Python爬虫学习笔记(四)————XPath解析
目录
0.xpath最新下载地址和安装教程
1.xpath安装
2.xpath基本使用
3.xpath基本语法
4.实例
(1)xpath解析本地文件
(2)xpath解析服务器响应的数据
①获取百度网站的“百度一下”四个字
②获取站长素材网站情侣图片前十页的图片
0.xpath最新下载地址和安装教程
https://blog.csdn.net/laosao_66/article/details/131752611
1.xpath安装
注意:提前安装xpath插件
(1)打开chrome浏览器
(2)点击右上角小圆点
(3)更多工具
(4)扩展程序
(5)拖拽xpath插件到扩展程序中
(6)如果crx文件失效,需要将后缀修改zip
(7)再次拖拽
(8)关闭浏览器重新打开
(9)ctrl + shift + x
(10)出现小黑框
2.xpath基本使用
xpath解析分为两种
一种是解析本地文件 方法为:etree.parse
另一种是解析服务器响应的数据 (即从response.read().decode('utf-8') 里解析,这种用的多 方法为:etree.HTML()
- (1)安装lxml库 pip install lxml ‐i https://pypi.douban.com/simple
- (2)导入lxml.etree from lxml import etree
- (3)etree.parse() 解析本地文件 html_tree = etree.parse('XX.html')
- (4)etree.HTML() 服务器响应文件 html_tree = etree.HTML(response.read().decode('utf‐8')
- (5)html_tree.xpath(xpath路径)
3.xpath基本语法
- 路径查询 //:查找所有子孙节点,不考虑层级关系
- / :找直接子节点
- 谓词查询 //div[@id] //div[@id="maincontent"]
- 属性查询 //@class
- 模糊查询 //div[contains(@id, "he")] //div[starts‐with(@id, "he")]
- 内容查询 //div/h1/text()
- 逻辑运算 //div[@id="head" and @class="s_down"] //title | //price
4.实例
(1)xpath解析本地文件
本地 HTML文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="11" class="c1">北京</li><li id="12">上海</li><li id="c3">深圳</li><li id="c4">武汉</li></ul>< ! -- <ul>-->
< ! -- <li>大连</li>-->
< ! -- <li>锦州</li>-->
< ! -- <li>沈阳</li>-->
< ! -- </ul>--></body>
</html>
xpath解析本地文件
from lxml import etree# xpath解析
# (1)本地文件 etree.parse
# (2)服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()# xpath解析本地文件
tree = etree.parse('爬虫_解析_xpath的基本使用.html')#tree.xpath('xpath路径')# 查找ul下面的li
li_list = tree.xpath('//body/ul/li')# 查找所有有id的属性的li标签
# text()获取标签中的内容
li_list = tree.xpath('//ul/li[@id]/text()')# 找到id为l1的li标签 注意引号的问题
li_list = tree.xpath('//ul/li[@id="l1"]/text()')# 查找到id为l1的li标签的class的属性值
li = tree.xpath('//ul/li[@id="l1"]/@class')# 查询id中包含l的li标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')# 查询id的值以l开头的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')#查询id为l1和class为c1的
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')# 判断列表的长度
print(li_list)
print(len(li_list))(2)xpath解析服务器响应的数据
①获取百度网站的“百度一下”四个字
# (1) 获取网页的源码
# (2) 解析 解析的服务器响应的文件 etree.HTML
# (3) 打印import urllib.requesturl = 'https://www.baidu.com/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}# 请求对象的定制
request = urllib.request.Request(url = url,headers = headers)# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)# 获取网页源码
content = response.read().decode('utf-8')# 解析网页源码 来获取我们想要的数据
from lxml import etree# 解析服务器响应的文件
tree = etree.HTML(content)# 获取想要的数据 xpath的返回值是一个列表类型的数据
result = tree.xpath('//input[@id="su"]/@value')[0]# 这样写也可以,xpath路径可以在选中区域后右键直接copy
# result = tree.xpath('//*[@id="su"]//@value')[0] print(result)②获取站长素材网站情侣图片前十页的图片
注:一般涉及图片的网站都会进行懒加载
# (1) 请求对象的定制
# (2)获取网页的源码
# (3)下载# 需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.htmlimport urllib.request
from lxml import etreedef create_request(page):if(page == 1):url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'else:url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',}request = urllib.request.Request(url = url, headers = headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef down_load(content):
# 下载图片# urllib.request.urlretrieve('图片地址','文件的名字')tree = etree.HTML(content)name_list = tree.xpath('//div[@id="container"]//a/img/@alt')# 一般涉及图片的网站都会进行懒加载src_list = tree.xpath('//div[@id="container"]//a/img/@src2')for i in range(len(name_list)):name = name_list[i]src = src_list[i]url = 'https:' + srcurllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')if __name__ == '__main__':start_page = int(input('请输入起始页码'))end_page = int(input('请输入结束页码'))for page in range(start_page,end_page+1):# (1) 请求对象的定制request = create_request(page)# (2)获取网页的源码content = get_content(request)# (3)下载down_load(content)
相关文章:
————XPath解析)
Python爬虫学习笔记(四)————XPath解析
目录 0.xpath最新下载地址和安装教程 1.xpath安装 2.xpath基本使用 3.xpath基本语法 4.实例 (1)xpath解析本地文件 (2)xpath解析服务器响应的数据 ①获取百度网站的“百度一下”四个字 ②获取站长素材网站情侣图片前十页的…...

