第五章.与学习相关技巧—Batch Normalization
第五章.与学习相关技巧
5.3 Batch Normalization
- Batch Norm以进行学习时的mini_batch为单位,按mini_batch进行正则化,具体而言,就是进行使数据分布的均值为0,方差为1的正则化。
- Batch Norm是调整各层激活值的分布使其拥有适当的广度。
1.优点
- 可以使学习快速进行
- 不那么依赖初始值
- 抑制过拟合(降低Dropout等的必要性)
2.数学式
1).均值:

2).方差:
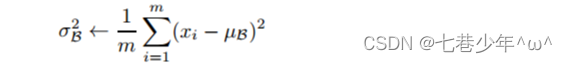
3).正则化:

- 参数说明:
①.ε:微小值(1e-7),防止出现除数为0的情况
4).缩放和平移
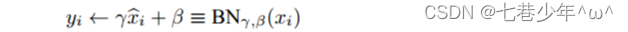
- 参数说明:
①.α,β:一开始α=1,β=0,然后通过学习调整到合适的值。
3.通过MNIST数据集来对比使用Batch Norm层与不使用Batch Norm层的差异。
1).不同权重初始值的标准差:
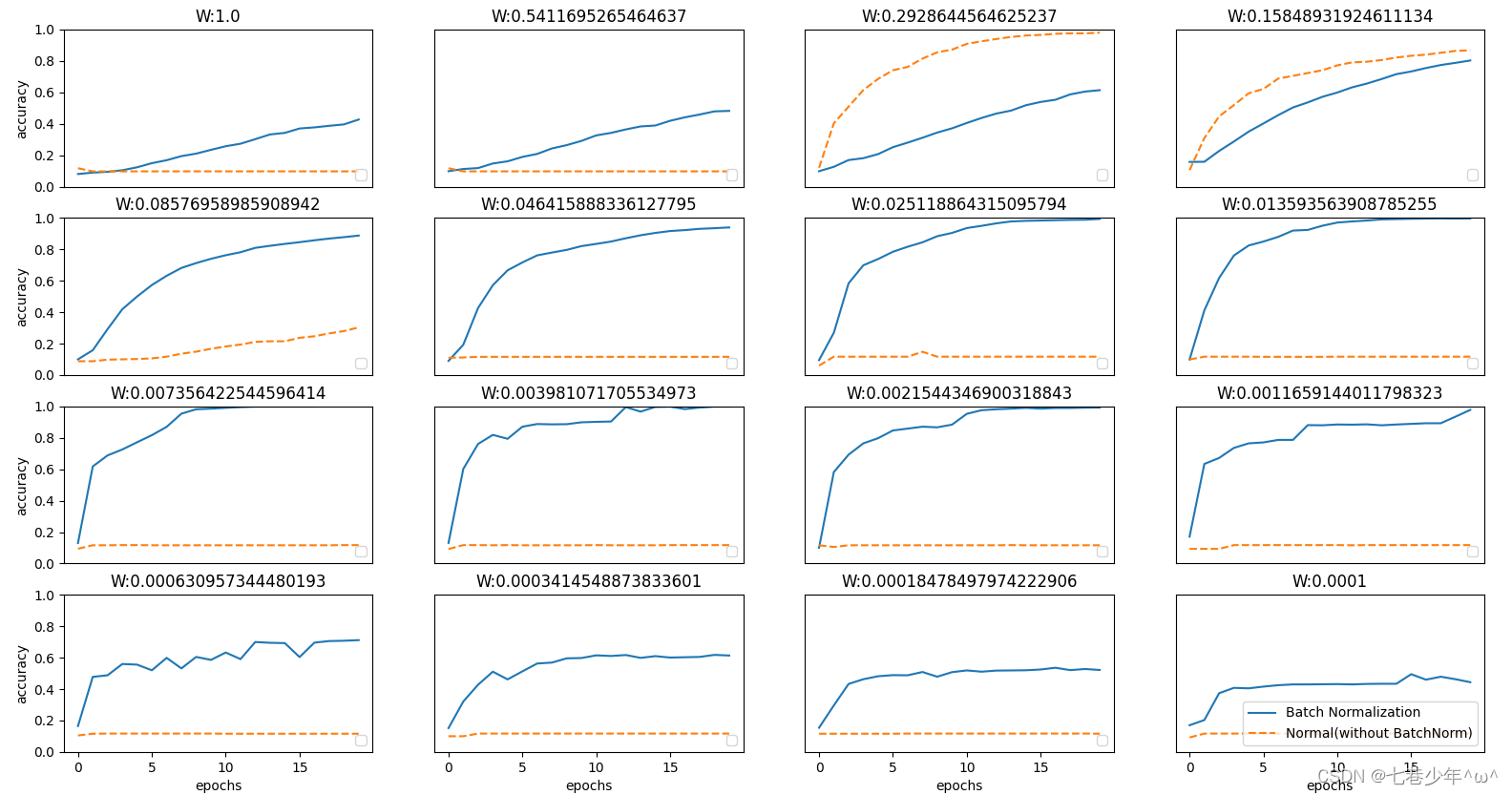
2).图像分析:
-
从图像可知,几乎所有的情况下都是使用Batch Norm时学习进行的更快,同时也可以发现,在不使用Batch Norm的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行。
-
综上,通过使用Batch Norm,可以推动学习的进行,并且对权重初始值变得健壮,不那么依赖初始值。
3).代码实现:
import sys, ossys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from collections import OrderedDict# 加载数据
def get_data():(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)return (x_train, t_train), (x_test, t_test)def Sigmoid(x):return 1 / (1 + np.exp(-x))def Relu(x):return np.maximum(x, 0)def numerical_gradient(f, x):h = 1e-4 # 0.0001grad = np.zeros_like(x)it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])while not it.finished:idx = it.multi_indextmp_val = x[idx]x[idx] = float(tmp_val) + hfxh1 = f(x) # f(x+h)x[idx] = tmp_val - hfxh2 = f(x) # f(x-h)grad[idx] = (fxh1 - fxh2) / (2 * h)x[idx] = tmp_val # 还原值it.iternext()return gradclass SoftmaxWithLoss:def __init__(self):self.loss = None # 损失self.y = None # softmax的输出self.t = None # 监督数据(one_hot vector)# 输出层函数:softmaxdef softmax(self, x):if x.ndim == 2:x = x.Tx = x - np.max(x, axis=0)y = np.exp(x) / np.sum(np.exp(x), axis=0)return y.Tx = x - np.max(x) # 溢出对策return np.exp(x) / np.sum(np.exp(x))# 交叉熵误差def cross_entropy_error(self, y, t):if y.ndim == 1:t = t.reshape(1, t.size)y = y.reshape(1, y.size)# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引if t.size == y.size:t = t.argmax(axis=1)batch_size = y.shape[0]return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size# 正向传播def forward(self, x, t):self.t = tself.y = self.softmax(x)self.loss = self.cross_entropy_error(self.y, self.t)return self.loss# 反向传播def backward(self, dout=1):batch_size = self.t.shape[0]if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况dx = (self.y - self.t) / batch_sizeelse:dx = self.y.copy()dx[np.arange(batch_size), self.t] -= 1dx = dx / batch_sizereturn dxclass Affine:def __init__(self, W, b):self.W = Wself.b = bself.x = Noneself.original_x_shape = None# 权重和偏置参数的导数self.dW = Noneself.db = None# 正向传播def forward(self, x):# 对应张量self.original_x_shape = x.shapex = x.reshape(x.shape[0], -1)self.x = xout = np.dot(self.x, self.w) + self.breturn out# 反向传播def backward(self, dout):dx = np.dot(dout, self.W.T)self.dW = np.dot(self.x.T, dout)self.db = np.sum(dout, axis=0)# 还原输入数据的形状dx = dx.reshape(*self.original_x_shape)return dxclass SGD:def __init__(self, lr):self.lr = lrdef update(self, params, grads):for key in params.keys():params[key] -= self.lr * grads[key]# 调整各层的激活值分布使其拥有适当的广度
