大数据框架之Hadoop:MapReduce(一)MapReduce概述
1.1MapReduce定义
MapReduce是一个分布式计算框架,用于编写批处理应用程序,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
这里以词频统计为例进行说明,MapReduce 处理的流程如下:
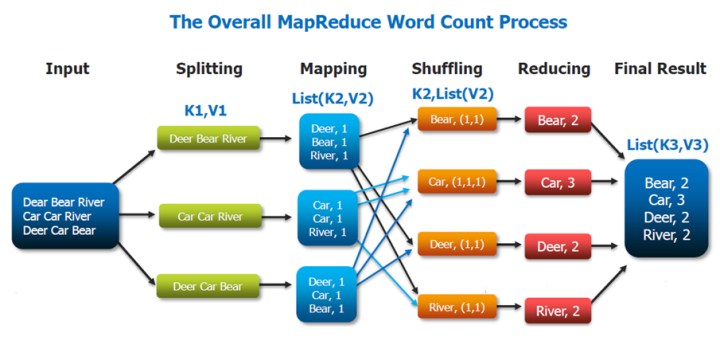
- input : 读取文本文件;
- splitting : 将文件按照行进行拆分,此时得到的
K1行数,V1表示对应行的文本内容; - mapping : 并行将每一行按照空格进行拆分,拆分得到的
List(K2,V2),其中K2代表每一个单词,由于是做词频统计,所以V2的值为 1,代表出现 1 次; - shuffling:由于
Mapping操作可能是在不同的机器上并行处理的,所以需要通过shuffling将相同key值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到K2为每一个单词,List(V2)为可迭代集合,V2就是 Mapping 中的 V2; - Reducing : 这里的案例是统计单词出现的总次数,所以
Reducing对List(V2)进行归约求和操作,最终输出。
MapReduce 编程模型中 splitting 和 shuffing 操作都是由框架实现的,需要我们自己编程实现的只有 mapping 和 reducing,这也就是 MapReduce 这个称呼的来源。
1.2MapReduce优缺点
1、优点
- Mapr易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布在大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
- 良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
- 高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它就有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
- 适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
2、缺点
- 不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
- 不擅长流式计算
流失计算的输入数据时动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
- 不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能,而是使用后,每个MapReduce作业的输出结果都会写入磁盘,会造成大量的磁盘IO,导致性能非常低下。
1.3MapReduce核心思想
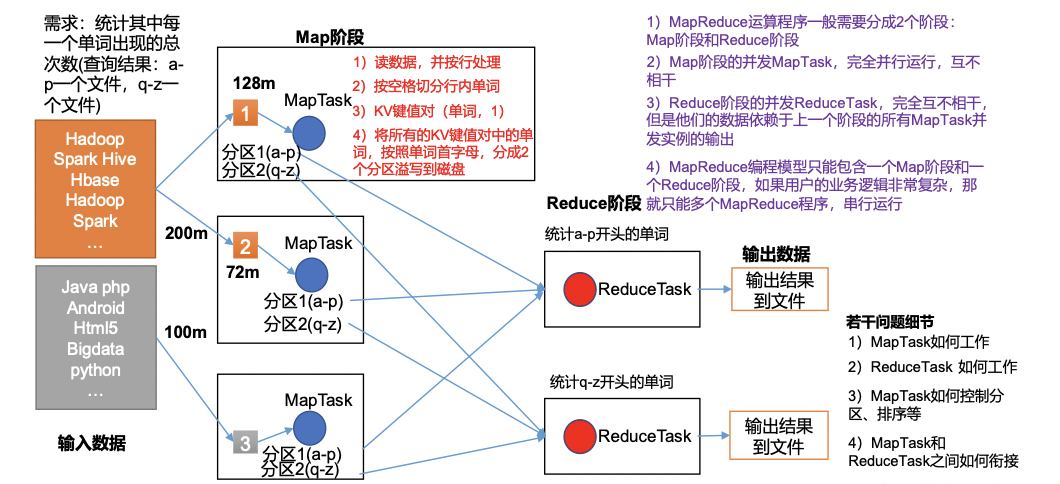
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
1.4MapReduce进程
一个完整的MapR程序在分布式运行时有三类实例进程:
1)MrAppMaster:负责整个程序的过程调度及状态协调
2)MapTask:负责Map阶段的整个数据处理流程
3)ReduceTask:负责Reduce阶段的整个数据处理流程。
1.5常用数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
1.6MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver。
1、Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的为业务逻辑写在map()方法中
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(MapTask进程)对每一个<K,V>调用一次
2、Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)ReduceTask进程对每一组相同的K的<k,v>组调用一次reduce()方法
3、Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象。
1.7WordCount词频统计案例实操
1、需求
在给定的文本文件中统计输出每个单词出现的总次数
(1)输入数据
atguigu atguigu
ss ss
cls cls
jiao
banzhang
xue
hadoop
(2)期望输出数据
atguigu 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
2、需求分析
按照MapReduce编程规范,分别编写Mapper,Reducer,Driver。
需求:统计一堆文件中单词出现的个数(WordCount案例)

