《DiffIR:用于图像修复的高效扩散模型》学习笔记
paper:2303.09472
GitHub:GitHub - Zj-BinXia/DiffIR: This project is the official implementation of 'Diffir: Efficient diffusion model for image restoration', ICCV2023
目录
摘要
1、介绍
2、相关工作
2.1 图像恢复(Image Restoration):
2.2 扩散模型(Diffusion Models):
3、方法
3.1 预备知识:扩散模型
3.2 整体框架
3.3 预训练DiffIR
3.3.1动态多头转置注意力(DMTA)
3.3.2 动态门控前馈网络(DGFN)
3.2.3 预训练目标
3.4 扩散模型在图像恢复中的应用
4、实验
4.1 实验设置
4.2 图像修复任务的评估
4.3 图像超分辨率任务的评估
4.4 图像运动去模糊任务的评估
4.5 消融实验
摘要
扩散模型(Diffusion Model,DM)通过将图像合成过程建模为去噪网络的逐步应用,已实现了SOTA(state-of-the-art,最先进)的性能。然而,与图像合成不同,图像修复(Image Restoration,IR)需要强约束以生成与真实图像(ground-truth)一致的结果。因此,对于IR任务,传统DM需要在大型模型上运行大量迭代来估计整个图像或特征图,这种方法效率较低。
为了解决这一问题,我们提出了一种高效的用于IR的扩散模型(DiffIR),该模型由紧凑的IR先验提取网络(Compact IR Prior Extraction Network,CPEN)、动态IR Transformer(Dynamic IR Transformer,DIRformer)和去噪网络组成。具体来说,DiffIR的训练包括两个阶段:预训练和扩散模型的训练。
- 在预训练阶段,我们将真实图像输入到CPEN中,以提取一个紧凑的IR先验表示(IR Prior Representation,IPR),用于指导DIRformer。
- 在第二阶段,我们训练扩散模型,仅使用低质量(LQ)图像直接估计与预训练的CPEN生成相同的IRP。
我们观察到,由于IRP只是一个紧凑的向量,DiffIR相比传统DM能够以更少的迭代次数获得准确的估计,并生成更稳定、更加真实的结果。由于迭代次数较少,DiffIR可以采用CPEN、DIRformer和去噪网络的联合优化,从而进一步减少估计误差的影响。
我们在多个IR任务上进行了广泛的实验,DiffIR在减少计算成本的同时,实现了SOTA性能。
1、介绍
图像修复(Image Restoration,IR)是一个长期存在的问题,其原因在于它广泛的应用价值和病态性质(ill-posed nature)。IR旨在从受多种退化因素(例如模糊、遮罩、降采样)影响的低质量(LQ)图像中恢复出高质量(HQ)图像。目前,基于深度学习的IR方法已取得显著成功,因为它们可以从大规模数据集中学习强大的先验信息。
病态性质:
解的非唯一性:
- 给定一张低质量(LQ)的图像,可能有无数种高质量(HQ)的图像符合它。这是因为多个HQ图像在经过退化过程(例如模糊、降采样、噪声添加)后可能生成相同的LQ图像。例如,从一张低分辨率图片生成高分辨率图片时,原始细节信息可能已经丢失,导致复原结果存在多解性。
解的存在性:
- 某些极端情况下,输入的LQ图像可能缺乏足够的信息来恢复出一张合理的HQ图像。例如,在遮挡严重或噪声极大的图像中,某些区域几乎没有可恢复的信息。
解的对输入的敏感性:
- 微小的输入噪声可能导致解的巨大差异。例如,在去噪任务中,如果算法对噪声过于敏感,可能无法有效地恢复图像的原始细节,甚至进一步放大噪声。
近年来,扩散模型(Diffusion Models,DMs)通过一系列去噪自动编码器构建,已在图像合成和IR任务(如图像修复[如修补(inpainting)和超分辨率)中取得了令人印象深刻的成果。具体来说,DM通过逆扩散过程迭代地去噪图像,能够从随机采样的高斯噪声映射到复杂目标分布(如真实图像或潜在表示分布)。与生成对抗网络(GANs)不同,DMs不会遭受模式崩溃(mode collapse)和训练不稳定性的问题。
模式崩溃是指生成器(Generator)无法学习到真实数据分布的多样性,仅生成少数几种模式的样本。换句话说,生成器会输出有限的、相似的样本,而忽略了数据分布中的其他可能性。
作为一种基于似然的模型,DM需要在大型去噪模型上进行大量迭代(约50至1000步),以精确建模数据的细节,这消耗了大量的计算资源。然而,与图像合成任务需要从零生成每个像素不同,IR任务仅需要在给定的LQ图像上添加准确的细节。因此,如果DM直接采用图像合成的范式来处理IR任务,不仅会浪费大量计算资源,还可能生成一些与给定LQ图像不匹配的细节。
在本文中,我们旨在设计一个基于DM的IR网络,以充分、高效地利用DM强大的分布映射能力来恢复图像。为此,我们提出了DiffIR。由于Transformer可以建模长距离像素依赖关系,我们采用Transformer模块作为DiffIR的基本单元,并以U-Net形状堆叠这些Transformer模块,形成动态IR Transformer(Dynamic IRformer,DIRformer),用于提取和聚合多层次特征。我们将DiffIR的训练分为两个阶段:
在第一阶段,我们开发了一个紧凑的IR先验提取网络(Compact IR Prior Extraction Network,CPEN),用于从真实图像中提取一个紧凑的IR先验表示(IPR),以指导DIRformer。此外,我们为DIRformer开发了动态门控前馈网络(Dynamic Gated Feed-Forward Network,DGFN)和动态多头转置注意力(Dynamic Multi-Head Transposed Attention,DMTA),以充分利用IPR。需要注意的是,CPEN和DIRformer是联合优化的。
在第二阶段,我们训练DM直接从LQ图像中估计精确的IPR。由于IPR较轻量且仅用于添加细节以完成修复,DiffIR能够在少量迭代后估计出相当准确的IPR,并获得稳定的视觉结果。
除了上述方案和架构上的创新外,我们还展示了联合优化的有效性。在第二阶段,我们观察到估计出的 IPR(图像恢复先验)可能仍存在一些微小误差,这会影响 DIRformer 的性能。然而,传统的扩散模型需要大量迭代,因此无法实现与解码器的联合优化。由于我们的 DiffIR 仅需要少量迭代,因此可以运行所有迭代并获得估计的 IPR,然后与 DIRformer 共同优化。
如图所示,我们的 DiffIR 在消耗远少于其他基于扩散模型的方法(例如 RePaint 和 LDM)的计算资源的同时,达到了 SOTA(State-of-the-Art)的性能。尤其是,DiffIR 的效率比 RePaint 高 1000 倍。

