构建自己的ChatGPT:从零开始构建个性化语言模型

🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁
🦄 个人主页——libin9iOak的博客🎐
🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺
🌊 《IDEA开发秘籍》学会IDEA常用操作,工作效率翻倍~💐
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
文章目录
- 构建自己的ChatGPT:从零开始构建个性化语言模型
- 摘要:
- 1. 引言
- 2. 了解ChatGPT和自然语言处理基础
- 3. 构建ChatGPT之前的准备
- 4. 数据收集和预处理
- 5. 搭建ChatGPT模型
- 5.1. Transformer架构简介
- 5.2. 自注意力机制
- 5. 3. 编码器-解码器结构
- 5.4. 模型细节
- a. 词嵌入层
- b. 位置编码
- c. 多层编码器
- d. 解码器
- 5.5. 模型训练
- 5.6. 模型生成
- 6. 模型训练与优化
- 6.1. 学习率调整
- 6.2. 梯度裁剪
- 6.3. 批量归一化
- 6.4. Dropout
- 6.5. 预训练模型微调
- 6.6. 模型评估与调参
- 6.7. 并行化训练
- 7. 测试和评估
- 7.1. 自动评估指标
- a. BLEU(Bilingual Evaluation Understudy)
- b. Perplexity
- 7.2. 人工评估
- 7.3. 对比实验
- 7.4. 数据集划分
- 7.5. 模型选择和调优
- 8. 个性化语言模型的应用
- 9. 面临的挑战与解决方案
- 9.1. 过拟合
- 9.2. 梯度消失和梯度爆炸
- 9.3. 训练时间和资源
- 9.4. 数据质量和多样性
- 10. 未来展望
- 11. 结论
- 12. 参考文献
- 原创声明

