LangChain大型语言模型(LLM)应用开发(三):Chains

LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,以便在不同的应用程序中使用。
今天我们来学习DeepLearning.AI的在线课程:LangChain for LLM Application Development的第三门课:Chains,该门课程主要讲解LangChain的核心组件:链,即Chain, chain可以将大型语言模型(LLM)和提示语(prompt)结合在一起, 你还可以创建多种不同功能的Chain,然后将这些chain组合在一起,对文本或其他数据执行一系列操作。
目录
-
LLMChain
-
Sequential Chains
-
SimpleSequentialChain
-
SequentialChain
-
Router Chain
下面我们导入本地环境配置文件.env, 在.env文件中我们存放了opai的api key 。
import osfrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file下面我们导入一个csv文件,该文件存放了用户对产品的评论信息。
import pandas as pd
df = pd.read_csv('Data.csv')
df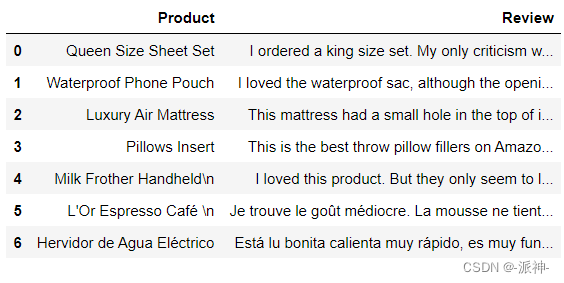
LLMChain
LLMChain是最基本的chain,他将LLM和prompt组合在一起,下面我们要实现一个让LLM给生产不同产品的公司取名字的功能:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain#定义大型语言模型
llm = ChatOpenAI(temperature=0.9)prompt = ChatPromptTemplate.from_template("描述生产{product}的公司的一个最佳名称是什么?"
)#将llm和prompt组合在一起创建一个LLMChain的实例
chain = LLMChain(llm=llm, prompt=prompt)#执行chain
product = "床上用品"
chain.run(product)
这里我们定义llm时使用的温度参数temperature为0.9,该参数的取值范围为0-1,之所以这里要设置为0.9,因为temperature的值越大,那么llm返回结果的随机性就越大,这里我们要实现的功能是给公司取名字的功能,因此我们需要LLM具有较大的灵活性和多样性,所以llm每次返回的结果可能都会不一样,这也就是我们希望llm实现的功能。
Sequential Chains
Sequential chain 是另一种类型的chain。它可以将多个chain组合在一起,其中一个chain的输出是下一个chain的输入。

SimpleSequentialChain
SimpleSequentialChain是最基本的一种Sequential Chains,因为它只有一个输入和一个输出,其中前一个chain的输出为后一个chain的输入,如下图所示:
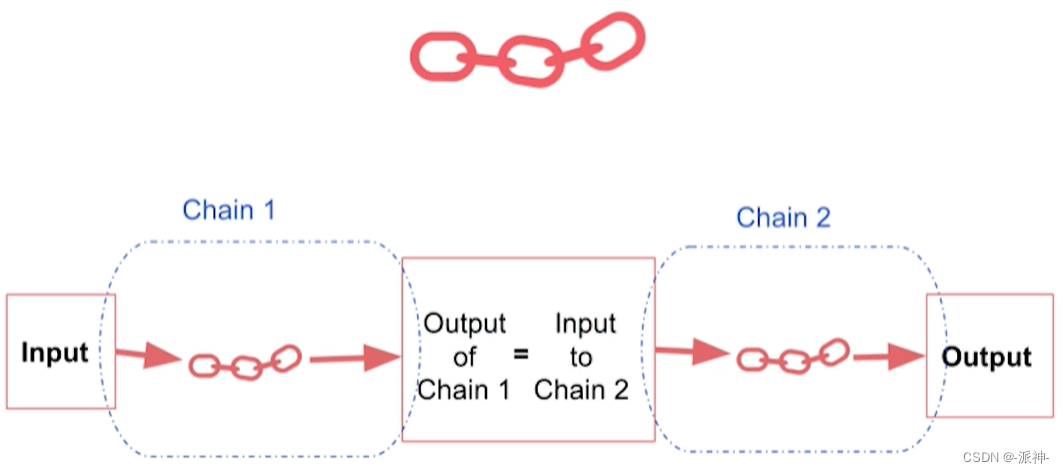
下面我们看个例子,在这个例子中我们除了要执行之前LLMChain的给公司取名的功能外,我们还要需要llm生成20个字左右的公司名称的描述信息,所以,在这里需要创建两个chain, 一个chain负责给公司取名字,另一个chain负责就公司的名字生成20个字左右的描述信息,最后我们需要将这两个chain组合在一起,创建一个新的chain,对于这个新的chain它只有一个输入和一个输出,输入就是公司生产的产品,输出则是对公司名称的20字左右的描述信息。
from langchain.chains import SimpleSequentialChainllm = ChatOpenAI(temperature=0.9)# prompt template 1
first_prompt = ChatPromptTemplate.from_template("描述生产{product}的公司的一个最佳名称是什么?"
)# Chain 1
chain_one = LLMChain(llm=llm, prompt=first_prompt)# prompt template 2
second_prompt = ChatPromptTemplate.from_template("为以下公司编写 20 个字的描述:{company_name}”"
)
# chain 2
chain_two = LLMChain(llm=llm, prompt=second_prompt)# 将chain1和chain2组合在一起生成一个新的chain.
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two],verbose=True)
#执行新的chain
overall_simple_chain.run(product)
SequentialChain
SequentialChain与SimpleSequentialChain的区别在于它可以有多个输入和输出,而SimpleSequentialChain只有一个输入和输出,如下图所示:

在下面的例子中我对官方课件的代码做了修改,原来官方的代码只有4个chain, 而我在此基础上增加了一个chain,这样的修改主要是让大家更好的理解该案例中涉及的prompt的含义,原先的prompt使用的都是英语,我都将其翻译成了中文,这样大家就比较能看懂这些prompt了,该案例主要功能是要让llm对前面导入的用户评语进行分析,并给出回复,因为用户的评语可能使用的是多种不同的语言,为此我们需要让chain能够识别用户评语使用的是那种语言,并将其翻译成中文,最后给出回复,具体来说包含以下功能和步骤:
- 将用户评论翻译成中文
- 用一句话概括用户评论
- 识别出用户评论使用的语言
- 按原始评论语言生成回复
- 将回复翻译成中文
from langchain.chains import SequentialChain#定义llm
llm = ChatOpenAI(temperature=0.9)# prompt template 1: 将评论翻译成中文
first_prompt = ChatPromptTemplate.from_template("将下面的评论翻译成中文:""\n\n{Review}"
)
# chain 1: input= Review and output= Chinese_Review
chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="Chinese_Review")
#概括评论
second_prompt = ChatPromptTemplate.from_template("你能用 1 句话概括以下评论吗:""\n\n{Chinese_Review}"
)
# chain 2: input= Chinese_Review and output= summary
chain_two = LLMChain(llm=llm, prompt=second_prompt, output_key="summary")# prompt template 3: 识别评论使用的语言
third_prompt = ChatPromptTemplate.from_template("下面的评论使用的是什么语言?:\n\n{Review}"
)
# chain 3: input= Review and output= language
chain_three = LLMChain(llm=llm, prompt=third_prompt,output_key="language")# prompt template 4: 生成回复信息
fourth_prompt = ChatPromptTemplate.from_template("使用指定语言编写对以下摘要的后续回复:""\n\n摘要:{summary}\n\n语言:{language}")
# chain 4: input= summary, language and output= followup_message
chain_four = LLMChain(llm=llm, prompt=fourth_prompt,output_key="followup_message")# prompt template 5: 将回复信息翻译成中文
five_prompt = ChatPromptTemplate.from_template("将下面的评论翻译成中文:""\n\n{followup_message}"
)
# chain 5: input= followup_message and output= Chinese_followup_message
chain_five = LLMChain(llm=llm, prompt=five_prompt, output_key="Chinese_followup_message")# overall_chain: input= Review
# output= language,Chinese_Review,summary, followup_message,#Chinese_followup_message
overall_chain = SequentialChain(chains=[chain_one, chain_two, chain_three, chain_four,chain_five],input_variables=["Review"],output_variables=["language","Chinese_Review", "summary","followup_message","Chinese_followup_message"],verbose=True
)这里我们看到我们在定义最后的overall_chain 时设置了输入变量和输出变量,因此这些输入和输出变量最后会作为中间结果被输出。
下面我们看一下用户的评语:
review = df.Review[5]
print(review)
接下来我们执行SequentialChain:
overall_chain(review)
Router Chain
有一种应用场景就是我们有时候希望根据信息的内容将其传送到不同的chain,而每个chain的职能是只擅长回答自己所属领域的问题,那么在这种场景下我们就需要一种具有"路由器"功能的chain来将信息传输到不同职能的chain.
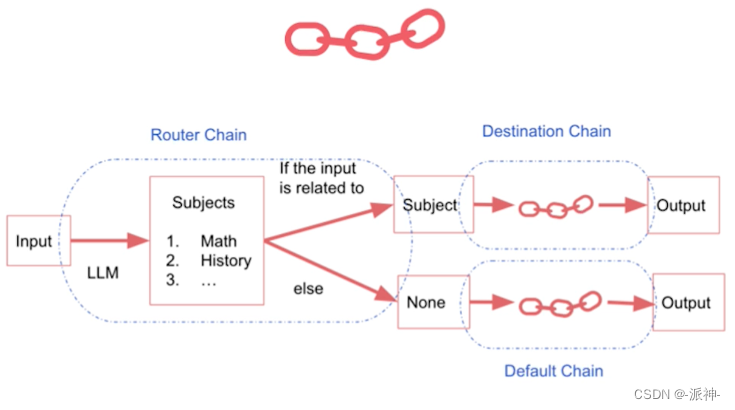
