Spring后置处理器BeanFactoryPostProcessor与BeanPostProcessor源码解析
文章目录
- 一、简介
- 1、BeanFactoryPostProcessor
- 2、BeanPostProcessor
- 二、BeanFactoryPostProcessor 源码解析
- 1、BeanDefinitionRegistryPostProcessor 接口实现类的处理流程
- 2、BeanFactoryPostProcessor 接口实现类的处理流程
- 3、总结
- 三、BeanPostProcessor 源码解析
一、简介
Spring有两种类型的后置处理器,分别是 BeanFactoryPostProcessor 和 BeanPostProcessor ,这里再贴出我画的 Spring 启动过程,可以看看这两种后置处理器在 Spring 启动过程中位置。
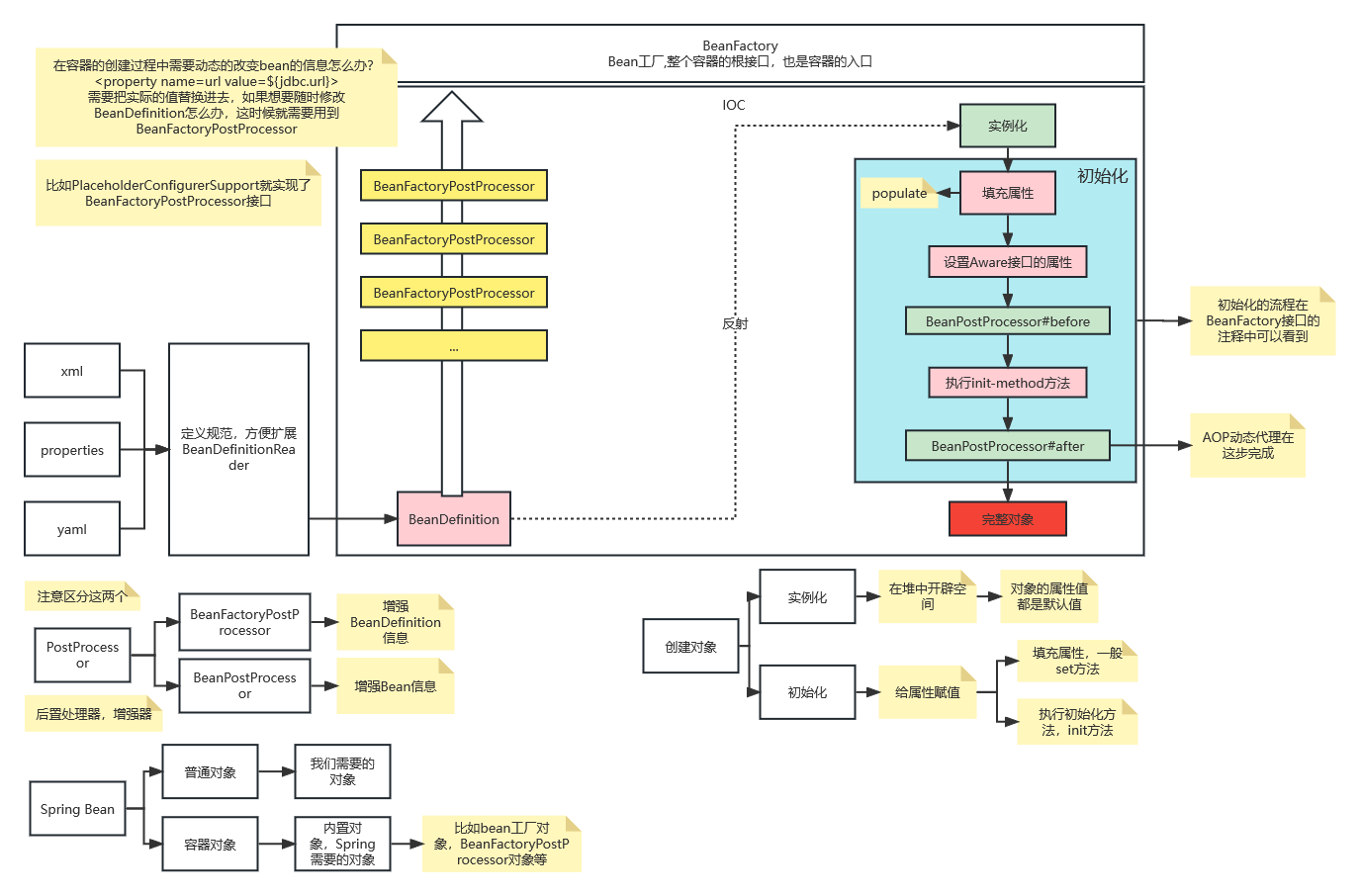
1、BeanFactoryPostProcessor
BeanFactoryPostProcessor 的 postProcessBeanFactory 方法在 Spring 容器启动时被调用,可以对整个容器中的 BeanDefinition (Bean 定义)进行处理,BeanFactoryPostProcessor 还有个子接口 BeanDefinitionRegistryPostProcessor ,其 postProcessBeanDefinitionRegistry 方法也可以对 BeanDefinition 进行处理的,但两个的侧重点不一样, BeanDefinitionRegistryPostProcessor 侧重于创建自定义的 BeanDefinition,而 BeanFactoryPostProcessor 侧重于对已有的 BeanDefinition 进行修改。
2、BeanPostProcessor
BeanPostProcessor 是在 Bean 初始化方法调用前后,对 Bean 进行一些预处理或后处理,这个接口有两个方法,分别是 postProcessBeforeInitialization 和 postProcessAfterInitialization,分别用来执行预处理和后处理。
二、BeanFactoryPostProcessor 源码解析
处理 BeanFactoryPostProcessor 的源码在哪里呢,我们先找到 Spring 的核心方法 refresh 方法(在 AbstractApplicationContext 类里),在里面找到 invokeBeanFactoryPostProcessors 方法
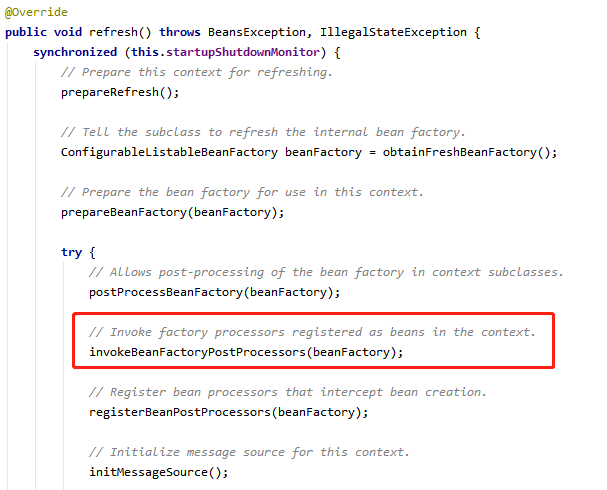
跟进去这个方法
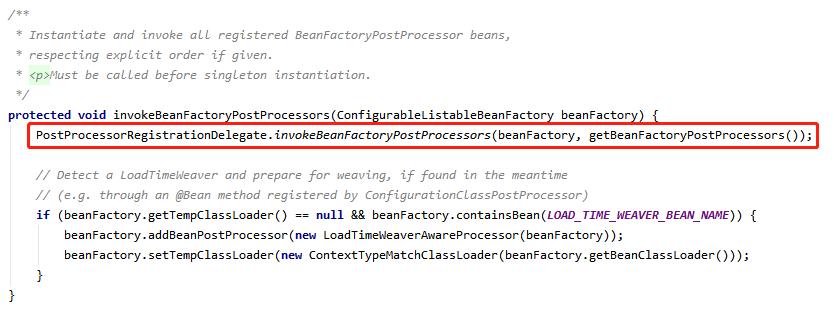
在跟进到 PostProcessorRegistrationDelegate 类的 invokeBeanFactoryPostProcessors 方法里,就到了核心处理逻辑了,先列出这个方法的代码
public static void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {// Invoke BeanDefinitionRegistryPostProcessors first, if any.Set<String> processedBeans = new HashSet<>();if (beanFactory instanceof BeanDefinitionRegistry) {BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {BeanDefinitionRegistryPostProcessor registryProcessor =(BeanDefinitionRegistryPostProcessor) postProcessor;registryProcessor.postProcessBeanDefinitionRegistry(registry);registryProcessors.add(registryProcessor);}else {regularPostProcessors.add(postProcessor);}}// Do not initialize FactoryBeans here: We need to leave all regular beans// uninitialized to let the bean factory post-processors apply to them!