深度学习实际使用经验总结
以下仅是个人在使用过程中的经验总结,请谨慎参考。
常用算法总结
图像分类
- 常用算法(可作为其他任务的骨干网络):
- 服务端:VGG、ResNet、ResNeXt、DenseNet
- 移动端:MobileNet、ShuffleNet等
- 适用场景:识别区分场景类型
目标检测
- 常用算法:Yolo系列
- 适用场景:检测识别场景中的目标类型及位置
目标跟踪
- 单目标:SiamFC、SiamRPN、SiamRPN++
- 多目标:ByteTrack、deep sort
- 适用场景:在上下文连续多帧中持续定位目标位置变化,如跟踪人的位置变化
人脸识别
- 人脸检测:MTCNN、RetinaFace
- 特征提取:ArcFace
- 特征匹配:Nmslib、Annoy
- 适用场景:直播、点播场景下人脸坐标定位和人物身份识别
度量学习
- 常用算法:神经网络模型 + Contrastive Learning
- 适用场景:将输入转换为高维特征,根据特征相似度完成具体任务,如音乐识别等
音频识别
- 常用算法:音频频谱 + 神经网络模型
- 适用场景:如识别音频中是否出现音乐,以及出现的是哪一首音乐
传统图像算法
- 常用算法:边缘检测、直线检测、透视变化、坐标映射
- 适用场景:如识别足球场地边缘,根据球员实时位置构建赛场态势图
常用技术总结
网络设计
- 卷积网络
- 池化
- 全连接网络
- 残差网络
- 分组卷积
- 深度可分离卷积
- Inception网络
- BatchNorm/LayerNorm
- 循环神经网络
- Transformer网络
特征融合
- FPN特征金字塔
- PAN特征融合
- UNet细粒度特征融合
- Attention全局注意力
- 多分支融合叠加
激活函数
- Sigmoid
- ReLU
- Tanh
- Leakey-ReLU
- PReLU
- Swish
优化算法
- 随机梯度下降
- 批量梯度下降
- 小批量梯度下降
- 动量梯度下降
- 自适应梯度下降
损失函数
- 单分类损失Logistic Loss
- 多分类损失CE
- 多标签分类损失BCE
- 类别不均衡损失Focal Loss
- 回归损失MSE、L1 Smoothing
- 多任务损失
- Contrastive Loss
- Label Smoothing
数据增强
- 平移/旋转/翻转/缩放
- 添加高斯噪声
- 亮度/对比度/饱和度变换
- 数据融合MixUp
- 随机掩码Cutout
- 频谱掩码(音频数据增强)
模型压缩
- 模型剪枝
- 模型重参数化
- 模型蒸馏
- 模型量化
训练策略
- 迁移学习
- 权重衰减
- 学习率衰减
- WarmUp预热
- DropOut/DropBlock
- 并行训练
- Early Stopping
使用经验总结
数据预处理:在数据预处理阶段,通常包含以下流程
- 数据加载:这部分可能涉及到大规模训练数据的高性能加载,消除数据读取造成的性能瓶颈
- 数据增强:根据具体任务选择合适的数据增强策略
- 数据归一化:将数据的数值做归一化处理,加速模型的收敛速度
网络模型设计:根据具体的业务场景,选择/设计合适的网络架构,通常遵循以下原则:
- 优先选择开源的预训练模型参数,使用自有数据进行微调训练
- 使用开源预训练模型的基础部分,修改模型的上层适配自有的业务场景
- 根据业务场景自行设计模型架构(通常只在没有开源参考模型的条件下使用,模型效果很难得到保证)
- 通常情况下对于图像、视频数据,追求模型效果一般使用ResNet34、ResNet50等模型架构,追求处理性能一般使用ResNet18、MobileNet、ShuffleNet模型架构
损失函数设计:根据具体业务场景,选择/设计合适的损失函数,通常遵循以下原则:
- 分类场景一般使用交叉熵损失Cross Entropy
- 类别极度不均衡的分类场景(不均衡比例超过1000以上),分类损失尝试Focal Loss
- 在分类损失场景下使用Label Smoothing软化模型的学习能力
- 回归损失根据使用场景可选MSE、MAE、L1 Smoothing等