在下面的例子中,我们有多个不同职能的chain,它们负责回复关于不同学科领域的用户问题,比如数学chain,历史chain,物理chain,计算机chain,每个chain都只擅长回复自己专业领域的问题,这里我们还有一个路由chain, 它的作用是识别用户问题属于哪个领域,然后将问题传输给那个领域的chain,让其来完成回答用户问题的功能。下面我们首先定义4个专业领域的prompt模板,在这些模板中我们将告知llm它的职责与定位:
physics_template="""你是一位非常聪明的物理学教授。\
你擅长以简洁易懂的方式回答有关物理的问题。 \
当你不知道某个问题的答案时,你就承认你不知道。这里有一个问题:
{input}"""math_template="""你是一位非常优秀的数学家。\
你很擅长回答数学问题。 \
你之所以如此出色,是因为你能够将难题分解为各个组成部分,\
回答各个组成部分,然后将它们组合起来回答更广泛的问题。这里有一个问题:
{input}"""history_template = """你是一位非常优秀的历史学家。\
你对各个历史时期的人物、事件和背景有深入的了解和理解。 \
你有能力思考、反思、辩论、讨论和评价过去。 \
你尊重历史证据,并有能力利用它来支持你的解释和判断。这里有一个问题:
{input}"""computerscience_template="""你是一位成功的计算机科学家。\
你有创造力,协作精神,前瞻性思维,自信,有很强的解决问题的能力,\
对理论和算法的理解,以及出色的沟通能力。\
你很擅长回答编程问题。
你是如此优秀,因为你知道如何通过描述一个机器可以很容易理解的命令步骤来解决问题,\
你知道如何选择一个解决方案,在时间复杂度和空间复杂度之间取得良好的平衡。这里有一个问题:
{input}"""接下来我们还还需要对这些模板功能进行结构化的解释说明这样便于后面的路由chain能找到它们,为此我们要定义一个模板的索引结构:
prompt_infos = [{"name": "physics", "description": "擅长回答有关物理方面的问题", "prompt_template": physics_template},{"name": "math", "description": "擅长回答有关数学方面的问题", "prompt_template": math_template},{"name": "history", "description": "擅长回答有关历史方面的问题", "prompt_template": history_template},{"name": "computer science", "description": "擅长回答有关计算机科学方面的问题", "prompt_template": computerscience_template}
]接下来我们还需要定义一个目标chain的集合,所谓的目标chain就是指回答单一领域问题的chai成,它们都是基本的LLMChain:
from langchain.chains import LLMChain
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI#定义llm
llm = ChatOpenAI(temperature=0)#创建目标chain
destination_chains = {}
for p_info in prompt_infos:name = p_info["name"]prompt_template = p_info["prompt_template"]prompt = ChatPromptTemplate.from_template(template=prompt_template)chain = LLMChain(llm=llm, prompt=prompt)destination_chains[name] = chain destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
print(destinations_str)
这里我们还生成了一个目标字符串destinations_str,它会在后面别嵌入到路由chain的prompt模板中来为定位目标chain提供索引。
接下来我们还需要定义default_chain,这个chain的作用是当用户的问题与现有的所有目标chain都无法匹配时,那么就由default_chain来回答用户的问题:
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)这里我们看到default_prompt 中只包含了一个变量{input},没有包含任何的前缀信息,这是因为default_chain回答的是哪些无法被识别的属于领域的问题,所以这里就让LLM自由发挥了。
下面我们要创建一个路由prompt模板,这是给后续的路由chain使用的:
MULTI_PROMPT_ROUTER_TEMPLATE = """给定一个原始文本输入到\
一个语言模型并且选择最适合输入的模型提示语。\
你将获得可用的提示语的名称以及该提示语最合适的描述。\
如果你认为修改原始输入最终会导致语言模型得到更好的响应,你也可以修改原始输入。<< FORMATTING >>
返回一个 Markdown 代码片段,其中 JSON 对象的格式如下:
```json
{{{{
"destination": string \ 要使用的提示语的名称或"DEFAULT"
"next_inputs": string \ 原始输入的可能修改版本