// Separate between BeanDefinitionRegistryPostProcessors that implement// PriorityOrdered, Ordered, and the rest.List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.String[] postProcessorNames =beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);for (String ppName : postProcessorNames) {if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));processedBeans.add(ppName);}}sortPostProcessors(currentRegistryProcessors, beanFactory);registryProcessors.addAll(currentRegistryProcessors);invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);currentRegistryProcessors.clear();// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);for (String ppName : postProcessorNames) {if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));processedBeans.add(ppName);}}sortPostProcessors(currentRegistryProcessors, beanFactory);registryProcessors.addAll(currentRegistryProcessors);invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);currentRegistryProcessors.clear();// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.boolean reiterate = true;while (reiterate) {reiterate = false;postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);for (String ppName : postProcessorNames) {if (!processedBeans.contains(ppName)) {currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));processedBeans.add(ppName);reiterate = true;}}sortPostProcessors(currentRegistryProcessors, beanFactory);registryProcessors.addAll(currentRegistryProcessors);invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);currentRegistryProcessors.clear();}// Now, invoke the postProcessBeanFactory callback of all processors handled so far.invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);}else {// Invoke factory processors registered with the context instance.invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);}// Do not initialize FactoryBeans here: We need to leave all regular beans// uninitialized to let the bean factory post-processors apply to them!String[] postProcessorNames =beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,// Ordered, and the rest.List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();List<String> orderedPostProcessorNames = new ArrayList<>();List<String> nonOrderedPostProcessorNames = new ArrayList<>();for (String ppName : postProcessorNames) {if (processedBeans.contains(ppName)) {// skip - already processed in first phase above}else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));}else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {orderedPostProcessorNames.add(ppName);}else {nonOrderedPostProcessorNames.add(ppName);}}// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.sortPostProcessors(priorityOrderedPostProcessors, beanFactory);invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);// Next, invoke the BeanFactoryPostProcessors that implement Ordered.List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();for (String postProcessorName : orderedPostProcessorNames) {orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));}sortPostProcessors(orderedPostProcessors, beanFactory);invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);// Finally, invoke all other BeanFactoryPostProcessors.List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();for (String postProcessorName : nonOrderedPostProcessorNames) {nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));}invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);// Clear cached merged bean definitions since the post-processors might have// modified the original metadata, e.g. replacing placeholders in values...beanFactory.clearMetadataCache();
}
