java篇 类的进阶0x0A:万类之祖:Object 类
文章目录
- 万类之祖:Object 类
- `hashCode()` 与 `equals()`
- `hashCode()` 方法
- `equals()` 方法
- `==` vs. `equals()`
- String 的 `equals()`
- 为什么要重写 hashCode 和 equals 方法
- 重写(覆盖)前 `hashCode()` 和 `equals()` 的作用
- 什么情况下需要重写(覆盖) `hashCode()` 和 `equals()` ?
- 为什么重写`equals()` 方法一定要重写 `hashCode()` 方法
- 自动覆盖 `equals()` 与 `hashCode()`
- `toString()` 方法
- 自动覆盖 `toString()`
- Objects 类
万类之祖:Object 类
所有的类(除了 Object 类本身),都间接或者直接地继承自 Object 类。
Object 类只有成员方法,没有成员变量。
在 IDEA 中:菜单栏 --> Navigate --> Type Hierarchy (或直接 ctrl + H)
可以看到当前类的类继承关系。
可以看到,无论是哪条类继承链,最上方总会是 Object 类( java.lang.Object)。
这也是为什么在 IDEA 中写代码时,经常在输入点操作符(.)后,会弹出一大堆的不是我们自己编写的方法提示(/推荐)让我们选择,因为这些弹出来推荐使用的方法,都是 Object 类中定义的,而我们自己编写的类所创建的对象,自然会继承这些方法。
我们虽然没有显式在自定义类中
extends Object,但 java 会给我们自动补上extends Object。当然你自定义一个类,非自己写上比如说public class TestUse extends Object也没有问题,测试过并不会报错。但 IDEA 会提示你可以删除冗余的extends Object。
package org.test.extendstest.statictest;public class TestUse {public static void main(String[] args) {Object obj = new Object();System.out.println("Object 类的实例信息:"+obj); // Object 类的实例信息:java.lang.Object@404b9385A a = new A();System.out.println("打印 A 类的实例信息"); // 打印 A 类的实例信息printObj(a);}public static void printObj(Object obj){System.out.println(obj);// org.test.extendstest.statictest.A@682a0b20System.out.println(obj.toString()); // org.test.extendstest.statictest.A@682a0b20System.out.println(obj.getClass());// class org.test.extendstest.statictest.ASystem.out.println(obj.hashCode());// 1747585824// 1747585824 转换成 16 进制就是 682a0b20}
}
代码详细解析如下:
package org.test.extendstest.statictest;public class TestUse {public static void main(String[] args) {Object obj = new Object();System.out.println("Object 类的实例信息:"+obj);// 当然,null 直接用 System.out.println(null) 是可以正常输出 “null” 的。
// printObj((Object)null); // 如果不注释会报错,因为 null 无法调用 .toString、.getClass、.hashCode 函数
// printObj(null); // 如果不注释会报错,因为 null 无法调用 .toString、.getClass、.hashCode 函数A a = new A();System.out.println("打印 A 类的实例信息");printObj(a);}public static void printObj(Object obj){System.out.println(obj);// 其实在 IDEA 中 ctrl 点击 println 进去看代码,会发现经过相关调用跳转,最终调用的函数是:/*public static String valueOf(Object obj) {return (obj == null) ? "null" : obj.toString();}*/// 也就是会判断是不是 null ,是 null 就输出 “null”,不是的话就调用 .toString(),所以输出和下方的 .toString() 一样。// 看看实现System.out.println(obj.toString()); // 查看 .toString() 源码/*public String toString() {return getClass().getName() + "@" + Integer.toHexString(hashCode());}*/// 可以看到输出的是一个拼接的字符串,分别就有调用下方的 .getClass() 和 .hashCode()// 这里 .toHexString() 就是转 16 进制,也就是把 hashCode() 返回的哈希值转成 16 进制// native 方法。// java 的类库里有许多 native 方法,native 的意思是这个方法没有方法体,它方法的代码实际上是用本地(操作系统,平台相关,比如只能跑在 windows 或只能跑在 mac OS 上)的代码实现的(C 或 C++)。它存在一个映射机制,根据方法名,对应到本地的 c/c++ 写的和平台相关的方法。System.out.println(obj.getClass()); System.out.println(obj.hashCode());/*@IntrinsicCandidatepublic final native Class<?> getClass(); // java 源码中没有方法体(方法体在计算机的某个 dll 中定义)*//*@IntrinsicCandidatepublic native int hashCode(); // java 源码中没有方法体(方法体在计算机的某个 dll 中定义)*/}
}// 输出结果:
// Object 类的实例信息:java.lang.Object@404b9385
// 打印 A 类的实例信息
// org.test.extendstest.statictest.A@682a0b20
// org.test.extendstest.statictest.A@682a0b20
// class org.test.extendstest.statictest.A
// 1747585824// 1747585824 转换成 16 进制就是:682a0b20
// 哈希码是一个标识,相对比较唯一地去标识一个对象(但不确保完全唯一,因为存在哈希碰撞,两个对象刚好同一个哈希值,但只要是哈希值(哈希码)不同,那对象就肯定是不同的)
hashCode() 与 equals()
参考:
- https://blog.csdn.net/qq_50838572/article/details/122877342
hashCode()和equals()这两个基本上是初级 java 程序员面试必考的内容。
hashCode() 和 equals() 是最常覆盖的两个方法。覆盖原则是:equals() 为 true ,hashCode 就应该相等。这是一种约定俗成的规范。
equals()是true是hashCode()相等的充分不必要条件;hashCode()相等是equals()为true的必要不充分条件。
e q u a l s ( ) 是 t r u e ⇒ h a s h C o d e ( ) 相等 equals() 是 true\Rightarrow hashCode() 相等 equals()是true⇒hashCode()相等
h a s h C o d e ( ) 相等 ⇏ e q u a l s ( ) 是 t r u e hashCode() 相等 \nRightarrow equals() 是 true hashCode()相等⇏equals()是true
hashCode() 方法
hashCode 可以翻译为 “哈希码”,或者 “散列码”,是一个表示对象的特征值的 int 整数。
当没有任何类去覆盖 hashCode() ,可以简单地认为哈希码的值就是这个对象在内存中的地址(Object 中 hashcode() 是根据对象的存储地址转换而形成的一个哈希值)。
// Object 的 hashCode() 是 native 方法,因此在 java 源码中是没有方法体的。它本质上是用 C++ 来实现的。
@IntrinsicCandidate
public native int hashCode();
equals() 方法
equals 方法应该用来判断两个对象从逻辑上是否相等。(并不是判断这两个对象是不是同一个对象)
这里之所以是“应该”,是因为如果不覆盖的