知识图谱推理的学习逻辑规则(上)
知识图谱推理的学习逻辑规则 摘要介绍相关工作模型知识图谱推理逻辑规则概率形式化参数化优化 实验实验设置实验结果 结论 原文: 摘要 本文研究了在知识图谱上进行推理的学习逻辑规则。 逻辑规则用于预测时提供了可解释性并且可以推广到其他任务中,因…...

【从零开始学习C++ | 第二十一篇】C++新增特性 (上)
目录 前言: 委托构造函数: 类内初始化: 空指针: 枚举类: 总结: 前言: C的学习难度大,内容繁多。因此我们要及时掌握C的各种特性,因此我们更新本篇文章,向…...
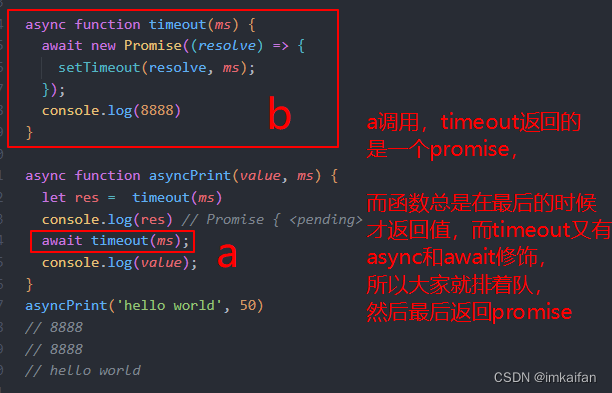
你真的会用async和await么?
背景 背景就是遇到了一个比较烦人的模块,里面的涉及到了大量的async 和 awiat。发现大多人对这个语法糖一知半解,然后大量的滥用,整理一下 async 前置知识: Promise.resolve(foo) new Promise(resolve > resolve(foo)…...
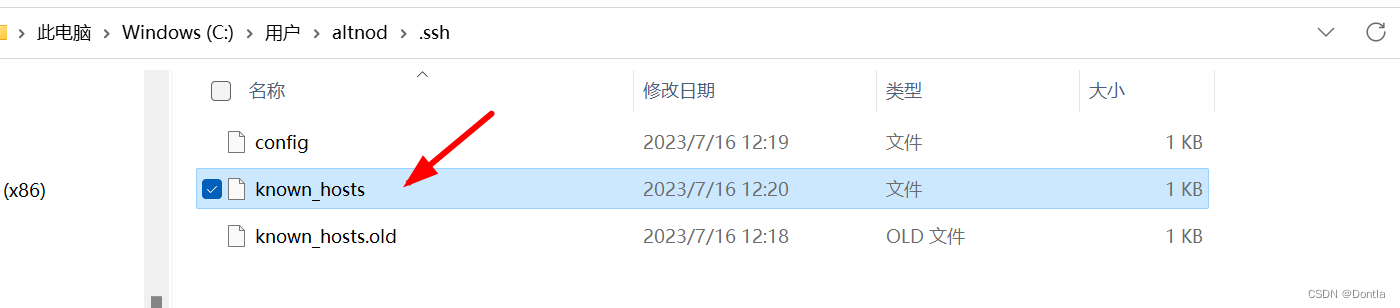