}}}}
```记住:"destination"必须是下面指定的候选提示语中的一种,\
如果输入语句不适合任何候选提示语,则它就是"DEFAULT"。记住:"next_inputs"可以只是原始输入,如果你认为不需要做任何修改的话。<< CANDIDATE PROMPTS >>
{destinations}<< INPUT >>
{{input}}<< OUTPUT (remember to include the ```json)>>"""这上面的模板里,我们允许LLM修改用户的原始输入,如果修改后的输入能产生更好的输出效果的话,也就是说LLM会先判断是否需要修改用户的prompt,如果觉得有必要修改用户的prompt,那么就会把修改过的prompt传送给后续处理特定领域问题的chain,如果没必要修改,那么就直接把用户的prompt传送给后续的chain。下面还需要在路由prompt模板中嵌入destinations_str,它是为识别领域chain提供索引:
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str
)print(router_template)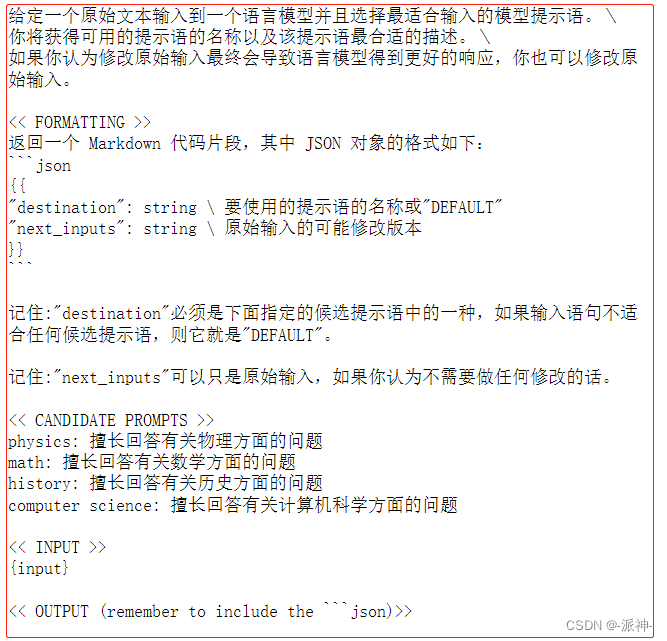
接下来我们要定义最核心的MultiPromptChain,它的三个主要参数为路由chain, 领域chain(集合),默认chain。由这3个主要的参数,我们也能猜测出MultiPromptChain的主要处理逻辑:首先让路由chain来识别用户prompt,并将其传送给特定领域chain,如果没找到合适的领域chain,则由默认chain来处理用户prompt,这里我们给MultiPromptChain的verbose设置为True,这样MultiPromptChain在处理用户prompt的时候会输出一些中间结果,这些中间结果有助于我们观察llm的思维过程是否和我们给它的设定的业务逻辑是一致的。如果不想显示中间结果可以把verbose参数设置为False:
router_chain = LLMRouterChain.from_llm(llm, router_prompt)chain = MultiPromptChain(router_chain=router_chain, destination_chains=destination_chains, default_chain=default_chain, verbose=True)下面我们来设计一些简单的问题,这些问题可能涉及到不同的领域,我们看看llm是怎么来回答用户问题的:
response = chain.run("2+2等于几?")
print(response)
这里我们可以看到LLM能按照我们的router_template模板内的要求识别出该问题属于"math"领域,然后由该领域的chain来回答这个问题,并最后返回了正确的答案。
response = chain.run("成吉思汗是谁?")
print(response) 
对于“成吉思汗是谁?”这个问题,我们发现LLM对问题进行了修改,它把用户的问题改成了:“成吉思汗是哪个历史时期的重要人物?”,可能是LLM觉得修改后的prompt更有助于后续的领域chain来回答这个问题吧。
response = chain.run("什么是黑体辐射?")
print(response)
response = chain.run("为什么学习机器学习都要使用python语言?")
print(response)
response = chain.run("天上一共有多少颗星星?")
print(response)
对于“天上一共有多少颗星星?”这个问题,我们看到LLM并没有识别出来它属于哪个领域,因此它返回的领域值为None, 然后该问题交由默认chain来回答。
总结
今天我们学习了Langchain的核心组件chain。主要分为LLMChain,Sequential Chains,Router Chain,其中LLMChain是最基本的chain它简单的组合了LLM和promt, Sequential Chains主要包含SimpleSequentialChain和SequentialChain,对于SimpleSequentialChain来说它只是简单的将多个LLMChain串联在一起,前一个chain的输出是后一个chain的输入,所以总体上来说SimpleSequentialChain只有一个输入和一个输出,而SequentialChain则具体多个输入或输出。而Router Chain则是具有路由功能的chain ,它可以将用户的问题进行分类,从而将问题传递给特定的chain。
参考资料
https://learn.deeplearning.ai/langchain/lesson/4/chains
相关文章:
LangChain大型语言模型(LLM)应用开发(三):Chains
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…...
FPGA——点亮led灯
文章目录 一、实验环境二、实验任务三、实验过程3.1 编写verliog程序3.2 引脚配置 四、仿真4.1 仿真代码4.2仿真结果 五、实验结果六、总结 一、实验环境 quartus18.1 vscode Cyclone IV开发板 二、实验任务 每间隔1S实现led灯的亮灭,实现流水灯的效果。 三、实…...

