JVM详解(超详细)
目录
JVM 的简介
JVM 执行流程
JVM 运行时数据区
由五部分组成
JVM 的类加载机制
类加载的过程(五个)
双亲委派模型
类加载器
双亲委派模型的优点
JVM 中的垃圾回收策略 GC
GC 中主要分成两个阶段
死亡对象的判断算法
引用计数算法
可达性分析算法
垃圾回收算法
标记清楚算法
复制算法
标记整理算法
分代回收算法
一个对象的一生
JVM 的简介
Java Virtual Machine(Java虚拟机)
JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。
虚拟机介绍: 通过软件模拟的具有完整硬件的功能, 运行在一个完全隔离的环境中的完整计算机系统.
常见的虚拟机: JVM, VMwave, Virtual Box.....
JVM 与其他两个虚拟机之间的区别:
- VMwave与VirtualBox是通过软件模拟物理CPU的指令集,物理系统中会有很多的寄存器;
- JVM则是通过软件模拟Java字节码的指令集,JVM中只是主要保留了PC寄存器,其他的寄存器都进
行了裁剪。
| JVM 的初心: 就是为了让 Java 程序员能够比较简单的, 感知不到 系统层面的一些内容 还可以说让程序员只关注业务逻辑, 不要关注底层的实现细节 |
JVM 执行流程
JVM 是 java 运行的基础, 也是实现一次编译到处运行的关键, 下面就来说说 JVM 是怎么执行的~
以下是JVM详细的执行流程:
程序在执行之前先要把 java 代码转换为字节码 (class 文件), JVM 首先需要把字节码通过一定的方式类加载器(类加载器 ClassLoad) 把文件加载到内存中 运行中 运行是数据区 (Runtime Data Area), 而字节码文件是 JVM 的一套指令集规范, 并不能直接交给底层操作系统去执行, 云溪需要特定的命令解释器执行引擎 (Execution Engine) 将字节码翻译成底层系统指令再交由 CPU 去执行, 而这个过程中需要顶哦用其他语言的接口 本地库接口 (Native Interface) 来实现整个程序的功能, 这就是这四个只要组成部分的职责和功能

主要是四个部分来执行 java 程序的 :
- 类加载器 (ClassLoader)
- 运行时数据区 (Runtime Data Area)
- 执行引擎 (Execution Engine)
- 本地库接口 (Native Interface)
JVM 运行时数据区
- JVM 运行时数据区域也叫作内存布局, 和 java 内存模型 (Java Memory Model, 简称 JMM) 完全不同
- JVM 就是一个 Java 进程, Java 进程会从操作系统这里申请一大块区域, 给 Java 代码使用进一步划分, 给出不同的用途
由五部分组成
1. 堆: new 出来的对象 (成员变量)
堆的作用: 程序中创建的所有对象都保存在堆中
堆中分为两个区域:
1. 新生代: 放新建的对象
2. 老生代: 当经过一定 GC 次数之后还存活的对象会放入老生代
2. 栈: 维护方法之间的调用关系 (局部变量)(两个栈放到了一起)
- Java 虚拟机栈 : Java 虚拟机栈的生命周期和线程相同,Java 虚拟机栈描述的是 Java 方法执行的
内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数
栈、动态链接、方法出口等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈 - 本地方法栈 : 本地方法栈和虚拟机栈类似,只不过 Java 虚拟机栈是给 JVM 使用的,而本地方法栈是给本地方法使用的
3. 方法区(旧)/元数据区(新) : 放的是类加载(加载的类信息、常量、静态变量、即时编译器编译后的代码等数据)之后的类对象(.class 文件) (静态变量)
4. 程序计数器 : 记录当前程序指定到那个指令了
一个方法中各个地方对应在数据区中的位置
void func() {Test t = new Test();}解释:
new Test 这个对象, 对象的本体是在堆上的
t 本身是一个引用类型, t 是一个局部变量, 此时 t 是在栈上的
void func() : 一个方法在内存中, 是以一些二进制(字节码)的方式来存储的,在方法区中存储
总结:
堆和元数据区, 在一个 JVM 进程中, 只有一份
栈(本地方法栈和虚拟机栈) 和 程序计数器 则是存在多份(每个线程都有一份)
JVM 的线程和操作系统的线程是一对一的关系
每次在 Java 代码中创建的线程, 必然会在系统中有一个对应的线程
JVM 的类加载机制
把.class 文件, 加载到内存, 得到 类对象 这样的过程
程序要想运行, 就需要把依赖的"指令和数据" 加载到内存中