vscode远程连接提示:过程试图写入的管道不存在(删除C:\Users\<用户名>\.ssh\known_hosts然后重新连接)
文章目录 复现过程原因解决方法总结 复现过程 我是在windows上用vscode远程连接到我的ubuntu虚拟机上,后来我的虚拟机出了点问题,我把它回退了,然后再连接就出现了这个问题 原因 本地的known_hosts文件记录服务器信息与现服务器的信息冲突了…...
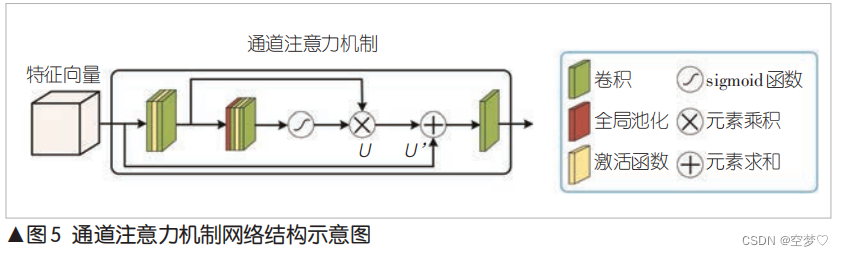
【005】基于深度学习的图像语 通信系统
摘要 语义通信是一种新颖的通信方式,可通过传输数据的语义信息提高带宽效率。提出一种用于无线图像传输的系统。该系统基于深度学习技术开发并以端到端(E2E)的方式进行训练。利用深度学习实现语义特征的提取和重建,在发送端提取信…...
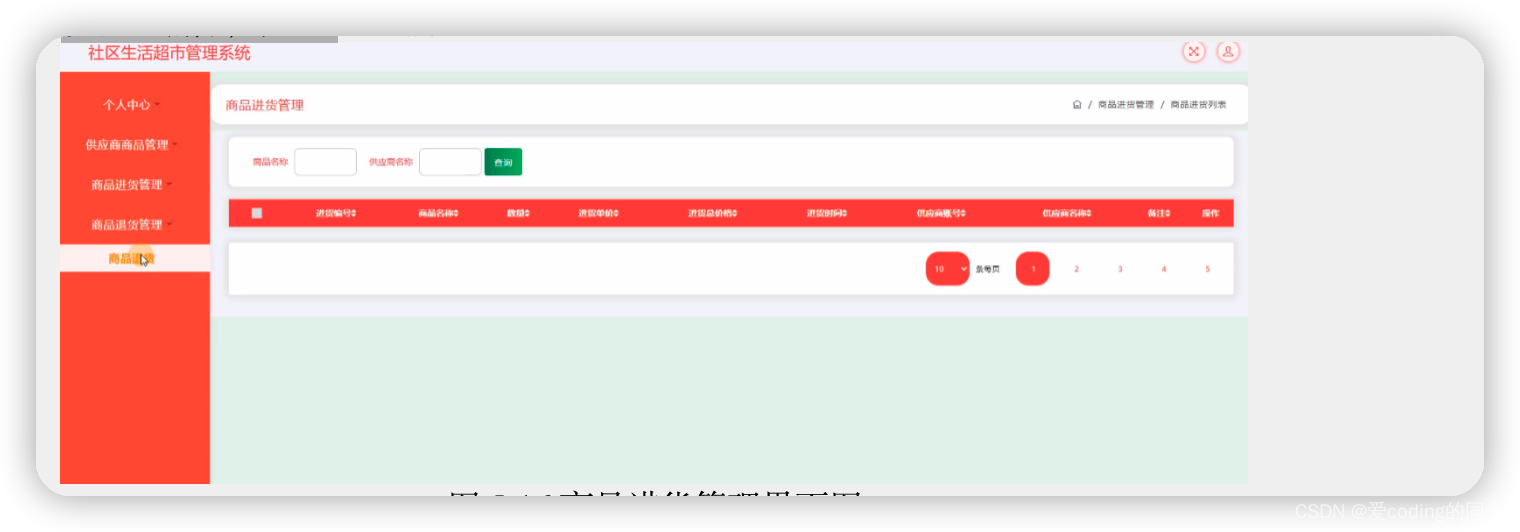
基于ssm的社区生活超市的设计与实现
博主介绍:专注于Java技术领域和毕业项目实战。专注于计算机毕设开发、定制、文档编写指导等,对软件开发具有浓厚的兴趣,工作之余喜欢钻研技术,关注IT技术的发展趋势,感谢大家的关注与支持。 技术交流和部署相关看文章…...

