将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo

本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。
在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器。
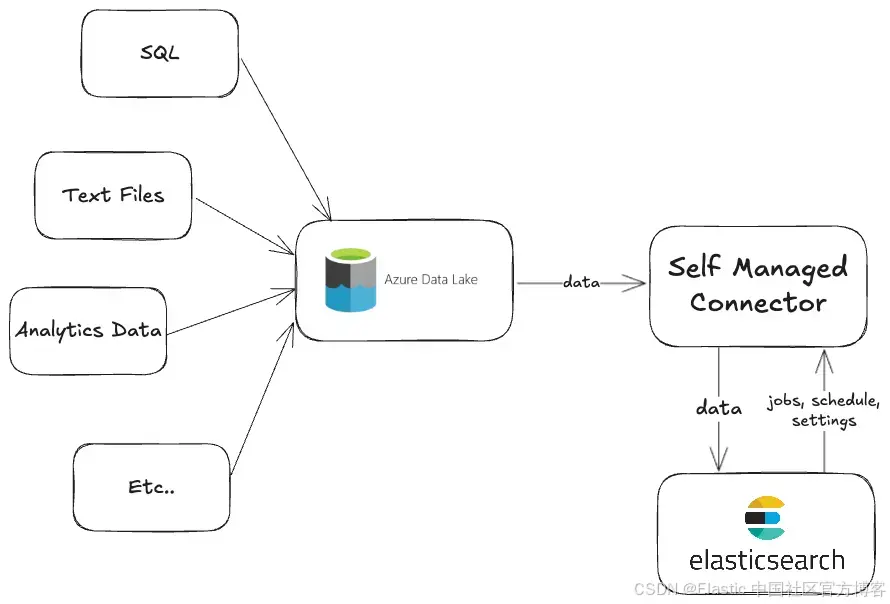
我们已经上传了一些 OneLake 文档并将其索引到 Elasticsearch 中以供搜索。但是,这仅适用于一次性上传。如果我们想要同步数据,那么我们需要开发一个更复杂的系统。
幸运的是,Elastic 有一个连接器框架可用于开发满足我们需求的自定义连接器:
我们现在将根据本文制作一个 OneLake 连接器:如何为 Elasticsearch 创建自定义连接器。
步骤
- 连接器引导
- 实现 BaseDataSource 类
- 身份验证
- 运行连接器
- 配置计划
连接器引导
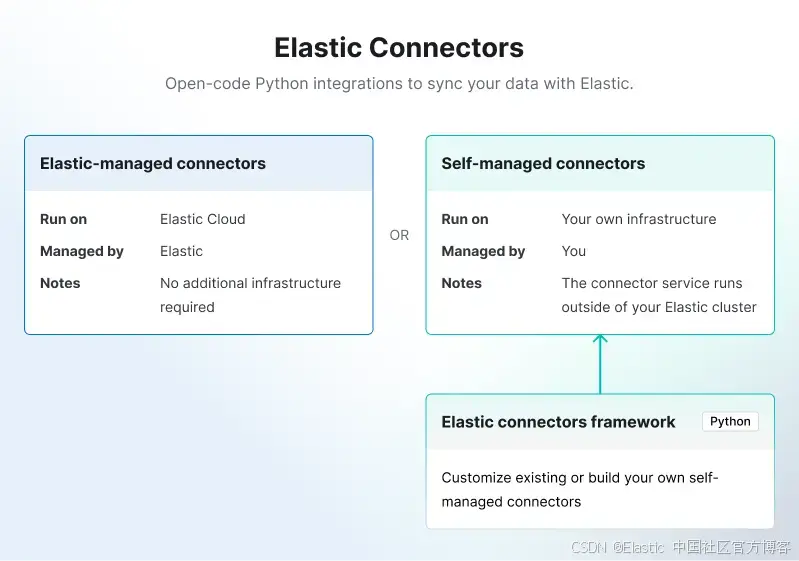
背景信息:Elastic 连接器分为两种类型:
- Elastic 托管连接器:完全由 Elastic Cloud 托管和运行。
- 自托管连接器:由用户自行托管,必须部署在你的基础设施中。
自定义连接器属于 “连接器客户端” 类别,因此我们需要下载并部署连接器框架。
首先,克隆连接器的代码库:
git clone https://github.com/elastic/connectors现在在 requirements/framework.txt 文件末尾添加你将使用的依赖项。在本例中:
azure-identity==1.19.0
azure-storage-file-datalake==12.17.0这样,存储库就完成了,我们可以开始编码了。
实现 BaseDataSource 类
你可以在此存储库中找到完整的工作代码。
我们将介绍 onelake.py 文件中的核心部分。
在导入和类声明之后,我们必须定义将捕获配置参数的 __init__ 方法。
"""OneLake connector to retrieve data from datalakes"""from functools import partialfrom azure.identity import ClientSecretCredential
from azure.storage.filedatalake import DataLakeServiceClientfrom connectors.source import BaseDataSourceACCOUNT_NAME = "onelake"class OneLakeDataSource(BaseDataSource):"""OneLake"""name = "OneLake"service_type = "onelake"incremental_sync_enabled = True# Here we can enter the data that we'll later need to connect our connector to OneLake.def __init__(self, configuration):"""Set up the connection to the azure base clientArgs:configuration (DataSourceConfiguration): Object of DataSourceConfiguration class."""super().__init__(configuration=configuration)self.tenant_id = self.configuration["tenant_id"]self.client_id = self.configuration["client_id"]self.client_secret = self.configuration["client_secret"]self.workspace_name = self.configuration["workspace_name"]self.data_path = self.configuration["data_path"]然后,你可以配置 UI 将显示的表单,使用返回配置字典的 get_default_configuration 方法填充这些参数。
