代码随想录算法训练营第二十二天 | 读PDF复习环节2
读PDF复习环节2
- 本博客的内容只是做一个大概的记录,整个PDF看下来,内容上是不如代码随想录网站上的文章全面的,并且PDF中有些地方的描述,是很让我疑惑的,在困扰我很久后,无意间发现,其网站上的讲解完全符合我的思路。这次看完这些PDF后,暂时一段时间内不会再看了,要复习还是依靠,代码随想录网站,视频,和我自己写的博客吧
- 二叉树章节
- 递归三部曲
- 判断了递归中不会有空节点,就可以不写返回条件?以前序遍历为例
- 二叉树的迭代遍历(一定要学会)
- 前中后序遍历的,统一迭代方法
- 二叉树的层序遍历
- 117. 填充每个节点的下一个右侧节点指针 II
- 104.二叉树的最大深度
- 111.二叉树的最小深度
- 上面求最大深度和最小深度的题目,我们后面还会遇到,可以发现,其实递归也不一定比迭代法好用,只不过能不能想的到,使用层序遍历,就是需要修炼的了。
- 226.翻转二叉树,通过本题,希望学会,如何将递归方法中的逻辑,写在相对应的迭代法中
- 只要是能编写出相应迭代法的递归法,在时间复杂度上二者差不多,在空间复杂度上,迭代法要优于递归。因为递归需要系统堆栈存储参数,返回值等信息。
- 通过上一题,我们要意识到,非统一版本的迭代法,前序和后序都是基于栈的,也是靠栈来遍历的,而非统一版本的迭代法的中序遍历,是靠指针来遍历的。这二者是不同的。而统一版本的迭代法,前中后序都是基于栈来遍历的。
- 对称二叉树
- 经过上一题,学会了如何处理,在迭代法中要处理空节点的情况。统一风格的迭代法中,因为要用空节点来标记要处理的中间节点,就不能再让空节点入栈了。中序迭代遍历也不行,因为中序迭代法,是需要指针来指示当前位置的,所以也要求空节点不入栈。
- 二叉树的最大深度
- 虽然我们之前写过了,前中后序的迭代法代码,但是并不代表,迭代法的代码和递归中的前中后序对应,非统一编写风格的迭代法只能模拟前序遍历,后序遍历是通过翻转,中序遍历是通过指针。统一编写风格的迭代法,是可以利用栈来模拟递归和回溯的,代码随想录中也说了,有些递归算法的对应迭代法,写起来的代码逻辑是很难的。
- 非统一编写风格中,因为空节点不入栈,所以无法知道,目前代码的处理逻辑在哪个节点。但是统一风格下,有None的存在,当遍历到叶子节点时,我们可以通过pop四次,得到左右叶子,将处理的结果append进栈,再append一个None,我目前感觉这样的处理逻辑应该可行。
- 求二叉树的最小深度
- 有点乱了,求最小深度,前序和迭代,不会写
- 完全二叉树的节点个数
- 平衡二叉树
- 本题的迭代法太麻烦,要先搞一个函数,专门计算深度,在搞另一个函数,从前序开始,遍历每一个节点,去判断左右子树,太复杂,本题的迭代法不做学习。
- 二叉树的所有路径
- 本题的迭代法,在编写感觉上,与递归稍有不同,关键点在于搞清楚,增加路径的逻辑应该放在哪里,以及遇到叶子节点的处理逻辑,是否需要加入最后一个节点的数值?迭代法因为在初始化时,要有根节点,所以在加入路径的逻辑上,与迭代法不同,要注意体会。
- 想不明白的时候,就自己模拟试试。
- 迭代法,模拟前中后序就用栈,适合层序遍历就用队列。
- 左叶子之和
- 树左下角的值
- 路径总和
- 路径总和II
- 用迭代法记录所有路径是很繁琐的,这种题不适合迭代法,一定要体会其中区别!问“有没有?”,迭代法可以;“找出所有可能?”迭代法不行。
- 递归函数,什么时候需要返回值,什么时候不需要?
- 前面两道,路径总和的题,可以在子节点判断后,再加一个判断做剪枝
- 前面两题,我写的和代码随想录写的细节有些不同,我是从空列表开始递归,卡哥是先让根节点入栈了,这一个差异,就导致代码编写风格差异一看上去还挺大。
- 中序后序建立二叉树,前序中序建立二叉树,这两题只要想清楚,区间的左右边界就可以了,过。
- 最大二叉树,同上一题,都是构造的题目
- 合并二叉树
- 二叉搜索树中的搜索
- 验证二叉搜索树(重要!重要!重要!因为我一直不会)
- 这道题我竟然还是不会!
- 看到二叉搜索树就要想到中序遍历,中序遍历得到的数组是递增的。
- 二叉搜索树的最小绝对差
- 二叉搜索树中的众数
- 怎么bug一直调不好了?这题有很多细节我没注意到,下面的是错误的代码
- 上述代码的致命错误,大致如下:首先是初始化上的错误,两个计数器必须全部置0,另外,让根节点进去结果列表,这是毫无道理的!第二点就是没有处理好第一个节点(最左下的节点),当 pre 是 None 时,我们应该将 count 赋值为 1 ,这样最左下的节点就可能作为结果。第三点,对于当前节点是否是空节点的判断,只能决定,当前的 count 是多少,而结果处理逻辑,肯定是要放在 if 判断之外的,不然也同样会漏掉,最左下节点作为结果的情况。
- 如果本题不是二叉搜索树,而是一般二叉树,就要利用字典了
- 二叉树的最近公共祖先
- 二叉搜索树的最近公共祖先
- 这道题,因为有序树的存在,思路和上一题完全不一样了!本题的核心在于利用二叉搜索树的性质。需要理解的是,按照如下规则找到的节点,一定是最近的公共祖先,因为一旦向下进入左右孩子,必然会丢失掉 p q 中的一个。
- 二叉搜索树中的插入操作
- 删除二叉搜索树中的节点
- 这道题写下来还是蛮难的,而且我感觉我现在的逻辑也没有很清晰,加了不少 if 判断。我主要的思路就是,删除当前节点后,直接用当前节点的左孩子顶上来,然后把当前节点的右子树,加到左孩子的最右。这样就满足二叉搜索树的性质。但是还要处理很多特殊情况,这也是我这么多 if 的由来,比如我取了当前节点的左右孩子,那么自然就要考虑,如果是空怎么办?都是空?一个是空?情况都要考虑清楚。
- 只要取了节点的左右孩子,还想取它的value,就要想到,判断是否是None。看看代码随想录的解答吧
- 卡哥给出的,普通树的删除方法,以及迭代法,都先不做学习了,先掌握最基本的递归法。
- 本题对于第五步,删除拼接的情况,本来就有两种选择,上面我都提到了,左接右,右接左。
- 修剪二叉搜索树
- 不会,理不清处理逻辑。
- 看看代码随想录的解答。这是一个思维转变的问题,好好理解。
- 这道题非常非常重要。迭代法先不做学习了、
- 将有序数组转换为二叉搜索树
- 把二叉搜索树转换为累加树
本博客的内容只是做一个大概的记录,整个PDF看下来,内容上是不如代码随想录网站上的文章全面的,并且PDF中有些地方的描述,是很让我疑惑的,在困扰我很久后,无意间发现,其网站上的讲解完全符合我的思路。这次看完这些PDF后,暂时一段时间内不会再看了,要复习还是依靠,代码随想录网站,视频,和我自己写的博客吧
二叉树章节
二叉树章节,做不出来的题基本上都有一个共性,对二叉树的数据结构特性不熟悉,从而没有编写思路,或者在判断条件上产生疏漏。
完全二叉树:除了最底层可能没填满,其余每层节点数都达到最大值,并且最下面一层的节点,都集中在该层最左边的若干位置。一个很关键的点:完全二叉树的某些子树,一定是满二叉树,节点数量是可以计算的。去计算最左和最后,一直向左找,计数,一直向右找,计数,如果两数相等,这颗子树就是满二叉树。
二叉搜索树:若它的左子树不空,则左子树上所有节点的值,均小于它的根节点的值。若它的右子树不空,则右子树上所有节点的值,均大于它的根节点的值。它的左右子树也分别为二叉搜索树。
平衡二叉树:它是一个空树,或者它的左右两个子树的高度差的绝对值不超过1,并且左右子树都是一颗平衡二叉树。
二叉树的链式存储,是大家一直在用的,那么其顺序存储,要注意,需要将树填补为一颗满二叉树,才能满足公式,如果父节点的数组下标是 i , 那么它的左孩子就是 i2+1,右孩子是 i2+2 。
在遍历方式上,主要分为两大类,深度优先遍历(前中后序)遍历,广度优先遍历(层序遍历)。层序遍历有时候是很好用的方法,有的题,用递归解法较复杂,或者在代码编写逻辑上不好思考,后面会提到。
深度优先遍历的三种方法中,后序遍历是应用最多的,因为很多时候,我们都需要去收集,左右子树的信息,来决定当前节点的方式,或者说,需要将某些信息,一层一层地返回到根节点,这时候都需要后序遍历。中序遍历,和二叉搜索树,严格绑定。前序遍历需要的场景,一般都有比较明显的特征,可以意识到。
前序遍历:中左右;中序遍历:左中右;后序遍历:左右中。

二叉树的节点定义:
class TreeNode:def __init__(self, val, left = None, right = None):self.val = valself.left = leftself.right = right
递归三部曲
1、确定递归函数的参数和返回值。2、确定终止条件。3、确定单层递归的逻辑
判断了递归中不会有空节点,就可以不写返回条件?以前序遍历为例
两个版本代码的对比,一个带空节点判断,一个不带。
class Solution:def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:if root == None :return []self.res = []self.digui(root)return self.resdef digui(self,root):self.res.append(root.val)if root.left:self.digui(root.left)if root.right:self.digui(root.right)class Solution:def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:if root == None :return []self.res = []self.digui(root)return self.resdef digui(self,root):if root == None :returnself.res.append(root.val)self.digui(root.left)self.digui(root.right)二叉树的迭代遍历(一定要学会)
前序遍历:
class Solution:def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:if root == None :return []stack = [root]res = []while stack :node = stack.pop()res.append(node.val)# 注意,空节点不入栈if node.right :stack.append(node.right)if node.left :stack.append(node.left)return res
后序遍历:
class Solution:def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:if root == None :return []stack = [root]res = []while stack :node = stack.pop()res.append(node.val)# 空节点不入栈if node.left:stack.append(node.left)if node.right:stack.append(node.right)# 代码编写顺序是,中左右,但是因为使用的是栈,那么在res数组中的顺序是,中右左,倒序,左右中return res[::-1]