我们的主要贡献包括以下三点:
(1)我们提出了 DiffIR,这是一种强大、简单且高效的基于扩散模型的基准方法,专用于图像恢复。与图像生成不同,图像恢复任务的输入图像中大多数像素是已知的。因此,我们利用扩散模型强大的映射能力来估计一个紧凑的 IPR,以指导图像恢复,从而提升了扩散模型在图像恢复任务中的效率和稳定性。
传统扩散模型需要从噪声中生成整张图像,需要大量迭代(例如 100-1000 步),而 DiffIR 专注于利用扩散模型的分布映射能力生成紧凑的 IPR,仅添加细节来完成图像恢复。这种设计避免了大规模的计算浪费,显著提升效率和稳定性。
(2)我们为动态 IRformer(DIRformer)提出了动态多头转置注意力(Dynamic Gated Transposed Attention, DGTA)和动态门控前馈网络(Dynamic Gated Feed-Forward Network, DGFN),以充分挖掘 IPR 的潜力。与之前的潜变量扩散模型(Latent DM)仅单独优化去噪网络不同,我们提出了联合优化去噪网络和解码器(即 DIRformer)的方法,以进一步提升对估计误差的鲁棒性。
传统的扩散模型在优化时只能单独训练去噪网络,而无法与解码器(如 DIRformer)联合优化。这种分离优化会降低模型应对估计误差的能力。
(3)大量实验表明,所提出的 DiffIR 在图像恢复任务中实现了 SOTA 性能,同时相比其他基于扩散模型的方法消耗了更少的计算资源。
2、相关工作
2.1 图像恢复(Image Restoration):
作为先驱工作,SRCNN、DnCNN和 ARCNN 利用紧凑型 CNN 在图像恢复任务上取得了出色的性能。此后,相较于传统的图像恢复方法,基于 CNN 的方法变得更为流行。截至目前,研究人员从多个角度对 CNN 进行了深入研究,获得了更为精细的网络架构设计和学习方案,包括残差块 、GAN 、注意力机制、知识蒸馏等其他方法。
最近,Transformer 模型作为一种自然语言处理工具,在计算机视觉领域中广受欢迎。与 CNN 相比,Transformer 能够建模图像中不同区域的全局交互,并实现最先进(SOTA)的性能。目前,Transformer 已被广泛应用于多个视觉任务,例如图像识别、分割、目标检测 和图像恢复。
2.2 扩散模型(Diffusion Models):
扩散模型(DMs)在密度估计和样本质量方面取得了最先进的成果。扩散模型采用参数化的马尔可夫链来优化似然函数的变分下界,使其能够比其他生成模型(如 GAN)生成更精确的目标分布。近年来,DM 在图像恢复任务中影响力逐渐增强,例如超分辨率 和图像修复(inpainting)。SR3 和 SRdiff 将扩散模型引入到图像超分辨率任务中,并实现了比最先进的基于 GAN 的方法更优的性能。此外,Palette受到条件生成模型 的启发,提出了一种用于图像恢复的条件扩散模型。LDM 提出了在潜在空间中执行扩散模型以提高恢复效率。此外,RePaint通过在扩散模型中重新采样迭代设计了一种改进的去噪策略以用于图像修复任务。
然而,这些基于扩散模型的图像恢复方法直接采用了扩散模型在图像生成任务中的范式。然而,在图像恢复任务中,大部分像素是已知的,因此没有必要在整张图像或特征图上执行扩散模型。我们的 DiffIR 在一个紧凑的 IPR 上执行扩散模型,从而使扩散模型在图像恢复任务中处理更加高效和稳定。
3、方法
3.1 预备知识:扩散模型
在本文中,我们采用扩散模型(DMs)来生成准确的图像恢复先验表示(IPR)。在训练阶段,扩散模型通过次迭代定义了一个扩散过程,该过程将输入图像
转换为高斯噪声
。扩散过程的每次迭代可描述如下:
其中是在时间步
的噪声图像,
是预定义的缩放因子,
表示高斯分布。
实际上这就是
到
的概率分布,
表示正态分布,
是论文中设置的缩放因子,
表示
表示加噪的噪声强度。
方程可进一步简化为:
其中,
。
在推理阶段(逆过程),扩散模型从高斯随机噪声图开始,并逐渐去噪
,直到生成高质量的输出图像
:
其中均值为:
方差为:
在逆过程中的唯一不确定变量是噪声,表示在
中的噪声成分。
扩散模型通过去噪网络来估计
。为了训练
,给定一个干净图像
,扩散模型随机采样一个时间步
和噪声
,并根据方程(2)生成带噪声图像 xtx_txt。然后,扩散模型根据以下目标优化网络参数
:
3.2 整体框架
传统的扩散模型(DMs)需要大量的迭代、计算资源和模型参数来生成准确且真实的图像或潜在特征图。虽然扩散模型在从头生成图像(图像合成)方面表现出色,但将扩散模型的图像合成范式直接应用于图像恢复(IR)是一种浪费计算资源的做法。因为在图像恢复中,大多数像素和信息已经给出,直接对整个图像或特征图进行扩散模型处理,不仅会浪费大量的迭代和计算,而且很容易生成更多的伪影。因此,虽然扩散模型具有强大的数据估计能力,但将现有的图像合成扩散模型范式应用于图像恢复是低效的。为了处理这个问题,我们提出了一种高效的扩散模型用于图像恢复(即,DiffIR),它采用扩散模型估计紧凑的图像恢复先验(IPR),以引导网络恢复图像。由于IPR非常轻量,DiffIR的模型大小和迭代次数可以大大减少,从而比传统扩散模型生成更准确的估计。
如图所示,DiffIR主要由一个紧凑的IPR先验提取网络(CPEN)、动态IR变换器(DIRformer)和去噪网络组成。我们分两个阶段训练DiffIR,包括DiffIR的预训练和扩散模型的训练。