构建自己的ChatGPT:从零开始构建个性化语言模型
摘要:
在本篇博客中,我们将探讨如何构建自己的ChatGPT(Generative Pre-trained Transformer),这是一种个性化语言模型,能够自动生成人类类似的文本内容。我们将逐步介绍了解ChatGPT和自然语言处理基础、构建ChatGPT之前的准备、数据收集和预处理、搭建ChatGPT模型、模型训练与优化、测试和评估、以及个性化语言模型的应用。同时,我们还将深入讨论面临的挑战,并提供相应的解决方案。最后,我们将展望个性化语言模型的未来发展方向。
1. 引言
自然语言处理(NLP)技术近年来取得了长足的进步,其中基于深度学习的语言模型成为了研究的热点。ChatGPT作为近年来最受欢迎的语言模型之一,能够生成连贯的文本,甚至可以与用户进行实时对话。在这篇博客中,我们将一步步指导您如何构建自己的个性化ChatGPT语言模型,为您的项目或应用增添更多的魅力。
2. 了解ChatGPT和自然语言处理基础
在本节中,我们将深入了解ChatGPT的基本概念、原理和工作机制。ChatGPT是OpenAI推出的基于Transformer架构的预训练语言模型。它通过大规模的无监督学习从海量文本数据中学习到语言的结构和规律,从而具备了生成自然语言文本的能力。理解ChatGPT的原理将为我们构建个性化语言模型奠定坚实基础。同时,我们还将回顾一些自然语言处理的基础知识,包括词嵌入、序列模型等,以便更好地理解ChatGPT的构建过程。
3. 构建ChatGPT之前的准备
在开始构建ChatGPT之前,我们需要明确项目的目标和所需资源。首先,我们需要明确希望我们的ChatGPT能够达到怎样的效果和应用场景。其次,我们需要准备一台性能足够强大的计算机或使用云计算资源,因为训练大规模语言模型需要大量的计算资源和时间。同时,我们需要安装Python环境和相应的深度学习库,如TensorFlow或PyTorch,以及Hugging Face等库,这些库将大大简化我们构建ChatGPT的过程。
4. 数据收集和预处理
数据是训练语言模型的关键,良好的数据集将对模型性能产生巨大影响。在这一部分,我们将介绍如何收集适用于您个性化ChatGPT模型的数据,并进行必要的数据预处理。数据预处理包括文本清洗、分词、编码等过程,以及将数据划分为训练集、验证集和测试集等步骤,确保数据的质量和可用性。
5. 搭建ChatGPT模型
在这一章节中,我们将从头开始搭建ChatGPT模型。我们将介绍Transformer架构的基本原理,并解释其在生成文本方面的优势。随后,我们将逐步构建模型的各个组件,包括自注意力机制、编码器-解码器结构等,确保模型能够正确地生成文本。
在本章节中,我们将详细介绍如何从头开始搭建ChatGPT模型,该模型将基于Transformer架构,并利用自注意力机制和编码器-解码器结构来实现文本生成功能。下面是具体的步骤:
5.1. Transformer架构简介
Transformer是一种基于注意力机制的神经网络架构,由Vaswani等人于2017年提出,并在自然语言处理任务中取得了重大突破。Transformer摒弃了传统的循环神经网络(RNN)结构,采用了自注意力机制,使得模型能够并行处理输入序列,从而显著提高了计算效率。
5.2. 自注意力机制
自注意力机制是Transformer的核心组件之一。它允许模型在处理输入序列时,能够根据输入序列中的其他元素自适应地给予不同的注意权重。自注意力机制通过计算注意力分数来实现这一功能,然后将注意力分数与输入序列进行加权求和,得到每个位置的表示。
5. 3. 编码器-解码器结构
在构建ChatGPT模型时,我们需要同时考虑到输入序列(文本的历史信息)和输出序列(即将生成的文本)。为此,我们使用了编码器-解码器结构。编码器负责处理输入序列,将其转换为一系列高维表示;而解码器则利用这些高维表示,结合自注意力机制,生成目标序列,即我们希望模型生成的文本。
5.4. 模型细节
接下来,我们将逐步搭建ChatGPT模型的具体细节:
a. 词嵌入层
我们首先引入词嵌入层,将输入的文本转换为向量表示。词嵌入层将每个词转换为高维向量,使得模型能够更好地理解词汇之间的语义关系。
b. 位置编码
由于Transformer没有像RNN那样的顺序信息,我们需要引入位置编码来告知模型输入序列中每个单词的位置信息。位置编码的添加使得模型能够理解输入序列的顺序。
