数据仓库建设-数仓分层
数据仓库能够帮助企业做出更好的决策,提高业务效率和效益;在数据仓库建设时,绕不开的话题就是数仓分层。
一、数据分层的好处
1. 降低数据开发成本
通用的业务逻辑加工好,后续的开发任务可以基于模型快速使用,数据需求的响应速度也会更快。
2. 降低任务运维成本
业务发展过程中,数据指标口径、统计逻辑变化是常态,任务失败也屡见不鲜。如果每一次调整都需要对所有的数据任务进行修改,再去回溯数据,那维护起来就比较困难,而且数据还会经常出错。
数仓分层就是希望通过对最基础的、常用的数据进行抽象,找出数据的主干,对主干进行修复后,下游的叶子节点就可以最小变动。例如,当产品改版后,涉及流量统计指标口径需要调整,通过数据分层,只修改最底层的源表的逻辑就可以实现整个链路的数据更新。
3. 方便共享复用,减少重复建设
不同的开发人员、不同时期开发的模型,如果没有分层管理规范,往往导致后期使用时找不到。需要花费很长时间沟通、翻代码确认,最终耗时反而没有重新写一套逻辑来的快。长此以往,数据复用度低,带来存储和计算资源的浪费。
通过数据分层,将数据有序的管理起来,就像图书馆的书架导航,可以快速帮助使用者找到所需要的书籍在那一层书架中。

4. 统一数据口径
同一个指标在数据加工处理时,复用的是同一个数据模型表,这样很大程度可以规避数据统计不统一的问题。
二、数据仓库的分层
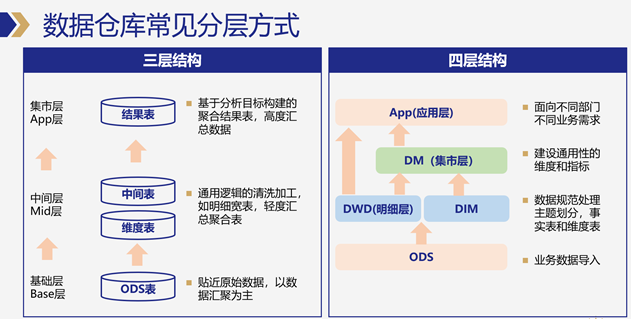
**ODS层:**源数据层,一般是从各种业务系统、日志数据库将数据汇集到数据仓库中,作为原始数据存储和备份。通过数据同步的方式,将业务从库数据同步到HDFS、Hive等,适合海量数据存储和加工处理的系统中。
**DWD层:**数据明细层,对ODS层数据进行规范化处理,例如脏数据过滤、数据格式化等,但仍以数据明细方式存储,且将数据进行主题、层级划分。
**DIM层:**维度表,在维度建模理论中,可以通过业务主题宽表关联维度表方式,快速输出直观的数据分析结果。
**DM层:**数据集市层,基于对业务的需求的理解和抽象,建立通用的指标和分析维度模型,数据仍以明细为主,部分可以直接累加和汇总的数据指标,可以采用聚合结果的方式呈现。
**APP层:**数据应用层,面向不同业务部门、不同产品需求提供具体业务场景的结果表,通过数据同步方式再从数仓同步到MySQL等查询引擎,供前端数据产品输出使用。定制化程度高。
三、阿里数仓分层
阿里巴巴数仓分层采用了比传统三层架构更为细致的分层结构,具体包括以下六层:
- 采集层:该层主要负责数据的采集和传输,从各种数据源(如业务系统、应用日志、社交网络等)中收集数据,并将数据传输到数据仓库中进行存储和处理。在采集层中,数据需要进行格式化、清洗、验证等处理,确保数据的准确性和完整性。
- 存储层:该层主要负责数据的存储和管理,包括数据的分区、压缩、索引等操作。
- 计算层:该层主要负责数据的计算和分析,包括数据的加工、转换、聚合等操作。
- 模型层:该层主要负责数据模型的设计和管理,包括物理模型、逻辑模型、维度模型、事实模型等。
- 应用层:该层主要负责数据的展示和可视化,包括BI工具、数据可视化工具、报表系统等
- 安全层:该层主要负责数据的安全和保护,包括数据的访问控制、数据加密、数据备份等。
阿里巴巴数仓分层相比传统的三层架构更为细致,每一层的功能更为明确和专业化,从而能够更好地支持企业的数据分析和决策支持工作。这种分层结构的优点在于,可以将数据处理和管理的工作划分为不同的层级,实现各层之间的解耦和协作,从而提高数据处理和管理的效率和准确性。
四、小结
数据仓库是企业决策过程中必不可少的组成部分,通过数据仓库可以有效地提高企业决策的效率和效益。数据仓库的分层架构可以帮助企业更好地管理和维护数据仓库,提高数据仓库的可扩展性、可维护性和可管理性。数据仓库的建设过程需要经过多个步骤,包括需求分析、数据清洗和预处理、数据仓库模型设计、数据集成和管理、元数据管理、数据挖掘和分析、部署和维护。
相关文章:
数据仓库建设-数仓分层
数据仓库能够帮助企业做出更好的决策,提高业务效率和效益;在数据仓库建设时,绕不开的话题就是数仓分层。 一、数据分层的好处 1. 降低数据开发成本 通用的业务逻辑加工好,后续的开发任务可以基于模型快速使用,数据需…...
共享与协作:时下最热门的企业共享网盘推荐!
现代企业面临着越来越大的数据存储和共享压力。为了提高公司的生产力和效率,许多企业开始寻找共享网盘解决方案。这些共享网盘平台可以帮助企业集中管理文件和数据,并方便快速地与同事、客户或供应商共享。以下是几款好用的企业共享网盘。 Zoho Workdriv…...