equals(),那么就是继承 Object 类中的equals()方法,但这个原始的equals()就真的仅仅是在判断两个对象是不是同一个对象。这样是没什么意义的,所以要通过覆盖,让equals()真正去判断两个对象在业务逻辑上是否相等。
== vs. equals()
== 在引用数据类型当中进行的是地址的比较,equals() 方法在 Object 类当中其底层也是用 == 比较地址,但是不同的类可能会重写equals() 方法,比如 String 类中的 equals() 方法就是先比较地址是否相同,如果相同直接返回 true,地址不同再比较值,如果值相等那么同样返回 true。
// Object 类中的 equals()
public boolean equals(Object obj) {return (this == obj);
}// String 类中覆盖的 equals()
public boolean equals(Object anObject) {if (this == anObject) {return true;}return (anObject instanceof String aString)&& (!COMPACT_STRINGS || this.coder == aString.coder)&& StringLatin1.equals(value, aString.value);
}
String 的 equals()
因为在 java 中 String 类实在用得太多了,对象创建也太多了,所以 java 针对 String 添加了一些优化。
public class StringEqualsTest {public static void main(String[] args) {String s1 = "aaabbb";String s2 = "aaa" + "bbb";System.out.println("用 == 判断结果:"+(s1 == s2)); // 用 == 判断结果:trueSystem.out.println("用 equals 判断结果:"+ s1.equals(s2)); // 用 equals 判断结果:true}
}
这个输出结果可能会让人惊讶。因为按道理,== 比较的是对象的实际地址,也就是判断两个引用对象是否是同一个对象,而字符串是不可变的,拼接实际上是创建一个新的对象,因此 s1 与 s2 本应该是两个不同的对象,但输出却不是 false 而是 true。
这是因为 java 对 String 类对象做了特殊的优化:
-
java 会有一个专门的地方用来放字符串,如果创建的字符串不是特别长,而且整个程序运行的时候,字符串创建也没有太多时,就把这些创建的字符串放到一个地方。当你创建一个新的字符串时,Java 会先去那个地方去找,看有没有一样的字符串,如果有的话,就直接返回这个字符串的引用,而不重新创建一个字符串。
这是因为本来 String 类的对象就是不可变的,你即便创建一个新的 String 对象,和沿用之前创建的(值一样的)是没有任何区别的。所以 java 可以放心地做这种事情。
所以 s1 和 s2 实际上指向的就是同一个对象。
但 java 对 String 的优化也是有限制的,如果太长了,突破了这个限制,比如创建的 s1 很长很长,s2 也很长很长,那么即便已经创建了 s1,s2 的值和 s1 一样,但仍旧会给 s2 重新创建一个新的对象。此时,用
==判断,则 s1 与 s2 是不相同的。但用equals()判断,因为值实际是一样的,所以 s1 与 s2 是相等的。Kevin:对上面这个“限制”的说法,Kevin 表示存疑。因为实际上试过很长很长的(IDEA中String声明中赋值的常量字符串最多不超过65535字符,否则报错:常量字符串过长。所以就用了极限不报错的长度),但仍然
==的结果为 true。再次尝试测试代码如下:
import java.util.Scanner;public class StringEqualsTest {public static void main(String[] args) {String s1 = "aaabbb";String s2 = "aaa" + "bbb";System.out.println("用 == 判断结果:"+(s1 == s2)); // trueSystem.out.println("用 equals 判断结果:"+ s1.equals(s2)); // trueScanner scanner = new Scanner(System.in);System.out.println("请输入 s3:");String s3 = scanner.nextLine(); // 输入 aaabbbSystem.out.println("请输入 s4:");String s4 = scanner.nextLine(); // 输入 aaabbbSystem.out.println("用 == 判断结果:" + (s3 == s4)); // falseSystem.out.println("用 equals 判断结果:" + s3.equals(s4)); // trueSystem.out.println("s1 == s3:"+(s1==s3)); // falseSystem.out.println("s1.equals(s3):"+s1.equals(s3)); // trueString s5 = new String("aaabbb");String s6 = new String("aaabbb");System.out.println("用 == 判断结果:" + (s5 == s6)); // falseSystem.out.println("用 equals 判断结果:" + s5.equals(s6)); // trueSystem.out.println("用 == 判断结果:" + (s1 == s5)); // falseSystem.out.println("用 equals 判断结果:" + s1.equals(s5)); // trueSystem.out.println("用 == 判断结果:" + (s3 == s5)); // falseSystem.out.println("用 equals 判断结果:" + s3.equals(s5)); // trueStringBuilder s7 = new StringBuilder("aaa");StringBuilder s8 = new StringBuilder("aaa");s7.append("bbb");s8.append("bbb");System.out.println(s7==s8); // falseSystem.out.println(s7.toString()==s8.toString()); // falseSystem.out.println(s7.toString().equals(s8)); // falseSystem.out.println(s7.toString().equals(s8.toString())); // trueSystem.out.println(s7.toString()==s1); // falseSystem.out.println(s7.toString().equals(s1)); // true} }发现,只要是通过 Scanner 输入的字符串、或者
new String()创建的字符串,无论多短,即便值相同,也不会是同一个对象,即==永远为 false。Kevin:所以一开始的 s1 与 s2 之所以相等,和字符串长度应该没有关系,当然这也的确有 java 对 String 类的优化在里面。但这里主要应该是因为
String s1 = "aaabbb";中"aaabbb"是显式字符串常量(而不被认为是对象,对象应该放于堆中),存放在常量池里。但new String("aaabbb")存放在内存的堆中。而无论是new String()、new StringBuilder()还是 Scanner的nextLine()实际上都创建了新的 String 对象,只是对象中存放的值相等罢了,所以 java 对 String 的优化仅仅是用在了 “显式字符串常量” 上,而与字符串长短无关。
鉴于这种不统一的表现,用 == 来判断两个引用指向的字符串是否相等是不靠谱的。
因此在实际判断两个 String 类对象是否相等,应该使用 equals() 而非 ==。
为什么要重写 hashCode 和 equals 方法
重写(覆盖)前 hashCode() 和 equals() 的作用
重写前,equals() 与 hashCode() 源代码如下(由于 hashCode() 是 native method,所以在 java 源代码中没有方法体):
// Object 类中的 equals(),效果是直接判断两个对象是否为同一个对象
public boolean equals(Object obj) {return (this == obj);
}// Object 类中的 hashCode(),效果是根据对象的存储地址转换为一个哈希值(int 类型值)
@IntrinsicCandidate
public native int hashCode();
什么情况下需要重写(覆盖) hashCode() 和 equals() ?
可以看到,Object 的 equals() 真的没什么意义,仅仅是判断这个对象是不是它自己,而业务中,我们通常是需要对比的是两个不同的对象,比较它们的业务逻辑意义上是否相同,即它们包含的数据是否相同。如果相同则判断它们相同,所以,equals() 需要根据程序员自己的业务逻辑去覆盖,仅仅沿用 Object 中定义的 equals() 意义不大。