中序遍历:
class Solution:def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:if root == None :return []stack = []cur = rootres = []while stack or cur:# 同样注意,空节点不入栈if cur :stack.append(cur)cur = cur.leftelse :cur = stack.pop()res.append(cur.val)cur = cur.rightreturn res
上面三种迭代方法,需要注意的共同点是:迭代法中,要保证,空节点不入栈。
前中后序遍历的,统一迭代方法
以中序遍历为例:因为是迭代法,使用的是栈作为数据结构,在代码中的编写顺序,和在结果集中的保存顺序,是不一样的。代码编写是,右中左,结果集中就是,左中右
lass Solution:def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:if root == None :return []stack = [root]res = []while stack :node = stack.pop()if node == None :node = stack.pop()res.append(node.val) else :# 当node不是空节点时的操作,是关键# 要根据遍历顺序重新调整元素顺序# 因为是使用堆栈,所以要从下向上看,左中右if node.right : # 右stack.append(node.right)stack.append(node) # 中stack.append(None)if node.left : # 左stack.append(node.left)return res
二叉树的层序遍历
层序遍历是有标准写法的。代码随想录中列出的,与层序遍历相关的10道题,都是稍微修改就可以做出来的。
class Solution:def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:if root == None :return []dq = deque()dq.append(root)res = []level = []while dq :size = len(dq)for i in range(size):node = dq.popleft()level.append(node.val)if node.left :dq.append(node.left)if node.right :dq.append(node.right)res.append(level)level = []return res
117. 填充每个节点的下一个右侧节点指针 II
以层序遍历为模板。
from collections import deque
class Solution:def connect(self, root: 'Node') -> 'Node':if root == None :return rootdq = deque()dq.append(root)pre = Nonewhile dq :size = len(dq)for i in range(size):if i == 0 :pre = dq.popleft()else :node = dq.popleft()pre.next = nodepre = nodeif pre.left :dq.append(pre.left)if pre.right :dq.append(pre.right)return root
104.二叉树的最大深度
class Solution:def maxDepth(self, root: TreeNode) -> int:if not root:return 0depth = 0queue = collections.deque([root])while queue:depth += 1for _ in range(len(queue)):node = queue.popleft()if node.left:queue.append(node.left)if node.right:queue.append(node.right)return depth
111.二叉树的最小深度
需要注意的是,只有当左右孩子都为空的时候,才说明遍历的最低点了。如果其中一个孩子为空则不是最低点.
class Solution:def minDepth(self, root: TreeNode) -> int:if not root:return 0depth = 0queue = collections.deque([root])while queue:depth += 1 for _ in range(len(queue)):node = queue.popleft()if not node.left and not node.right:return depthif node.left:queue.append(node.left)if node.right:queue.append(node.right)return depth
上面求最大深度和最小深度的题目,我们后面还会遇到,可以发现,其实递归也不一定比迭代法好用,只不过能不能想的到,使用层序遍历,就是需要修炼的了。
226.翻转二叉树,通过本题,希望学会,如何将递归方法中的逻辑,写在相对应的迭代法中
本题用什么遍历顺序?
对于使用基于递归的方法来说:前序,后序,层序,都可以。唯独中序不行。这个自己画画图就可以知道。
对于使用迭代的方法来说:同递归。(这里的迭代,指的是,不加入None的迭代法)
对于使用统一方式迭代的方法来说:任何顺序都可以。
递归代码,前序遍历:
class Solution:def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:if root == None :return rootroot.left , root.right = root.right, root.leftself.invertTree(root.left)self.invertTree(root.right)return root
递归代码,中序遍历:
class Solution:def invertTree(self, root: TreeNode) -> TreeNode:if not root:return Noneself.invertTree(root.left)root.left, root.right = root.right, root.leftself.invertTree(root.left)return root
迭代代码,中序遍历:
class Solution:def invertTree(self, root: TreeNode) -> TreeNode:if not root:return None stack = [root] while stack:node = stack.pop() if node.left:stack.append(node.left)node.left, node.right = node.right, node.left if node.left:stack.append(node.left) return root
迭代代码,前序遍历:
class Solution:def invertTree(self, root: TreeNode) -> TreeNode:if not root:return None stack = [root] while stack:node = stack.pop() node.left, node.right = node.right, node.left if node.left:stack.append(node.left)if node.right:stack.append(node.right) return root
统一迭代风格的C++代码,中序遍历:
class Solution {
public:TreeNode* invertTree(TreeNode* root) {stack<TreeNode*> st;if (root != NULL) st.push(root);while (!st.empty()) {TreeNode* node = st.top();if (node != NULL) {st.pop();if (node->right) st.push(node->right); // 右st.push(node); // 中st.push(NULL);if (node->left) st.push(node->left); // 左} else {st.pop();node = st.top();st.pop();swap(node->left, node->right); // 节点处理逻辑}}return root;}
};
为什么这个中序就是可以的呢,因为这是用栈来遍历,而不是靠指针来遍历,避免了递归法中翻转了两次的情况。
只要是能编写出相应迭代法的递归法,在时间复杂度上二者差不多,在空间复杂度上,迭代法要优于递归。因为递归需要系统堆栈存储参数,返回值等信息。
通过上一题,我们要意识到,非统一版本的迭代法,前序和后序都是基于栈的,也是靠栈来遍历的,而非统一版本的迭代法的中序遍历,是靠指针来遍历的。这二者是不同的。而统一版本的迭代法,前中后序都是基于栈来遍历的。
对称二叉树
这道题就是后序遍历,但是我觉得在编写风格上,对我来说总感觉这不是后序遍历,用前序遍历的逻辑就写出来了,似乎我还没有完全掌握这道题。
递归法:
class Solution:def isSymmetric(self, root: Optional[TreeNode]) -> bool:if root == None :return Truereturn self.digui(root.left,root.right)def digui(self,left,right):if left == None and right != None :return Falseelif left != None and right == None :return Falseelif left == None and right == None :return Trueelse :if left.val != right.val :return Falseelse :flag1 = self.digui(left.left,right.right)flag2 = self.digui(left.right,right.left)return flag1 and flag2
迭代法:没写出来,困惑点在于:在判断时,需要考虑空节点,但是迭代法的空节点,应该不能入栈的?