c. 多层编码器
在ChatGPT模型中,我们通常使用多层编码器来对输入序列进行处理。每一层编码器都包含自注意力机制和前馈神经网络,使得模型能够在不同抽象层次上理解输入序列的信息。
d. 解码器
在解码器中,我们将使用类似的多层结构来生成目标序列,即我们希望模型生成的文本。解码器通过注意编码器的输出和自注意力机制来逐步生成文本,直到完成整个序列的生成。
5.5. 模型训练
构建好ChatGPT模型后,我们将使用数据集进行模型训练。训练的目标是最小化模型生成文本与实际目标文本之间的差距,通常使用最大似然估计(MLE)作为训练目标。我们会使用一些优化算法,如Adam,来调整模型的参数,从而使得模型能够更好地生成符合预期的文本。
5.6. 模型生成
经过训练后,我们的ChatGPT模型就可以用来生成文本了。在生成时,我们会将一个初始的输入文本传入模型,然后利用解码器逐步生成后续的文本。为了增加生成的多样性,我们可以采用一些采样策略,如贪婪采样、束搜索等。
通过以上步骤,我们将成功搭建一个基本的ChatGPT模型,并使其能够生成个性化的文本内容。在实际应用中,我们可以根据具体需求对模型进行调优和改进,以获得更好的效果和用户体验。
6. 模型训练与优化
模型的训练和优化是确保ChatGPT性能良好的关键步骤。我们将详细讨论训练过程中的注意事项,如学习率调整、梯度裁剪等,以及一些优化技巧,如批量归一化、Dropout等,以提高模型的生成能力和效率。同时,我们还将介绍如何利用预训练模型进行微调,以便更好地适应特定任务或领域。
在模型训练与优化阶段,我们需要关注一系列重要的注意事项和优化技巧,以确保ChatGPT模型具有较好的性能和生成能力。下面是我们将要详细讨论的内容:
6.1. 学习率调整
学习率是控制模型参数更新步长的重要超参数。过大的学习率可能导致训练过程不稳定,而过小的学习率会使得模型训练过慢。在模型训练过程中,我们通常采用学习率衰减或动态调整的方法,逐渐降低学习率,使得模型在训练初期能够快速学习,而在训练后期逐渐稳定。
6.2. 梯度裁剪
梯度裁剪是一种防止梯度爆炸问题的技巧。在深度学习中,由于反向传播时梯度可能会非常大,导致模型权重更新过于剧烈。梯度裁剪通过限制梯度的大小,使得梯度不会超过一定阈值,从而稳定训练过程。
6.3. 批量归一化
批量归一化(Batch Normalization)是一种用于加速训练过程和稳定模型的技术。它通过在每个小批量数据上对输入进行归一化,使得模型在训练过程中更容易收敛。批量归一化还有助于防止梯度消失问题,并允许使用更大的学习率。
6.4. Dropout
Dropout是一种用于防止过拟合的正则化技术。它在训练过程中随机丢弃一部分神经元,使得模型在不同神经元组合上进行训练,减少神经元之间的依赖关系。这样可以提高模型的泛化能力,防止过拟合。
6.5. 预训练模型微调
如果有预训练的语言模型,如GPT-2或BERT,我们可以利用这些模型进行微调,以便更好地适应特定任务或领域。预训练模型通常在大规模数据上进行了预训练,具有丰富的语言知识。通过微调,我们可以在较少的训练数据上快速提高模型性能。
6.6. 模型评估与调参
在训练过程中,我们需要定期评估模型在验证集上的性能。通过监控模型在验证集上的表现,我们可以选择最佳的模型进行保存,避免过拟合。同时,我们还需要对模型的超参数进行调优,如学习率、批量大小等,以找到最优的组合。
6.7. 并行化训练
为了加快训练速度,我们可以采用并行化训练的方法。将模型训练过程拆分为多个计算节点并行进行,利用多台机器或GPU进行分布式训练,从而减少训练时间。
通过以上训练和优化技巧,我们可以有效地提高ChatGPT模型的性能和生成能力。同时,利用预训练模型进行微调,可以使得模型更加适应特定任务或领域,提高模型的应用价值。在训练和优化过程中,持续的实验和调整将有助于找到最佳的模型和超参数组合。
7. 测试和评估
在这一部分,我们将介绍如何对构建的ChatGPT模型进行测试和评估。我们将使用一系列标准评估指标,如BLEU、Perplexity等,来评估模型的性能,并确保其在各项指标上达到预期要求。同时,我们将进行人工评估,以获得对模型生成文本质量的直观感受。
在测试和评估ChatGPT模型的过程中,我们将采用多种方法来验证模型的性能和生成文本的质量。以下是我们将采取的评估步骤:
7.1. 自动评估指标
a. BLEU(Bilingual Evaluation Understudy)