- 表征学习(也叫对比学习或度量学习)优先使用Circle Loss、ArcFace Loss、Triplet Loss等损失函数,模型训练时根据具体业务场景适当增大训练批量batch size,提升表征学习的特征区分度
训练策略:迭代训练更新模型参数,逐步提升模型效果
- 优先使用小批量梯度下降 + Momentum动量 + LR decay学习率衰减 + Weight Decay权重衰减训练策略
- 如果使用多GPU并行训练,训练的批量大小batch size和学习率LR要同比例改变
- 先使用极少的训练数据验证模型训练效果,排除模型在设计上的问题和工程化问题,然后再迁移到大数据量,避免造成无效的资源和时间浪费
- 模型训练过程中保存每轮迭代预测异常的数据,通过bad case分析,逐步提升数据质量或调整模型策略
- 保存模型每轮迭代的准确率、召回率、loss变化曲线,监控是否发生过拟合、欠拟合等问题
模型验证:使用实际场景数据验证模型的预测性能,包括效果和速度
- 优先检查网络架构和模型参数的匹配情况,防止参数不匹配带来的潜在错误(问题较难定位)
- 使用训练数据验证模型的预测效果,排除训练和验证阶段数据处理不一致带来的差异
- 保证验证数据和训练数据具有相同或相似的数据分布
- 将模型转换为推理模式,固化BatchNorm、Dropout等具有随机性的操作
- 避免不必要的资源消耗,如使用torch.no_grad避免不必要的显存占用
- 关注模型在推理阶段的显卡内存占用,保证分配的内存资源大于波动的峰值
常见问题和思考——模型训练阶段
模型训练效果差
- 常见问题:神经网络模型在训练过程中,没有学习到有效的信息,模型收敛慢或者不收敛
- 原因分析:
- 训练数据中存在脏数据(首要排除的因素)
- 没有使用预训练模型和数据归一化
- 训练集过大,模型容量小,出现欠拟合
- 训练集过小,模型容量大,出现过拟合
- 学习率设置过大,导致参数更新过快,结果出现震荡
- 学习率设置过小,导致参数更新过慢,学习进展缓慢
- 数值稳定性问题导致数值溢出,出现梯度爆炸
- 网络设计问题导致梯度消失
- 使用了不合理的批量大小
- 使用了不合理的训练迭代次数及停止策略
- 使用了不合理的学习率衰减策略
- 使用了不合理的参数初始化策略
- 使用了不合理的数据增强,比如检测人体时对图像做了上下翻转
- 使用了不合理的损失函数,比如分类问题使用回归损失函数
- 使用了不合理的网络架构,根据一维、二维、多维、时序数据选择合适的架构
- 使用了较强的正则化,限制模型的学习能力,出现欠拟合
- 使用了较弱的正则化,过渡学习训练集,出现过拟合
模型训练速度慢
- 常见问题:神经网络模型训练慢,主要体现在收敛慢、资源使用率低等方面
- 原因分析:
- 没有使用GPU资源进行模型训练
- 模型训练时使用过小的学习率,导致参数更新慢
- 模型训练时使用了过大的batch size,导致参数更新频次少
- 模型训练时使用了过小的batch size,没有充分利用计算资源
- 没有使用预训练参数,重头训练效率低
- 没有使用Batch Norm等做数据归一化
- 训练过程中存在过多的内存、磁盘访问
- 模型过于简单,不具备学习复杂任务的能力
- 使用了过强的正则化,限制了模型的学习能力
- 没有使用单机多卡、多机多卡并行训练
- 模型复杂度高,参数量大,以及使用过大的图像分辨率
- 训练数据量大,数据加载成为性能瓶颈
常见问题和思考——模型预测阶段
模型预测指标
- 分类模型:准确率、召回率、PR曲线、ROC曲线(类别不均衡)
- 检测模型:mAP、准确率、召回率
- 特征提取模型:top 1、top K、r_precision
模型预测效果差
- 常见问题:神经网络模型训练效果较好,但是在预测阶段模型表现较差
- 原因分析:
- 模型训练和测试的数据处理pipeline不一致,比如训练时做了Normalize,测试时没做Normalize
- 模型在测试时没有切换到推理模式,如pytorch中的eval()转换
- 输入的数据维度不正确,比如训练时使用[N, C, H, W],测试时也要使用同样的数据维度顺序,有些模型即使输入的数据尺寸和训练时不一样也不会报错
