【计算机视觉中的 GAN 】 - 生成学习简介(1)
一、说明
在阅读本文之前,强烈建议先阅读预备知识,否则缺乏必要的推理基础。本文是相同理论GAN原理的具体化范例,阅读后有两个好处:1 巩固了已经建立的GAN基本概念 2 对具体应用的过程和套路进行常识学习,这种练习题一般的项目,是需要反复几个才能成为行家。好了,我们出发吧!
预备知识:
计算机视觉中的 GAN - 生成学习简介 |人工智能之夏 (theaisummer.com)
【深度学习】生成对抗网络Generative Adversarial Nets_无水先生的博客-CSDN博客
二、GAN概念概述
什么是生成式学习?什么是 GAN?我们为什么要使用它?与自动编码器有什么区别?GAN模型的基本训练算法是什么?我们如何让它学习有意义的表示?它在什么计算机视觉应用中有用?如何为她/他的问题设计一个?
我们将解决所有这些问题以及很多问题!在本评论系列文章中,我们将重点介绍用于计算机视觉应用的大量 GAN。具体来说,我们将慢慢建立导致生成对抗网络(GAN)发展的想法和原则。我们将遇到不同的任务,例如条件图像生成,3D对象生成,视频合成。
让我们从回顾第一部分的内容开始!
通常,数据生成方法存在于从计算机视觉到自然语言处理的各种现代深度学习应用程序中。在这一点上,我们能够通过人眼产生几乎无法区分的生成数据。生成学习大致可分为两大类:
- a)变分自动编码器(VAE)
- b)生成对抗网络(GAN)。
2.1 为什么不只是自动编码器?
很多人仍然想知道为什么研究人员让GANs变得如此困难。为什么不直接使用自动编码器并最小化均方误差,使目标图像与预测图像匹配?原因是这些模型产生的结果很差(对于图像生成)。实际上,由于平均,仅最小化距离会产生模糊的预测。请记住,L1 或 L2 损失是标量,它是所有像素的平均数量。直观地说,这是一个类似于应用平滑过滤器的概念,该滤镜根据平均值对像素值求平均值。其次,不可能以这种方式产生多样性(如变分自动编码器)。这就是为什么研究界的注意力采用了GAN模型。请记住,这不是比较,而是GAN方法的区别。
那么,让我们从头开始:对抗式学习到底是什么?
2.2 什么是对抗式学习?
我们已经通过实验验证,深度学习模型极易受到攻击,这些攻击基于测试时对模型输入的微小修改。假设您有一个经过训练的分类器,该分类器可以使用正确的标签正确识别图像中的对象。
可以构建一个对抗性示例,这是一个视觉上无法区分的图像。这些对抗图像可以通过噪声扰动来构建。但是,图像分类不正确。为了解决这个问题,一种常见的方法是将对抗性示例注入训练集(对抗性训练)。因此,可以提高神经网络的鲁棒性。这种类型的示例可以通过添加噪声、应用数据增强技术或沿与梯度相反的方向扰动图像(以最大化损失而不是最小化损失)来生成。尽管如此,这些类型的技术还是有点手工制作的,所以总会有不同的扰动可以用来欺骗我们的分类器。现在让我们反过来想!
如果我们对拥有一个健壮的分类器不感兴趣,而是对替换对抗性示例的手工制作过程感兴趣,该怎么办?通过这种方式,我们可以让网络创建视觉上吸引人的不同示例。所以,这正是生成术语发挥作用的地方。我们专注于生成数据集的代表性示例,而不是使网络对扰动更健壮!让我们使用另一个网络为我们完成这项工作。您如何调用生成类似于训练示例的现实示例的网络?当然是发电机!
三、香草 GAN(生成对抗网络 2014)
3.1 生成机
由于生成器只是一个神经网络,我们需要为它提供一个输入并决定输出是什么。在最简单的形式中,输入是从小范围的实数分布中采样的随机噪声。这就是我们所说的潜在空间或连续空间。但是,由于我使用“随机”一词,这意味着每次从随机分布中采样时,我都会得到不同的向量样本。这就是随机性的意义所在。这样的输入将为我们提供非确定性的输出。因此,我们可以生成的样本数量没有限制!随机性也是您在与生成对抗学习(GAN)相关的论文中看到期望值符号的原因。输出将是用于生成图像的生成图像或我们想要生成的内容。主要区别在于,现在我们专注于生成特定分布的代表性示例(即狗、绘画、街道图片、飞机等)。
3.2 鉴别器
鉴别器只不过是分类器。但是,我们不是在正确的类中对图像进行分类,而是专注于学习类的分布(假设生成建筑物图像)。因此,由于所需类是已知的,我们希望分类器量化该类对实际类分布的代表性。这就是为什么鉴别器输出单个概率的原因,其中 0 对应于虚假生成的图像,1 对应于我们分布中的真实样本。
理想的发生器会产生无法区分的示例,这意味着输出为 0.5。在博弈论方面,这个对手被称为2人最小最大游戏。在博弈论中,最小-最大博弈或纳什均衡是涉及两个玩家的非合作博弈的数学表示,其中假设每个玩家都知道另一个玩家的均衡策略,并且没有玩家通过改变自己的策略而获得任何好处。
生成器 G 试图生成接近真实分布的假示例,以欺骗鉴别器 D,而 D 试图确定分布的起源。规则GAN的核心思想是基于通过D的“间接”训练,该训练也在动态更新。
3.3 生成对抗训练方案
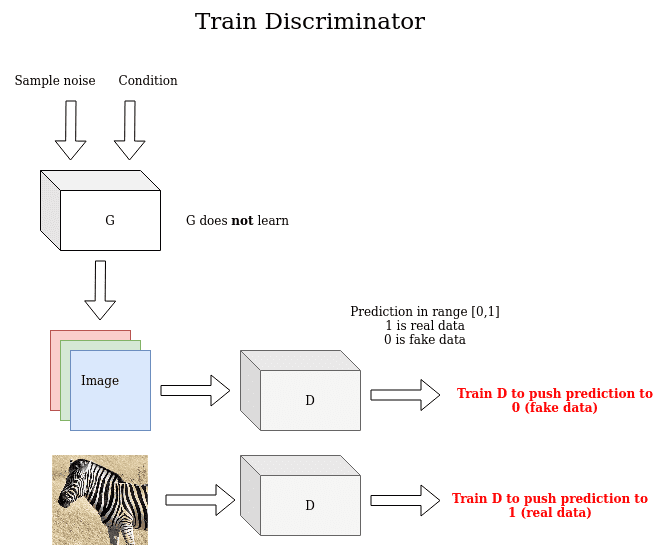
基于上述原则,第一个GAN于2014年推出。了解生成式学习的训练过程很重要。一个关键的见解是间接训练:这基本上意味着生成器的训练不是为了最小化到特定图像的距离,而只是为了欺骗鉴别器!这使模型能够以无监督的方式学习。最后,请注意,训练生成器时的基本事实在输出中为 1(如真实图像),即使示例是假的。发生这种情况是因为我们的目标只是愚弄D。下图说明了此过程:
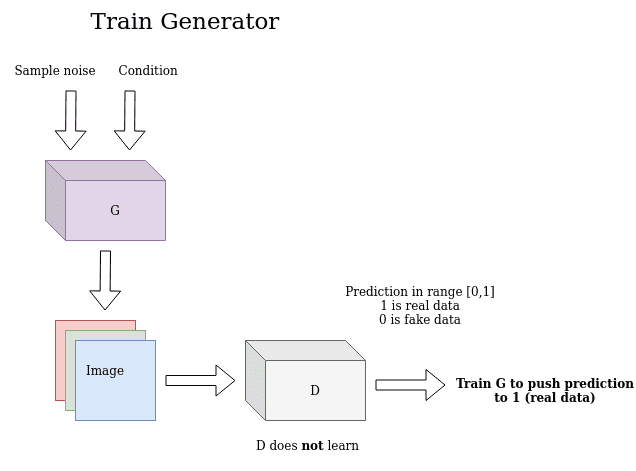
另一方面,判别器使用真实图像和生成的图像来区分它们,将真实图像的预测推到1(真实),将生成图像的预测推到0(假)。在此阶段,请注意生成器未经过训练。
GAN的作者提出了一种由G和D的4个全连接层组成的架构。当然,G 输出图像的一维向量,D 输出 (1,0) 范围内的标量。
3.4 GAN培训计划在行动
代表性赋予我们控制思想的权力。在看到代码之前了解数学是很好的。因此,给定鉴别器 D、生成器 G、vale 函数 V,基本的双人最小值游戏可以定义为(M 是样本):
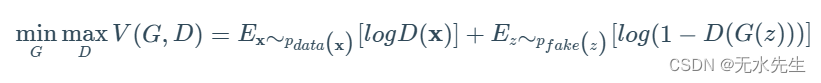
在实践中,回想一下期望值的离散定义,它看起来像这样:
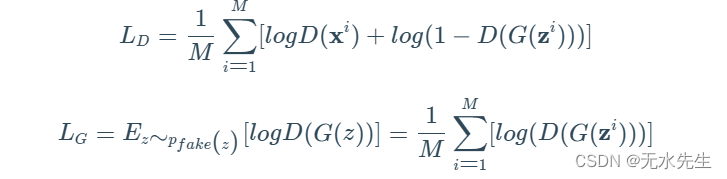
