爬取微博热搜榜并进行数据分析
设计方案
爬虫爬取的内容
:爬取微博热搜榜数据。
网络爬虫设计方案概述
用requests库访问页面用get方法获取页面资源,登录页面对页面HTML进行分析,用beautifulsoup库获取并提取自己所需要的信息。再讲数据保存到CSV文件中,进行数据清洗,数据可视化分析,绘制数据图表,并用最小二乘法进行拟合分析。
主题页面的结构特征分析
1.主题页面的结构与特征分析
:通过观察页面HTML源代码,可以发现每个热搜名称的标题都位于"td",class_='td-02’标签的子标签中,热度和排名则分布在"td",class_='td-03’和"td",class_='td-01’标签中,他们的关系是 class>a>span。按照标签的从属关系 可从标签中遍历出我们所需要的内容。
2.Htmls页面解析
通过页面定位分析发现这是标题所在标签位置,td",class_='td-02“的子标签a 中,我们可以通过find all 函数来提取我们所需要的标题信息

继续审查页面元素 发现热度和排名所在的标签位置,查到所需要的内容的标签位置后,就可以开始编写爬虫程序了


三、网络爬虫程序设计
1.数据爬取与采集
import requests
from bs4 import BeautifulSoup
import bs4
#定义函数第一步从网络上获取热搜排名网页内容
url = "https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
def getHTMLText(url):try:#设置表头信息kv={"User-Agent":"Mozilla/5.0"} r = requests.get(url, headers=kv, timeout=30) #请求时间30s# 解决乱码问题r.raise_for_status() r.encoding=r.apparent_encoding #修改编码方式return r.textexcept:return "" #若出现异常则会返回空字符串
#使用BeautifulSoup工具解析页面
html = getHTMLText(url)
soup=BeautifulSoup(html,'html.parser')
# 爬取热搜名字
sou = soup.find_all("td",class_='td-02')
#创立空列表 把热搜名字数据填入
name = []
for x in sou:name.append(x.a.string)
# 获取热度排名
# 同理创立空列表
paiming = []
top = soup.find_all('span')
for y in top:paiming.append(y.string)
#用字符串格式化输出数据
print('{:^40}'.format('微博热搜'))
print('{:^15}\t{:^25}\t{:^40}'.format('排名', '热搜内容', '热度'))
list = []
#输出数据的前20条
for i in range(21):print('{:^15}\t{:^25}\t{:^40}'.format(i+1, name[i], paiming[i]))list.append([i+1,name[i],paiming[i]])
#用pandas对数据进行储存,并生成文件
df= pd.DataFrame(list,columns = ['排名','热搜内容','热度'])
df.to_csv('resou.csv')

生成文件

2.对数据进行清洗和处理
读取文件
df = pd.DataFrame(pd.read_csv('resou.csv'))
#输出信息
print(df)

开始进行数据清洗
删除无效列与行
df.drop('热搜内容', axis=1, inplace = True)
df.head() #输出数据前五行

检查是否有重复值
df.duplicated()

检查是否有空值
print(df['热度'].isnull().value_counts())
#若有则删除缺失值
df[df.isnull().values==True]
df.corr()

将数据统计信息打印出来
df.describe()

3.数据分析与可视化
继续数据分析与可视化
构建线性回归预测模型
from sklearn.linear_model import LinearRegression
X = df.drop("热度", axis = 1)
predict_model = LinearRegression()
predict_model.fit(X, df['排名']) #训练模型
print("回归系数为:", predict_model.coef_) # 判断相关性

绘制散点图
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
import numpy as np
%matplotlib inline
排名 = (df["排名"])
热度 = (df["热度"])
plt.rcParams['font.sans-serif']=['SimHei'] #用于正常显示中文标签
plt.figure(figsize=(8,5))
plt.scatter(排名,热度,color=[0,0,1,0.4],label=u"样本数据",linewidth=2) #颜色用RGB值
plt.title("排名 scatter",color="blue")
plt.xlabel("排名")
plt.ylabel("热度")
plt.legend()
plt.grid()
plt.show()