- 模型参数加载不完全,以pytorch框架为例,加载模型时设置完全匹配的参数为False,在加载过程中即使参数和模型不匹配也不会报错,但是会使用默认的随机参数
模型预测资源占用高
- 常见问题:神经网络模型在预测阶段GPU使用率低,CPU使用率高,或者出现显卡内存溢出
- 原因分析:
- 数据预处理在CPU上进行,没有充分利用GPU算力
- 在预测阶段模型没有设置成推理模式,计算产生无用的中间结果占用资源
- 深度学习框架如Pytorch自动搜索最优算子导致显存占用短暂飙升
模型处理未知类别
- 常见问题:如何让分类模型对未见过的数据类别说“不知道,不认识”,提升鲁棒性
- 解决方案:
- 给分类模型添加一个其他类别,此种方法不适用于真实开放环境
- 使用BCE(Binary Cross Entropy)多标签二分类损失函数,以猫狗分类为例,分别输出是猫狗的概率,如果输出既不是猫也不是狗,则表示未知
- 使用表征学习(度量学习)方法通过特征匹配进行分类识别,将输入的数据与已知类别进行相似度匹配
模型效果提升
- bad case分析:数据决定了模型的上限,提升模型性能首先应当从数据层面入手,避免脏数据带来的负面影响
- 数据增强:通过给训练数据增加异常扰动提升模型效果的鲁棒性
- 图像数据增强:随机裁剪、旋转、翻转、缩放、颜色/亮度/对比度调整、多图像融合等
- 音频数据增强:频谱随机连续掩码、多频谱融合等
- 选择合适的网络架构:针对具体的使用场景选择合适的网络架构,如图像使用2D卷积、音频使用1D卷积等
- 选择合适的损失函数:针对具体任务使用合适的损失函数,常见的是分类损失、回归损失及混合损失
- 选择合适的评价指标:如分类使用准确率、召回率,类别不均衡使用ROC,目标检测使用mAP等
- 使用开源预训练模型:预训练模型通常具备较好的参数基础,在此基础上进行训练有助于提升性能
- 多模型融合:使用不同的弱模型训练多个效果稍弱的模型,融合多个模型结果提升最终性能
- 知识蒸馏:使用知识蒸馏将大模型学习到的知识迁移到小模型,在提升效果的同时还可以提升速度
常见问题与思考——模型推理加速
模型推理加速
- 数据处理层面
- 将数据预处理、后处理等操作在GPU上进行
- 避免在CPU和GPU之间频繁进行数据拷贝
- 避免保存大量的中间结果,如磁盘写入
- 网络模型层面
- 模型剪枝:根据具体业务场景,裁剪掉与业务不相关的计算模块
- 算子融合:将多个算子融合成一个,减少内存访问次数,如将Conv + BN融合成Conv
- 半精度推理:使用float16进行模型推理
- 分组卷积:使用分组卷积降低网络模型的参数量和计算量,但是会增加内存访问次数
- 模型蒸馏:将大模型学习到的知识迁移到小模型,在提升效果的同时还可以提升速度
- 部署工具层面
- 服务端:ONNX、TensorRT
- 移动端:NCNN、MNN
影响模型速度的主要因素
- 数据处理层面
- 没有使用GPU资源进行推理
- 输入数据尺寸大,如高分辨率图像
- 模型架构层面
- 网络模型参数量大
- 网络模型计算量大
- 网络模型并行度低,如存在多分支结构等
- 内存访问次数多,如大量使用分组卷积
- 工程实现层面
- 没有使用批量推理,没有充分利用GPU的并行计算能力
- 不合理的数据复用导致频繁拷贝
常见问题与思考——工程化问题
工程化常见问题
- 算法集群扩容
- kafka topic的partition数量要大于算法消费者数量
- 直播场景混流和AI算法结果对齐
- 算法解码处理直播流内容,获取每帧的dts、pts时间戳
- 混流侧根据算法返回结果以及dts、pts时间戳对齐到原流,将算法结果压制到直播流中
- 算法侧和混流侧使用pts解码时间戳对齐,不用dts时间戳,否则会造成画面闪烁
- Kafka、Redis数据保存周期
- 根据业务场景和处理性能设定保存周期,保存周期过长造成额外资源占用,保存周期过短造成数据丢失
- Restful API高稳定性、高并发
- 算法模型对外提供API接口需要关注高并发、高稳定性,通常使用gunicorn进行部署
- 算法模型高并发部署需要成倍的资源,重点关注显存、内存和CPU资源占用情况
- 容器化部署
- 关注容器CUDA版本与主机显卡驱动,以及深度学习框架之间的匹配问题
相关文章:

深度学习实际使用经验总结
以下仅是个人在使用过程中的经验总结,请谨慎参考。 常用算法总结 图像分类 常用算法(可作为其他任务的骨干网络):服务端:VGG、ResNet、ResNeXt、DenseNet移动端:MobileNet、ShuffleNet等适用场景&#x…...

【广州华锐互动】AR智慧机房设备巡检系统
AR智慧机房设备巡检系统是一种新型的机房巡检方式,它通过使用增强现实技术将机房设备、环境等信息实时呈现在用户面前,让巡检人员可以更加高效地完成巡检任务。 首先,AR智慧机房设备巡检系统具有极高的智能化程度。该系统可以根据用户设定的…...
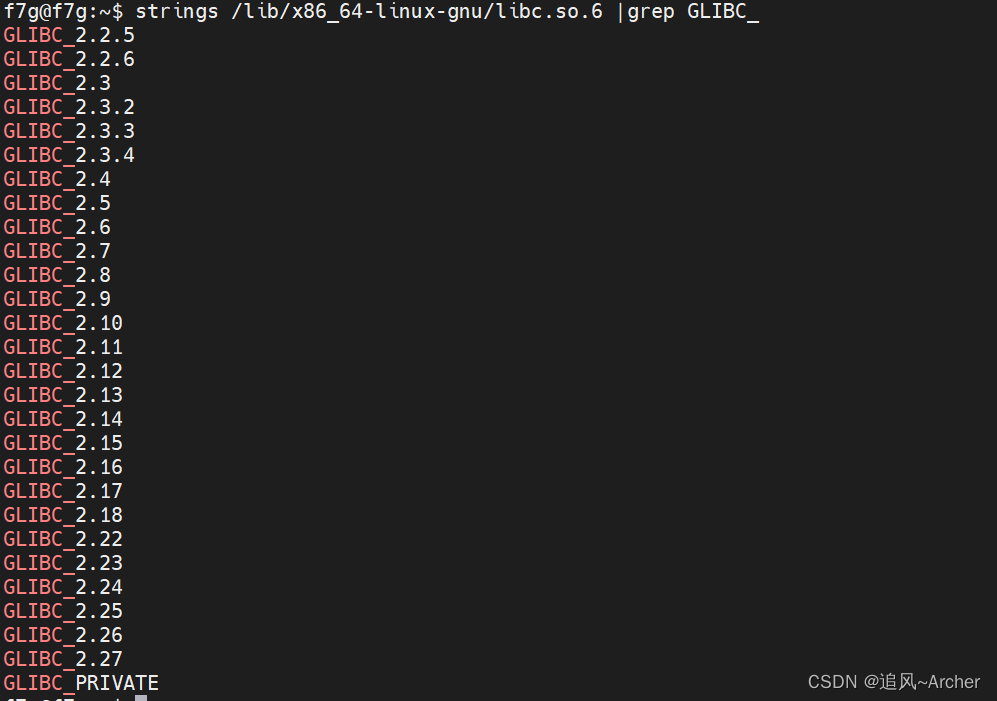
关于Ubuntu 18.04 LTS环境下运行程序出现的问题
关于Ubuntu 18.04 LTS环境下运行程序出现的问题 1.运行程序时出现以下情况 2.检查版本 strings /lib/x86_64-linux-gnu/libc.so.6 |grep GLIBC_ 发现Ubuntu18.04下的glibc版本最高为2.27,而现程序所使用的是glibc2.34,所以没办法运行, 3.解决办法 安装glibc2.34库, …...
「苹果安卓」手机搜狗输入法怎么调整字体大小及键盘高度?
手机搜狗输入法怎么调整字体大小及键盘高度? 1、在手机上准备输入文字,调起使用的搜狗输入法手机键盘; 2、点击搜狗输入法键盘左侧的图标,进入更多功能管理; 3、在搜狗输入法更多功能管理内找到定制工具栏,…...
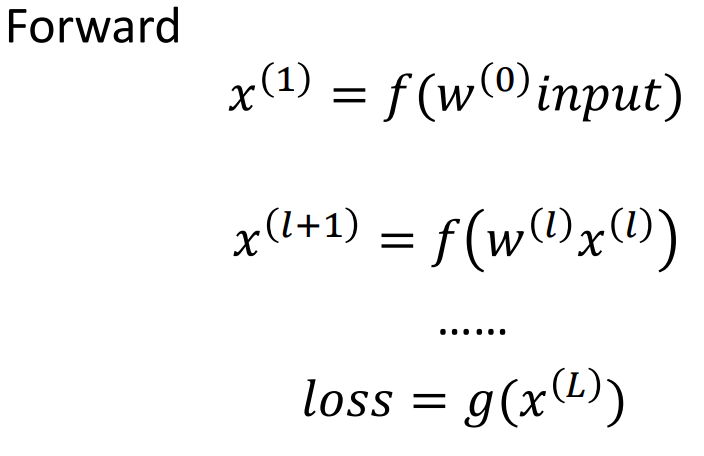
【人工智能】神经网络、前向传播、反向传播、梯度下降、局部最小值、多层前馈网络、缓解过拟合的策略
神经网络、前向传播、反向传播 文章目录 神经网络、前向传播、反向传播前向传播反向传播梯度下降局部最小值多层前馈网络表示能力多层前馈网络局限缓解过拟合的策略前向传播是指将输入数据从输入层开始经过一系列的权重矩阵和激活函数的计算后,最终得到输出结果的过程。在前向…...