这段代码比较长,我们可以分成两部分来看,前半部分处理 BeanDefinitionRegistryPostProcessors 接口的实现类,后半部分处理 BeanFactoryPostProcessor 接口的实现类,我们先看 BeanDefinitionRegistryPostProcessors 接口的处理流程
1、BeanDefinitionRegistryPostProcessor 接口实现类的处理流程
首先创建了一个名叫 processedBeans 的 HashSet

是为了记录处理过的 PostProcessor 的名字,目的是防止重复处理,然后下面对 beanFactory 的类型进行了判断,如果是 BeanDefinitionRegistry 类型,会有一大段的处理逻辑,如果不是,就调用 invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory); 方法
if (beanFactory instanceof BeanDefinitionRegistry) {...
}else {// Invoke factory processors registered with the context instance.invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
这个方法,其实就是循环执行所有 PostProcessor 的 postProcessBeanFactory 方法,我们再来看如果是 BeanDefinitionRegistry 类型,是怎么处理的,先看第一段
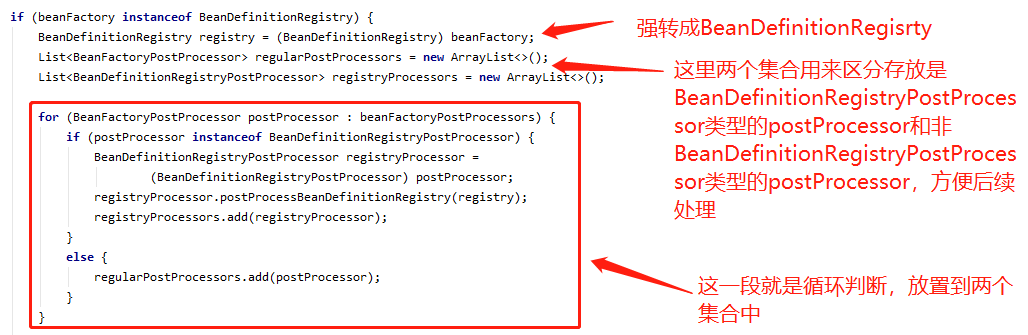
这一段是将传进来的参数 BeanFactoryPostProcessor 集合进行区分,分成 BeanDefinitionRegistryPostProcessor 类型(后面简称 BDRPP)和非 BeanDefinitionRegistryPostProcessor 类型,其实就是 BeanFactoryPostProcessor 类型(后面简称 BFPP),并执行了 BDRPP 类型的 postProcessBeanDefinitionRegistry 方法,并且,把两种类型分别添加到了两个集合里 registryProcessors 和 regularPostProcessors,继续往下看
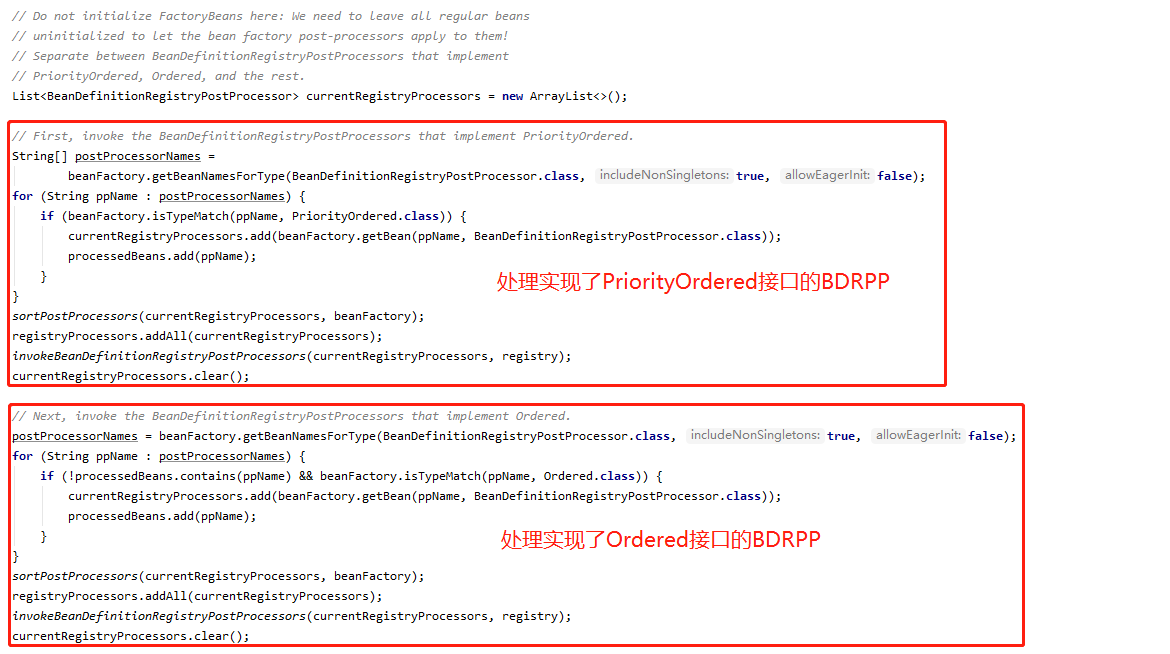
这一段,先声明了一个 BDRPP 类型的集合,用于存放在 Spring 容器里找到的 BDRPP,然后从 Spring 容器里找到所有 BDRPP 的名字,循环并找到实现了 PriorityOrdered 接口的 BDRPP,排序,添加到之前定义区分 BDRPP 和 BFPP 的集合 registryProcessors 里,然后执行了这些实现了 PriorityOrdered 接口的 BDRPP 的 postProcessBeanDefinitionRegistry 方法,下面以同样的方式处理实现了 Ordered 接口的 BDRPP,这里先科普下 PriorityOrdered 和 Ordered
PriorityOrdered和Ordered是 Spring 框架中用于定义 Bean 的加载顺序的接口。而PriorityOrdered是Ordered的子类,实现了这两个接口的类,需要实现一个getOrder()方法,返回一个 int 值,这个值越大,优先级就越低,而实现了PriorityOrdered接口的 Bean 的加载顺序会优先于实现了Ordered接口的Bean,且两者都优先于没实现这两个接口的 Bean
所以,这里先处理的实现了 PriorityOrdered 接口的 BDRPP ,再处理了实现了 Ordered 接口的 BDRPP ,有的人会好奇哦,为什么上面已经调用过一次 beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);,下面为什么还要再调一次,这不是重复代码了吗,其实不是,执行了 BDRPP 的 postProcessBeanDefinitionRegistry 方法,有可能会产生新的 BDRPP ,所以需要再重新取一次,继续看下面的代码
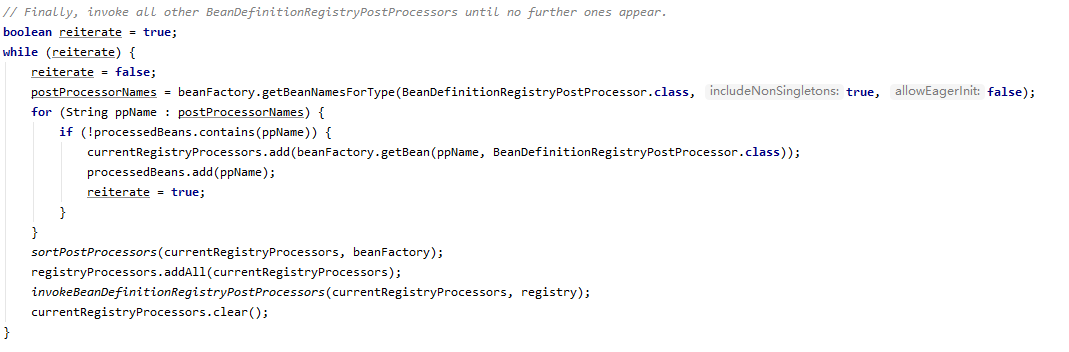