3.3 预训练DiffIR
在介绍预训练 DiffIR 之前,我们首先需要介绍第一阶段中的两个关键网络:紧凑的图像恢复先验提取网络(CPEN)和动态图像恢复变换器(DIRformer)。
CPEN 的结构如图所示,主要由残差块和线性层堆叠而成,用于提取紧凑的图像恢复先验(IPR)表示。之后,DIRformer 利用提取的 IPR 恢复低质量(LQ)图像。

DIRformer 的结构如图所示,它由 U-Net 形状的动态变换器块堆叠而成。动态变换器块包括动态多头转置注意力(DMTA, 绿色框)和动态门控前馈网络(DGFN,蓝灰框),它们使用 IPR 作为动态调制参数,将恢复细节加入到特征图中。

在预训练阶段(图 2 (a)),我们共同训练 CPEN 和 DIRformer。具体来说,我们首先将高质量(GT)图像和低质量(LQ)图像拼接在一起,并通过 PixelUnshuffle 操作对其进行降采样,得到 CPEN 的输入。然后,CPEN 提取表示为:
随后,IPR 被送入 DIRformer 的 DGFN 和 DMTA,作为动态调制参数引导恢复过程:
其中, 表示元素逐点相乘,
表示层归一化,
为线性层,
和
分别为输入和输出特征图,维度为
,而
。
3.3.1动态多头转置注意力(DMTA)

接下来,在 DMTA 中,我们聚合全局空间信息。具体来说,被投影为查询
,键
,以及值
。其中,
是
的逐点卷积,
是
的深度卷积。然后,我们将查询
、键
和值
进行重塑,分别得到
、
、
。接下来,对
和
执行点积操作,生成转置注意力图
,其大小比常规注意力图(
)更高效。
DMTA 的整体过程如下:
其中,是一个可学习的缩放参数。与传统的多头自注意力类似,我们将通道分离为多个头部,并分别计算注意力图。
3.3.2 动态门控前馈网络(DGFN)

随后,在 DGFN 中,我们聚合局部特征。首先,通过 卷积聚合不同通道的信息,然后采用
的深度卷积聚合空间邻域像素的信息。此外,我们引入门控机制以增强信息编码。DGFN 的整体过程定义为:
3.2.3 预训练目标
我们联合训练 CPEN 和 DIRformer,使得 DIRformer 可以充分利用由 CPEN 提取的 IPR。重建的目标损失为:
其中, 和
分别表示高质量的真实图像和恢复的高质量图像,
表示 L1 范数。如果任务更强调视觉质量(如修复和超分辨率任务),可以进一步添加感知损失和对抗损失。
3.4 扩散模型在图像恢复中的应用

