListenableFutureCallback<? super T> var1);void addCallback(SuccessCallback<? super T> var1, FailureCallback var2);default CompletableFuture<T> completable() {CompletableFuture<T> completable = new DelegatingCompletableFuture(this);this.addCallback(completable::complete, completable::completeExceptionally);return completable;}
}
继续优化sendMessage方法
public void sendMessage(String topic, Object o) {ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onSuccess(SendResult<String, Object> sendResult) {logger.info("生产者成功发送消息到" + topic + "-> " + sendResult.getProducerRecord().value().toString());}@Overridepublic void onFailure(Throwable throwable) {logger.error("生产者发送消息:{} 失败,原因:{}", o.toString(), throwable.getMessage());}});}
使用lambda表达式再继续优化:
public void sendMessage(String topic, Object o) {ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));}
我们使用send(String topic, @Nullable V data)方法的时候实际会new 一个ProducerRecord对象发送,
@Overridepublic ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {ProducerRecord<K, V> producerRecord = new ProducerRecord<>(topic, data);return doSend(producerRecord);}
ProducerRecord类中有多个构造方法:
public ProducerRecord(String topic, V value) {this(topic, null, null, null, value, null);}public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V......}
如果我们想在发送的时候带上timestamp(时间戳)、key等信息的话,sendMessage()方法可以这样写:
public void sendMessage(String topic, Object o) {// 分区编号最好为 null,交给 kafka 自己去分配ProducerRecord<String, Object> producerRecord = new ProducerRecord<>(topic, null, System.currentTimeMillis(), String.valueOf(o.hashCode()), o);ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(producerRecord);future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));}
5.创建消费消息的消费者
import cn.javaguide.springbootkafka01sendobjects.entity.Book;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;@Service
publicclass BookConsumerService {@Value("${kafka.topic.my-topic}")private String myTopic;@Value("${kafka.topic.my-topic2}")private String myTopic2;privatefinal Logger logger = LoggerFactory.getLogger(BookProducerService.class);privatefinal ObjectMapper objectMapper = new ObjectMapper();@KafkaListener(topics = {"${kafka.topic.my-topic}"}, groupId = "group1")public void consumeMessage(ConsumerRecord<String, String> bookConsumerRecord) {try {Book book = objectMapper.readValue(bookConsumerRecord.value(), Book.class);logger.info("消费者消费topic:{} partition:{}的消息 -> {}", bookConsumerRecord.topic(), bookConsumerRecord.partition(), book.toString());} catch (JsonProcessingException e) {e.printStackTrace();}}@KafkaListener(topics = {"${kafka.topic.my-topic2}"}, groupId = "group2")public void consumeMessage2(Book book) {logger.info("消费者消费{}的消息 -> {}", myTopic2, book.toString());}
}6.创建一个 Rest Controller
import cn.javaguide.springbootkafka01sendobjects.entity.Book;
import cn.javaguide.springbootkafka01sendobjects.service.BookProducerService;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import java.util.concurrent.atomic.AtomicLong;/*** @author shuang.kou*/
@RestController
@RequestMapping(value = "/book")
publicclass BookController {@Value("${kafka.topic.my-topic}")String myTopic;@Value("${kafka.topic.my-topic2}")String myTopic2;privatefinal BookProducerService producer;private AtomicLong atomicLong = new AtomicLong();BookController(BookProducerService producer) {this.producer = producer;}@PostMappingpublic void sendMessageToKafkaTopic(@RequestParam("name") String name) {this.producer.sendMessage(myTopic, new Book(atomicLong.addAndGet(1), name));this.producer.sendMessage(myTopic2, new Book(atomicLong.addAndGet(1), name));}
}
7.测试
输入命令:
curl -X POST -F 'name=Java' http://localhost:9090/book
my-topic 有2个partition(分区) 当你尝试发送多条消息的时候,你会发现消息会被比较均匀地发送到每个 partion 中
相关文章:
【Java/大数据】Kafka简介
Kafka简介 Kafka概念关键功能应用场景 Kafka的原理Kafka 的消息模型早期的队列模型发布-订阅模型Producer、Consumer、Broker、Topic、PartitionPartitionoffsetISR Consumer Groupleader选举Controller leaderPartition leader producer 的写入流程 多副本机制replicas的同步时…...

