hive之文件格式与压缩

hive文件格式:
概述:
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择text file、orc、parquet、sequence file等。
文本文件:
文本文件就是txt文件,我们默认的文件类型就是txt文件
ORC文件:
ORC介绍:
ORC(Optimized Row Columnar)file format是Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高Hive读写数据和处理数据的性能。
我们文件一般都是一个二维表,行式存储就是以一行数据为一个单位,存储在相邻的位置,列示存储是以一列数据为单位,一个单位内的数据放在相邻的位置。
如下图两种方式的比较:
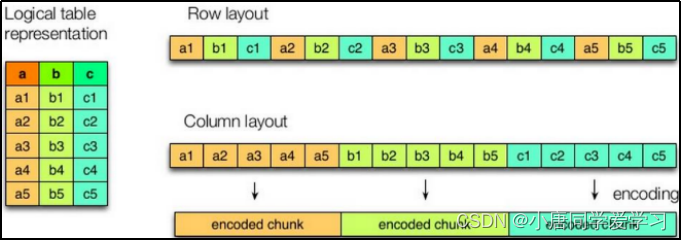
在日常使用的时候hive查询出来的大部分是大量列信息,少量使用where进行条件查询
orc格式在存储的过程中会在hive表上进行横向切分,分割成两次分别进行列式存储
对分割后的数据进行列式存储时,会把它存储到orc文件的一个strip(条带)中,剩下的数据存入其他条带中,条带中并不止存对应的列,还存有一个indexdata--索引(存放每列区(column)的最大值,最小值,行位置)(可以减少大量io操作)默认10000行记录一个索引。
在文件最后还存有一个StripeFooter(存放每个column的编码信息---在存入orc文件的时候并不会按照原表进行存储而是会进行编码存储)
在文件开头有一个header:ORC(可以用于判断文件类型)
文件的底部还有一个FileFooter(存储的有header的长度,各Strip的信息:strips的起始位置,索引长度,数据的长度,StripsFooter的长度等,还存储有各column的统计信息:最值,hashNull)
ORC文件还有一个PostScript,保存这FileFooter的长度,文件压缩的参数,文件的版本等信息。
还有一个区域用于保存Postscrip的长度(文件的最后一个字节)