# Method to generate the Enterprise Search UI fields for the variables we need to connect to OneLake.@classmethoddef get_default_configuration(cls):"""Get the default configuration for OneLakeReturns:dictionary: Default configuration"""return {"tenant_id": {"label": "OneLake tenant id","order": 1,"type": "str",},"client_id": {"label": "OneLake client id","order": 2,"type": "str",},"client_secret": {"label": "OneLake client secret","order": 3,"type": "str","sensitive": True, # To hide sensitive data like passwords or secrets},"workspace_name": {"label": "OneLake workspace name","order": 4,"type": "str",},"data_path": {"label": "OneLake data path","tooltip": "Path in format <DataLake>.Lakehouse/files/<Folder path>","order": 5,"type": "str",},"account_name": {"tooltip": "In the most cases is 'onelake'","default_value": ACCOUNT_NAME,"label": "Account name","order": 6,"type": "str",},}然后我们配置下载方法,并从 OneLake 文档中提取内容。
async def download_file(self, file_client):"""Download file from OneLakeArgs:file_client (obj): File clientReturns:generator: File stream"""try:download = file_client.download_file()stream = download.chunks()for chunk in stream:yield chunkexcept Exception as e:self._logger.error(f"Error while downloading file: {e}")raiseasync def get_content(self, file_name, doit=None, timestamp=None):"""Obtains the file content for the specified file in `file_name`.Args:file_name (obj): The file name to process to obtain the content.timestamp (timestamp, optional): Timestamp of blob last modified. Defaults to None.doit (boolean, optional): Boolean value for whether to get content or not. Defaults to None.Returns:str: Content of the file or None if not applicable."""if not