模型转换 PyTorch转ONNX 入门
前言
本文主要介绍如何将PyTorch模型转换为ONNX模型,为后面的模型部署做准备。转换后的xxx.onnx模型,进行加载和测试。最后介绍使用Netron,可视化ONNX模型,看一下网络结构;查看使用了那些算子,以便开发部署。
目录
前言
一、PyTorch模型转ONNX模型
1.1 转换为ONNX模型且加载权重
1.2 转换为ONNX模型但不加载权重
1.3 torch.onnx.export() 函数
二、加载ONNX模型
三、可视化ONNX模型
一、PyTorch模型转ONNX模型
将PyTorch模型转换为ONNX模型,通常是使用torch.onnx.export( )函数来转换的,基本的思路是:
- 加载PyTorch模型,可以选择只加载模型结构;也可以选择加载模型结构和权重。
- 然后定义PyTorch模型的输入维度,比如(1, 3, 224, 224),这是一个三通道的彩色图,分辨率为224x224。
- 最后使用torch.onnx.export( )函数来转换,生产xxx.onnx模型。
下面有一个简单的例子:
import torch
import torch.onnx# 加载 PyTorch 模型
model = ...# 设置模型输入,包括:通道数,分辨率等
dummy_input = torch.randn(1, 3, 224, 224, device='cpu')# 转换为ONNX模型
torch.onnx.export(model, dummy_input, "model.onnx", export_params=True)
1.1 转换为ONNX模型且加载权重
这里举一个resnet18的例子,基本思路是:
- 首先加载了一个预训练的 ResNet18 模型;
- 然后将其设置为评估模式。接下来定义一个与模型输入张量形状相同的输入张量,并使用
torch.randn()函数生成了一个随机张量。 - 最后,使用
onnx.export()函数将 PyTorch 模型转换为 ONNX 格式,并将其保存到指定的输出文件中。
程序如下:
import torch
import torchvision.models as models# 加载预训练的 ResNet18 模型
model = models.resnet18(pretrained=True)# 将模型设置为评估模式
model.eval()# 定义输入张量,需要与模型的输入张量形状相同
input_shape = (1, 3, 224, 224)
x = torch.randn(input_shape)# 需要指定输入张量,输出文件路径和运行设备
# 默认情况下,输出张量的名称将基于模型中的名称自动分配
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 将 PyTorch 模型转换为 ONNX 格式
output_file = "resnet18.onnx"
torch.onnx.export(model, x.to(device), output_file, export_params=True)
1.2 转换为ONNX模型但不加载权重
举一个resnet18的例子:基本思路是:
- 首先加载了一个预训练的 ResNet18 模型;
- 然后使用
onnx.export()函数将 PyTorch 模型转换为 ONNX 格式;指定参数do_constant_folding=False,不加载模型的权重。
import torch
import torchvision.models as models# 加载 PyTorch 模型
model = models.resnet18()# 将模型转换为 ONNX 格式但不加载权重
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, "resnet18.onnx", do_constant_folding=False)
下面构建一个简单网络结构,并转换为ONNX
import torch
import torchvision
import numpy as np# 定义一个简单的PyTorch 模型
class MyModel(torch.nn.Module):def __init__(self):super(MyModel, self).__init__()self.conv1 = torch.nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)self.relu = torch.nn.ReLU()self.maxpool = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.flatten = torch.nn.Flatten()self.fc1 = torch.nn.Linear(64 * 8 * 8, 10)def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.maxpool(x)x = self.conv2(x)x = self.relu(x)x = self.maxpool(x)x = self.flatten(x)x = self.fc1(x)return x# 创建模型实例
model = MyModel()# 指定模型输入尺寸
dummy_input = torch.randn(1, 3, 32, 32)# 将PyTorch模型转为ONNX模型
torch.onnx.export(model, dummy_input, 'mymodel.onnx', do_constant_folding=False)1.3 torch.onnx.export() 函数
看一下这个函数的参数
torch.onnx.export(model, args, f, export_params=True, opset_version=10, do_constant_folding=True, input_names=['input'], output_names=['output'], dynamic_axes=None, verbose=False, example_outputs=None, keep_initializers_as_inputs=None)
model:需要导出的 PyTorch 模型args:PyTorch模型输入数据的尺寸,指定通道数、长和宽。可以是单个 Tensor 或元组,也可以是元组列表。f:导出的 ONNX 文件路径和名称,mymodel.onnx。export_params:是否导出模型参数。如果设置为 False,则不导出模型参数。opset_version:导出的 ONNX 版本。默认值为 10。do_constant_folding:是否对模型进行常量折叠。如果设置为 True,不加载模型的权重。input_names:模型输入数据的名称。默认为 'input'。output_names:模型输出数据的名称。默认为 'output'。dynamic_axes:动态轴的列表,允许在导出的 ONNX 模型中创建变化的维度。verbose:是否输出详细的导出信息。example_outputs:用于确定导出 ONNX 模型输出形状的样本输出。keep_initializers_as_inputs:是否将模型的初始化器作为输入导出。如果设置为 True,则模型初始化器将被作为输入的一部分导出。
下面是只是一个常用的模板
import torch.onnx # 转为ONNX