读取ORC文件步骤:
一般读取ORC文件是从文件末尾开始,先进行读取最后一个字节(Postscript的长度),再通过得到的长度从倒数第二个字节进行向前推到Postscript的起始位置开始读取,从Postscript的数据中的得到File Footer的长度,再进行向前推进行访问,让后就可以根据File Footer中的内容进行定位。
建表语句:
create table orc_table
(column_specs)
stored as orc
tblproperties (property_name=property_value, ...);column_speccs是建表语句
tblproperties (property_name=property_value, ...)是一些建表的参数
| 参数 | 默认值 | 说明 |
| orc.compress | ZLIB | 压缩格式,可选项:NONE、ZLIB,、SNAPPY |
| orc.compress.size | 262,144(256kb) | 每个压缩块的大小(ORC文件是分块压缩的) |
| orc.stripe.size | 67,108,864(64MB一般与Hadoop中的块大小一致Hadoop2.x后是128MB) | 每个stripe的大小 |
| orc.row.index.stride | 10,000 | 索引步长(每隔多少行数据建一条索引) |
eg:
create table orc_table
( id int,name string
)
stored as orc;在导入数据的时候不能从文本文件load到orc文件(因为load其实是文件的复制,是带有格式的,在导入的时候是没有关系的,但是在读的是时候是不能正确读出的)
文本文件数据如何导入到orc格式的表中?
我们可以建立一个临时表,把文本文件中的数据导入到临时表中,通过insert+select的方式进行导入。(走计算)
Parquet文件:
Parquet文件是Hadoop生态中的一个通用的文件格式,它也是一个列式存储的文件格式。
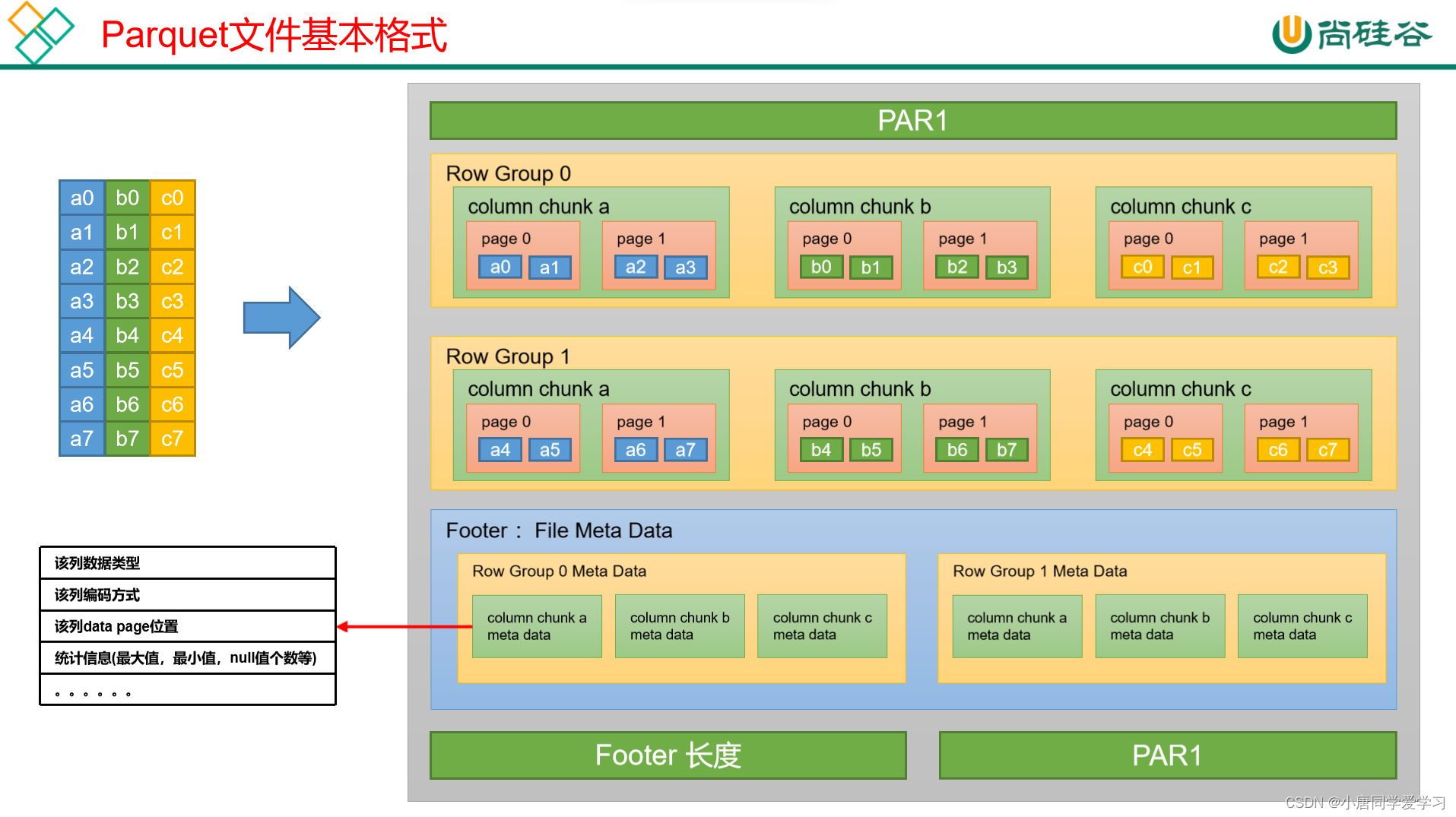
Parquet文件也会对表进行横向切分,切分后会存入到行组中(Row Group),在行组中的数据的每个列都形成一个列块(column chunk)列块中的数据会再分为页块(page)。
最后还有Footer(File Meta Data)中存储了每个行组(Row Group)中的每个列快(Column Chunk)的元数据信息,元数据信息包含了该列的数据类型、该列的编码方式、该类的Data Page位置等信息。File Meta Data中的Row Group的数量是与上边Row Group进行一一对应的。
在Parquet文件的开头与结尾都会占用4个字节进行存储 PAR1 (是Parquet的简写+版本号)
还会在下边保存Footer的长度
详细如图:
Parquet文件基本语法:
Create table parquet_table
(column_specs)
stored as parquet
tblproperties (property_name=property_value, ...);支持的参数如下:
| 参数 | 默认值 | 说明 |
| parquet.compression | uncompressed | 压缩格式,可选项:uncompressed,snappy,gzip,lzo,brotli,lz4 |
| parquet.block.size | 134217728 (128mb) | 行组大小,通常与HDFS块大小保持一致 |
| parquet.page.size | 1048576(1m) | 页大小 |
eg:
create table parquet_table
( id int,name string
)
stored as parquet ;