回归散点图
import seaborn as sns
sns.regplot(df.排名,df.热度)
plt.title('排名热度回归散点图')

绘制柱状图
plt.figure()
x=np.arange(0,20)
y=df.loc['1':'20','热度'] #选取画图数据范围
plt.bar(x, y,color='c',alpha=0.5) #增加透明度 使图更加美观
plt.xlabel('排名')
plt.ylabel('热度')
plt.title("热搜数据")
plt.show()

绘制折线图
plt.figure()
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
x=np.arange(0,20)
y=df.loc['1':'20','热度'] #选取画图数据范围
plt.plot(x, y,'r-o',color='blue')
plt.xlabel('排名')
plt.ylabel('热度')
plt.title("热搜数据")
plt.show()

绘制盒图
def box():plt.title('热度与排名盒图')sns.boxplot(x='排名',y='热度', data=df)
box()

用Seaborn绘制各种分布图
import seaborn as sns
sns.jointplot(x="排名",y='热度',data = df, kind='kde', color='r')
sns.jointplot(x="排名",y='热度',data = df, kind='hex')
sns.distplot(df['热度'])

绘制单核密度图
sns.kdeplot(df['热度'])

绘制排名与热度的回归图
sns.regplot(df.排名,df.热度)

4…根据排名与热度数据之间的关系,分析两个变量拟合一元二次曲线,建立变量之间的回归方程
# 用最小二乘法得出一元二次拟合方程
import numpy as np
from numpy import genfromtxt
import scipy as sp
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
plt.figure(figsize=(13,6))
plt.scatter(排名,热度,color=[0,0,0.8,0.4],label=u"样本数据",linewidth=2)
plt.xlabel("排名")
plt.ylabel("热度")
plt.legend()
def func(p,x):a,b,c=preturn a*(x**2)+(b*x)+c
def er_func(p,x,y):return func(p,x)-y
p0=[2,3,4]
P=leastsq(er_func,p0,args=(排名,热度))
a,b,c=P[0]
x=np.linspace(0,55,100)
y=a*(x**2)+(b*x)+c
plt.plot(x,y,color=[0,0,0.8,0.4],label=u"拟合直线",linewidth=2)
plt.scatter(x,y,color="c",label=u"样本数据",linewidth=2)
plt.legend()
plt.title('排名热度回归曲线')
plt.grid()
plt.show()