def Convert_ONNX(model): # 设置模型为推理模式model.eval() # 设置模型输入的尺寸dummy_input = torch.randn(1, input_size, requires_grad=True) # 导出ONNX模型 torch.onnx.export(model, # model being run dummy_input, # model input (or a tuple for multiple inputs) "xxx.onnx", # where to save the model export_params=True, # store the trained parameter weights inside the model file opset_version=10, # the ONNX version to export the model to do_constant_folding=True, # whether to execute constant folding for optimization input_names = ['modelInput'], # the model's input names output_names = ['modelOutput'], # the model's output names dynamic_axes={'modelInput' : {0 : 'batch_size'}, # variable length axes 'modelOutput' : {0 : 'batch_size'}}) print(" ") print('Model has been converted to ONNX')if __name__ == "__main__": # 构建模型并训练# xxxxxxxxxxxx# 测试模型精度#testAccuracy() # 加载模型结构与权重model = Network() path = "myFirstModel.pth" model.load_state_dict(torch.load(path)) # 转换为ONNX Convert_ONNX(model)二、加载ONNX模型
加载ONNX模型,通常需要用到ONNX、ONNX Runtime,所以需要先安装。
pip install onnxpip install onnxruntime加载ONNX模型可以使用ONNX Runtime库,以下是一个加载ONNX模型的示例代码:
import onnxruntime as ort# 加载 ONNX 模型
ort_session = ort.InferenceSession("model.onnx")# 准备输入信息
input_info = ort_session.get_inputs()[0]
input_name = input_info.name
input_shape = input_info.shape
input_type = input_info.type# 运行ONNX模型
outputs = ort_session.run(input_name, input_data)# 获取输出信息
output_info = ort_session.get_outputs()[0]
output_name = output_info.name
output_shape = output_info.shape
output_data = outputs[0]print("outputs:", outputs)
print("output_info :", output_info )
print("output_name :", output_name )
print("output_shape :", output_shape )
print("output_data :", output_data )以下是一个示例程序,将 resnet18 模型从 PyTorch 转换为 ONNX 格式,然后加载和测试 ONNX 模型的过程:
import torch
import torchvision.models as models
import onnx
import onnxruntime# 加载 PyTorch 模型
model = models.resnet18(pretrained=True)
model.eval()# 定义输入和输出张量的名称和形状
input_names = ["input"]
output_names = ["output"]
batch_size = 1
input_shape = (batch_size, 3, 224, 224)
output_shape = (batch_size, 1000)# 将 PyTorch 模型转换为 ONNX 格式
torch.onnx.export(model, # 要转换的 PyTorch 模型torch.randn(input_shape), # 模型输入的随机张量"resnet18.onnx", # 保存的 ONNX 模型的文件名input_names=input_names, # 输入张量的名称output_names=output_names, # 输出张量的名称dynamic_axes={input_names[0]: {0: "batch_size"}, output_names[0]: {0: "batch_size"}} # 动态轴,即输入和输出张量可以具有不同的批次大小
)# 加载 ONNX 模型
onnx_model = onnx.load("resnet18.onnx")
onnx_model_graph = onnx_model.graph
onnx_session = onnxruntime.InferenceSession(onnx_model.SerializeToString())# 使用随机张量测试 ONNX 模型
x = torch.randn(input_shape).numpy()
onnx_output = onnx_session.run(output_names, {input_names[0]: x})[0]print(f"PyTorch output: {model(torch.from_numpy(x)).detach().numpy()[0, :5]}")
print(f"ONNX output: {onnx_output[0, :5]}")
上述代码中,首先加载预训练的 resnet18 模型,并定义了输入和输出张量的名称和形状。
然后,使用 torch.onnx.export() 函数将模型转换为 ONNX 格式,并保存为 resnet18.onnx 文件。
接着,使用 onnxruntime.InferenceSession() 函数加载 ONNX 模型,并使用随机张量进行测试。
最后,将 PyTorch 模型和 ONNX 模型的输出进行比较,以确保它们具有相似的输出。
三、可视化ONNX模型
使用Netron,可视化ONNX模型,看一下网络结构;查看使用了那些算子,以便开发部署。
这里简单介绍一下
Netron是一个轻量级、跨平台的模型可视化工具,支持多种深度学习框架的模型可视化,包括TensorFlow、PyTorch、ONNX、Keras、Caffe等等。它提供了可视化网络结构、层次关系、输出尺寸、权重等信息,并且可以通过鼠标移动和缩放来浏览模型。Netron还支持模型的导出和导入,方便模型的分享和交流。
Netron的网页在线版本,直接在网页中打开和查看ONNX模型Netron
开源地址:GitHub - lutzroeder/netron: Visualizer for neural network, deep learning, and machine learning models