BLEU是一种常用的自动评估指标,用于衡量模型生成的文本与参考文本之间的相似性。它通过比较n-gram重叠来计算文本之间的匹配程度。较高的BLEU分数表示模型生成的文本更接近参考文本,从而表明模型性能较好。
b. Perplexity
Perplexity是一种衡量语言模型预测能力的指标。在ChatGPT中,我们可以使用Perplexity来衡量模型生成文本的流畅程度和一致性。较低的Perplexity值意味着模型能够更好地预测下一个词,从而生成更连贯的文本。
7.2. 人工评估
自动评估指标虽然能够提供一定程度上的衡量,但仍难以完全反映模型生成文本的质量。因此,我们需要进行人工评估来获得对模型生成文本质量的直观感受。在人工评估中,我们会邀请一些评估者阅读并评价模型生成的文本,从而得到更全面和准确的评估结果。
7.3. 对比实验
为了更好地验证模型性能,我们还可以进行对比实验。我们可以将构建的ChatGPT模型与其他类似的语言模型进行比较,包括传统的n-gram语言模型和其他基于深度学习的语言模型。通过对比实验,我们可以更好地了解ChatGPT模型的优势和不足之处。
7.4. 数据集划分
在进行测试和评估时,我们需要将数据集划分为训练集、验证集和测试集。训练集用于模型的训练,验证集用于调整模型的超参数和防止过拟合,而测试集用于最终评估模型的性能。划分数据集的过程需要保证数据的随机性和一致性,以确保评估结果的准确性。
7.5. 模型选择和调优
根据测试和评估的结果,我们可以选择最佳的模型,或者对模型进行调优。调优的过程可以包括调整模型的超参数,增加训练数据的规模,或者采用更复杂的模型结构。通过不断地优化模型,我们可以使得ChatGPT模型生成的文本更加符合预期要求。
通过以上测试和评估步骤,我们可以全面地了解ChatGPT模型的性能,并对其生成的文本质量进行准确的评估。这将有助于我们进一步改进模型,提高其生成文本的质量和可用性。同时,评估结果也将指导我们在实际应用中合理地使用ChatGPT模型,以满足不同场景下的需求。
8. 个性化语言模型的应用
除了生成文本,个性化语言模型还有许多有趣的应用。在这一章节中,我们将探讨ChatGPT在对话系统、内容创作、智能助手等领域的实际应用,并展示其在提高用户体验、推动商业发展等方面的潜在价值。同时,我们还将展示如何通过调整模型参数和输入文本来实现个性化的生成结果。
9. 面临的挑战与解决方案
构建个性化语言模型并不是一帆风顺的,我们将面临各种挑战。在这一部分,我们将讨论可能遇到的问题,如过拟合、梯度消失等,以及提供相应的解决方案,帮助您克服困难并优化模型的性能。
在构建个性化语言模型的过程中,确实会遇到一些挑战,这些挑战可能会影响模型的性能和效果。以下是一些常见的挑战以及相应的解决方案:
9.1. 过拟合
过拟合是指模型在训练集上表现很好,但在新的未见过的数据上表现较差。这是因为模型过于复杂或训练数据过少,导致模型记住了训练集的噪声而不是学习到普遍规律。
解决方案:为了克服过拟合,我们可以采取以下措施:
- 增加训练数据量:更多的数据有助于模型学习更多的通用规律,减少过拟合的可能性。
- 数据增强:通过对训练数据进行旋转、平移、缩放等操作,生成更多的数据样本,增加数据的多样性。
- 正则化:引入L1或L2正则化惩罚项,限制模型权重的大小,防止模型过度拟合。
- Dropout:在训练过程中随机丢弃一部分神经元,使得模型在不同神经元组合上进行训练,减少过拟合。
9.2. 梯度消失和梯度爆炸
在深度学习中,特别是在RNN和一些较深的神经网络中,梯度消失和梯度爆炸是常见的问题。梯度消失指的是在反向传播过程中,梯度逐层递减,导致较早层的权重更新非常缓慢。梯度爆炸指的是梯度逐层递增,导致较早层的权重更新过快,导致不稳定的训练过程。
解决方案:解决梯度消失和梯度爆炸问题的方法有以下几种:
- 使用激活函数:合理选择激活函数可以缓解梯度消失问题。ReLU、Leaky ReLU和ELU等激活函数都有一定的抑制梯度消失的能力。
- 权重初始化:合理初始化权重可以避免梯度爆炸问题。使用较小的初始化权重,如Xavier初始化或He初始化。
- 梯度裁剪:限制梯度的大小,防止梯度爆炸。
- LSTM和GRU:使用长短期记忆网络(LSTM)或门控循环单元(GRU)等特殊的循环神经网络结构,可以减少梯度消失问题。
9.3. 训练时间和资源