长短期记忆网络(LSTM)原理解析
长短期记忆网络(Long Short-Term Memory,简称LSTM)是一种常用于处理序列数据的深度学习模型。它在循环神经网络(Recurrent Neural Network,RNN)的基础上进行了改进,旨在解决传统RNN中的梯度消失…...
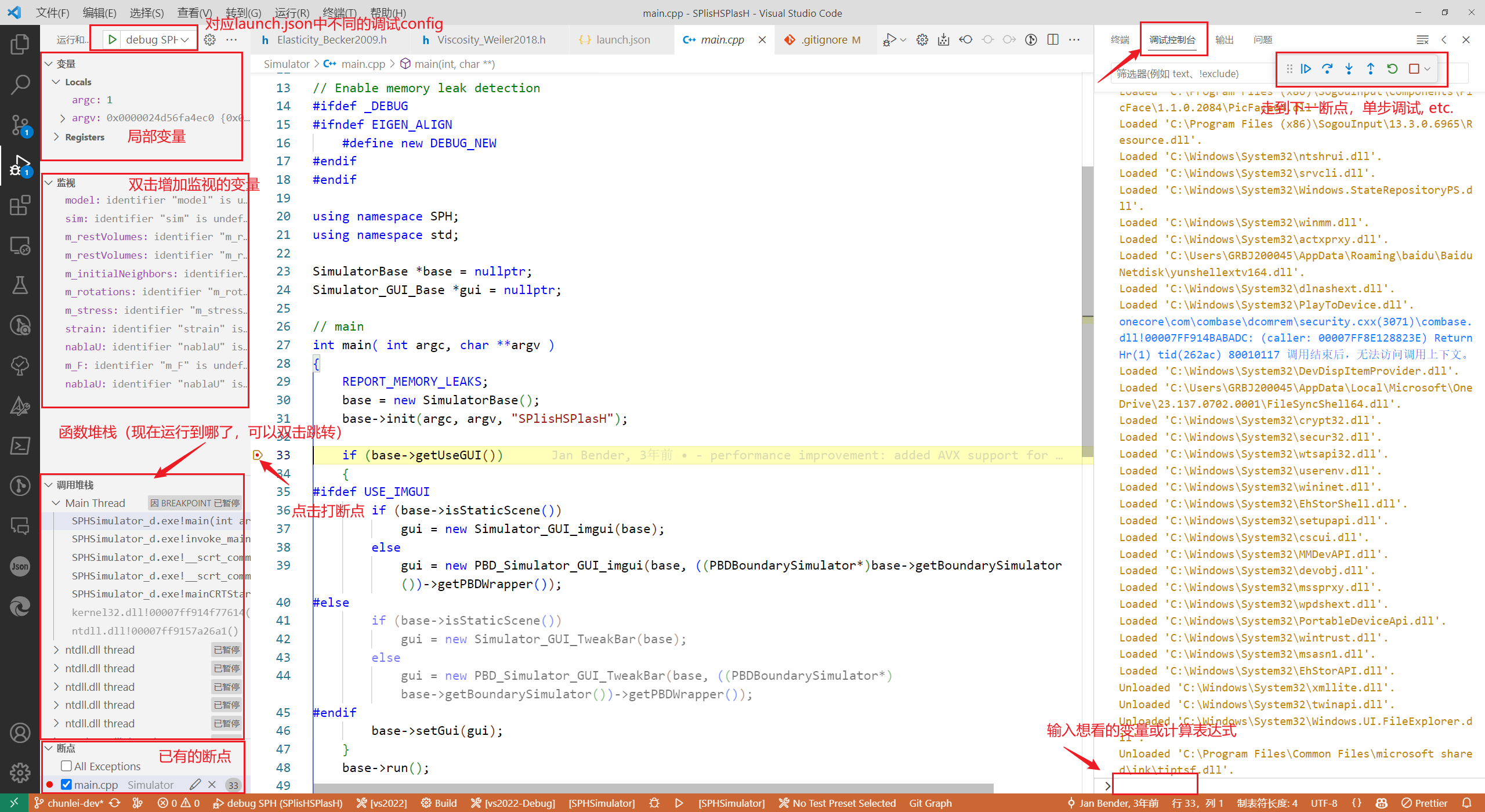
vscode debug的方式
在.vscode文件夹下建立launch.json 例子1:调试python 来自 https://github.com/chunleili/tiPBD/tree/amg {"version": "0.2.0","configurations": [{"name": "hpbd 5 5","type": "python&quo…...