使用队列:
import collections
class Solution:def isSymmetric(self, root: TreeNode) -> bool:if not root:return Truequeue = collections.deque()queue.append(root.left) #将左子树头结点加入队列queue.append(root.right) #将右子树头结点加入队列while queue: #接下来就要判断这这两个树是否相互翻转leftNode = queue.popleft()rightNode = queue.popleft()if not leftNode and not rightNode: #左节点为空、右节点为空,此时说明是对称的continue#左右一个节点不为空,或者都不为空但数值不相同,返回falseif not leftNode or not rightNode or leftNode.val != rightNode.val:return Falsequeue.append(leftNode.left) #加入左节点左孩子queue.append(rightNode.right) #加入右节点右孩子queue.append(leftNode.right) #加入左节点右孩子queue.append(rightNode.left) #加入右节点左孩子return True
使用栈:
class Solution:def isSymmetric(self, root: TreeNode) -> bool:if not root:return Truest = [] #这里改成了栈st.append(root.left)st.append(root.right)while st:rightNode = st.pop()leftNode = st.pop()if not leftNode and not rightNode:continueif not leftNode or not rightNode or leftNode.val != rightNode.val:return Falsest.append(leftNode.left)st.append(rightNode.right)st.append(leftNode.right)st.append(rightNode.left)return True
层次遍历:
class Solution:def isSymmetric(self, root: TreeNode) -> bool:if not root:return Truequeue = collections.deque([root.left, root.right])while queue:level_size = len(queue)if level_size % 2 != 0:return Falselevel_vals = []for i in range(level_size):node = queue.popleft()if node:level_vals.append(node.val)queue.append(node.left)queue.append(node.right)# 注意层次遍历这里,空节点也要入栈的,这样才能比较else:level_vals.append(None)if level_vals != level_vals[::-1]:return Falsereturn True
经过上一题,学会了如何处理,在迭代法中要处理空节点的情况。统一风格的迭代法中,因为要用空节点来标记要处理的中间节点,就不能再让空节点入栈了。中序迭代遍历也不行,因为中序迭代法,是需要指针来指示当前位置的,所以也要求空节点不入栈。
前序遍历:
class Solution:def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:if root == None :return []stack = [root]res = []while stack :node = stack.pop()if node == None :continueres.append(node.val)stack.append(node.right)stack.append(node.left)return res
层序遍历:
class Solution:def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:if root == None :return []dq = deque()dq.append(root)res = []level = []while dq :size = len(dq)for i in range(size):node = dq.popleft()if node == None :continuelevel.append(node.val)dq.append(node.left)dq.append(node.right)if level != []:res.append(level)level = []return res
二叉树的最大深度
根节点的高度等于最大深度,后序遍历很好写。求高度,是自底向上的,用后序遍历。求深度,是自顶向下的,用前序遍历。
高度求解法:
class Solution:def maxDepth(self, root: Optional[TreeNode]) -> int:if root == None :return 0return 1 + max(self.maxDepth(root.left) , self.maxDepth(root.right))
深度求解法:递归
class Solution:def maxDepth(self, root: Optional[TreeNode]) -> int:if root == None :return 0self.maxd = 0depth = 0self.digui(root,depth)return self.maxddef digui(self,root,depth):if root == None :if depth > self.maxd :self.maxd = depthreturnself.digui(root.left,depth+1)self.digui(root.right,depth+1)
迭代法,求深度
class Solution:def maxDepth(self, root: Optional[TreeNode]) -> int:if root == None :return 0stack = [(root,1)]maxd = 0while stack :(cur,depth) = stack.pop()maxd = max(maxd,depth)if cur.left :stack.append((cur.left,depth+1))if cur.right :stack.append((cur.right,depth+1))return maxd
层序遍历法:
套用模板即可。
统一编写风格的迭代法:
class Solution:def maxDepth(self, root: Optional[TreeNode]) -> int:if root == None :return 0stack = [(root,1)]maxd = 0while stack :(cur,depth) = stack.pop()if cur :# 中stack.append((cur,depth))stack.append((None,0))# 左if cur.left :stack.append((cur.left,depth+1))# 右if cur.right :stack.append((cur.right,depth+1))# 那么在栈中的顺序就是:右左中,当然这里什么顺序都不是了,因为不需要回溯,只需要记录每次的depthelse :(cur,depth) = stack.pop()maxd = max(maxd,depth)return maxd
虽然我们之前写过了,前中后序的迭代法代码,但是并不代表,迭代法的代码和递归中的前中后序对应,非统一编写风格的迭代法只能模拟前序遍历,后序遍历是通过翻转,中序遍历是通过指针。统一编写风格的迭代法,是可以利用栈来模拟递归和回溯的,代码随想录中也说了,有些递归算法的对应迭代法,写起来的代码逻辑是很难的。
非统一编写风格中,因为空节点不入栈,所以无法知道,目前代码的处理逻辑在哪个节点。但是统一风格下,有None的存在,当遍历到叶子节点时,我们可以通过pop四次,得到左右叶子,将处理的结果append进栈,再append一个None,我目前感觉这样的处理逻辑应该可行。
求二叉树的最小深度
后序:
class Solution:def minDepth(self, root: Optional[TreeNode]) -> int:if root == None :return 0left = self.minDepth(root.left)right = self.minDepth(root.right)# 这里也可以不用left和right来判断,可以用root.left,root.right是否为None来判断if left == 0 and right != 0 :return 1+rightelif left != 0 and right == 0 :return 1+left# 这个判断条件冗余了,和下面else的结果一样elif left == 0 and right == 0 :return 1else :return 1 + min(left,right)
有点乱了,求最小深度,前序和迭代,不会写
前序:
class Solution:def __init__(self):self.result = float('inf')def getDepth(self, node, depth):if node is None:returnif node.left is None and node.right is None:self.result = min(self.result, depth)if node.left:self.getDepth(node.left, depth + 1)if node.right:self.getDepth(node.right, depth + 1)def minDepth(self, root):if root is None:return 0self.getDepth(root, 1)return self.result迭代:
class Solution:def minDepth(self, root: TreeNode) -> int:if not root:return 0depth = 0queue = collections.deque([root])while queue:depth += 1 for _ in range(len(queue)):node = queue.popleft()if not node.left and not node.right:return depthif node.left:queue.append(node.left)if node.right:queue.append(node.right)return depth
完全二叉树的节点个数
利用完全二叉树的性质,提前判断。但归根结底还是后序遍历。
如果是一般二叉树,可以递归可以层序遍历,但是想要利用完全二叉树的性质,只能递归。
class Solution:def countNodes(self, root: Optional[TreeNode]) -> int:if root == None :return 0if root.left == None and root.right == None :return 1return self.count_fun(root)def count_fun(self,root):if root == None :return 0cleft = 0cright = 0head1 = roothead2 = rootwhile head1.left :head1 = head1.leftcleft += 1while head2.right :head2 = head2.rightcright += 1if cleft == cright :number = pow(2,cleft+1)-1return numberelse :return 1 + self.count_fun(root.left) + self.count_fun(root.right)