同样,Object 中的 hashCode() 是根据对象的实际地址映射出来的一个 int 整数,如果用 hashCode() 来判断两个对象是否相同也没有太大意义。因为除去有可能不同对象发生哈希碰撞,判断的仍旧仅仅是这个对象是否是它自身。
所以“什么情况下需要重写(覆盖) hashCode() 和 equals() ?”的答案是:根据具体业务需求来重写这两个方法。
为什么重写equals() 方法一定要重写 hashCode() 方法
那么问题来了,如果现在想比较两个不同对象中包含的数据是否一致,如果一致,就判断两个对象相同,那么似乎只重写 equals() 就够了,在 equals() 中把两个对象的所有成员变量(或者业务逻辑中重视的那几个成员变量,即可以不将所有成员变量一一对比,而只对比你想对比的并依比较结果判断两个对象在业务逻辑上是否相等)挨个比较一下不就可以了吗?为什么还得把 hashCode() 重写呢?
原因是这样的:
-
很多时候,我们的需求不是光判断这两个对象所包含的数据是否相同,然后仅仅作出一个对象是否相同的判断。这个行为背后是有下一步的,比如说:在 java 的一个容器里,容器中的对象是不允许重复的,而是否重复,就是由 hashCode 来判断。比如 HashSet 或者 HashMap 的 key,是不允许重复的。现在的场景可能是,我需要往一个这样的容器中放入对象,如果对象是和容器中已经存在的对象相同,我就让它覆盖,如果不同,那就正常放入这个新的对象。
比如说容器里的对象只有一个 age 属性,现在存在 A 对象和 B 对象,A.age = 13; B.age = 13,那么这两个对象就应该判断为相同的(通过重写
equals()),但是如果不重写hashCode(),那么这两个对象因为内存地址是不同的,也就是说hashCode()的返回值是不同的,就会被 java 认为是不同的两个对象,可以同时放入到这个容器中,而不会发生覆盖行为。HashMap: 是一个散列表,它存储的内容是键值对(key-value)映射。该类实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
HashSet: 可以认为 HashSet 是简化版的 HashMap,但存储的内容不是键值对(key-value)映射,可以认为 HashSet 仅仅实现了 key 的部分。该类实现了 Set 接口,不允许出现重复元素,不保证集合中元素的顺序,允许包含值为 null 的元素,但最多只能一个。
下面看一个只重写 equals() ,而不重写 hashCode() 的例子:
// 只重写 equals() ,而不重写 hashCode()
public class Dog {private String name;public Dog(String name) {this.name = name;}// 重写 equals()@Overridepublic boolean equals(Object o) {if (this == o) return true;if (!(o instanceof Dog)) return false;Dog dog = (Dog) o;return name.equals(dog.name);}@Overridepublic String toString() {return "{ Dog: " + name + " }";}}// 调用类
import java.util.HashSet;public class TestUse {public static void main(String[] args) {Dog a = new Dog("Tom");Dog b = new Dog("Tom");Dog c = new Dog("Jerry");System.out.println(a == b); // falseSystem.out.println(a.equals(b)); // trueSystem.out.println(a == c); // falseSystem.out.println(a.equals(c)); // falseHashSet hashset = new HashSet();hashset.add(a);hashset.add(b);hashset.add(c);System.out.println(hashset); // [{ Dog: Jerry }, { Dog: Tom }, { Dog: Tom }]}
}
// 输出结果:
// false
// true
// false
// false
// [{ Dog: Jerry }, { Dog: Tom }, { Dog: Tom }]// 这样就很别扭了,a 和 b 应该是当作同一只狗的,但方法 hashset 里却没有覆盖掉。
下面再看一个同时重写了 equals() 与 hashCode() 的例子:
import java.util.Objects;public class Dog {private String name;public Dog(String name) {this.name = name;}// 重写 equals()@Overridepublic boolean equals(Object o) {if (this == o) return true;if (!(o instanceof Dog)) return false;Dog dog = (Dog) o;return name.equals(dog.name);}// 重写 hashCode()// 现在一般都不自己重写 hashCode(),都把它交给 IDEA 去自动生成,因为 hashCode 已经有一套相对标准的生成流程了,我们只需要让 IDEA 帮我们生成就好。@Overridepublic int hashCode() {return Objects.hash(name); // 用一个静态方法 Objects.hash()来生成哈希码}@Overridepublic String toString() {return "{ Dog: " + name + " }";}
}// 调用类
import java.util.HashSet;public class TestUse {public static void main(String[] args) {Dog a = new Dog("Tom");Dog b = new Dog("Tom");Dog c = new Dog("Jerry");System.out.println(a == b); // falseSystem.out.println(a.equals(b)); // trueSystem.out.println(a == c); // falseSystem.out.println(a.equals(c)); // falseHashSet hashset = new HashSet();hashset.add(a);hashset.add(b);hashset.add(c);System.out.println(hashset); // [{ Dog: Tom }, { Dog: Jerry }]}
}
// 输出结果:
// false
// true
// false
// false
// [{ Dog: Tom }, { Dog: Jerry }]// 这样一来,就可以覆盖掉相同的对象了,业务逻辑就变得合理了。
自动覆盖 equals() 与 hashCode()
其实在 IDEA 中,可以直接让 IDEA 自动生成覆盖的 equals() 与 hashCode():
-
源代码空白处鼠标右击 -->
Generate...(Alt + Insert)-->equals() and hashCode()。里面的选项见到的都打勾就好了。
toString() 方法
toString() 就是把类里的信息(通过生成 String)描述出来。
自动覆盖 toString()
其实在 IDEA 中,可以直接让 IDEA 自动生成覆盖的 toString() :
-
源代码空白处鼠标右击 -->
Generate...(Alt + Insert)-->toString()。选择要描述的属性(可以选择其中几个或全选),然后点击
OK。
// 自动生成的 toString() 类似下面格式:
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' + // 其实这里的 name(指标黑色的成员变量)其实就是调 toString() 方法得到一个 String,然后拼接。
'}';
}// 如果这些属性本身是引用类型,其实就是调用它们的 toString 方法返回一个 String,然后再把这些 String 拼接。
// 或许在 java 程序中显式地看到 toString() 的调用并不多,但实际上对 toString(默默地调用还是很多的。
toString() 方法不仅仅是在调用的时候有用,在 debug 时,IDEA 其实也会调用对象的 toString() 方法帮我们获取到这个对象的状态信息并展示出来,方便我们调试。(如 debug 时,显示在每行运行过的源代码右边的灰色的信息,其实调用的就是 toString(),底部的监控信息也是调用的 toString(),当然下方的对象信息还可以进一步点击左方的尖括号展开看对象信息,但没展开前实际上就是调用的 toString(),和我们定义的 toString() 的格式一致,帮助我们看到有数据的类的 实例/对象 里面是什么数据)

