一、1、Hadoop的安装与环境配置
安装JDK:
首先检查Java是否已经安装:
java -version如果没有安装,点击链接https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 并选择相应系统以及位数下载(本文选择jdk-8u381-linux-x64.tar.gz,如具体版本不同则灵活修改)
为其单独创立一个文件夹,然后将其放到该目录下(下载后以具体为止为准):
sudo mkdir -p /usr/local/java
sudo mv ~/Downloads/jdk-8u381-linux-x64.tar.gz /usr/local/java/进入该目录进行解压:
cd /usr/local/java
sudo tar xvzf jdk-8u381-linux-x64.tar.gz解压成功后会在当前目录下看到jdk1.8.0_381安装包,然后删除安装包:
sudo rm jdk-8u381-linux-x64.tar.gz配置JDK:
设置环境变量,打开环境变量的配置文件:
sudo vim /etc/profile在末尾添加:
JAVA_HOME=/usr/local/java/jdk1.8.0_381
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export JAVA_HOME
export PATH告诉linux Java JDK的位置并设置为默认模式:
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/local/java/jdk1.8.0_381/bin/java" 1
sudo update-alternatives --install "/usr/bin/javac" "javac" "/usr/local/java/jdk1.8.0_381/bin/javac" 1
sudo update-alternatives --install "/usr/bin/javaws" "javaws" "/usr/local/java/jdk1.8.0_381/bin/javaws" 1
sudo update-alternatives --set java /usr/local/java/jdk1.8.0_381/bin/java
sudo update-alternatives --set javac /usr/local/java/jdk1.8.0_381/bin/javac
sudo update-alternatives --set javaws /usr/local/java/jdk1.8.0_381/bin/javaws重新加载环境变量的配置文件:
source /etc/profile检测Java版本:
java -version如果出现以下代表成功:
java version "1.8.0_381"
Java(TM) SE Runtime Environment (build 1.8.0_381-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.381-b07, mixed mode)安装Hadoop:
进入镜像文件https://mirrors.cnnic.cn/apache/hadoop/common/ 选择对应Hadoop版本(本文选择hadoop-3.3.6.tar.gz)
然后将其解压至刚刚创建的文件夹 /usr/local并删除安装包:
sudo tar -zxf ~/Downloads/hadoop-3.3.6.tar.gz -C /usr/local
rm ~/Downloads/hadoop-3.3.6.tar.gz重命名文件夹并修改权限(其中phenix为用户名):
cd /usr/local/
sudo mv hadoop-3.3.6 hadoop
sudo chown -R phenix ./hadoop检测hadoop版本:
/usr/local/hadoop/bin/hadoop version出现以下信息则代表成功:
Hadoop 3.3.6
Subversion ssh://git.corp.linkedin.com:29418/hadoop/hadoop.git -r e2f1f118e465e787d8567dfa6e2f3b72a0eb9194
From source with checksum 7b2d8877c5ce8c9a2cca5c7e81aa4026
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar配置Hadoop(伪分布式):
切换到路径/usr/local/hadoop/etc/hadoop下,需要修改2个配置文件core-site.xml和hdfs-site.xml。
首先打开core-site.xml
cd /usr/local/hadoop/etc/hadoop
vim core-site.xml在<configuration></configuration>中添加如下配置:
<configuration><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>注:本文使用的是hdfs://localhost:9000即hdfs文件系统
再打开hdfs-site.xml:
vim hdfs-site.xml同样在<configuration></configuration>中添加如下配置:
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/usr/local/hadoop/tmp/dfs/data</value></property>
</configuration>注:dfs.replication就是指备份的份数;dfs.namenode.name.dir和dfs.datanode.data.dir分别指名称节点和数据节点存储路径
切换回hadoop主目录并执行NameNode的格式化(格式化成功后轻易不要再次格式化):
cd /usr/local/hadoop
./bin/hdfs namenode -format出现以下信息代表成功:
00000000 using no compression
18/08/20 11:07:16 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 320 bytes saved in 0 seconds .
18/08/20 11:07:16 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/08/20 11:07:16 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at phenix/127.0.1.1
************************************************************/手动添加JAVA_HOME,在hadoop-env.sh文件中添:
cd etc/hadoop/
vim hadoop-env.sh在hadoop-env.sh文件中添加如下内容即可:
export JAVA_HOME=/usr/local/java/jdk1.8.0_381设置本机免密码登录(不设置启动会报错Permission denied)
切换到 ~/.ssh目录下:
ssh-keygen -t rsa
# 一路回车+yes
cat id_rsa.pub >> authorized_keys
# 将公钥追加到authorized_keys文件
chmod 600 authorized_keys
# 更改权限开启NameNode和DataNode守护进程:
./sbin/start-dfs.sh开启yarn资源管理器:
./sbin/start-yarn.sh验证:
jps出现以下六个则代表启动成功:
18192 DataNode
18922 NodeManager
20044 Jps
18812 ResourceManager
18381 SecondaryNameNode
18047 NameNode简单示例:
首先切换至hadoop主目录并在HDFS中创建用户目录:
./bin/hdfs dfs -mkdir -p /user/hadoop
创建输入文件夹:
./bin/hdfs dfs -mkdir /user/hadoop/input将etc/hadoop下所有的xml文件复制到输入:
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input然后通过命令查看:
./bin/hdfs dfs -ls /user/hadoop/input结果如下:
Found 8 items
-rw-r--r-- 1 phenix supergroup 8814 2020-01-31 13:21 /user/hadoop/input/capacity-scheduler.xml
-rw-r--r-- 1 phenix supergroup 1119 2020-01-31 13:21 /user/hadoop/input/core-site.xml
-rw-r--r-- 1 phenix supergroup 10206 2020-01-31 13:21 /user/hadoop/input/hadoop-policy.xml
-rw-r--r-- 1 phenix supergroup 1173 2020-01-31 13:21 /user/hadoop/input/hdfs-site.xml
-rw-r--r-- 1 phenix supergroup 620 2020-01-31 13:21 /user/hadoop/input/httpfs-site.xml
-rw-r--r-- 1 phenix supergroup 3518 2020-01-31 13:21 /user/hadoop/input/kms-acls.xml
-rw-r--r-- 1 phenix supergroup 5939 2020-01-31 13:21 /user/hadoop/input/kms-site.xml
-rw-r--r-- 1 phenix supergroup 690 2020-01-31 13:21 /user/hadoop/input/yarn-site.xml运行grep:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep /user/hadoop/input output 'dfs[a-z]+'查看运行结果:
./bin/hdfs dfs -cat output/*出现以下输出则说明Hadoop集群搭建完成:
1 1 dfsadmin我们还可以利用HDFS Web界面,不过只能查看文件系统数据,点击链接http://ip:9870即可进行查看
相关文章:

一、1、Hadoop的安装与环境配置
安装JDK: 首先检查Java是否已经安装: java -version 如果没有安装,点击链接https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 并选择相应系统以及位数下载(本文选择jdk-8u381-linux-x64…...
:论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失)
剑指YOLOv7改进最新MPDIoU损失函数(23年7月首发论文):论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失
💡本篇内容:剑指YOLOv7改进最新MPDIoU损失函数(23年7月首发论文):论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失 💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可 💡:重点:该专栏《剑指YOLOv7原…...
)
前端JavaScript面试100问(上)
1、解释一下什么是闭包 ? 闭包:就是能够读取外层函数内部变量的函数。闭包需要满足三个条件: 访问所在作用域;函数嵌套;在所在作用域外被调用 。 优点: 可以重复使用变量,并且不会造成变量污染 。缺点&am…...

C语言第九课------------------数组----------------C中之将
作者前言 作者介绍: 作者id:老秦包你会, 简单介绍: 喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 个人主页::小小页面 gitee页面:秦大大 一个爱分享的小博主 欢迎小可爱…...
MySQL的安装
掌握在Windows系统中安装MySQL数据库 MySQL的介绍 MySQL数据库管理系统由瑞典的DataKonsultAB公司研发,该公司被Sun公司收购,现在Sun公司又被Oracle公司收购,因此MySQL目前属于 Oracle 旗下产品。MySQL 软件采用了双授权政策,分…...
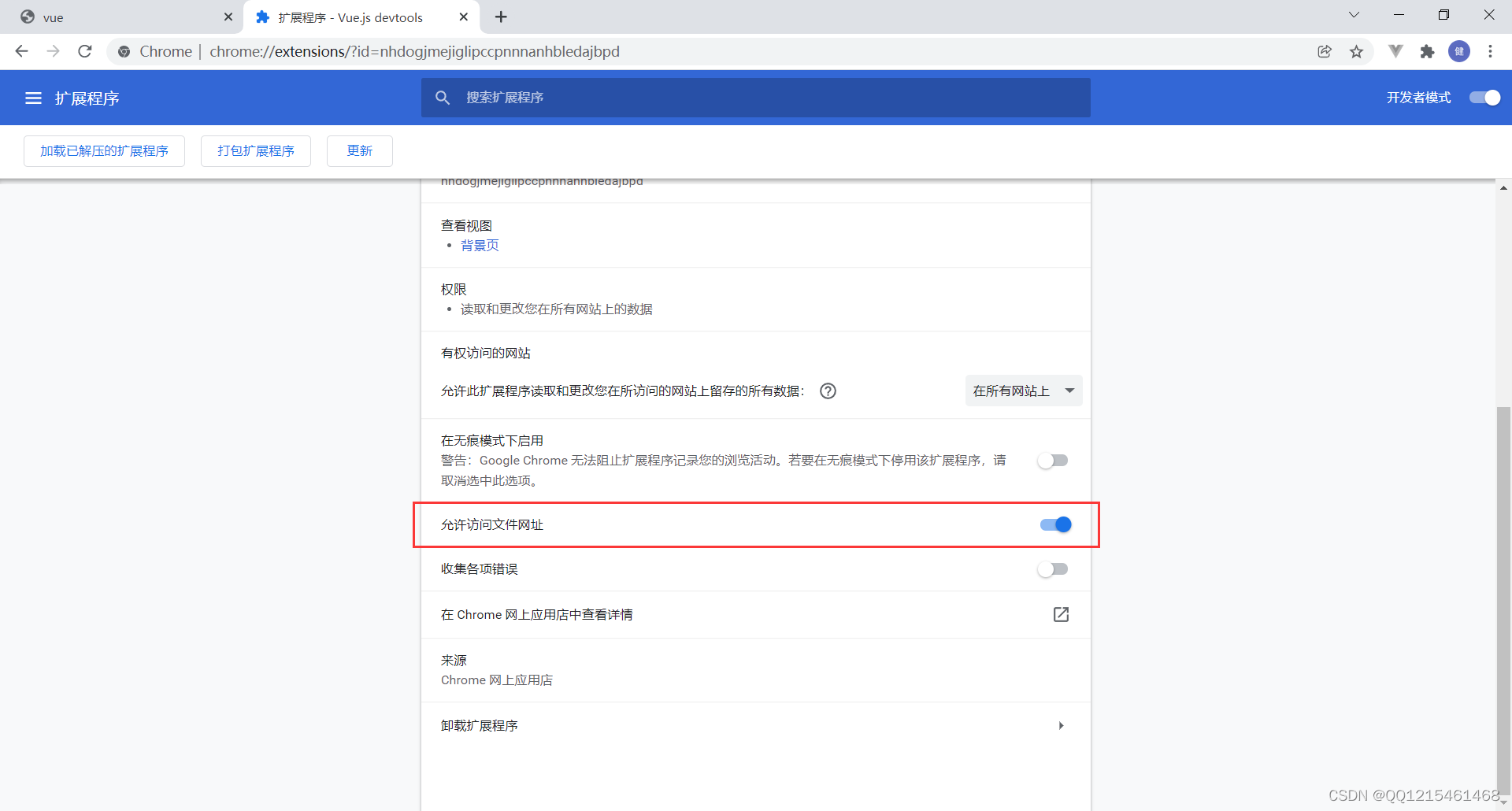
在Chrome(谷歌浏览器)中安装Vue.js devtools开发者工具及解决Vue.js not detected报错
文章目录 一、Vue.js devtools开发者工具安装1.打开谷歌浏览器——点击扩展程序——选择管理扩展程序2.先下载添加一个谷歌助手到扩展程序中(根据提示进行永久激活)3.点击谷歌浏览器的应用商店4.输入Vue.js devtools——搜索——选择下载 二、解决Vue.js…...
算法在MovieLens ml-100k数据集上构建精确的推荐系统:深入理解GroupLens数据的操作)
用Python实现概率矩阵分解(PMF)算法在MovieLens ml-100k数据集上构建精确的推荐系统:深入理解GroupLens数据的操作
第一部分:推荐系统的重要性以及概率矩阵分解的介绍 在如今的数字化时代,推荐系统在我们的日常生活中起着重要的作用。无论我们在哪个电商网站上购物,哪个音乐平台听歌,或者在哪个电影网站看电影,都会看到推荐系统的身影。它们根据我们的喜好和行为,向我们推荐可能喜欢的…...