平衡二叉树
一开始是想就用题目给的 isBalanced 函数,一个函数解决问题,但是发现要从叶子节点计算高度,所以还得两个函数。
在一个就是本题,别想着整个在迭代开始前的判断剪枝,其实省不了多少空间,还可能导致返回值异常的bug。
class Solution:def isBalanced(self, root: Optional[TreeNode]) -> bool:if root == None :return Trueself.res = Trueself.compute(root)return self.resdef compute(self,root):if root == None :return 0left = self.compute(root.left)right = self.compute(root.right)if abs(left-right) > 1 : self.res = Falsereturn 1 + max(left,right)
求深度需要前序遍历,从上到下去查;求高度需要后序遍历,从下到上去计算。
这道题真正想剪枝,应该引入一个不可能的值,作为判断条件。
class Solution:def isBalanced(self, root: Optional[TreeNode]) -> bool:if root == None :return Trueself.res = Trueself.compute(root)return self.resdef compute(self,root):if root == None :return 0left = self.compute(root.left)if left == -1 :return -1right = self.compute(root.right)if right == -1 :return -1if abs(left-right) > 1 : self.res = Falseresult = -1else :result = 1 + max(left,right)return result
本题的迭代法太麻烦,要先搞一个函数,专门计算深度,在搞另一个函数,从前序开始,遍历每一个节点,去判断左右子树,太复杂,本题的迭代法不做学习。
二叉树的所有路径
本题我采用了字符串作为承载路径的数据结构,之前我一直习惯用的是列表,可以放心大胆的 append 和 pop , 用字符串的话,就要想好需不需要回溯,做隐式回溯的话,处理逻辑应该放在哪里。
本题是前序遍历。
class Solution:def binaryTreePaths(self, root: Optional[TreeNode]) -> List[str]:if root == None :return Noneself.res = []ss = ''self.find_allroad(root,ss)return self.resdef find_allroad(self,root,ss):if root == None :return if root.left == None and root.right == None :ss = ss + str(root.val)self.res.append(ss)self.find_allroad(root.left,ss + str(root.val) + '->')self.find_allroad(root.right,ss + str(root.val) + '->')
本题的迭代法,在编写感觉上,与递归稍有不同,关键点在于搞清楚,增加路径的逻辑应该放在哪里,以及遇到叶子节点的处理逻辑,是否需要加入最后一个节点的数值?迭代法因为在初始化时,要有根节点,所以在加入路径的逻辑上,与迭代法不同,要注意体会。
想不明白的时候,就自己模拟试试。
class Solution:def binaryTreePaths(self, root: Optional[TreeNode]) -> List[str]:if root == None :return Nonest = [root]path = [str(root.val)]res = []while st :node = st.pop()ss = path.pop()if node.left == None and node.right == None :res.append(ss)if node.right :st.append(node.right)path.append(ss+'->'+str(node.right.val))if node.left :st.append(node.left)path.append(ss+'->'+str(node.left.val))return res
迭代法,模拟前中后序就用栈,适合层序遍历就用队列。
左叶子之和
感觉自己写的这个代码,逻辑不是很清晰。但是代码随想录的解答也是这样写的,如果当前是左叶子,就覆盖之前计算的值(这个值其实就是0),但是 if 判断又不能放在递归函数前面,那样会将正确的值覆盖。
class Solution:def sumOfLeftLeaves(self, root: Optional[TreeNode]) -> int:if root == None :return 0left = self.sumOfLeftLeaves(root.left)right = self.sumOfLeftLeaves(root.right)if root.left != None and root.left.left == None and root.left.right == None :left = root.left.valreturn left + right
错误的 if 位置,错误的代码:
class Solution:def sumOfLeftLeaves(self, root: Optional[TreeNode]) -> int:if root == None :return 0if root.left != None and root.left.left == None and root.left.right == None :left = root.left.valleft = self.sumOfLeftLeaves(root.left)right = self.sumOfLeftLeaves(root.right)return left + right
迭代法:前序遍历,统计每一个左叶子就好了。
class Solution:def sumOfLeftLeaves(self, root: Optional[TreeNode]) -> int:if root == None :return 0st = [root]res = 0while st :node = st.pop()if node.left != None and node.left.left == None and node.left.right == None :res += node.left.valif node.left :st.append(node.left)if node.right :st.append(node.right)return res
树左下角的值
本题使用层序遍历,思路非常简单,是层序遍历的模板题,这里我使用递归。
递归,要使用前序遍历,这样才能优先左边搜。
class Solution:def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:self.maxdepth = 0# 如果depth初值给0的话,因为一开始会等于maxdepth,就要单独判断,二叉树只有一个# 根节点的情况了,如果给1的话,就不需要单独判断depth = 1self.value = 0self.find_left(root,depth)return self.valuedef find_left(self,root,depth):if root == None :returnif root.left == None and root.right == None :# 本题的关键就在于这一句,必须是严格大于if depth > self.maxdepth :self.maxdepth = depthself.value = root.valself.find_left(root.left,depth+1)self.find_left(root.right,depth+1)
路径总和
第一次自己尝试编写,代码随想录风格的,利用设置返回值,找到就返回的递归代码。
需要注意的还是那一点:理清处理逻辑,递归函数怎么写,需不需要回溯,需要回溯,想写成隐式的怎么写,显式的怎么写,在收获结果的时候,处理逻辑怎么写,终止条件怎么写。
class Solution:def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:if root == None :return False# 注意处理逻辑,一开始这里最后一个条件我写的是:targetSum == 0 ,一直错误# 后来才发现,我没有去处理最后一个节点!if root.left == None and root.right == None and targetSum == root.val :return Trueif self.hasPathSum(root.left,targetSum-root.val) :return Trueif self.hasPathSum(root.right,targetSum-root.val) :return Truereturn False
迭代法:
class Solution:def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:if root == None :return Falsest = [root]value = [targetSum]while st :node = st.pop()t = value.pop()if node.left == None and node.right == None and t == node.val :return Trueif node.left :st.append(node.left)value.append(t-node.val)if node.right :st.append(node.right)value.append(t-node.val)return False路径总和II
class Solution:def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:if root == None :return []self.res = []path = []self.find_all_road(root,path,targetSum)return self.resdef find_all_road(self,root,path,targetSum):if root == None :returnif root.left == None and root.right == None and targetSum == root.val :path.append(root.val)self.res.append(path.copy())path.pop()path.append(root.val)self.find_all_road(root.left,path,targetSum-root.val)self.find_all_road(root.right,path,targetSum-root.val)path.pop()
用迭代法记录所有路径是很繁琐的,这种题不适合迭代法,一定要体会其中区别!问“有没有?”,迭代法可以;“找出所有可能?”迭代法不行。
递归函数,什么时候需要返回值,什么时候不需要?