idea创建spark教程
1、环境准备 java -version scala -version mvn -version spark -version 2、创建spark项目 创建spark项目,有两种方式;一种是本地搭建hadoop和spark环境,另一种是下载maven依赖;最后在idea中进行配置,下面分别记录两…...

【JavaEE】DI与DL的介绍-Spring项目的创建-Bean对象的存储与获取
Spring的开发要点总结 文章目录 【JavaEE】Spring的开发要点总结(1)1. DI 和 DL1.1 DI 依赖注入1.2 DL 依赖查询1.3 DI 与 DL的区别1.4 IoC 与 DI/DL 的区别 2. Spring项目的创建2.1 创建Maven项目2.2 设置国内源2.2.1 勾选2.2.2 删除本地jar包2.2.3 re…...

C#图片处理
查找图片所在位置 原理:使用OpenCvSharp对比查找小图片在大图片上的位置 private static System.Drawing.Point Find(Mat BackGround, Mat Identify, double threshold 0.8) {using (Mat res new Mat(BackGround.Rows - Identify.Rows 1, BackGround.Cols - Iden…...

php 开发微信 h5 支付 APIv3 接入超详细流程
✨ 目录 🎈 申请商户号🎈 申请商户证书🎈 设置V3密钥🎈 开通H5支付🎈 设置支付域名🎈 SDK 下载🎈 第一次下载平台证书🎈非第一次下载平台证书🎈 H5下单 🎈 申…...
HTML学习 第一部分(前端学习)
参考学习网站: 网页简介 (w3schools.com) 我的学习思路是:网站实践视频。 视频很重要的,因为它会给你一种开阔思路的方式。你会想,噢!原来还可以这样。这是书本或者网站教程 所不能教给你的。而且,对一些教程&#…...

