Spark的DataFrame和Schema详解和实战案例Demo
1、概念介绍
Spark是一个分布式计算框架,用于处理大规模数据处理任务。在Spark中,DataFrame是一种分布式的数据集合,类似于关系型数据库中的表格。DataFrame提供了一种更高级别的抽象,允许用户以声明式的方式处理数据,而不需要关心底层数据的细节和分布式计算的复杂性。Schema在Spark中用于描述DataFrame中的数据结构,类似于表格中的列定义。
让我们分别介绍一下DataFrame和Schema:
DataFrame:
DataFrame是由行和列组成的分布式数据集合,类似于传统数据库或电子表格的结构。Spark的DataFrame具有以下特点:
分布式计算:DataFrame是分布式的,可以在集群中的多个节点上进行并行处理,以实现高性能的大规模数据处理。
不可变性:DataFrame是不可变的,这意味着一旦创建,就不能修改。相反,对DataFrame的操作会生成新的DataFrame。
延迟执行:Spark采用了延迟执行策略,即DataFrame上的操作并不立即执行,而是在需要输出结果时进行优化和执行。
用户可以使用SQL语句、Spark的API或Spark SQL来操作DataFrame,进行数据过滤、转换、聚合等操作。DataFrame的优势在于其易用性和优化能力,Spark会根据操作的执行计划来优化整个计算过程,以提高性能。
Schema:
Schema是DataFrame中数据的结构描述,它定义了DataFrame的列名和列的数据类型。在Spark中,Schema是一个包含列名和数据类型的元数据集合。DataFrame的Schema信息对于优化计算和数据类型的正确解释至关重要。
通常,Schema是在创建DataFrame时自动推断的,也可以通过编程方式显式指定。指定Schema的好处是可以确保数据被正确解释并且避免潜在的类型转换错误。如果数据源不包含Schema信息或者需要修改Schema,可以使用StructType和StructField来自定义Schema。例如,可以创建一个包含多个字段和数据类型的Schema,如字符串、整数、日期等。
在使用Spark读取数据源时,如CSV文件、JSON数据、数据库表等,Spark会尝试自动推断数据的Schema。如果数据源本身没有提供足够的信息,可以使用schema选项来指定或者通过后续的数据转换操作来调整DataFrame的Schema。
总结:DataFrame是Spark中一种强大的分布式数据结构,允许用户以声明式的方式处理数据,而Schema则用于描述DataFrame中数据的结构信息,确保数据被正确解释和处理。这两个概念共同构成了Spark强大的数据处理能力。
代码实战
package test.scalaimport org.apache.spark.sql.SparkSession
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{IntegerType, StringType, StructType}object TestSchema {def getSparkSession(appName: String, localType: Int): SparkSession = {val builder: SparkSession.Builder = SparkSession.builder().appName(appName)if (localType == 1) {builder.master("local[8]") // 本地模式,启用8个核心}val spark = builder.getOrCreate() // 获取或创建一个新的SparkSessionspark.sparkContext.setLogLevel("ERROR") // Spark设置日志级别spark}def main(args: Array[String]): Unit = {println("Start TestSchema")val spark: SparkSession = getSparkSession("TestSchema", 1)val structureData = Seq(Row("36636", "Finance", Row(3000, "USA")),Row("40288", "Finance", Row(5000, "IND")),Row("42114", "Sales", Row(3900, "USA")),Row("39192", "Marketing", Row(2500, "CAN")),Row("34534", "Sales", Row(6500, "USA")))val structureSchema = new StructType().add("id", StringType).add("dept", StringType).add("properties", new StructType().add("salary", IntegerType).add("location", StringType))val df = spark.createDataFrame(spark.sparkContext.parallelize(structureData), structureSchema)df.printSchema()df.show(false)val row = df.first()val schema = row.schemaval structTypeList = schema.toListprintln(structTypeList.size)for (i <- 0 to structTypeList.size - 1) {val structType = structTypeList(i)println(structType.name, row.getAs(structType.name), structType.dataType, structType.dataType)}}
}
输出
Start TestSchema
Using Spark’s default log4j profile: org/apache/spark/log4j-defaults.properties
23/07/29 09:47:59 INFO SparkContext: Running Spark version 2.4.0
23/07/29 09:47:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
23/07/29 09:47:59 INFO SparkContext: Submitted application: TestSchema
23/07/29 09:47:59 INFO SecurityManager: Changing view acls to: Nebula
23/07/29 09:47:59 INFO SecurityManager: Changing modify acls to: Nebula
23/07/29 09:47:59 INFO SecurityManager: Changing view acls groups to:
23/07/29 09:47:59 INFO SecurityManager: Changing modify acls groups to:
23/07/29 09:47:59 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Nebula); groups with view permissions: Set(); users with modify permissions: Set(Nebula); groups with modify permissions: Set()
23/07/29 09:48:01 INFO Utils: Successfully started service ‘sparkDriver’ on port 60785.
23/07/29 09:48:01 INFO SparkEnv: Registering MapOutputTracker
23/07/29 09:48:01 INFO SparkEnv: Registering BlockManagerMaster
23/07/29 09:48:01 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/07/29 09:48:01 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
23/07/29 09:48:01 INFO DiskBlockManager: Created local directory at C:\Users\Nebula\AppData\Local\Temp\blockmgr-6f861361-4d98-4372-b78a-2949682bd557
23/07/29 09:48:01 INFO MemoryStore: MemoryStore started with capacity 8.3 GB
23/07/29 09:48:01 INFO SparkEnv: Registering OutputCommitCoordinator
23/07/29 09:48:01 INFO Utils: Successfully started service ‘SparkUI’ on port 4040.
23/07/29 09:48:01 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://LAPTOP-PEA8R2PO:4040
23/07/29 09:48:01 INFO Executor: Starting executor ID driver on host localhost
23/07/29 09:48:01 INFO Utils: Successfully started service ‘org.apache.spark.network.netty.NettyBlockTransferService’ on port 60826.
23/07/29 09:48:01 INFO NettyBlockTransferService: Server created on LAPTOP-PEA8R2PO:60826
23/07/29 09:48:01 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
23/07/29 09:48:01 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, LAPTOP-PEA8R2PO, 60826, None)
23/07/29 09:48:01 INFO BlockManagerMasterEndpoint: Registering block manager LAPTOP-PEA8R2PO:60826 with 8.3 GB RAM, BlockManagerId(driver, LAPTOP-PEA8R2PO, 60826, None)
23/07/29 09:48:01 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, LAPTOP-PEA8R2PO, 60826, None)
23/07/29 09:48:01 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, LAPTOP-PEA8R2PO, 60826, None)
相关文章:

Spark的DataFrame和Schema详解和实战案例Demo
1、概念介绍 Spark是一个分布式计算框架,用于处理大规模数据处理任务。在Spark中,DataFrame是一种分布式的数据集合,类似于关系型数据库中的表格。DataFrame提供了一种更高级别的抽象,允许用户以声明式的方式处理数据,…...

WPF线程使用详解:提升应用性能和响应能力
在WPF应用程序开发中,线程的合理使用是保证应用性能和响应能力的关键。WPF提供了多种线程处理方式,包括UI线程、后台线程、Task/Async Await和BackgroundWorker。这些方式与传统的Thread类相比,更加适用于WPF框架,并能够简化线程操…...
ava版知识付费平台免费搭建 Spring Cloud+Spring Boot+Mybatis+uniapp+前后端分离实现知识付费平台
提供私有化部署,免费售后,专业技术指导,支持PC、APP、H5、小程序多终端同步,支持二次开发定制,源码交付。 Java版知识付费-轻松拥有知识付费平台 多种直播形式,全面满足直播场景需求 公开课、小班课、独…...

libuv库学习笔记-basics_of_libuv
Basics of libuv libuv强制使用异步和事件驱动的编程风格。它的核心工作是提供一个event-loop,还有基于I/O和其它事件通知的回调函数。libuv还提供了一些核心工具,例如定时器,非阻塞的网络支持,异步文件系统访问,子进…...
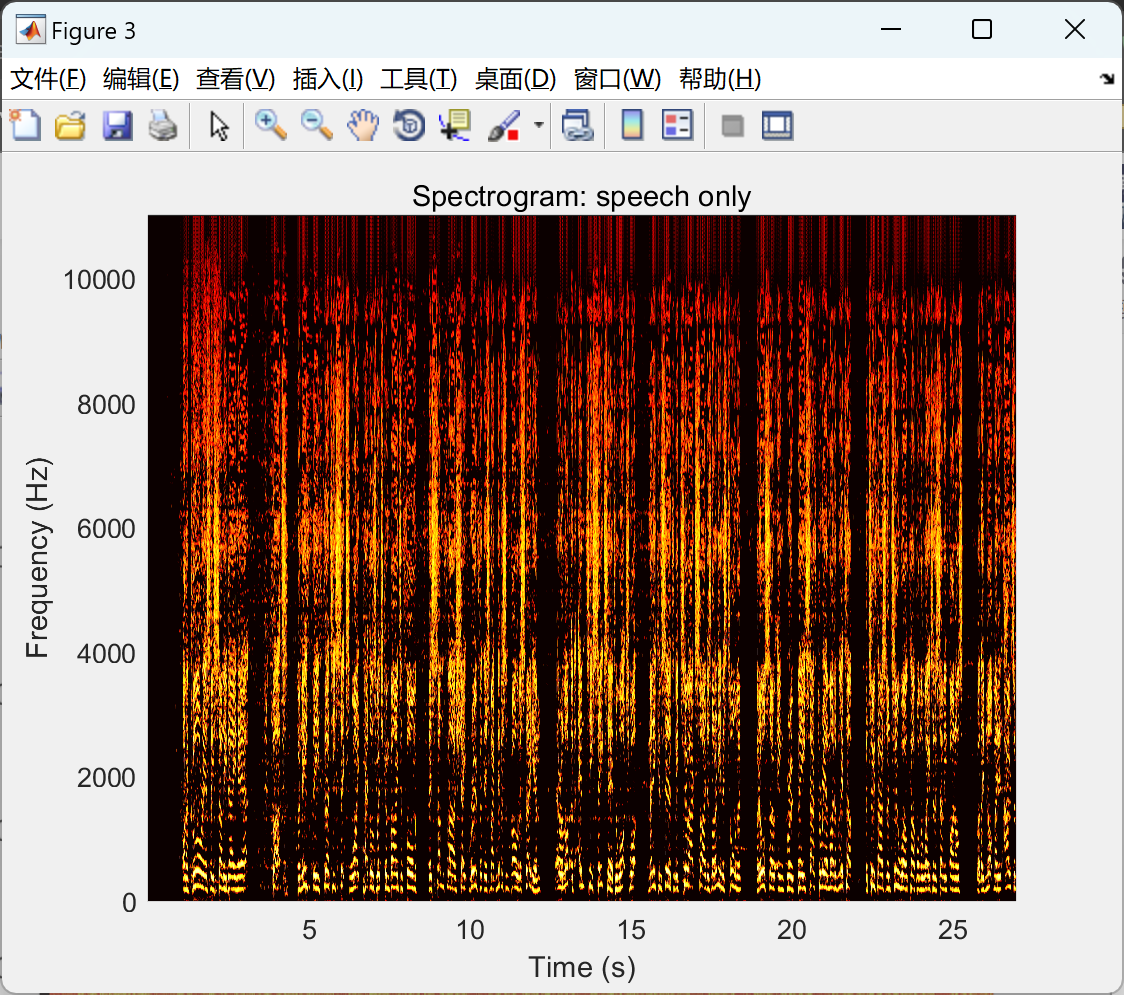
【Vuvuzela 声音去噪算法】基于流行的频谱减法技术的声音去噪算法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
Vue + Element-ui组件上传图片报错问题解决方案
在前端开发中,我们经常需要模拟网络请求以进行单元测试或开发调试。而在模拟网络请求时,我们常常会使用到MockXMLHttpRequest对象。MockXMLHttpRequest对象是一个用于模拟XMLHttpRequest对象的工具,它提供了一种简单的方式来模拟网络请求&…...