知道了执行了 BDRPP 的 postProcessBeanDefinitionRegistry 方法,有可能会产生新的 BDRPP ,这段就好理解了,一直循环获取 BDRPP,执行其 postProcessBeanDefinitionRegistry 方法,直到不产生新的 BDRPP 为止

最后,因为 BDRPP 是 BFPP 的子类,所以也是需要执行 BFPP 里的 postProcessBeanFactory 方法的,但是 BDRPP 的先执行,BFPP 的后执行。
到此 BDRPP 的处理完了,下面看 BFPP 的
2、BeanFactoryPostProcessor 接口实现类的处理流程
看完 BeanDefinitionRegistryPostProcessor 之后,BeanFactoryPostProcessor(后面简称 BFPP)的处理流程就比较简单了,先看第一段代码
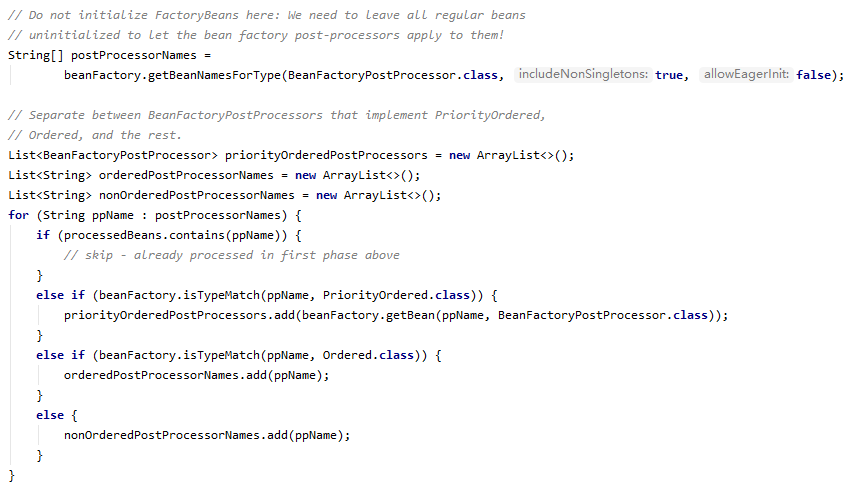
获取 Spring 容器里所有 BFPP 类型的 Bean,然后分成三类,分别是实现了 PriorityOrdered 接口的,实现了 Ordered 接口的,其他(也就是不需要排序的),这里需要注意,因为获取 BFPP 类型的 Bean,会将 BDRPP 类型的也获取到,因为 BDRPP 是 BFPP 的子类嘛,所以之前处理过的 BDRPP 需要跳过,继续看下面

这边就很好理解了,按照 PriorityOrdered > Ordered > 其他,的顺序依次执行 postProcessBeanFactory 方法
3、总结
总结一下执行顺序
- 先执行了
BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法,按照顺序PriorityOrdered>Ordered> 其他; - 再执行了
BeanDefinitionRegistryPostProcessor的postProcessBeanFactory方法; - 最后执行
BeanFactoryPostProcessor的postProcessBeanFactory方法,按照顺序PriorityOrdered>Ordered> 其他;
三、BeanPostProcessor 源码解析
处理 BeanPostProcessor (后面简称 BPP)的源码在哪里呢,我们知道 BPP 是在 Bean 实例化过程中,init 方法执行前后调用的,入口在 Spring 的核心方法 refresh 方法中的 finishBeanFactoryInitialization(beanFactory); 方法里,里面嵌套很多方法,我们直接来到创建 Bean 的核心方法里,也就是 AbstractAutowireCapableBeanFactory 类的 doCreateBean 方法,在这个方法里找到 exposedObject = initializeBean(beanName, exposedObject, mbd); 这句
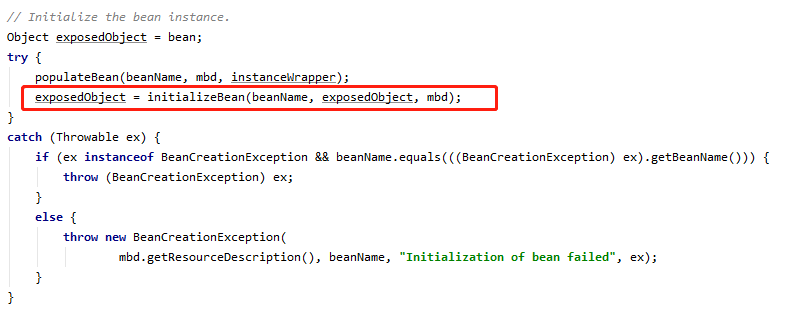
在对 Bean 进行实例化和属性填充之后,就会执行这个方法,进一步完成 Bean 的初始化,我们看看这个方法

可以看到在执行 init 方法前后,分别执行了 applyBeanPostProcessorsBeforeInitialization 和 applyBeanPostProcessorsAfterInitialization 方法,这两个方法里,循环了所有的 BPP,调用了其 postProcessBeforeInitialization 和 postProcessAfterInitialization 方法。
相关文章:
Spring后置处理器BeanFactoryPostProcessor与BeanPostProcessor源码解析
文章目录 一、简介1、BeanFactoryPostProcessor2、BeanPostProcessor 二、BeanFactoryPostProcessor 源码解析1、BeanDefinitionRegistryPostProcessor 接口实现类的处理流程2、BeanFactoryPostProcessor 接口实现类的处理流程3、总结 三、BeanPostProcessor 源码解析 一、简介…...
