sparksql参数
Spark参数场景配置
| 参数类型 | 参数 | 参数说明 | 平台默认值 | 场景与建议 |
|---|---|---|---|---|
| 资源申请 | spark.executor.memory | Executor Java进程的堆内存大小 即Executor Java进程的Xmx值 | 2g | 默认设置,或者同时等比例增大,最高不超过默认值的3倍,超过的单独拿出来看下 (注意作业是否数据倾斜) 可根据单个文件大小进行预估 若是orc格式,需乘以2-3倍 |
| spark.yarn.executor.memoryOverhead | Executor Java进程的off-heap内存,包括JVM overhead,sort,shuffle以及Netty的堆外内存等 | 1g | 保持默认值,建议值1-3g 特殊问题单独拿出来讨论 executor的内存大小限制: (YARN container最大内存限制) | |
| spark.executor.cores | Executor中同时可以执行的task数目 共享整个excutor内存,cores越多,平均下来单个task占用的资源就越少 | 1 | 建议值1-3 再多需单独拿出来讨论 建议spark.executor.cores * spark.dynamicAllocation.maxExecutors < 5000 | |
| spark.dynamicAllocation.maxExecutors | 开启动态资源分配后,同一时刻,最多可申请的executor个数 | 1000 | 流量以及数据量在30亿以上的作业 可提高至2000个(不建议再提高) 其他情况保持默认 当在Spark UI中观察到task较多时,可适当调大此参数,缩短作业执行时间。 一般保持shuffle.partitions / (maxExecutors*executor.cores)=2 | |
| spark.dynamicAllocation.minExecutors | executor的最小个数。平台默认设置为3,即在任何时刻,作业都会保持至少有3个及以上的executor存活 | 3 | 保持默认即可 | |
| spark.memory.fraction | 存储+执行内存占节点总内存的大小,社区版是0.6。平台为了方便的把hive任务迁移到spark任务,把该区域的内存比例调小至0.3 | 0.3 | 没有udf或者udf不会消耗太多内存的任务可以调整到0.5甚至社区版默认的0.6,减少spill的次数,提升性能。HBO参数修改方案v2 | |
| spark.driver.memory | driver使用内存大小 | 10G |
| |
| spark.yarn.driver.memoryOverhead | driver进程的off-heap内存 | spark.driver.memory * 0.1,并且不小于384m |
| |
| spark.sql.autoBroadcastJoinThreshold | 当执行join时,小表被广播的阈值 当被设置为-1,则禁用广播 该参数设置的过大会对driver和executor都产生压力。 | 26214400 |
| |
| 文件合并 | spark.hadoop.hive.exec.orc.split.strategy | 参数控制在读取ORC表时生成split的策略: BI策略以文件为粒度进行split划分; ETL策略会将文件进行切分,多个stripe组成一个split; HYBRID策略当文件的平均大小大于hadoop最大split值(默认256M)时使用ETL策略,否则使用BI策略 | BI模式 |
|
| 文件合并 | spark.hadoop.mapreduce.input.fileinputformat.split.minsize | 计算Split划分时的minSize | 保持默认 | |
| spark.hadoop.mapreduce.input.fileinputformat.split.maxsize | 控制在ORC切分时stripe的合并处理。具体逻辑是,当几个stripe的大小小于spark.hadoop.mapreduce.input.fileinputformat.split.maxsize时,会合并到一个task中处理。可以适当调小该值,如set spark.hadoop.mapreduce.input.fileinputformat.split.maxsize=134217728。以此增大读ORC表的并发 | 建议值不超过128m | ||
| spark.hadoopRDD.targetBytesInPartition | 读取输入文件时&最终合并小文件时,每个task读取的数据量 | 33554432 | 1:非grouping set情况 建议67108864, 如果发现读取文件的task较多,可以适当增大该值到128m。 2:grouping set 情况 建议调下该值 降低该值 详见case ----详见作业最后一个阶段遇到shuffle慢节点 | |
| spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 开启spark.sql.adaptive.enabled后,最后一个stage在进行动态合并partition时,会根据shuffle read的数据量除以该参数设置的值来计算合并后的partition数量。所以增大该参数值会减少partition数量,反之会增加partition数量 | 67108864 (64M) | 256m, 可以适当增大或减小 | |
| spark.sql.mergeSmallFileSize | 写入hdfs后小文件合并的阈值。如果生成的文件平均大小低于该参数配置,则额外启动一轮stage进行小文件的合并。 当任务中添加task:Listing leaf files and directorioes for 55 paths | 128000000 |
| |
| shuffle相关 | spark.sql.shuffle.partitions | reduce阶段(shuffle read)的数据分区,分区数越多,启动的task越多,同时生成的文件数也会越多。 | 2000 | 1. 建议一个partition保持在256mb左右的大小就好。当作业数据较多时,适当调大该值,当作业数据较少时,适当调小以节省资源 2. spark.sql.shuffle.partitions设置过大可能会导致很多reducer同时向一个mapper拉取数据。该mapper由于请求压力过大挂掉或响应缓慢,从而导致fetch failed |
| spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 最后一个stage在进行动态合并partition时,会根据shuffle read的数据量除以该参数设置的值来计算合并后的partition数量。所以增大该参数值会减少partition数量,反之会增加partition数量。 | 67108864 (64M) |
| |
| spark.sql.statistics.fallBackToHdfs | 当表的文件大小元数据信息不可能用时回退到hdfs计算表的文件大小,从而决定是否使用map join. 分区表如果读入数据较少也不会优化为BroadcastJoin, 可以通过添加该参数优化: | false | 1:建议保持默认 2:如果mapjoin的值不生效 建议设置为true | |
| 推测执行 | spark.speculation | spark推测执行的开关,作用同hive的推测执行 | true |
|
| spark.speculation.interval | 开启推测执行后,每隔多久通过checkSpeculatableTasks方法检测是否有需要推测式执行的tasks | 1000ms |
| |
| spark.speculation.quantile | 当成功的Task数超过总Task数的spark.speculation.quantile时(社区版默认75%,公司默认99%),再统计所有成功的Tasks的运行时间,得到一个中位数,用这个中位数乘以spark.speculation.multiplier(社区版默认1.5,公司默认3)得到运行时间门限,如果在运行的Tasks的运行时间超过这个门限,则对它启用推测。 | 0.99 | 1: 如果资源充足,可以适当减小 spark.speculation.quantile和spark.speculation.multiplier的值 2:目前不建议调整 |
相关文章:

sparksql参数
Spark参数场景配置 参数类型 参数 参数说明 平台默认值 场景与建议 资源申请 spark.executor.memory Executor Java进程的堆内存大小 即Executor Java进程的Xmx值 2g 默认设置,或者同时等比例增大,最高不超过默认值的3倍,超过的单独拿出来看下 (注意作业是否数据倾斜&…...
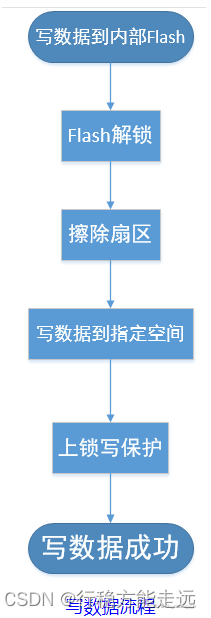
STM32读写内部Flash
参考:https://blog.csdn.net/Caramel_biscuit/article/details/131925715 参考:https://blog.csdn.net/qq_36075612/article/details/124087574?spm1001.2014.3001.5502 目录 内存映射内部Flash的构成对内部Flash的写入过程查看工程内存的分布ROM加载空…...
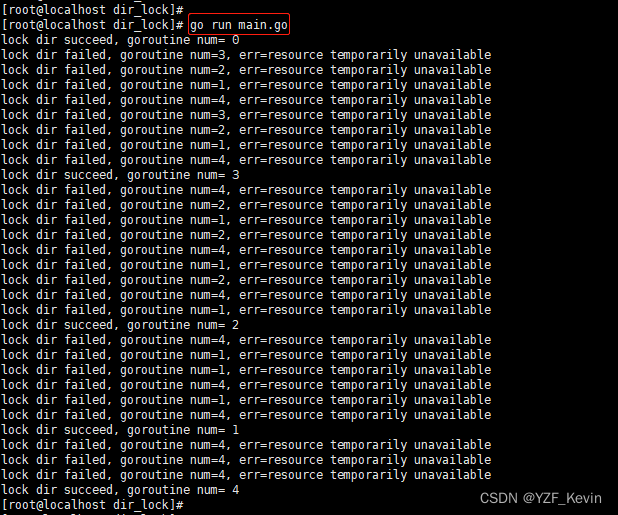
golang文件锁,目录锁,syscall包的使用
先说结论 1. golang提供了syscall包来实现文件/目录的加锁,解锁 2. syscall包属于文件锁,是比较底层的技术,并不能在所有操作系统上完全实现,linux上实现了,windows下面就没有 3. 加锁时调用syscall.Flock(fd&#…...
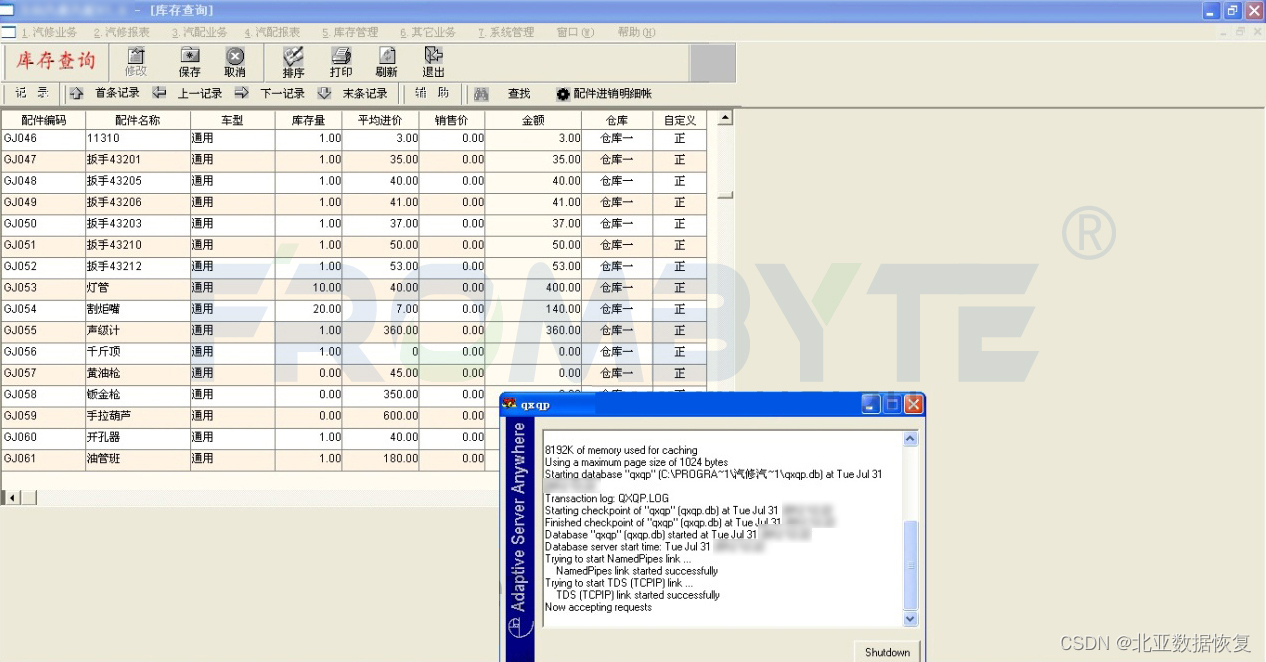
数据库数据恢复-Syabse数据库存储页底层数据杂乱的数据恢复案例
数据库恢复环境: Sybase版本:SQL Anywhere 8.0。 数据库故障: 数据库所在的设备意外断电后,数据库无法启动。 错误提示: 使用Sybase Central连接后报错: 数据库故障分析: 经过北亚企安数据恢复…...

