Stable Diffusion - 扩展 SegmentAnything 和 GroundingDINO 实例分割算法 插件的配置与使用
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131918652
Paper and GitHub:
- Segment Anything: SAM - Segment Anything
- GitHub: https://github.com/facebookresearch/segment-anything
- Grounding DINO: Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
- 定位 DINO: 结合DINO与基于语言的预训练用于开放集合的目标检测
- GitHub: https://github.com/IDEA-Research/GroundingDINO
Segment Anything:
Segment Anything 是关于图像分割领域的研究,提出了一个新的任务、模型和数据集,能够根据输入的提示(如点或框)生成高质量的物体掩码,或者对于整张图像进行分割。这个模型被称为 Segment Anything Model (SAM),使用了一个高效的模型结构,结合卷积神经网络和 Transformer 架构。SAM在一个由 11M 张图像和 1.1B 个掩码组成的大规模数据集上进行了训练,这个数据集被称为 SA-1B。SAM 具有强大的零样本迁移能力,能够适应不同的图像分布和任务。在多个分割任务上评估 SAM 的性能,发现零样本表现令人印象深刻,甚至超过了之前的全监督结果。
SAM的主要贡献:
- 提出了一个新的图像分割任务,即 Segment Anything (SA),要求模型根据输入的提示(如点或框)生成物体掩膜,或者对整张图像进行分割。
- 设计并实现一个高效且强大的图像分割模型,即 Segment Anything Model (SAM),使用基于 ResNet-50 的卷积神经网络作为编码器,和基于 ViT-B/16 的 Transformer 作为解码器。
- 利用 SAM 在一个数据收集循环中,构建目前最大的图像分割数据集(远远超过之前的数据集),即 SA-1B,包含了 11M 张经过许可和隐私保护的图像,以及 1.1B 个物体掩码。
- 评估 SAM 在多个分割任务上的零样本迁移能力,包括 COCO、ADE20K、Cityscapes、Mapillary Vistas、Open Images V6等,发现在所有任务上都取得了优异的结果,甚至超过了之前的全监督方法。
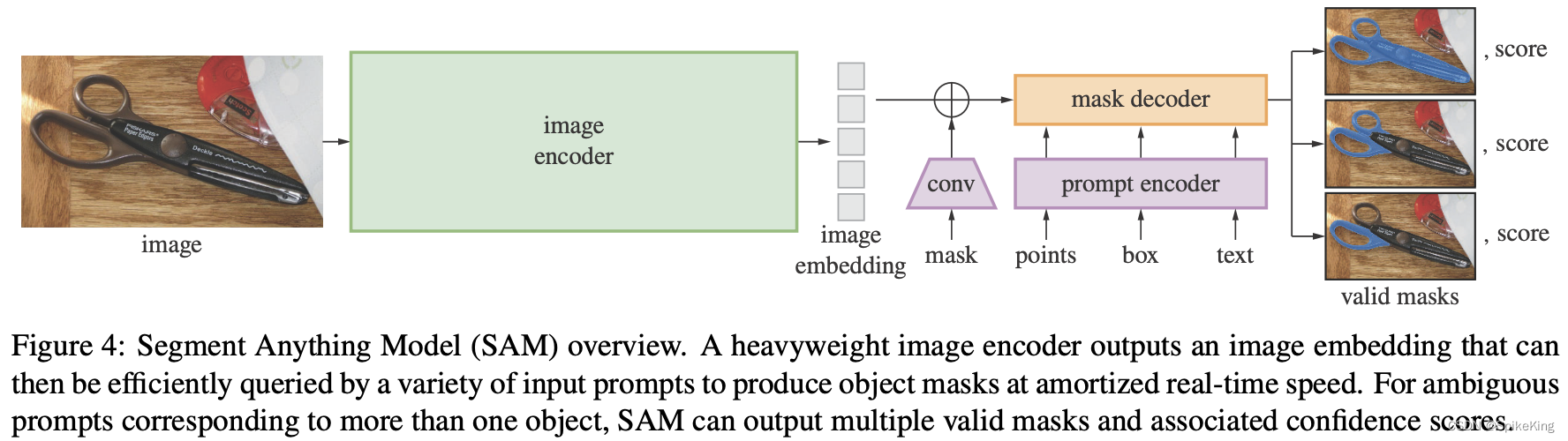
Grounding DINO:
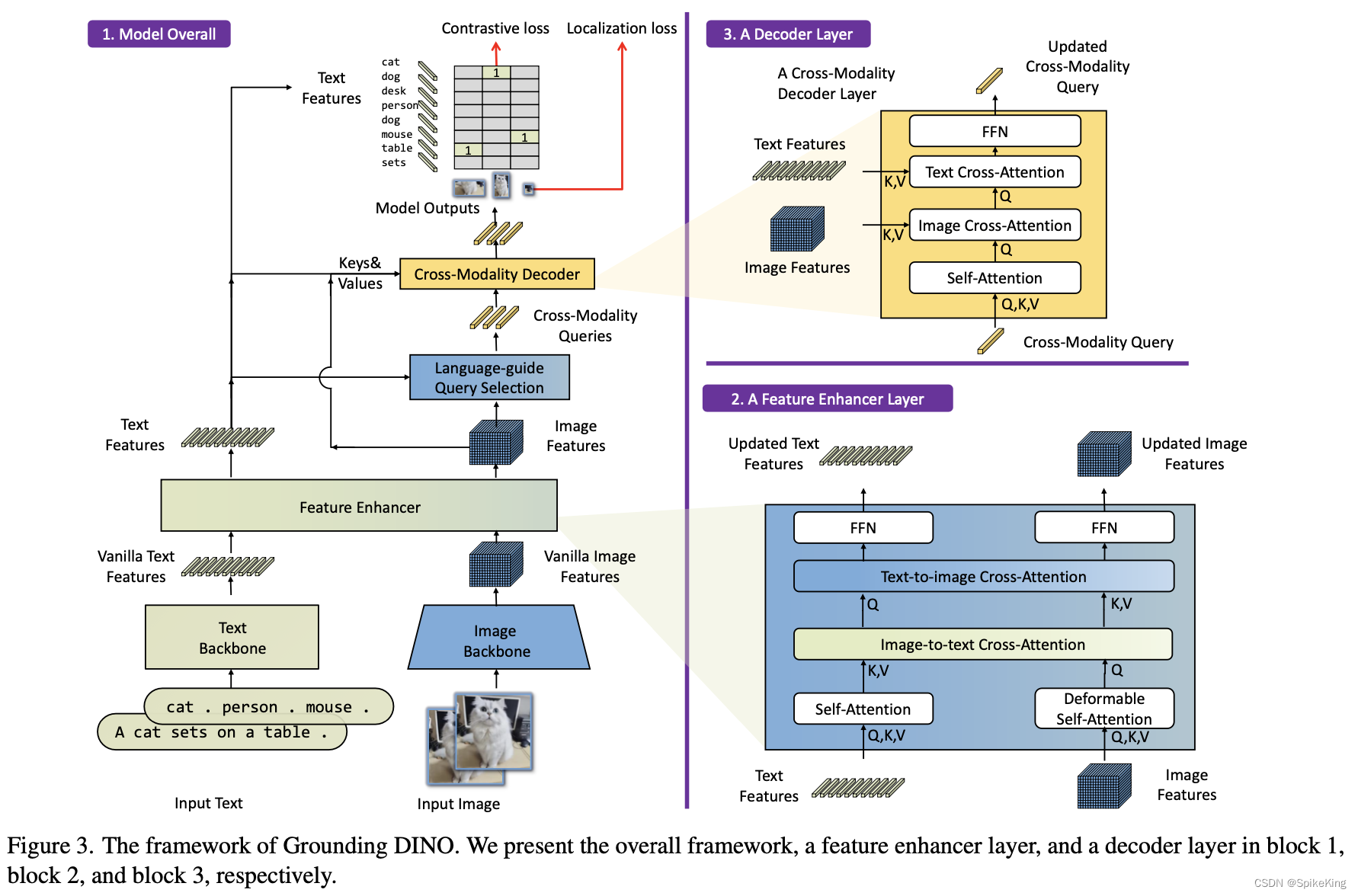
Grounding DINO 是开放集合的目标检测器,通过结合基于 Transformer 的检测器 DINO 和基于语言的预训练模型,可以检测出任意人工输入的类别名字或者相关表达的目标。
开放集合的目标检测是指在没有给定类别标签的情况下,根据人类的语言输入,识别出图像中的目标,并且给出其位置和类别信息。这是一个具有挑战性和实用性的任务,可以应用于多种场景,比如搜索引擎、智能助理、无人驾驶等。然而,现有的目标检测器通常是基于有限的类别集合进行训练和测试的,也就是说,只能检测出预先定义好的类别,而不能处理新颖或未知的类别。为了解决这个问题,Grounding DINO 有效融合语言和视觉模态,使得检测器可以根据语言输入来扩展其概念范围,并且可以处理多种形式的语言输入,比如类别名字、属性描述、指代表达等。