支持多种操作系统:
macOS: Download
Linux: Download
Windows: Download
Browser: Start
Python Server: Run pip install netron and netron [FILE] or netron.start('[FILE]').
下面是可视化模型截图:

还能查看某个节点(运算操作)的信息,比如下面MaxPool,点击一下,能看到使用的3x3的池化核,是否有填充pads,步长strides等参数。

分享完毕~
相关文章:
模型转换 PyTorch转ONNX 入门
前言 本文主要介绍如何将PyTorch模型转换为ONNX模型,为后面的模型部署做准备。转换后的xxx.onnx模型,进行加载和测试。最后介绍使用Netron,可视化ONNX模型,看一下网络结构;查看使用了那些算子,以便开发部署…...
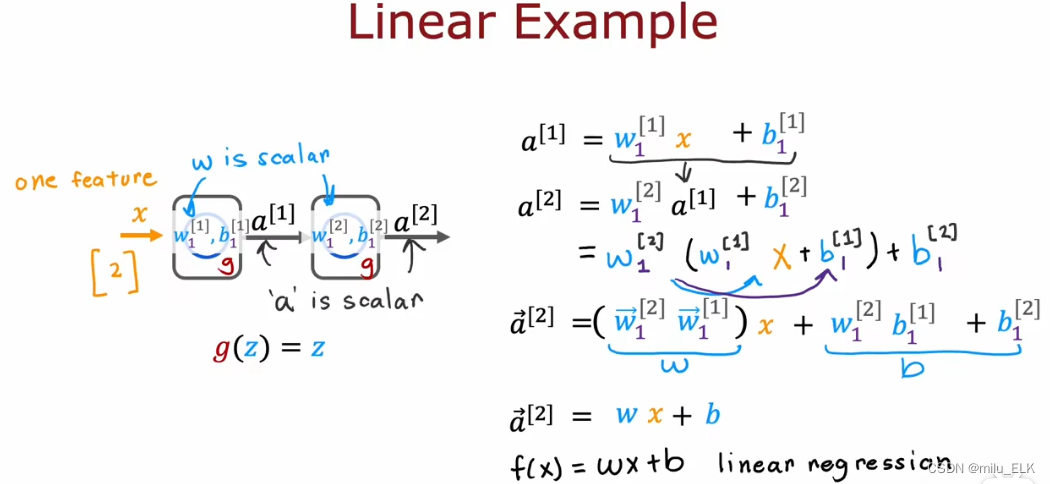
【深度学习】激活函数
上一章——认识神经网络 新课P54介绍了强人工智能概念,P55到P58解读了矩阵乘法在代码中的应用,P59,P60介绍了在Tensflow中实现神经网络的代码及细节,详细的内容可以自行观看2022吴恩达机器学习Deeplearning.ai课程,专…...
)
【新2023】华为OD机试 - 数字的排列(Python)
华为 OD 清单查看地址:blog.csdn.net/hihell/category_12199275.html 数字的排列 题目 小华是个很有对数字很敏感的小朋友, 他觉得数字的不同排列方式有特殊的美感。 某天,小华突发奇想,如果数字多行排列, 第一行1个数, 第二行2个, 第三行3个, 即第n行n个数字,并且…...