NXP i.MX 6ULL工业开发板硬件说明书( ARM Cortex-A7,主频792MHz)
前 言 本文档主要介绍TLIMX6U-EVM评估板硬件接口资源以及设计注意事项等内容。 创龙科技TLIMX6U-EVM是一款基于NXP i.MX 6ULL的ARM Cortex-A7高性能低功耗处理器设计的评估板,由核心板和评估底板组成。核心板经过专业的PCB Layout和高低温测试验证,稳…...
Ubuntu 放弃了战斗向微软投降
导读这几天看到 Ubuntu 放弃 Unity 和 Mir 开发,转向 Gnome 作为默认桌面环境的新闻,作为一个Linux十几年的老兵和Linux桌面的开发者,内心颇感良多。Ubuntu 做为全世界Linux界的桌面先驱者和创新者,突然宣布放弃自己多年开发的Uni…...
高并发的哲学原理(六)-- 拆分网络单点(下):SDN 如何替代百万人民币的负载均衡硬件
上一篇文章的末尾,我们利用负载均衡器打造了一个五万 QPS 的系统,本篇文章我们就来了解一下负载均衡技术的发展历程,并一起用 SDN(软件定义网络)技术打造出一个能够扛住 200Gbps 的负载均衡集群。 负载均衡发展史 F5 …...

用OpenCV进行图像分割--进阶篇
1. 引言 大家好,我的图像处理爱好者们! 在上一篇幅中,我们简单介绍了图像分割领域中的基础知识,包含基于固定阈值的分割和基于OSTU的分割算法。这一次,我们将通过介绍基于色度的分割来进一步巩固大家的基础知识。 闲…...
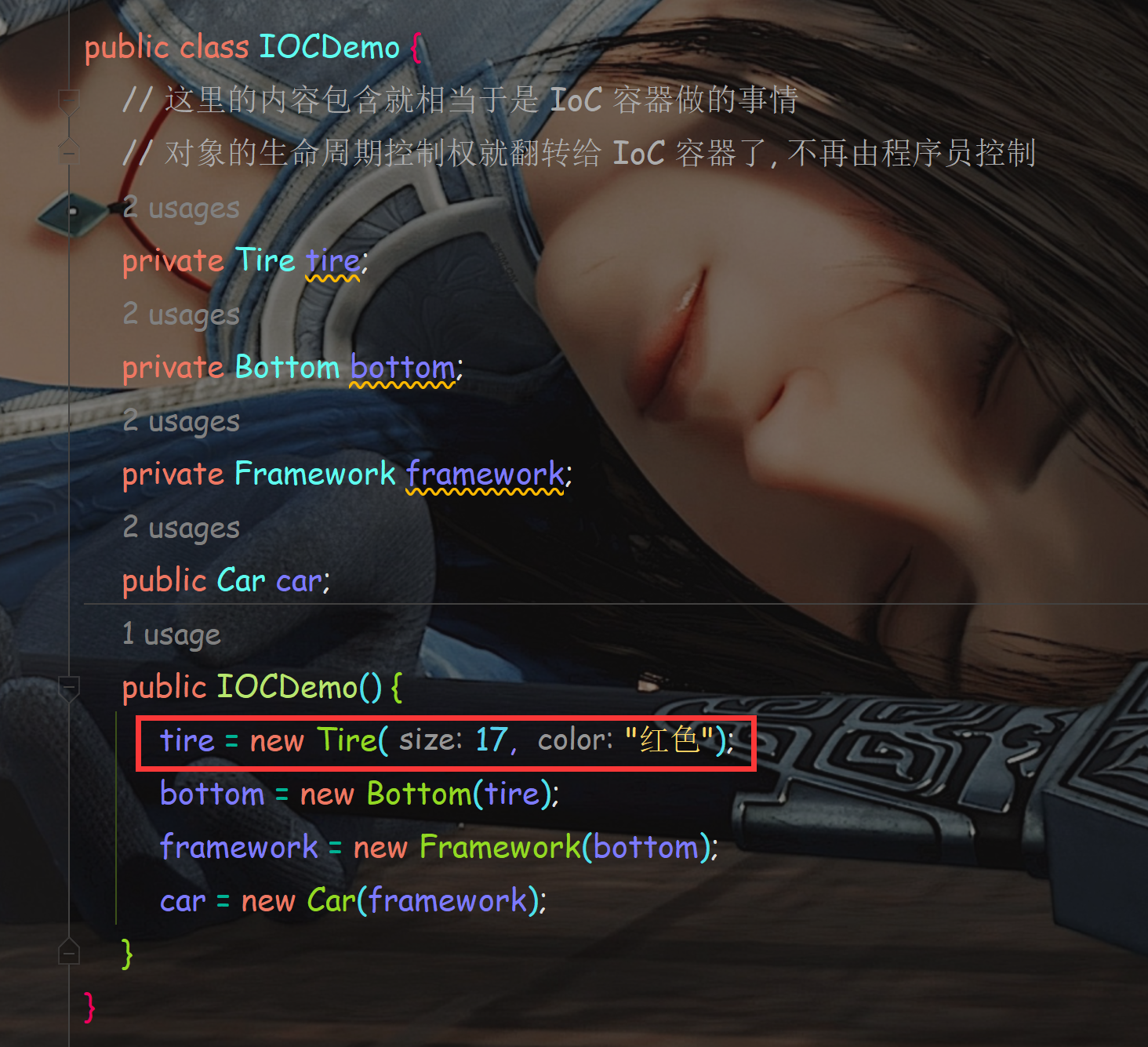
Spring框架概述及核心设计思想