事实上,鉴别器执行梯度上升,而生成器执行梯度下降。这可以通过检查上述方程的生成器部分的差异来观察到。请注意,D 需要访问真实和虚假数据,而 G 无法访问真实图像。让我们看看这个美丽而惊人的想法在真正的python代码中实践:
import torchdef ones_target(size):'''For real data when training D, while for fake data when training GTensor containing ones, with shape = size'''return torch.ones(size, 1)def zeros_target(size):'''For data when training DTensor containing zeros, with shape = size'''return torch.zeros(size, 1)def train_discriminator(discriminator, optimizer, real_data, fake_data, loss):N = real_data.size(0)# Reset gradientsoptimizer.zero_grad()# Train on Real Dataprediction_real = discriminator(real_data)# Calculate error and backpropagatetarget_real = ones_target(N)error_real = loss(prediction_real, target_real)error_real.backward()# Train on Fake Dataprediction_fake = discriminator(fake_data)# Calculate error and backpropagatetarget_fake = zeros_target(N)error_fake = loss(prediction_fake, target_fake)error_fake.backward()# Update weights with gradientsoptimizer.step()return error_real + error_fake, prediction_real, prediction_fakedef train_generator(discriminator, optimizer, fake_data, loss):N = fake_data.size(0)# Reset the gradientsoptimizer.zero_grad()# Sample noise and generate fake dataprediction = discriminator(fake_data)# Calculate error and backpropagatetarget = ones_target(N)error = loss(prediction, target)error.backward()optimizer.step()return error
3.5 GAN 中的模式折叠
一般来说,GAN容易出现所谓的模式崩溃问题。后者通常是指无法充分表示所有可能输出的像素空间的生成器。相反,G只选择几个与噪声图像相对应的有限影响模式。通过这种方式,D能够区分真假,并且G的损失变得非常不稳定(由于梯度爆炸)。我们将在我们的系列中多次重温模式崩溃,因此掌握基本原理至关重要。
基本上,G 卡在一个参数设置中,它总是发出相同的点。发生崩溃后,鉴别器了解到这个单点来自发生器,但梯度下降无法分离相同的输出。结果,D的梯度将生成器产生的单个点永远推到空间周围。
模式崩溃可能会以相反的方式发生:如果在训练鉴别器时卡在局部最小值并且他无法找到最佳策略,那么生成器很容易欺骗当前的鉴别器(在几次迭代中)。
最后,我会用简单的术语来解释模式崩溃:2 人游戏的状态,其中一名玩家获得了几乎不可逆转的优势,这使得很难输掉游戏。
四、条件 GAN(条件生成对抗网络 2014)
条件概率是给定另一个事件发生的概率的度量。在这项工作中,介绍了GAN的条件版本。基本上,条件信息可以通过简单地输入任何“额外”数据来利用,例如图像标签/标签等。通过根据辅助信息调节模型,可以指导数据生成过程。
根据生成任务,可以通过将信息输入 D 和 G 作为通过级联的额外输入来执行条件反射。在诸如医学图像生成等其他领域中,条件可能是人口统计信息(即年龄,身高)或语义分割。
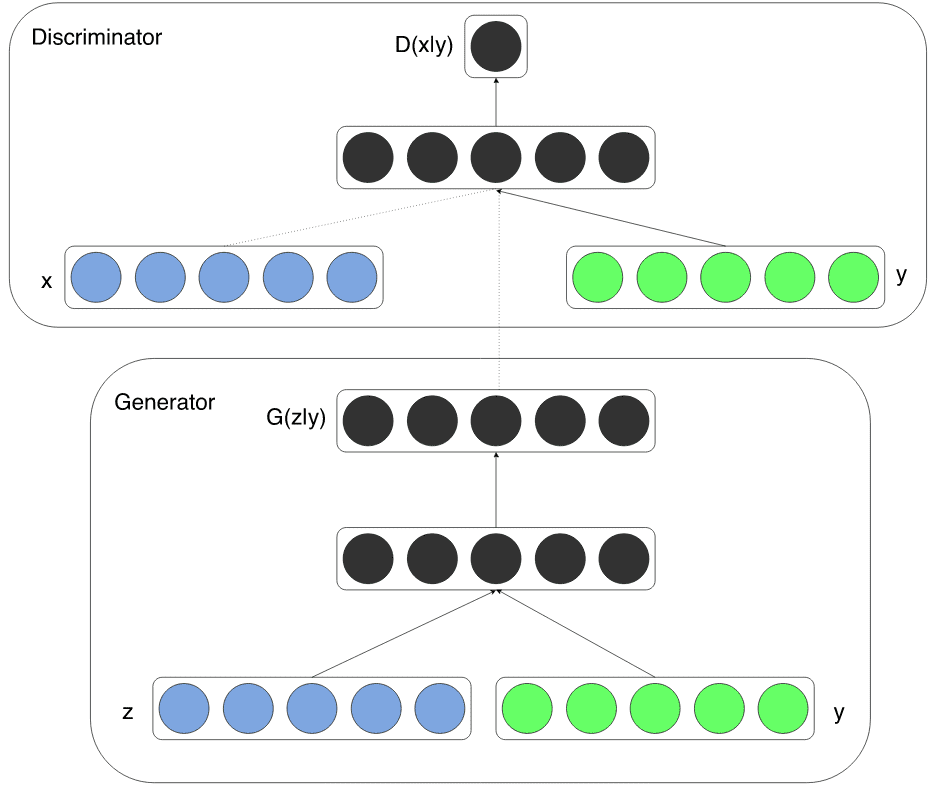
从cGAN论文中获取的GAN调节的视觉表示
五、DCGAN(使用深度卷积生成对抗网络的无监督表示学习 2015)
DCGAN是第一个卷积GAN。深度卷积生成对抗网络(DCGAN)是GAN的拓扑约束变体。为了减少每层的参数数量,以及使训练更快、更稳定,引入了以下原则:
-
将任何池化层替换为 D 中的跨步卷积。这是合理的,因为池化是固定操作。相比之下,跨步卷积也可以看作是学习池化操作,这增加了模型的表现能力。缺点是它还增加了可训练参数的数量。
-
在 G 中使用转置卷积。由于采样噪声是一维向量,因此通常将其投影并重塑为具有大量特征图的小二维网格(即1x2)。这就是为什么G使用转置卷积来增加空间维度(通常将它们加倍)并减少特征图的数量。
-
在 G 和 D 中使用批量归一化。批量归一化可根据层中每个批次的统计数据稳定训练并启用具有更高学习率的训练。
-
删除完全连接的隐藏层以获得更深的架构,以减少训练参数的数量和训练时间。
-
在 G 中对所有图层使用 ReLU 激活,但输出除外,输出在图像范围内生成值 [-1,1]
-
在所有层的鉴别器中使用 LeakyReLU 激活。这两个激活函数都是非线性的,使模型能够学习更复杂的表示。
-
D 的特征映射比比较方法(K 均值)少。一般来说,对于 G 和 D,不清楚哪个模型应该更复杂,因为它与任务相关。在这项工作中,G 比 D 具有更多的可训练参数。但是,这种设计选择背后没有理论依据。
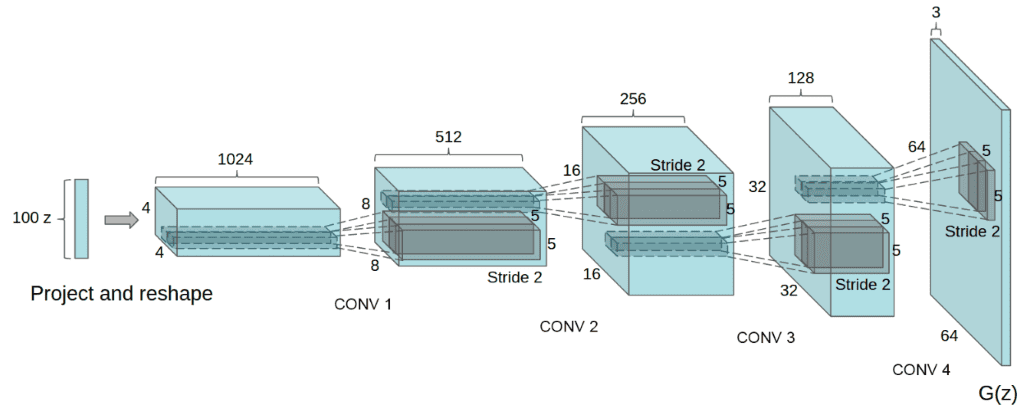
DCGAN的无条件生成器
结果和讨论
让我们观察 MNIST 数据集中 DCGAN 模型的输出,给定一个简单的实现