一个tomcat部署两个服务的server.xml模板
一个服务的文件夹名字叫hospital,一个服务的文件夹叫ROOT,一个tomcat运行两个服务如何配置呢?注意一个appBase为webapps,另一个appBase为webapps1,当然也可以放在一个webappps里面。 <Service name"Catalina">&l…...

CentOS 7安装Docker
文章目录 安装Docker1.CentOS安装Docker1.1.卸载(可选)1.2.安装docker1.3.启动docker1.4.配置镜像加速 2.CentOS7安装DockerCompose2.1.下载2.2.修改文件权限2.3.Base自动补全命令: 3.Docker镜像仓库3.1下载一个镜像 安装Docker Docker 分为 …...

Nginx前端部署
1. 前端打包 执行如下命令,构建前端代码,构建成功后会在目录dist下生成构建完成的文件,将dist整个文件夹拷贝到服务器中 npm install npm run build dev 2.nginx配置 进入nginx目录/usr/local/nginx/conf,修改nginx.conf文件&a…...

17网商品详情API:使用与数据解析方法
17网是一家知名的电商平台,提供了大量的商品选择。开发者可以通过17网的商品详情API来快速获取和展示商品的详细信息。 17网商品详情API简介 介绍17网商品详情API的作用和目的,解释为何使用该API可以实现丰富的商品详情展示功能。 获取API访问权限 说…...
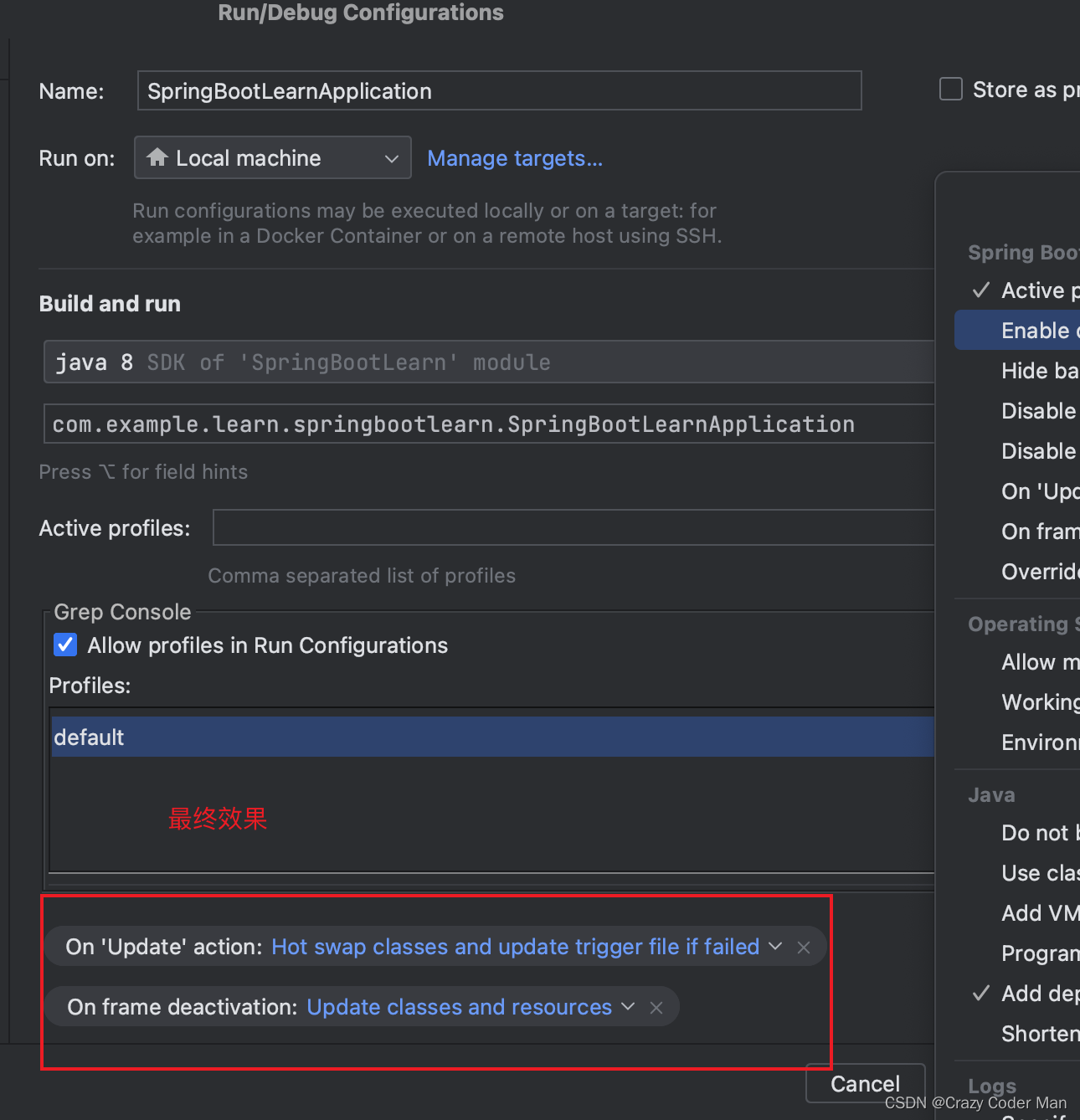
解决新版 Idea 中 SpringBoot 热部署不生效
标题 依赖中添加 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <opt…...

Node.js: express + MySQL实现修改密码
实现修改密码,本篇文章实现修改密码只考虑以下几个方面: (1),获取旧密码 (2),获取新密码 (3),将获取到的旧密码与数据库中的密码进行比对…...