如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii)
如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (这种情况我们在236. 二叉树的最近公共祖先 (opens new window)中介绍)
如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(本题的情况)
前面两道,路径总和的题,可以在子节点判断后,再加一个判断做剪枝
if root == None :returnif root.left == None and root.right == None and targetSum == root.val :path.append(root.val)self.res.append(path.copy())path.pop()if root.left == None and root.right == None :return
但是一定要注意顺序,要放在判断当前叶子节点不符合要求之后。
前面两题,我写的和代码随想录写的细节有些不同,我是从空列表开始递归,卡哥是先让根节点入栈了,这一个差异,就导致代码编写风格差异一看上去还挺大。
中序后序建立二叉树,前序中序建立二叉树,这两题只要想清楚,区间的左右边界就可以了,过。
最大二叉树,同上一题,都是构造的题目
合并二叉树
class Solution:def mergeTrees(self, root1: Optional[TreeNode], root2: Optional[TreeNode]) -> Optional[TreeNode]:if root1 == None and root2 == None :return Noneelif root1 == None :return root2elif root2 == None :return root1else :root1.val += root2.valroot1.left = self.mergeTrees(root1.left,root2.left)root1.right = self.mergeTrees(root1.right,root2.right)return root1构造树,一般采用的是前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。
迭代法:代码随想录给的是用对队列,但是并不是层序遍历的模板!用栈作为容器一样可以!这里我是用的栈。
class Solution:def mergeTrees(self, root1: Optional[TreeNode], root2: Optional[TreeNode]) -> Optional[TreeNode]:if root1 == None :return root2if root2 == None :return root1head = root1st = [root1,root2]while st :# 因为用的是栈,后进先出,这里顺序要注意,是反的root2 = st.pop()root1 = st.pop()root1.val += root2.val# 在四个有效的判断中,顺序很重要,要先判定左右是否都不空# 因为当root有空时,会存在给root1的赋值操作,这时候再判断,本来一空一不空,# 现在变成都不空了,出现错误!if root1.left != None and root2.left != None :st.append(root1.left)st.append(root2.left)if root1.right != None and root2.right != None :st.append(root1.right)st.append(root2.right)if root1.left == None and root2.left != None :root1.left = root2.leftif root1.left != None and root2.left == None : # 可不写pass if root1.right == None and root2.right != None :root1.right = root2.rightif root1.right != None and root2.right == None : # 可不写pass# 还有,root1和root2的左孩子均为空,root1和root2的右孩子均为空# 这两种情况,也可以不写return head二叉搜索树中的搜索
class Solution:def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:if root == None :return Noneif root.val == val :return rootif root.val > val :res = self.searchBST(root.left,val)if res :return reselse :res = self.searchBST(root.right,val)if res :return resreturn None
精简版本:不管返回值是不是None , 直接返回就行!
class Solution:def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:if root == None :return Noneif root.val == val :return rootif root.val > val :return self.searchBST(root.left,val)else :return self.searchBST(root.right,val)
二叉搜索树,因为其结构特殊性的存在,不需要回溯操作,所以不需要栈或队列来模拟递归。直接循环!
class Solution:def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:if root == None :return Nonewhile root != None :if root.val == val :return rootif root.val > val :root = root.leftelse :root = root.rightreturn None
验证二叉搜索树(重要!重要!重要!因为我一直不会)
这道题我竟然还是不会!
现在能想到,避开陷阱,不是仅仅比较左右孩子就可以的!
但是,依然忘了迭代法怎么编写!
递归法就是先中序遍历得到数组,再遍历数组。
class Solution:def __init__(self):self.vec = []def traversal(self, root):if root is None:returnself.traversal(root.left)self.vec.append(root.val) # 将二叉搜索树转换为有序数组self.traversal(root.right)def isValidBST(self, root):self.vec = [] # 清空数组self.traversal(root)for i in range(1, len(self.vec)):# 注意要小于等于,搜索树里不能有相同元素if self.vec[i] <= self.vec[i - 1]:return Falsereturn True
这里用递归法的一个技巧在于,声明一个全局变量节点。
class Solution:def __init__(self):self.pre = None # 用来记录前一个节点def isValidBST(self, root):if root is None:return Trueleft = self.isValidBST(root.left)if self.pre is not None and self.pre.val >= root.val:return Falseself.pre = root # 记录前一个节点right = self.isValidBST(root.right)return left and right
迭代法:
class Solution:def isValidBST(self, root):stack = []cur = rootpre = None # 记录前一个节点while cur is not None or len(stack) > 0:if cur is not None:stack.append(cur)cur = cur.left # 左else:cur = stack.pop() # 中if pre is not None and cur.val <= pre.val:return Falsepre = cur # 保存前一个访问的结点cur = cur.right # 右return True
看到二叉搜索树就要想到中序遍历,中序遍历得到的数组是递增的。
二叉搜索树的最小绝对差
代码逻辑和上一题完全相同。
class Solution:def __init__(self):self.pre = Noneself.minabs = infdef getMinimumDifference(self, root: Optional[TreeNode]) -> int:if root == None :return 0self.getMinimumDifference(root.left)if self.pre != None :self.minabs = min(self.minabs,root.val-self.pre.val)self.pre = rootself.getMinimumDifference(root.right)return self.minabs
class Solution:def getMinimumDifference(self, root: Optional[TreeNode]) -> int:if root == None :return 0res = infpre = Nonecur = rootst = []while st or cur :if cur :st.append(cur)cur = cur.leftelse :cur = st.pop()if pre != None :res = min(res,cur.val-pre.val)pre = curcur = cur.rightreturn res二叉搜索树中的众数
怎么bug一直调不好了?这题有很多细节我没注意到,下面的是错误的代码
class Solution:def findMode(self, root: Optional[TreeNode]) -> List[int]:self.maxcount = 1self.res = []self.pre = Noneself.count = 1self.findall(root)return self.resdef findall(self,root):if root == None :return self.findall(root.left)if self.pre :if self.pre.val == root.val :self.count += 1else :count = 1if self.count > self.maxcount :self.res.clear()self.res.append(root.val)self.maxcount = self.countelif self.count == self.maxcount :self.res.append(root.val)self.pre = rootself.findall(root.right)上述代码的致命错误,大致如下:首先是初始化上的错误,两个计数器必须全部置0,另外,让根节点进去结果列表,这是毫无道理的!第二点就是没有处理好第一个节点(最左下的节点),当 pre 是 None 时,我们应该将 count 赋值为 1 ,这样最左下的节点就可能作为结果。第三点,对于当前节点是否是空节点的判断,只能决定,当前的 count 是多少,而结果处理逻辑,肯定是要放在 if 判断之外的,不然也同样会漏掉,最左下节点作为结果的情况。
正确代码:
class Solution:def findMode(self, root: Optional[TreeNode]) -> List[int]:self.maxcount = 0self.res = []self.pre = Noneself.count = 0self.findall(root)return self.resdef findall(self,root):if root == None :return self.findall(root.left)if self.pre :if self.pre.val == root.val :self.count += 1else :self.count = 1else :self.count = 1if self.count > self.maxcount :self.res.clear()self.res.append(root.val)self.maxcount = self.countelif self.count == self.maxcount :self.res.append(root.val)self.pre = rootself.findall(root.right)
迭代法,就是中序遍历,只要理清本题的,众数处理逻辑就好,和递归的逻辑是一样的
class Solution:def findMode(self, root: Optional[TreeNode]) -> List[int]:count = 0maxcount = 0pre = Nonecur = rootst = []res = []while st or cur :if cur :st.append(cur)cur = cur.leftelse :cur = st.pop()if pre :if pre.val == cur.val :count += 1else :count = 1else :count = 1pre = curif count > maxcount :res.clear()res.append(cur.val)maxcount = countelif count == maxcount :res.append(cur.val)cur = cur.rightreturn res
如果本题不是二叉搜索树,而是一般二叉树,就要利用字典了