使用 DCGAN 提高图像质量
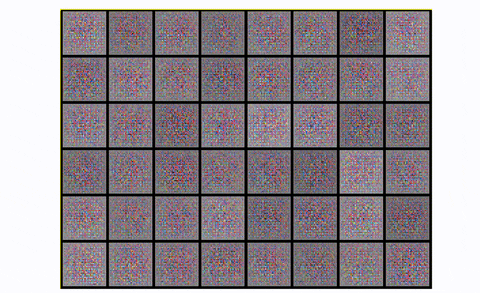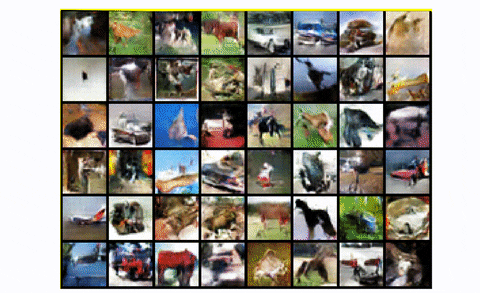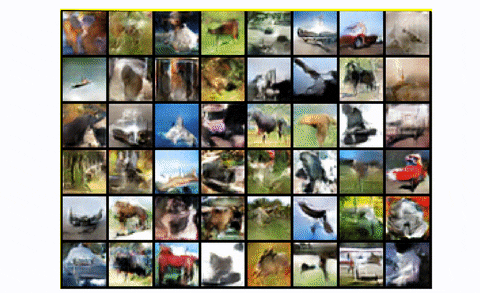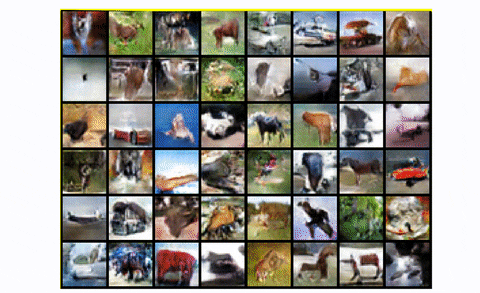
使用卷积模块,输出数字更清晰,包含的噪声更少。如果你想在实践中观察模式崩溃,你可以尝试在CIFAR-10中训练DCGAN,只使用一个类:
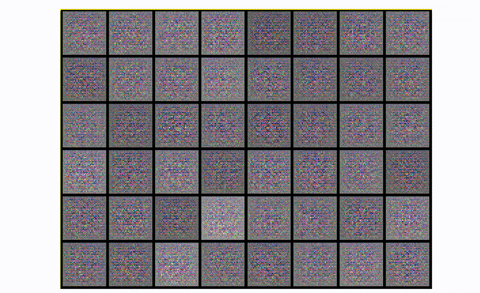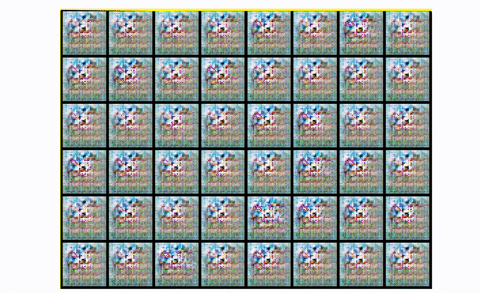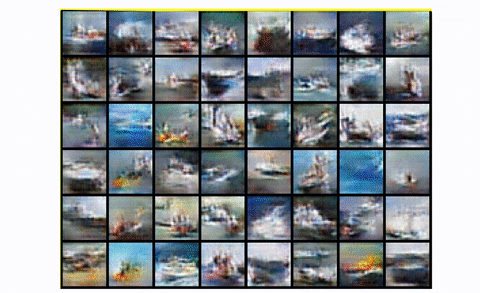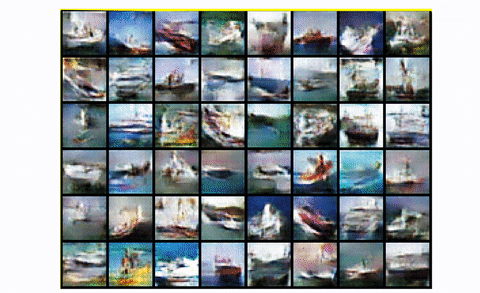
在CIFAR10中观测DCGAN中的模式崩溃,使用一个类
基本上,你从噪音开始。然后,您有一个公平的表示,它开始看起来像所需的图像。然后轰!生成器从字面上折叠它是重复的方形图案。发生了什么事?模式崩溃!.
总而言之,DCGAN是大多数下一个架构所基于的标准卷积基线。与标准GAN相比,它在视觉质量(模糊度较小)和训练稳定性方面都显示出很大的改进。然而,正如我们将看到的,对于像CIFAR-10的无条件图像生成这样的大尺度,它有很大的空间来创造伟大的工程魔法。最后,让我们看一下在整个 CIFAR-10 数据集中用所有类训练 DCGAN 的结果。
DCGAN在CIFAR10
很公平,对吧?
六、Info GAN:通过信息最大化生成对抗网络进行表征学习(2016)
我们已经讨论过 cGAN 的条件变量,通常是类标签或标签。但是,有两个问题没有答案:
a)与噪声相比,有多少信息被传递到生成过程中,以及
b)位于潜在空间中的完全无监督条件可以帮助我们在发电机空间中“行走”吗?
这项工作通过解开的表征和相互信息来解决这些问题。
6.1 解开的表示
解缠表示是一种无监督学习技术,它将每个特征分解(解缠)为狭义定义的变量,并将它们编码为单独的维度。如原始Info GAN论文中所述,解开表示对于需要了解数据重要属性(面部识别,对象识别)的自然任务很有用。就我个人而言,我喜欢将解开表示视为数据较低维度的解码信息。因此,有人认为一个好的生成模型会自动学习解开的表示。
动机是合成观察到的数据的能力具有某种形式的理解。基本上,我们希望模型能够发现独立和关键的无监督表示。这是通过引入一些独立的连续/分类变量来实现的。问题是,是什么让这些条件变量(通常称为潜在代码)与GAN中的现有输入噪声不同?相互信息最大化!
6.2 GAN中的互信息
在通用GAN中,生成器可以自由忽略额外的潜在条件变量。这可以通过找到满足以下条件的解决方案来实现:P(x|c) = P(x)。为了解决琐碎代码的问题,提出了一种信息论正则化。更具体地说,潜在代码c和生成器分布G(z,c)之间应该有高度的互信息。
两个随机变量(条件和输出)的互信息 (MI) 是它们之间相互依赖性的定量度量。从字面上看,它通过观察生成器的输出来量化获得的有关条件变量的“信息量”。因此,如果 I 是给定生成器输出的代码信息量,则I(c |G(z, c))应该很高。MI有一个直观的解释:它是在观察条件随机变量时减少生成的输出中的不确定性。
因此,我们希望P(c|x)要高(小熵)。这意味着给定观察到的生成的图像x,我们很有可能观察到该条件。换句话说,潜在变量c中的信息不应该在生成过程中丢失。接下来的问题自己出现了,我们如何估计条件分布P(c|x)?让我们训练一个神经网络来模拟所需的分布!
6.3 实现条件互信息
由于添加另一个网络来模拟此概率会增加复杂性,因此作者建议通过添加输出此概率的附加层,使用现有的鉴别器对其进行建模。因此,D还有另一个需要学习的目标:最大化互信息!这个额外的目标就是它在标题中被称为互信息正则化(类似于权重衰减)的原因。
因此,给定Q具有D层加上额外分类层的模型,可以定义添加到GAN目标中的辅助损失L_I(G,Q)。最后,我们对GAN的训练过程没有变化,几乎没有额外的开销(计算上没有额外的目标)。这就是 InfoGan 如此绝妙的想法!
6.4 结果
改变连续条件变量,说明我们可以使用低维解缠表示在图像的高维空间中导航。实际上,观察到表征学习会导致有意义的表征,例如旋转和厚度。代码可以在这里找到。