public class Dog {private String name;public Dog(String name) {this.name = name;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (!(o instanceof Dog)) return false;Dog dog = (Dog) o;return name.equals(dog.name);}@Overridepublic int hashCode() {return Objects.hash(name);}// 覆盖定义的 toString()@Overridepublic String toString() {return "Dog{" +"name='" + name + '\'' +'}';}
}
Objects 类
Objects 类与 Object 类是不同的,要注意区别。查看 Objects 类的继承关系,会发现 Objects 类也是继承自 Object 类的。
Object(java.lang)||--- Objects(java.util)
使用 java.lang 包的类是无需导入的,但使用 java.util 包里的类是需要 import 导入的。
再看看两个相似但不同的函数:equals()
// Objects 类里的 equals()
public static boolean equals(Object a, Object b) { return (a == b) || (a != null && a.equals(b));
}// Object 类里的 equals()
public boolean equals(Object obj) { return (this == obj);
}可以看到 Objects 类里的 equals() 是静态方法,而 Object 类里的 equals() 是实例方法。
而且从程序逻辑来说,Object 的 .equals() 是判断两个对象是不是同一个对象(使用 ==),而 Objects.equals() 则是会判断两个对象是不是同一个对象或非空的情况下调用 Object 的 .equals()。
相关文章:
java篇 类的进阶0x0A:万类之祖:Object 类
文章目录 万类之祖:Object 类hashCode() 与 equals()hashCode() 方法equals() 方法 vs. equals()String 的 equals() 为什么要重写 hashCode 和 equals 方法重写(覆盖)前 hashCode() 和 equals() 的作用什么情况下需要重写(覆盖&a…...