压缩:
Hive表数据进行压缩:
在Hive表中和计算过程中,保持数据的压缩,对磁盘空间的有效利用和提高查询性能都是十分有益的。
注:在Hive中,不同文件类型的表,声明数据压缩的方式是不同的。
1)TextFile
若一张表的文件类型为TextFile,若需要对该表中的数据进行压缩,多数情况下,无需在建表语句做出声明。直接将压缩后的文件导入到该表即可,Hive在查询表中数据时,可自动识别其压缩格式,进行解压。
我们怎么让我们的hive表是压缩的那?
(1)我们使用load语句,load的原表就是一个压缩的文件,可以直接进行压缩
(2)使用insert into 语句,如果使用这种方式就需要进行设置参数。
需要注意的是,在执行往表中导入数据的SQL语句时,用户需设置以下参数,来保证写入表中的数据是被压缩的。
--SQL语句的最终输出结果是否压缩
set hive.exec.compress.output=true;
--输出结果的压缩格式(以下示例为snappy)
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;2)ORC
若一张表的文件类型为ORC,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下:
create table orc_table
(column_specs)
stored as orc
tblproperties ("orc.compress"="snappy");3)Parquet
若一张表的文件类型为Parquet,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下:
create table orc_table
(column_specs)
stored as parquet
tblproperties ("parquet.compression"="snappy");计算过程中使用压缩:
计算过程就是mapreduce的过程。
1)单个MR的中间结果进行压缩:
这个就是在map阶段后(shuffer)的数据进行压缩,压缩后可以 降低shuffle阶段的网络IO
参数如下:
--开启MapReduce中间数据压缩功能
set mapreduce.map.output.compress=true;
--设置MapReduce中间数据数据的压缩方式(以下示例为snappy)
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;2)单条SQL语句的中间结果进行压缩:
这里指的是有些SQL语句是比较复杂的需要多个MR阶段,则会对两个MR之间的临时数据进行压缩
可通过以下参数进行配置:
--是否对两个MR之间的临时数据进行压缩
set hive.exec.compress.intermediate=true;
--压缩格式(以下示例为snappy)
set hive.intermediate.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;相关文章:
hive之文件格式与压缩
hive文件格式: 概述: 为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择text file、orc、parquet、sequence file等。 文本文件: 文本文件就是txt文件&…...
云原生容器内的一次pg_repack排错和解决过程
postgresql的pg_repack 这个cronjob一直执行不了。 排错过程: 用命令 kubectl describe job pg-repack-scheduler-manual-wv82r -n xxx没有查看用有用信息想办法进它启动的pod查看,于是在执行pg_repack.sh命令前,先加一个睡眠时间,如下: - …...