旋转和厚度的无监督建模,InfoGAN
“值得注意的是,在潜在变量中,生成器不会简单地拉伸或旋转数字,而是调整其他细节,如厚度或笔触样式,以确保生成的图像看起来很自然。” ~ 信息甘
七、改进的 GAN 训练技术 (2016)
这是一项伟大的实验工作,总结了可用于自身问题的训练技巧,以稳定 GAN 中的训练。由于GAN训练包括寻找两个玩家的纳什均衡梯度下降,因此对于许多任务(游戏)可能无法收敛。基本上,纳什均衡是一个没有一个球员可以通过改变其权重来提高的点。主要原因是成本函数通常是非凸的,参数是连续的。最后,参数空间是极高维的。
为了更好地理解这一点,请考虑预测分辨率为128x128(16384像素)的图像的任务就像试图在R16384的复杂世界中寻找路径一样。高维路径称为流形,基本上是满足我们目标的生成图像的集合。如果我们的目标是学习人脸,那么我们的目标是找到世界上代表人脸的一小部分。在这条路径中移动就是在表示人脸的向量解决方案内移动。我強烈推薦英伟達的這個視頻。这项工作的代码可以在这里找到。现在,让我们开始训练魔法吧!
7.1 功能匹配
基本上,生成器被训练为匹配鉴别器中间层上特征的期望值。新目标要求生成器生成与真实数据的统计信息(中间表示)匹配的数据。通过以这种方式训练鉴别器,我们要求D找到那些对真实数据与当前模型生成的数据最具区别的特征。到目前为止的经验结果表明,特征匹配在常规GAN变得不稳定的情况下确实有效。为了测量距离,采用了L2范数。
7.2 小批量歧视
理念:小批量判别使我们能够非常快速地生成具有视觉吸引力的样品。
动机:由于鉴别器独立处理每个示例,因此其梯度之间没有协调,因此没有机制来告诉生成器的输出彼此更加不同。
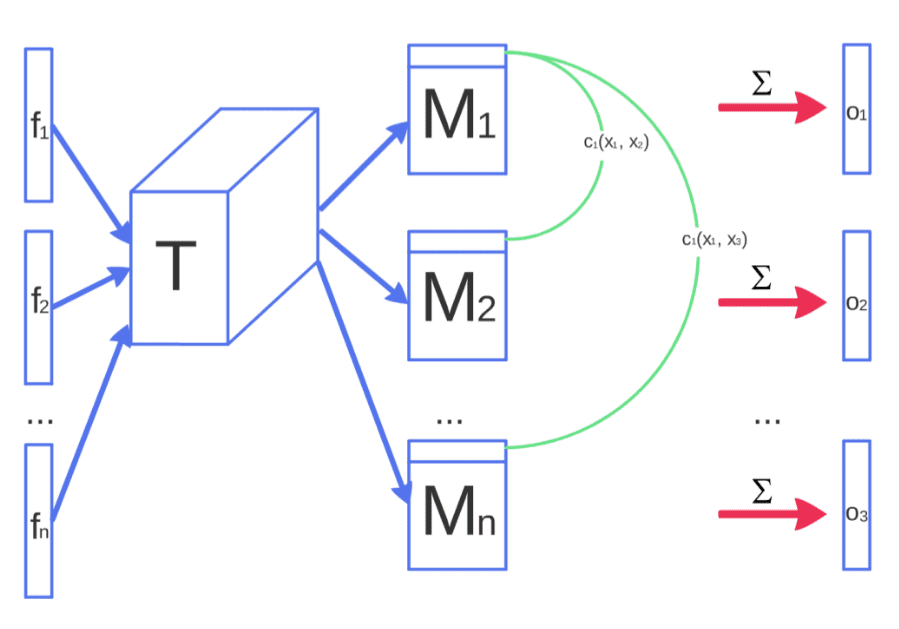
解决方案:允许鉴别器组合查看多个数据示例,并执行我们所说的小批量判别。如上图所示,中间特征向量乘以 3D 张量,得到由 M1 表示的矩阵序列。基于矩阵,最终目标是量化每个数据对的成对相似性的度量。直观地说,现在每个样本都会有额外的信息o(xi),表示与其他数据样本相比的相似性。
事实上,它们将小批量层的输出相似度 o(xi) 与其输入的中间特征 f(xi) 连接起来。然后,结果被输入到鉴别器的下一层。因此,鉴别器的任务仍然有效地将单个示例分类为真实数据或生成数据,但它现在能够使用小批量中的其他示例作为辅助信息。然而,这种方法的计算复杂度巨大,因为它需要所有样本之间的成对相似性。
7.3 历史平均体重
参数的历史平均值可以在线更新,因此此学习规则可以很好地扩展到较长的时间序列。它对于梯度下降可能失败的低维问题非常有用。如果你曾经看过动量是如何工作的,它的工作原理是相同的,只是它只解释了之前的梯度。历史权重平均大致相同,但过去有多个时间步长。
7.4 单侧标签平滑和虚拟批次归一化
仅在正标签(真实数据样本)中将标签平滑化为α(而不是 0)。这里不多说。与标准批次规范化相反,在虚拟批次归一化中,每个示例 x 都基于在参考批次示例上收集的统计信息进行规范化。动机是批量规范化导致输入示例 x 的神经网络输出高度依赖于同一小批量的其他输入。为了应对这种情况,选择一次参考批次的示例,并在训练期间保持固定。但是,引用批处理仅使用其自己的统计信息进行规范化,因此计算成本很高。
7.5 初始分数:评估图像质量
该文没有逐一检查视觉质量,而是提出了一种新的定量方法来评估模型。这可以简单地描述为两步方法:首先,使用预先训练的分类器(InceptionNet)推断生成图像的标签(条件概率)。然后,测量分类器的KL散度与无条件概率的比较。为此,我们不需要志愿者来评估我们的模型,我们可以量化模型的分数。
7.6 半监督学习
可以使用任何标准分类器进行半监督学习,只需将来自 GAN 生成器 G 的样本添加到我们的数据集中,用新的“生成”类标记它们,或者没有额外的类,因为预训练分类器以低熵(高概率,即人类 97/100)识别标签(条件概率)。
7.7 结果和讨论