mysql取24小时数据
MySQL是一种常用的关系型数据库管理系统。在进行实时数据处理时,我们常常需要查询最近24小时的数据来进行分析和处理。下面我们将介绍如何使用MySQL查询最近24小时的数据。 SELECT * FROM table_name WHERE timestamp_column > DATE_SUB(NOW(), INTERVAL 24 HOU…...
TCP/IP网络编程 第十五章:套接字和标准I/O
标准I/O函数的优点 标准I/O函数的两个优点 将标准I/O函数用于数据通信并非难事。但仅掌握函数使用方法并没有太大意义,至少应该 了解这些函数具有的优点。下面列出的是标准I/O函数的两大优点: □标准I/O函数具有良好的移植性(Portability) □标准I/O函数可以利用缓…...
SaleSmartly,客户满意度调查的绝对好助手
企业使用客户满意度调查来收集反馈并评估客户满意度水平,包括有关产品质量、服务、支持和整体满意度的问题。客户满意度调查的主要目标是直接从客户那里收集有价值的见解,以了解他们的需求、偏好和期望。这种反馈可以帮助企业确定需要改进的领域…...
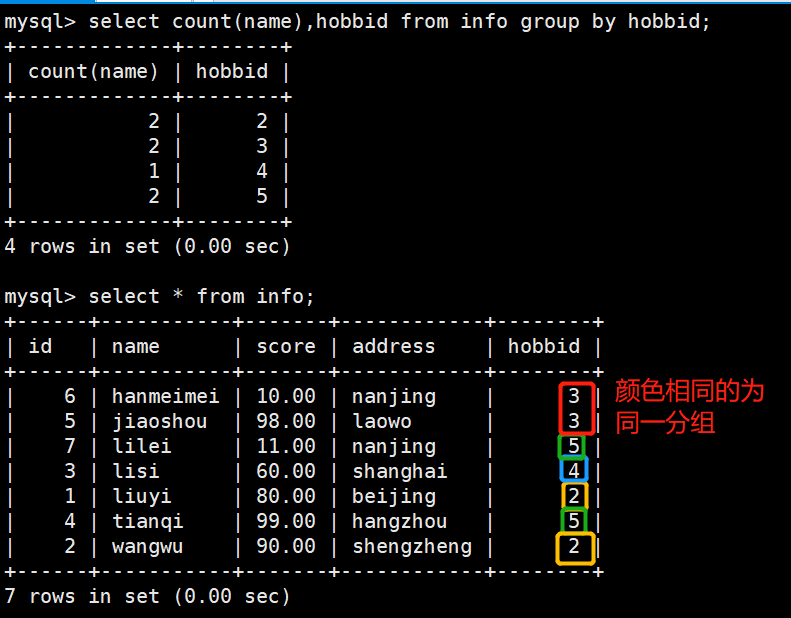
MySQL高阶语句
文章目录 一.常用查询1.按关键字排序(ORDER BY 语句)1.1 语法格式1.2 ASC和DESC的排序概念1.3 举例1.3.1 数据库有一张info表,记录了学生的id,姓名,分数,地址和爱好1.3.2 按分数排序,默认不指定…...
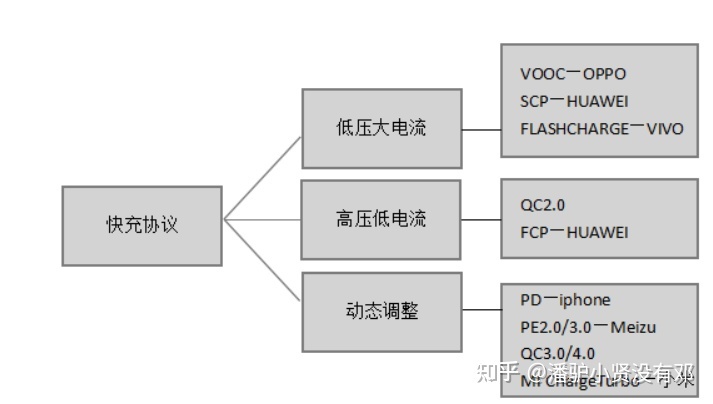
手机快充协议
高通:QC2.0、QC3.0、QC3.5、QC4.0、QC5.0、 FCP、SCP、AFC、SFCP、 MTKPE1.1/PE2.0/PE3.0、TYPEC、PD2.0、PD3.0/3.1、VOOC 支持 PD3.0/PD2.0 支持 QC3.0/QC2.0 支持 AFC 支持 FCP 支持 PE2.0/PE1.1 联发科的PE(Pump Express)/PE 支持 SFCP 在PP…...