【动手学深度学习】读写文件
【动手学深度学习】读写文件 加载和保存张量 对于单个张量 我么可以直接调用load和save函数分别读写,这两个函数要求我们提供一个名称,save要求保存的变量作为输入 import torch from torch import nn from torch.nn import functional as F# 创建一个…...
http-server 的安装与使用
文章目录 问题背景http-server简介安装nodejs安装http-server开启http服务http-server参数 问题背景 打开一个文档默认使用file协议打开,不能发送ajax请求,只能使用http协议才能请求资源,所以此时我们需要在本地建立一个http服务,…...

SQL高级教程
SQL TOP 子句 TOP 子句 TOP 子句用于规定要返回的记录的数目。 对于拥有数千条记录的大型表来说,TOP 子句是非常有用的。 注释:并非所有的数据库系统都支持 TOP 子句。 SQL Server 的语法: SELECT TOP number|percent column_name(s) F…...
9.pixi.js编写的塔防游戏(类似保卫萝卜)-群炮弹发射逻辑
游戏说明 一个用pixi.js编写的h5塔防游戏,可以用electron打包为exe,支持移动端,也可以用webview控件打包为app在移动端使用 环境说明 cnpm6.2.0 npm6.14.13 node12.22.7 npminstall3.28.0 yarn1.22.10 npm config list electron_mirr…...
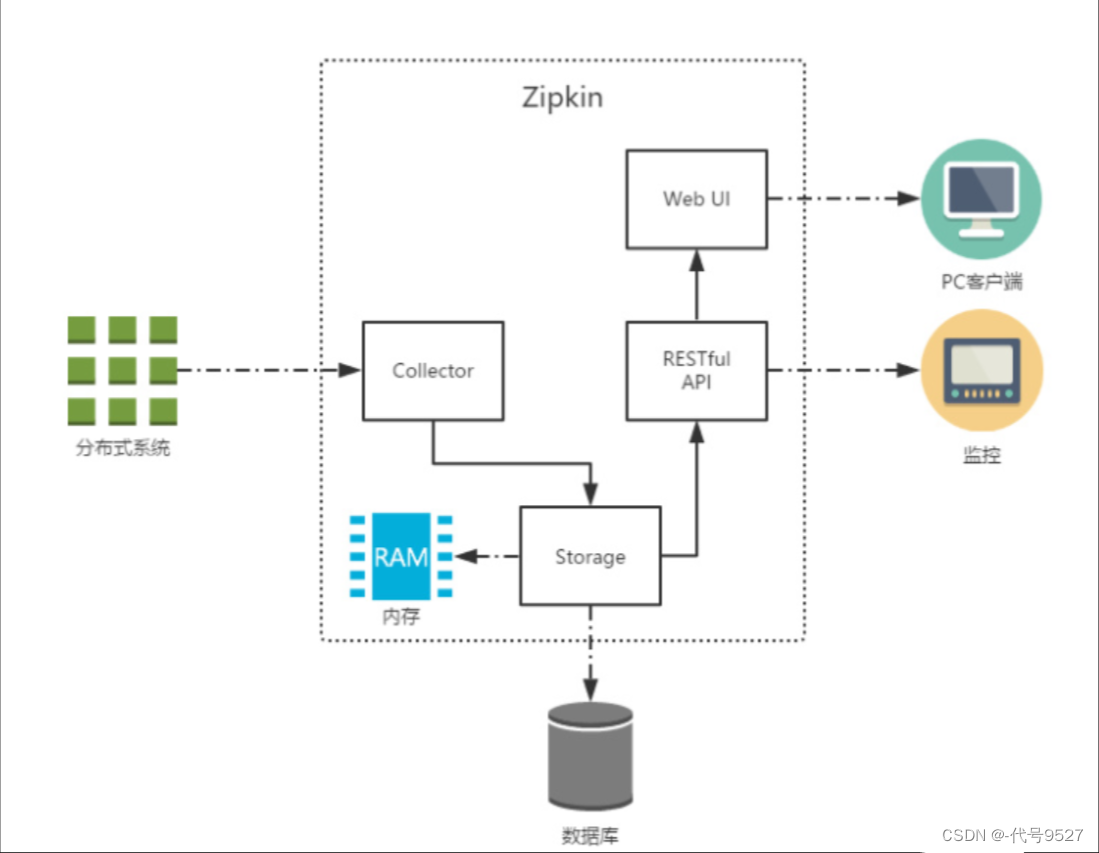
分布式链路追踪
文章目录 1、背景2、微服务架构下的问题3、链路追踪4、核心概念5、技术选型对比6、zipkin 1、背景 随着互联网业务快速扩展,软件架构也日益变得复杂,为了适应海量用户高并发请求,系统中越来越多的组件开始走向分布式化,如单体架构…...