微信加粉计数器后台开发
后台包括管理后台与代理后台两部分 管理后台 管理后台自带网络验证卡密系统,一个后台可以完成对Pc端的全部对接,可以自定义修改分组名称 分享等等代理后台 分享页 调用示例 <?php$request new HttpRequest(); $request->setUrl(http://xxxxxxx/api); $request->…...

黑客是什么?想成为黑客需要学习什么?
什么是黑客 在《黑客辞典》里有不少关于“黑客”的定义, 大多和“精于技术”或“乐于解决问题并超越极限”之类的形容相关。然而,若你想知道如何成为一名黑客,只要牢记两点即可。 这是一个社区和一种共享文化,可追溯到那群数十年前使…...

iOS中__attribute__的使用
通过__attribute编译期指令将数据注册至Mach-O指定段的section,可以提供更灵活的注册方式,避免了非必要依赖。通过这种方式不仅仅能够在任何地方注册string,甚至可以注册C函数。 下面的库提供了注册和读取内容的简单方式,主要支持…...

腾讯、飞书等在线表格自动化编辑--python
编辑在线表格 一 目的二 实现效果三 实现过程简介1、本地操作表格之后进入导入在线文档2、直接操作在线文档 四 实现步骤讲解1、实现方法的选择2、导入类库3、设置浏览器代理直接操作已打开浏览器4、在线文档登录5、在线文档表格数据操作6、行数不够自动添加行数 五 代码实现小…...

开源库nlohmann json使用备忘
nlohmann/json是一个用于解析JSON的开源C库,口碑一流,无需额外安装其他第三方库,还支持单个头文件模式,使用起来非常方便直观。 1. 编译 从官网https://github.com/nlohmann/json的Release页面下载单个json.hpp即可直接使用&…...

语音识别开源框架 openAI-whisper
Whisper 是一种通用的语音识别模型。 它是OpenAI于2022年9月份开源的在各种音频的大型数据集上训练的语音识别模型,也是一个可以执行多语言语音识别、语音翻译和语言识别的多任务模型。 GitHub - yeyupiaoling/Whisper-Finetune: 微调Whisper语音识别模型和加速推理…...

php做的中秋博饼游戏之绘制骰子图案功能示例
先看代码 header(Content-Type:image/png); $img imagecreatetruecolor(200, 200); $white imagecolorallocate($img, 255, 255, 255); $grey imagecolorallocate($img, 100, 100, 100); $blue imagecolorallocate($img, 0, 102, 255); $red imagecolorallocate($img, …...

erlang 虚拟机优化参数
sbwt none 将CPU忙等待关闭将有助于降低系统显示的CPU使用率,因为开启了忙等待的BEAM,CPU负载并不代表真实的工作情况; K true 开启epoll IO模型 swt low Sets scheduler wakeup threshold. Defaults to medium. The thresh…...
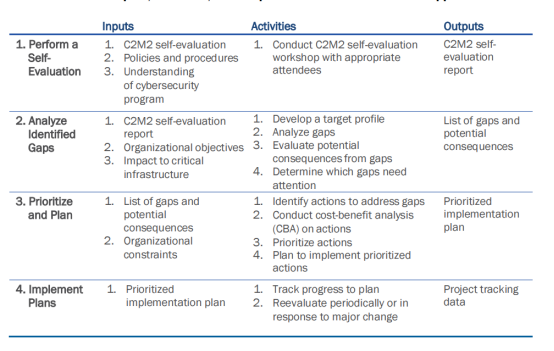
网络安全能力成熟度模型介绍
一、概述 经过多年网络安全工作,一直缺乏网络安全的整体视角,网络安全的全貌到底是什么,一直挺迷惑的。目前网络安全的分类和厂家非常多,而且每年还会冒出来不少新的产品。但这些产品感觉还是像盲人摸象,只看到网络安…...