摘自原始出版物
基于所提出的技术,GANs首次能够学习可区分的特征。图示的动物特征包括眼睛和鼻子。然而,这些特征并没有正确地组合成具有真实解剖结构的动物。尽管如此,这是朝着GAN发展迈出的一大步。总而言之,这项基础工作的结果是:
基于特征匹配的思想,可以生成人类认可的全局统计数据。发生这种情况是因为人类视觉系统对图像统计数据有很强的适应性,可以帮助推断图像所代表的类别,而它可能对对图像解释不太重要的局部统计数据不太敏感。但是,我们将在下一篇文章中看到,更好的模型尝试使用不同的技术来学习它们。
此外,通过让鉴别器D对图像中显示的对象进行分类,作者试图偏置D,从而开发内部表示。后者强调与人类强调的相同特征。这种效应可以理解为迁移学习的一种方法,并且可以更广泛地应用。
八、结论
在本文中,我们以生成学习的思想为基础。我们引入了对抗学习和GAN训练方案的概念。然后,我们讨论了模态崩溃、条件生成和基于互信息的解缠表示。基于观察到的训练问题,我们介绍了训练GAN的基本技巧。最后,我们在训练网络和实际观察到的模式崩溃时看到了一些结果。有关最近发布的具有多个 GAN 以进行大量实验的出色存储库,请访问此存储库。
如果您想要一门全新的 GAN 课程,我们强烈推荐 Coursera 专业化。如果您想建立自动编码器的背景,我们还建议以下Udemy课程。
到现在为止,您开始意识到我们声称只是第一部分,是大多数教程声称的完整GAN指南。但是,我谦虚地请您考虑检查该系列的其余部分,还有更多有趣的东西。每天一篇 GAN 文章就足够了!
在下一篇文章中,我们将看到更高级的架构和训练技巧,这些技巧导致了更高分辨率的图像和 3D 对象生成。
}
九、引用
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ...和Bengio, Y. (2014).生成对抗网络。神经信息处理系统进展(第2672-2680页)。
- Mirza, M., & Osindero, S. (2014).条件生成对抗网络。arXiv预印本arXiv:1411.1784。 Radford, A., Metz, L., & Chintala, S. (2015).使用深度卷积生成对抗网络的无监督表示学习。arXiv预印本arXiv:1511.06434。
- Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016).Infogan:通过信息最大化生成对抗网络进行可解释的表示学习。神经信息处理系统进展(第2172-2180页)。
- Salimans,T.,Goodfellow,I.,Zaremba,W.,Cheung,V.,Radford,A.和Chen,X.(2016)。改进了训练甘斯的技术。神经信息处理系统进展(第2234-2242页)。
相关文章:
【计算机视觉中的 GAN 】 - 生成学习简介(1)
一、说明 在阅读本文之前,强烈建议先阅读预备知识,否则缺乏必要的推理基础。本文是相同理论GAN原理的具体化范例,阅读后有两个好处:1 巩固了已经建立的GAN基本概念 2 对具体应用的过程和套路进行常识学习,这种练习题一…...