from collections import defaultdictclass Solution:def searchBST(self, cur, freq_map):if cur is None:returnfreq_map[cur.val] += 1 # 统计元素频率self.searchBST(cur.left, freq_map)self.searchBST(cur.right, freq_map)def findMode(self, root):freq_map = defaultdict(int) # key:元素,value:出现频率result = []if root is None:return resultself.searchBST(root, freq_map)max_freq = max(freq_map.values())for key, freq in freq_map.items():if freq == max_freq:result.append(key)return result
二叉树的最近公共祖先
首先明确用后序遍历,其次要明白,为什么当左右只有一个有值时,返回这个值就可以了。
class Solution:def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':if root == None :return Noneif root == p or root == q :return rootleft = self.lowestCommonAncestor(root.left,p,q)right = self.lowestCommonAncestor(root.right,p,q)if left != None and right != None :return rootelif left != None and right == None :return leftelif left == None and right != None :return rightelse :return None


本题没有迭代法,本题的讲解写的很好,可以多读读。
最近公共祖先
二叉搜索树的最近公共祖先
又没写出来,错误代码如下。受上一题影响,总想在上一题的基础上稍作改动,但是发现,在二叉搜索树中,同时匹配两个值是不现实的,逻辑会非常混乱。
class Solution:def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':if root == None :return Noneif root == p or root == q :return rootif root.val > p.val and root.val > q.val:return self.lowestCommonAncestor(root.left,p,q)elif root.val < p.val and root.val < q.val:return self.lowestCommonAncestor(root.right,p,q)else :left =
这道题,因为有序树的存在,思路和上一题完全不一样了!本题的核心在于利用二叉搜索树的性质。需要理解的是,按照如下规则找到的节点,一定是最近的公共祖先,因为一旦向下进入左右孩子,必然会丢失掉 p q 中的一个。

class Solution:def traversal(self, cur, p, q):if cur is None:return cur# 中if cur.val > p.val and cur.val > q.val: # 左left = self.traversal(cur.left, p, q)if left is not None:return leftif cur.val < p.val and cur.val < q.val: # 右right = self.traversal(cur.right, p, q)if right is not None:return rightreturn curdef lowestCommonAncestor(self, root, p, q):return self.traversal(root, p, q)
既然本题已经无所谓遍历顺序,变成了一道寻找二叉搜索树的节点的题目,迭代法自然可行,且简便了。
class Solution:def lowestCommonAncestor(self, root, p, q):while root:if root.val > p.val and root.val > q.val:root = root.leftelif root.val < p.val and root.val < q.val:root = root.rightelse:return rootreturn None
二叉搜索树中的插入操作
本题要注意的是,一定要写递归函数返回值,利用返回值去修改二叉树,如果没有修改,返回值就是原本树的自身。
另外,本题要理解,明确只往空节点插入就可以了,不要想着更改树的结构。
class Solution:def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:root = self.insert(root,val)return rootdef insert(self,root,val):if root == None :node = TreeNode(val) return nodeif root.val > val :root.left = self.insert(root.left,val)else :root.right = self.insert(root.right,val)return root
其实不需要额外定义一个函数。
class Solution:def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:if root == None :node = TreeNode(val) return nodeif root.val > val :root.left = self.insertIntoBST(root.left,val)else :root.right = self.insertIntoBST(root.right,val)return root
删除二叉搜索树中的节点
这道题写下来还是蛮难的,而且我感觉我现在的逻辑也没有很清晰,加了不少 if 判断。我主要的思路就是,删除当前节点后,直接用当前节点的左孩子顶上来,然后把当前节点的右子树,加到左孩子的最右。这样就满足二叉搜索树的性质。但是还要处理很多特殊情况,这也是我这么多 if 的由来,比如我取了当前节点的左右孩子,那么自然就要考虑,如果是空怎么办?都是空?一个是空?情况都要考虑清楚。
只要取了节点的左右孩子,还想取它的value,就要想到,判断是否是None。看看代码随想录的解答吧
我的代码:目标删除节点的右孩子,往目标删除节点的左孩子的最右去接
class Solution:def deleteNode(self, root: Optional[TreeNode], key: int) -> Optional[TreeNode]:if root == None :return Noneif root.val < key :root.right = self.deleteNode(root.right,key)elif root.val > key :root.left = self.deleteNode(root.left,key)else :node = root.left pre = root.rightif node == None and pre == None: # 左右均为空return Noneelif node == None : # 左为空return pre# 这里我觉得是,我是让右孩子向右接,所以 pre 为空,无所谓else :while node.right :node = node.rightnode.right = prereturn root.leftreturn root
删除二叉搜索树中的节点

卡哥给出的,普通树的删除方法,以及迭代法,都先不做学习了,先掌握最基本的递归法。
根据卡哥给的思路,对上面自己的代码进行了小修改,思路是:目标删除节点的左孩子,往目标删除节点的右孩子的最左去接。
class Solution:def deleteNode(self, root: Optional[TreeNode], key: int) -> Optional[TreeNode]:if root == None :return Noneif root.val < key :root.right = self.deleteNode(root.right,key)elif root.val > key :root.left = self.deleteNode(root.left,key)else :node = root.left pre = root.rightif node == None and pre == None: # 左右都为空return Noneelif node == None : # 左为空return preelif pre == None : # 右为空return nodeelse :while pre.left :pre = pre.left pre.left = nodereturn root.rightreturn root本题对于第五步,删除拼接的情况,本来就有两种选择,上面我都提到了,左接右,右接左。
代码随想录的代码:
class Solution:def deleteNode(self, root, key):if root is None:return rootif root.val == key:if root.left is None and root.right is None:return Noneelif root.left is None:return root.rightelif root.right is None:return root.leftelse:cur = root.rightwhile cur.left is not None:cur = cur.leftcur.left = root.leftreturn root.rightif root.val > key:root.left = self.deleteNode(root.left, key)if root.val < key:root.right = self.deleteNode(root.right, key)return root
修剪二叉搜索树
不会,理不清处理逻辑。
自己写的错误代码:
class Solution:def trimBST(self, root: Optional[TreeNode], low: int, high: int) -> Optional[TreeNode]:if root == None :return Noneif root.val >= low and root.val <= high :root.left = self.trimBST(root.left,low,high)root.right = self.trimBST(root.right,low,high)return root elif root.val < low :head = root.rightif head == None :return Nonehead.left = self.trimBST(head.left,low,high)head.right = self.trimBST(head.right,low,high)return headelif root.val > high :head = root.leftif head == None :return Nonehead.left = self.trimBST(head.left,low,high)head.right = self.trimBST(head.right,low,high)return head
看看代码随想录的解答。这是一个思维转变的问题,好好理解。
修剪二叉搜索树
class Solution:def trimBST(self, root: TreeNode, low: int, high: int) -> TreeNode:if root is None:return Noneif root.val < low:# 寻找符合区间 [low, high] 的节点return self.trimBST(root.right, low, high)if root.val > high:# 寻找符合区间 [low, high] 的节点return self.trimBST(root.left, low, high)root.left = self.trimBST(root.left, low, high) # root.left 接入符合条件的左孩子root.right = self.trimBST(root.right, low, high) # root.right 接入符合条件的右孩子return root这道题非常非常重要。迭代法先不做学习了、
将有序数组转换为二叉搜索树
取数组中间数值,递归构造即可。
把二叉搜索树转换为累加树
之前做过类似的题。
class Solution:def __init__(self):self.last = Nonedef convertBST(self, root: Optional[TreeNode]) -> Optional[TreeNode]:if root == None :return Noneroot.right = self.convertBST(root.right)if self.last :root.val += self.last.valself.last = rootroot.left = self.convertBST(root.left)return root
迭代法:
class Solution:def convertBST(self, root: Optional[TreeNode]) -> Optional[TreeNode]:if root == None :return Nonest = []cur = rootlast = Nonewhile st or cur :if cur :st.append(cur)cur = cur.rightelse :cur = st.pop()if last :cur.val += last.vallast = curcur = cur.leftreturn root
相关文章:
代码随想录算法训练营第二十二天 | 读PDF复习环节2
读PDF复习环节2 本博客的内容只是做一个大概的记录,整个PDF看下来,内容上是不如代码随想录网站上的文章全面的,并且PDF中有些地方的描述,是很让我疑惑的,在困扰我很久后,无意间发现,其网站上的讲…...