具体来说,Grounding DINO 采用 DINO 作为基础的目标检测器,DINO 是一种基于Transformer的端到端的目标检测器,不需要锚框或者预定义的特征金字塔,而是使用可学习的查询向量来表示目标,并且使用自注意力机制来捕捉图像中的全局上下文信息。为了使 DINO 能够处理开放集目标检测任务,Grounding DINO 提出 3 个关键的改进点:
- 特征增强器(Feature Enhancer):这是一个基于 Transformer 的编码器,将图像特征和语言特征进行融合,并且输出一个增强后的图像特征表示。这样可以使得图像特征包含更多与语言输入相关的信息,从而提高检测器对新颖或未知类别的泛化能力。
- 语言引导查询选择(Language-Guided Query Selection):这是一个基于 Transformer 的解码器,将增强后的图像特征和语言特征作为输入,并且输出一个查询向量集合。这个查询向量集合可以根据语言输入来动态地调整其数量和内容,从而更好地匹配图像中与语言输入相关的目标。
- 跨模态解码器(Cross-Modality Decoder):这是一个基于 Transformer 的解码器,将查询向量集合和增强后的图像特征作为输入,并输出最终的检测结果。这个解码器可以利用自注意力机制来进行跨模态融合,并且可以使用多头注意力机制来进行多尺度特征融合。
除了以上 3 个改进点之外,Grounding DINO 还使用了一种基于语言的预训练方法,叫做 Grounded Pre-Training(GPT),可以在大规模无标注数据上对模型进行预训练,从而提高模型对语言和视觉模态之间关系的理解能力。GPT 主要包括 2 个阶段:
- 自监督预训练(Self-Supervised Pre-Training):这个阶段使用了一种基于对比学习的方法,叫做 MOCO,可以在无标注的图像上学习图像特征的表示。同时,这个阶段还使用了一种基于掩码语言模型的方法,叫做 BERT,可以在无标注的文本上学习语言特征的表示。这两种方法分别对应于图像编码器和语言编码器,可以分别提取图像和语言的低层特征,并且可以通过一个对齐损失函数来进行联合优化,从而使得图像和语言的特征在同一个空间中对齐。
- 监督预训练(Supervised Pre-Training):这个阶段使用了一种基于多任务学习的方法,可以在有标注的数据上对模型进行微调,从而提高模型对语言和视觉模态之间关系的理解能力。这个阶段主要包括 3 个任务:
- 目标检测(Object Detection):这个任务使用 COCO 数据集,是一个常用的目标检测数据集,包含了 80 个类别和超过 20 万张图像。这个任务可以使模型学习如何根据类别名字来检测出图像中的目标,并给出其位置和类别信息。
- 属性检测(Attribute Detection):这个任务使用 LVIS 数据集,是一个新颖的目标检测数据集,包含了 1200 个类别和超过 100 万张图像。这个任务可以使模型学习如何根据属性描述来检测出图像中的目标,并给出其位置和属性信息。
- 指代表达理解(Referring Expression Comprehension):这个任务使用 RefCOCO/+/g 数据集,是一个常用的指代表达理解数据集,包含了超过 14 万个指代表达和超过 5 万张图像。这个任务可以使模型学习如何根据指代表达来检测出图像中的目标,并且给出其位置和指代信息。
通过以上 2 个阶段的预训练,模型可以在不同的语言输入形式下,对不同的目标类别进行有效的检测。
SD的启动命令:
nohup python -u launch.py --listen --port 9301 --xformers --no-half-vae --enable-insecure-extension-access --theme dark --gradio-queue > nohup.62.out &
参数