python爬虫试手
同事让帮忙在某个网站爬点数据,首次尝试爬虫,遇到的问题及解决思路记录下。 大体需求是需要爬取详情页内的信息,详情页有一定格式规律,但是详情页需要从列表页跳入,列表页中的每一条记录需要鼠标悬停才会弹出跳转链接…...
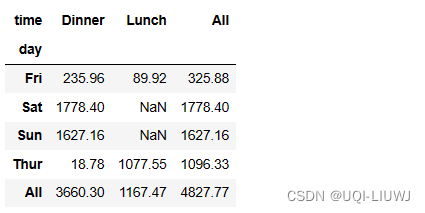
pandas 笔记:pivot_table 数据透视表
1 基本使用方法 pandas.pivot_table(data, valuesNone, indexNone, columnsNone, aggfuncmean, fill_valueNone, marginsFalse, dropnaTrue, margins_nameAll, observedFalse, sortTrue)2 主要参数 dataDataFramevalues要进行聚合的列index在数据透视表索引(index…...
从图像分割到GAN生成:转置卷积(Transpose Conv)的两种实战配置与调参心得
转置卷积实战指南:图像分割与GAN生成中的核心技巧 在计算机视觉领域,我们常常需要将低分辨率特征图恢复到原始尺寸——无论是为了像素级预测的图像分割任务,还是从潜在空间生成逼真图像的GAN模型。传统插值方法如双线性插值虽然简单ÿ…...

手把手教你用LVGL特殊符号打造炫酷UI界面
手把手教你用LVGL特殊符号打造炫酷UI界面 在嵌入式设备开发中,UI设计往往面临资源受限的挑战。LVGL(Light and Versatile Graphics Library)作为一款轻量级开源图形库,通过其丰富的特殊符号系统,让开发者能够在有限资…...

3分钟快速上手:免费高效的Elasticsearch可视化工具Elasticvue终极指南
3分钟快速上手:免费高效的Elasticsearch可视化工具Elasticvue终极指南 【免费下载链接】elasticvue Elasticsearch gui for the browser 项目地址: https://gitcode.com/gh_mirrors/el/elasticvue 你是否曾经为复杂的Elasticsearch集群管理而烦恼?…...

RGBLEDBlender:嵌入式RGB LED色彩混合与动态控制框架
1. RGBLEDBlender 库深度解析:面向嵌入式系统的 RGB 色彩混合与动态控制框架RGBLEDBlender 是一个轻量级、面向硬件的 RGB LED 色彩混合库,专为资源受限的微控制器平台(尤其是 Arduino 生态)设计。该库由 Erik Sikich 于 2016 年 …...

图结构AI Agent记忆机制深度解析:小白/程序员必备,收藏学习大模型前沿技术!
图结构AI Agent记忆机制深度解析:小白/程序员必备,收藏学习大模型前沿技术! 本文深入解析了基于图结构的AI Agent记忆机制,揭示了LLM驱动AI Agent面临的三大局限:知识截断、工具 incompetence 和性能饱和。文章强调记…...

如何在Photoshop中快速掌握AVIF格式:新手完整操作终极指南
如何在Photoshop中快速掌握AVIF格式:新手完整操作终极指南 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 还在为网站图片加载速度慢而烦恼吗&#…...

老牌CMS的隐痛:从DedeCMS漏洞看开源系统会员模块的安全设计误区
DedeCMS会员模块漏洞剖析:开源系统安全设计的深层反思 当一款拥有百万级安装量的老牌CMS系统曝出前台任意密码修改漏洞时,我们看到的不仅是一个具体的技术缺陷,更是开源项目在安全架构设计上的系统性隐忧。2018年那场影响广泛的DedeCMS漏洞事…...

SOONet效果展示:多查询并行定位——‘倒水’‘接电话’‘写笔记’三任务同步响应
SOONet效果展示:多查询并行定位——‘倒水’‘接电话’‘写笔记’三任务同步响应 1. 引言:当视频搜索变得像说话一样简单 想象一下,你有一段长达一小时的会议录像,现在需要快速找到“张三站起来发言”、“李四在白板上画图”以及…...

保姆级教程:MogFace人脸检测模型-large快速上手,无需代码轻松体验
保姆级教程:MogFace人脸检测模型-large快速上手,无需代码轻松体验 1. 认识MogFace人脸检测模型 1.1 什么是MogFace MogFace是目前最先进的人脸检测方法之一,在Wider Face六项榜单上长期保持领先地位。这个模型通过三个创新点显著提升了检测…...

SDMatte Web服务灰度发布:新模型版本AB测试与用户反馈闭环机制
SDMatte Web服务灰度发布:新模型版本AB测试与用户反馈闭环机制 1. 引言 在AI图像处理领域,模型迭代更新是持续提升服务质量的必经之路。SDMatte作为一款专注于高质量图像抠图的AI模型,近期完成了新版本SDMatte的研发工作。本文将详细介绍我…...