[oeasy]python0085_ASCII之父_Bemer_COBOL_数据交换网络
编码进化 回忆上次内容 上次 回顾了 字符编码的 进化过程 IBM 在数字化过程中 作用 非常大IBM 的 BCDIC 有 黑历史 😄 6-bit的 BCDIC 直接进化成 8-bit的 EBCDIC补全了 小写字母 和 控制字符 在ibm就是信息产业的年代 ibm的标准 怎么最终 没有成为 行业的标准 呢…...

volatile,内存屏障
volatile的特性可见性: 对于其他线程是可见,假设线程1修改了volatile修饰的变量,那么线程2是可见的,并且是线程安全的重排序: 由于CPU执行的时候,指令在后面的会先执行,在指令层级的时候我们晓得volatile的特性后,我们就要去volatile是如何实现的,这个很重要!&#…...

【ESP 保姆级教程】玩转emqx MQTT篇① —— 系统主题、延迟发布、服务器配置预算、常见问题
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-18 ❤️❤️ 本篇更新记录 2023-02-18 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...
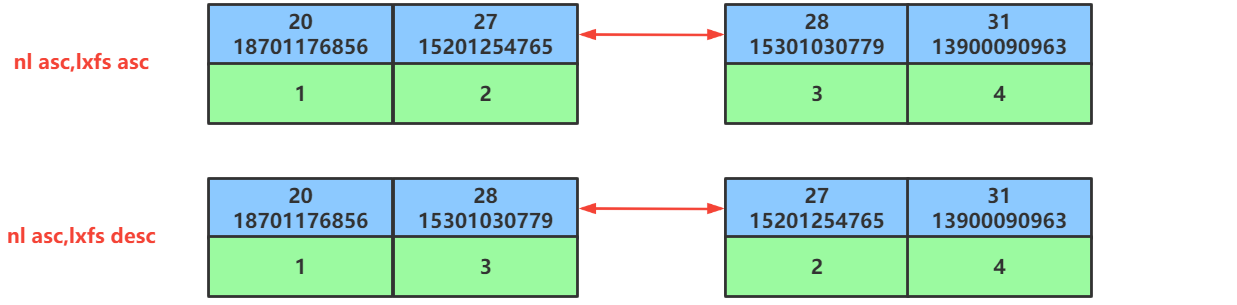
第48讲:SQL优化之ORDER BY排序查询的优化
文章目录1.ORDEY BY排序查询优化方面的概念2.ORDER BY排序的优化原则3.ORDER BY排序优化的案例3.1.准备排序优化的表以及索引3.2.同时对nl和lxfs字段使用升序排序3.3.同时对nl和lxfs字段使用降序排序3.4.排序时调整联合索引中字段的位置顺序3.5.排序时一个字段使用升序一个字段…...
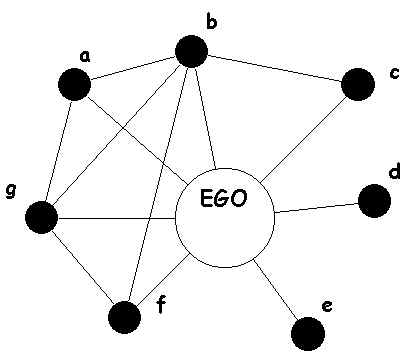
[Datawhale][CS224W]图机器学习(三)
目录一、简介与准备二、教程2.1 下载安装2.2 创建图2.2.1 常用图创建(自定义图创建)1.创建图对象2.添加图节点3.创建连接2.2.2 经典图结构1.全连接无向图2.全连接有向图3.环状图4.梯状图5.线性串珠图6.星状图7.轮辐图8.二项树2.2.3 栅格图1.二维矩形栅格…...

2023版最新最强大数据面试宝典
此套面试题来自于各大厂的真实面试题及常问的知识点,如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待!目前已经更新到第4版,广受好评!复习大数据面试题,看这一套就够了&am…...

CSS 中的 BFC 是什么,有什么作用?
BFC,即“块级格式化上下文”(Block Formatting Context),是 CSS 中一个重要的概念,它指的是一个独立的渲染区域,让块级盒子在布局时遵循一些特定的规则。BFC 的存在使得我们可以更好地控制文档流࿰…...