Centos Certbot 使用
安装 可选配置:启动EPEL存储库 非必要项 yum install -y epel-release yum clean all yum makecache #启用可选通道 可以不配置 yum -y install yum-utils yum-config-manager --enable rhui-REGION-rhel-server-extras rhui-REGION-rhel-server-optional必要配置…...

VL163的基本信息
VL163是2:4差分通道多路复用/demux开关USB 3.1应用,为交换机信号性能支持高达USB 3.1,并使用QFN-28 3.5x4.5mm绿色封装。 VL163 QFN28 只能处理2Lane数据信号。自己没有CC识别沟通协议,如果要做USB-C Swtich,就要通过别的USB-C协…...
IntelliJ IDEA 2023.2 新版本,拥抱 AI
IntelliJ IDEA 近期连续发布多个EAP版本,官方在对用户体验不断优化的同时,也新增了一些不错的功能,尤其是人工智能助手补充,AI Assistant,相信在后续IDEA使用中,会对开发者工作效率带来不错的提升。 以下是…...
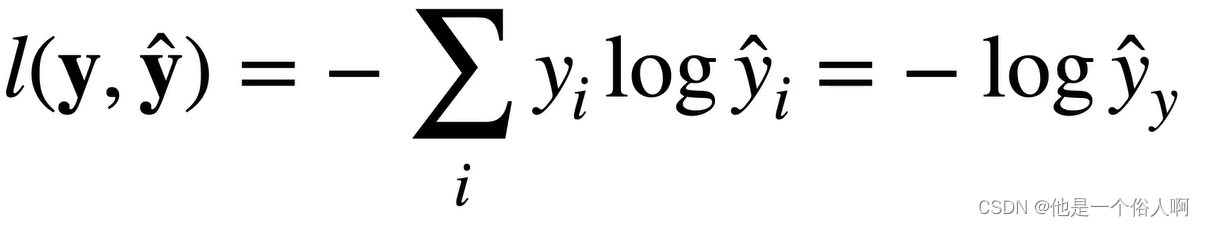
softmax回归
模型 softmax回归是多类分类模型,用于获取每个分类的置信度,置信度计算方式如下 经过全连接层,得到输出O,将O作为softmax的输入 O是输出向量,每个分量表示一个类别,y_hat_i表示i类别的置信度࿰…...

.NET 8 Preview 5推出!
作者:Jiachen Jiang 排版:Alan Wang 我们很高兴与您分享 .NET 8 Preview 5 中的所有新功能和改进!此版本是 Preview 4 版本的后续版本。在每月发布的版本中,您将看到更多新功能。.NET 6 和 7 用户可以密切关注此版本,而…...
Spring核心概念、IoC和DI的认识、Spring中bean的配置及实例化、bean的生命周期
初始Spring 一、Spring核心概念1.1IoC(Inversion of Contral):控制反转1.2IoC代码实现1.2DI代码实现 二、bean的相关操作2.1bean的配置2.1.1bean的基础配置2.1.2bean的别名配置2.1.3bean的作用范围配置 2.2bean的实例化 - - 构造方法2.3bean的实例化 - - 实例工厂与…...
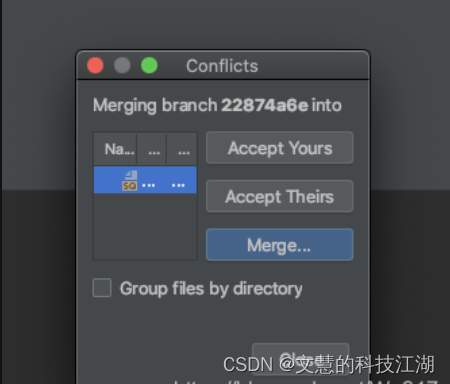
git冲突“accept theirs”和“accept yours”
Accept Yours 就是直接选取本地的代码,覆盖掉远程仓库的 Accept Theirs 是直接选取远程仓库的,覆盖掉自己本地的 我们选择Merge,自己手动行进选择、修改。 这里左边部分是你本地仓库的代码,右边部分是远程仓库的代码,中间的res…...
Vision Transformer (ViT)
生成式模型与判别式模型 生成式模型,又称概率模型,是指通过学习数据的分布来建立模型P(y|x),然后利用该模型来生成新的数据。生成式模型的典型代表是朴素贝叶斯模型,该模型通过学习数据的分布来建立概率模型,然后利用该模型来生成新的数据。判别式模型,又称非概率模型,…...
OpenGL Metal Shader 编程:解决图片拉伸变形问题
前面发了一些关于 Shader 编程的文章,有读者反馈太碎片化了,希望这里能整理出来一个系列,方便系统的学习一下 Shader 编程。 由于主流的 Shader 编程网站,如 ShaderToy, gl-transitions 都是基于 GLSL 开发 Shader ,加…...