3、环境准备
(1)创建maven工程
按照要求填写相应的名称即可
(2)在pom.xml文件中添加如下依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.cuiyf41</groupId><artifactId>mr-quickstart-java</artifactId><version>1.0-SNAPSHOT</version><properties><maven_compiler_plugin.version>3.6.1</maven_compiler_plugin.version><java.version>1.8</java.version></properties><!-- 仓库 --><repositories><repository><id>central</id><name>Maven Repository</name><url>http://maven.aliyun.com/nexus/content/groups/public</url><releases><enabled>true</enabled></releases></repository></repositories><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.6</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.6</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.6</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>${maven_compiler_plugin.version}</version><configuration><source>${java.version}</source><target>${java.version}</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.12.4</version><configuration><skipTests>true</skipTests></configuration></plugin><!-- 打包工具 --><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><mainClass>com.cuiyf41.wordCount.WordcountDriver</mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>
(3)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4、编写程序
(1)编写Mapper类
package com.cuiyf41.wordCount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for (String word: words){k.set(word);context.write(k, v);}}
}
WordCountMapper 继承自 Mapper 类,这是一个泛型类,定义如下:
WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {......
}
- KEYIN :
mapping输入 key 的类型,即每行的偏移量 (每行第一个字符在整个文本中的位置),Long类型,对应 Hadoop 中的LongWritable类型; - VALUEIN :
mapping输入 value 的类型,即每行数据;String类型,对应 Hadoop 中Text类型; - KEYOUT :
mapping输出的 key 的类型,即每个单词;String类型,对应 Hadoop 中Text类型; - VALUEOUT:
mapping输出 value 的类型,即每个单词出现的次数;这里用int类型,对应IntWritable类型。
(2)编写Reducer类
package com.cuiyf41.wordCount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {int sum;IntWritable v = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {// 1 累加求和sum = 0;for(IntWritable count:values){sum += count.get();}// 2 输出v.set(sum);context.write(key, v);}
}
(3)编写Driver驱动类
package com.cuiyf41.wordCount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordcountDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 输入输出路径需要根据自己电脑上实际的输入输出路径设置args = new String[] { "/Users/cuiyufei/IdeaProjects/input", "/Users/cuiyufei/IdeaProjects/output" };// 1 获取配置信息以及封装任务Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置jar加载路径job.setJarByClass(WordcountDriver.class);// 3 设置map和reduce类job.setMapperClass(WordcountMapper.class);job.setReducerClass(WordcountReducer.class);// 4 设置map输出job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交boolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
5、本地测试
在Driver中添加本地测试文件和输出文件目录
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "/Users/cuiyufei/IdeaProjects/input", "/Users/cuiyufei/IdeaProjects/output" };
在Driver文件中右键运行即可。
6、集群上测试
(0)用maven打jar包,需要添加的打包插件依赖
注意:标记红颜色的部分需要替换为自己工程主类
<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin </artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><mainClass>com.atguigu.mr.WordcountDriver</mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
注意:如果工程上显示红叉。在项目上右键->maven->update project即可。
(1)将程序打成jar包,然后拷贝到Hadoop集群中
步骤详情:右键->Run as->maven install。等待编译完成就会在项目的target文件夹中生成jar包。如果看不到。在项目上右键->Refresh,即可看到。修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群。
(2)启动Hadoop集群
(3)执行WordCount程序
[root@hdp101 software]# hadoop jar wc.jar com.atguigu.wordcount.WordcountDriver /user/atguigu/input /user/atguigu/output
相关文章:
大数据框架之Hadoop:MapReduce(一)MapReduce概述
1.1MapReduce定义 MapReduce是一个分布式计算框架,用于编写批处理应用程序,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一…...