--xformers有效降低显存占用,提升出图速度。
示例图像,提示词来源于真实图像的导出:
1girl,bag,black hair,earrings,full body,glasses,handbag,jewelry,lipstick,looking at viewer,makeup,pantyhose,pencil skirt,polka dot,polka dot dress,sheer legwear,skirt,smile,solo,standing,sunglasses,wall,
a woman in a pink dress leaning against a wall with a white purse and a handbag on her hip,Carol Bove,feminine,a cubist painting,op art,
best quality,masterpiece,ultra high res,(photorealistic:1.4),
Negative prompt: (badhandv4:1.2),(ng_deepnegative_v1_75t, bad_prompt_version2-neg, EasyNegative:0.9),
(worst quality, low quality:1.3),(depth of field, blurry:1.2),(greyscale, monochrome:1.1),croped,lowres,text,jpeg artifacts,(logo,signature,watermark,username,artist name,title:1.3),
Steps: 30, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 3576157745, Size: 768x1024, Model hash: e4a30e4607, Model: 麦橘写实_MajicMIX_Realistic_v6, Denoising strength: 0.3, Clip skip: 2, ADetailer model: face_yolov8n.pt, ADetailer prompt: "detailed face, close-up, portrait,", ADetailer confidence: 0.3, ADetailer dilate/erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer model 2nd: hand_yolov8s.pt, ADetailer prompt 2nd: "detailed hand, perfect hand,", ADetailer confidence 2nd: 0.3, ADetailer dilate/erode 2nd: 4, ADetailer mask blur 2nd: 4, ADetailer denoising strength 2nd: 0.4, ADetailer inpaint only masked 2nd: True, ADetailer inpaint padding 2nd: 32, ADetailer version: 23.7.6, Hires upscale: 2, Hires steps: 10, Hires upscaler: 8x_NMKD-Superscale_150000_G, Version: v1.4.0
Used embeddings: badhandv4 [dba1], ng_deepnegative_v1_75t [1a3e], bad_prompt_version2-neg [afea], EasyNegative [119b]
图像:

SAM 插件:segment-anything
GroundingDINO的Huggingface工程:Huggingface - GroundingDINO
1. SAM 模型
安装插件,搜索segment anything,下载 SAM 模型,即:
cd stable_diffusion_webui_docker/extensions/sd-webui-segment-anything/models/sambypy downfile /stable_diffusion/extensions/segment_anything/sam_vit_h_4b8939.pth sam_vit_h_4b8939.pth
启用 Segment Anything (分离图像元素) 脚本,点击 人物的裙子,出现黑点,即:

再点击 预览分割结果,即出现全部的分割项,物体从小到大,预览有些形变,真实图像正常,即:
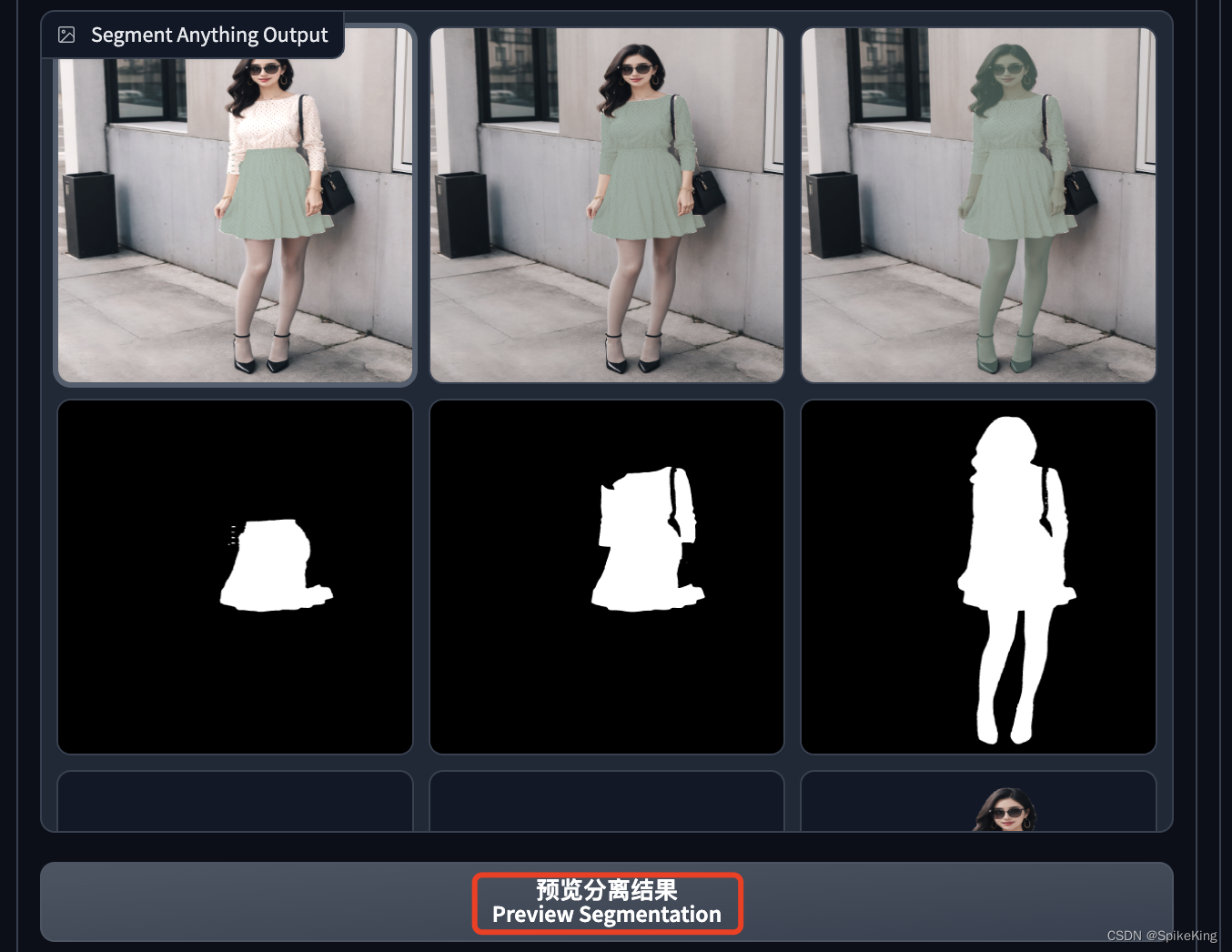
即将所需的裙子部分全部分割出来。
2. GroundingDINO 模型
进入 segment anything 的配置页面,启用本地 Groudingdino 功能,这样就可以直接使用 Huggingface 的工程:

下载 Huggingface 的 GroundingDINO 组件:
cd stable_diffusion_webui_docker/extensions/sd-webui-segment-anything/models/bypy downdir /huggingface/GroundingDINO grounding-dino
在使用时,还需下载 bert-base-uncased 与 tokenizer.json,大约 440 M。
启用 GroundingDINO:
- 选择所使用的模型,主要用于目标检测。
- 选择提示词,用于标识所要分割物体。
即:
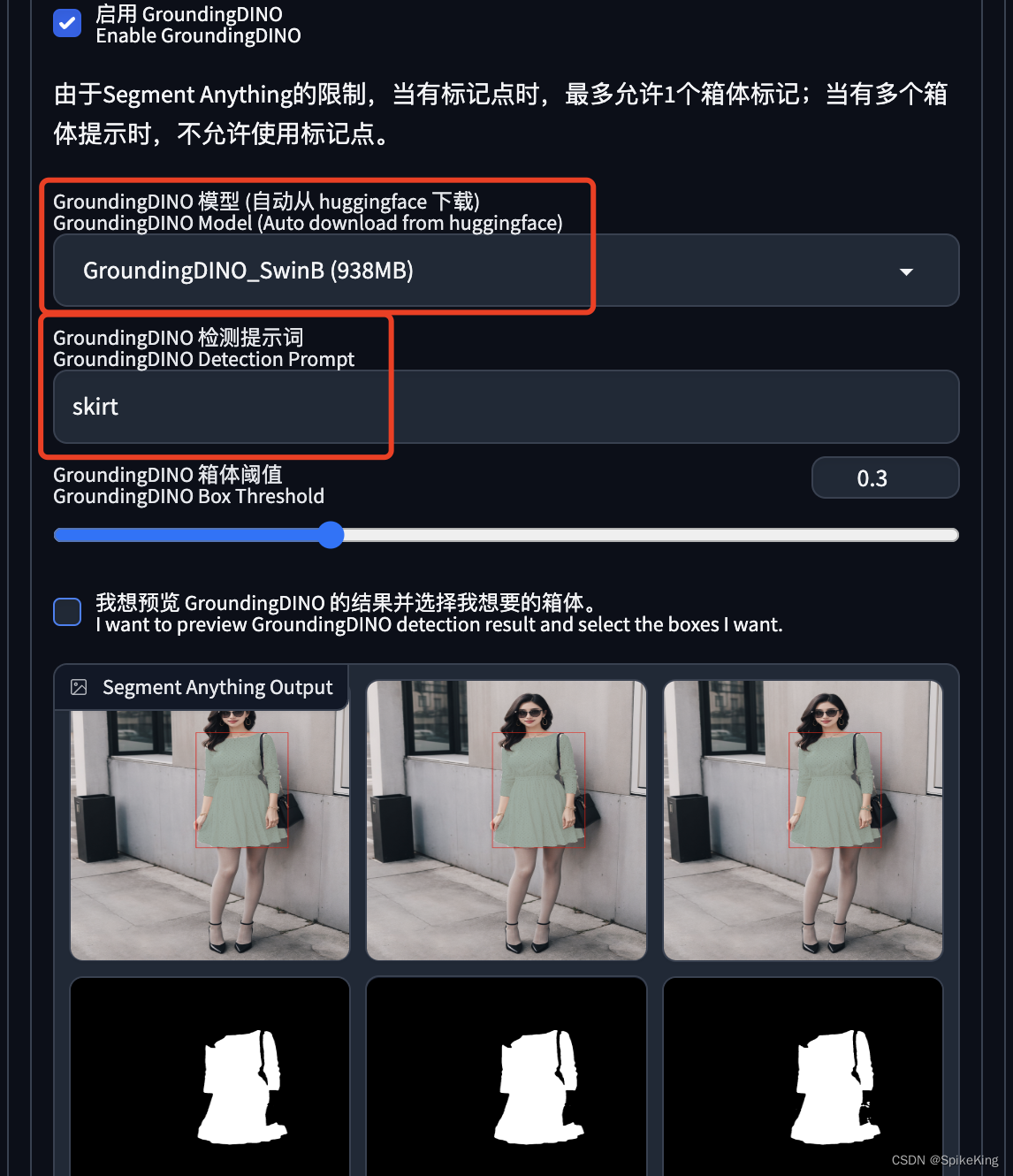
即 GroundingDINO 通过提示词,进行目标检测,再结合 Segment Anything 的实例分割,可以取得更好的性能。
Bug: 遇到 [Errno 39] Directory not empty: '/stable_diffusion_webui_docker/venv/lib/python3.8/site-packages/~IL'
关闭 SD 服务,删除 ~IL 文件夹,再重新启动,即可。
3. 局部重绘
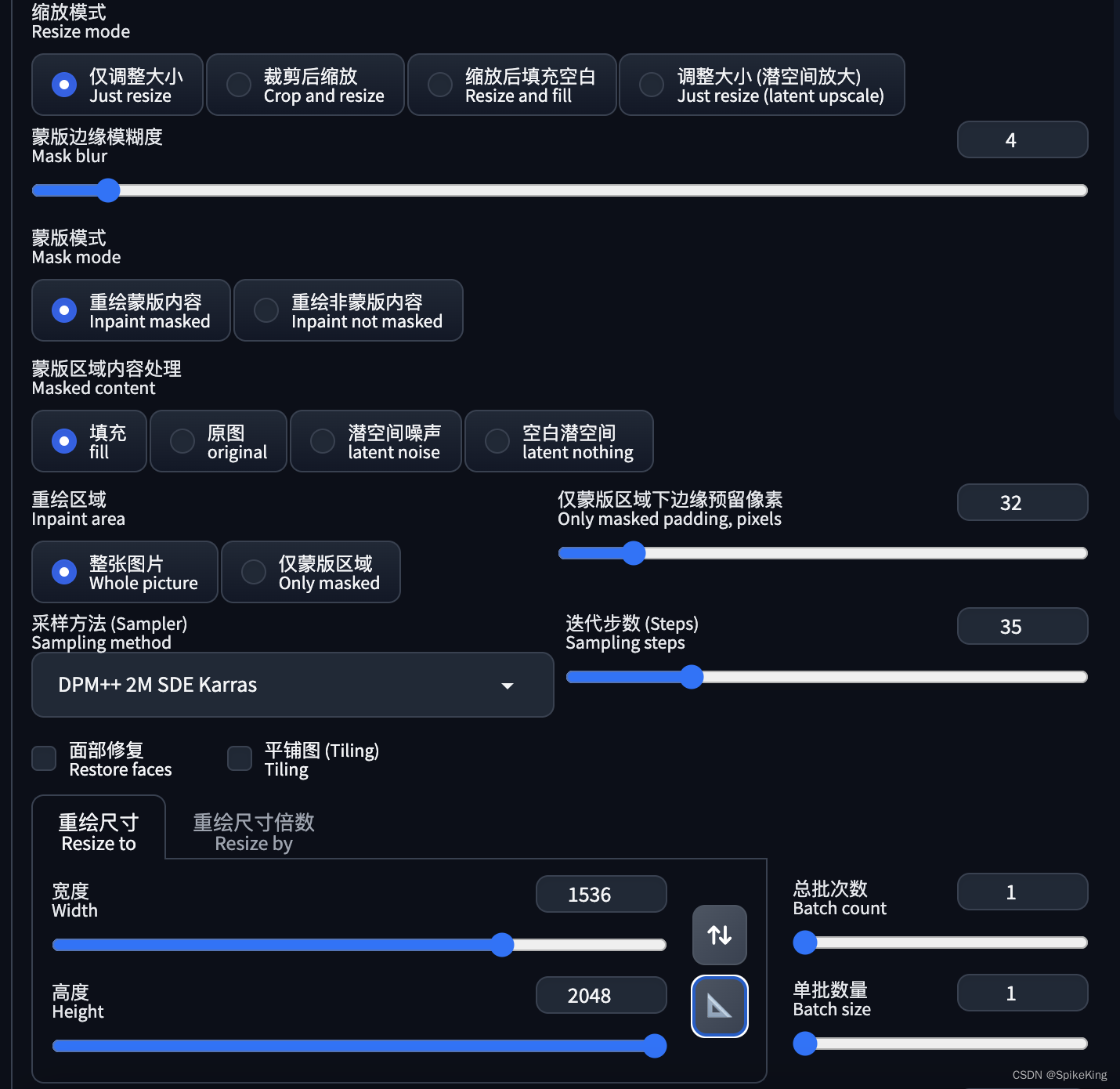
保持之前的图像与 Mask,原图与模版的效果如下:

使用 图生图 的 上传重绘模版 功能,上传原图与Mask,设置如下:
缩放模式:仅调整大小蒙版模式:重绘蒙版内容蒙版区域内容处理:填充(fill)重绘区域:整张图片,边缘更加和谐- 同时开启
ControlNet的软边缘(SoftEdge)模式,强化纹理效果。
即:
提示词:
yellow pencil skirt,polka dot dress,skirt,
yellow pencil skirt,polka dot dress,skirt,
best quality,masterpiece,ultra high res,(photorealistic:1.4),
负向提示词:
(ng_deepnegative_v1_75t, bad_prompt_version2-neg, EasyNegative:0.9),
(worst quality, low quality:1.3),(depth of field, blurry:1.2),(greyscale, monochrome:1.1),lowres,jpeg artifacts,
增加 局部重绘 (Inpaint) 功能,同时,控制模式 选择 更偏向提示词。
裙子颜色的依次效果如下:

袜子提示词,修改颜色属性,注意不同随机种子差别较大:
(black color wrap hip pantyhose:1.3),thights,stockings,high heels,
best quality,masterpiece,ultra high res,(photorealistic:1.4),
采样模式:DDIM,随机种子:3474825489,ControlNet控制模型:更偏向提示词,提升重绘幅度至:0.8
颜色:image、black、pink、blue、yellow,袜子颜色的依次效果如下:

具体信息:
(black color wrap hip pantyhose:1.3),thights,stockings,high heels,
best quality,masterpiece,ultra high res,(photorealistic:1.4),
Negative prompt: (ng_deepnegative_v1_75t, bad_prompt_version2-neg, EasyNegative:0.9),
(worst quality, low quality:1.3),(depth of field, blurry:1.2),(greyscale, monochrome:1.1),lowres,jpeg artifacts,
Steps: 20, Sampler: DDIM, CFG scale: 7, Seed: 3474825489, Size: 1536x2048, Model hash: e4a30e4607, Model: 麦橘写实_MajicMIX_Realistic_v6, Denoising strength: 0.8, Clip skip: 2, Mask blur: 4, ControlNet 0: “preprocessor: none, model: control_v11p_sd15_softedge [a8575a2a], weight: 1, starting/ending: (0, 1), resize mode: Just Resize, pixel perfect: True, control mode: My prompt is more important, preprocessor params: (512, -1, -1)”, Version: v1.4.0
即通过 Segment Anything + Grounding DINO + ControlNet + Inpaint 实现局部重绘。
相关文章:
Stable Diffusion - 扩展 SegmentAnything 和 GroundingDINO 实例分割算法 插件的配置与使用
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/131918652 Paper and GitHub: Segment Anything: SAM - Segment Anything GitHub: https://github.com/facebookresearch/s…...
-[基础知识])
自然语言处理从入门到应用——LangChain:提示(Prompts)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录 模型编程的新方法是使用提示(Prompts)。提示指的是模型的输入。这个输入通常由多个组件构成。PromptTemplate负责构建这个输入,LangChain提供了多个类和函数,使得构建和处…...
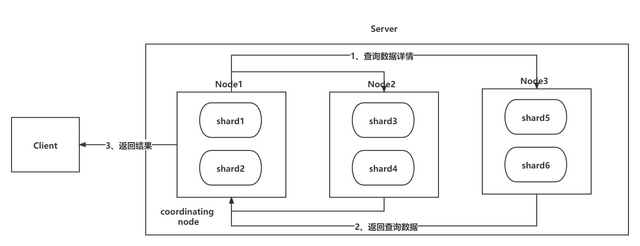
Elasticsearch-增删改查数据工作原理
集群 集群的基本概念: 集群:ES 集群由一个或多个 Elasticsearch 节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值为 “elasticsearch”。节点:一个 Elasticsearch 服务启动实例就是一个节点ÿ…...