5.完整程序代码
import requests
from bs4 import BeautifulSoup
import bs4
import pandas as pd #引入pandas用于数据可视化
from pandas import DataFrame
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
from sklearn.linear_model import LinearRegression
#定义函数第一步从网络上获取热搜排名网页内容
url = "https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
def getHTMLText(url):try:#设置表头信息kv={"User-Agent":"Mozilla/5.0"} r = requests.get(url, headers=kv, timeout=30) #请求时间30s# 解决乱码问题r.raise_for_status() r.encoding=r.apparent_encoding #修改编码方式return r.textexcept:return "" #若出现异常则会返回空字符串#使用BeautifulSoup工具解析页面
html = getHTMLText(url)
soup=BeautifulSoup(html,'html.parser')# 爬取热搜名字
sou = soup.find_all("td",class_='td-02')#创立空列表 把热搜名字数据填入
name = []
for x in sou:name.append(x.a.string)# 获取热度排名
# 同理创立空列表
paiming = []
top = soup.find_all('span')
for y in top:paiming.append(y.string)#用字符串格式化输出数据
print('{:^40}'.format('微博热搜'))
print('{:^15}\t{:^25}\t{:^40}'.format('排名', '热搜内容', '热度'))
list = []#输出数据的前20条
for i in range(21):print('{:^15}\t{:^25}\t{:^40}'.format(i+1, name[i], paiming[i]))list.append([i+1,name[i],paiming[i]])#用pandas对数据进行储存,并生成文件
df= pd.DataFrame(list,columns = ['排名','热搜内容','热度'])
df.to_csv('resou.csv')#读取文件
df = pd.DataFrame(pd.read_csv('resou.csv'))
#输出信息
print(df)#开始进行数据清洗
#删除无效列与行
df.drop('热搜内容', axis=1, inplace = True)
df.head() #输出数据前五行#检查是否有重复值
df.duplicated() #检查是否有空值
print(df['热度'].isnull().value_counts())
#若有则删除缺失值
df[df.isnull().values==True]
df.corr()# 将数据统计信息打印出来
df.describe()#进行数据分析与可视化
X = df.drop("热度", axis = 1)
predict_model = LinearRegression()
predict_model.fit(X, df['排名']) #训练模型
print("回归系数为:", predict_model.coef_) # 判断相关性#绘制散点图
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
import numpy as np
%matplotlib inline
排名 = (df["排名"])
热度 = (df["热度"])
plt.rcParams['font.sans-serif']=['SimHei'] #用于正常显示中文标签
plt.figure(figsize=(8,5))
plt.scatter(排名,热度,color=[0,0,1,0.4],label=u"样本数据",linewidth=2) #颜色用RGB值
plt.title("排名 scatter",color="blue")
plt.xlabel("排名")
plt.ylabel("热度")
plt.legend()
plt.grid()
plt.show()#回归散点图
import seaborn as sns
sns.regplot(df.排名,df.热度)
plt.title('排名热度回归散点图')#绘制柱状图
plt.figure()
x=np.arange(0,20)
y=df.loc['1':'20','热度'] #选取画图数据范围
plt.bar(x, y,color='c',alpha=0.5) #增加透明度 使图更加美观
plt.xlabel('排名')
plt.ylabel('热度')
plt.title("热搜数据")
plt.show()# 绘制折线图
plt.figure()
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
x=np.arange(0,20)
y=df.loc['1':'20','热度'] #选取画图数据范围
plt.plot(x, y,'r-o',color='blue')
plt.xlabel('排名')
plt.ylabel('热度')
plt.title("热搜数据")
plt.show()#绘制盒图
def box():plt.title('热度与排名盒图')sns.boxplot(x='排名',y='热度', data=df)
box()#用Seaborn绘制各种分布图
sns.jointplot(x="排名",y='热度',data = df, kind='kde', color='r')
sns.jointplot(x="排名",y='热度',data = df, kind='hex')
sns.distplot(df['热度'])# 绘制单核密度图
sns.kdeplot(df['热度'])#绘制排名与热度的回归图
sns.regplot(df.排名,df.热度)# 用最小二乘法得出一元二次拟合方程
plt.figure(figsize=(13,6))
plt.scatter(排名,热度,color=[0,0,0.8,0.4],label=u"样本数据",linewidth=2)
plt.xlabel("排名")
plt.ylabel("热度")
plt.legend()
def func(p,x):a,b,c=preturn a*(x**2)+(b*x)+c
def er_func(p,x,y):return func(p,x)-y
p0=[2,3,4]
P=leastsq(er_func,p0,args=(排名,热度))
a,b,c=P[0]
x=np.linspace(0,55,100)
y=a*(x**2)+(b*x)+c
plt.plot(x,y,color=[0,0,0.8,0.4],label=u"拟合直线",linewidth=2)
plt.scatter(x,y,color="c",label=u"样本数据",linewidth=2)
plt.legend()
plt.title('排名热度回归曲线')
plt.grid()
plt.show()
四、结论
1.通过对热搜主题的数据分析与可视化的回归曲线可以看出 热度和排名是成正相关的,数据的可视化与图表可以清晰明了的将数据的关系体现出来,让我们直观的了解热度和排名的变化。
2.此次程序设计对于我来还是有难度的,初期对HTML页面的不熟悉,我不断的去查阅资料和视频一次次的去解决,通过这次设计我了解学习了BeautifulSoup库的使用,BeautifulSoup库在用于HTML解析和提取相关信息方面是非常厉害的,BeautifulSoup库的学习对以后的爬虫设计上很有帮助
相关文章:
爬取微博热搜榜并进行数据分析
设计方案 爬虫爬取的内容 :爬取微博热搜榜数据。 网络爬虫设计方案概述 用requests库访问页面用get方法获取页面资源,登录页面对页面HTML进行分析,用beautifulsoup库获取并提取自己所需要的信息。再讲数据保存到CSV文件中,进行…...
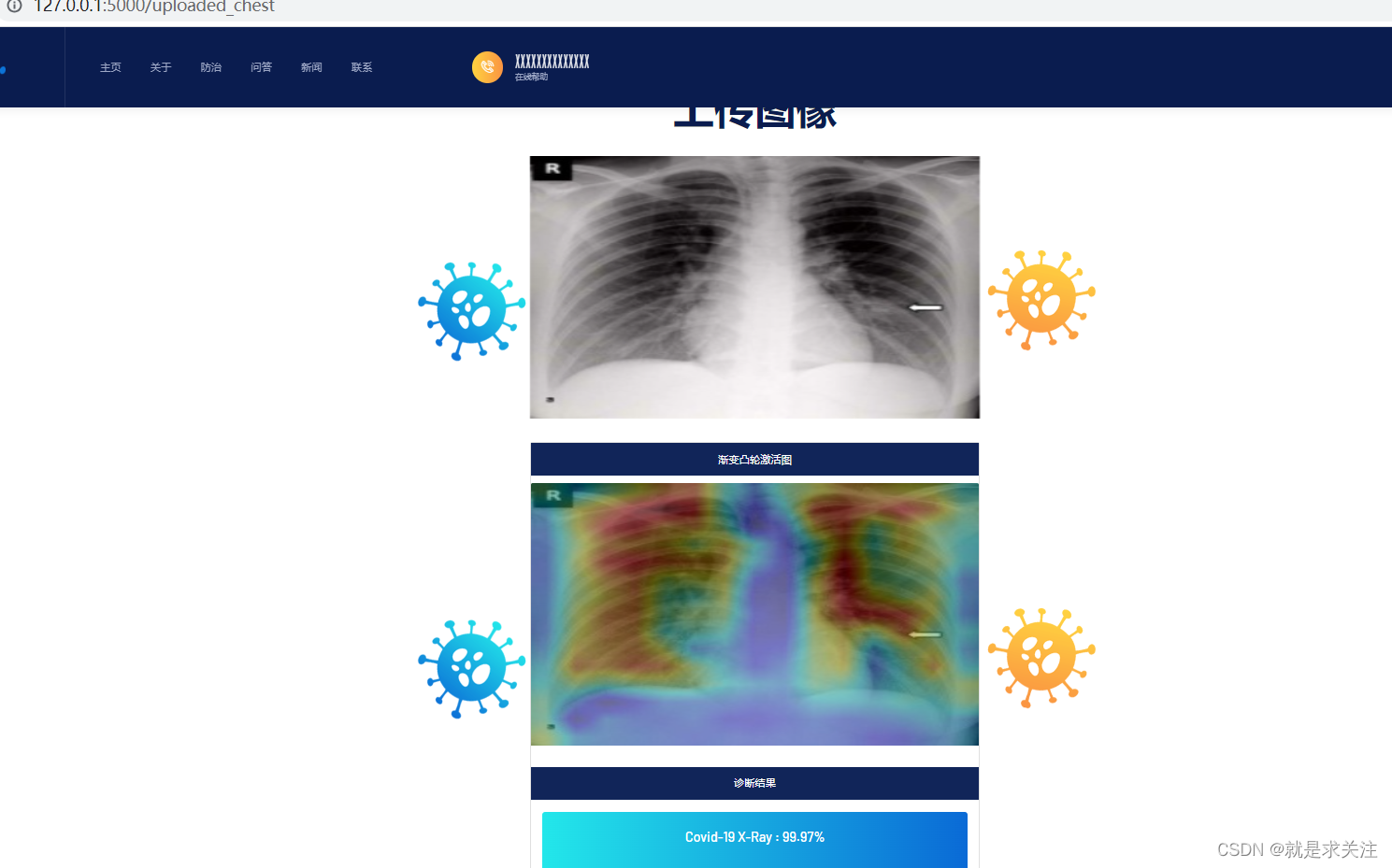
基于深度神经网络的肺炎检测系统实现
一、说在前面 使用AI进行新冠肺炎图像诊断可以加快病例的诊断速度,提高诊断的准确性,并在大规模筛查中发挥重要作用,从而更好地控制和管理这一流行病。然而,需要强调的是,AI技术仅作为辅助手段,最终的诊断决…...