一文搞定python语法进阶
前言前面我们已经学习了Python的基础语法,了解了Python的分支结构,也就是选择结构、循环结构以及函数这些具体的框架,还学习了列表、元组、字典、字符串这些Python中特有的数据结构,还用这些语法完成了一个简单的名片管理系统。下…...

2019蓝桥杯真题数列求值(填空题) C语言/C++
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 给定数列 1,1,1,3,5,9,17,⋯,从第 4 项开始,每项都是前 3 项的和。 求第 20190324 项的最后 4 位数字。 运行限制 最大运行时间:…...
spring中@Autowire和@Resource的区别在哪里?
介绍今天使用Idea写代码的时候,看到之前的项目中显示有warning的提示,去看了下,是如下代码?Autowire private JdbcTemplate jdbcTemplate;提示的警告信息Field injection is not recommended Inspection info: Spring Team recommends: &quo…...
算法训练营DAY54|583. 两个字符串的删除操作、72. 编辑距离
583. 两个字符串的删除操作 - 力扣(LeetCode)https://leetcode.cn/problems/delete-operation-for-two-strings/这道题也是对于编辑距离的铺垫题目,是可以操作两个字符串的删除,使得两个字符串的字符完全相同,这道题可…...

【Ctfshow_Web】信息收集和爆破
0x00 信息收集 web1 直接查看源码 web2 查看不了源码,抓包即可看到(JS拦截了F12) web3 抓包,发送repeater,在响应包中有Flag字段 web4 题目提示后台地址在robots,访问/robots.txt看到Disallow: /fl…...

基于机器学习的推荐算法研究与实现
摘要随着互联网的普及,人们可以通过搜索引擎、社交网络等方式获取大量的信息资源。但是,面对如此之多的信息,人们往往会感到迷失和困惑,无法快速准确地找到自己需要的信息。在这种情况下,推荐算法的出现为我们提供了一…...
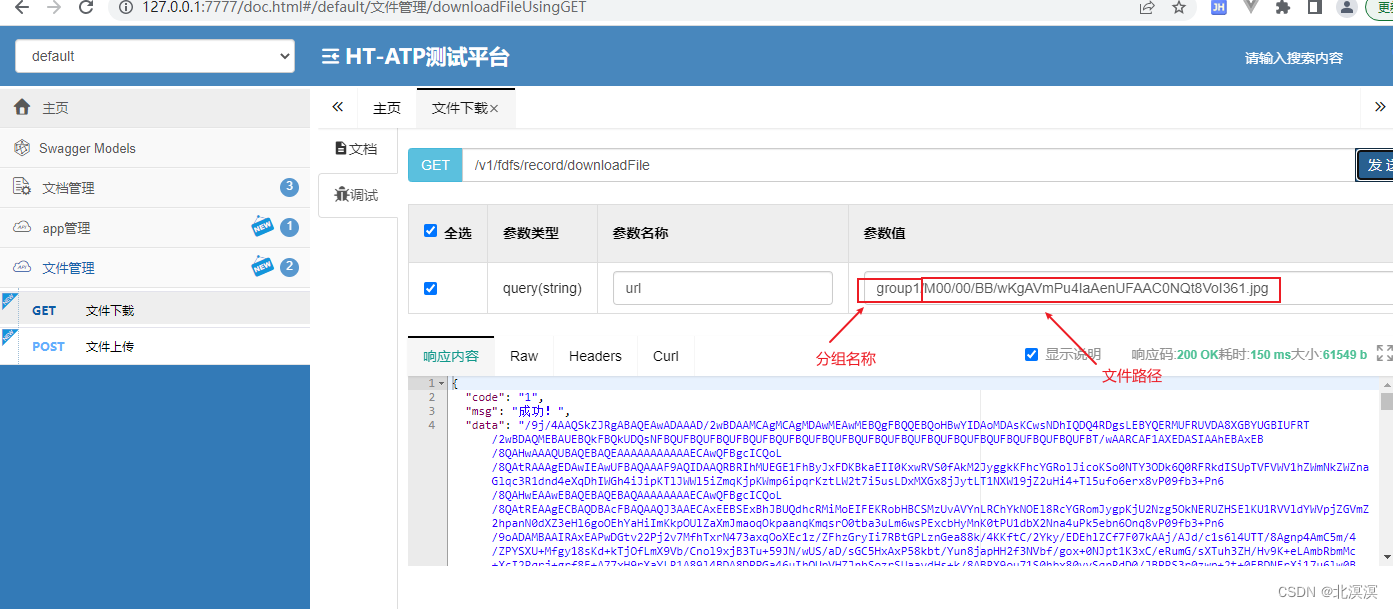
(二十四)ATP应用测试平台——springboot集成fastdfs上传与下载功能
前言 本节内容我们主要介绍一下如何在springboot项目中集成fastdfs组件,实现文件的上传与下载。关于fastdfs服务中间键的安装过程,本节内容不做介绍。fastdfs是一个轻量级的分布式文件系统,也是我们文件存储中常常使用的组件之一,…...