总结在使用 Git 踩过的坑
问题一: 原因 git 有两种拉代码的方式,一个是 HTTP,另一个是 ssh。git 的 HTTP 底层是通过 curl 的。HTTP 底层基于 TCP,而 TCP 协议的实现是有缓冲区的。 所以这个报错大致意思就是说,连接已经关闭,但是此时有未处理…...

从 HTTP 到 gRPC:APISIX 中 etcd 操作的迁移之路
罗泽轩,API7.ai 技术专家/技术工程师,Apache APISIX PMC 成员。 原文链接 Apache APISIX 现有基于 HTTP 的 etcd 操作的局限性 etcd 在 2.x 版本的时候,对外暴露的是 HTTP 1 (以下简称 HTTP)的接口。etcd 升级到 3.x…...
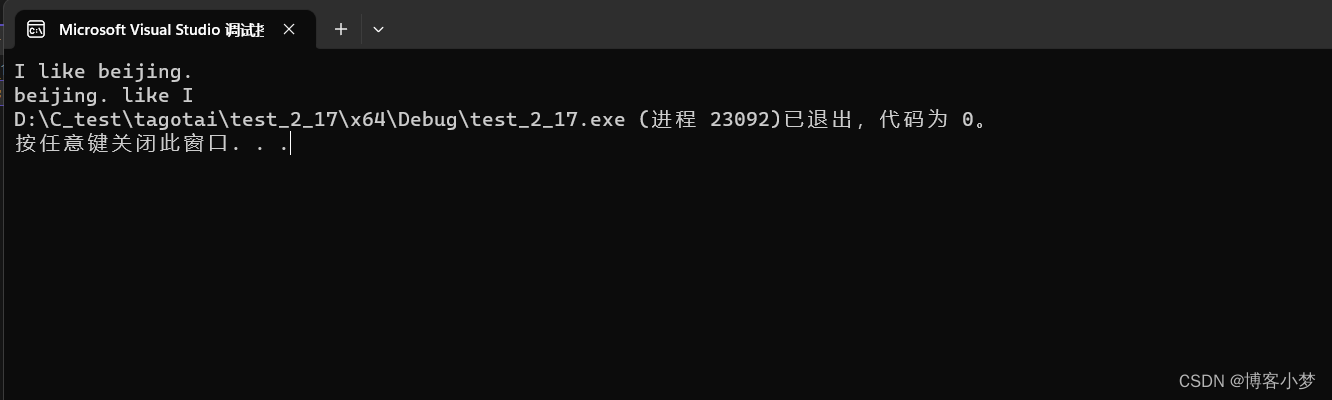
【C语言每日一题】——倒置字符串
【C语言每日一题】——倒置字符串😎前言🙌倒置字符串🙌总结撒花💞😎博客昵称:博客小梦 😊最喜欢的座右铭:全神贯注的上吧!!! 😊作者简…...

Native扩展开发的一般流程(类似开发一个插件)
文章目录大致开发流程1、编写对应的java类服务2、将jar包放到对应位置3、配置文件中进行服务配置4、在代码中调用5、如何查看服务调用成功大致开发流程 1、编写服务,打包为jar包2、将jar包放到指定的位置3、在配置文件中进行配置,调用对应的服务 1、编…...