IO进、线程——守护进程
守护进程 守护进程的创建过程 1、创建子进程,并退出父进程: 守护进程的创建通常通过fork()系统调用实现。fork()会创建一个新的子进程,该子进程是调用进程(父进程)的副本。父进程会继续执行fork()之后的代码&#x…...
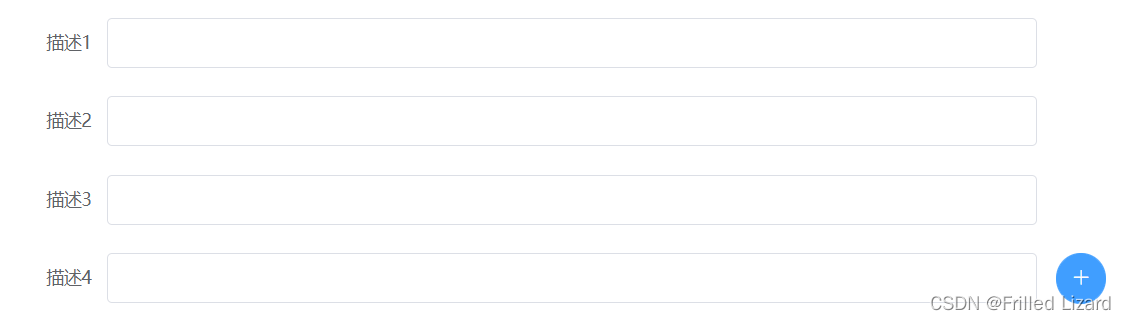
通过v-for生成的input无法连续输入
部分代码:通过v-for循环生成el-form-item,生成多个描述输入框 更改之前的代码(key绑定的是item): <el-form-item class"forminput" v-for"(item,index) in formdata.description" :key"…...

Ventoy 使用教程图文详细版
文章目录 Ventoy 使用教程图文详细版简介安装 Ventoy下载 Ventoy制作基于 Ventoy 的启动U盘使用 Ventoy复制 ISO 文件启动电脑选择 ISO 文件结论Ventoy 使用教程图文详细版 简介 Ventoy 是一款开源的 U盘 启动工具,设计用于简化从 U盘 启动操作系统的过程。其中最主要的特点是…...

脚手架 --- command框架<一>
版本:6.0.0 假设脚手架名称:big-cat-cli 实例化 const commander require(commander) const program new commander.Command()program 基本信息配置 program.name(Object.keys(pkg.bin)[0]) // 赋值name, 显示在useage 前部分.usage(<command>…...

SpringBoot整合Zookeeper
引入Jar包 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId> </dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>s…...

Java和C#选哪个?
选择语言是一个非常重要的决定,因为它可能会对你的职业生涯产生深远的影响。C#和Java都是非常流行的编程语言,它们都有自己的优点和适用场景。 可以从下面几个方面来考虑: 1、就业前景: 就业前景是选择专业时需要考虑的一个非常…...

首批!棱镜七彩通过汽车云-汽车软件研发效能成熟度模型能力评估
2023年7月25-26日,由中国信息通信研究院、中国通信标准化协会联合主办的“2023年可信云大会”隆重召开。会上,在中国信息通信研究院云计算与大数据研究所副所长栗蔚的主持下,中国信通院发布了“2023年上半年可信云评估结果”,并由…...

【Docker】容器的数据卷
目录 一、数据卷的概念与作用 二、数据卷的配置 三、数据卷容器的配置 一、数据卷的概念与作用 在了解什么是数据卷之前我们先来思考以下这些问题: 1.如果我们一个容器在使用后被删除,那么他里面的数据是否也会丢失呢?比如容器内的MySQL的…...
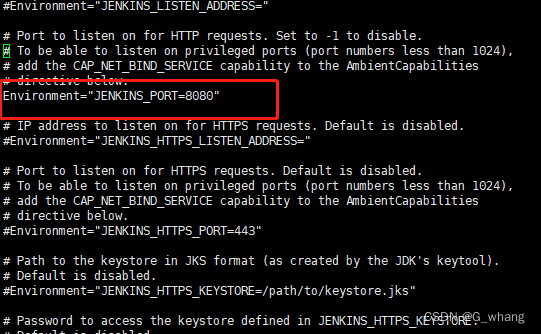
CentOS7安装jenkins
一、安装相关依赖 sudo yum install -y wget sudo yum install -y fontconfig java-11-openjdk二、安装Jenkins 可以查看官网的安装方式 安装官网步骤 先导入jenkins yum 源 sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat-stable/jenkins.repo…...

Hadoop的伪分布式安装方法
实验环境: 操作系统:Linux (Ubuntu 20.04.5) Hadoop版本:3.3.2 JDK版本:1.8.0_162 hadoop与jdk的安装包可详见博客中: https://blog.csdn.net/weixin_52308622/article/details/131947961?spm1001.2014.3001.550…...

iOS 应用上架的步骤和工具简介
APP开发助手是一款能够辅助iOS APP上架到App Store的工具,它解决了iOS APP上架流程繁琐且耗时的问题,帮助跨平台APP开发者顺利将应用上架到苹果应用商店。最重要的是,即使没有配置Mac苹果机,也可以使用该工具完成一系列操作&#…...
【信号去噪】基于马氏距离和EDF统计(IEE-TSP)的基于小波的多元信号去噪方法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

智驾SOC shell编程应用实战笔记
文章目录 1. 引言2. 基础2.1 "$"的作用3. 实战笔记3.1 统计某一端口的连接数3.2 获取当前脚本执行的绝对路径3.3 判断某一文件是否存在参考1. 引言 智驾SOC(System on a Chip)是指集成了处理器、存储器、外设和其他功能模块的片上系统,广泛应用于汽车领域中的智能…...