class BatchNormlization:def __init__(self, gamma, beta, momentum, running_mean=None, running_var=None):self.gamma = gammaself.beta = betaself.momentum = momentumself.input_shape = None # Conv层的情况下为4维,全连接层的情况下为2维# 测试时使用的平均值和方差self.running_mean = running_meanself.running_var = running_var# backward时使用的中间数据self.batch_size = Noneself.xc = Noneself.std = Noneself.dgamma = Noneself.dbeta = Nonedef __forward(self, x, train_flg):if self.running_mean is None:N, D = x.shapeself.running_mean = np.zeros(D)self.running_var = np.zeros(D)if train_flg:mu = x.mean(axis=0)xc = x - muvar = np.mean(xc ** 2, axis=0)std = np.sqrt(var + 1e-7)xn = xc / stdself.batch_size = x.shape[0]self.xc = xcself.xn = xnself.std = stdself.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * muself.running_var = self.momentum * self.running_var + (1 - self.momentum) * varelse:xc = x - self.running_meanxn = xc / (np.sqrt(self.running_var + 1e-7))return self.gamma * xn + self.betadef forward(self, x, train_flg=True):self.input_shape = x.shapeif x.ndim != 2:N, C, H, W = x.shapex = x.reshape(N, -1)out = self.__forward(x, train_flg)return out.reshape(*self.input_shape)def __backward(self, dout):dbeta = dout.sum(axis=0)dgamma = np.sum(self.xn + dout, axis=0)dxn = self.gamma * doutdxc = dxn / self.stddstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)dvar = 0.5 * dstd / self.stddxc += (2.0 / self.batch_size) * self.xc * dvardmu = np.sum(dxc, axis=0)dx = dxc - dmu / self.batch_sizeself.dgamma = dgammaself.dbeta = dbetareturn dxdef backward(self, dout):if dout.ndim != 2:N, C, H, W = dout.shapedout = dout.reshape(N, -1)dx = self.__backward(dout)dx = dx.reshape(*self.input_shape)return dx# 在学习过程中随机删除神经元的方法:dropout_ratio神经元的删除比
class Dropout:def __int__(self, dropout_ratio=0.5):self.dropout_ratio = dropout_ratioself.mask = None# 正向传播def forward(self, x, train_flg=True):if train_flg:self.mask = np.random.rand(*x.shape) > self.dropout_ratioreturn x * self.maskelse:return x * (1 - self.dropout_ratio)# 反向传播def backward(self, dout):return dout * self.mask# 全连接的多层神经网络
class MultiLayerNet:def __init__(self, input_size, hidden_size_list, output_size, activation='relu', weight_init_std='relu',weight_decay_lambda=0, use_dropout=False, dropout_ratio=0.5, use_batchnorm=False):self.input_size = input_sizeself.hidden_size_list = hidden_size_listself.output_size = output_sizeself.hidden_layer_num = len(hidden_size_list)self.use_dropout = use_dropoutself.use_batchnorm = use_batchnormself.weight_decay_lambda = weight_decay_lambdaself.params = {}# 初始化权重self.