类加载的过程(五个)
1. 加载 (Loading) : 找到 .class 文件(双亲委派模型), 并且读文件内容
2. 验证(Verification) : 这一阶段的目的是确保Class文件的字节 流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信 息被当作代码运行后不会危害虚拟机自身的安全。
3. 准备(Preparation) : 给类对象 分配内存空间(未初始化的空间, 内存空间中的数据全是 0 的) (类对象中的静态成员啥的也是 全0 的) 类加载最终 是为了得到类对象
4. 解析(Resolution) : java 虚拟机将常量池内的符号引用替换为直接引用的过程, 也就是针对字符串常量进行初始化
符号引用
在.class 文件中就存在了, 但是他们只是知道彼此之间的相对位置(偏移量), 不知道自己在内存中的实际地址,这时候字符串常量就是 符号引用
直接引用
真正加载到内存中, 就会把字符串常来那个填充到内存中的特定地址上,字符串常量之间的相对位置还是一样的, 但是这些字符串有了自己真正的内存地址, 此时的字符串就是直接引用了
5. 初始化 (Initialzation) : 针对类对象进行初始化, (初始化静态成员, 执行静态代码块, 类要是有父类还需要加载父类) Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程
类加载 这个动作什么时候会触发?
不是 JVM 一启动就会触发, 就是把 .class 都加载了!! 整体是一个 "懒加载" 的策略(懒汉模式) 非必要不加载
什么叫做"必要"
1 创建这个类的实例
2 使用这个类的静态方法/ 静态属性
3 使用子类,会触发父类的加载
类加载中最关键的考点:
双亲委派模型
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最 终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无 法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载
作用:
就是在第一个步骤中, 找 .class 文件这个过程
类加载器
JVM 中类加载, 需要用到一组特殊的模块,类加载器
在 JVM 中, 内置了三个类加载器
BootStrap ClassLoader 负责加载 Java 标准库中的类
Extension CllassLoader 负责加载一些非标准的但是 Sun/Oracle 扩展库的类
Application ClassLoader 负责加 载项目中自己写的类 以及 第三方库中的类

双亲委派模型的优点
1. 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那
么在 B 类进行加载时就不需要再重复加载 C 类了。
2. 安全性:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了
JVM 中的垃圾回收策略 GC
简单来说就是帮助程序员自动释放内存的
C语言中 , malloc 的内存必须手动 free ,否则就容易出现内存泄漏
内存泄漏: 光申请内存, 不释放, 内存逐渐用完了, 导致程序崩溃
申请的时机是明确的 => 使用到了必须得申请
释放的时机是模糊的 => 彻底不使用才能释放
JVM 中的内存有好几个区域, 是释放哪个部分的空间呢?
堆(new 出来的对象)
程序计数器 就是一个单纯存地址的整数, 也是随着线程一起销毁, 方法调用完毕, 方法的局部变量自然随着出栈操作就销毁了元数据区/方法区, 存的类对象, 很少会卸载
GC 也就是以对象 为单位进行释放的(说是释放内存, 其实是释放对象)
GC 中主要分成两个阶段
1. 找谁是垃圾把垃圾对象的内存释放掉
2. 垃圾回收算法
基本的思想方法, 不代表 JVM 真实的实现方式
JVM 的真正实现方法, 是基于这些思想方法, 但是有做出很多细节上的调整和优化
我们如何找到垃圾:
如果一个对象没有一个对象引用他,此时这个对象一定是无法被使用的,这样的就算是垃圾,也叫做死亡对象
对于垃圾对象的识别是比较保守的
但是又怎么知道一个对象是否有引用指向?
死亡对象的判断算法
引用计数算法
给对象增加一个引用计数器,每当有一个地方引用它时,计数器就+1;当引用失效时,计数器就-1;任何时刻计数器为0的对象就是不能再被使用的,即对象已"死"
优点: 实现简单, 判定效率高
缺点:
- 浪费内存空间
- 无法解决对象的循环引用问题,比如两个对象互相引用,导致引用计数的判定逻辑错误
Java没有采取 python PHP 采取了
可达性分析算法
把对象之间的引用关系, 理解成了一个树型结构, 从一些特殊的起点出发,进行遍历, 只要能遍历访问到的对象, 就是可达,再把不可达的当做成垃圾
可达性分析的关键要点, 需要有起点
1) 栈上的局部变量(每个栈的每个局部变量, 都是起点)
2) 常量池中的引用对象
3) 方法区中, 静态成员引用的对象
上述三点也叫做 : gcroots
优点: 克服了引用计数算法的缺点
缺点:
- 消耗更多的时间,因此某个对象成了垃圾, 也不一定能第一时间发现,因为扫描的过程需要消耗时间的
- 在进行可达性分析的时候, 要顺藤摸瓜, 一旦这个过程中, 当前代码中的对象的引用关系发生了变化, 就麻烦了,因此需要再摸瓜的过程中, 需要让其他的业务线程暂停工作,这个问题称为 STW 问题 但是经过了这么多年的优化, 虽说是不能完全的消除, 已经可以让 STW 的时间尽量缩短了
垃圾回收算法
三种典型的策略:
标记清楚算法
"标记-清除"算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段 : 首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象
缺点:
- 效率问题 : 标记和清楚这两个过程的效率都不高
- 空间问题 : 标记清楚后会产生大量不连续的内存碎片, 空间碎片太多可能会导致以后再程序运行中需要分配较大对象时, 无法找到足够连续内存而不得不提前触发另一次垃圾收集