C#实现计算题验证码
开发环境:C#,VS2019,.NET Core 3.1,ASP.NET Core API 1、建立一个验证码控制器 新建两个方法Create和Check,Create用于创建验证码,Check用于验证它是否有效。 声明一个静态类变量存放列表,列…...

【lesson6】Linux下:第一个小程序,进度条代码
文章目录 准备工作sleep问题fflush回车与换行的区别 进度条代码 准备工作 sleep问题 首先我们来看一段代码: 这时候有个 问题这个代码是输出“hello world”还是先sleep三秒? 再来一段代码 这个代码是先sleep三秒还是先输出“hello world”ÿ…...

PostgreSQL实战-pg13主从复制切换测试
PostgreSQL实战-pg13主从复制切换测试 配置PostgreSQL的环境变量 修改/etc/profile文件, vim /etc/profile添加如下内容: # 指定postgres的数据位置 export PGDATA=/var/lib/pg13/data数据联动测试 清空数据表数据 TRUNCATE TABLE tablename;主库清空数据表数据 从库对…...

如何使用OpenCV库进行图像检测
import cv2 # 加载Haar级联分类器 face_cascade cv2.CascadeClassifier(cv2.data.haarcascades haarcascade_frontalface_default.xml) # 读取输入图像 img cv2.imread(input_image.jpg) gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 使用Haar级联分类器进行人脸检测 …...

Linux 内核中的信号处理:从发送到捕获
Linux 内核中的信号处理:从发送到捕获 引言 作为一名深耕操作系统和嵌入式开发的工程师,我深知通知机制的重要性。在系统开发中,及时的通知可以帮助系统快速响应事件。在 Linux 内核中,信号是一种重要的进程间通信机制,…...

汇川小型机 H5U编写程序 设备采用回转hu小型机编写程序不含的硬件配置有ECT的总线
汇川小型机 H5U编写程序 设备采用回转hu小型机编写程序不含的硬件配置有ECT的总线,包括汇川660系列伺服驱动器以及Io模块。 设备程序分段明确采用梯形图编写更加方便,直观,易懂各个伺服轴密切配合,实现收放卷pid调节,以…...

不止基础管理!国产 CRM 软件如何用数据分析赋能客户与销售工作
引言2026年国内企业数字化转型已进入深水区,CRM早已脱离了单纯的客户信息台账工具属性,数据分析能力成为衡量CRM产品价值的核心指标——从线索获客成本核算到跟单转化率优化,从客户复购价值挖掘到全链路风险管控,高质量的数据分析…...

4步完成Axure本地化设置:让新手轻松上手的中文界面方案
4步完成Axure本地化设置:让新手轻松上手的中文界面方案 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包,不定期更新。支持 Axure 9、Axure 10。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

【小白友好】Qwen2.5-VL-7B-Instruct快速上手:无需代码的图文智能问答工具
Qwen2.5-VL-7B-Instruct快速上手:无需代码的图文智能问答工具 1. 工具简介 Qwen2.5-VL-7B-Instruct是一款基于阿里通义千问多模态大模型的视觉交互工具,专为RTX 4090显卡优化。它最大的特点是完全可视化操作,无需编写任何代码就能实现强大的…...

JAVA面试-equals与==的本质区别
Java中 与 equals() 的区别是面试和日常开发的核心知识点,其核心差异在于比较的对象: 是比较引用地址或基本类型的值,而 equals() 是比较对象的内容,但其默认行为与重写密切相关 。 为了清晰地理解,我们可以将比较场…...

如何让Windows高效识别苹果设备?极简驱动安装工具3分钟解决连接难题
如何让Windows高效识别苹果设备?极简驱动安装工具3分钟解决连接难题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitco…...
,并放置任务栏中,.desktop文件使用)
[ linux添加应用图标到桌面 ] : 中将应用程序添加图标(快捷方式 ),并放置任务栏中,.desktop文件使用
.desktop文件格式在你的主目录中打开终端(ctrlaltt),接着输入以下代码:touch test.desktop vim test.desktop这里我选择的是vim的编辑方式,当然如果你没有vim或者说不太熟练的话,你可以直接双击打开该文件。代码解释:t…...

PrimeTime:默认配置文件
相关阅读 PrimeTimehttps://blog.csdn.net/weixin_45791458/category_12900271.html?spm1001.2014.3001.5482 当启动PrimeTime时,它会自动执行三个设置文件中的命令,这些文件具有相同的文件名.synopsys_pt.setup,但位于不同的目录中&#x…...

美国人形机器人发展浅析
美国人形机器人产业正从实验室研发向工业实用化与商业化加速过渡,主要企业(波士顿动力、特斯拉、Figure AI等)均已推出量产级产品,覆盖工业制造、军事应用等核心场景,技术迭代与规模化部署成为当前行业关键词。一、主要…...