python 实现串口指令通讯
上一篇文章文章写了串口数据的读取,这篇文章讲串口数据的写入(指令控制) 与下位机通信往往需要十六进制形式进行数据通信,根据设备串口通信指令文档进行指令通信,本篇以灯光控制为例: 1.pyserial模块封装…...
pytorch深度学习逻辑回归 logistic regression
# logistic regression 二分类 # 导入pytorch 和 torchvision import numpy as np import torch import torchvision from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import matplotlib.pyplot as …...
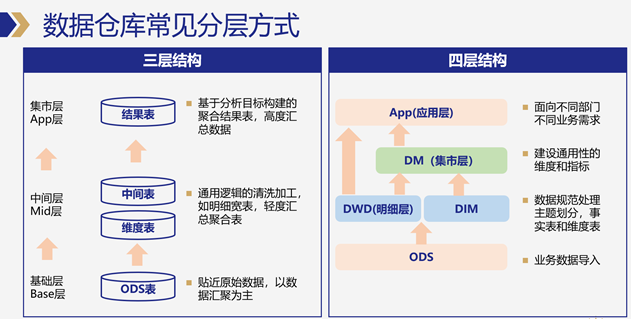
数据仓库建设-数仓分层
数据仓库能够帮助企业做出更好的决策,提高业务效率和效益;在数据仓库建设时,绕不开的话题就是数仓分层。 一、数据分层的好处 1. 降低数据开发成本 通用的业务逻辑加工好,后续的开发任务可以基于模型快速使用,数据需…...
共享与协作:时下最热门的企业共享网盘推荐!
现代企业面临着越来越大的数据存储和共享压力。为了提高公司的生产力和效率,许多企业开始寻找共享网盘解决方案。这些共享网盘平台可以帮助企业集中管理文件和数据,并方便快速地与同事、客户或供应商共享。以下是几款好用的企业共享网盘。 Zoho Workdriv…...