centos 7升级gcc到10.5.0
目录 1、安装gcc 1.1、查看是否含有gcc及gcc版本 1.2、快速安装gcc 2、升级gcc 2.1、下载gcc源码包并解压缩 2.2、下载编译依赖项 2.3、新建gcc-bulid目录(与gcc-10.5.0同级)并进入该目录中 2.4、生成Makefile文件 2.5、开始编译 2.6、安装 2…...

从脚手架搭建到部署访问路程梳理
1、vue-cli 起文件: 2、配置 webpack :打包配置等,env文件( 处理线上和测试的ip), https://www.ibashu.cn/news/show_377892.html 3、样式:封装 style :组件(element-u…...

数据库应用:MySQL数据库SQL高级语句与操作
目录 一、理论 1.克隆表与清空表 2.SQL高级语句 3.SQL函数 4.SQL高级操作 5.MySQL中6种常见的约束 二、实验 1.克隆表与清空表 2.SQL高级语句 3.SQL函数 4.SQL高级操作 5.主键表和外键表 三、总结 一、理论 1.克隆表与清空表 克隆表:将数据表的数据记录…...

xshell连接WSL2
1. 卸载 ssh server sudo apt-get remove openssh-server2. 安装 ssh server sudo apt-get install openssh-server3. 修改 ssh server 配置 sudo vim /etc/ssh/sshd_config需要修改以下几项: Port 2222 #默认的是22,但是windows有自己的ssh服务&am…...

Flask新手教程
Flask简介 Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。 Flask 可以很好地结合MVC模式进行开发,开发人员分工合作,小型团队在短时间内就可以完成功能丰富的中小型网站或…...

拼多多API接口,百亿补贴商品详情页面采集
电商API的数据类型 电商API提供的数据种类多样,一般可分为以下几类: 1.商品数据:商品ID、商品名称、商品价格、库存等。 2.交易数据:订单号、付款时间、收货人等。 3.店铺数据:店铺ID、店铺名称、开店时间、店铺评…...
)
C++入门(未完待续)
1.命名空间 使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染 定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员 ①.普通的命名空间 n…...
————XPath解析)
Python爬虫学习笔记(四)————XPath解析
目录 0.xpath最新下载地址和安装教程 1.xpath安装 2.xpath基本使用 3.xpath基本语法 4.实例 (1)xpath解析本地文件 (2)xpath解析服务器响应的数据 ①获取百度网站的“百度一下”四个字 ②获取站长素材网站情侣图片前十页的…...