移远通信推出新一代高算力智能模组SG885G-WF,为工业和消费级IoT应用带来全新性能标杆
2023年7月24日,全球领先的物联网整体解决方案供应商移远通信宣布,正式推出其新一代旗舰级安卓智能模组SG885G-WF。该智能模组具有高达48 TOPS 的AI综合算力、强大性能及丰富的多媒体功能,非常适用于需要高处理能力和多媒体功能的工业和消费者…...
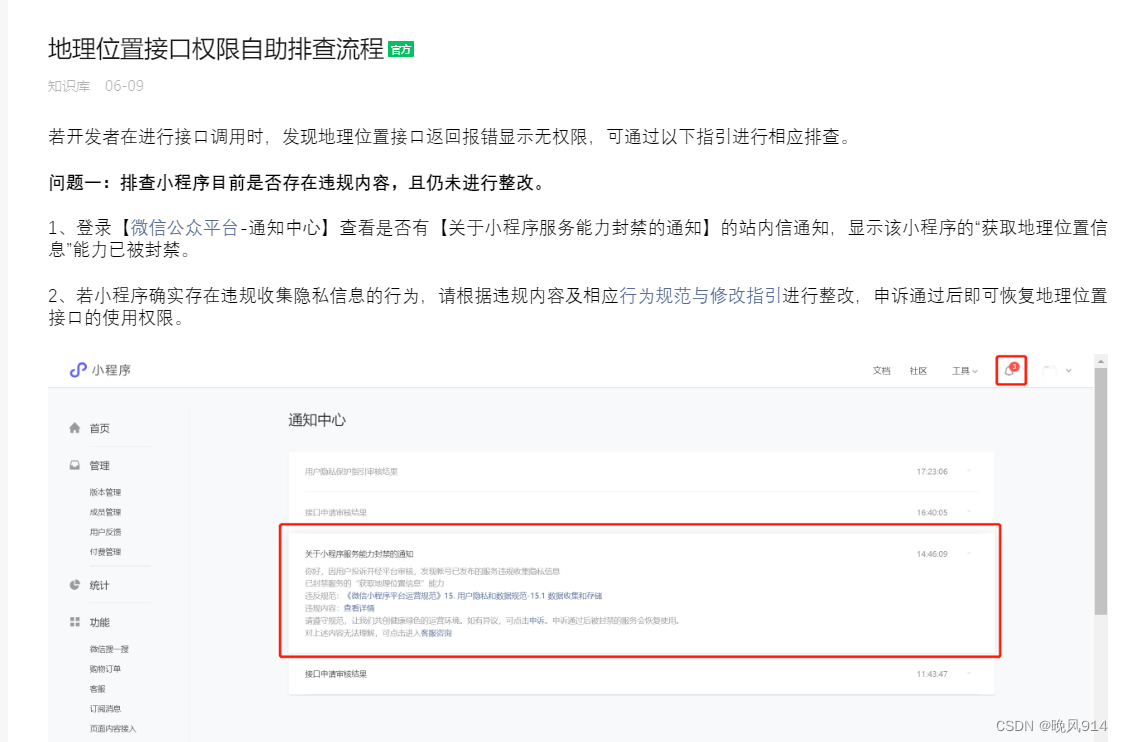
微信小程序开发,小程序类目符合,线上版本无权限申请wx.getLocation接口
我开发 的小程序类目符合wx.getLocation接口的申请标准 但是却还是显示无权限申请 后来研究好久才发现,小程序需要在发布线上版本时提交用户隐私保护指引 如未设置也可以在 设置-服务内容声明-用户隐私保护指引-声明处理用户信息项并补充填写后提交用户隐私协议审核…...
)
vue2企业级项目(五)
vue2企业级项目(五) 页面适配、主题切换 1、适配 项目下载插件 npm install --save-dev style-resources-loader vue-cli-plugin-style-resources-loader修改vue.config.js部分内容 const path require("path");module.exports {pluginOpt…...

