论文笔记--FEDERATED LEARNING: STRATEGIES FOR IMPROVING COMMUNICATION EFFICIENCY
论文笔记--FEDERATED LEARNING: STRATEGIES FOR IMPROVING COMMUNICATION EFFICIENCY
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 联邦学习(federated learning, FL)
- 3.2 Structured updates
- 3.3 Sketched Update
- 4. 文章亮点
- 5. 原文传送门
1. 文章简介
- 标题:FEDERATED LEARNING: STRATEGIES FOR IMPROVING COMMUNICATION EFFICIENCY
- 作者:Jakub Konecny, H. Brendan McMahan, Felix X. Yu, Ananda Theertha Suresh, Dave Bacon
- 日期:2016
- 期刊:arxiv
2. 文章概括
文章给出了一种联邦学习(federated learning, FL)的新的方法,可以提升多终端之间的交流效率,从而支持多台设备在不稳定网络下的快速传输。
3 文章重点技术
3.1 联邦学习(federated learning, FL)
先简要叙述下联邦学习的概念:一个共享的全局模型被部署于中央服务器,然后各个客户端通过本地数据进行训练,并将更新后的模型传输回中央服务器。假设FL的目的是学习一个参数为 W ∈ R d 1 × d 2 W\in\mathbb{R}^{d_1\times d_2} W∈Rd1×d2的模型,则联邦学习的第 t ≥ 0 t\ge 0 t≥0轮按如下几个步骤执行:
- 随机选择 n t n_t nt个可用的客户端集合 S t S_t St,在这些客户端上从中央服务器下载当前的模型 W W W
- 上述选定的客户端用各自的本地数据更新模型,得到更新后的参数分别为 W t 1 , … , W t n t W_t^1, \dots, W_t^{n_t} Wt1,…,Wtnt,从而各自的更新量为 H t i : = W t i − W t , i = 1 , … , n t H_t^i := W_t^i - W_t ,i = 1, \dots, n_t Hti:=Wti−Wt,i=1,…,nt,
- 上述选定的客户端将更新量 H t 1 , … , H t n t H_t^1, \dots, H_t^{n_t} Ht1,…,Htnt分别发送到中央服务器
- 服务器将所有更新的模型进行聚合(通常采用均值): H t : = 1 n t ∑ i ∈ S t H t i H_t := \frac 1{n_t} \sum_{i\in S_t} H_t^i Ht:=nt1∑i∈StHti,并更新全局模型: W t + 1 = W t + η t H t W_{t+1} = W_t + \eta_t H_t Wt+1=Wt+ηtHt。
其中, η t \eta_t ηt表示每一轮的学习率,简单起见文章采用 η t = 1 \eta_t=1 ηt=1。
上述步骤中,第3步耗时较长,尤其是模型很大或者网络不稳定的时候。文章提出了两种方法来减少第3步的耗时:Structured updates和Sketched updates。
3.2 Structured updates
文章提出的第一种效率提升方式为结构更新,即限制更新的 H t i H_t^i Hti为某种预定义的结构。文章考虑了两种预定义的结构
- low rank:限制每一轮更新的参数矩阵 H t i ∈ R d 1 , … , d 2 H_t^i \in \mathbb{R}^{d_1, \dots, d_2} Hti∈Rd1,…,d2的秩最多为某个固定数值 k k k。为此,我们可以将 H t i H_t^i Hti表示为两个矩阵的乘积: H t i = A t i B t i H_t^i = A_t^i B_t^i Hti=AtiBti,其中 A t i ∈ R d 1 , … , k , B t i ∈ R k , … , d 2 A_t^i \in \mathbb{R}^{d_1, \dots, k}, B_t^i \in \mathbb{R}^{k, \dots, d_2} Ati∈Rd1,…,k,Bti∈Rk,…,d2,则由 rank ( A B ) ≤ rank ( A ) \text{rank} (AB) \le \text{rank} (A) rank(AB)≤rank(A)可以知道 H t i ≤ k H_t^i \le k Hti≤k。我们初始化一个随机的 A t i A_t^i Ati,然后训练的时候仅更新 B t i B_t^i Bti的参数。则模型上传的时候我们只需上传 A t i A_t^i Ati的随机种子和 B t i B_t^i Bti的参数即可。故我们将效率从 d 1 × d 2 d_1 \times d_2 d1×d2提升为 k × d 2 k \times d_2 k×d2,提升了 d 1 / k d_1/k d1/k倍。