知识图谱推理的学习逻辑规则(上)
知识图谱推理的学习逻辑规则 摘要介绍相关工作模型知识图谱推理逻辑规则概率形式化参数化优化 实验实验设置实验结果 结论 原文: 摘要 本文研究了在知识图谱上进行推理的学习逻辑规则。 逻辑规则用于预测时提供了可解释性并且可以推广到其他任务中,因…...

【从零开始学习C++ | 第二十一篇】C++新增特性 (上)
目录 前言: 委托构造函数: 类内初始化: 空指针: 枚举类: 总结: 前言: C的学习难度大,内容繁多。因此我们要及时掌握C的各种特性,因此我们更新本篇文章,向…...
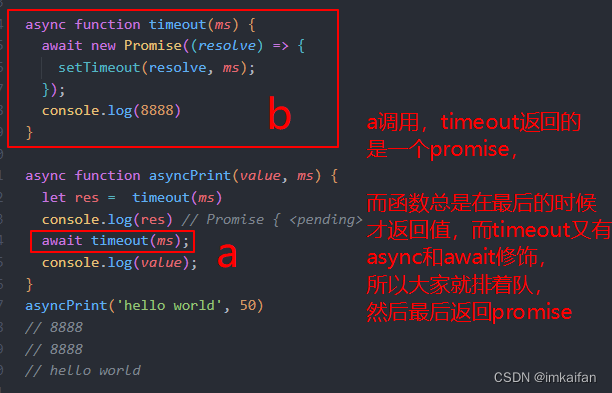
你真的会用async和await么?
背景 背景就是遇到了一个比较烦人的模块,里面的涉及到了大量的async 和 awiat。发现大多人对这个语法糖一知半解,然后大量的滥用,整理一下 async 前置知识: Promise.resolve(foo) new Promise(resolve > resolve(foo)…...
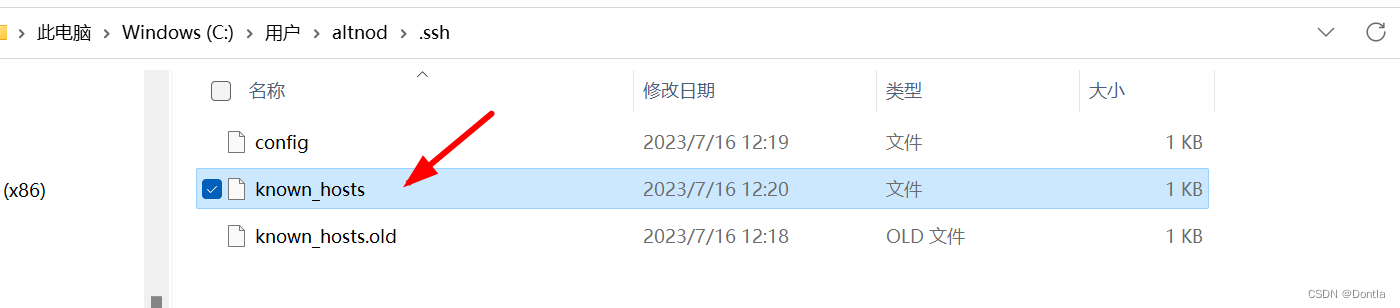
vscode远程连接提示:过程试图写入的管道不存在(删除C:\Users\<用户名>\.ssh\known_hosts然后重新连接)
文章目录 复现过程原因解决方法总结 复现过程 我是在windows上用vscode远程连接到我的ubuntu虚拟机上,后来我的虚拟机出了点问题,我把它回退了,然后再连接就出现了这个问题 原因 本地的known_hosts文件记录服务器信息与现服务器的信息冲突了…...
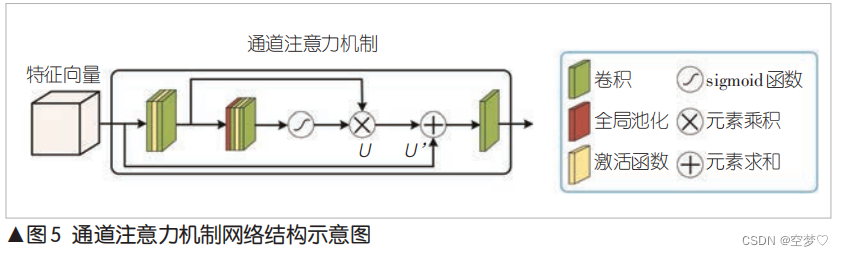
【005】基于深度学习的图像语 通信系统
摘要 语义通信是一种新颖的通信方式,可通过传输数据的语义信息提高带宽效率。提出一种用于无线图像传输的系统。该系统基于深度学习技术开发并以端到端(E2E)的方式进行训练。利用深度学习实现语义特征的提取和重建,在发送端提取信…...