doit:returnfile_client = await self._get_file_client(file_name)file_properties = file_client.get_file_properties()file_extension = self.get_file_extension(file_name)doc = {"_id": f"{file_client.file_system_name}_{file_properties.name}", # workspacename_data_path"name": file_properties.name.split("/")[-1],"_timestamp": file_properties.last_modified,"created_at": file_properties.creation_time,}can_be_downloaded = self.can_file_be_downloaded(file_extension=file_extension,filename=file_properties.name,file_size=file_properties.size,)if not can_be_downloaded:return docextracted_doc = await self.download_and_extract_file(doc=doc,source_filename=file_properties.name.split("/")[-1],file_extension=file_extension,download_func=partial(self.download_file, file_client),)return extracted_doc if extracted_doc is not None else doc为了让我们的连接器对框架可见,我们需要在 connectors/config.py 文件中声明它。为此,我们将以下代码添加到源中:
"sources": {..."onelake": "connectors.sources.onelake:OneLakeDataSource",...}身份验证
在测试连接器之前,我们需要获取 client_id, tenant_id 和 client_secret,我们将使用它们从连接器访问工作区。
我们将使用 service principals 作为身份验证方法。
Azure service principal 是为与应用程序、托管服务和自动化工具一起使用以访问 Azure 资源而创建的身份。
步骤如下:
- 创建应用程序并收集 client_id、tenant_id 和 client_secret
- 在工作区中启用 service principal
- 将 service principal 添加到工作区
你可以逐步遵循本教程。
准备好了吗?现在是测试连接器的时候了!
运行连接器
连接器准备好后,我们现在可以连接到我们的 Elasticsearch 实例。
转到: Search > Content > Connectors > New connector 并选择 Customized Connector
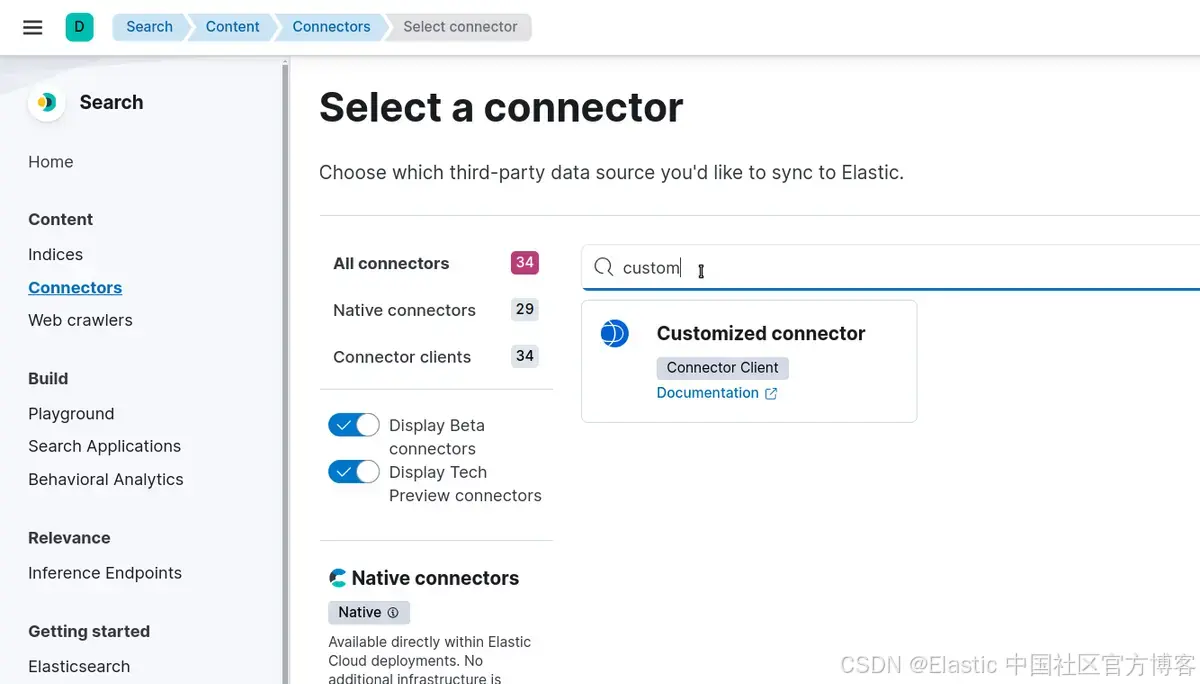
选择要创建的名称,然后选择 “Create and attach an index” 以创建与连接器同名的新索引。
你现在可以使用 Docker 运行它或从源代码运行它。在此示例中,我们将使用 “Run from source”。
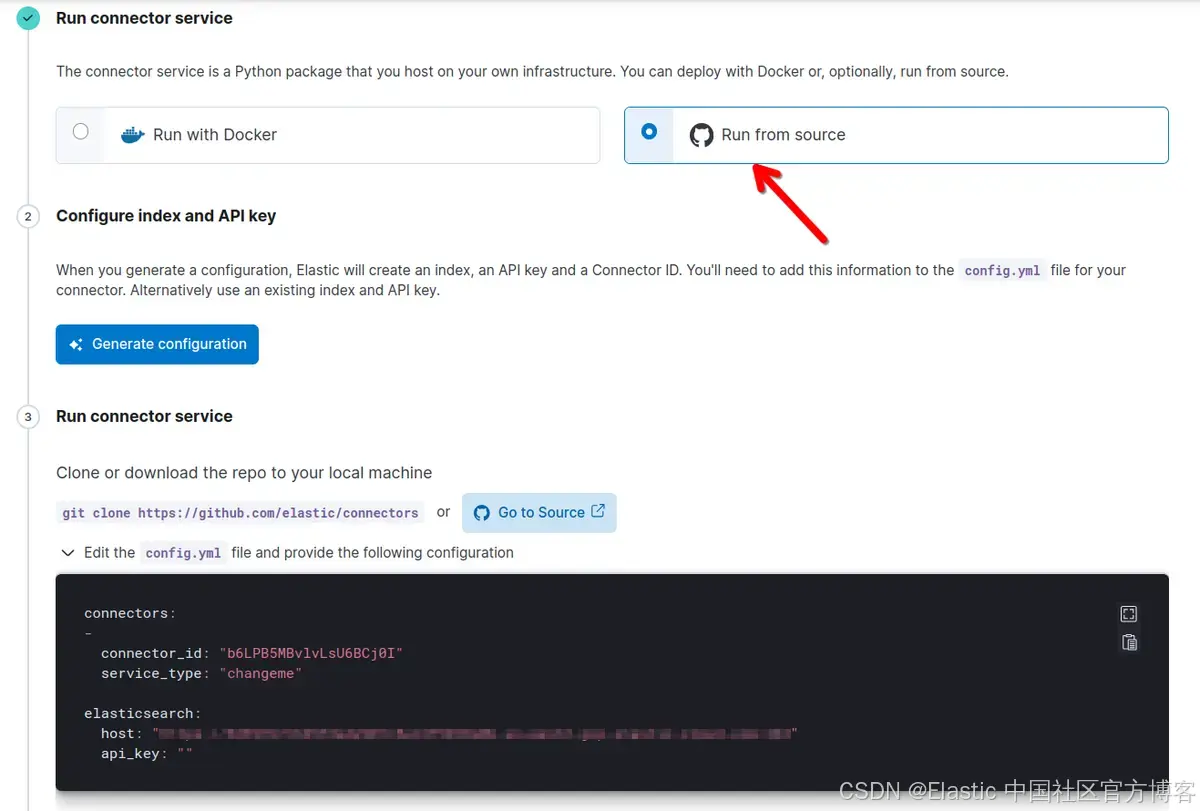
单击 “Generate Configuration”,然后将框中的内容粘贴到项目根目录中的 config.yml 文件中。在字段 service_type 上,你必须匹配 Connectors/config.py 中的连接器名称。在本例中,将 changeme 替换为 onelake。
现在,你可以使用以下命令运行连接器:
make install
make run如果连接器正确初始化,你应该在控制台中看到如下消息:

注意:如果出现兼容性错误,请检查你的连接器/版本文件并与你的 Elasticsearch 集群版本进行比较:与 Elasticsearch 的版本兼容性。我们建议保持连接器版本和 Elasticsearch 版本同步。在本文中,我们使用 Elasticsearch 和连接器版本 8.15。
如果一切顺利,我们的本地连接器将与我们的 Elasticsearch 集群通信,我们将能够使用我们的 OneLake 凭据对其进行配置:
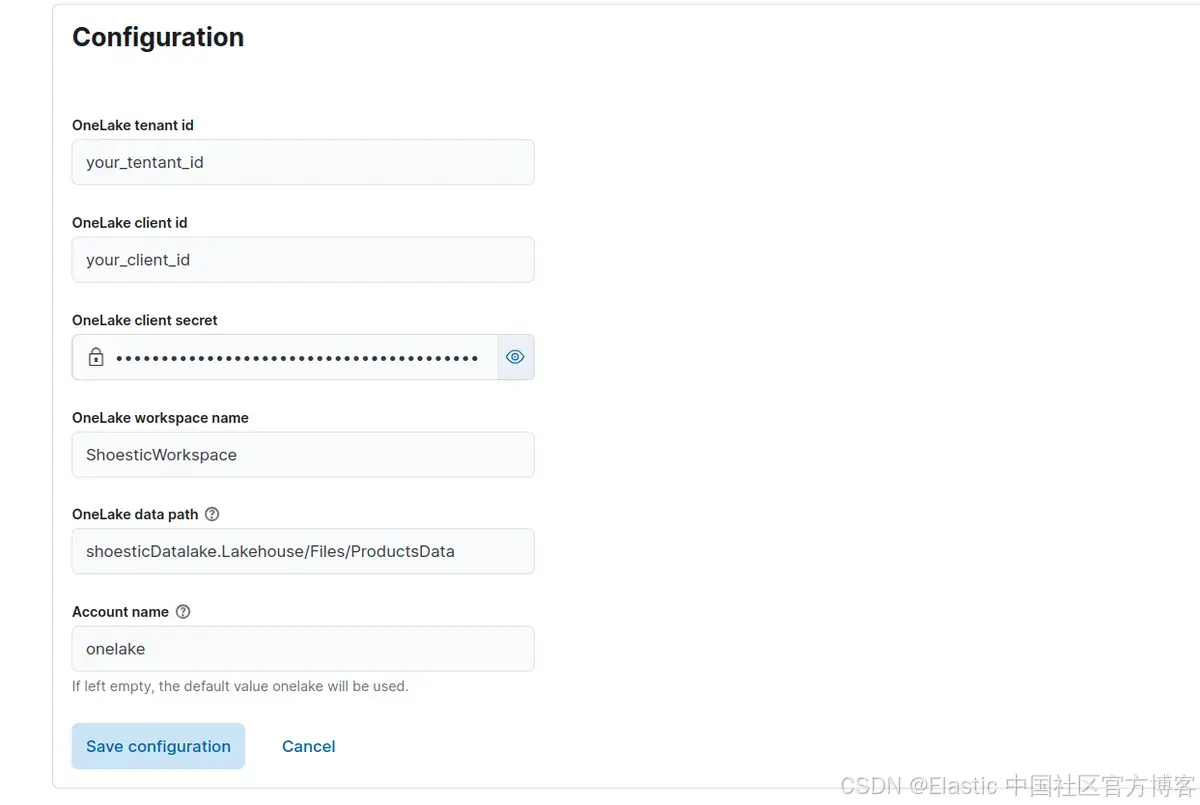
我们现在将索引来自 OneLake 的文档。为此,请单击 Sync > Full Content,运行完整内容同步:
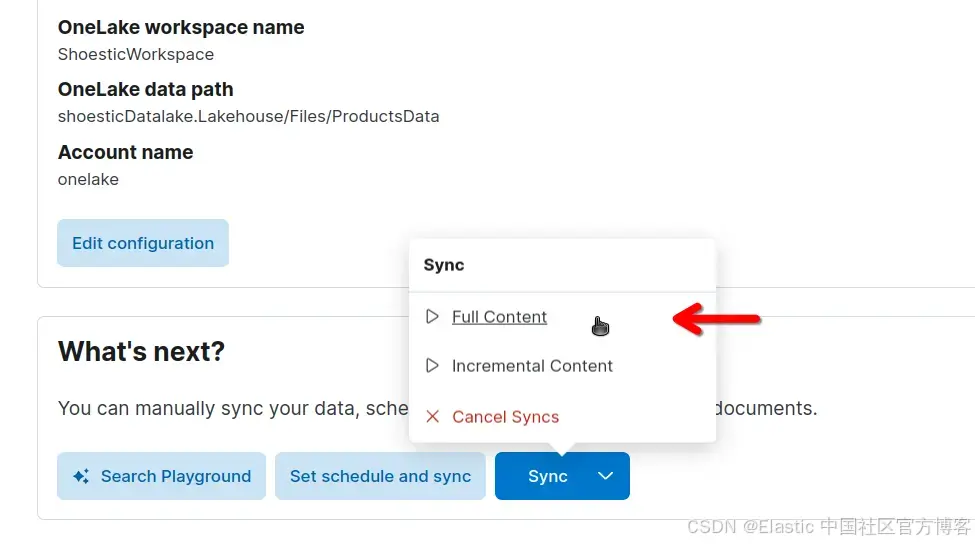
同步完成后,你应该在控制台中看到以下内容:

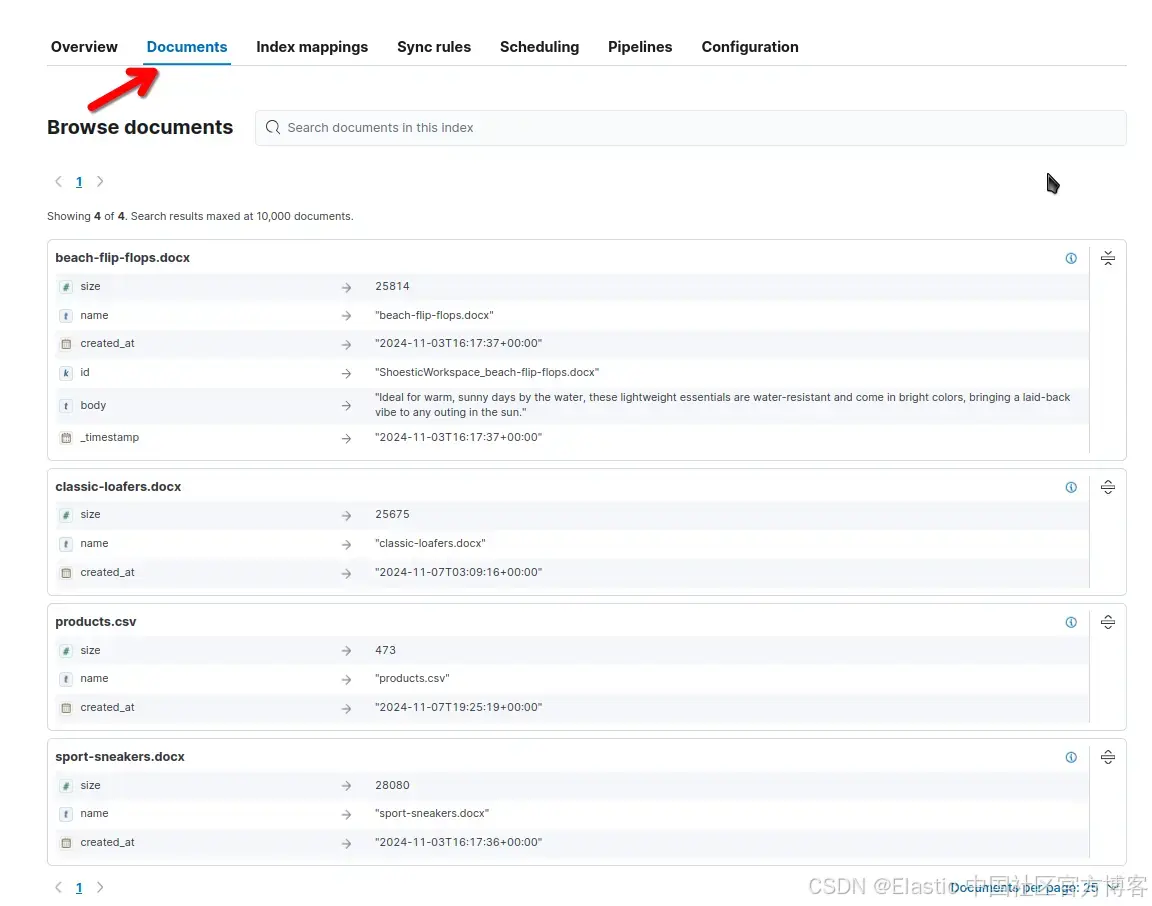
在企业搜索 UI 中,你可以单击 “Documents” 来查看已索引的文档:
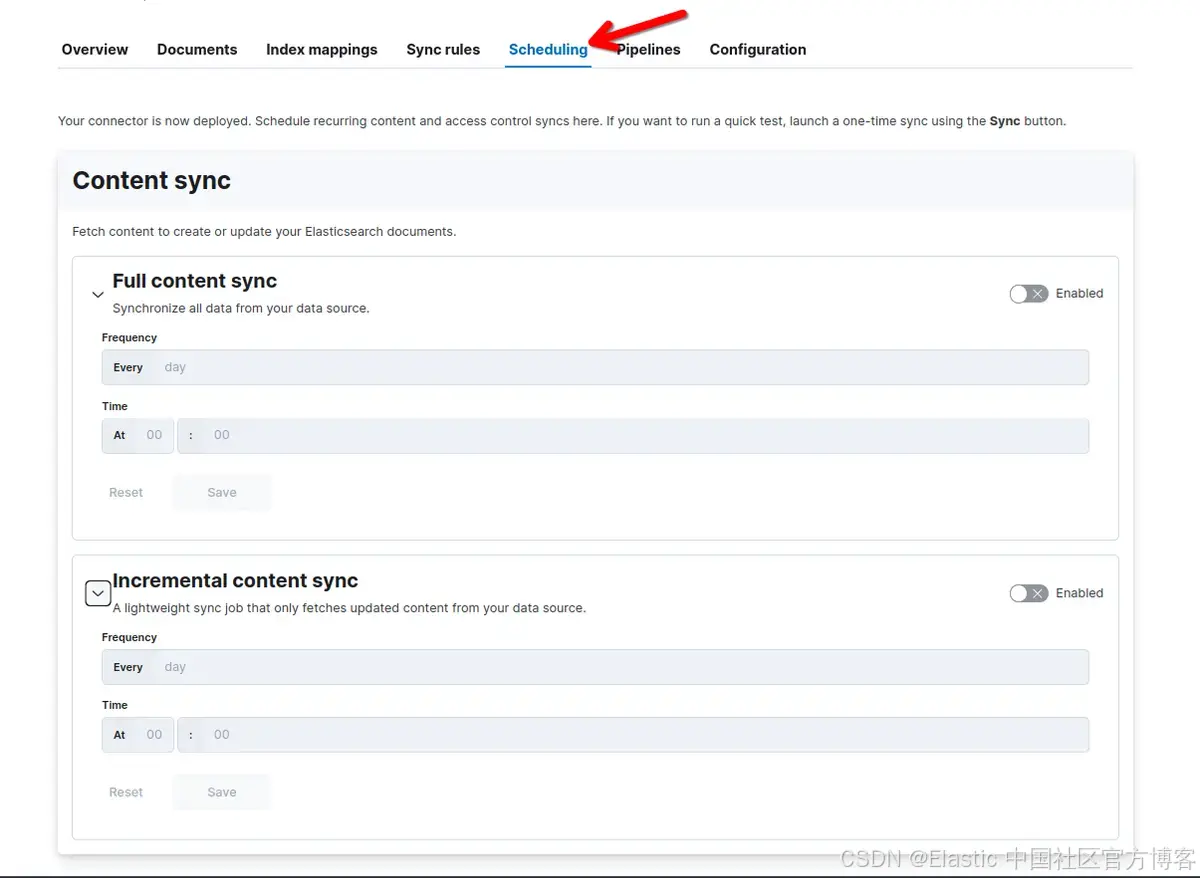
配置计划
你可以根据需要使用 UI 安排定期内容同步,以使索引保持更新并与 OneLake 同步。
要配置计划同步,请转到 “Search > Content > Connectors,然后选择你的连接器。然后单击 “scheduling”:
或者,你可以使用允许 CRON 表达式的更新连接器调度 API。
结论
在第二部分中,我们通过使用 Elastic 连接器框架并开发我们自己的 OneLake 连接器来轻松与我们的 Elastic Cloud 实例通信,将我们的配置更进一步。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训何时开始!
Elasticsearch 包含新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Indexing OneLake data into Elasticsearch - Part II - Elasticsearch Labs
相关文章:
将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo 本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。 在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器…...