【HTML5】拖放详解及实现案例
文章目录 效果预览代码实现 效果预览 代码实现 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>一颗不甘坠落的流星</title><style>#div1,#div2 {float: left;width: 100px;height: 27px;margin: 10px;paddin…...

Codeforces Round 888 (Div. 3)(视频讲解全部题目)
[TOC](Codeforces Round 888 (Div. 3)(视频讲解全部题目)) Codeforces Round 888 (Div. 3)(A–G)全部题目详解 A Escalator Conversations #include<bits/stdc.h> #define endl \n #define INF 0x3f3f3f3f using namesp…...
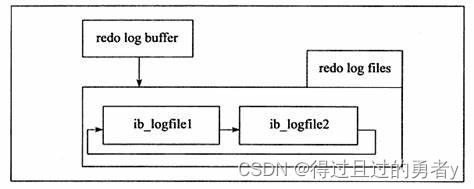
MySQL之深入InnoDB存储引擎——物理文件
文章目录 一、参数文件二、日志文件三、表结构定义文件四、InnoDB 存储引擎文件1、表空间文件2、重做日志文件 一、参数文件 当 MySQL 实例启动时,数据库会先去读一个配置参数文件,用来寻找数据库的各种文件所在位置以及指定某些初始化参数。在默认情况…...

Jquery操作html常用函数
1. text() 获取元素的文本内容:$("#element").text(); 设置元素的文本内容:$("#element").text("New Text"); 2. html() 获取元素的 HTML 内容:$("#element").html(); 设置元素的 HTML 内容&am…...

【Lua学习笔记】Lua进阶——Table,迭代器
文章目录 官方唯一指定数据结构--tabletable的一万种用法字典和数组 迭代器ipairs()pairs() 回到Table 在【Lua学习笔记】Lua入门中我们讲到了Lua的一些入门知识点,本文将补充Lua的一些进阶知识 官方唯一指定数据结构–table 在上篇文章的最后,我们指出…...