计算机组成原理实验避坑指南:存储器地址映射常见错误及解决方法
计算机组成原理实验避坑指南:存储器地址映射常见错误及解决方法 第一次在Proteus里搭建存储器系统时,看着密密麻麻的地址线和片选信号,我对着实验指导书发呆了半小时——明明按照图示连接了所有线路,可写入RAM的数据总是莫名其妙出…...

OpenClaw环境隔离方案:ollama-QwQ-32B镜像与本地Python虚拟环境整合
OpenClaw环境隔离方案:ollama-QwQ-32B镜像与本地Python虚拟环境整合 1. 为什么需要环境隔离 上周我在尝试将OpenClaw接入本地部署的ollama-QwQ-32B模型时,遇到了一个棘手的问题:我的开发环境突然崩溃了。事后排查发现,是OpenCla…...

3000 字深度拆解:Paperxie AI 期刊写作界面全解析 —— 科研人必看的 “投刊效率密码”
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/期刊论文https://www.paperxie.cn/ai/journalArticleshttps://www.paperxie.cn/ai/journalArticles 一、引言:科研人的投稿困局,藏在每一个被忽略的界面细节里 当科研人熬过无数个深…...

LabVIEW新手避坑指南:用For循环和数组搞定水仙花数,别再手动算啦!
LabVIEW实战:用For循环与数组高效求解水仙花数的5个关键技巧 水仙花数这个经典的编程练习题,在文本编程语言中可能只需十几行代码,但切换到LabVIEW的图形化编程环境时,不少初学者会陷入连线混乱和逻辑纠结。本文将从实际工程视角…...

PyFluent:重新定义CFD仿真自动化的技术革命
PyFluent:重新定义CFD仿真自动化的技术革命 【免费下载链接】pyfluent 项目地址: https://gitcode.com/gh_mirrors/pyf/pyfluent 行业痛点分析:CFD工程师的效率困境 在现代工程设计流程中,计算流体动力学(CFD)…...

安全第一:OpenClaw+GLM-4.7-Flash的本地化数据处理方案
安全第一:OpenClawGLM-4.7-Flash的本地化数据处理方案 1. 为什么我们需要本地化AI解决方案 上个月我帮一位律师朋友处理合同审查任务时,遇到了一个棘手问题——他需要分析上百份涉及商业机密的文件,但担心使用云端AI服务会导致数据泄露。这…...

brpc并发编程模型性能对比:基准测试结果
brpc并发编程模型性能对比:基准测试结果 【免费下载链接】brpc brpc is an Industrial-grade RPC framework using C Language, which is often used in high performance system such as Search, Storage, Machine learning, Advertisement, Recommendation etc. &…...

MBPFan技术解析:MacBook在Linux环境下的智能散热控制机制
MBPFan技术解析:MacBook在Linux环境下的智能散热控制机制 【免费下载链接】mbpfan 项目地址: https://gitcode.com/gh_mirrors/mb/mbpfan 在Linux系统上使用MacBook的用户经常面临散热管理的技术挑战,系统原生的温度控制策略往往无法充分发挥苹果…...

如何快速下载Google Drive受保护PDF:终极免费解决方案指南
如何快速下载Google Drive受保护PDF:终极免费解决方案指南 【免费下载链接】Google-Drive-PDF-Downloader 项目地址: https://gitcode.com/gh_mirrors/go/Google-Drive-PDF-Downloader 你是否经常遇到Google Drive中那些"仅查看"权限的PDF文件&am…...

为什么流水线ADC能用Dither,而SAR ADC效果差?深入解析两种架构下的Dither技术差异与改进方案
流水线ADC与SAR ADC中Dither技术的差异化设计与工程实践 在高速高精度数据采集系统中,量化噪声的非线性特性始终是困扰设计者的核心难题。当我们用频谱分析仪观察一个理想正弦波经过ADC转换后的输出时,那些突兀的谐波分量往往源自量化过程的非线性失真。…...