WPF icon的设置
想给控件设置个圆形图片,代码如下: <Setter Property"Icon"><Setter.Value><Image Source"/WpfApp1;component/Resource/1.ico" Width"16" Height"16"/></Setter.Value></Setter&…...

使用frp中的xtcp映射穿透指定服务实现不依赖公网ip网速的内网穿透p2p
使用frp中的xtcp映射穿透指定服务实现不依赖公网ip网速的内网穿透p2p 管理员Ubuntu配置公网服务端frps配置service自启(可选) 配置内网服务端frpc配置service自启(可选) 使用者配置service自启(可选) 效果 通过frp实现内网client访问另外一个内网服务器 管理员 1)…...
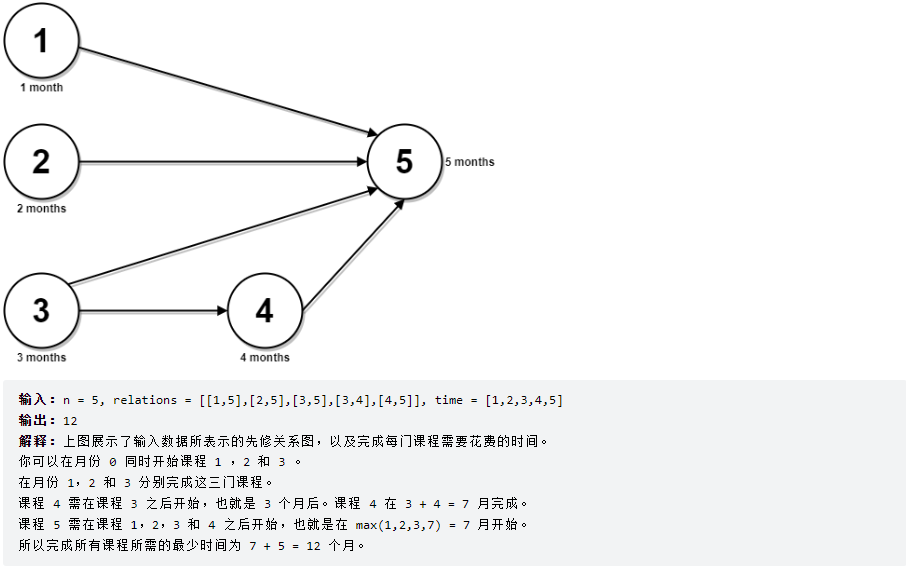
2023-07-28 LeetCode每日一题(并行课程 III)
2023-07-28每日一题 一、题目编号 2050. 并行课程 III二、题目链接 点击跳转到题目位置 三、题目描述 给你一个整数 n ,表示有 n 节课,课程编号从 1 到 n 。同时给你一个二维整数数组 relations ,其中 relations[j] [prevCoursej, next…...
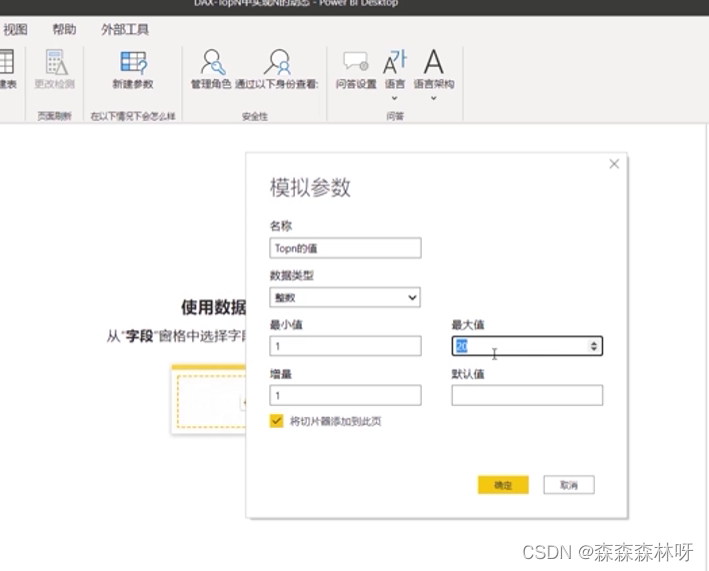
8.11 PowerBI系列之DAX函数专题-TopN中实现N的动态
需求 实现 1 ranking by amount rankx(allselected(order_2[产品名称]),[total amount]) 2 rowshowing_boolean var v_ranking [ranking by amount] var v_topN-no [topN参数 值] var v_result int( v_ranking < v_topN_no) return v_result 3 将度量值2放入视觉对象筛…...