复制算法
复制"算法是为了解决"标记-清理"的效率问题。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次清理掉。这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片等复杂情况,只需要移动堆顶指针,按顺序分配即可。此算法实现简单,运行高效
缺点:
- 内存利用率比较低
- 如果大部分对象都是要保留的,此时垃圾很少,复制成本就很高了

标记整理算法
复制收集算法在对象存活率较高时会进行比较多的复制操作,效率会变低。因此在老年代一般不能使用复制算法。
针对老年代(存活实现比较长的对象)的特点,提出了一种称之为"标记-整理算法"。标记过程仍与"标记-清除"过程一致,但后续步骤不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉端边界以外的内存。

实际上 JVM 的实现思路, 是结合了上述几种思想方法
分代回收算法
当前 JVM 垃圾收集都采用的是"分代收集(Generational Collection)"算法,这个算法并没有新思想,只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代。在新生代中,每次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法;而老年代中对象存活率高、没有额外空间对它进行分配担保,就必须采用"标记-清理"或者"标记-整理"算法
针对不同的情况, 采用不同的策略,给对象设定了年龄的概念 , 描述了这个对象存在了多久了,如果一个对象刚诞生, 认为是 0 岁,每次经过一轮扫描(可达性分析), 没被标记为垃圾, 这个对象就涨了一岁,通过年龄区分这个对象的存活时间,针对不同的年龄对象采用不同的策略
图文总结分代回收:
针对不同年龄的对象采用不同的回收策略
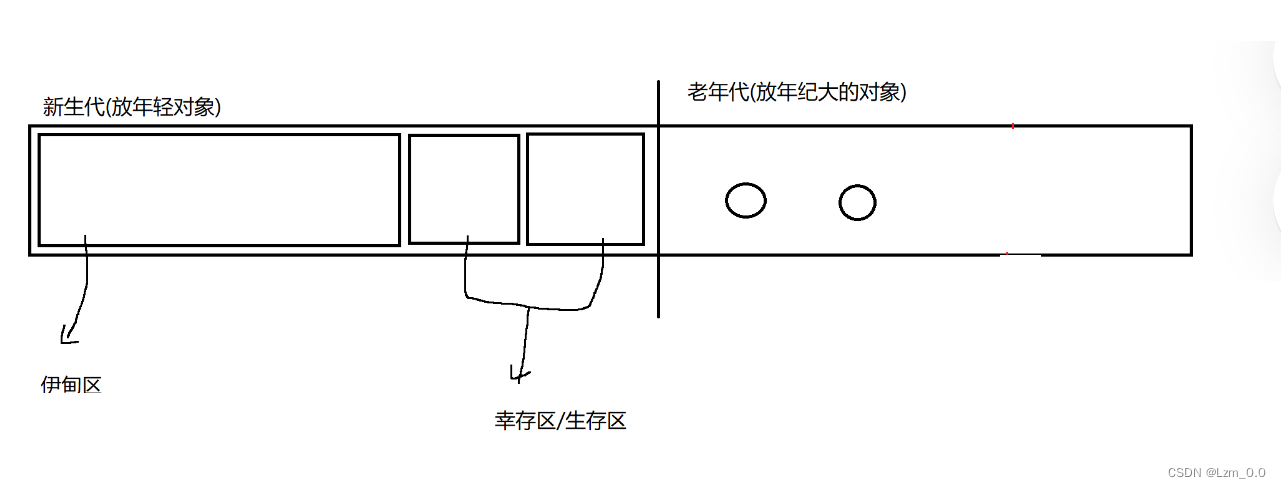
- 新创建的对象, 放到伊甸区
当垃圾回收扫描到伊甸区之后, 绝大部分对象都会在第一轮 GC 中被干掉
- 如果熬过第一轮 GC , 就会通过复制算法, 拷贝到生存区,生存区分为两大半, 一次使用其中一半
- 当这个对象在生存区, 熬过若干轮 GC 后,年龄增长到一定程度时, 就会通过复制算法拷贝到老年区
- 进入老年区年纪也就大了, 再消亡的概率也就小了, 所以针对老年区的 GC 次数也就降低了很多
如果老年区发现了垃圾对象, 使用标记整理的方式清楚
特殊情况: 如果对象非常大, 直接送进老年区(因为进行复制算法成本比较高, 而且大的对象也不是很多)
一个对象的一生
我是一个普通的 Java 对象,我出生在 伊甸 区,在 伊甸 区我还看到和我长的很像的小兄弟,我们在 伊甸 区中玩了挺长时间。有一天伊甸区中的人实在是太多了,我就被迫去了 生存区的 “From” 区(S0 区),自从去生存 区,我就开始漂了,有时候在 Survivor 的 “From” 区,有时候Survivor 的 “To” 区(S1 区),居无定所。直到我 18 岁的时候,爸爸说我成人了,该去社会上闯闯了。于是我就去了年老代那边,年老代里,人很多,并且年龄都挺大的,我在这里也认识了很多人。在老年代里,我生活了很多年(每次GC加一岁)然后被回收了, 最终还是被回收不过甚是精彩