构建个性化语言模型通常需要大量的训练时间和计算资源,特别是对于较大的模型和大规模的数据集。这可能成为一个挑战,特别是对于个人或资源有限的团队。
解决方案:为了解决训练时间和资源问题,可以采取以下措施:
- 选择适当规模的模型:根据资源情况,选择适当规模的模型,权衡模型性能和训练时间。
- 使用分布式训练:将训练过程拆分为多个计算节点并行进行,利用多台机器或GPU进行分布式训练,缩短训练时间。
- 使用预训练模型:如果有适用于自己任务的预训练模型,可以使用预训练模型进行微调,减少训练时间和资源消耗。
9.4. 数据质量和多样性
构建个性化语言模型需要高质量的数据集,以及涵盖多样化的文本内容,以确保模型具有广泛的应用能力。然而,获取高质量和多样性的数据并不容易。
解决方案:为了保证数据质量和多样性,可以考虑以下方法:
- 数据清洗:对数据进行必要的清洗和去噪,确保数据质量。
- 数据增强:通过数据增强技术生成更多的数据样本,增加数据的多样性。
- 引入领域知识:利用领域专家的知识来筛选和收集具有代表性的数据。
通过解决上述挑战,并采取相应的解决方案,我们可以优化个性化语言模型的性能,使其更加适用于不同的任务和应用场景。
10. 未来展望
随着人工智能技术的不断发展,个性化语言模型的未来充满了无限可能。在这一章节中,我们将展望个性化语言模型的未来发展方向,并探讨可能的研究方向和应用场景。我们相信,个性化语言模型将在各个领域发挥更加重要和广泛的作用。
11. 结论
通过本篇博客的学习,您应该对构建个性化ChatGPT语言模型有了全面的了解。个性化语言模型作为一种强大的自然语言处理技术,将为您的项目和应用带来更加出色的效果和用户体验。不过,构建个性化语言模型仍然是一个复杂而充满挑战的任务,需要不断地学习和改进。希望本文能为您在个性化语言模型的构建和应用方面提供帮助。
12. 参考文献
- Vaswani, A., et al. (2017). “Attention is All You Need.” In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017).
- Radford, A., et al. (2018). “Improving Language Understanding by Generative Pre-Training.” URL: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
- Devlin, J., et al. (2019). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019).
- Hugging Face Transformers Library: https://github.com/huggingface/transformers
原创声明
=======
作者wx: [ libin9iOak ]
本文为原创文章,版权归作者所有。未经许可,禁止转载、复制或引用。
作者保证信息真实可靠,但不对准确性和完整性承担责任。
未经许可,禁止商业用途。
如有疑问或建议,请联系作者。
感谢您的支持与尊重。
点击
下方名片,加入IT技术核心学习团队。一起探索科技的未来,共同成长。
相关文章:
构建自己的ChatGPT:从零开始构建个性化语言模型
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...
– 底层原理(二)之 迭代器 iterator)
【react】react18的学习(十二)– 底层原理(二)之 迭代器 iterator
迭代器iterator 是一种 ES6 规范,具有这种机制的数据结构才可以使用for of循环:返回每一项的值; 原型链具有Symbol.iterator属性的数据结构都具备;如数组、部分类数组、字符串等; 普通对象就不能用; for-…...
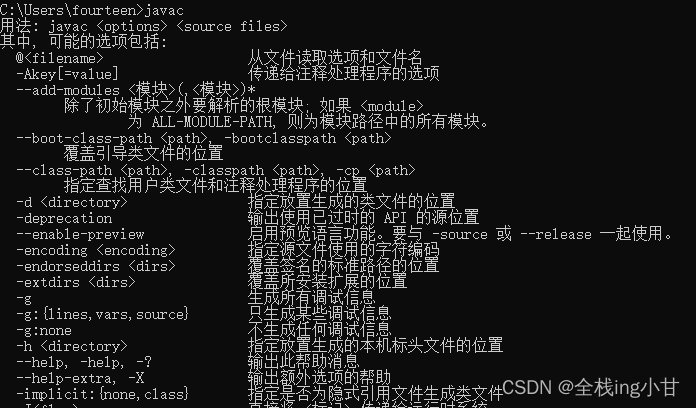
一遍过JavaSE基础知识
文章目录 前言安装Java Development Kit (JDK)安装jdk配置开发环境验证是否安装配置成功 编写第一个Java程序hello world运行Java程序的流程 数据类型和变量数据类型变量 程序逻辑控制条件语句循环语句跳转语句 数组声明和创建数组访问数组元素数组长度遍历数组多维数组 面向对…...