后端性能测试的类型
目录 性能测试的类型 负载测试(load testing) 压力测试(Stress Testing) 可扩展性测试( 尖峰测试(Spike Testing) 耐久性测试(Endurance Testing) 并发测试(Concurrency Testing) 容量测试(Capacity Testing) 资料获取方法 性能测试的类型 性能测试:确定软…...

关闭Tomcat的日志输出
要关闭Tomcat的日志输出,您可以在Tomcat的配置文件中进行相应的调整。具体地说,您可以通过修改logging.properties文件来关闭Tomcat的日志输出。这个文件通常位于Tomcat的conf目录下。请按照以下步骤进行: 打开Tomcat安装目录,找…...

express 路由匹配和数据获取
express配置路由只需要通过app.method(url,func)来配置,其中url配置和其中的参数获取方法不同 直接写全路径 路由中允许存在. get请求传入的参数 router.get("/home", (req, res) > {res.status(200).send(req.query); });通过/home?a1会收到对象…...

62 | Python 操作 PDF
文章目录 Python 操作 PDF 教程1. 安装 PyPDF22. 读取 PDF 文件3. 创建 PDF 文件4. 修改 PDF 文件练习题1. 创建一个新的 PDF 文件,其中包含两个页面。第一个页面包含一段文本和一张图片,第二个页面包含一个表格。2. 打开练习题中创建的 PDF 文件,并将第一个页面中的文本修改…...

[SQL挖掘机] - 左连接: left join
介绍: 左连接是一种多表连接方式,它以左侧的表为基础,并返回满足连接条件的匹配行以及左侧表中的所有行,即使右侧的表中没有匹配的行。左连接将左表的每一行与右表进行比较,并根据连接条件返回结果集。 左连接的工作原理如下&am…...
Android 之 使用 SoundPool 播放音效
本节引言: 第九章给大家带来的是Android中的多媒体开发,与其说是多媒体开发还不如是多媒体相关API的 的使用,说下实际开发中我们做了一些和多媒体搭边的东西:拍照,录音,播放音乐,播放视频... 嗯…...

防火墙的ALG、NAT、双机热备知识点详解
具体的NAT和双机热备实验请到:NAT与双机热备实验 目录 1、ALG 2、NAT ALG 3、NAT域间双向转换 4、NAT域内双向转换 5、双出口NAT 6、防火墙的双机热备 解决方案1:VGMP 6.1 双机热备份技术产生的背景: 6.2 VRRP在多区域防火墙组网中的…...