- random rank:限制每一轮更新的参数矩阵 H t i ∈ R d 1 , … , d 2 H_t^i \in \mathbb{R}^{d_1, \dots, d_2} Hti∈Rd1,…,d2为一个稀疏矩阵,满足某种与定义的稀疏模式(只需随机选出non-zero的索引即可),更新的时候我们只更新non-zero的参数。上传模型的时候只需上传稀疏化的随机种子和非零元素的更新值即可。
3.3 Sketched Update
文章提出的第二种效率提升方法为sketched update,核心思想为在各个客户端训练完整的参数更新,然后将更新的参数进行压缩上传,再在中央服务器上解压然后更新全局模型的参数。文章实验了几种不同的压缩方法:
- subsampling:各个客户端每次更新完模型之后从 H t i H_t^i Hti中随机采样一小部分值 H ^ t i \hat{H}_t^i H^ti发送到中央服务器,然后取各个客户端的平均更新值作为全局的更新值。当每个客户端每一轮的随机mask独立时,我们有 E [ H ^ t ] = H t \mathbb{E} [\hat{H}^t] = H_t E[H^t]=Ht。
- probabilistic quantiazation:首先介绍one-bit的情况。令 h = ( h 1 , … , h d 1 × d 2 ) h = (h_1, \dots, h_{d_1\times d_2}) h=(h1,…,hd1×d2)为 H t i H_t^i Hti的平铺向量,取 h m a x = max j ( h j ) h_{max} = \max_j (h_j) hmax=maxj(hj), h m i n = min j ( h j ) h_{min} = \min_j (h_j) hmin=minj(hj),则可以将 h h h压缩为: h ‾ j = { h m a x , with probability h j − h m i n h m a x − h m i n h m i n , with probability h m a x − h j h m a x − h m i n \overline{h}_j = \begin{cases} h_{max}, \quad \text{with probability} \quad \frac {h_j - h_{min}}{h_{max}-h_{min}}\\h_{min}, \quad \text{with probability} \quad \frac {h_{max} - h_j}{h_{max}-h_{min}}\end{cases} hj={hmax,with probabilityhmax−hminhj−hminhmin,with probabilityhmax−hminhmax−hj,则可以得到 E [ h ‾ ] = h m a x h − h m i n h m a x − h m i n + h m i n h m a x − h h m a x − h m i n = h \mathbb{E} [\overline{h}] = h_{max} \frac {h - h_{min}}{h_{max}-h_{min}} +h_{min} \frac {h_{max} - h}{h_{max}-h_{min}} = h E[h]=hmaxhmax−hminh−hmin+hminhmax−hminhmax−h=h,从而 h ‾ \overline{h} h为 h h h的无偏估计。上述为one-bit的情况,我们可以增加bit数,将 [ h m i n , h m a x ] [h_{min}, h_{max}] [hmin,hmax]划分为 2 b 2^b 2b个区间,然后按照上述定义将每个子区间内的 h j h_j hj进行压缩。发送的时候我们只需要发送区间数和每个子区间端点的个数即可,对应的发送量为 2 b 2^b 2b。
- Quantilization by structured random rotations:上述方法当不同维度的数值比较相近的时候效果较好。比如大部分的值为0,但 m a x = 1 , m i n = − 1 max =1, min = -1 max=1,min=−1,则上述压缩方法有明显的误差。为此,我们可以先对 h h h应用一个旋转(乘一个随机正交矩阵),则上述误差可以得到有效控制(有其它研究可以支撑)。解码阶段,需要首先将压缩后的参数乘正交矩阵的逆阵再进行聚合、更新。
4. 文章亮点
文章提出了两类联邦学习加速的算法:基于预定义参数和基于参数压缩的方法。数值实验表明我们的方法可以在精度损失很少的情况下更快地发送参数。
5. 原文传送门
FEDERATED LEARNING: STRATEGIES FOR IMPROVING COMMUNICATION EFFICIENCY
相关文章:

论文笔记--FEDERATED LEARNING: STRATEGIES FOR IMPROVING COMMUNICATION EFFICIENCY
论文笔记--FEDERATED LEARNING: STRATEGIES FOR IMPROVING COMMUNICATION EFFICIENCY 1. 文章简介2. 文章概括3 文章重点技术3.1 联邦学习(federated learning, FL)3.2 Structured updates3.3 Sketched Update 4. 文章亮点5. 原文传送门 1. 文章简介 标题:FEDERATE…...
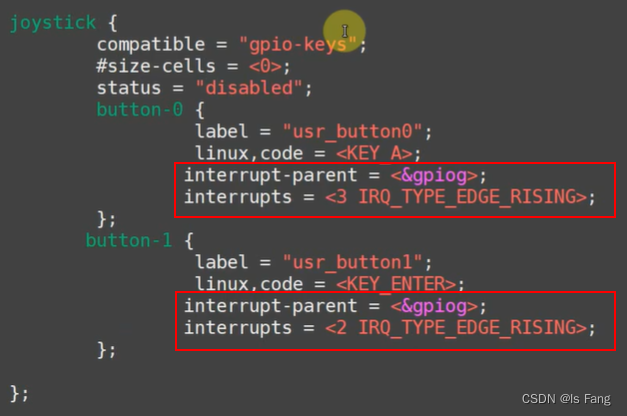
STM32MP157驱动开发——按键驱动(异步通知)
文章目录 “异步通知 ”机制:信号的宏定义:信号注册 APP执行过程驱动编程做的事应用编程做的事异步通知方式的按键驱动程序(stm32mp157)button_test.cgpio_key_drv.cMakefile修改设备树文件编译测试 “异步通知 ”机制: 信号的宏定义&#x…...