深度学习实战44-Keras框架下实现高中数学题目的智能分类功能应用
大家好,我是微学AI ,今天给大家介绍一下深度学习实战44-Keras框架实现高中数学题目的智能分类功能应用,该功能是基于人工智能技术的创新应用,通过对数学题目进行智能分类,提供个性化的学习辅助和教学支持。该功能的实现可以通过以下步骤:首先,采集大量的高中数学题目数据…...

Redis Sentinel 及 Redis Cluster
Redis Sentinel Redis-Sentinel(哨兵模式)是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是…...

shell中按照特定字符分割字符串,并且在切分后的每段内容后加上特定字符(串),然后再用特定字符拼接起来
文件中的内容,可以这么写: awk -F, -v OFS, {for(i1;i<NF;i){$i$i"_suffix"}}1 input.txt-F,:设置输入字段分隔符为逗号(,),这将使awk按照逗号分割输入文本。-v OFS‘,’:设置输…...

探寻智能化未来:AI与Web3共创金融领域巨大潜力
人工智能(AI)和Web3技术的迅猛发展为我们带来了许多新的机遇和影响。在数字经济和社会的浪潮中,结合了AI的智能化能力和Web3的去中心化与区块链技术,我们将进入一个智能化的Web3时代。人工智能和Web3技术是开拓生产力极限和重新定…...
Django学习笔记-表单(forms)的使用
在Django中提供了了form表单,可以更为简单的创建表单模板信息,简化html的表单。 一、网页应用程序中表单的应用 表单通常用来作为提交数据时候使用。 1.1 创建表单模板文件夹 在项目文件夹下创建一个template文件夹,用于存储所有的html模…...