文章目录 一. Spring框架概述1. 什么是Spring框架2. 为什么要学习框架?3. Spring框架学习的难点 二. Spring核心设计思想1. 容器是什么?2. IoC是什么?3. Spring是IoC容器4. DI(依赖注入)5. DL(依赖查找&…...

Unity自定义后处理——Vignette暗角
大家好,我是阿赵。 继续说一下屏幕后处理的做法,这一期讲的是Vignette暗角效果。 一、Vignette效果介绍 Vignette暗角的效果可以给画面提供一个氛围,或者模拟一些特殊的效果。 还是拿这个角色作为底图 添加了Vignette效果后࿰…...
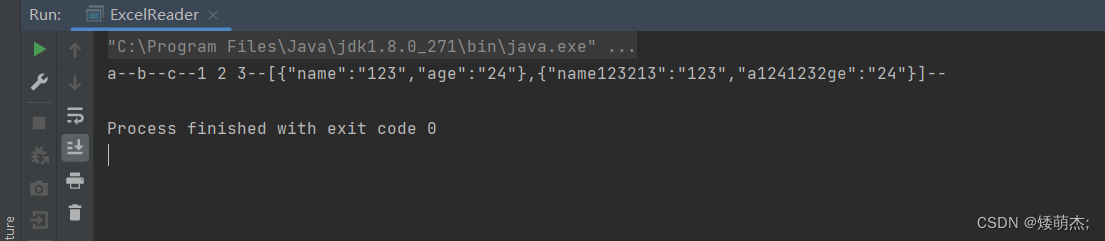
Java读取Excel 单元格包含换行问题
Java读取Excel 单元格包含换行问题 需求解决方案 需求 针对用户上传的Excel数据,或者本地读取的Excel数据。单元格中包含了换行,导致读取的数据被进行了切片。 正常读取如下图所示。 解决方案 目前是把数据读取出来的cell转成字符串后,…...

Django实现接口自动化平台(十)自定义action names【持续更新中】
相关文章: Django实现接口自动化平台(九)环境envs序列化器及视图【持续更新中】_做测试的喵酱的博客-CSDN博客 深入理解DRF中的Mixin类_做测试的喵酱的博客-CSDN博客 python中Mixin类的使用_做测试的喵酱的博客-CSDN博客 本章是项目的一…...
[爬虫]解决机票网站文本混淆问题-实战讲解
前言 最近有遇到很多小伙伴私信向我求助,遇到的问题基本上都是关于文本混淆或者是字体反爬的问题。今天给大家带来其中一个小伙伴的实际案例给大家讲讲解决方法 📝个人主页→数据挖掘博主ZTLJQ的主页 个人推荐python学习系列: ☄️爬虫J…...