在第二阶段,我们利用扩散模型(DM)强大的数据估计能力来估计图像先验表示(IPR)。具体来说,我们使用预训练的 CPENS1 来捕获 IPR,记为 。随后,我们对
应用扩散过程以采样
,可描述为:
其中是总的迭代次数,
和
分别由(
)。
扩散模型的加噪过程。
在反向过程当中,由于 IPR 是紧凑的,DiffIRS2 仅需要比传统扩散模型更少的迭代次数和更小的模型规模,就能够获得非常好的估计。
传统扩散模型在训练时,由于迭代的计算成本巨大,只能随机采样一个时间步 ,并仅在该时间步优化去噪网络。由于缺乏去噪网络和解码器(DIRformer)的联合训练,去噪网络导致的微小估计误差会降低 DIRformer 的潜力。相比之下,DiffIR 从第
步开始,运行所有去噪迭代,以获得
并将其传递到 DIRformer 进行联合优化:
改进点1:全面执行反向扩散迭代,避免了传统方法中随机采样时间步导致的次优训练问题。
其中 表示同样的噪声,我们使用 CPENS2 和去噪网络来预测噪声。值得注意的是,与传统扩散模型不同,我们的 DiffIRS2 删除了方差估计,这对精确的 IPR 估计和更好的性能很有帮助。
改进点2:去掉方差估计,简化模型结构,提高了对 IPR 的预测精度。
在扩散模型的反向过程中,我们首先使用 CPENS2 从低质量图像中提取条件向量
其中 CPENS2 的结构与 CPENS1 相同,但第一层卷积的输入维度不同。然后我们使用去噪网络 在每个时间步
预测噪声:
预测的噪声被代入获得 并开始下一次迭代。经过 TTT 次迭代后,我们获得最终估计的 IPR Z^∈R4C′\hat{Z} \in \mathbb{R}^{4C'}Z^∈R4C′。我们通过以下损失联合训练 CPENS2、去噪网络和 DIRformer:
其中还可以在 中加入感知损失和对抗损失以提升视觉质量。
在推理阶段,我们只使用扩散过程的反向部分。CPENS2 从低质量图像中提取条件向量,我们随机采样一个高斯噪声
。去噪网络利用
和
经过
次迭代后估计出 IPR
。随后,DIRformer 利用该 IPR 对低质量图像进行修复。
扩散模型还是用到了加噪和去噪过程,不过就是少了解码器和编码器,因为输入的直接就是
。之后预测的
通过DIRformer 进行图像修复。
4、实验
4.1 实验设置
我们分别将该方法应用于三个典型的图像修复(Image Restoration, IR)任务:
(a) 图像修复(inpainting);
(b) 图像超分辨率(super-resolution, SR);
(c) 单张图像运动去模糊(single-image motion deblurring)。
我们的 DiffIR 模型采用 4 层的编码器-解码器结构。从第 1 层到第 4 层,DMTA 模块中的注意力头数量为[1, 2, 4, 8],通道数为 [48,96,192,384]。此外,在所有图像修复任务中,我们通过调整 DIRformer 中动态 transformer 块的数量,使 DiffIR 与现有的最新方法(SOTA)在参数量和计算成本上相当。具体地,从第 1 层到第 4 层,不同任务中的动态 transformer 块数量设置为:
- 图像修复:[1,1,1,9];
- 超分辨率:[13,1,1,1];
- 去模糊:[3,5,6,6];
另外,根据之前的研究,我们在图像修复和超分辨率任务中引入了对抗损失(adversarial loss)和感知损失(perceptual loss)。CPEN 模块的通道数 设置为 64。
在扩散模型的训练过程中,总时间步数 T 设置为 4(确实显著减少了时间步,正常的扩散T是1000,怪不得反向可以直接全部迭代),(
)从
线性递增到
。我们使用 Adam 优化器(
)进行模型训练。
4.2 图像修复任务的评估
我们在图像修复任务中按照 LaMa的相同设置对 DiffIR S2 进行训练和验证。具体而言,我们使用 Places-Standard 和 CelebA-HQ 数据集,分别以批量大小为 30 和图像块大小为 256 训练我们的 DiffIR 模型。我们将 DiffIR S2 与最新的图像修复方法(包括 ICT 、LaMa 和 RePaint)进行对比,使用 LPIPS 和 FID指标在验证集上评估性能。
定量结果如表 1 所示。可以看到,我们的 DiffIR S2 显著优于其他方法。特别是,DiffIR S2 在 Places 和 CelebA-HQ 数据集上,使用宽遮罩时,相较于具有竞争力的 LaMa 方法,分别在 FID 指标上超出 0.2706 和 0.5583,并且消耗的总参数量和计算量与之相当。此外,与基于扩散模型(DM)的 RePaint 方法相比,DiffIR S2 仅消耗其 4.3% 的参数量和 0.1% 的计算资源,同时取得了更好的性能。这表明,DiffIR 能够充分且高效地利用扩散模型(DM)的数据估计能力完成图像修复任务。

定性结果如图 所示。我们的 DiffIR S2 能够生成比其他竞争性图像修复方法更加真实且合理的结构和细节。

4.3 图像超分辨率任务的评估
我们在图像超分辨率(SR)任务上对 DiffIR S2 进行训练和验证。具体来说,我们在 DIV2K(800 张图像)和 Flickr2K (2650 张图像)数据集上进行 4 倍超分辨率训练,批量大小设置为 64,低质量图像块的尺寸为 64×64。我们在五个基准数据集(Set5 、Set14 、General100 、Urban100 和 DIV2K100 )上,使用 LPIPS 和 PSNR 指标评估 DiffIR S2 和其他最新的基于 GAN 的超分辨率方法。
表 2 展示了 DiffIR S2 与最新基于 GAN 的超分辨率方法的性能和计算量(MultAdds)比较,包括 SFTGAN、SRGAN 、ESRGAN 、USRGAN、SPSR 和 BebyGAN 。可以看到,DiffIR S2 达到了最佳性能。与具有竞争力的超分辨率方法 BebyGAN 相比,DiffIR S2 在 DIV2K100 和 Urban100 数据集上的 LPIPS 指标分别领先 0.0151 和 0.0089,但仅消耗其 63% 的计算资源。此外,值得注意的是,DiffIR S2 在性能上显著超越了基于扩散模型的 LDM 方法,同时仅消耗 2% 的计算资源。