相关文章:
JVM详解(超详细)
目录 JVM 的简介 JVM 执行流程 JVM 运行时数据区 由五部分组成 JVM 的类加载机制 类加载的过程(五个) 双亲委派模型 类加载器 双亲委派模型的优点 JVM 中的垃圾回收策略 GC GC 中主要分成两个阶段 死亡对象的判断算法 引用计数算法 可达性分析算法 垃圾回收算…...
Vue学习Day3——生命周期\组件化
一、Vue生命周期 Vue生命周期:就是一个Vue实例从创建 到 销毁 的整个过程。 生命周期四个阶段:① 创建 ② 挂载 ③ 更新 ④ 销毁 1.创建阶段:创建响应式数据 2.挂载阶段:渲染模板 3.更新阶段:修改数据,更…...

Rust vs Go:常用语法对比(八)
题目来自 Golang vs. Rust: Which Programming Language To Choose in 2023?[1] 141. Iterate in sequence over two lists Iterate in sequence over the elements of the list items1 then items2. For each iteration print the element. 依次迭代两个列表 依次迭代列表项1…...

pytorch学习-线性神经网络——softmax回归+损失函数+图片分类数据集
1.softmax回归 Softmax回归(Softmax Regression)是一种常见的多分类模型,可以用于将输入变量映射到多个类别的概率分布中。softmax回归是机器学习中非常重要并且经典的模型,虽然叫回归,实际上是一个分类问题 1.1分类与…...
Docker compose(容器编排)
Docker compose(容器编排) 一、安装Docker compose 1.安装Docker compose Docker Compose 环境安装 Docker Compose 是 Docker 的独立产品,因此需要安装 Docker 之后在单独安装 Docker Compose#下载 curl -L https://github.com/docker/co…...

xmind latex【记录备忘】
xmind latex 换行 换行必须要有\begin{align}和\end{align},此时再在里面用\才能换行,如果只写112\224是不能换行的...
)
RocketMQ(1.NameServer源码)
NameServer功能简述 主要功能如下 服务注册与发现:Nameserver扮演了RocketMQ集群中服务注册中心的角色。当RocketMQ中的Broker、Producer和Consumer启动时,它们会向Nameserver注册自己的网络地址和角色信息。Nameserver维护着集群中所有活跃实例的信息…...