linux好用命令+vs快捷键
linux好用命令 功能指令跳转到vim界面的最后一行shift键g复制当前路径下所有文件和目录(加-r才行)到target目录cp -r * /home/target删除指定文件rm -rf test.txt文件重命名(-i交互式提示)mv -i file1 file2移动某个内容…...

Git 构建分布式版本控制系统
版本控制概念Gitlab部署1.版本控制概念 1.1分类 (一)1 本地版本控制系统(传统模式) (二)2 集中化的版本控制系统 CVS、Subversion(SVN) (三)3 分布式…...
Day891.一主多从的切换正确性 -MySQL实战
一主多从的切换正确性 Hi,我是阿昌,今天学习记录的是关于一主多从的切换正确性的内容。 在切换任务的时候,要先主动跳过这些错误,通过主动跳过一个事务或者直接设置跳过指定的错误,用GTID解决找同步位点的问题 大多…...
【论文笔记】图像修复Learning Joint Spatial-Temporal Transformations for Video Inpainting
论文地址:https://arxiv.org/abs/2007.10247 源码地址:GitHub - researchmm/STTN: [ECCV2020] STTN: Learning Joint Spatial-Temporal Transformations for Video Inpainting 一、项目介绍 当下SITA的方法大多采用注意模型,通过搜索参考帧…...
代码随想录算法训练营第二天 | 977.有序数组的平方 、209.长度最小的子数组 、59.螺旋矩阵II、总结
打卡第二天,认真做了两道题目,顶不住了好困,明天早上练完车回来再重新看看。 今日任务 第一章数组 977.有序数组的平方209.长度最小的子数组59.螺旋矩阵II 977.有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每…...

Python pickle模块:实现Python对象的持久化存储
Python 中有个序列化过程叫作 pickle,它能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。也就是说,pickle 可以实现 Python 对象的存储及恢复。值得一提的是,pickle 是 python 语言的一个标准模…...
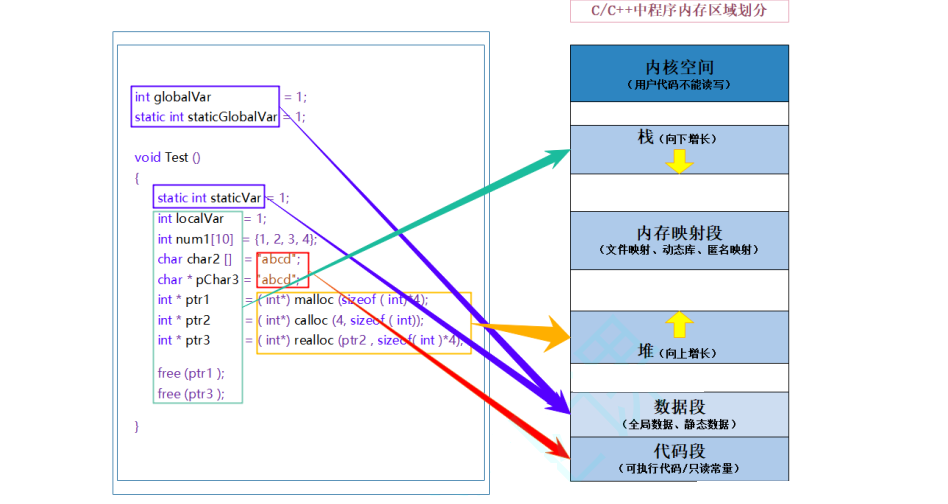
【C++】C/C++内存管理
文章目录1. C/C内存分布2. C语言当中的动态内存管理3. C 内存管理方式3.1 new/delete操作内置类型3.2 new和delete操作自定义类型4. operator new 和operator delete 函数5. new和delete的实现原理5.1 内置类型5.2 自定义类型6. 定位new表达式(placement-new)7. 常见面试题7.1 …...

