线程结构——链表
C++中的链表是一种非常常见的数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
链表结构包括单向链表、双向链表和循环链表;
1.单向链表
单向链表由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针;
1.1 定义
//单向链表结构
class Node
{
public:int data;Node* next;
};//单向链表类
class LinkedList {
public:LinkedList() {head = nullptr;}
private:Node* head;
};
1.2 初始化
对于定义的单向链表类,可以通过构造函数定义元素为空的链表,也可以通过initialize来初始化包含一个元素的链表;
示例
LinkedList() {head = nullptr;}void initialize(int value) {head = new Node();head->data = value;head->next = nullptr;}
1.3 获取链表的长度
获取链表的长度,即计算链表中包含多少个元素,通过遍历其中的元素计算
int length() {int count = 0;Node* current = head;while (current != nullptr) {count++;current = current->next;}return count;}
1.4 插入元素 && 元素追加
插入元素
根据元素插入的位置和元素来进行元素的插入操作
示例
void insertNode(int index, int value) {// 判断是否满足插入条件if (index < 0 || index > length()) {return;} else if (index == 0) { //首元素Node* newNode = new Node();newNode->data = value;newNode->next = head;head = newNode;} else {Node* prevNode = getNode(index - 1); //根据下标获取元素的方法Node* newNode = new Node();newNode->data = value;newNode->next = prevNode->next;prevNode->next = newNode;}}
元素追加
元素的追加,将元素插入到元素的末尾
void append(int value) {Node* newNode = new Node();newNode->data = value;newNode->next = nullptr;if (head == nullptr) {head = newNode;} else {Node* current = head;while (current->next != nullptr) {current = current->next;}current->next = newNode;}}
1.5 删除元素 && 清空 && 判断是否为空
删除元素
根据下标对元素进行删除
void deleteNode(int index) {if (index < 0 || index >= length()) {return;} else if (index == 0) {Node* temp = head;head = head->next;delete temp;} else {Node* prevNode = getNode(index - 1);Node* currentNode = prevNode->next;prevNode->next = currentNode->next;delete currentNode;}}
清空链表
清空链表中的元素
void clear() {Node* current = head;while (current != nullptr) {Node* next = current->next;delete current;current = next;}head = nullptr;}
判断链表是否为空
bool isEmpty() {return (head == nullptr);}
1.6 根据下标获取元素
根据链表的下标,来获取该位置的元素
Node* getNode(int index) {if (index < 0 || index >= length()) {return nullptr;} else {Node* current = head;int i = 0;while (i < index) {current = current->next;i++;}return current;}}
1.7 链表数据元素的打印
void printList() {Node* current = head;while (current != nullptr) {std::cout << current->data << " ";current = current->next;}std::cout << std::endl;}
1.8 应用场景
数据缓存:单向链表可以用作缓存数据结构,新的数据可以插入到链表的头部,而旧的数据可以从尾部移除,以限制缓存大小并保持最近使用的数据在链表的头部。
队列和栈的实现:单向链表可以用来实现队列和栈这两种常见的数据结构。在队列中,数据从尾部插入(入队),从头部删除(出队)。在栈中,数据只在链表的头部插入和删除,模拟了后进先出(LIFO)的行为。
2.双向链表
双向链表与单向链表不同之处在于每个节点除了指向下一个节点的指针外,还包含指向前一个节点的指针,这使得双向链表可以在前后两个方向上遍历和操作节点。
2.1 定义
双向链表这里使用了模板
template<typename T>
class Node {
public:T data;Node<T>* prev;Node<T>* next;
};template<typename T>
class DoublyLinkedList {
public:DoublyLinkedList() {head = nullptr;}
private:Node<T>* head;
};
2.2 初始化
void initialize(const T& value) {head = new Node<T>();head->data = value;head->prev = nullptr;head->next = nullptr;}
2.3 获取链表的长度
int length() {int count = 0;Node<T>* current = head;while (current != nullptr) {count++;current = current->next;}return count;}
2.4 插入元素 && 元素追加
插入元素
void insertNode(int index, const T& value) {if (index < 0 || index > length()) {return;} else if (index == 0) {Node<T>* newNode = new Node<T>();newNode->data = value;newNode->prev = nullptr;newNode->next = head;if (head != nullptr) {head->prev = newNode;}head = newNode;} else {Node<T>* prevNode = getNode(index - 1);Node<T>* nextNode = prevNode->next;Node<T>* newNode = new Node<T>();newNode->data = value;newNode->prev = prevNode;newNode->next = nextNode;prevNode->next = newNode;if (nextNode != nullptr) {nextNode->prev = newNode;}}}
元素追加
void append(const T& value) {Node<T>* newNode = new Node<T>();newNode->data = value;newNode->prev = nullptr;newNode->next = nullptr;if (head == nullptr) {head = newNode;} else {Node<T>* current = head;while (current->next != nullptr) {current = current->next;}current->next = newNode;newNode->prev = current;}}
2.5 删除元素 && 清空 && 判断是否为空
删除元素