TimescaleDB时序数据库初识
注:本文翻译自https://legacy-docs.timescale.com/v1.7/introduction TimescaleDB是一个开源时间序列数据库,针对快速摄取和复杂查询进行了优化。它说的是“完整的SQL”,因此像传统的关系数据库一样易于使用,并且以以前为NoSQL数…...

Numpy-聚合函数
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。 函数名说明np.sum()求和np.prod()所有元素相乘np.mean()平均值np.std()标准差np.var()方差np.median()中位数np.power()幂运算np.sqrt()开方np.min()最小…...
企业博客资讯如何高效运营起来?
运营一个高效的企业博客资讯需要综合考虑多个因素,包括内容策划、发布频率、优化推广、互动反馈等。下面将从这些方面介绍如何高效运营企业博客资讯。 如何高效运营企业博客资讯 内容策划 首先,需要制定一个明确的内容策略。确定博客的定位和目标受众…...

跟我学c++中级篇——模板的继承
一、继承 面向对象编程有三个特点:封装、继承和多态。其中继承在其中起着承上启下的作用。一般来说,继承现在和组合的应用比较难区分,出于各种场景和目的,往往各有千秋。但目前主流的观点,一般是如果没有特殊情况&…...
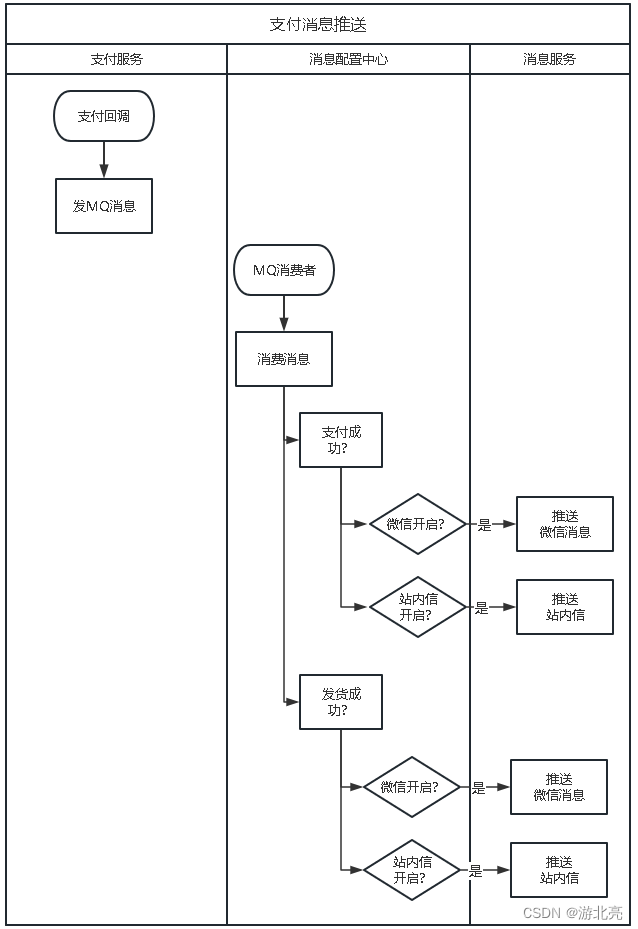
需求分析案例:消息配置中心
本文介绍了一个很常见的消息推送需求,在系统需要短信、微信、邮件之类的消息推送时,边界如何划分和如何设计技术方案。 1、需求 一个系统,一般会区分多个业务模块,并拆分成不同的业务系统,例如一个商城的架构如下&am…...

自动化测试——环境
一、搭建环境 1、安装Slenium pip install selenium 2、安装浏览器驱动-》查询浏览器版本-》下载对应版本驱动-》在path路径中配置(浏览器更新需要重新下载) pip install webdriver -helper(自动化)python3.9以上 pip install 安…...

短视频矩阵营销系统技术开发者开发笔记分享
一、开发短视频seo抖音矩阵系统需要遵循以下步骤: 1. 确定系统需求:根据客户的需求,确定系统的功能和特点,例如用户注册登录、视频上传、视频浏览、评论点赞等。 2. 设计系统架构:根据系统需求,设计系统的…...

vue2和vue3引用ueditor的区别
官方文档入口 UEditor Docs vue2使用方式 UE.vue组件 <template><div><script id"editor" type"text/plain"></script><Upload v-if"isupload" :config"{total:9}" :isupload"isupload" ret…...
【每日运维】RockyLinux8非容器化安装Mysql、Redis、RabitMQ单机环境
系统版本:RockyLinux 8.6 安装方式:非容器化单机部署 安装版本:mysql 8.0.32 redis 6.2.11 rabbitmq 3.11.11 elasticsearch 6.7.1 前置条件:时间同步、关闭selinux、主机名、主机解析host 环境说明:PC电脑VMware Work…...
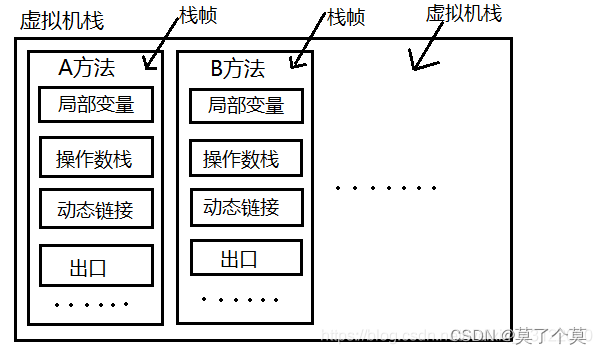
第一次后端复习整理(JVM、Redis、反射)
1. JVM 文章仅为自身笔记 详情查看一篇文章掌握整个JVM,JVM超详细解析!!! 1.1 什么是JVM jvm是Java虚拟机 1.2 Java文件的编译过程 程序员编写代码形成.java文件经过javac编译成.class文件再通过JVM的类加载器进入运行时数据…...
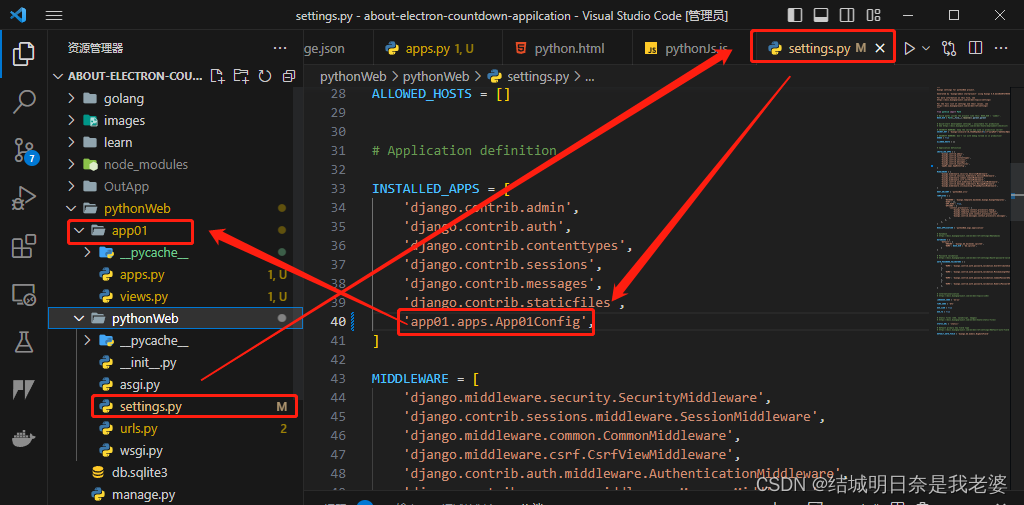
python的web学习(一)-初识django
文章目录 软件创建项目默认项目文件说明App的概念(应用)apps.py编写URL和视图函数对应关系【urls.py】编写视图函数【views.py】启动服务 软件 python下载 django下载 创建项目 django-admin startproject 文件名默认项目文件说明 项目名 manage.py(项目管理,启…...