【云原生】Kubernetes之ConfigMap
ConfigMap ConfigMap 是一种 API 对象,用来将非机密性的数据保存到键值对中。使用时, Pods 可以将其用作环境变量、命令行参数或者存储卷中的配置文件 ConfigMap 将你的环境配置信息和 容器镜像 解耦,便于应用配置的修改 说明:…...
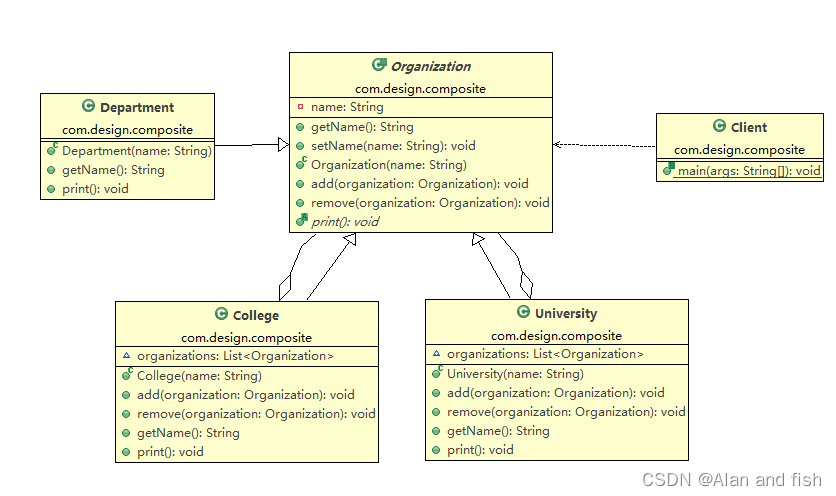
8.python设计模式【组合模式】
内容:将对象组合成树形结构以表示“部分-整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。角色: 抽象组建(component)叶子组建(Leaf)复合组建(Composite)客户端 (Client) UML 图 举个例子 需求…...