void deleteNode(int index) {if (index < 0 || index >= length()) {return;} else if (index == 0) {Node<T>* temp = head;head = head->next;if (head != nullptr) {head->prev = nullptr;}delete temp;} else {Node<T>* currNode = getNode(index);if (currNode == nullptr) {return;}Node<T>* prevNode = currNode->prev;Node<T>* nextNode = currNode->next;prevNode->next = nextNode;if (nextNode != nullptr) {nextNode->prev = prevNode;}delete currNode;}}
清空
void clear() {Node<T>* current = head;while (current != nullptr) {Node<T>* next = current->next;delete current;current = next;}head = nullptr;}
判断链表是否为空
bool isEmpty() {return (head == nullptr);}
2.6 根据下标来获取元素
Node<T>* getNode(int index) {if (index < 0 || index >= length()) {return nullptr;} else {Node<T>* current = head;int i = 0;while (i < index) {current = current->next;i++;}return current;}}
2.7 链表数据元素的打印
双向链表支持正向输出和反向输出
void printListForward(Node<T>* first) {Node<T>* current = first;while (current != nullptr) {std::cout << current->data << " ";current = current->next;}std::cout << std::endl;}void printListBackward(Node<T>* last) {Node<T>* current = last;while (current != nullptr) {std::cout << current->data << " ";current = current->prev;}std::cout << std::endl;}
2.8 应用的场景
实现链表或双端队列:双向链表天然支持在链表头和链表尾高效地插入和删除元素,使其适用于实现链表或双端队列(deque)等数据结构。
实现LRU缓存算法:LRU(Least Recently Used)缓存算法中,当缓存已满时,最近最少使用的元素会被淘汰。双向链表可以方便地记录元素的访问顺序,并且在需要淘汰元素时,可以快速删除链表尾部的节点。
实现迭代器:双向链表的双向遍历特性使其非常适合用于实现迭代器。迭代器可以用于遍历容器中的元素,而双向链表可以提供前向和后向的遍历方式。
3.循环链表
循环链表是一种特殊类型的链表,其中链表的最后一个节点指向第一个节点,形成一个循环。与普通链表不同,循环链表没有一个明确的末尾节点,可以通过任何一个节点遍历整个链表。
3.1 定义
template<typename T>
class Node {
public:T data;Node<T>* next;
};template<typename T>
class CircularLinkedList {
public:CircularLinkedList() {head = nullptr;}
private:Node<T>* head;
};
3.2 初始化
void initialize(const T& value) {head = new Node<T>;head->data = value;head->next = head;}
3.3 获取链表的长度
int length() {if (head == nullptr) {return 0;} else {int count = 1;Node<T>* current = head->next;while (current != head) {count++;current = current->next;}return count;}}
3.4 插入元素 && 元素追加
插入元素
void insertNode(int index, const T& value) {Node<T>* newNode = new Node<T>();newNode->data = value;if (isEmpty() || index <= 0) {head = newNode;head->next = head;} else {Node<T>* prevNode = getNode(index - 1);if (prevNode == nullptr) {delete newNode;return;}newNode->next = prevNode->next;prevNode->next = newNode;}}
元素追加
void append(const T& value) {Node<T>* newNode = new Node<T>;newNode->data = value;newNode->next = head;if (head == nullptr) {head = newNode;newNode->next = head;} else {Node<T>* current = head;while (current->next != head) {current = current->next;}current->next = newNode;}}
3.5 删除元素 && 清空 && 判断是否为空
删除元素
void deleteNode(int index) {if (isEmpty() || index < 0) {return;} else if (index == 0) {Node<T>* currNode = head;if (head->next == head) {head = nullptr;} else {Node<T>* lastNode = head;while (lastNode->next != head) {lastNode = lastNode->next;}lastNode->next = head->next;head = head->next;}delete currNode;} else {Node<T>* prevNode = getNode(index - 1);if (prevNode == nullptr || prevNode->next == head) {return;}Node<T>* currNode = prevNode->next;prevNode->next = currNode->next;delete currNode;}}
清空
void clear() {Node<T>* current = head;while (current != nullptr && current->next != head) {Node<T>* next = current->next;delete current;current = next;}head = nullptr;}
判断是否为空
bool isEmpty() {return (head == nullptr);}
3.6 根据下标来获取元素
Node<T>* getNode(int index) {if (index < 0 || index >= length()) {return nullptr;} else {Node<T>* current = head;int i = 0;while (i < index) {current = current->next;i++;}return current;}}
3.7 链表元素的打印
void printCircularLinkedList(Node<T>* head) {if (head == nullptr) {return; // 空链表}Node<T>* current = head;do {std::cout << current->data << " ";current = current->next;} while (current != head);std::cout << std::endl;}
3.8 应用场景
环形缓冲区(Circular Buffer):环形缓冲区是一种常用的高效数据存储结构,常用于实现循环队列。在环形缓冲区中,最后一个元素的下一个位置是第一个元素,形成一个循环。循环链表提供了一种有效的数据结构来实现环形缓冲区。
循环播放列表:在音乐播放器或视频播放器中,可以使用循环链表来实现循环播放列表。每个歌曲或视频可以用链表节点表示,通过调整节点的顺序,可以实现循环播放功能。
相关文章:

线程结构——链表
C中的链表是一种非常常见的数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。 链表结构包括单向链表、双向链表和循环链表; 1.单向链表 单向链表由一系列节点组成,每个节点包含一个数据元素和…...
的日志系统设计)
freeRTOS:基于(信号量+线程)的日志系统设计
1.日志的重要性 故障排查与调试:嵌入式系统通常运行在资源有限的环境中,故障排查和调试变得尤为复杂。日志系统可以记录系统在运行过程中的各种操作、状态和事件信息,方便开发人员追踪和定位问题所在。通过分析日志,可以快速找到故…...
数据可视化(1)
使用python带的matplotlib库进行简单的绘图。使用之前先进行安装,pip install matplotlib。如果安装了Anaconda,则无需安装matplotlib。 1.简单折线图 #绘制简单图表 import matplotlib.pyplot as plt plt.plot([1,2,3,4,5]) plt.show() import matplotlib.pyp…...
Llama 2: Open Foundation and Fine-Tuned Chat Models
文章目录 TL;DRIntroduction背景本文方案 实现方式预训练预训练数据训练细节训练硬件支持预训练碳足迹 微调SFTSFT 训练细节 RLHF人类偏好数据收集奖励模型迭代式微调(RLHF)拒绝采样(Rejection Sampling)PPO多轮一致性的系统消息&…...
)
BTY-DNS AMA回顾:致力于创建Web3领域中的去中心化身份(DID)
传统域名系统 (DNS) 是一个分层的分散信息存储,用于将用户在网络浏览器中输入可读名称(例如www.baidu.com)解析为IP地址,来访问互联网上的计算机。传统域名系统存在一些例如过于集中化管理、效率并不高等局限性问题。而去中心化域…...