__init_weight(weight_init_std)# 生成层activation_layer = {'sigmoid': Sigmoid, 'relu': Relu}self.layer = OrderedDict()for idx in range(1, self.hidden_layer_num + 1):self.layer['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)])if self.use_batchnorm:self.params['gamma' + str(idx)] = np.ones(hidden_size_list[idx - 1])self.params['beta' + str(idx)] = np.zeros(hidden_size_list[idx - 1])self.layer['BatchNorm' + str(idx)] = BatchNormlization(self.params['gamma' + str(idx)],self.params['beta' + str(idx)])self.layer['Activation—_function' + str(idx)] = activation_layer[activation]if self.use_dropout:self.layer['Dropout' + str(idx)] = Dropout(dropout_ratio)idx = self.hidden_layer_num + 1self.layer['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)])self.last_layer = SoftmaxWithLoss()def __init_weight(self, weight_init_std):"""设定权重的初始值Parameters----------weight_init_std : 指定权重的标准差(e.g. 0.01)指定'relu'或'he'的情况下设定“He的初始值”指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”"""all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size]for idx in range(1, len(all_size_list)):scale = weight_init_stdif str(weight_init_std).lower() in ('relu', 'he'):scale = np.sqrt(2.0 / all_size_list[idx - 1]) # 使用ReLU的情况下推荐的初始值elif str(weight_init_std).lower() in ('sigmoid', 'xavier'):scale = np.sqrt(1.0 / all_size_list[idx - 1]) # 使用sigmoid的情况下推荐的初始值self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx - 1], all_size_list[idx])self.params['b' + str(idx)] = np.zeros(all_size_list[idx])def predict(self, x, train_flg=False):for key, layer in self.layers.items():if "Dropout" in key or "BatchNorm" in key:x = layer.forward(x, train_flg)else:x = layer.forward(x)return xdef loss(self, x, t, train_flg=False):"""求损失函数参数x是输入数据,t是教师标签"""y = self.predict(x, train_flg)weight_decay = 0for idx in range(1, self.hidden_layer_num + 2):W = self.params['W' + str(idx)]weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)return self.last_layer.forward(y, t) + weight_decaydef accuracy(self, X, T):Y = self.predict(X, train_flg=False)Y = np.argmax(Y, axis=1)if T.ndim != 1: T = np.argmax(T, axis=1)accuracy = np.sum(Y == T) / float(X.shape[0])return accuracydef numerical_gradient(self, X, T):"""求梯度(数值微分)Parameters----------X : 输入数据T : 教师标签Returns-------具有各层的梯度的字典变量grads['W1']、grads['W2']、...是各层的权重grads['b1']、grads['b2']、...是各层的偏置"""loss_W = lambda W: self.loss(X, T, train_flg=True)grads = {}for idx in range(1, self.hidden_layer_num + 2):grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)])grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)])if self.use_batchnorm and idx != self.hidden_layer_num + 1:grads['gamma' + str(idx)] = numerical_gradient(loss_W, self.params['gamma' + str(idx)])grads['beta' + str(idx)] = numerical_gradient(loss_W, self.params['beta' + str(idx)])return gradsdef gradient(self, x, t):# forwardself.loss(x, t, train_flg=True)# backwarddout = 1dout = self.last_layer.backward(dout)layers = list(self.layers.values())layers.reverse()for layer in layers:dout = layer.backward(dout)# 设定grads = {}for idx in range(1, self.hidden_layer_num + 2):grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.params['W' + str(idx)]grads['b' + str(idx)] = self.layers['Affine' + str(idx)].dbif self.use_batchnorm and idx != self.hidden_layer_num + 1:grads['gamma' + str(idx)] = self.layers['BatchNorm' + str(idx)].dgammagrads['beta' + str(idx)] = self.layers['BatchNorm' + str(idx)].dbetareturn grads# 加载数据