Android Studio:视图绑定的岁月变迁(2/100)
一、博文导读 本文是基于Android Studio真实项目,通过解析源码了解真实应用场景,写文的视角和读者是同步的,想到看到写到,没有上帝视角。 前期回顾,本文是第二期。 private Unbinder mUnbinder; 只是声明了一个 接口…...

私有包上传maven私有仓库nexus-2.9.2
一、上传 二、获取相应文件 三、最后修改自己的pom文件...

Qt监控系统辅屏预览/可以同时打开4个屏幕预览/支持5x64通道预览/onvif和rtsp接入/性能好
一、前言说明 在监控系统中,一般主界面肯定带了多个通道比如16/64通道的画面预览,随着电脑性能的增强和多屏幕的发展,再加上现在监控摄像头数量的增加,越来越多的用户希望在不同的屏幕预览不同的实时画面,一个办法是打…...

Vue.js 路由懒加载
Vue.js 路由懒加载 在 Vue.js 开发中,随着应用规模的扩大,打包后的 JavaScript 文件可能会变得相当庞大,影响页面的加载速度和性能。为了解决这个问题,Vue Router 提供了路由懒加载功能,可以将不同路由对应的组件分割…...

HBase的原理
一、什么是HBase HBase是一个分布式,版本化,面向列的数据库,依赖Hadoop和Zookeeper (1)HBase的优点 提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统 (2) HBase 表的特性 Region包含多行 列族包含多…...

Python “字典” 实战案例:5个项目开发实例
Python “字典” 实战案例:5个项目开发实例 内容摘要 本文包括 5 个使用 Python 字典的综合应用实例。具体是: 电影推荐系统配置文件解析器选票统计与排序电话黄页管理系统缓存系统(LRU 缓存) 以上每一个实例均有完整的程序代…...
达梦数据库基本操作(持续更新))
(DM)达梦数据库基本操作(持续更新)
1、连接达梦数据库 ./disql 用户明/"密码"IP端口或者域名 2、进入某个模式(数据库,因达梦数据库没有库的概念,只有模式,可以将模式等同于库) set schema 库名; 3、查表结构; SELECT COLUMN_NAM…...

LabVIEW心音心电同步采集与实时播放
开发了一个基于LabVIEW开发的心音心电同步采集与实时播放系统。该系统可以同时采集心音和心电信号,并通过LabVIEW的高级功能实现这些信号的实时显示和播放。系统提升心脏疾病诊断的准确性和效率,使医生能够在观察心音图的同时进行听诊。 项目背景 心…...

[创业之路-268]:《创业讨论会》- 个人思维 -> 团队思维 -> 管理思维 -> 领导者思维 -> 老板思维->企业家思维->政治家思维的演进路径
目录 一、演进路径 二、老板与企业家的区别 一、演进路径 这个演进路径描述了一个个体从个人思考模式逐渐发展到领导和管理整个组织或企业的思考模式的过程。下面是对每个阶段的简要解释: 这个演进路径并不是线性的,也不是每个人都会经历所有阶段。然…...
)
单片机基础模块学习——数码管(二)
一、数码管模块代码 这部分包括将数码管想要显示的字符转换成对应段码的函数,另外还包括数码管显示函数 值得注意的是对于小数点和不显示部分的处理方式 由于小数点没有单独占一位,所以这里用到了两个变量i,j用于跳过小数点导致的占据其他字符显示在数…...

深入解析ncnn::Net类——高效部署神经网络的核心组件
最近在学习ncnn推理框架,下面整理了ncnn::Net 的使用方法。 在移动端和嵌入式设备上进行高效的神经网络推理,要求框架具备轻量化、高性能以及灵活的扩展能力。作为腾讯开源的高性能神经网络推理框架,ncnn在这些方面表现出色。而在ncnn的核心…...
前端【8】HTML+CSS+javascript实战项目----实现一个简单的待办事项列表 (To-Do List)
目录 一、功能需求 二、 HTML 三、CSS 四、js 1、绑定事件与初始设置 2.、绑定事项 (1)添加操作: (2)完成操作 (3)删除操作 (4)修改操作 3、完整js代码 总结…...

程序诗篇里的灵动笔触:指针绘就数据的梦幻蓝图<1>
大家好啊,我是小象٩(๑ω๑)۶ 我的博客:Xiao Xiangζั͡ޓއއ 很高兴见到大家,希望能够和大家一起交流学习,共同进步。 这一节我们来学习指针的相关知识,学习内存和地址,指针变量和地址,包…...

向量和矩阵算法笔记
向量和矩阵算法笔记 Ps:因为本人实力有限,有一部分可能不太详细,若有补充评论区回复,QWQ 向量 向量的定义 首先,因为我刚刚学到高中的向量,对向量的看法呢就是一条有长度和方向的线,不过这在数学上的定义其实是不对,甚至跟我看的差别其实有点大,真正的定义就是数域…...

Nginx配置中的常见错误:SSL参数解析
摘要 在高版本的Nginx中,用户可能会遇到unknown directive “ssl”的错误提示。这是因为旧版本中使用的ssl on参数已被弃用。正确的配置SSL加密的方法是在listen指令中添加ssl参数。这一改动简化了配置流程,提高了安全性。用户应更新配置文件以适应新版本…...
積分方程與簡單的泛函分析6.有連續對稱核的弗雷德霍姆積分算子的特徵值
1)def弗雷德霍姆算子的核函數定義 定义: 设 是定义在矩形区域 上的函数。 若满足以下条件,则称 为弗雷德霍姆算子的核函数: 实值性: 是实值函数,即对于任意的 ,。 这是因为在许多实际的物理和数学问题中,所涉及的量往往是实数值,例如在积分方程描述的物理模型中,…...