责任链vs金融登录
金融app相对普通app而言,出于安全考虑,其安全校验方式比较多,以某些银行app为例,手机号登录成功后,会增加指纹、手势、OCR人脸等验证!这些安全项的校验,会根据用户的风险等级有不同的校验优先级…...
通过VIOOVI,了解联合作业分析的意义和目标!
现如今企业的主流生产模式就是流水线生产,一道工序结束后,紧接着开展下一项工序,这种作业模式可以以一种比较高效的方式缩减生产时间。尽管流水作业的效率已经够高的了,但是各个工序之间如果衔接不到位的话,会造成生产…...
清洁机器人规划控制方案
清洁机器人规划控制方案 作者联系方式Forrest709335543qq.com 文章目录 清洁机器人规划控制方案方案简介方案设计模块链路坐标变换算法框架 功能设计定点自主导航固定路线清洁区域覆盖清洁贴边沿墙清洁自主返航回充 仿真测试仿真测试准备定点自主导航测试固定路线清洁测试区域…...
设计模式 - 工厂模式
一、 简单工厂(Simple Factory Pattern) 1、概念 一个工厂对象决定创建出哪一种产品类的实力,但不属于GOF23种设计模式。 简单工厂适用于工厂类负责创建的对象较少的场景,且客户端只需要传入工厂类的参数,对于如何创…...

elementUI this.$confirm 文字大小样式
dangerouslyUseHTMLString:true // message部分 以html片段处理 customClass //MessageBox 的自定义类名 整个comfirm框自定义类名 cancelButtonClass // 取消按钮的自定义类名 confirmButtonClass // 确定按钮的自定义类名<style> .addcomfirm{width: 500px; } .a…...

Kafka的TimingWheel
Kafka的TimingWheel是Kafka中的一个时间轮实现,用于管理和处理延迟消息。时间轮是一种定时器的数据结构,可以高效地管理和触发定时事件。 在Kafka中,TimingWheel用于处理延迟消息的重试。当Kafka生产者发送消息到Kafka集群,但由于某些原因导致消息发送失败,生产者会将这些…...

第2集丨webpack 江湖 —— 创建一个简单的webpack工程demo
目录 一、创建webpack工程1.1 新建 webpack工程目录1.2 项目初始化1.3 新建src目录和文件1.4 安装jQuery1.5 安装webpack1.6 配置webpack1.6.1 创建配置文件:webpack.config.js1.6.2 配置dev脚本1.7 运行dev脚本 1.8 查看效果1.9 附件1.9.1 package.json1.9.2 webpa…...
Python(Web时代)——初识flask
flask简介 介绍 Flask是一个用Python编写的Web 微框架,让我们可以使用Python语言快速实现一个网站或Web服务。它是BSD授权的,一个有少量限制的免费软件许可。它使用了 Werkzeug 工具箱和 Jinja2 模板引擎。 Flask 的设计理念是简单、灵活、易于扩展&a…...

二、SQL-5.DQL-8).案例练习
1、查询年龄为20,21,22,23岁的员工信息 select * from emp where age in(20, 21, 22, 23) and gender 女; 2、查询性别为男,并且年龄在20-40岁(含)以内的姓名为三个字的员工 select * from emp where gender 男 && age between 2…...