C# LINQ和Lambda表达式对照
C# LINQ和Lambda表达式对照 1. 基本查询语句 Linq语法: var datafrom a in db.Areas select a ; Lamda语法: var datadb.Areas; sql语法: SELECT * FROM Areas2. 简单的WHERE语句 Linq语法: var datafrom a in db.orderI…...
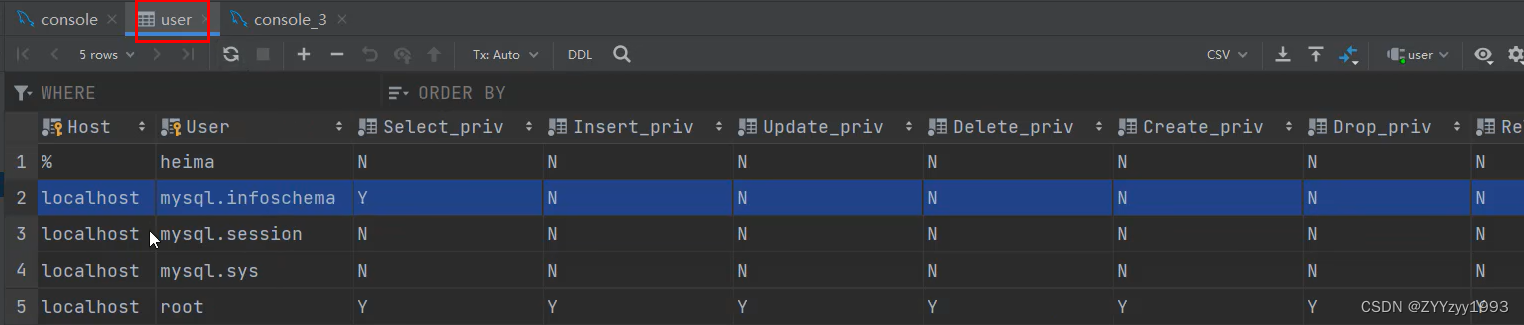
二、SQL-6.DCL-1).用户管理
一、DCL介绍 Data Control Language 数据控制语言 用来管理数据库 用户、控制数据库的 访问权限。 二、语法 1、管理用户 管理用户在系统数据库mysql中的user表中创建、删除一个用户,需要Host(主机名)和User(用户名࿰…...