【设计模式——学习笔记】23种设计模式——装饰器模式Decorator(原理讲解+应用场景介绍+案例介绍+Java代码实现)
生活案例 咖啡厅 咖啡定制案例 在咖啡厅中,有多种不同类型的咖啡,客户在预定了咖啡之后,还可以选择添加不同的调料来调整咖啡的口味,当客户点了咖啡添加了不同的调料,咖啡的价格需要做出相应的改变。 要求ÿ…...

《golang设计模式》第一部分·创建型模式-01-单例模式(Singleton)
文章目录 1. 概述1.1 目的1.2 实现方式 2. 代码示例2.1 设计2.2 代码 1. 概述 1.1 目的 保证类只有一个实例有方法能让外部访问到该实例 1.2 实现方式 懒汉式 在第一次调用单例对象时创建该对象,这样可以避免不必要的资源浪费 饿汉式 在程序启动时就创建单例对象…...
若依微服务整合activiti7.1.0.M6
若依微服务3.6.3版本整合activiti7(7.1.0.M6) 目前有两种办法集成activiti7 放弃activiti7新版本封装的API,使用老版本的API,这种方式只需要直接集成即可,在7.1.0.M6版本中甚至不需要去除security的依赖。不多介绍&a…...

Ubuntu 下安装软件,卸载,查看已经安装的软件
参考网址:http://wiki.ubuntu.org.cn/UbuntuSkills 一般的安装程序用三种: .deb 和.rpm 这两种安装文件 .bundle 这是二进制的安装文件 而 tar.gz 这类的只是压缩包(相当于 .rar,.zip 压缩包一样),如果此类文件是程序的话&a…...
微信小程序导入微信地址
获取用户收货地址。调起用户编辑收货地址原生界面,并在编辑完成后返回用户选择的地址。 1:原生微信小程序接口使用API:wx.chooseAddress(OBJECT) wx.chooseAddress({success (res) {console.log(res.userName)console.log(res.postalCode)c…...

如何在Debian中配置代理服务器?
开始搭建代理服务器 首先我参考如下文章进行搭建代理服务器,步骤每一个命令都执行过报了各种错,找了博客 目前尚未开始,我已经知道我的路很长,很难走呀,加油,go!go!go! …...
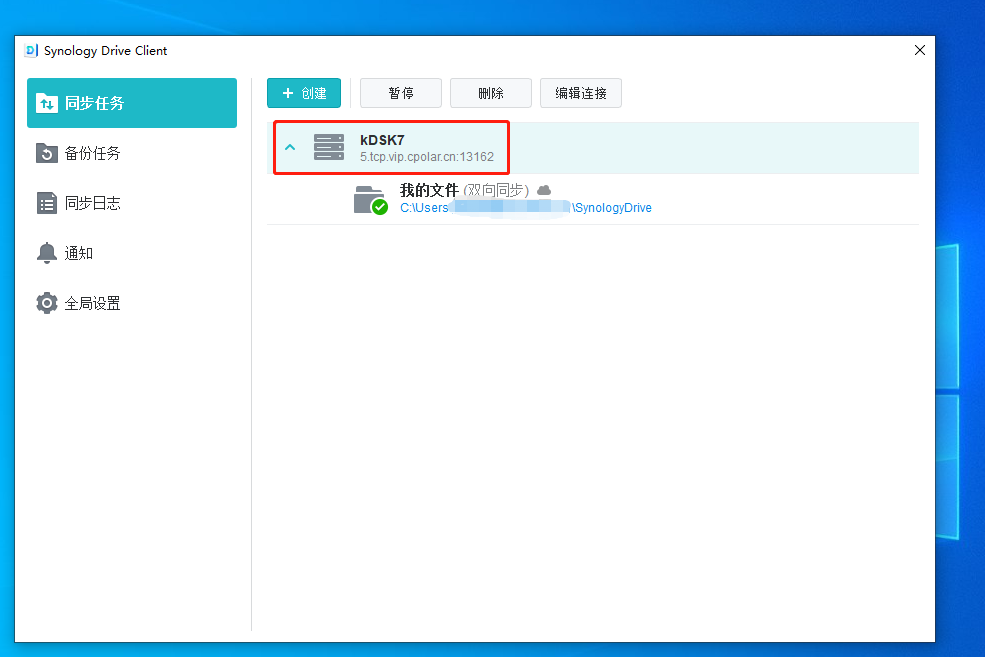
在外远程NAS群晖Drive - 群晖Drive挂载电脑磁盘同步备份【无需公网IP】
文章目录 前言1.群晖Synology Drive套件的安装1.1 安装Synology Drive套件1.2 设置Synology Drive套件1.3 局域网内电脑测试和使用 2.使用cpolar远程访问内网Synology Drive2.1 Cpolar云端设置2.2 Cpolar本地设置2.3 测试和使用 3. 结语 前言 群晖作为专业的数据存储中心&…...