【已解决】Flask项目报错AttributeError: ‘Request‘ object has no attribute ‘is_xhr‘
文章目录 报错及分析报错代码分析 解决方案必要的解决方法可能有用的解决方法 报错及分析 报错代码 File "/www/kuaidi/6f47274023d4ad9b608f078c76a900e5_venv/lib/python3.6/site-packages/flask/json.py", line 251, in jsonifyif current_app.config[JSONIFY_PR…...

【Java基础教程】Java学习路线攻略导图——史诗级别的细粒度归纳,持续更新中 ~
Java学习路线攻略导图 上篇 前言1、入门介绍篇2、程序基础概念篇3、包及访问权限篇4、异常处理篇5、特别篇6、面向对象篇7、新特性篇8、常用类库篇 前言 🍺🍺 各位读者朋友大家好!得益于各位朋友的支持和关注,我的专栏《Java基础…...

IntelliJ IDEA 2023.1 更新内容总结
IntelliJ IDEA 2023.1 更新内容总结 * 主要更新内容 * UI 大改版 * 性能改进项 * 其它更新内容IntelliJ IDEA 2023.1 更新内容总结 主要更新内容 IntelliJ IDEA 2023.1 针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施, …...

什么是计算机蠕虫?
计算机蠕虫诞生的背景 计算机蠕虫的诞生与计算机网络的发展密切相关。20世纪60年代末和70年代初,互联网还处于早期阶段,存在着相对较少的计算机和网络连接。然而,随着计算机技术的进步和互联网的普及,计算机网络得以迅速扩张&…...
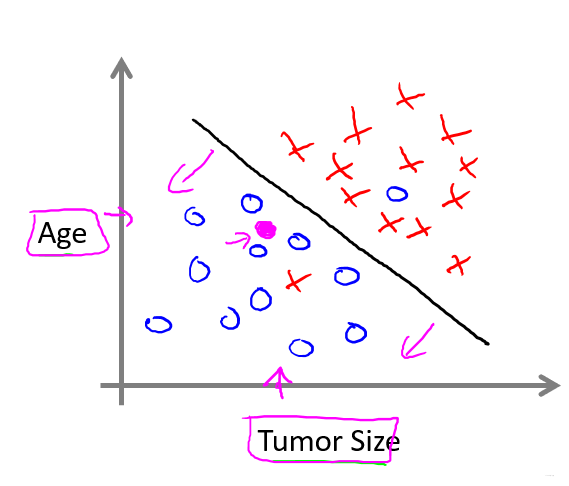
【机器学习】吴恩达课程1-Introduction
一、机器学习 1. 定义 计算机程序从经验E中学习,解决某一任务T,进行某一性能P,通过P测定在T上的表现因经验E而提高。 2. 例子 跳棋程序 E:程序自身下的上万盘棋局 T:下跳棋 P:与新对手下跳棋时赢的概…...
)
DBC转excel(python语言)
重复造轮子,只是为了熟悉一下DBC格式。 与同类工具的不同点: 能批量转换在同一文件夹下的所有DBC,省时省力。很多同类工具转换后的excel列宽较小,不能直接显示全部信息。本代码使用了自适应的列宽,看起来更方便。** …...
)
Java集合(List、Set、Map)
Java中的集合是用于存储和组织对象的数据结构。Java提供了许多不同的集合类,包括List、Set和Map等,以满足不同的需求。下面将介绍一些常见的Java集合类及其使用方法。 一、List List是一个有序的集合,它允许元素重复出现,并提供…...

Linux--只执行一次的计划任务--at命令
Linux–只执行一次的计划任务–at命令 文章目录 Linux--只执行一次的计划任务--at命令一、atd的启动和at的运行方式二、at总结 一、atd的启动和at的运行方式 atd的启动: systemctl restrat atd #重新启动atd这个服务 systemctl enable atd #让这个服务开机自启动 sy…...

关于贪心算法的一个小结
下面的内容主要参考了数据结构与算法之美。 贪心算法的应用有: 霍夫曼编码(Huffman Coding) Prim和Kruskal最小生成树算法 01背包问题(当允许取部分物品的时候) 分糖果 我们有m个糖果和n个孩子。我们现在要把糖果分给这些孩子吃ÿ…...
五、DQL-2.基本查询
一、数据准备 1、删除表employee: drop table employee; 2、创建表emp: 3、添加数据: 4、查看表数据: 【代码】 -- 查询数据--------------------------------------------------------- drop table emp;-- 数据准备-----------…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...