ArduPilot之433电传模块集成之H7Dual飞控Rx/Tx丝印问题
ArduPilot之433电传模块集成之H7Dual飞控Rx/Tx丝印问题 1. 源由2. 安装3. 排查3.1 电气连接3.2 软件配置3.3 模块测试3.4 通信测试3.5 定位问题 4. 总结5. 参考资料 1. 源由 鉴于最近iNav最新固件6.1.1出现远航炸机,还是回到相对可靠的Ardupilot,在Mavl…...

python爬虫优化手段
当使用Python进行网络资源爬取时,会涉及到网络请求、数据处理和存储等操作,这些操作可能会对电脑性能产生一定的影响。以下是一些关于Python爬取网络资源的常见注意事项: 网络请求频率:频繁的网络请求可能会对电脑性能产生较大的影…...

Bootstrap-学习文档
Bootstrap 简介 什么是 Bootstrap? Bootstrap 是一个用于快速开发 Web 应用程序和网站的前端框架。 Bootstrap是前端开发中比较受欢迎的框架,简洁且灵活。它基于HTML、CSS和JavaScript,HTML定义页面元素,CSS定义页面布局&#x…...
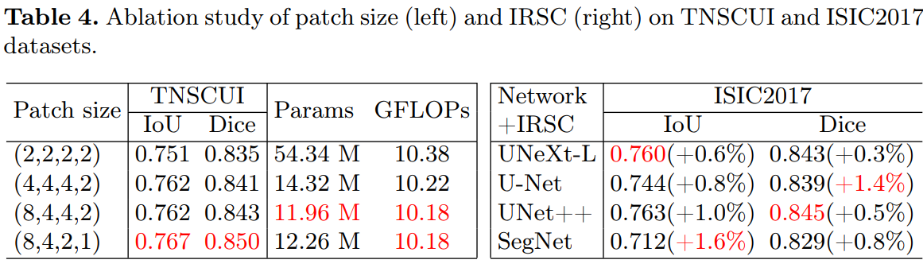
【图像分类】CNN + Transformer 结合系列.1
介绍三篇结合使用CNNTransformer进行学习的论文:CvT(ICCV2021),Mobile-Former(CVPR2022),SegNetr(arXiv2307). CvT: Introducing Convolutions to Vision Transformers, …...

Stable Diffusion - 扩展 SegmentAnything 和 GroundingDINO 实例分割算法 插件的配置与使用
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/131918652 Paper and GitHub: Segment Anything: SAM - Segment Anything GitHub: https://github.com/facebookresearch/s…...
-[基础知识])
自然语言处理从入门到应用——LangChain:提示(Prompts)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录 模型编程的新方法是使用提示(Prompts)。提示指的是模型的输入。这个输入通常由多个组件构成。PromptTemplate负责构建这个输入,LangChain提供了多个类和函数,使得构建和处…...
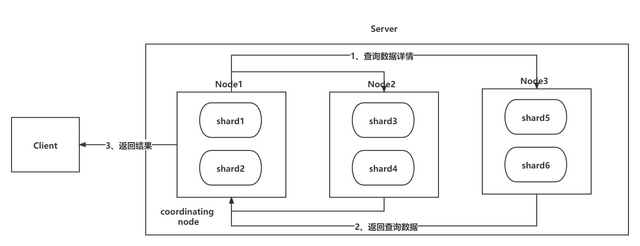
Elasticsearch-增删改查数据工作原理
集群 集群的基本概念: 集群:ES 集群由一个或多个 Elasticsearch 节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值为 “elasticsearch”。节点:一个 Elasticsearch 服务启动实例就是一个节点ÿ…...