机器学习分布式框架ray运行TensorFlow实例
使用Ray来实现TensorFlow的训练是一种并行化和分布式的方法,它可以有效地加速大规模数据集上的深度学习模型的训练过程。Ray是一个高性能、分布式计算框架,可以在集群上进行任务并行化和数据并行化,从而提高训练速度和可扩展性。 以下是实现…...
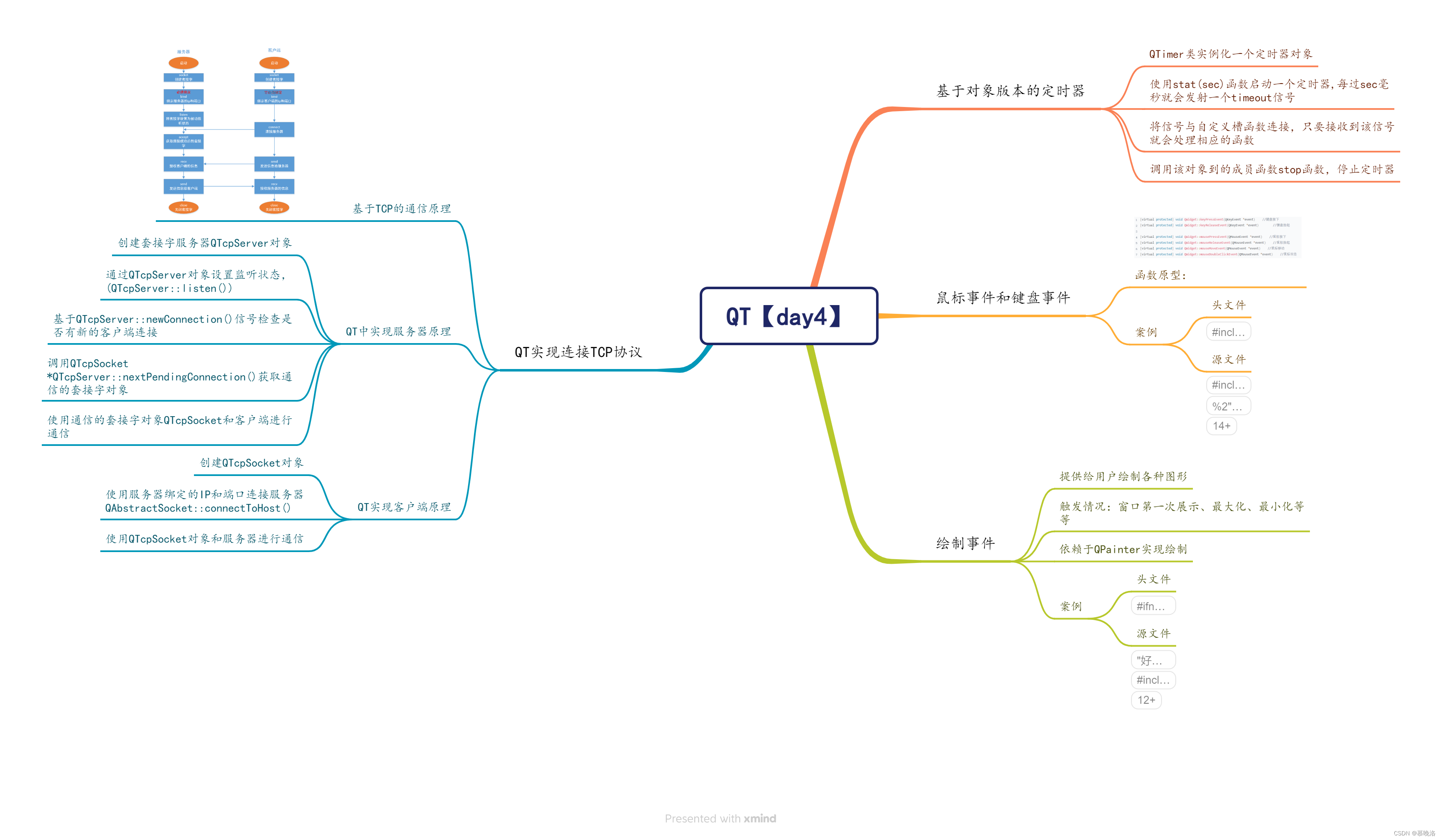
QT【day4】
chat_QT服务器端: //.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include<QTcpServer> //服务器类 #include<QTcpSocket> //客户端类 #include<QMessageBox> //对话框类 #include<QList> //链表容器 #inc…...

java中方法相关知识点详解
方法 简介 方法是一段用来完成特定功能的代码片段,用于定义该类或该类的实例的行为特征和功能实现语句块【复合语句】 语句块中定义的变量只能用于自己,外部不能使用 语句块可以使用外部的变量,而外部不能使用语句块的变量语法 [修饰符1 修饰…...

【算法训练营】Fibonacci数列+合法括号序列判断+两种排序方法
7.29 Fibonacci数列题目解析代码 合法括号序列判断题目题解代码 两种排序方法题目:题解代码 Fibonacci数列 题目 题目链接: 点击跳转 解析 【题目解析】: 本题是对于Fibonacci数列的一个考察,Fibonacci数列的性质是第一项和第二项都为1&am…...
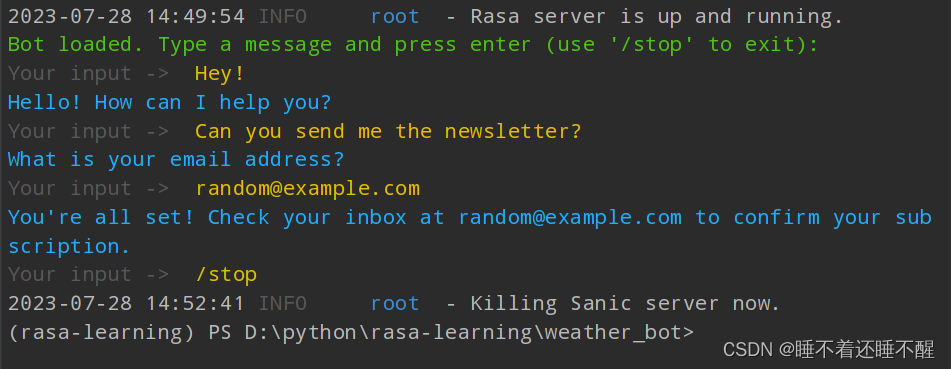
【Rasa】入门案例学习
Rasa初体验--构建对话机器人 NLU数据 version: "3.1"nlu:- intent: greetexamples: |- Hi- Hey!- Hello- Good day- Good morning- intent: subscribeexamples: |- I want to get the newsletter- Can you send me the newsletter?- Can you sign me up for the ne…...

基于java的坦克大战游戏的设计与实现--开题报告--【毕业论文】
文章目录 本系列校训毕设的技术铺垫文章主体层次选题目的和意义:与本课题相关的技术和方法综述:主要设计内容:设计的环境、方法及措施:参考文献 配套资源 本系列校训 互相伤害互相卷,玩命学习要你管,天生我…...

学习笔记|百度文心千帆大模型平台测试及页面交互简易代码
目前百度文心一言的内测资格申请相当拉胯,提交申请快3个月,无任何音讯。不知道要等到什么时候。 百度适时开放了百度文心千帆大模型平台,目前可以提交申请测试,貌似通过的很快,已取得测试申请资格,可以用起…...