定性结果如图所示。DiffIR S2 在视觉质量上表现最佳,生成了包含更真实细节的图像。这些视觉对比结果与定量评估一致,进一步展示了 DiffIR 的优越性。DiffIR 能够高效地利用扩散模型的强大能力进行图像恢复。更多的视觉结果展示在补充材料中。

4.4 图像运动去模糊任务的评估
我们在 GoPro数据集上训练 DiffIR 模型用于图像运动去模糊任务,并在两个经典基准数据集(GoPro 和 HIDE )上对 DiffIR 进行评估。我们将 DiffIRS2 与最新的图像运动去模糊方法进行对比,包括 Restormer 、MPRNet和 IPT。
定量结果(使用 PSNR 和 SSIM 指标)如表所示从结果中可以看到,DiffIRS2 在运动去模糊任务中表现优越:
- 在 GoPro 数据集上,DiffIRS2 分别比 IPT 和 MIMI-Unet+ 高出 0.68 dB 和 0.54 dB。
- 分别在 GoPro 和 HIDE 数据集上,DiffIRS2 比 Restormer 高出 0.28 dB 和 0.33 dB,且仅消耗其 78% 的计算资源。
这些结果表明了 DiffIR 在图像运动去模糊任务上的有效性。

定性结果如图所示,DiffIRS2 在视觉质量上表现最佳,生成的图像包含更多真实细节,与对应的高质量(HQ)图像更为接近。

4.5 消融实验
DiffIRS2-V3与DiffIRS1的对比
DiffIRS2-V3实际上是表1中采用的DiffIRS2,而DiffIRS1是第一阶段的预训练网络,输入为真实图像。比较DiffIRS1和DiffIRS2-V3,我们可以看到DiffIRS2-V3与DiffIRS1的LPIPS相似,这意味着DM具有强大的数据建模能力,可以预测准确的IPR(图像修复特征)。
进一步验证DM的有效性
为了进一步证明DM的有效性,我们取消在DiffIRS2-V3中使用DM,得到DiffIRS2-V1。比较DiffIRS2-V1和DiffIRS2-V3,我们可以看到,使用DM的DiffIRS2-V3明显优于DiffIRS2-V1。这意味着DM学习到的IPR能够有效地引导DIRformer(图像修复网络)恢复低质量(LQ)图像。
探索更好的DM训练方案
我们比较了两种训练方案:传统的DM优化和我们提出的联合优化。由于传统DM方法需要多次迭代来估计大型图像或特征图,它们必须通过随机采样时间步来优化去噪网络,而无法与后面的解码器(即本文中的DIRformer)联合优化。由于DiffIR仅使用DM来估计紧凑的一维IPR向量,我们可以通过多次迭代来获得较为精确的结果。因此,我们可以通过运行去噪网络的所有迭代来获得IPR,并与DIRformer一起进行联合优化。比较DiffIRS2-V2和DiffIRS2-V3,DiffIRS2-V3明显优于DiffIRS2-V2,这证明了我们提出的联合优化方法在训练DM时的有效性。因为DM在IPR的最小估计误差可能导致DIRformer的性能下降,而联合训练DM和DIRformer可以解决这个问题。
插入噪声的影响
在传统的DM方法中,它们会在逆向DM过程中插入方差噪声,以生成更逼真的图像。与传统的DM方法预测图像或特征图不同,我们使用DM来估计IPR。在DiffIRS2-V4中,我们在逆向DM过程中插入噪声。正如我们所见,DiffIRS2-V3的表现优于DiffIRS2-V4。这意味着取消插入噪声可以更好地保证估计的IPR的准确性。
DM的损失函数
我们探索了哪些损失函数最适合引导去噪网络和CPENS2学习估计准确的IPR。从低质量图像中。我们定义了三个损失函数:(1) 定义Ldiff作为优化损失;(2) 采用L2来度量估计误差;(3) 使用Kullback-Leibler散度来度量分布相似性。
其中, 和
分别是从DiffIRS1和DiffIRS2提取的IPR,
和
是通过softmax操作分别归一化的
和
。我们分别在DiffIRS2上应用这些损失函数来学习直接从低质量图像中估计准确的IPR。然后,我们在CelebA-HQ数据集上进行评估,Ldiff的表现优于L2和Lkl。
迭代次数的影响
在这一部分,我们探索了DM中迭代次数对DiffIRS2性能的影响。我们设置了DiffIRS2中的不同迭代次数,并调整了公式中的(
),使得扩散过程后的 Z 为高斯噪声(即
)。随着迭代次数增加到3,DiffIRS2的性能会显著提高。当迭代次数大于4时,DiffIRS2的性能几乎保持稳定,意味着它达到了上限。此外,我们可以看到,我们的DiffIRS2比传统DM方法(需要超过200次迭代)具有更快的收敛速度。这是因为我们仅在IPR(一个紧凑的一维向量)上执行DM。
相关文章:
《DiffIR:用于图像修复的高效扩散模型》学习笔记
paper:2303.09472 GitHub:GitHub - Zj-BinXia/DiffIR: This project is the official implementation of Diffir: Efficient diffusion model for image restoration, ICCV2023 目录 摘要 1、介绍 2、相关工作 2.1 图像恢复(Image Rest…...