【新解法】华为OD机试 - 任务调度 | 备考思路,刷题要点,答疑,od Base 提供
华为 OD 清单查看地址:blog.csdn.net/hihell/category_12199275.html 任务调度 题目 现有一个 CPU 和一些任务需要处理,已提前获知每个任务的任务 ID、优先级、所需执行时间和到达时间。 CPU 同时只能运行一个任务,请编写一个任务调度程序,采用“可抢占优先权调度”调度…...
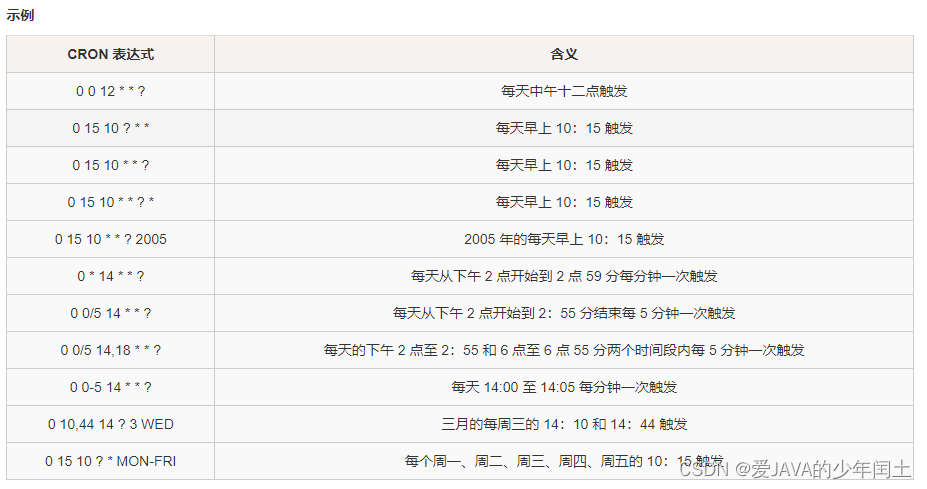
Spring3定时任务
简介 Spring 内部有一个 task 是 Spring 自带的一个设定时间自动任务调度,提供了两种方式进行配置,一种是注解的方式,而另外一种就是 XML 配置方式了;注解方式比较简洁,XML 配置方式相对而言有些繁琐,但是应用场景的不…...
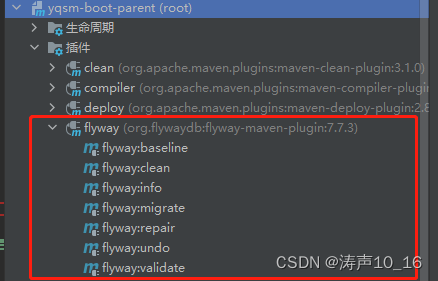
数据库版本管理工具Flyway应用研究
目录1 为什么使用数据库版本控制2 数据库版本管理工具选型:Flyway、Liquibase、Bytebase、阿里 DMSFlywayLiquibaseBytebase阿里 DMS3 Flyway数据库版本管理研究3.1 参考资料3.2 Flyway概述3.3 Flyway原理3.4 Flyway版本和功能3.5 Flyway概念3.5.1 版本迁移…...

更换 Ubuntu 系统 apt 命令安装软件源
更换 Ubuntu 系统 apt 命令安装软件源清华大学开源软件镜像站 https://mirrors.tuna.tsinghua.edu.cn/ 1. Ubuntu 的软件源配置文件 /etc/apt/sources.list MIRRORS -> 使用帮助 -> ubuntu https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/ Ubuntu 系统 apt 命令安…...
2023年可见光通信(LiFi)研究新进展
可见光无线通信Light Fidelity(LiFi)又称“光保真技术”,是一种利用可见光进行数据传输的全新无线传输技术。LiFi是一种以半导体光源作为信号发射源,利用无需授权的自由光谱实现无线连接的新型无线通信技术,支持高密度…...
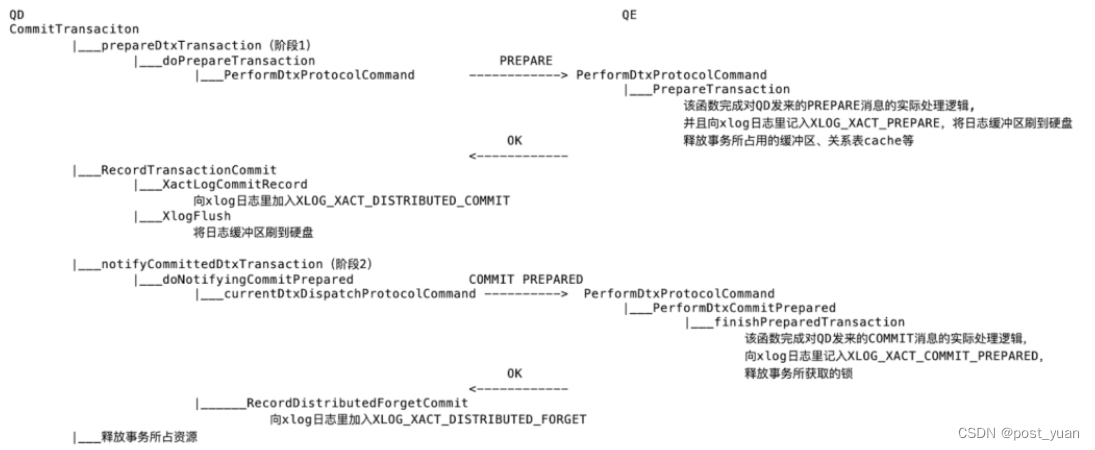
Greenplum的两阶段提交
注:本文章引自终于把分布式事务讲明白了! 在前面的文章中,我们了解了单机库中的事务一致性实现以及分布式事务中的两阶段提交协议。大多数分布式系统都是采用了两阶段提交塄来保证事务的原子性,Greenplum也是采用了两阶段提交&am…...