mysql取24小时数据
MySQL是一种常用的关系型数据库管理系统。在进行实时数据处理时,我们常常需要查询最近24小时的数据来进行分析和处理。下面我们将介绍如何使用MySQL查询最近24小时的数据。 SELECT * FROM table_name WHERE timestamp_column > DATE_SUB(NOW(), INTERVAL 24 HOU…...
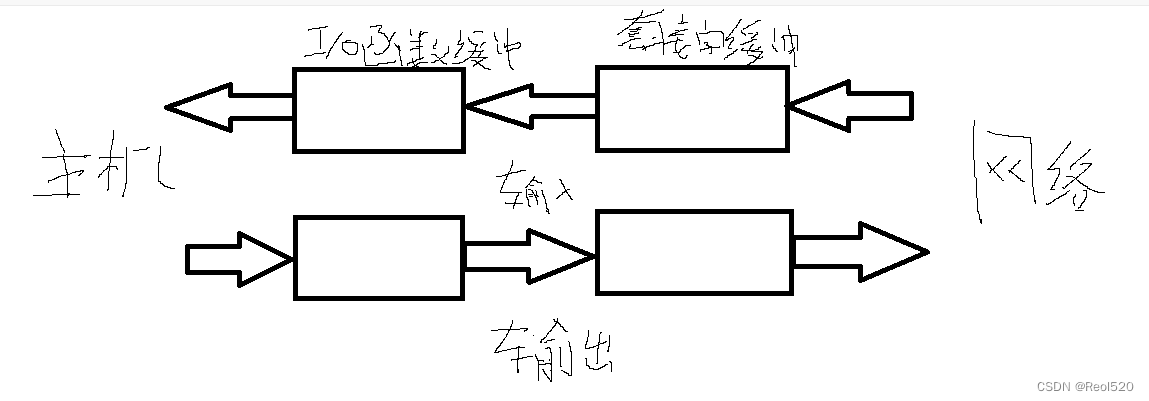
TCP/IP网络编程 第十五章:套接字和标准I/O
标准I/O函数的优点 标准I/O函数的两个优点 将标准I/O函数用于数据通信并非难事。但仅掌握函数使用方法并没有太大意义,至少应该 了解这些函数具有的优点。下面列出的是标准I/O函数的两大优点: □标准I/O函数具有良好的移植性(Portability) □标准I/O函数可以利用缓…...
SaleSmartly,客户满意度调查的绝对好助手
企业使用客户满意度调查来收集反馈并评估客户满意度水平,包括有关产品质量、服务、支持和整体满意度的问题。客户满意度调查的主要目标是直接从客户那里收集有价值的见解,以了解他们的需求、偏好和期望。这种反馈可以帮助企业确定需要改进的领域…...
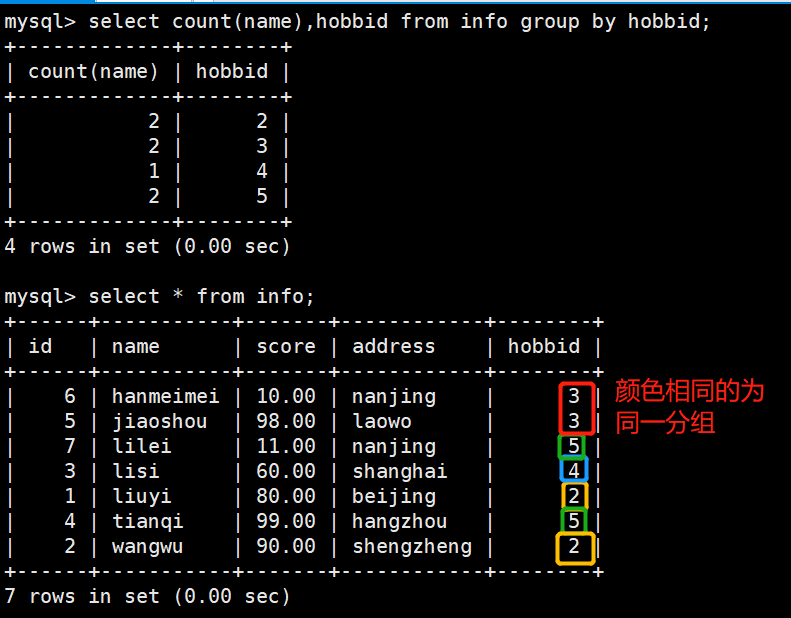
MySQL高阶语句
文章目录 一.常用查询1.按关键字排序(ORDER BY 语句)1.1 语法格式1.2 ASC和DESC的排序概念1.3 举例1.3.1 数据库有一张info表,记录了学生的id,姓名,分数,地址和爱好1.3.2 按分数排序,默认不指定…...
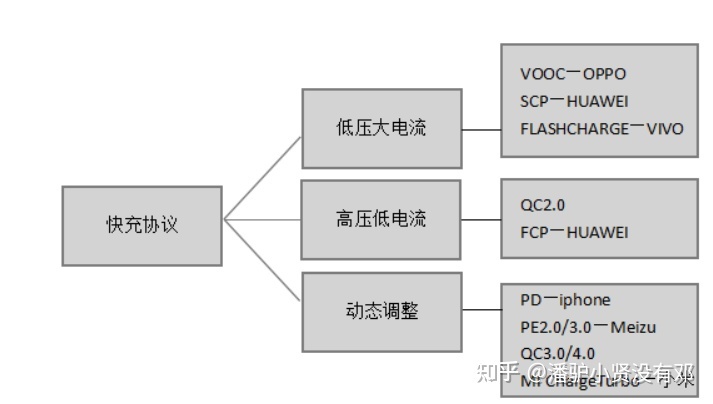
手机快充协议
高通:QC2.0、QC3.0、QC3.5、QC4.0、QC5.0、 FCP、SCP、AFC、SFCP、 MTKPE1.1/PE2.0/PE3.0、TYPEC、PD2.0、PD3.0/3.1、VOOC 支持 PD3.0/PD2.0 支持 QC3.0/QC2.0 支持 AFC 支持 FCP 支持 PE2.0/PE1.1 联发科的PE(Pump Express)/PE 支持 SFCP 在PP…...

centos 7升级gcc到10.5.0
目录 1、安装gcc 1.1、查看是否含有gcc及gcc版本 1.2、快速安装gcc 2、升级gcc 2.1、下载gcc源码包并解压缩 2.2、下载编译依赖项 2.3、新建gcc-bulid目录(与gcc-10.5.0同级)并进入该目录中 2.4、生成Makefile文件 2.5、开始编译 2.6、安装 2…...

从脚手架搭建到部署访问路程梳理
1、vue-cli 起文件: 2、配置 webpack :打包配置等,env文件( 处理线上和测试的ip), https://www.ibashu.cn/news/show_377892.html 3、样式:封装 style :组件(element-u…...