医疗器械维修工程师心得
彩虹医械维修技能班9月将开展本年第三期长期班,目前咨询人员也陆续多了起来,很多刚了解到医疗行业的,自身也没有多少相关的基础,在咨询时会问到没有基础能否学的会? 做了这行业的都知道,无论多么复杂的设备…...
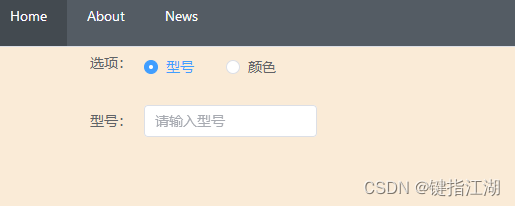
Vue3 Radio单选切换展示不同内容
Vue3 Radio单选框切换展示不同内容 环境:vue3tsviteelement plus 技巧:v-if,v-show的使用 实现功能:点击单选框展示不同的输入框 效果实现前的代码: <template><div class"home"><el-row …...
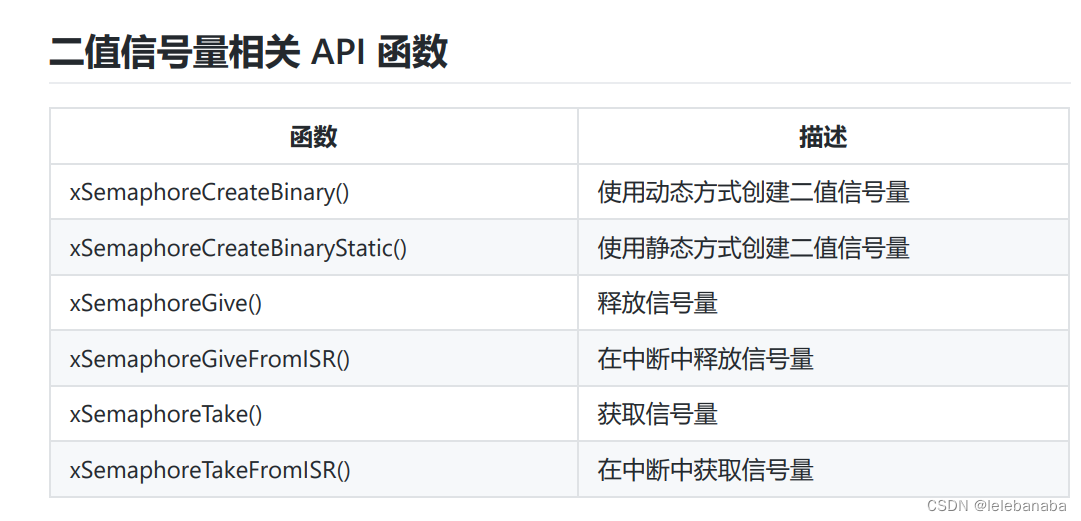
FreeRTOS之二值信号量
什么是信号量? 信号量(Semaphore),是在多任务环境下使用的一种机制,是可以用来保证两个或多个关键代 码段不被并发调用。 信号量这个名字,我们可以把它拆分来看,信号可以起到通知信号的作用&am…...