【测试】自动化测试02
努力经营当下,直至未来明朗! 文章目录前言 回顾 预告一、常见的元素操作1. 输入文本sendKeys()2. 点击click3. 提交submit(通过回车键提交)4. 清除clear5. 获取文本getText()6. 获取属性对应的值getAttribute()7. 查看title和ur…...
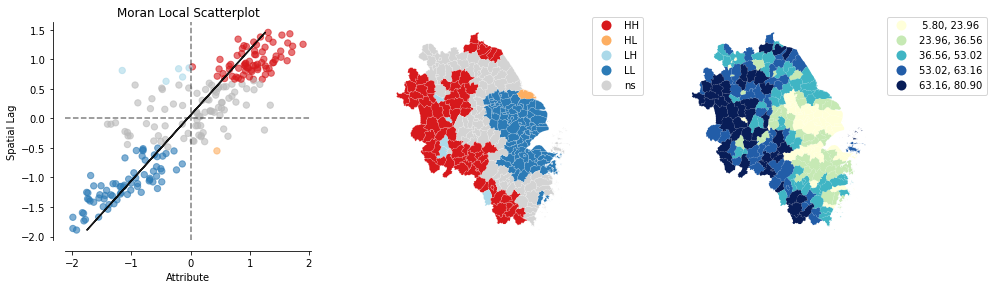
Python空间分析| 02 利用Python计算空间局部自相关(LISA)
局部空间自相关 import esda import numpy as np import pandas as pd import libpysal as lps import geopandas as gpd import contextily as ctx import matplotlib.pyplot as plt from geopandas import GeoDataFrame from shapely.geometry import Point from pylab im…...

idea快捷编码:生成for循环、主函数、判空非空、生成单例方法、输出;自定义快捷表达式
前言 idea可根据输入的简单表达式进行识别,快速生成语句 常用的快捷编码:生成for循环、主函数、判空非空、生成单例方法、输出 自定义快捷表达式 博客地址:芒果橙的个人博客 【http://mangocheng.com】 一、idea默认的快捷表达式查看 Editor…...

【Spring】@Value注入配置文件 application.yml 中的值失败怎么办
本期目录一、 问题背景二、 问题原因三、 解决方法一、 问题背景 今天碰到的问题是用 Value 注解无法注入配置文件 application.yml 中的配置值。 检查过该类已经交给 Spring 容器管理了,即已经在类上加了 Configuration 和 ConfigurationProperties(prefix &quo…...
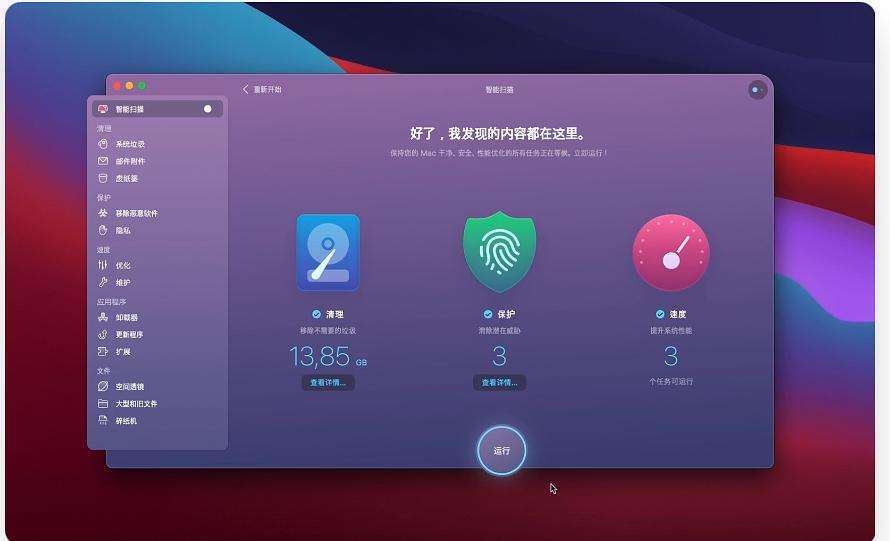
CleanMyMac清理工具软件功能优势介绍
CleanMyMac更新最新版本x4.12,完美适配新版系统macOS10.14,拥有全新的界面。CleanMyMac可以让您安全、智能地扫描和清理整个系统,删除大型未使用的文件,减少iPod库的大小,最精确的应用程序卸载,卸载不必要的…...