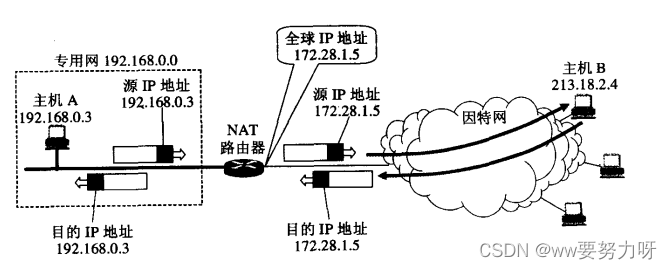
计算机网络————网络层
文章目录 网络层设计思路IP地址IP地址分类IP地址与硬件地址 协议ARP和RARPIP划分子网和构造超网划分子网构造超网(无分类编址CIDR) ICMP 虚拟专用网VPN和网络地址转换NATVPNNAT 网络层设计思路 网络层向上只提供简单灵活的、无连接的、尽最大努力交付的数…...
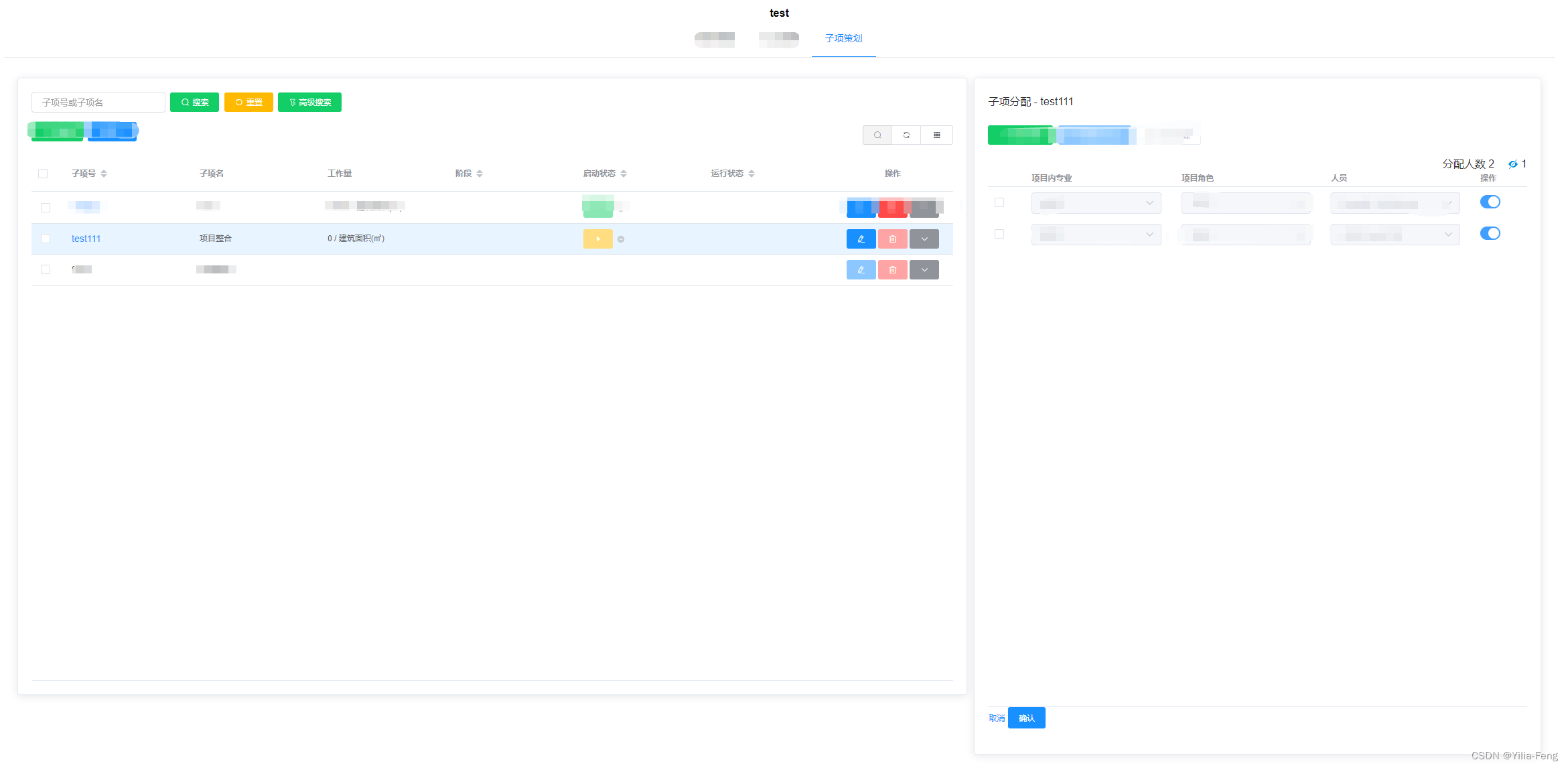
el-table刷新后保持高亮并改变状态字段
一、需求: 1、点击左侧右边显示具体内容 2、点击右边确认 左侧依旧高亮并且改变启动状态颜色 3、点击刷新、重置、高级搜索等不高亮 右边也不显示具体内容 二、效果图: 三、具体实施 1、定义highlight-current-row 是否高亮行 <el-table ref&quo…...