ChatGPT API进阶调用指南
原文:ChatGPT API进阶调用指南 ChatGPT API 进阶调用指南 ChatGPT API 是基于 OpenAI 的 GPT模型的一个强大工具,可以用于构建各种对话式应用。以下是一些使用 Markdown 语法的进阶调用指南,以帮助您更好地利用 ChatGPT API。 设置用户角色…...

人工智能术语翻译(四)
文章目录 摘要MNOP 摘要 人工智能术语翻译第四部分,包括I、J、K、L开头的词汇! M 英文术语中文翻译常用缩写备注Machine Learning Model机器学习模型Machine Learning机器学习ML机器学习Machine Translation机器翻译MTMacro Average宏平均Macro-F1宏…...

kubernetes持久化存储卷
kubernetes持久化存储卷 kubernetes持久化存储卷一、存储卷介绍二、存储卷的分类三、存储卷的选择四、本地存储卷之emptyDir五、本地存储卷之 hostPath六、网络存储卷之nfs七、PV(持久存储卷)与PVC(持久存储卷声明)7.1 认识pv与pvc7.2 pv与pvc之间的关系7.3 实现nfs类型pv与pvc…...
【Rust笔记】意译解构 Object Safety for trait
意译解构Object Safety for trait 借助【虚表vtable】对被调用成员函数【运行时内存寻址】的作法允许系统编程语言Rust模仿出OOP高级计算机语言才具备的【专用多态Ad-hoc Polymorphism】特性。 计算机高级语言中的“多态”术语是一个泛指。它通常可被细化为 基于继承关系的“子…...

Spring Boot单元测试入门指南
Spring Boot单元测试入门指南 JUnit是一个成熟和广泛应用的Java单元测试框架,它提供了丰富的功能和灵活的扩展机制,可以帮助开发人员编写高质量的单元测试。通过JUnit,开发人员可以更加自信地进行重构、维护和改进代码,同时提高代…...

《面试1v1》如何能从Kafka得到准确的信息
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...

2023秋招面试题持续更新中。。。
目录 1.八股文渐进式MVVM三次握手,四次挥手viteajax组件化和模块化虚拟dom原理流程浏览器内核浏览器渲染过程回流和重绘nextTick 2.项目相关1.声明式导航和编程式导航重写push和replace方法:性能优化图片懒加载路由懒加载 http请求方式 1.八股文 渐进式…...
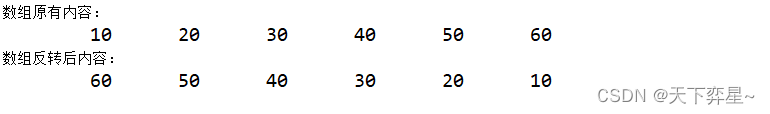
Java | 数组排序算法
一、冒泡排序 冒泡排序的基本思想是对比相邻的元素值,如果满足条件就交换元素值,把较小的元素移到数组前面,把较大的元素移到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部升到顶…...

android studio 连接SQLite数据库并实现增删改查功能
功能代码及调试代码 package com.example.bankappdemo;import android.annotation.SuppressLint; import android.content.ContentValues; import android.database.sqlite.SQLiteDatabase; import android.os.Bundle; import android.util.Log; import android.view.View; im…...