tkinter制作任意图形窗口
import tkinter from PIL import Image, ImageTkdog tkinter.Tk() # 设置图片描绘的坐标,注意乘号是字母x dog.geometry(500x500200100) # 不允许修改大小 dog.resizable(False, False) # 不显示标题栏 dog.overrideredirect(True) # 设置白色透明色,这…...

视频监控综合管理平台EasyCVR多分屏默认播放协议的配置优化
视频监控综合管理平台EasyCVR具备视频融合汇聚能力,TSINGSEE青犀视频平台基于云边端一体化架构,可支持多协议、多类型设备接入,包括:NVR、IPC、视频编码器、无人机、车载设备、智能手持终端、移动执法仪等。国标GB28181视频平台Ea…...

2023杭电多校第三场 1012.Noblesse Code
传送门:Vjudge 前题提要:一道挺有意思的数论题.赛时对于这道题没什么想法,但是赛后细品之后其实感觉也就那么一回事.但是这种 更相损减术与辗转相除法 相转化的题目还是有点典的,需要好好消化一下. 首先看完题目.我们需要考虑的是 ( A , B ) (A,B) (A,B)与 ( a , b ) (a,b) (…...

ubuntu qt 环境变量配置
ubuntu设置qt环境变量 qt 安装路径为:/home/ljn/Qt5.12 包含bin等目录的路经:/home/ljn/Qt5.14.2/5.14.2/gcc_64 环境变量配置 打开配置文件: sudo gedit /etc/profile在底部添加: export PATH"/home/ljn/Qt5.14.2/Tool…...
:功能实现)
按照Vue写WPF(0):功能实现
文章目录 前言VUE具有的功能如何专业到WPF上面 前言 我最近学了WPF之后我终于知道为什么WPF学习曲线那么陡峭了。因为WPF没有组件化的思想,或者说没有按照Vue一样去模板化开发。 为什么我推荐Vue的想法呢。因为Vue最大的特点就是模板化,让Vue工程师去写…...

vb+ACCESS教师管理系统设计设计与实现
--------------前言-------------- 教师管理系统是一个企事业单位不可缺少的部分,它的内容对于企事业单位的决策者和管理者来说都至关重要,所以教师管理系统应该能够为用户提供充足的信息和快捷的查询手段。但一直以来人们使用传统人工的方式管理文件信息,这种管理方式存在…...

C++笔记之对指针类型的变量进行+1操作
C笔记之对指针类型的变量进行1操作 在C中,对指针类型的变量进行"1"操作会根据指针的数据类型而有所不同。这涉及到指针的算术运算,C中的指针算术运算是根据指针所指向的数据类型的大小来进行的。 code review! 文章目录 C笔记之对指针类型的…...

第六章 游标
游标 本文内容较短,我们只是为了更容易的实现b树,简单地重构一下。 我们将添加一个Cursor 表示表中对象的位置。Cursor应提供如下几个方面的能力: 在表的开头创建游标在表的末尾创建游标访问游标指向的行将游标前进到下一行 这是本文我们…...
Github上方导航栏介绍
Code Watch:相当于关注,到时候这个项目又有什么操作,就会以通知的形式提醒你。 Fork:也就是把这个项目拉到你的仓库里,之后你可以对该代码进行修改,之后你可以发起Pull Request,简称PR…...
)
【vue3+ts】TypeError: Cannot read properties of undefined (reading ‘commit‘)
项目场景: <script lang"ts"> import { defineComponent, reactive, ref } from vue import { useStore } from vuex export default defineComponent({name: Login.vue,components: {},setup () {const onFormSubmit (result: boolean) > {if…...
seq2seq、attention、self-attention、transformer、bert
seq2seq seq2seq:输入序列,输出序列,将输入的语言转为一个向量,最后输出再将向量转为语言shortcoming:The final state is incapable of remembering a long sequence.即太长了记不住 attention 用attention可以改进seq2seq中的…...

07.计算机网络——数据链路层
文章目录 数据链路层以太网帧格式MAC地址理解MAC地址和IP地址认识MTUMTU对IP协议的影响MTU对UDP协议的影响MTU对于TCP协议的影响 ARP协议**ARP**协议的作用ARP协议的工作流程ARP数据报的格式 数据链路层 数据链路层在物理层提供的服务的基础上向网络层提供服务,…...

海外服务器推荐:国外高性能服务器免费
对于寻找高性能的海外服务器,海外服务器推荐指导,我建议您考虑以下因素: 1. 可靠性和性能:选择信誉良好、可靠性好的服务器提供商。它们应该有稳定的网络基础设施和高性能的服务器硬件来满足您的需求。 2. 位置选择:…...
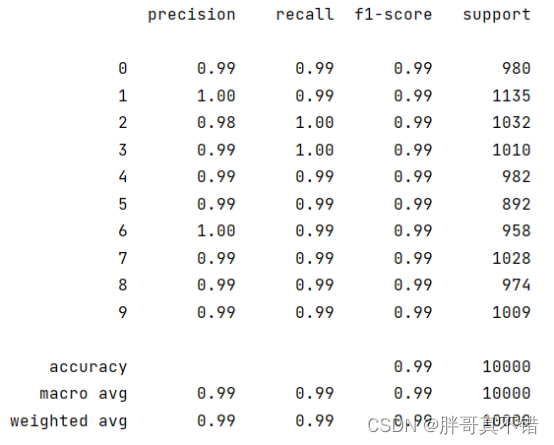
Python基于PyTorch实现卷积神经网络分类模型(CNN分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 卷积神经网络,简称为卷积网络,与普通神经网络的区别是它的卷积层内的神经元只覆…...
JMeter 配置环境变量步骤
通过给 JMeter 配置环境变量,可以快捷的打开 JMeter: 打开终端。执行 jmeter。 配置环境变量的方法如下。 Mac 和 Linux 系统 1、在 ~/.bashrc 中加如下内容: export JMETER_HOMEJMeter所在目录 export PATH$JAVA_HOME/bin:$PATH:.:$JME…...