免费LLM API实战指南:从选型到架构的完整解决方案
1. 项目概述:一份免费LLM API的实用指南 如果你正在开发AI应用,或者只是想低成本地体验各种大语言模型,那么“API调用成本”绝对是一个绕不开的痛点。无论是OpenAI还是Anthropic,按Token计费的模式在频繁调用下,账单数…...
)
别再只会点灯了!用51单片机和继电器模块,做个智能插座控制台灯(附完整代码)
从点灯到智能家居:51单片机与继电器模块的实战进阶指南 当你已经能够熟练地用51单片机点亮LED灯时,是否想过将这些基础技能转化为实际生活中的实用工具?本文将带你跨越实验板与真实世界的鸿沟,用最常见的51单片机和继电器模块&…...

飞书文档批量导出工具:25分钟搞定700+文档的迁移难题
飞书文档批量导出工具:25分钟搞定700文档的迁移难题 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 当企业需要切换办公平台或进行数据备份时,飞书文档的批量迁移常常成为…...

弯曲波触觉反馈技术:为触摸屏注入真实按键手感的工程实践
1. 项目概述:当触摸屏需要“手感”在2012年,如果你告诉一个家电设计师,未来的微波炉、冰箱或烤箱面板将是一块完全平整、没有任何物理凸起的玻璃或塑料板,他可能会皱起眉头。因为这意味着用户将失去最直接的交互反馈——那个“咔哒…...

为Odoo ERP构建安全的AI数据访问层:基于权限治理的语义查询实践
1. 项目概述:为Odoo ERP构建一个受治理的AI数据访问层如果你正在使用Odoo管理企业业务,同时又希望让AI助手(比如Claude、Cursor)能够安全地查询销售数据、分析库存状况,而不是让它们直接面对你的生产数据库写SQL&#…...

Steam SDK上传游戏包体避坑指南:路径、验证码与BuildID那些事儿
Steam SDK上传游戏包体避坑指南:路径、验证码与BuildID那些事儿 第一次通过Steam SDK上传游戏包体时,开发者往往会遇到各种意料之外的"坑"。这些看似小问题却可能导致数小时的无效排查。本文将从实战角度,分享那些官方文档没细说但…...

Modbus RTU 与 Modbus TCP 深入指南-结束语
结束语本指南涵盖了Modbus RTU和Modbus TCP的物理层、数据链路层、报文格式、CRC算法、通信模型、功能码详解、性能优化、安全加固、故障排查、工程实践、过渡策略及现代替代方案。核心要点回顾:RTU:串口,远距离,简单可靠…...

从找石油到防灾害:地震勘探技术如何跨界守护城市安全?
地震勘探技术的跨界革命:从油气勘探到城市安全守护者 上世纪20年代,当第一批地球物理学家尝试用炸药激发地震波来寻找石油时,他们或许不会想到,这项技术会在百年后成为保护现代城市安全的"透视眼"。传统的地震勘探技术…...

从零构建Telegram天气机器人:Python异步编程与API集成实战
1. 项目概述:一个能聊天的天气机器人 如果你用过Telegram,大概率会见过或者用过一些机器人。它们能帮你查新闻、翻译、管理任务,甚至陪你聊天。今天要聊的这个项目, imkarimkarim/Telegram-Weather-Bot ,就是一个典型…...

3D Tiles Tools终极指南:如何快速掌握3D模型格式转换与优化
3D Tiles Tools终极指南:如何快速掌握3D模型格式转换与优化 【免费下载链接】3d-tiles-tools 项目地址: https://gitcode.com/gh_mirrors/3d/3d-tiles-tools 在3D地理空间数据可视化领域,3D Tiles Tools是一套功能强大的开源工具集,专…...