重庆市北斗新型智慧城市政府项目
技术栈:使用vue2JavaScriptElementUIvuexaxiosmapboxcesium 项目描述:重庆市北斗新型智慧城市政府项目是基于千寻孪界开发的一款智慧城市项目,包含车辆实时位置定位,智能设备的报警,基础设施的部设等等功能 工作内容&a…...
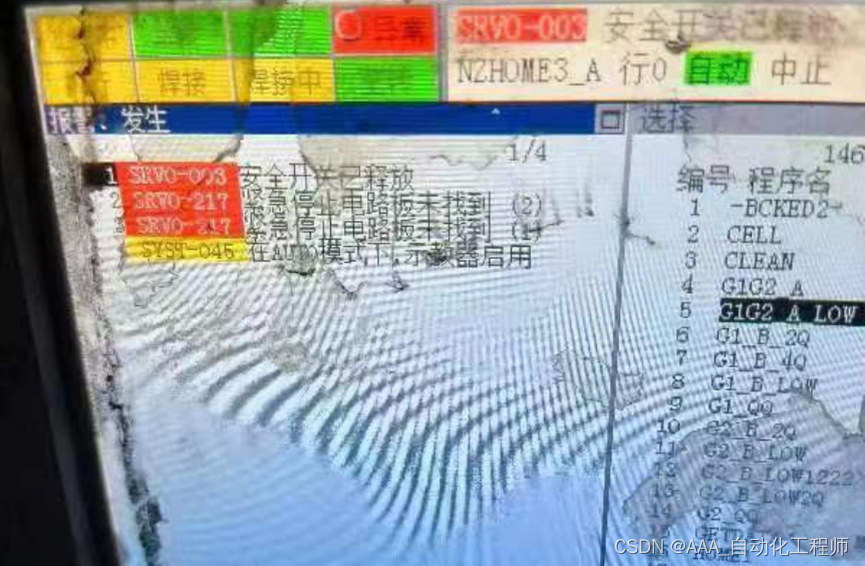
FANUC机器人SRVO-217故障报警原因分析及参考解决办法
FANUC机器人SRVO-217故障报警原因分析及参考解决办法 如下图所示,示教器提示:SRVO-217紧急停止电路板未找到, 查阅手册可以看到以下的报警说明: 故障原因: 通电时未能识别紧急停止电路板或者增设的安全I/O装置。连接有多个安全I/O装置的系统中,在报警信息的最后,会显示发…...
统信UOS安装mysql数据库(mariadb)-统信UOS安装JDK-统信UOS安装nginx(附安装包)
统信UOS离线全套安装教程(手把手教程) 银河麒麟的各种离线全套安装教程: https://blog.csdn.net/ACCPluzhiqi/article/details/131988147 1.统信UOS桌面系统安装mysql(mariadb) 2.统信UOS桌面系统安装JDK 3.统信UOS桌…...

上门小程序开发|上门服务小程序|上门家政小程序开发
随着移动互联网的普及和发展,上门服务成为了许多人生活中的一部分。上门小程序是一种基于小程序平台的应用程序,它提供了上门服务的在线平台,为用户提供了便捷的上门服务体验。下面将介绍一些适合开发上门小程序的商家。 家政服务商家&am…...
1000道网络安全必备面试题合集,秋招金九银十必看!!!
以下为网络安全各个方向涉及的面试题,星数越多代表问题出现的几率越大,祝各位都能找到满意的工作。 注:本套面试题,已整理成pdf文档,但内容还在持续更新中,因为无论如何都不可能覆盖所有的面试问题&#x…...

从0-1实现简易Raft分布式共识算法
一、Raft前置简介 Raft目前是最著名的分布式共识性算法,被广泛的应用在各种分布式框架、组件中,如Redis、RocketMq、Kafka、Nacos(CP)等 根据Raft论文,可将Raft拆分为如下4个功能模块: 领导者选举日志同…...
Spring 创建和使用
Spring 是⼀个包含了众多⼯具⽅法的 IoC 容器。既然是容器那么它就具备两个最基本的功能: 将对象存储到容器(Spring)中; 从容器中将对象取出来。 在 Java 语⾔中对象也叫做 Bean 1.创建 Spring 项目 接下来使⽤ Maven ⽅式来创…...
Javadoc comment自动生成
光标放在第二行 按下Alt Shift j 下面是Java doc的生成 Next Next-> Finish...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...