Python中的数据科学实验库有哪些?
Python中有许多数据科学实验库可供使用。以下是一些常用的库: NumPy:用于处理大型多维数组和矩阵的基础数学库。Pandas:用于数据处理和分析的库,提供了灵活的数据结构和数据操作工具。Matplotlib:用于创建静态、动态和…...

区间预测 | MATLAB实现QRLSTM长短期记忆神经网络分位数回归多输入单输出区间预测
区间预测 | MATLAB实现QRLSTM长短期记忆神经网络分位数回归多输入单输出区间预测 目录 区间预测 | MATLAB实现QRLSTM长短期记忆神经网络分位数回归多输入单输出区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRLSTM长短期记忆神经网络分位数回…...

Pytorch nn.Linear的基本用法与原理详解
1. 参考 Pytorch nn.Linear的基本用法与原理详解_iioSnail的博客-CSDN博客 [机器学习]深度学习初学者大疑问之nn.Linear(a,b)到底代表什么?_五阿哥爱跳舞的博客-CSDN博客...
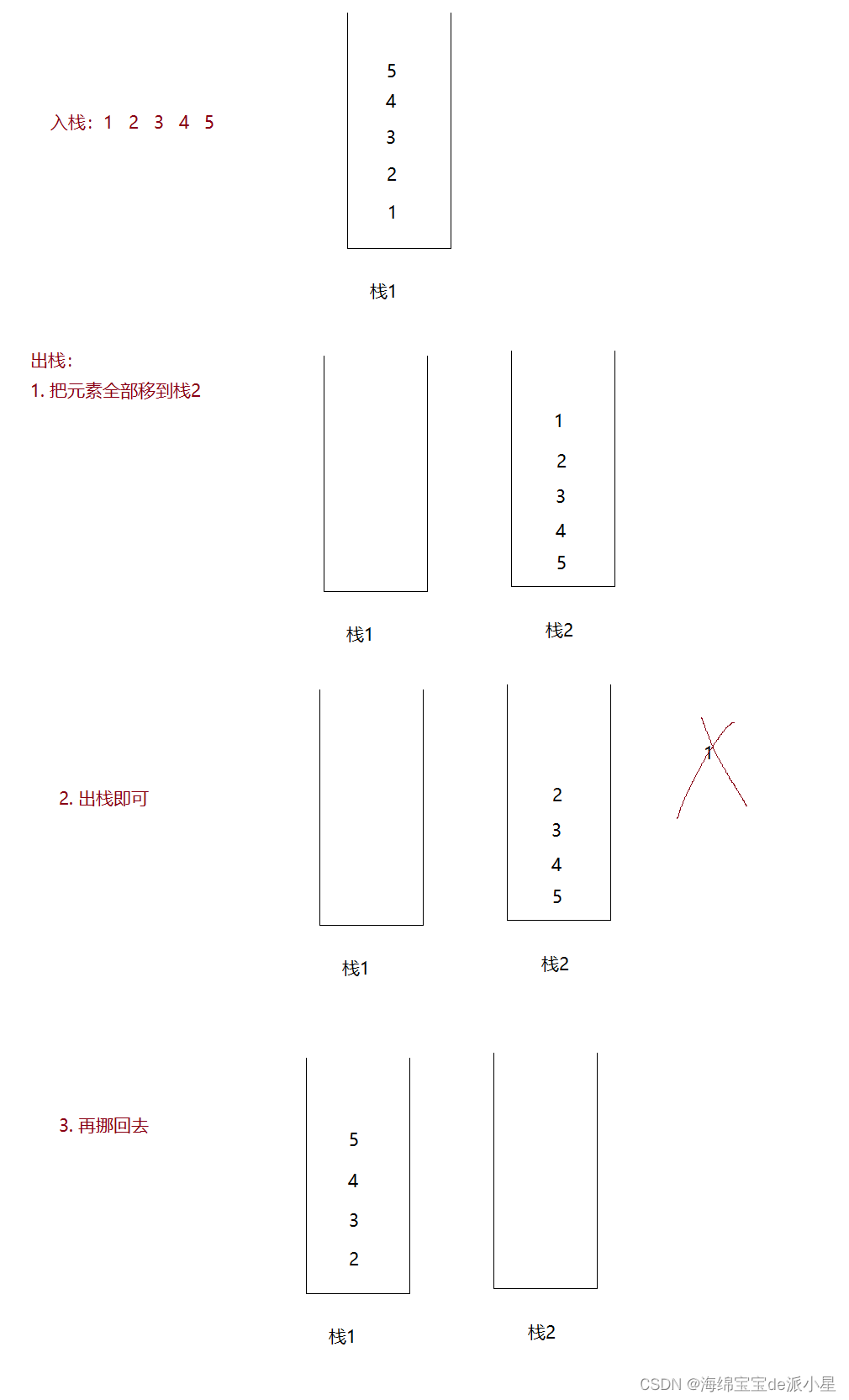
数据结构:栈和队列的实现和图解二者相互实现
文章目录 写在前面栈什么是栈栈的实现 队列什么是队列队列的实现 用队列实现栈用栈模拟队列 写在前面 栈和队列的实现依托的是顺序表和链表,如果对顺序表和链表不清楚是很难真正理解栈和队列的 下面为顺序表和链表的实现和图解讲解 手撕图解顺序表 手撕图解单链表 …...

深入理解C++命名空间
文章目录 1. 命名空间的概念2. 解决命名冲突3. 嵌套命名空间4. 使用命名空间别名总结 在C编程中,命名空间(Namespace)是一种非常有用的工具,它可以帮助我们组织和管理代码,避免命名冲突。本文将深入介绍C命名空间的概念…...

<MySQL>建表SQ和CRUD SQ脚本案例二
1. MySQL 建表SQ脚本案例: 地域表 CREATE TABLE xxx_region_list_dic (seqId INT(11) NOT NULL AUTO_INCREMENT,sortId INT(11) DEFAULT NULL,name VARCHAR(255) NOT NULL COMMENT 地域,code VARCHAR(25) NOT NULL COMMENT 编码,isEnable VARCHAR(25) DEFAULT NULL…...

webpack基础配置
webpack基础 webpack 处理css兼容问题webpack 处理css闪屏问题webpack 优化压缩css代码总结webpack 两种开发模式webpack 基本的功能webpack配置 5概念devServer 生产环境webpack配置实例开发环境webpack配置实例webpack优化 webpack 处理css兼容问题 下载loader 引入 package…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...