Vue3 30天精进之旅:Day01 - 初识Vue.js的奇妙世界
引言 在前端开发领域,Vue.js是一款极具人气的JavaScript框架。它以其简单易用、灵活高效的特性,吸引了大量开发者。本文是“Vue 3之30天系列学习”的第一篇博客,旨在帮助大家快速了解Vue.js的基本概念和核心特性,为后续的深入学习…...

[笔记] 极狐GitLab实例 : 手动备份步骤总结
官方备份文档 : 备份和恢复极狐GitLab 一. 要求 为了能够进行备份和恢复,请确保您系统已安装 Rsync。 如果您安装了极狐GitLab: 如果您使用 Omnibus 软件包,则无需额外操作。如果您使用源代码安装,您需要确定是否安装了 rsync。…...

将本地项目上传到 GitLab/GitHub
以下是将本地项目上传到 GitLab 的完整步骤,从创建仓库到推送代码的详细流程: 1. 在 GitLab 上创建新项目 登录 GitLab,点击 New project。选择 Create blank project。填写项目信息: Project name: 项目名称(如 my-p…...

switch组件的功能与用法
文章目录 1 概念介绍2 使用方法3 示例代码 我们在上一章回中介绍了PageView这个Widget,本章回中将介绍Switch Widget.闲话休提,让我们一起Talk Flutter吧。 1 概念介绍 我们在这里介绍的Switch是指左右滑动的开关,常用来表示某项设置是打开还是关闭。Fl…...

mac 电脑上安装adb命令
在Mac下配置android adb命令环境,配置方式如下: 1、下载并安装IDE (android studio) Android Studio官网下载链接 详细的安装连接请参考 Mac 安装Android studio 2、配置环境 在安装完成之后,将android的adb工具所在…...

Couchbase UI: Dashboard
以下是 Couchbase UI Dashboard 页面详细介绍,包括页面布局和功能说明,帮助你更好地理解和使用。 1. 首页(Overview) 功能:提供集群的整体健康状态和性能摘要 集群状态 节点健康状况:绿色(正…...

[极客大挑战 2019]Knife1
题目 蚁剑直接连接密码是Syc 拿下flag flag{1d373584-fc74-4a2c-a6d4-3691314be4ab}...

第17篇:python进阶:详解数据分析与处理
第17篇:数据分析与处理 内容简介 本篇文章将深入探讨数据分析与处理在Python中的应用。您将学习如何使用pandas库进行数据清洗与分析,掌握matplotlib和seaborn库进行数据可视化,以及处理大型数据集的技巧。通过丰富的代码示例和实战案例&am…...