ARM Ubuntu内核更新记录
1,系统版本说明:ARM 鲲鹏920 cat /etc/lsb-release DISTRIB_IDUbuntu DISTRIB_RELEASE18.04 DISTRIB_CODENAMEbionic DISTRIB_DESCRIPTION"Ubuntu 18.04.5 LTS" 2, 将source.list中的deb-src打开 # 默认注释了源码镜像以提高 apt…...
【sgUploadTray】上传托盘自定义组件,可实时查看上传列表进度
【sgUploadTray】上传托盘自定义组件,可实时查看上传列表进度 特性: 可以全屏可以还原尺寸可以最小化可以回到右下角默认位置支持删除队列数据 sgUploadTray源码 <template><div :class"$options.name" :show"show" :size…...
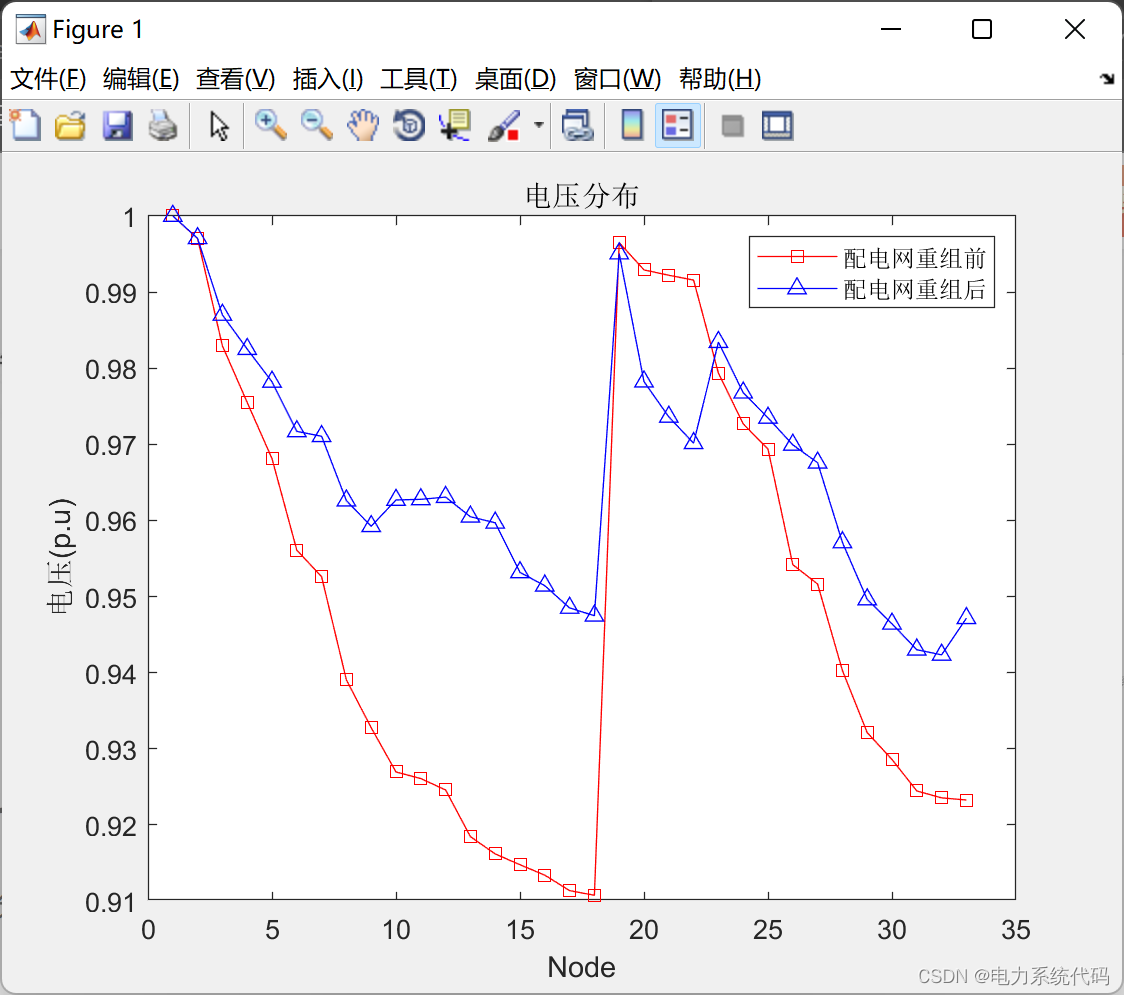
改进二进制粒子群算法在配电网重构中的应用(Matlab实现)【论文复现】
目录 0 概述 1 配电网重构的目标函数 2 算例 3 matlab代码实现 0 概述 配电系统中存在大量的分段开关和联络开关,配电网重构正是通过调整分段开关和联络升大的组合状态来变换网络结构,用于优化配电网某些指标,使其达到最优状态。正常运行时,则通…...