AVFoundation - 音频录制
文章目录 需要调用到麦克风方法,别忘记添加 Privacy - Microphone Usage Description @interface AudioRecorder ()<AVAudioRecorderDelegate>@property (strong, nonatomic) AVAudioRecorder *recorder;@end@implementation AudioRecorder- (void...
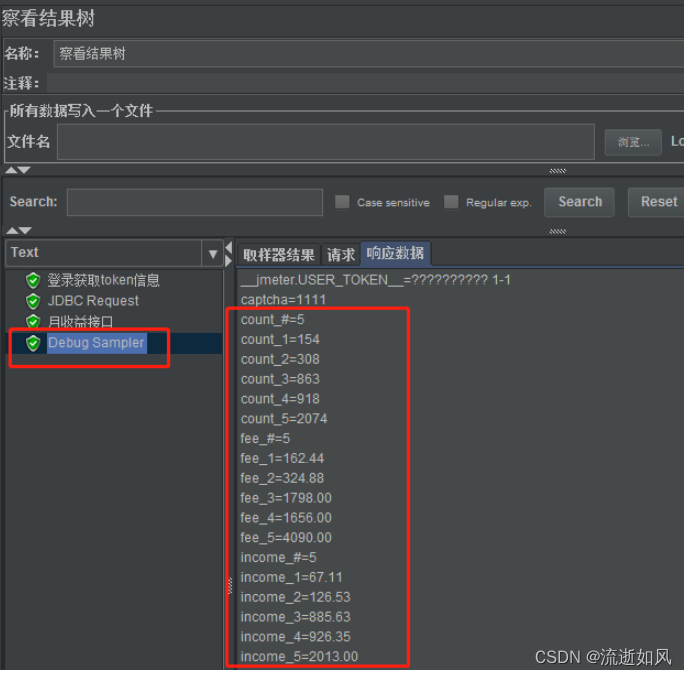
Jmeter+MySQL链接+JDBC Connection配置元件+使用
参考大大的博客学习:怎么用JMeter操作MySQL数据库?看完秒懂!_jmeter mysql_程序员馨馨的博客-CSDN博客 注:里面所有没打码的都是假数据,麻烦大家自行修改正确的信息。 一、背景 需要取数据库中的值,作为…...
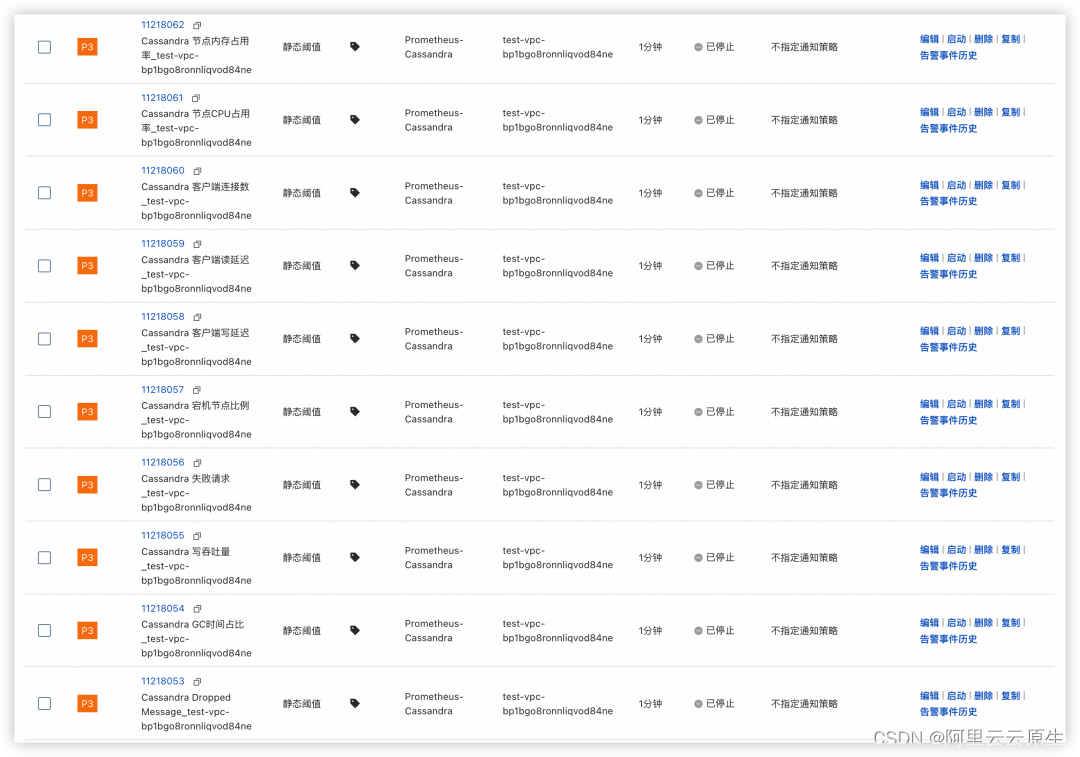
统一观测丨使用 Prometheus 监控 Cassandra 数据库最佳实践
作者:元格 本篇内容主要包括四部分:Cassandra 概览介绍、常见关键指标解读、常见告警规则解读、如何通过 Prometheus 建立相应监控体系。 Cassandra 简介 Cassandra 是什么? Apache Cassandra 是一个开源、分布式、去中心化、弹性可伸缩、…...