浙大数据结构第五周之05-树7 堆中的路径
题目详情: 将一系列给定数字依次插入一个初始为空的小顶堆H[]。随后对任意给定的下标i,打印从H[i]到根结点的路径。 输入格式: 每组测试第1行包含2个正整数N和M(≤1000),分别是插入元素的个数、以及需要打印的路径条数。下一行给出区间[-1…...
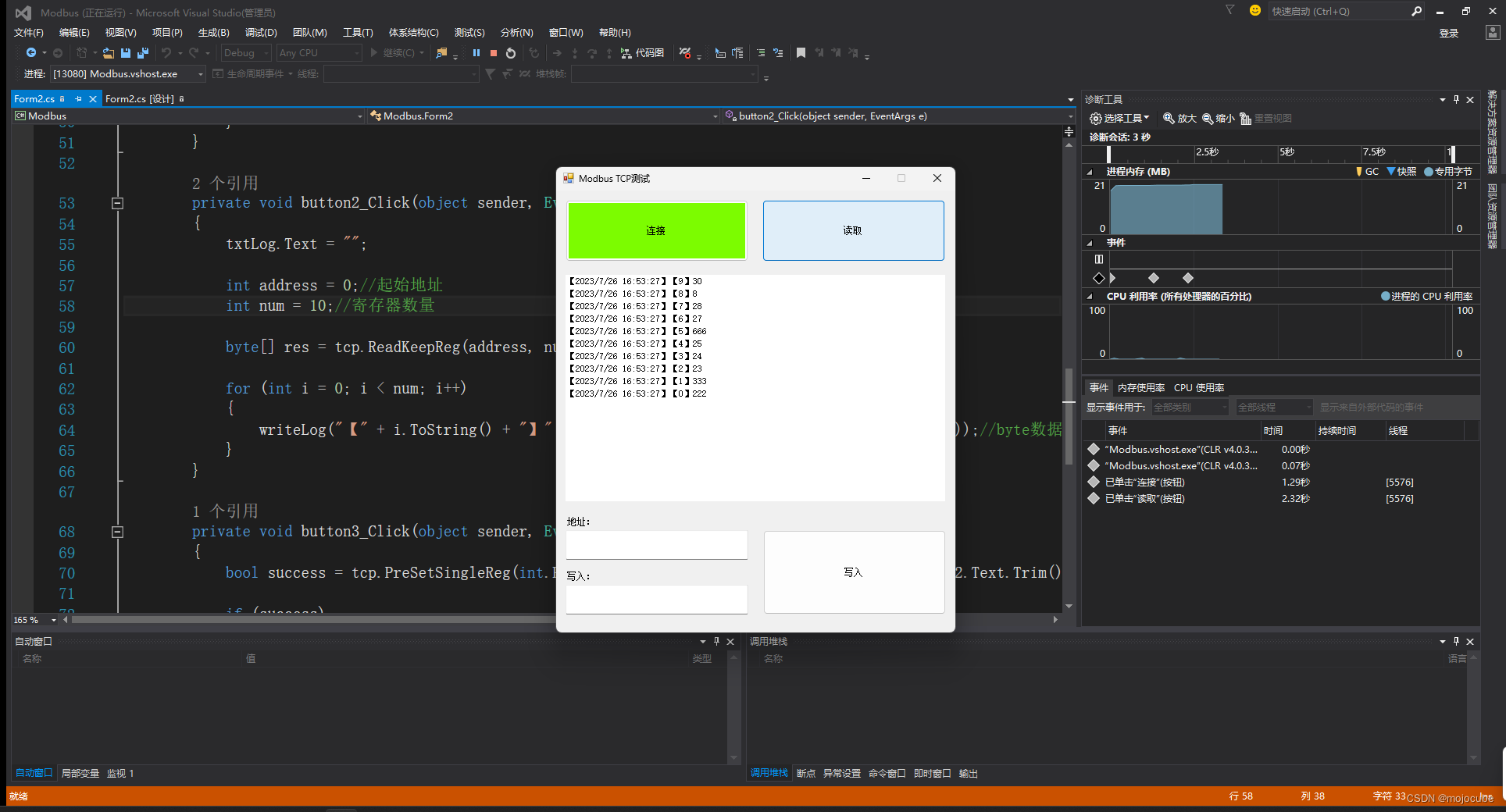
C# Modbus TCP上位机测试
前面说了三菱和西门子PLC的上位机通信,实际在生产应用中,设备会有很多不同的厂家生产的PLC,那么,我们就需要一种通用的语言,进行设备之间的通信,工业上较为广泛使用的语言之一就是Modbus。 Modbus有多种连…...
)
instr字符查找函数(oracle用instr来代替like)
instr函数:字符查找函数。其功能是查找一个字符串在另一个字符串中首次出现的位置。 instr函数在Oracle/PLSQL中是返回要截取的字符串在源字符串中的位置。 语法 instr( string1, string2, start_position,nth_appearance ) 参数 string1:源字符串&am…...

trie树的一点理解
这个是最简单的数据结构:因为只需要记住两句话就能完美的写出简洁优雅的代码 1. 每次都是从根节点开始看(或者说从第零次插入的东西开始遍历,son[][]里面存的是第几次插入) 2每次遍历都是插入和查询的字符串 #include<iostream> using namespace …...