JavaWeb+jsp+Tomcat的叮当书城项目
点击以下链接获取源码: https://download.csdn.net/download/qq_64505944/88123111?spm1001.2014.3001.5503 技术:ssm jsp JDK1.8 MySQL5.7 Tomcat8.3 源码数据库课程设计 功能:管理员与普通用户和超级管理员三个角色,管理员可…...
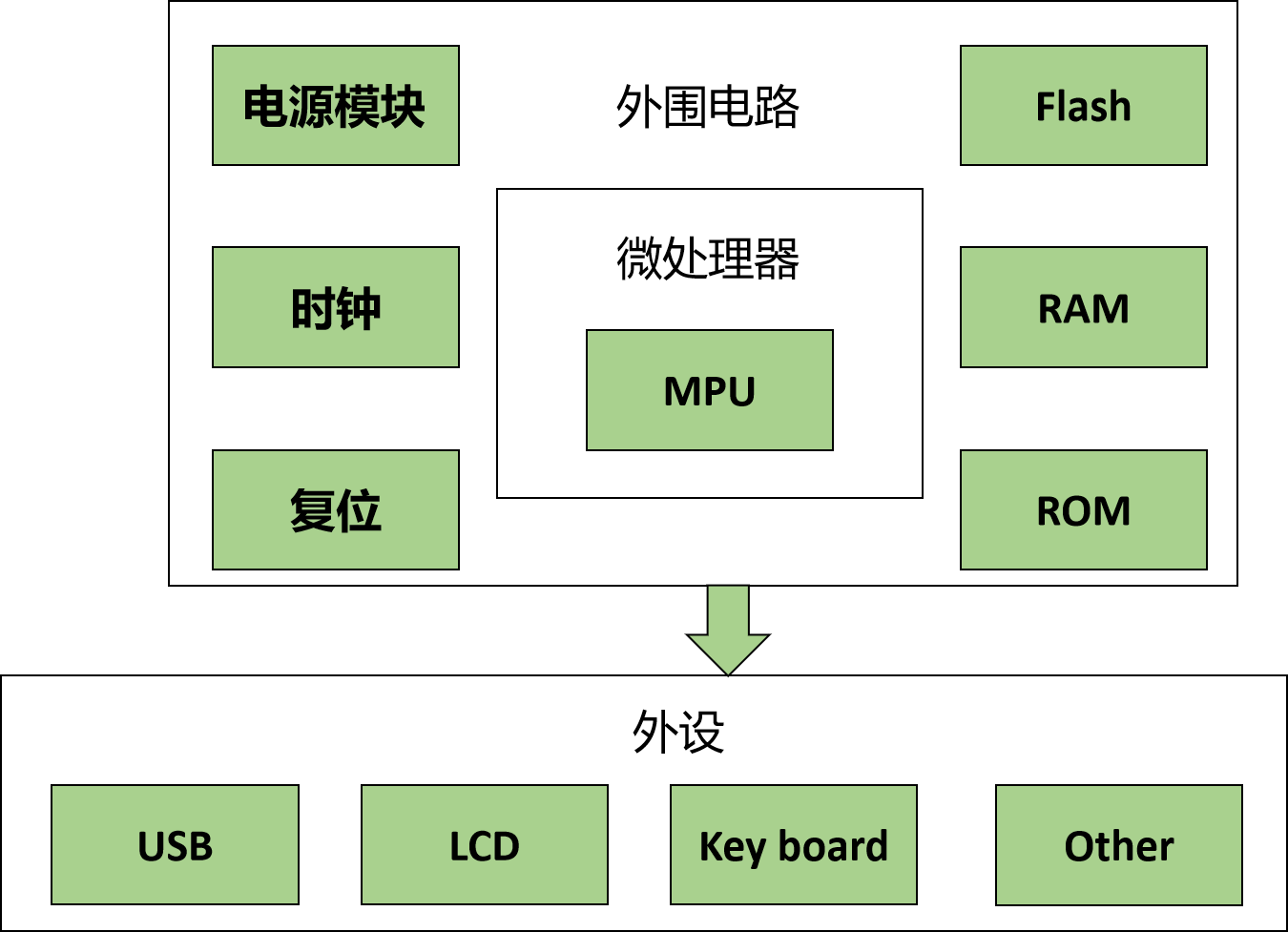
【嵌入式Linux系统开发】——系统移植概述
目录 🍉🍉一、什么是嵌入式系统 🍉🍉二、嵌入式系统操作 🍉🍉三、嵌入式Linux的特点 🍉🍉四、嵌入式系统的组成 1、硬件和软件 2、硬件层 3、中间层 4、软件层 5、 功能层与执…...

升讯威在线客服系统是如何实现对 IE8 完全完美支持的(怎样从 WebSocket 降级到 Http)【干货】
简介 升讯威在线客服与营销系统是基于 .net core / WPF 开发的一款在线客服软件,宗旨是: 开放、开源、共享。努力打造 .net 社区的一款优秀开源产品。 完整私有化包下载地址 💾 https://kf.shengxunwei.com/freesite.zip 当前版本信息 发布…...
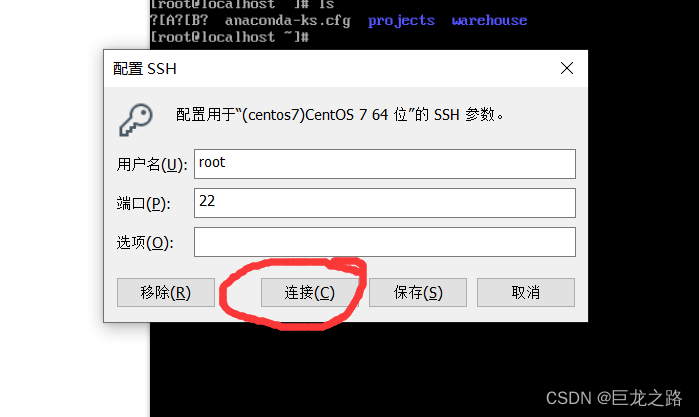
用VMware给运行在VMware上的CentOS7生成一个以SSH方式连接VMware上的CentOS7的运行在Windows上的命令行窗口
2023年7月27日,周四早上 目录 一个发现生成方法如果上面的方法连接失败,就采取这个方法 一个发现 今天早上无意间发现VMware可以生成一个以SSH方式连接着CentOS7的Windows命令行窗口, 这样做可以带来一定的便利性 : 方便复制、…...

C语言基础-3
1、函数 函数是C语言代码的基本组成部分,它是一个小的模块,整个程序由很多个功能独立的模块(函数)组成。这就是程序设计的基本分化方法。 main:C语言中所谓的主函数,主函数就是一种特别的函数。特别之处在于…...
 | 命名规范)
Python 编程规范进阶(1) | 命名规范
养成良好的开发、编程习惯 跟着google开源项目走 https://github.com/google/styleguide 近期Target: 命名规范; Pythonic 积累 按照需求写需要的API; 写前先动脑子,比如画流程图,测试接口; Google 推荐的P…...
算法----二叉搜索树中第K小的元素
题目 二叉搜索树中第K小的元素 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。 示例 1: 输入:root [3,1,4,null,2], k 1 输出ÿ…...

阿里Java开发手册~安全规约
1. 【强制】隶属于用户个人的页面或者功能必须进行权限控制校验。 说明: 防止没有做水平权限校验就可随意访问、修改、删除别人的数据,比如查看他人的私信 内容、修改他人的订单。 2. 【强制】用户敏感数据禁止直接展示,必须对展示数据进…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...