【文章系列解读】Nerf
1. Nerf NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 2020年8月3日 (0)总结 NeRF工作的过程可以分成两部分:三维重建和渲染。(1)三维重建部分本质上是一个2D到3D的建模过程ÿ…...

基于springboot,vue网上订餐系统
开发工具:IDEA 服务器:Tomcat9.0, jdk1.8 项目构建:maven 数据库:mysql5.7 前端技术 :VueElementUI 服务端技术:springbootmybatisredis 本系统分用户前台和管理后台两部分,项…...
Nautilus Chain 更换全新测试网,主网即将在不久上线
目前,Nautilus Chain 正在为主网上线前的最后阶段做准备,据悉该链更新了全新的测试网,在此前版本的测试网的基础上进行了全新的技术升级,最新测试网版本与生态发展的技术规划更为贴近。本次测试网升级将会是最后一次测试网版本的迭…...

攻防世界web:Web_php_wrong_nginx_config,python3后门
网上的wp中关于Web_php_wrong_nginx_config的后门代码都是python2的(源码来自:Weevely:一个 PHP 混淆后门的代码分析 - Phukers Blog) 以下是转换成python3的版本 # encoding: utf-8from random import randint, choice from ha…...

【VUE】解决图片视频加载缓慢/首屏加载白屏的问题
1 问题描述 在 Vue3 项目中,有时候会出现图片视频加载缓慢、首屏加载白屏的问题 2 原因分析 通常是由以下原因导致的: 图片或视频格式不当:如果图片或视频格式选择不当,比如选择了无损压缩格式,可能会导致文件大小过大…...
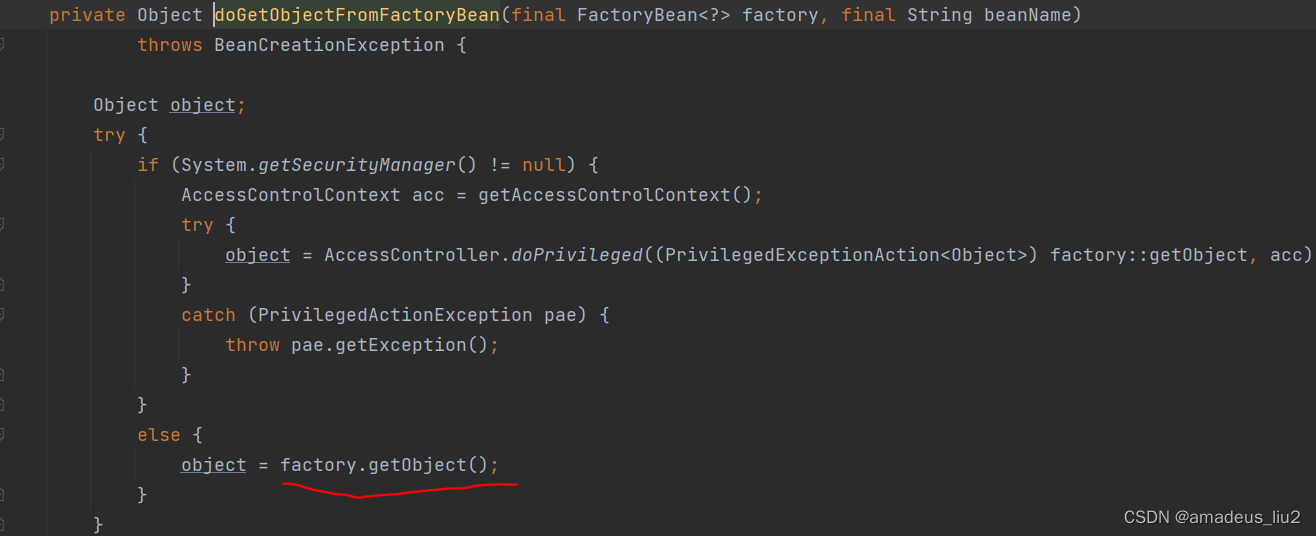
spring复习:(35)在getBean时,在哪里根据普通bean和工厂bean进行区分处理来返回的?
在AbstractBeanFactory的doGetBean方法: 调用的getObjectForBeanInstance方法部分代码如下: 如果不是工厂bean,则直接将实例返回,否则调用getObjectFromFactoryBean方法获取工厂bean的getObject方法返回的对象 protected Object getObjectF…...
Jenkins全栈体系(二)
Jenkins 第三章 Jenkins Git Maven 自动化部署配置 十、几种构建方式 快照依赖构建/Build whenever a SNAPSHOT dependency is built 当依赖的快照被构建时执行本job 触发远程构建 (例如,使用脚本) 远程调用本job的restapi时执行本job job依赖构建/Build after other proj…...
c++11 标准模板(STL)(std::basic_istream)(九)
定义于头文件 <istream> template< class CharT, class Traits std::char_traits<CharT> > class basic_istream : virtual public std::basic_ios<CharT, Traits> 类模板 basic_istream 提供字符流上的高层输入支持。受支持操作包含带格式的…...

OpenSource - Spring Startup Ananlyzer
文章目录 🚀Optimization of Spring Startup核心能力📈Spring应用启动数据采集报告应用启动时长优化 📈Spring应用启动数据采集报告安装jar包配置项应用启动自定义扩展 🚀应用启动时长优化支持异步化的Bean类型接入异步Bean优化 开…...