java商城系统和php商城系统对比
java商城系统和php商城系统是两种常见的电子商务平台,它们都具有一定的优势和劣势。那么,java商城系统和php商城系统又有哪些差异呢? 一、开发难度 Java商城系统和PHP商城系统在开发难度方面存在一定的差异。Java商城系统需要使用Java语言进…...

某制造企业基于 KubeSphere 的云原生实践
背景介绍 随着业务升级改造与软件产品专案的增多,常规的物理机和虚拟机方式逐渐暴露出一些问题: 大量服务部署在虚拟机上,资源预估和硬件浪费较大;大量服务部署在虚拟机上,部署时间和难度较大,自动化程度…...
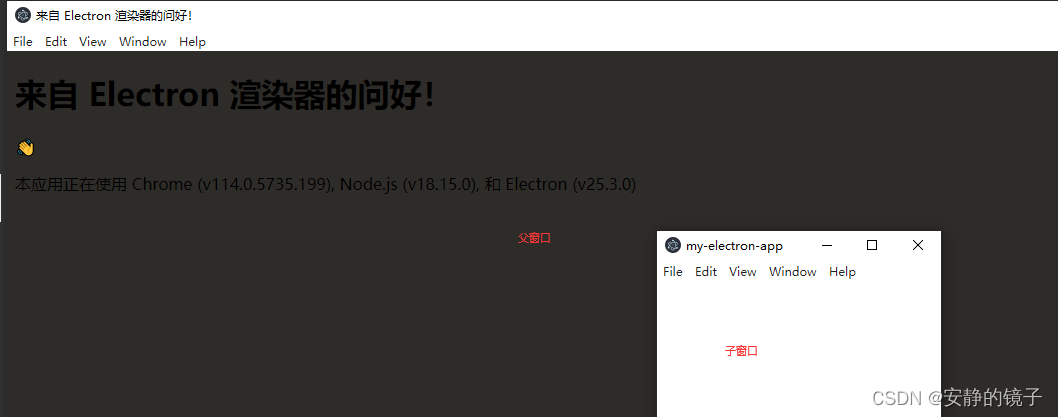
Electron 学习_BrowserWindow
BrowserWindow创建并控制浏览器窗口(主进程) 条件:在 app 模块 emitted ready 事件之前,您不能使用此模块。 1.在加载页面时,渲染进程第一次完成绘制时,如果窗口还没有被显示,渲染进程会发出 ready-to-show 事件 。 在…...
Docker学习笔记,包含docker安装、常用命令、dockerfile、docker-compose等等
😀😀😀创作不易,各位看官点赞收藏. 文章目录 Docker 学习笔记1、容器2、Docker 安装3、Docker 常用命令4、Docker 镜像5、自定义镜像5.1、镜像推送到阿里云5.2、镜像私有库 6、数据卷7、Docker 软件安装8、Docker File8.1、常见保…...
“ 错误的方法)
解决 “Module build failed (from ./node_modules/babel-loader/lib/index.js)“ 错误的方法
系列文章目录 文章目录 系列文章目录前言一、错误原因:二、解决方法:三、注意事项:总结 前言 在前端项目开发中,如果使用了 Babel 来转译 ES6 语法,有时会遇到错误信息 “Module build failed (from ./node_modules/b…...