Hive视图
hive的视图 简介 hive的视图简单理解为逻辑上的表hive只支持逻辑视图,不支持物化视图视图存在的意义 对数据进行局部暴露(涉及隐私的数据不暴露)简化复杂查询 创建视图: create view if not exists v_1 as select uid,movie f…...

node中使用jsonwebtoken实现身份认证
在现代web应用中,用户身份认证是非常重要且必不可少的一环。而使用Node.js和Express框架,可以方便地实现用户身份认证。而在这个过程中,jsonwebtoken这个基于JWT协议的模块可以帮助我们实现安全且可靠的身份认证机制,可以让我们轻…...

pyspark笔记:读取 处理csv文件
pyspark cmd上的命令 1 读取文件 1.1 基本读取方式 注意读取出来的格式是Pyspark DataFrame,不是DataFrame,所以一些操作上是有区别的 1.1.1 format DataFrame spark.read.format("csv").option(name,value).load(path) format表示读取…...
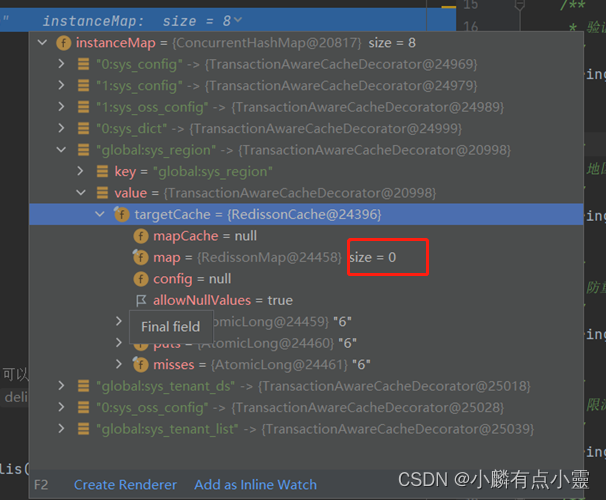
多租户分缓存处理
多租户redis缓存分租户处理 那么数据库方面已经做到了拦截,但是缓存还是没有分租户,还是通通一个文件夹里, 想实现上图效果,global文件夹里存的是公共缓存。 首先,那么就要规定一个俗称,缓存名字带有globa…...
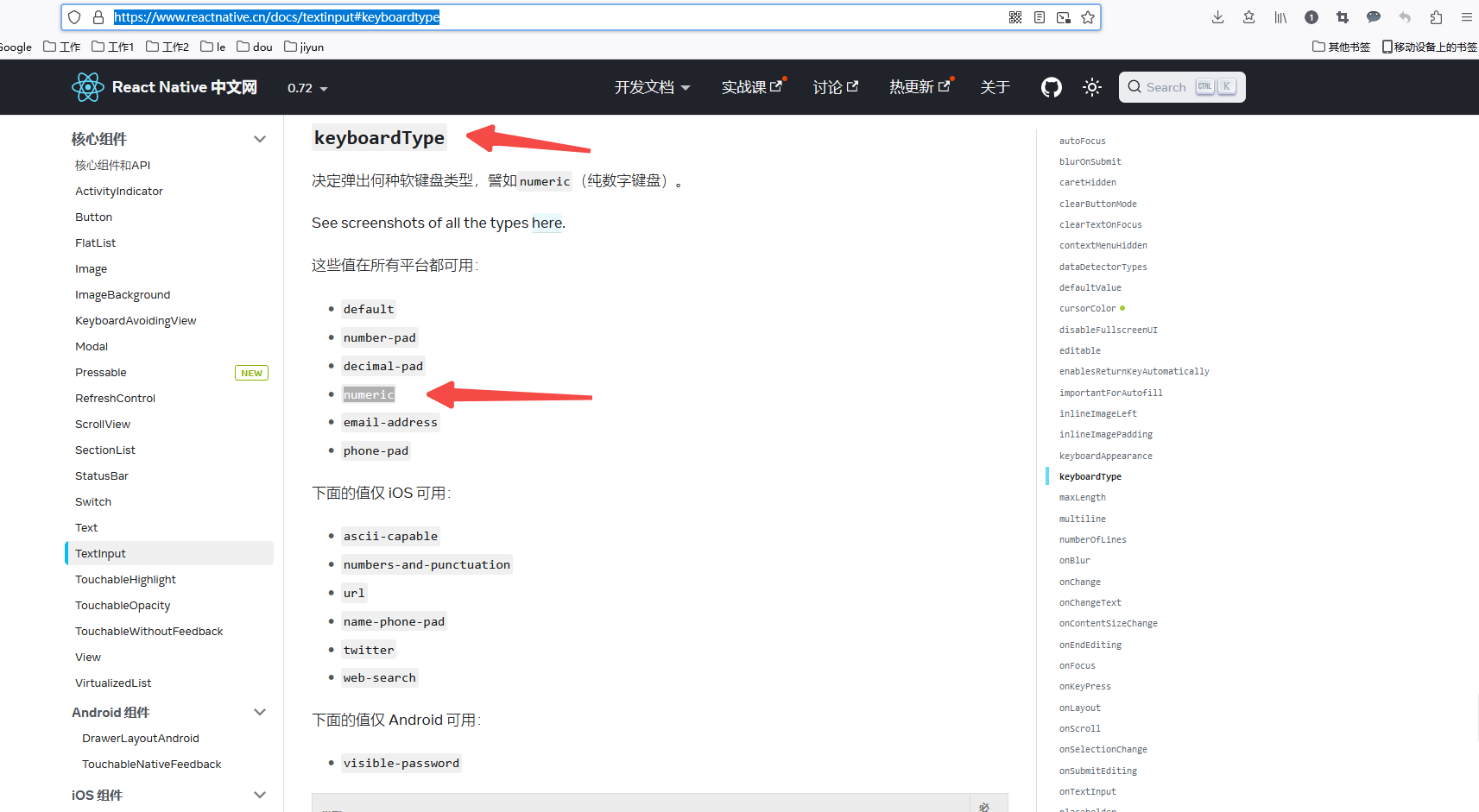
RN输入框默认设置数字键盘
<TextInput keyboardType"numeric"/> keyboardType 决定弹出何种软键盘类型,譬如numeric(纯数字键盘)。 See screenshots of all the types here. 这些值在所有平台都可用: defaultnumber-paddecimal-padnume…...

计算机网络——应用层
文章目录 **1 网络应用模型****2 域名系统DNS****3 文件传输协议FTP****4 电子邮件****4.1 电子邮件系统的组成结构****4.2 电子邮件格式与MIME****4.3 SMTP和POP3** **5 万维网WWW****5.1 HTTP** 1 网络应用模型 客户/服务器模型 C/S 服务器服务于许多来自其他称为客户机的主…...