数据库应用:MySQL数据库SQL高级语句与操作
目录 一、理论 1.克隆表与清空表 2.SQL高级语句 3.SQL函数 4.SQL高级操作 5.MySQL中6种常见的约束 二、实验 1.克隆表与清空表 2.SQL高级语句 3.SQL函数 4.SQL高级操作 5.主键表和外键表 三、总结 一、理论 1.克隆表与清空表 克隆表:将数据表的数据记录…...

xshell连接WSL2
1. 卸载 ssh server sudo apt-get remove openssh-server2. 安装 ssh server sudo apt-get install openssh-server3. 修改 ssh server 配置 sudo vim /etc/ssh/sshd_config需要修改以下几项: Port 2222 #默认的是22,但是windows有自己的ssh服务&am…...

遇到“用户对AIAgent进行提示词注入”怎么办?
文章目录先理解什么是“提示词注入”图片里的防护方法(两层)第一层:System Prompt 先贴“封条”第二层:输出端再加“安检门”总结先理解什么是“提示词注入” 你可以把 Agent(智能助手) 想象成一个 严格遵…...

WeChatExporter深度解析:如何三步搞定iOS微信聊天记录完整导出
WeChatExporter深度解析:如何三步搞定iOS微信聊天记录完整导出 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 还在为无法备份微信聊天记录而烦恼吗ÿ…...

从教程到实战:在快马平台部署企业级openclaw数据采集与监控系统
今天想和大家分享一个实战经验:如何把openclaw这个数据采集工具从教程变成真正的企业级应用。最近我在InsCode(快马)平台上完整走通了从开发到部署的全流程,整个过程比想象中顺畅很多。 任务调度器的实现 首先需要解决的是任务调度问题。传统教程里可能…...

【JavaWeb开发】从零构建前后端交互实战指南
1. JavaWeb前后端交互基础入门 第一次接触JavaWeb开发时,最让我困惑的就是前后端如何传递数据。记得刚开始做项目时,我傻乎乎地用字符串拼接HTML代码返回给前端,结果遇到中文乱码问题折腾了一整天。后来才发现,现代JavaWeb开发早已…...

3步释放华硕笔记本潜能:G-Helper轻量化控制工具的极致优化指南
3步释放华硕笔记本潜能:G-Helper轻量化控制工具的极致优化指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models …...

基于背景减除的PIV颗粒图像时均灰度分布分析方法
基于背景减除的PIV颗粒图像时均灰度分布分析方法 摘要 粒子图像测速(PIV)技术广泛应用于流体力学实验研究,其原始图像中包含大量示踪颗粒的灰度信息。除了用于速度场计算外,颗粒灰度分布还可用于分析颗粒浓度、粒径分布及混合特性。本文提出了一套完整的图像处理流程,包…...

从按键消抖到I2C通信:深入浅出聊聊MCU上拉/下拉电阻与开漏输出的那些坑
从按键消抖到I2C通信:深入浅出聊聊MCU上拉/下拉电阻与开漏输出的那些坑 在嵌入式系统开发中,GPIO配置看似简单,却暗藏玄机。记得第一次调试I2C总线时,通信速率始终上不去,最后发现竟是上拉电阻选型不当;另一…...

PFC3D模拟含纤维混凝土材料单轴压缩破坏
PFC3D含纤维混凝土材料单轴压缩破坏模拟去年在实验室折腾PFC3D模拟含纤维混凝土压缩破坏的时候,发现这玩意儿真是让人又爱又恨。纤维像调皮的孩子,在混凝土基体里各种"搞事情",今天就跟大家唠唠这个"微观破坏现场"的观察…...

蓝桥杯嵌入式备赛:STM32G431引脚复用功能表,一张图搞定定时器与ADC配置
蓝桥杯嵌入式备赛:STM32G431引脚复用功能实战指南 在蓝桥杯嵌入式赛场上,STM32G431作为官方指定开发平台的核心控制器,其引脚复用功能的灵活配置往往是决定项目成败的关键。许多参赛选手在紧张激烈的比赛中,常常因为引脚配置错误…...
)
STM32F103C8T6 DHT11温湿度监测系统 HAL库 CubeMX实战(避坑指南)
1. 项目背景与硬件选型 温湿度监测是物联网领域最基础也最实用的功能之一。我最近用STM32F103C8T6和DHT11搭建了一个环境监测节点,整个过程踩了不少坑,也积累了一些实战经验。这个方案特别适合需要低成本、快速上手的场景,比如智能家居、农业…...