Linux栈机制解析:从原理到实践应用
1. Linux中的栈机制概述在计算机系统中,栈(stack)是一种后进先出(LIFO)的数据结构,它不仅在软件层面有着广泛应用,在硬件层面也扮演着关键角色。大多数处理器架构都实现了硬件栈,有专门的栈指针寄存器和特定的硬件指令来完成入栈/…...

第1节:如何统一多源文档格式?
RAG与Agent性能调优:1.如何统一多元文档格式? Gitee地址:https://gitee.com/agiforgagaplus/OptiRAGAgent 文章详情目录:RAG与Agent性能调优 下一节:待更新 导论 从路口着手解决问题 在RAG技术中,文档…...

深入Helmholtz原理与NFA:EDLines如何像“质检员”一样控制误检率
Helmholtz原理与NFA:EDLines如何用数学语言定义"有意义"的线段 在计算机视觉领域,直线检测看似是个基础问题,却蕴含着深刻的数学智慧。当我们观察EDLines算法时,会发现它不仅仅是一系列操作步骤的堆砌,更是一…...

# 发散创新:基于Python与Stable Diffusion的AI绘画自动化流程设计与实践
发散创新:基于Python与Stable Diffusion的AI绘画自动化流程设计与实践 在人工智能技术飞速发展的今天,AI绘画已从实验室走向大众创作场景。如何将这一前沿能力融入开发者工作流?本文以 Python Stable Diffusion API(如InvokeAI或…...

雷达目标分类及宽带测角方案设计实现
本文参考,仅供学习使用基于飞腾M6678的雷达目标 分类和宽带测角研究与实现硬件计算平台介绍1. 飞腾M6678芯片核心参数与优势飞腾M6678是国防科技大学自主研发的国产多核DSP,专为数字信号处理设计,核心特性为:硬件资源:…...

08_Neo4j知识体系之企业级特性与高可用架构
08_Neo4j知识体系之企业级特性与高可用架构 体系 企业特性层:集群与高可用、安全与合规、备份恢复、监控运维、Neo4j Ops Manager关联能力:与关键业务系统、金融级稳定性、多环境治理、权限审计、灾备体系密切相关适用对象:企业架构师、DBA、…...

x86汇编堆栈
x86汇编堆栈 1)堆栈操作 x86汇编中的堆栈是一块特殊的内存区域,用于存储程序运行时的数据。它遵循"后进先出LIFO的原则",主要用于函数调用时的参数传递、局部变量存储以及保存返回地址。 堆栈操作的核心指令是PUSH和POP。PUSH指令将…...

flac3d7.0主应力方向导出与可视化:使用fish导出单元体数据并用matlab绘制塑性区图
flac3d7.0主应力方向的导出并绘图 使用fish将单元体的三个主应力方向数据导出,并使用matlab绘图,可只对部分区域(如塑性区)的数据进行绘图在岩土工程数值模拟后处理中,三维主应力方向可视化是个挺有意思的活。今天咱们直接上手实操࿰…...

基于两相交错并联技术的Buck-Boost变换器仿真研究:采用双向DCDC及多环控制策略实现高...
两相交错并联buck/boost变换器仿真 采用双向DCDC,管子均为双向管 模型内包含开环,电压单环,电压电流双闭环三种控制方式 两个电感的电流均流控制效果好可见下图电流细节 matlab/simulink/两相交错并联buck/boost变换器的仿真总能让工程师又爱…...

游戏开发中的乒乓缓存实战:Unity双缓冲技术如何提升渲染性能
游戏开发中的乒乓缓存实战:Unity双缓冲技术如何提升渲染性能 在Unity游戏开发中,渲染性能优化一直是开发者关注的焦点。当画面复杂度和特效层级不断提升时,传统的单缓冲机制往往难以满足流畅渲染的需求,这时乒乓缓存(P…...