(x_train, t_train), (x_test, t_test) = get_data()# 抽取训练数据
x_train = x_train[:1000]
t_train = t_train[:1000]# 超参数
iter_num = 10000000
lr = 0.01
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100def __train(weight_init_std):bn_network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,weight_init_std=weight_init_std, use_batchnorm=True)network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,weight_init_std=weight_init_std)optimizer = SGD(lr)train_acc_list = []bn_train_acc_list = []iter_per_epoch = max(train_size / batch_size, 1)epoch_cnt = 0for i in range(iter_num):# 数据抽取batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]for _network in (bn_network, network):grads = _network.gradient(x_batch, t_batch)optimizer.update(_network.params, grads)if i % iter_per_epoch == 0:train_acc = network.accuracy(x_train, t_train)train_acc_list.append(train_acc)bn_train_acc = _network.accuracy(x_train, t_train)bn_train_acc_list.append(bn_train_acc)print('train_acc,bn_train_acc|', str(train_acc) + str(bn_train_acc))epoch_cnt += 1if epoch_cnt >= max_epochs:breakreturn train_acc_list, bn_train_acc_list# 绘制图形
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)for i, w in enumerate(weight_scale_list):print("============== " + str(i + 1) + "/16" + " ==============")train_acc_list, bn_train_acc_list = __train(w)plt.subplot(4, 4, i + 1)plt.title("W:" + str(w))if i == 15:plt.plot(x, bn_train_acc_list, label='Batch Normalization', markevery=2)plt.plot(x, train_acc_list, linestyle="--", label='Normal(without BatchNorm)', markevery=2)else:plt.plot(x, bn_train_acc_list, markevery=2)plt.plot(x, train_acc_list, linestyle="--", markevery=2)plt.ylim(0, 1.0)if i % 4:plt.yticks([])else:plt.ylabel("accuracy")if i < 12:plt.xticks([])else:plt.xlabel("epochs")plt.legend(loc='lower right')plt.show()相关文章:
第五章.与学习相关技巧—Batch Normalization
第五章.与学习相关技巧 5.3 Batch Normalization Batch Norm以进行学习时的mini_batch为单位,按mini_batch进行正则化,具体而言,就是进行使数据分布的均值为0,方差为1的正则化。Batch Norm是调整各层激活值的分布使其拥有适当的广…...
Zynq非Video Mixer方案实现视频叠加输出,无需SDK配置,提供工程源码和技术支持
目录1、前言2、Video Mixer的不便之处3、FDMA取代Video Mixer实现视频叠加输出4、Vivado工程详解5、上板调试验证并演示6、福利:工程代码的获取1、前言 关于Zynq使用Video Mixer方案实现视频叠加输出方案请参考点击查看:Video Mixer方案 对于Zynq和Micr…...
从零实现Web服务器(二): 线程池以及线程池的作用,Get和Post的区别,项目中如何编写数据库连接池,定时器优化非活跃连接
文章目录一、线程池以及线程池的作用二、手写线程池三、Get和Post的区别四、如何编写数据库连接池五、定时器优化非活跃连接5.1. 基于排序链表实现。5.2. 基于小根堆实现。5.3. 基于红黑树实现。5.4. 基于时间轮实现。5.4.1 单时间轮实现5.4.2 多时间轮实现一、线程池以及线程池…...