[SQL挖掘机] - 字符串函数 - concat
介绍: concat函数用于连接字符串的函数。它接受多个字符串作为参数,并将它们按顺序连接起来形成一个新的字符串。 用法: 以下是concat函数的语法: concat(string1, string2, ...)其中,string1, string2, …是要连接的字符串参数。你可以传…...

Rust之所有权
1、所有权的概念: 程序需要管理自己在运行时使用的计算机内部空间。Rust语言采用包含特定规则的所有权系统来管理内存,这套规则允许编译器在编译的过程中执行检查工作,而不会产生任何的运行时开销。 (1)、所有权规则: Rust中的…...

RabbitMQ帮助类的封装
RabbitMQ帮助类的封装 基本部分 public class RabbitMQInvoker {#region Identy private static IConnection _CurrentConnection null;private readonly string _HostName null;private readonly string _UserName null;private readonly string _Password null;#endreg…...

mac 移动硬盘未正常退出,再次链接无法读取(显示)
(1)首先插入自己的硬盘,然后找到mac的磁盘工具 (2)打开磁盘工具,发现自己的磁盘分区在卸载状态;点击无法成功装载。 (3)打开终端,输入 diskutil list查看自…...
短视频账号矩阵系统源码开发部署路径
一、短视频批量剪辑的开发逻辑算法 1.视频剪辑之开发算法 自己研发视频剪辑是指通过对视频素材进行剪切、调整、合并等操作,利用后台计算机算法,进行抽帧抽组抽序进行排列以达到对视频内容进行修改和优化的目的。自己研发的视频剪辑工具可以通过后台码…...
前端 | ( 十一)CSS3简介及基本语法(上) | 尚硅谷前端html+css零基础教程2023最新
学习来源:尚硅谷前端htmlcss零基础教程,2023最新前端开发html5css3视频 系列笔记: 【HTML4】(一)前端简介【HTML4】(二)各种各样的常用标签【HTML4】(三)表单及HTML4收尾…...
Kafka入门到起飞系列 - 副本机制,什么是副本因子呢?
我们一直在讲一个主题会有多个分区,这多个分区可以分布在一台服务器上,也可以分布在多台服务器上,还可以增加分区(Kafka目前只支持分区),这是Kafka提供的一种横向扩展的手段 比如我们创建了一个主题&#x…...

2023年基准Kubernetes报告:6个K8s可靠性失误
云计算日益成为组织构建应用程序和服务的首选目的地。尽管一年来经济不确定性的头条新闻主要集中在通货膨胀增长和银行动荡方面,但大多数组织预计今年的云使用和支出将与计划的相同(45%),或高于计划的(45%)…...

程序员面试系列,k8s常见面试题
原文链接 一、什么是 Kubernetes?解释其主要功能和用途。 Kubernetes(通常简称为K8s)是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。它最初由谷歌开发,并于2014年捐赠给了云原生计算基金会&a…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...