传染病模型
title: 传染病模型 date: 2023-7-24 10:55:00 updated: 2023-7-24 10:55:00 tags: 算法数学建模传染病模型matlab categories: 数学建模 传染病模型中的符号表示 SI模型(艾滋传染模型) %% 直接求微分方程的解析解 dsolve(Dx1 -0.1 * x1 * x2 / 1000, D…...
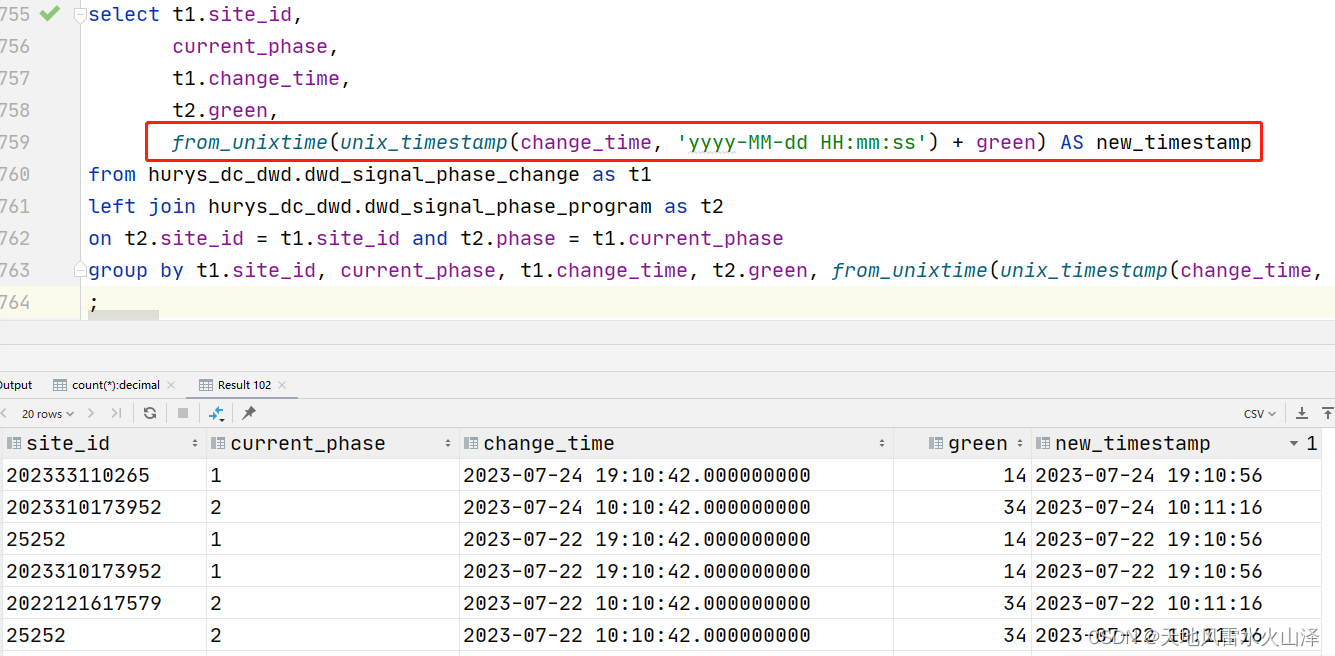
一百三十七、Hive——HQL运行报错(持续更新中)
一、timestamp字段与int字段相加 (一)场景 change_time字段是timestamp字段,代表一个红绿灯周期的开始时间(先是绿灯、再是黄灯、最后红灯),而green是int字段,代表绿灯的秒数,现在…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...

第5章 薪资重构——AI时代的程序员价值重估
第5章 薪资重构——AI时代的程序员价值重估 核心问题:AI时代,程序员的薪资会发生怎样的变化?哪些人在涨薪?哪些人在降薪? 5.1 问题定义:薪资分化的真相是什么? 5.1.1 一个令人震惊的数据 2026年第一季度,一个对比让整个技术圈哗然: 同一家公司内部: - 一个AI方向…...

关于我第九次博客作业
(1)Flex布局核心概念一、Flex 是什么Flex 是 CSS3 一维弹性布局,专治元素对齐、自适应、空间分配问题,布局更高效灵活。二、两大核心角色1. 父容器(Flex容器)设置 display: flex 即为弹性父盒子,负责统一规定子元素排列…...