空间多组学三大算法实战:从cell2location定位到Hotspot富集,一站式解析组织微环境
1. 空间多组学分析工作流概览 空间多组学技术正在彻底改变我们对组织微环境的理解方式。想象一下,你手里同时握有单细胞转录组数据和空间转录组数据,就像同时拥有了食材清单和菜谱,但如何把这些原材料变成一道美味佳肴?这就是我们…...

为什么你的STM32 DMA传输失败了?__HAL_LINKDMA宏的隐藏陷阱与解决方案
为什么你的STM32 DMA传输失败了?__HAL_LINKDMA宏的隐藏陷阱与解决方案 在STM32开发中,DMA(直接内存访问)传输是提升外设数据吞吐效率的关键技术。然而,许多开发者在实际项目中都会遇到DMA传输失败的问题,而…...

Tsuru平台安全加固终极指南:10个关键步骤保护你的PaaS环境
Tsuru平台安全加固终极指南:10个关键步骤保护你的PaaS环境 【免费下载链接】tsuru Open source and extensible Platform as a Service (PaaS). 项目地址: https://gitcode.com/gh_mirrors/ts/tsuru Tsuru是一款开源且可扩展的平台即服务(PaaS)解决方案&…...

【实测】GitNexus实测:拖入GitHub链接秒出代码知识图谱,今天涨了857星
腾讯10年程序员带你实测GitNexus——一款零服务器、纯浏览器端的代码知识图谱引擎,内置Graph RAG智能问答。今天GitHub Trending单日涨857星。 文章目录前言一、背景与痛点1.1 问题描述1.2 现有方案的不足二、GitNexus核心能力详解2.1 零服务器架构2.2 交互式知识图…...

利用快马平台快速搭建stm32f103c8t6最小系统板LED闪烁原型
最近在做一个嵌入式小项目,用到了经典的stm32f103c8t6最小系统板。作为嵌入式开发新手,最头疼的就是搭建开发环境和写各种初始化代码。不过这次尝试用InsCode(快马)平台后,整个过程顺畅多了,分享下我的经验。 项目背景 stm32f103c…...

行业内GEO优化服务哪家可靠
行业内可靠的GEO优化服务之选在当今数字化时代,随着用户搜索习惯从传统搜索引擎向生成式AI平台转型,企业面临着传统SEO/社媒营销失效、品牌曝光锐减等问题。GEO(生成式引擎优化)优化服务成为企业抢占AI搜索流量高地的关键。那么&a…...

用Go搞定微信扫码登录:一个后端接口+一个回调,附完整可运行代码
极简Go实现微信扫码登录:两个接口搞定全流程 每次看到新项目要接入微信登录就头疼?文档翻来覆去看不明白?其实用Go实现微信扫码登录,核心代码不超过200行。今天我们就用最粗暴的方式,把微信OAuth2.0登录简化为两个接口…...

新手友好:5步完成Llama3-8B对话系统的本地部署
新手友好:5步完成Llama3-8B对话系统的本地部署 1. 引言:为什么选择Llama3-8B? 如果你对AI对话模型感兴趣,想自己动手搭建一个,但又担心过程太复杂、电脑配置不够,那今天这篇文章就是为你准备的。 Meta-L…...

力扣第97题:多数元素
第一部分:问题描述 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入:nums = [3,2,3] 输出:3 示例 2: 输入:nums = [2,2,1,1,1…...

3大突破!网盘下载加速工具让你的文件获取效率倍增
3大突破!网盘下载加速工具让你的文件获取效率倍增 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...