[SQL挖掘机] - 标量子查询
介绍: 标量子查询(Scalar Subquery)是一种特殊类型的子查询,它返回单个值作为结果,而不是结果集。标量子查询通常嵌套在另一个查询的选择列表、条件或表达式中,并提供单个值来完成计算、比较或作为查询结果的一部分。…...

MTK 进META的两种方式
1. Preloader进meta: 开机情况下:先发adb reboot meta进入Preloader,然后再进META 2. 开机后直接进meta...
9.2-信息发送的Filter机制)
AutoSAR系列讲解(实践篇)9.2-信息发送的Filter机制
再强调一遍哈,这几节的内容大家看不懂没关系。都属于不常用的知识,仅作了解,假如用到了可以再挖出来看看。还有一点,很多的英文不太好翻译,比如这里的Filter,翻译成滤波,筛选我感觉都不太贴切,干脆就直接叫Filter了,之后应该会出现类似的英文,博主尽量想办法让大家理…...
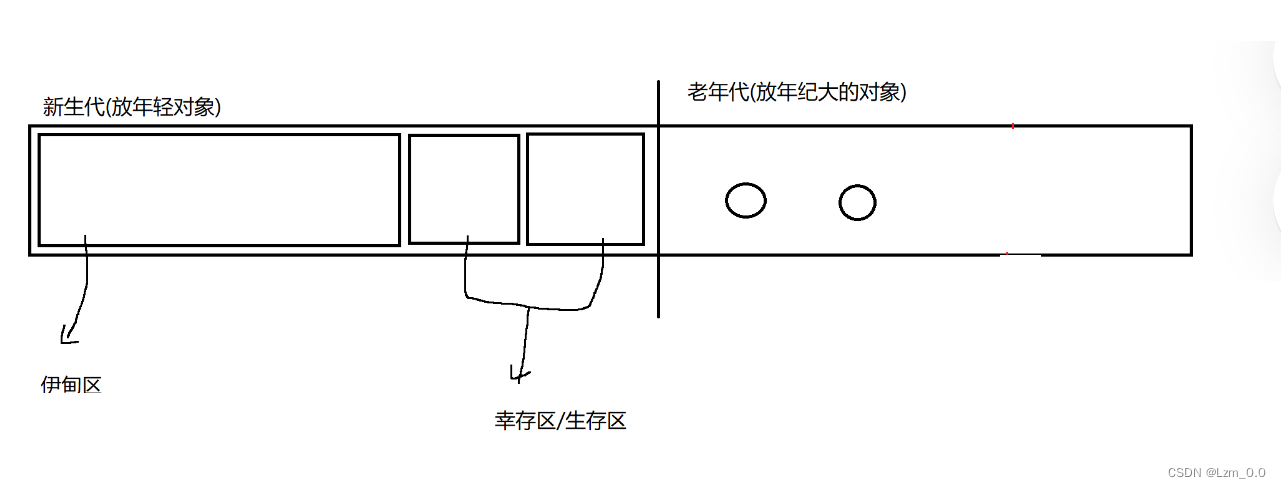
JVM详解(超详细)
目录 JVM 的简介 JVM 执行流程 JVM 运行时数据区 由五部分组成 JVM 的类加载机制 类加载的过程(五个) 双亲委派模型 类加载器 双亲委派模型的优点 JVM 中的垃圾回收策略 GC GC 中主要分成两个阶段 死亡对象的判断算法 引用计数算法 可达性分析算法 垃圾回收算…...
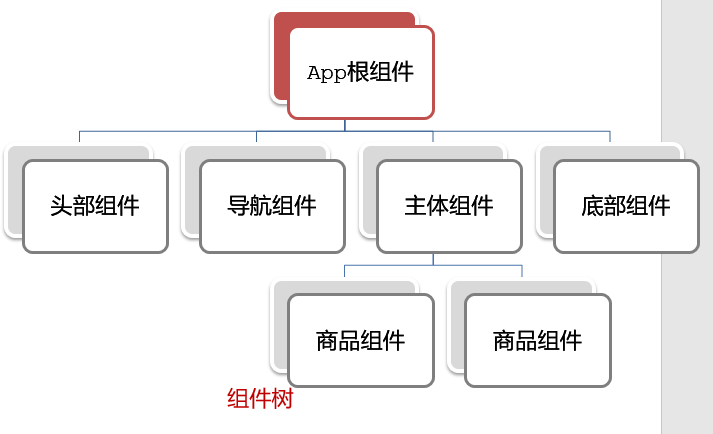
Vue学习Day3——生命周期\组件化
一、Vue生命周期 Vue生命周期:就是一个Vue实例从创建 到 销毁 的整个过程。 生命周期四个阶段:① 创建 ② 挂载 ③ 更新 ④ 销毁 1.创建阶段:创建响应式数据 2.挂载阶段:渲染模板 3.更新阶段:修改数据,更…...