ElasticSearch学习--数据聚合
介绍 数据聚合可以帮助我们对海量的数据进行统计分析,如果结合kibana,我们还能形成可视化的图形报表。自动补全可以根据用户输入的部分关键字去自动补全和提示。数据同步可以帮助我们解决es和mysql的数据一致性问题。集群可以帮助我们了解结构和不同节点…...
PostMan+Jmeter工具介绍及安装
目录 一、PostMan介绍编辑 二、下载安装 三、Postman与Jmeter的区别 一、开发语言区别: 二、使用范围区别: 三、使用区别: 四、Jmeter安装 附一个详细的Jmeter按照新手使用教程,感谢作者,亲测有效。 五、Jme…...
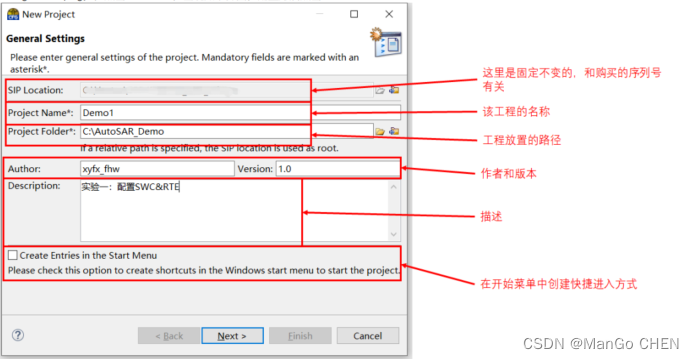
AutoSAR系列讲解(实践篇)7.4-实验:配置SWCRTE
注意: 实验篇是重点,有条件的同学最好跟着做一遍,然后回头对照着7.1-7.3理解其配置的目的和意义。实验下篇将在7.7节中继续做 一、实验概览 1、实验目的 通过本次实验,主要是让大家对Dev的配置有一个全流程的学习。这里会用到前两节的内容,将其串联起来,让大家能完整的…...