AI编程工具使用技巧:在Visual Studio Code中高效利用阿里云通义灵码
AI编程工具使用技巧:在Visual Studio Code中高效利用阿里云通义灵码 前言一、通义灵码介绍1.1 通义灵码简介1.2 主要功能1.3 版本选择1.4 支持环境 二、Visual Studio Code介绍1.1 VS Code简介1.2 主要特点 三、安装VsCode3.1下载VsCode3.2.安装VsCode3.3 打开VsCod…...

Yii框架中的扩展:如何使用外部库
在Yii框架中,扩展功能的一种常见且有效的方式是使用外部库。这些外部库可以帮助开发者实现特定的功能,如调用第三方API、处理图片、生成PDF文件或发送邮件等。以下是使用外部库扩展Yii框架的详细步骤: 一、安装外部库 使用Composerÿ…...

kettle与Springboot的集成方法,完整支持大数据组件
目录 概要整体架构流程技术名词解释技术细节小结 概要 在现代数据处理和ETL(提取、转换、加载)流程中,Kettle(Pentaho Data Integration, PDI)作为一种强大的开源ETL工具,被广泛应用于各种数据处理场景。…...

GitHub Actions 使用需谨慎:深度剖析其痛点与替代方案
在持续集成与持续部署(CI/CD)领域,GitHub Actions 曾是众多开发者的热门选择,但如今,其弊端逐渐显现,让不少人在使用前不得不深思熟虑。 团队由大约 15 名工程师组成,采用基于主干的开发方式&am…...

<iframe>标签和定时调用函数setInterval
iframe 标签和定时调用函数 setInterval 问题描述:解决方法: 问题描述: 今天遇到一个前端问题,在浏览器页面上传Excel文件后,然后点击导入按钮,经后端Java类读取文件内容校验后,将校验结果返回…...
:聚合函数、sql语句执行原理简要分析)
MYSQL学习笔记(六):聚合函数、sql语句执行原理简要分析
前言: 学习和使用数据库可以说是程序员必须具备能力,这里将更新关于MYSQL的使用讲解,大概应该会更新30篇,涵盖入门、进阶、高级(一些原理分析);这一篇是内容较少,主要讲解:聚合函数和简要介绍sql语句执行过…...

Qt——界面优化
一.QSS 1.背景 在网页前端开发领域中, CSS 是⼀个至关重要的部分。 描述了⼀个网页的 "样式"。 从而起到对网页美化的作用。 所谓样式,包括不限于大小,位置,颜色,背景,间距,字体等等…...

MySQL 数据库常见字段类型大全及详细解析
在工作期间会遇到数据库建表的业务,经常会使用复制粘帖等操作,而不清楚数据库的字段类型。本文记录了 MySQL 数据库常见字段类型,根据不同的数据需求,可以选择不同的字段类型来存储数据。 文章目录 一、整数类型1、TINYINT&#x…...

MATLAB 工具库的使用说明和案例示例
以下是一些常见的 MATLAB 工具库的使用说明和案例示例: 信号处理工具箱(Signal Processing Toolbox): 使用说明:提供了用于生成、测量、变换、过滤和可视化信号的函数和应用程序。包括重新采样、平滑、同步信号、设计…...

对于Docker的初步了解
简介与概述 1.不需要安装环境,工具包包含了环境(jdk等) 2.打包好,“一次封装,到处运行” 3.跨平台,docker容器在任何操作系统上都是一致的,这就是实现跨平台跨服务器。只需要一次配置好环境&…...

java基础学习——jdbc基础知识详细介绍
引言 数据的存储 我们在开发 java 程序时,数据都是存储在内存中的,属于临时存储,当程序停止或重启时,内存中的数据就会丢失,我们为了解决数据的长期存储问题,有以下解决方案: 通过 IO流书记&…...

第20篇:Python 开发进阶:使用Django进行Web开发详解
第20篇:使用Django进行Web开发 内容简介 在上一篇文章中,我们深入探讨了Flask框架的高级功能,并通过构建一个博客系统展示了其实际应用。本篇文章将转向Django,另一个功能强大且广泛使用的Python Web框架。我们将介绍Django的核…...

CukeTest使用 | 1 CukeTest是什么?如何下载安装?
CukeTest使用 | 1 CukeTest是什么?如何下载安装? 1 CukeTest是什么?2 关于开发者3 CukeTest有哪些特性?4 都支持哪些自动化技术类型?5 版本区别6 下载安装 特殊说明:学习内容主要来自官网的教程、以及网上公…...