IO进、线程——守护进程
守护进程 守护进程的创建过程 1、创建子进程,并退出父进程: 守护进程的创建通常通过fork()系统调用实现。fork()会创建一个新的子进程,该子进程是调用进程(父进程)的副本。父进程会继续执行fork()之后的代码&#x…...
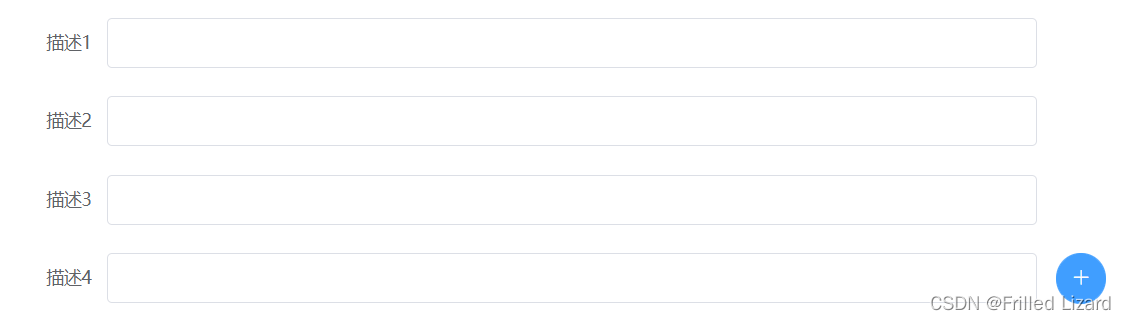
通过v-for生成的input无法连续输入
部分代码:通过v-for循环生成el-form-item,生成多个描述输入框 更改之前的代码(key绑定的是item): <el-form-item class"forminput" v-for"(item,index) in formdata.description" :key"…...

大厂面试秘籍:AI岗位必问的10道题解析
在人工智能技术迅猛发展的今天,AI测试开发岗位已成为大厂竞相争夺的热门领域。对于软件测试从业者而言,转型AI岗位不仅是职业跃迁的机遇,更是技术深化的挑战。一、基础概念题:AI、ML、DL的区别及测试意义这道题考察对人工智能生态…...

生成式AI系统“内容生成”合规:架构师如何避免“虚假信息”?附4个方法
生成式AI内容生成合规指南:架构师如何系统性规避虚假信息? 元数据框架 标题 生成式AI内容生成合规指南:架构师如何系统性规避虚假信息?——从理论到实践的4大核心策略 关键词 生成式AI合规, 虚假信息防范, 事实一致性, 架构设计, …...

OpenCore Legacy Patcher:让旧Mac重获新生的终极指南
OpenCore Legacy Patcher:让旧Mac重获新生的终极指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款革命性的开源…...

MatterGen:深度学习驱动的无机材料设计新范式
MatterGen:深度学习驱动的无机材料设计新范式 【免费下载链接】mattergen Official implementation of MatterGen -- a generative model for inorganic materials design across the periodic table that can be fine-tuned to steer the generation towards a wid…...

下篇:那个听声辨位的侦探后来破了大案——AI中隐马尔可夫模型的类型与作用,以及它为什么还在被使用
我们说了隐马尔可夫模型是一个“只能听声、不能见人”的侦探,靠着一串声音推理出隔壁房间在发生什么。现在的问题是:它到底有哪些具体的“形态”?不同类型的隐马尔可夫模型分别擅长什么?这个“老古董”在今天还能干什么࿱…...
)
【2026年最新600套毕设项目分享】基于springboot+vue的无人机共享管理系统(14299)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

收藏!从Prompt到Harness,AI工程升级三步搞定大模型应用
本文阐述了AI工程从关注Prompt到Context再到Harness的演进过程。Prompt工程负责明确任务指令,Context工程负责提供准确有效的信息供给,而Harness工程则关注AI在系统中的可靠执行与治理。三者并非替代关系,而是嵌套协作,共同推动AI…...

如何突破Cursor AI试用限制:3种方法重新获得Pro功能
如何突破Cursor AI试用限制:3种方法重新获得Pro功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...
,适配不同需求。)
摒弃固定显示界面,程序根据使用场景,自动切换显示界面(简洁版/详细版),适配不同需求。
一、 实际应用场景描述 (Scenario)假设你正在开发一台高精度光谱分析仪。这台设备有三种典型的使用者:1. 研发工程师(R&D):在实验室调试光路和算法。他们需要看到原始 ADC 值、温度漂移曲线、信噪比等详细数据。2. 质检员&…...

如何一站式解决漫画格式转换难题:CBconvert完整指南
如何一站式解决漫画格式转换难题:CBconvert完整指南 【免费下载链接】cbconvert CBconvert is a Comic Book converter 项目地址: https://gitcode.com/gh_mirrors/cb/cbconvert 还在为不同设备上的漫画格式兼容性问题而烦恼吗?CBconvert作为一款…...