跑步适合戴什么样的耳机、最好的跑步耳机推荐
每个人对于运动的方式都不尽相同,但大多数热爱运动的朋友都离不开音乐的陪伴。运动和带有节奏感的音乐能够激发我们更多的热情和动力。特别是在夏日的时候,我非常喜欢跑步。在酷热的天气里,如果没有音乐的伴随,跑步会变得单调乏味…...
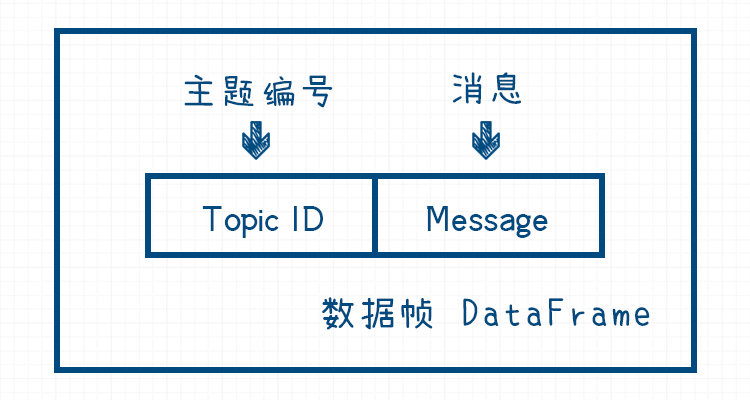
物联网的通信协议
物联网的通信协议 目录 物联网的通信协议一、UART串口通信1.1 串口通信1.2 异步收发1.3 波特率1.4 串口通信协议的数据帧1.5 优缺点1.5.1 优点1.5.2 缺点 二、I^2^C2.1 I^2^C2.2 I^2^C2.3 数据有效性2.4 起始条件S和停止条件P2.5 数据格式2.6 协议数据单元PDU2.7 优缺点2.7.1 优…...
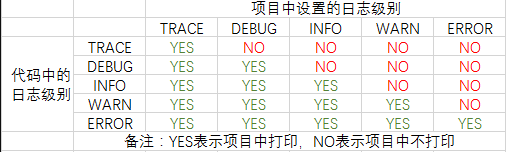
【业务功能篇56】SpringBoot 日志SLF4J Logback
3.5.1 日志框架分类与选择 3.5.1.1 日志框架的分类 日志门面 (日志抽象)日志实现JCL(Jakarta Commons Logging) SLF4J(Simple Logging Facade for Java)Jul(Java Util Logging) , Log4j , Log4j2 , Logback 记录型日志框架 Jul (Java Util Logging):JDK中的日志…...
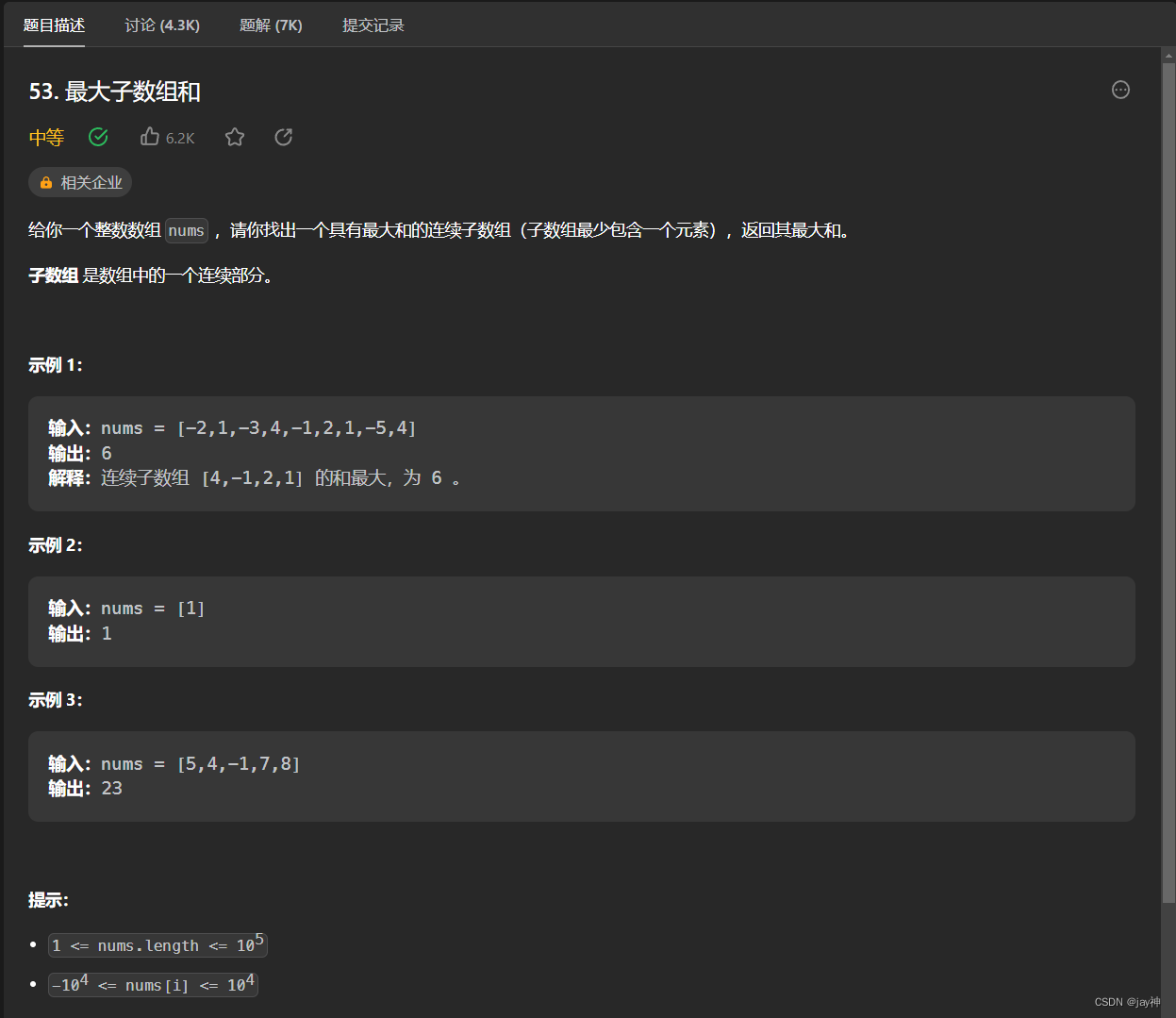
leetcode 53. 最大子数组和
2023.7.28 要求找最大和的 连续子数组, 我的思路是用一个temp记录局部最优值,用ans记录全局最优值。 然后在每次for循环进行一个判断:当前遍历元素temp值 是否大于当前遍历元素的值,如果大于,说明temp值是帮了正忙的&a…...

js 下载url返回的excel数据,并解析为json
XLSX GitHub地址:https://github.com/SheetJS/sheetjs/blob/github/dist/xlsx.full.min.js 需要先引入:XLSX.full.min.js // 下载文件的请求 fetch(downloadFileUrl).then(response > {return rsp.blob() }).then(data > {let reader new FileR…...

图文教程:使用 Photoshop、3ds Max 和 After Effects 创建被风暴摧毁的小屋
推荐: NSDT场景编辑器助你快速搭建可二次开发的3D应用场景 1. 在 Photoshop 中设置图像 步骤 1 打开 Photoshop。 打开 Photoshop 步骤 2 我已经将小屋的图像导入到Photoshop中以演示 影响。如果您愿意,可以使用其他图像。 图片导入 步骤 3 由于小…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...