Rust vs Go:常用语法对比(八)
题目来自 Golang vs. Rust: Which Programming Language To Choose in 2023?[1] 141. Iterate in sequence over two lists Iterate in sequence over the elements of the list items1 then items2. For each iteration print the element. 依次迭代两个列表 依次迭代列表项1…...

pytorch学习-线性神经网络——softmax回归+损失函数+图片分类数据集
1.softmax回归 Softmax回归(Softmax Regression)是一种常见的多分类模型,可以用于将输入变量映射到多个类别的概率分布中。softmax回归是机器学习中非常重要并且经典的模型,虽然叫回归,实际上是一个分类问题 1.1分类与…...
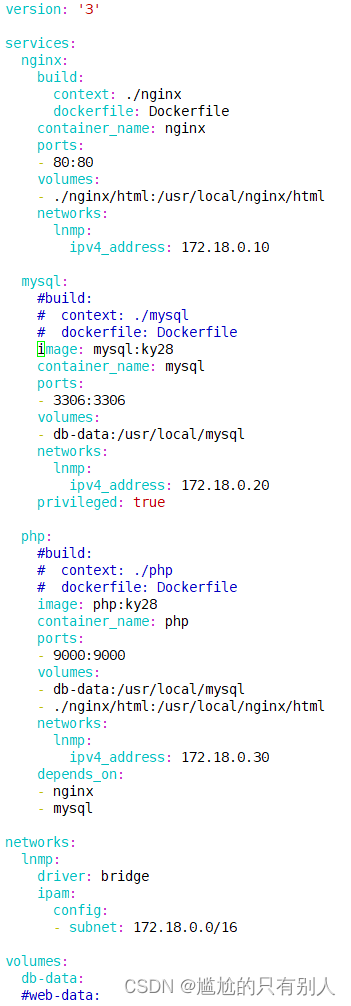
Docker compose(容器编排)
Docker compose(容器编排) 一、安装Docker compose 1.安装Docker compose Docker Compose 环境安装 Docker Compose 是 Docker 的独立产品,因此需要安装 Docker 之后在单独安装 Docker Compose#下载 curl -L https://github.com/docker/co…...