go学习 6、方法
6、方法 面向对象编程(OOP),封装、组合。 6.1 方法声明 在函数声明时,在其名字之前放上一个变量,即是一个方法。这个附加的参数会将该函数附加到这种类型上,即相当于为这种类型定义了一个独占的方法。 …...
MySQL Windows版本下载及安装时默认路径的修改
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、MySQL 下载二、默认路径修改1、安装前准备【非常重要】2、启动安装程序总结1、MySQL下载2、MySQL默认路径修改前言 MySQL 被Oracle收购后,各种操作规范及约束也相应的跟着来了,这不,只…...
第3章 配置与服务
1 CoreCms.Net.Configuration.AppSettingsHelper using Microsoft.Extensions.Configuration; using Microsoft.Extensions.Configuration.Json; namespace CoreCms.Net.Configuration { /// <summary> /// 【应用设置助手--类】 /// <remarks> /// 摘要&#x…...
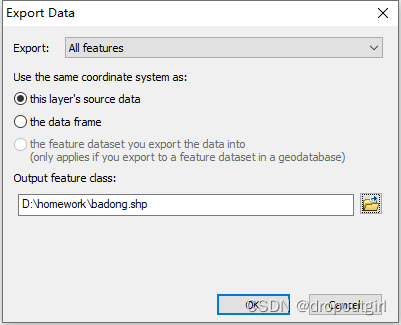
Arcgis之 KML/KMZ文件转shp
一般我们在Goole Earth上勾画的区域导出后都为KML或者KMZ格式的,但无法在arcgis等软件上直接应用,故需进行一定的转换 1.打开ArcMap,选择ArcToolbox->Conversion Tools->From KML->KML To Layer 得到如下结果(由于本KML…...

python绘制3D条形图
文章目录 数据导入三维条形图bar3d 数据导入 尽管在matplotlib支持在一个坐标系中绘制多组条形图,效果如下 其中,蓝色表示中国,橘色表示美国,绿色表示欧盟。从这个图就可以非常直观地看出,三者自2018到2022年的GDP变化…...

计算从曲线的起点到param指定的点的曲线段的长度
以下方法只能用于继承于AcDbCurve的类型 主要使用两个接口 派生类中此函数的实现应返回, 并将endParam设置为曲线端点的参数。 如果成功则返回Acad::eOk。 默认情况下, 该函数返回Acad::eNotImplemented。 virtual Acad::ErrorStatus getEndParam(double&endParam) cons…...

POLARDB IMCI 白皮书 云原生HTAP 数据库系统 一 数据压缩和打包处理与数据更新
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共…...
)
linux----源码安装如何加入到系统服务中(systemclt)
将自己源码安装的软件加入到系统服务中。例如nginx,mysql 就以nginx为例,源码安装,加入到系统服务中 使用yum安装nginx,自动会加入到系统服务 16-Linux系统服务 - 刘清政 - 博客园 (cnblogs.com) 第一步: 源码安装好nginx之后࿰…...
)
Unity 使用UnityWebRequest 读取存档 (IOS只能这样做)
打IOS包的时候发现的,不能使用正常的IO流读取,不然会读取不到数据,只能使用UnityWebRequest 读取 代码如下 public IEnumerator ReadArchive(Action<bool, string> ac, string filepath ""){UnityWebRequest request Unit…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析
TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析 【免费下载链接】torchdynamo A Python-level JIT compiler designed to make unmodified PyTorch programs faster. 项目地址: https://gitcode.com/gh_mirrors/to/torchdynamo TorchDynamo 是一个…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...