为什么伟大的产品只专注做一件事
uber 不允许你预订出租车。亚马逊一开始只是卖书。谷歌只是一个搜索引擎。麦当劳没有餐具。不知为什么,我们仍然相信一个产品要想成功,它必须做很多事情。这通常发生在两种情况下:当新产品试图让市场相信它们是值得的,或者当公司提…...
pycharm远程连接服务器,并单步调试服务器上的代码
每天都有不同的朋友来Push我 那如果比较健忘的话,为啥不问一下chatGPT呢 问题的缘由在我想在本地单步调试代码。。。 我的代码完全在云端服务器的,还有数据集都是,但实际上本地代码可以通过pycharm给他传上去。 但是在后面配置的时候需要两…...
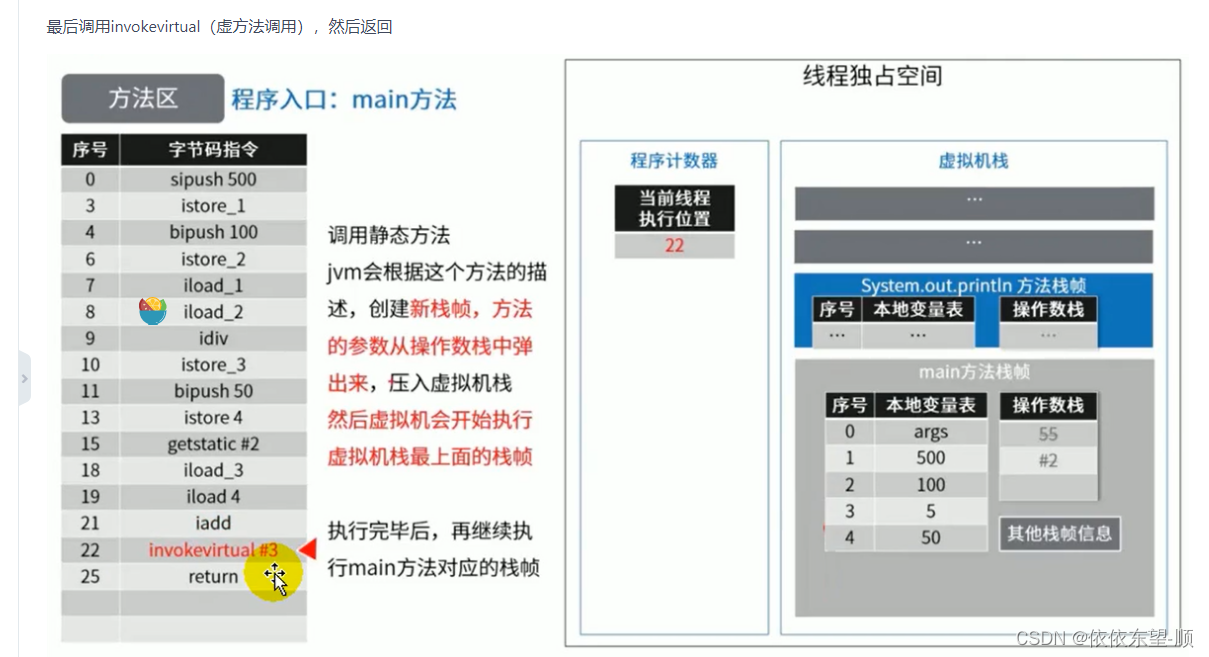
JVM05 方法区
Person:存放在元空间,也可以说方法区 person:存放在Java栈的局部变量表中 new Person():存放在Java堆中 1.方法区的理解 方法区主要存放的是 Class,而堆中主要存放的是 实例化的对象 方法区(Method Area…...