腾讯云内存型CVM服务器MA3、M6、M6ce和M5处理器CPU说明
腾讯云内存型CVM服务器CPU处理器大全,CVM内存型MA3、内存型M6、安全增强内存型M6ce、内存型M6p、内存型M5、MA2、M4、M3、M2、M1处理器主频、CPU性能性能大全说明,腾讯云内存型云服务器具有大内存的特点,适合高性能数据库、分布式内存缓存等需…...

集睿致远推出CS5466多功能拓展坞方案:支持DP1.4、HDMI2.1视频8K输出
ASL新推出的 CS5466是一款Type-C/DP1.4转HDMI2.1的显示协议转换芯片,,它通过类型C/显示端口链路接收视频和音 频流,并转换为支持TMDS或FRL输出信令。DP接收器支持81.Gbp s链路速率。HDMI输出端口可以作为TMDS或FRL发射机工作。FRL发射机符合HDMI 2.1规范…...
SQL中为何时常见到 where 1=1?
你是否曾在 SELECT 查询中看到过 WHERE 11 条件。我在许多不同的查询和许多 SQL 引擎中都有看过。这条件显然意味着 WHERE TRUE,所以它只是返回与没有 WHERE 子句时相同的查询结果。此外,由于查询优化器几乎肯定会删除它,因此对查询执行时间没…...

React AntDesign表批量操作时的selectedRowKeys回显选中
不知道大家是不是在AntDesign的某一个列表想要做一个批量导出或者操作的时候,发现只要选择下一页,即使选中的ids 都有记录下面,但是就是不回显 后来问了chatGPT,对方的回答是: 在Ant Design的DataTable组件中…...

anydesk远程控制,主动连接。
目标 远程控制目标电脑,且无需对方同意,并且可以控制目标电脑开关机。 实现 目标电脑和己方电脑均安装anydesk。目标电脑取消开机密码。打开目标电脑的anydesk在设置安全设置中打开为自主访问设置密码。 额外设置 为了让笔记本电脑合盖后仍能被控制…...
Spring Data Redis操作Redis
在Spring Boot项目中,可以使用Spring Data Redis来简化Redis操作,maven的依赖坐标: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></…...
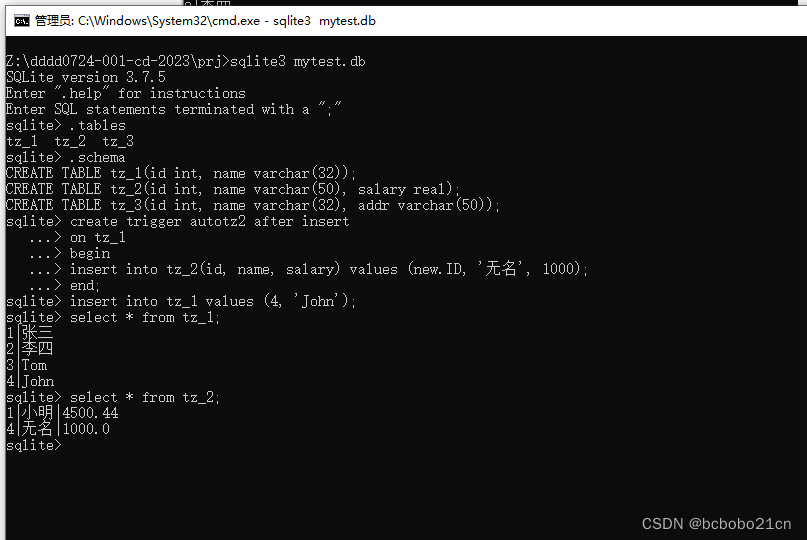
sqlite触发器1
SQLite 的触发器(Trigger)可以指定在特定的数据库表发生 DELETE、INSERT 或 UPDATE 时触发,或在一个或多个指定表的列发生更新时触发。 SQLite 只支持 FOR EACH ROW 触发器(Trigger),没有 FOR EACH STATEM…...