【C++】写一个函数实现系统时间与输入时间进行比较
目录 1 代码 2 运行结果 时间比较函数: 输入为字符串2023-7-28,将字符串分解为年、月、日信息。 获取系统时间2023-7-24,然后将输入时间和系统时间进行比较,输出比较结果。 1 代码 #include <ctime> #include<iostream> #include<vector> using names…...
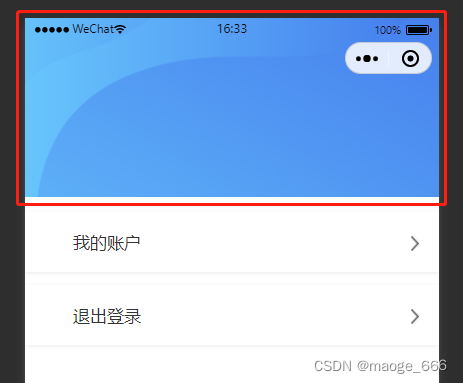
uniapp 微信小程序 navigationBarBackgroundColor 标题栏颜色渐变
大体思路: 第一步:“navigationStyle”:“custom” 第二步: template内 重点:给view添加ref“top” 第三步:添加渐变色样式 1、pages.json {"path" : "pages/user/user","style" : …...
----音视频暂停模块分析)
ffplay播放器剖析(7)----音视频暂停模块分析
文章目录 1. 暂停触发流程2. toggle_pause3. stream_toggle_pause 1. 暂停触发流程 1.通过SDL触发事件调用toggle_pause 2.toggle_pause调用stream_toggle_pause 3.stream_toggle_pause修改暂停变量 2. toggle_pause static void toggle_pause(VideoState *is) {stream_to…...
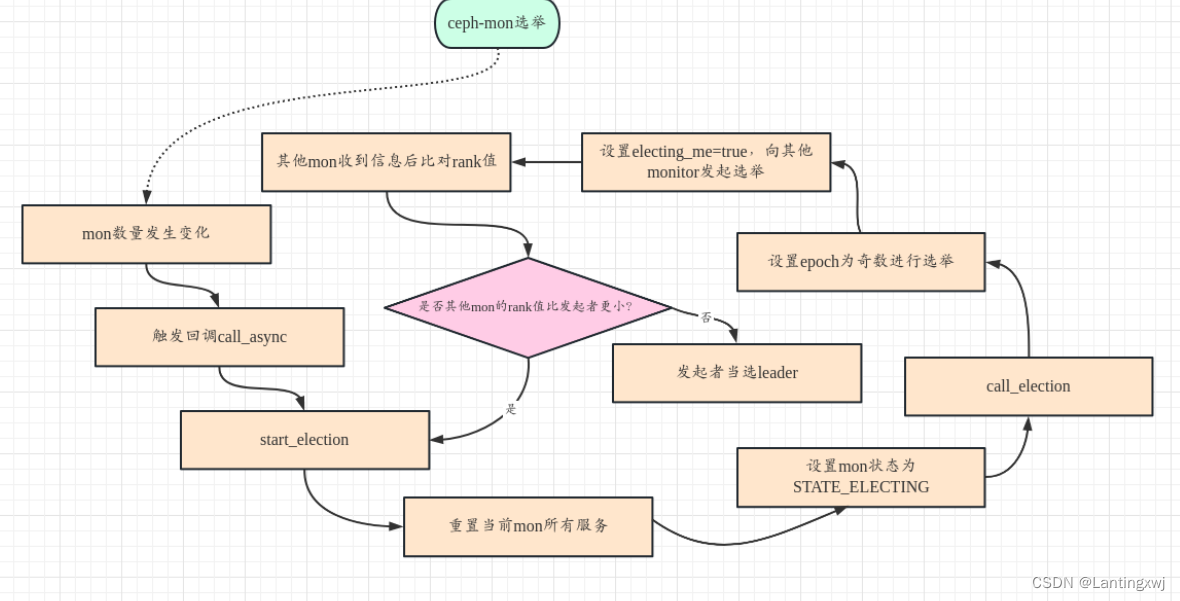
ceph-mon运行原理分析
一、流程:ceph-deploy部署ceph-mon组建集群 1.ceph-deploy部署ceph-mon的工作流程及首次启动 1)通过命令创建ceph-mon,命令为:ceph-deploy create mon keyring def mon(args):if args.subcommand create:mon_create(args)elif…...
听GPT 讲K8s源代码--pkg(八)
k8s项目中 pkg/kubelet/envvars,pkg/kubelet/events,pkg/kubelet/eviction,pkg/kubelet/images,pkg/kubelet/kubeletconfig这些目录都是 kubelet 组件的不同功能模块所在的代码目录。 pkg/kubelet/envvars 目录中包含了与容器运行…...

差速驱动机器人的车轮里程计模型
一、说明 车轮测程法是指使用旋转编码器(即连接到车轮电机以测量旋转的传感器)的测程法(即估计运动和位置)。这是轮式机器人和自动驾驶汽车定位的有用技术。 在本文中,我们将通过探索差速驱动机器人的车轮里程计模型来深入研究车轮里...

Pytorch个人学习记录总结 09
目录 损失函数与反向传播 L1Loss MSELOSS CrossEntropyLoss 损失函数与反向传播 所需的Loss计算函数都在torch.nn的LossFunctions中,官方网址是:torch.nn — PyTorch 2.0 documentation。举例了L1Loss、MSELoss、CrossEntropyLoss。 在这些Loss函数…...