盘点3个.Net开发的WMS仓库管理系统
更多开源项目请查看:一个专注推荐.Net开源项目的榜单 仓库管理系统在企业中,重要性越来越高,不仅可以提高效率,还能降低企业的压力,企业通过协调和优化资源使用和物料流动,能极大程度地提升了管理效率&…...

Linux下Java项目开机自动启动
Linux下Java项目开机自动启动1、在Linux上设置开机启动Java程序,例如:test.jar在Linux上启动Java程序的命令:2、可以将程序启动的指令做成一个shell脚本,简单的做法创建一个test.sh文件,内容如下:3、最重要的一步就是修…...
基于SpringBoot的智慧社区网站
文末获取源码 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏…...

数据分析与SAS学习笔记3
SAS在最新的展示图,表现力比较丰富。 SAS的处理流程: 数据步 过程步: ETL是数据分析非常重要的步骤。70%-90%花在收集数据以及整理数据,数据分析数据的时间不是很多的。 一个完整的数据步和过程步: 数据步基本语句总…...

天干地支蓝桥杯国赛
题目 分析 蓝桥杯国赛2020简单模拟题,你敢信,就是弄两个字符串数组。重点在于知道0000年是从哪个天干和地支开始的。 代码 #include <iostream> using namespace std;int year;int main() {cin >> year;string tiangan[10] {"geng&…...

Source lnsight工具的简单使用
多文件编程推荐用Source lnsight工具来进行编写 一、Source lnsight工具的简单使用 1、在桌面上新建一个文件夹factory,在文件夹里新建一个cat.c文件和si文件夹 2、打开Source lnsight工具,点击上方Project--->New Project 3、把文件夹factory中si文…...

100个变态的软件测试面试题及答案!——看完变态面试官对你竖起大拇指!
【纯干货!!!】花费了整整3天,整理出来的全网最实用软件测试面试大全,一共30道题目答案的纯干货,希望大家多多支持,建议 点赞!!收藏!!长文警告&…...

Windows保护机制GS:原理及SEH异常处理突破
前言 本次文章只用于技术讨论,学习,切勿用于非法用途,用于非法用途与本人无关! 所有环境均为本地环境分析,且在本机进行学习。 GS机制并没有对SEH提供保护,换句话说我们可以通过攻击程序的异常处理达到绕…...
大彩 串口屏
资料下载 视频 屏幕程序创建 创建 主界面设置 实现按钮和文本的添加,实现画面的切换 下面注释4有点问题,切换画面还是会下传指令集,只是无法在软件中进行指令集的设置了 按钮界面 首先第一步同上添加背景图片,然后添加…...

安装 cplex 求解器
安装 cplex 求解器 安装 cplex 求解器和python-docplexcplex 安装matlab 用户安装 cplexpython 版本安装 cplex 求解器和python-docplex cplex 安装 cplex 是解决优化问题的一个工具箱,用来线性规划、混合整数规划和二次规划的高性能数学规划求解器。可以理解成&a…...