python中——requests爬虫【中文乱码】的3种解决方法
requests是一个较为简单易用的HTTP请求库,是python中编写爬虫程序最基础常用的一个库。 而【中文乱码】问题,是最常遇到的问题,对于初学者来说,是很困恼的。 本文将详细说明,python中使用requests库编写爬虫程序时&…...
)
E. Nastya and Potions(DFS+记忆化搜索)
炼金术士纳斯蒂亚喜欢混合药剂。一共有n种药剂,ci硬币可以买到一种 i 型药剂。 任何一种药剂都只能通过一种方式获得,即混合其他几种药剂。混合过程中使用的药剂将被消耗掉。此外,任何药剂都不能通过一个或多个混合过程从自身获得。 作为一名…...

什么是tcp rst以及什么时候产生?
rst包是仅在header control bits设置rst的空payload包,用于强制关闭tcp连接。常在以下场景发送 远程主机没有监听该端口 远程主机强迫关闭了一个现有连接。比如服务端进程崩溃后重启会向之前连接发送rst 相比于四次挥手的fin,rst是在异常情况下的无条…...
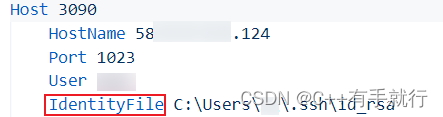
Visual Studio Code配置免密远程开发环境
VSCode安装插件 要是想连接远程服务器,先在本地安装下面的插件(红色圈起来的需要装) 连接远程服务器 配置服务器信息 保存然后再连接,输入密码,如果能连接上说明是没问题的,下面开始免密登录 免密配置 客…...
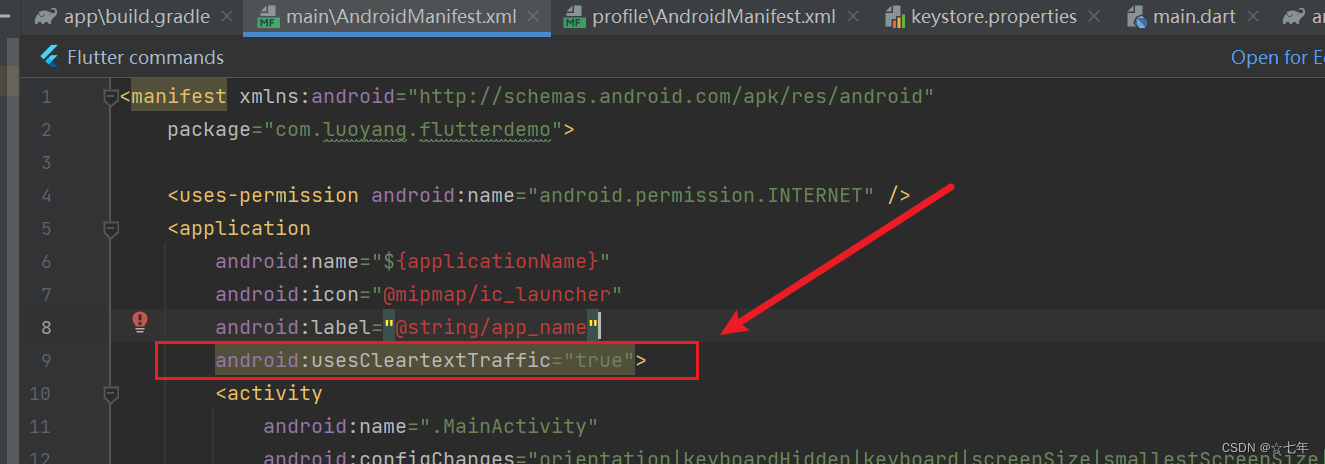
flutter android Webview 打开网页错误ERR_CLEARTEXT_NOT_PERMITTED 、 net:ERR_CACHE_MISS
当你在Flutter应用中尝试打开一个非安全连接的网页(例如HTTP连接而不是HTTPS连接)时,可能会遇到"ERR_CLEARTEXT_NOT_PERMITTED"错误。这是因为默认情况下,Android 9及更高版本禁止应用程序通过非安全的明文HTTP连接进行…...