高效文件同步:SyncTrayzor在Windows上的完整解决方案
高效文件同步:SyncTrayzor在Windows上的完整解决方案 【免费下载链接】SyncTrayzor Windows tray utility / filesystem watcher / launcher for Syncthing 项目地址: https://gitcode.com/gh_mirrors/sy/SyncTrayzor SyncTrayzor是Windows平台上最实用的Syn…...
)
LLVM指令调度实战:如何用llvm-mca优化AArch64代码性能(附TSV110配置示例)
LLVM指令调度实战:如何用llvm-mca优化AArch64代码性能(附TSV110配置示例) 在ARM架构的性能优化领域,指令调度质量直接影响着关键计算任务的吞吐量。本文将带您深入llvm-mca工具链的实际应用,通过TSV110处理器的具体案例…...

AI智能体应用工程师:少数人掌握的高薪未来,你离入场还有多远
AI智能体应用工程师 — 国家战略人才项目|企业刚需资质—国务院发布关于实施“人工智能”行动。文中指出:到2027年,率先实现人工智能与6大重点领域广泛深度融合,新一代智能体终端、智能体等应用普及率超过70%。 各地省政府于2025年市级“A1产业”专项基金…...
)
手把手教你用GD32F30x的定时器搞定BLDC电机霍尔信号捕获(附完整代码)
手把手教你用GD32F30x的定时器实现BLDC电机霍尔信号精准捕获 当你的GD32F30x开发板已经连接好BLDC电机的霍尔传感器,却发现转速计算总是不准确时,问题往往出在定时器的配置细节上。本文将带你从寄存器层面拆解霍尔信号捕获的全流程,解决实际开…...

Anlogic FD工具深度体验:如何用eMCU软核实现SF1芯片的PSRAM控制器设计
Anlogic FD工具实战:基于eMCU软核的PSRAM控制器设计进阶指南 当FPGA工程师需要在资源受限的SF1芯片上实现高性能存储控制时,Anlogic Future Dynasty(FD)工具链中的eMCU软核与PSRAM控制器组合提供了绝佳的解决方案。不同于基础教程…...

拆解一个Buck电路实例:我是如何根据Datasheet为我的电源项目挑选MOS管的
拆解一个Buck电路实例:我是如何根据Datasheet为我的电源项目挑选MOS管的 当我在设计一款输入36V、输出12V/5A的Buck转换器时,MOS管的选择成了整个项目的关键转折点。市面上琳琅满目的型号让人眼花缭乱,而Datasheet里密密麻麻的参数表格更像是…...

Bing Wallpaper自动化部署:GitHub Actions与持续集成
Bing Wallpaper自动化部署:GitHub Actions与持续集成 【免费下载链接】bing-wallpaper 项目地址: https://gitcode.com/gh_mirrors/bi/bing-wallpaper Bing Wallpaper项目是一个专注于收集和展示Bing每日壁纸的开源项目,通过自动化部署可以确保壁…...

量化版SenseVoice语音识别体验:模型缩小74%,速度提升33%实测
量化版SenseVoice语音识别体验:模型缩小74%,速度提升33%实测 1. 引言 语音识别技术正在快速渗透到我们的日常生活和工作中,从智能客服到会议记录,从实时字幕到语音搜索,这项技术正在改变我们与设备交互的方式。然而&…...

OpenClaw定时任务实践:Qwen3.5-4B-Claude实现凌晨数据备份自动化
OpenClaw定时任务实践:Qwen3.5-4B-Claude实现凌晨数据备份自动化 1. 为什么需要夜间自动化备份 作为一个独立开发者,我经常遇到这样的困境:白天在多个项目间切换开发,晚上关机前才想起忘记备份关键数据。手动执行备份不仅占用休…...

解决B站视频收藏难题的8K超清下载解决方案:Bilidown全解析
解决B站视频收藏难题的8K超清下载解决方案:Bilidown全解析 【免费下载链接】bilidown 哔哩哔哩视频解析下载工具,支持 8K 视频、Hi-Res 音频、杜比视界下载、批量解析,可扫码登录,常驻托盘。 项目地址: https://gitcode.com/gh_…...