DPR-34 AC22V【双位置继电器】
系列型号: DPR-20双位置继电器;DPR-31双位置继电器; DPR-32双位置继电器;DPR-33双位置继电器; DPR-34双位置继电器;DPR-35双位置继电器; DPR-11双位置继电器;DPR-12双位置继电器&…...
Ubuntu16.04搭建Fabric1.4环境
一、换源 为了提高下载速度,将ubuntu的源改成国内的源(推荐阿里云源和清华源) apt源保存在 /etc/apt/sources.list / 代表根目录 /etc 这个文件夹几乎放置了系统的所有配置文件 1.备份 sudo cp /etc/apt/sources.list sources_backup.l…...

【JavaScript】深度剖析prototype与__proto__到底是什么以及他们的关系
一个对象的 __proto__ 指向的是这个对象的构造函数的 prototype。 prototype 是什么 prototype 是函数的属性,是一个继承自 Object 的对象,默认的 prototype 只有一个属性,其中包含 constructor,指向当前函数自身。 Ctor.proto…...
css选择器
目录1、基本选择器(1)id选择器(2)类选择器(3)标签选择器(4)逗号选择器(5)*选择器(通配符选择器)2、包含选择器(1ÿ…...

聊聊我是怎么用Claude code来学习项目的吧
首先我和许多大学生一样我对项目这个的概念理解为零,但是我比较喜欢研究ai,我喜欢用ai去帮我写一些小项目啊,小游戏啊,还有一些脚本,像一些国外的cursor,国内的treat,还有Claude code我基本都玩…...

cvx小白入门
一、cvx是什么? 是一个解决优化问题的Matlab工具箱,通常用于解决凸优化问题,提供了一种简洁的方式来定义和求解优化模型。 二、cvx怎么安装? 我是首先安装的cvx,在官网下载cvx-w64.zip包,然后解压缩。我…...

ARM Cortex-R7低功耗架构设计与动态RAM保留技术
1. ARM Cortex-R7低功耗架构设计精要 在嵌入式实时系统中,功耗优化始终是工程师面临的核心挑战。ARM Cortex-R7 MPCore处理器通过创新的动态RAM保留技术,为工业控制、汽车电子等实时应用场景提供了高性能与低功耗的完美平衡方案。这套机制的精妙之处在于…...

CANN/asc-devkit Query API文档
Query 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...

AI编码助手经验治理:ExperienceEngine解决重复错误与智能进化
1. 项目概述:为编码智能体引入“经验治理层”如果你和我一样,长期使用像 Claude Code、Cursor 或 OpenClaw 这类 AI 编码助手,肯定会遇到一个让人头疼的问题:同一个项目里,AI 助手会反复犯下几乎一模一样的错误。比如&…...

显色指数 Ra、R9 数值原理:武汉家用照明色彩还原工程解析
在家装照明设计中,很多业主选灯只关注瓦数、色温,却忽略了显色指数这一核心工程参数。同一套家具、墙面、软装,在不同灯具照射下色彩差异巨大,出现发灰、偏色、质感廉价等问题,核心原因就是光源显色指数不达标。本文结…...

3个核心功能深度解析:Recaf字节码搜索的技术实践
3个核心功能深度解析:Recaf字节码搜索的技术实践 【免费下载链接】Recaf The modern Java bytecode editor 项目地址: https://gitcode.com/gh_mirrors/re/Recaf Recaf是一款现代化的Java字节码编辑器,专为逆向工程和代码分析设计。作为一款功能强…...

开源营销技能图谱:构建个人与团队的数字化能力体系
1. 项目概述:一个营销人的开源技能库如果你在营销行业摸爬滚打过几年,大概率会和我有一样的感受:这个领域变化太快了。今天还在研究信息流广告的OCPM出价,明天可能就要琢磨AIGC内容生成;刚把SEO的站内优化搞明白&#…...

网盘直链下载助手终极指南:三步解锁八大网盘高速下载
网盘直链下载助手终极指南:三步解锁八大网盘高速下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

终极Word转LaTeX神器:5分钟搞定专业文档格式转换
终极Word转LaTeX神器:5分钟搞定专业文档格式转换 【免费下载链接】docx2tex Converts Microsoft Word docx to LaTeX 项目地址: https://gitcode.com/gh_mirrors/do/docx2tex 还在为Word文档转换为LaTeX格式而烦恼吗?每次手动调整公式、表格和图片…...