代码随想录算法训练营day51 309.最佳买卖股票时机含冷冻期 714.买卖股票的最佳时机含手续费
题目链接309.最佳买卖股票时机含冷冻期 class Solution {public int maxProfit(int[] prices) {if (prices null || prices.length < 2) {return 0;}int[][] dp new int[prices.length][2];dp[0][0] -prices[0];dp[0][1] 0;dp[1][0] Math.max(dp[0][0], dp[0][1] - pr…...

做UI设计需要具备什么平面技能呢优漫动游
想要成为一名合格的UI设计师,那么需要学会的技能是非常多的,UI设计包含的知识点也比较多,那么具体做UI设计需要具备什么技能呢?来看看下面小编的详细介绍吧。 —、软件能力 一位好的ui设计师除了需要精通Photoshop.IlustratorDW.C4D等设…...
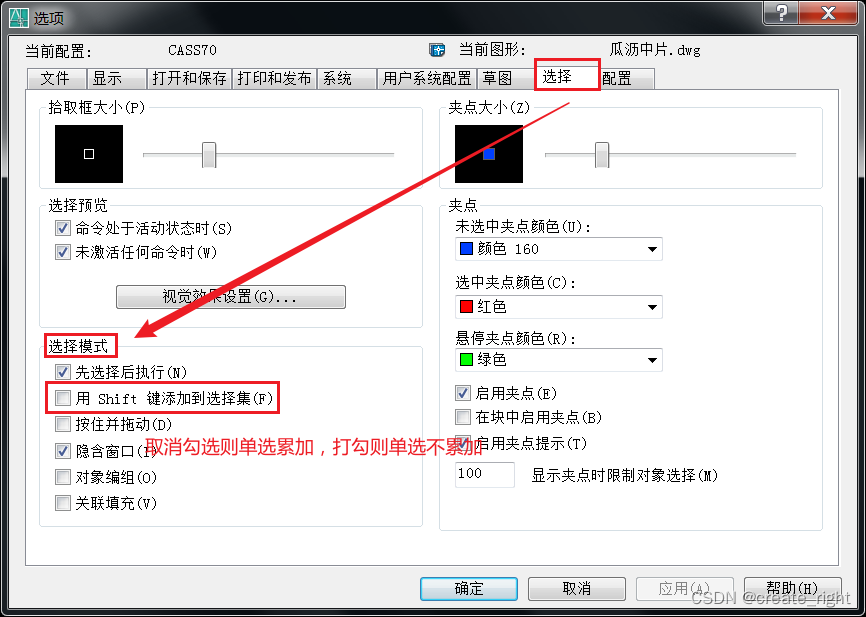
cass--单选不累加设置
打开软件,在空白处右击--选项--选择,如下: 完成后,点击确定按钮即可。...

暗黑3按键助手终极指南:5分钟配置,彻底告别手酸烦恼
暗黑3按键助手终极指南:5分钟配置,彻底告别手酸烦恼 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑破坏神3中繁复…...

)
数据分析之物化视图(Materialized View)
在数据分析场景中,随着数据量激增和查询复杂度提升,传统视图的性能瓶颈日益凸显,物化视图(Materialized View,简称MV)作为“预计算物理存储”的优化方案,成为提升数据分析效率的核心工具。它本质…...

猫抓浏览器扩展终极指南:3分钟掌握网页视频音频下载技巧
猫抓浏览器扩展终极指南:3分钟掌握网页视频音频下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&am…...

Qwen3-4B-Thinking多场景落地:医疗IT系统自然语言转HL7/FHIR指令
Qwen3-4B-Thinking多场景落地:医疗IT系统自然语言转HL7/FHIR指令 1. 引言:当医生说话,系统能听懂吗? 想象一下这个场景:一位医生在查房时,对身边的护士说:“给3床的李明开个血常规,…...

当CANopen遇上EtherCAT:用倍福EL6751网关连接伺服驱动器的实战心得
当CANopen遇上EtherCAT:用倍福EL6751网关连接伺服驱动器的实战心得 在工业自动化领域,EtherCAT凭借其高实时性和拓扑灵活性已成为主流总线协议,而CANopen则因其成熟稳定在中小型设备中广泛应用。当需要将支持CANopen协议的伺服驱动器…...
ClearerVoice-Studio多场景落地:直播回放降噪、远程会议分离、访谈提取
ClearerVoice-Studio多场景落地:直播回放降噪、远程会议分离、访谈提取 1. 开箱即用的语音处理利器 在日常工作和内容创作中,我们经常遇到这样的困扰:直播回放背景噪音太大影响观看体验,远程会议多人同时发言难以听清࿰…...

SEO推广合作价目表对网站排名有什么影响_SEO推广合作价目表的合理定价原则是什么
SEO推广合作价目表对网站排名有什么影响 在当今数字化时代,网站的SEO推广合作价目表不仅仅是企业与营销公司之间的商业协议,更是影响网站在搜索引擎上排名的一个重要因素。SEO推广合作价目表如何制定,对于提升网站的搜索引擎排名有着至关重要…...

REX-UniNLU C++高性能集成:模型推理加速方案
REX-UniNLU C高性能集成:模型推理加速方案 1. 为什么在C里跑NLU模型是个现实需求 很多做企业级文本处理的朋友都遇到过类似情况:业务系统用C写的,性能要求高、响应要快、不能随便加新语言栈。这时候突然需要接入一个中文NLP能力——比如从客…...

BGE-Reranker-v2-m3能否替代BM25?语义检索对比评测
BGE-Reranker-v2-m3能否替代BM25?语义检索对比评测 在构建智能问答、文档检索这类系统时,我们常常面临一个核心难题:如何从海量文档中,精准地找到用户真正需要的那几段信息?传统的关键词匹配方法,比如BM25…...