ARP协议(地址解析协议)
文章目录 ARP协议(地址解析协议)MAC地址ARP协议ARP具体实现同一链路不同链路 ARP 缓存缓存查询 APR请求/响应报文 ARP协议(地址解析协议) MAC地址 MAC 地址的全称是 Media Access Control Address,即媒体访问控制地址…...

第一篇:KNX入门实战|从协议基础到开发环境搭建,新手也能轻松上手
在智能楼宇与工业自动化领域,KNX协议绝对是绕不开的核心标准——作为全球通用的开放式楼宇控制协议(ISO/IEC 14543),它融合了欧洲三大总线协议的优势,能实现照明、空调、传感器等各类设备的无缝联动,广泛应…...

OpenClaw+Qwen3.5-9B低成本自动化:自建模型比API省80%
OpenClawQwen3.5-9B低成本自动化:自建模型比API省80% 1. 为什么我要研究OpenClaw的成本问题 上个月我尝试用OpenClaw自动化处理积压的3000多份PDF文件,结果被商用API的账单吓了一跳——单次归档任务的token消耗折算下来居然要12美元。这让我开始思考&a…...

从零配置上网行为管理:H3C AC本地认证与第三方AAA服务器切换指南
从零构建企业级网络认证体系:H3C AC与第三方AAA服务器实战解析 在数字化转型浪潮中,企业网络管理正面临前所未有的复杂挑战。当新员工入职第一天无法连接Wi-Fi,当市场部反映视频会议频繁卡顿,当IT部门发现内网存在异常流量却无法追…...

Selenoid API完全解析:从会话管理到资源监控的终极指南
Selenoid API完全解析:从会话管理到资源监控的终极指南 【免费下载链接】selenoid Selenium Hub successor running browsers within containers. Scalable, immutable, self hosted Selenium-Grid on any platform with single binary. 项目地址: https://gitcod…...

Topeka Android应用终极部署指南:从源码编译到多渠道分发的完整教程
Topeka Android应用终极部署指南:从源码编译到多渠道分发的完整教程 【免费下载链接】topeka A fun to play quiz that showcases material design on Android 项目地址: https://gitcode.com/gh_mirrors/to/topeka Topeka是一款基于Material Design设计理念…...

uosc与其他MPV脚本对比:为什么uosc是极简MPV播放器UI的终极选择
uosc与其他MPV脚本对比:为什么uosc是极简MPV播放器UI的终极选择 【免费下载链接】uosc Feature-rich minimalist proximity-based UI for MPV player. 项目地址: https://gitcode.com/gh_mirrors/uo/uosc 在众多MPV播放器UI脚本中,uosc以其独特的…...

鸣潮游戏自动化工具终极指南:解放双手的智能战斗与资源收集助手
鸣潮游戏自动化工具终极指南:解放双手的智能战斗与资源收集助手 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves 欢迎来…...

React 自定义 Hook 的命名规范与调用规则详解
React 允许在普通函数中调用 Hook,但该函数必须是符合约定的自定义 Hook(即以 use 开头),且只能在 React 组件或其它自定义 Hook 内部调用;违反规则虽不一定立即报错,却会破坏依赖追踪、导致状态异常或未来…...

共享单车智能通信系统架构与技术解析
1. 共享单车通信系统架构解析共享单车的智能通信系统主要由四大核心模块构成:智能车锁、供电系统、通信模块和云端平台。这套系统设计最精妙之处在于,它完美结合了移动通信技术、蓝牙短距传输和GPS定位技术,构建了一个稳定可靠的物联网应用场…...

CCLE数据库实战指南:从数据下载到肝癌细胞系分析
1. CCLE数据库入门指南 第一次接触CCLE数据库时,我和大多数新手一样感到无从下手。这个由Broad研究所维护的癌症细胞系百科全书,包含了超过1000种人类癌症细胞系的基因组、转录组和药理学数据。对于肝癌研究者来说,它就像一座待挖掘的金矿。 …...