如何用bitsandbytes轻松实现PyTorch大模型量化:内存减半,性能不减
如何用bitsandbytes轻松实现PyTorch大模型量化:内存减半,性能不减 【免费下载链接】bitsandbytes Accessible large language models via k-bit quantization for PyTorch. 项目地址: https://gitcode.com/gh_mirrors/bi/bitsandbytes 你是否曾因…...

1688代运营公司/月询盘从110涨到235,1688代运营只做了3件事
1688代运营公司/月询盘从110涨到235,1688代运营只做了3件事月询盘从110个上涨到235个,上周有个老客户跟我报喜,说他的店铺询盘涨了139%,翻了一倍还多。他是做运动户外产品的,1688店铺开了4年,但一直运营得不…...

解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务 对于依赖 Claude Code 进行开发的工程师而言,账号访问权限的…...

Smart_rtmpd配置全解:从单局域网到跨网段,你的OBS推流服务器搭建指南
Smart_rtmpd高阶配置指南:从局域网到跨网段的OBS推流实战 在当前的数字内容创作浪潮中,实时视频流传输已成为游戏直播、在线教育、企业内训等场景的刚需。对于技术爱好者和小型团队而言,自建推流服务器不仅能避免第三方平台的限制,…...

STM32CubeMX外部中断实战:从按键消抖到LED状态切换
1. STM32CubeMX外部中断基础配置 第一次用STM32CubeMX配置外部中断时,我盯着那一堆选项有点懵。后来发现其实只要抓住几个关键点,整个过程就像搭积木一样简单。这里以最常见的按键控制LED为例,带你一步步实现这个功能。 首先打开CubeMX新建…...
)
告别手动调样式!用QGIS表达式实现地图自动美化(附城市人口可视化案例)
用QGIS表达式实现地图智能美化的高阶技巧 你是否曾在深夜对着QGIS的样式面板反复点击,只为给上百个城市点设置不同大小?或是为了突出显示某些特定道路而不得不创建多个图层?这些重复性工作不仅消耗时间,更消磨创造力。本文将带你突…...

终极指南:如何为你的戴尔G15笔记本安装免费开源散热控制中心
终极指南:如何为你的戴尔G15笔记本安装免费开源散热控制中心 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 tcc-g15 是一款专为戴尔G15系列游戏笔…...

从零构建FreeRTOS认知:核心概念与实战框架精讲
1. 认识FreeRTOS:嵌入式系统的"交通指挥官" 第一次接触FreeRTOS时,我盯着文档里那些"任务"、"队列"、"调度器"之类的术语发懵,就像刚拿到驾照就被扔进了早高峰的十字路口。后来才发现,这…...

AI 写论文哪个软件最好?2026 毕业论文实测:真文献 + 真图表 + 全流程,虎贲等考 AI 稳占首选
📌 配图 1:首图海报 ——AI 写论文哪个最好|虎贲等考 AI|毕业论文神器|真实文献 实证图表 每年毕业季,所有人都在问:AI 写论文哪个软件最好?市面上工具看似很多,可一用…...

矩阵本地化获客技术落地:同城流量精准匹配与合规运营方案
前言同城本地化流量是短视频生态中转化率最高、精准度最强的流量赛道,广泛适配本地生活服务、实体门店、同城咨询、区域服务商等各类业态。相比于泛全域流量,同城用户具备明确的地域消费属性、就近服务需求,成交意向更强烈,获客落…...