效率倍增:用快马生成openclaw一键式部署与配置工具
效率倍增:用快马生成openclaw一键式部署与配置工具 最近在团队协作时遇到了一个头疼的问题:每次新成员加入或者更换开发机,都需要手动部署openclaw环境。这个过程中不仅需要重复下载、解压、配置,还经常因为网络代理、权限等问题…...

新手入门指南:在快马平台上学习openclaw升级命令的基础与实践
今天想和大家分享一下我在学习openclaw升级命令时的一些心得。作为一个刚接触命令行工具的新手,一开始看到那些复杂的参数和选项确实有点懵,但通过InsCode(快马)平台的实践,我发现其实掌握起来并没有想象中那么难。 认识openclaw的基本概念 …...

B站缓存视频合并神器:3步搞定离线视频完整观看体验
B站缓存视频合并神器:3步搞定离线视频完整观看体验 【免费下载链接】BilibiliCacheVideoMerge 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCacheVideoMerge 你是否曾经在B站缓存了喜欢的视频,却发现它们被分割成多个零散的文件&#…...

深入解析Kubernetes中的RuntimeClass:容器运行时的“多面手调度器”
前言在Kubernetes集群中,我们通常默认使用containerd或Docker作为容器运行时。但随着业务场景的多样化、安全要求的严苛化以及硬件能力的演进,单一的运行时模型已无法满足所有需求:如何让金融应用运行在强隔离的轻量级虚拟机中,抵…...

磁力链接聚合搜索神器magnetW:23个站点一键搜索,资源查找从未如此简单!
磁力链接聚合搜索神器magnetW:23个站点一键搜索,资源查找从未如此简单! 【免费下载链接】magnetW [已失效,不再维护] 项目地址: https://gitcode.com/gh_mirrors/ma/magnetW 还在为寻找资源而苦恼吗?每次需要下…...

京东智能评价助手:自动化评价解决方案与效率提升实践
京东智能评价助手:自动化评价解决方案与效率提升实践 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 如何通过技术手段解决电商评价的效率瓶颈? 在电商购物场景中&…...

DeepAnalyze舆情分析:社交媒体数据挖掘
DeepAnalyze舆情分析:社交媒体数据挖掘实战指南 1. 引言:社交媒体时代的舆情挑战 每天,社交媒体平台产生着海量的用户内容——从微博的热点讨论到小红书的消费分享,从抖音的短视频评论到专业论坛的技术交流。这些数据中蕴含着宝…...

OmenSuperHub:惠普游戏本性能管理新范式
OmenSuperHub:惠普游戏本性能管理新范式 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 一、性能管理的痛点与破局之道 当你在《艾尔登法环》…...

Ollama+OpenClaw打造全自动本地智能助手,零成本部署,24小时全力运行
没问题,我们将为你详细拆解如何将本地的 Ollama 模型,通过 OpenClaw、Coplaw、Autoclaw 等“超级操控终端”进行能力超进化,实现一个能替你执行系统任务、操控电脑的全自动本地智能助手。整个过程强调“零成本”和“深度集成”。 从文生文到…...

5分钟教程:人脸分析系统API调用,轻松实现人脸检测与属性分析自动化
5分钟教程:人脸分析系统API调用,轻松实现人脸检测与属性分析自动化 1. 为什么选择API调用方式 当你第一次接触人脸分析系统时,Web界面确实是最直观的选择。但当你需要处理大量图片或集成到自动化流程时,图形界面就显得力不从心了…...