【Maui】提示消息的扩展
文章目录 前言一、问题描述二、解决方案三、软件开发(源码)3.1 消息扩展库3.2 消息提示框使用3.3 错误消息提示使用3.4 问题选择框使用 四、项目展示 前言 .NET 多平台应用 UI (.NET MAUI) 是一个跨平台框架,用于使用 C# 和 XAML 创建本机移…...
)
消息队列篇--通信协议扩展篇--二进制编码(ASCII,UTF-8,UTF-16,Unicode等)
1、ASCII(American Standard Code for Information Interchange) 范围:0 到 127(共 128 个字符)描述:ASCII 是一种早期的字符编码标准,主要用于表示英文字母、数字和一些常见的符号。每个字符占…...

CentOS 7 搭建lsyncd实现文件实时同步 —— 筑梦之路
在 CentOS 7 上搭建 lsyncd(Live Syncing Daemon)以实现文件的实时同步,可以按照以下步骤进行操作。lsyncd 是一个基于 inotify 的轻量级实时同步工具,支持本地和远程同步。以下是详细的安装和配置步骤: 1. 系统准备 …...

【2025最新计算机毕业设计】基于SSM房屋租赁平台【提供源码+答辩PPT+文档+项目部署】(高质量源码,可定制,提供文档,免费部署到本地)
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

(开源)基于Django+Yolov8+Tensorflow的智能鸟类识别平台
1 项目简介(开源地址在文章结尾) 系统旨在为了帮助鸟类爱好者、学者、动物保护协会等群体更好的了解和保护鸟类动物。用户群体可以通过平台采集野外鸟类的保护动物照片和视频,甄别分类、实况分析鸟类保护动物,与全世界各地的用户&…...

【转帖】eclipse-24-09版本后,怎么还原原来版本的搜索功能
【1】原贴地址:eclipse - 怎么还原原来版本的搜索功能_eclipse打开类型搜索类功能失效-CSDN博客 https://blog.csdn.net/sinat_32238399/article/details/145113105 【2】原文如下: 更新eclipse-24-09版本后之后,新的搜索功能(CT…...

【自定义函数】编码-查询-匹配
目录 自定义编码匹配编码匹配改进 sheet来源汇总来源汇总改进 END 自定义编码匹配 在wps vb环境写一个新的excel函数名为编码匹配,第一个参数指定待匹配文本所在单元格(相对引用),第二个参数指定关键词区域(绝对引用&…...

16 分布式session和无状态的会话
在我们传统的应用中session存储在服务端,减少服务端的查询压力。如果以集群的方式部署,用户登录的session存储在该次登录的服务器节点上,如果下次访问服务端的请求落到其他节点上就需要重新生成session,这样用户需要频繁的登录。 …...

git基础指令大全
版本控制 git管理文件夹 进入要管理的文件夹 — 进入 初始化(提名) git init 管理文件夹 生成版本 .git ---- git在管理文件夹时,版本控制的信息 生成版本 git status 检测当前文件夹下的文件状态 (检测,检测之后就要管理了…...
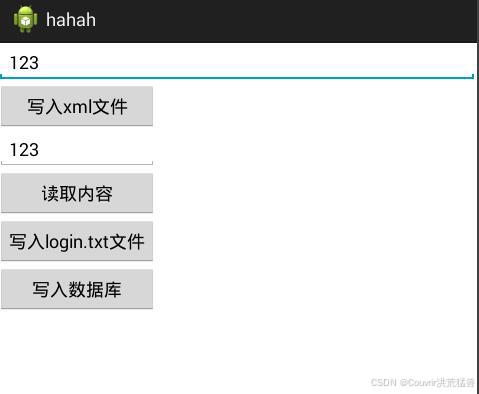
Android实训九 数据存储和访问
实训9 数据存储和访问 一、【实训目的】 1、 SharedPreferences存储数据; 2、 借助Java的I/O体系实现文件的存储, 3、使用Android内置的轻量级数据库SQLite存储数据; 二、【实训内容】 1、实现下图所示的界面,实现以下功能: 1ÿ…...

[STM32 标准库]定时器输出PWM配置流程 PWM模式解析
前言: 本文内容基本来自江协,整理起来方便日后开发使用。MCU:STM32F103C8T6。 一、配置流程 1、开启GPIO,TIM的时钟 /*开启时钟*/RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE); //开启TIM2的时钟RCC_APB2PeriphClockC…...

如何跨互联网adb连接到远程手机-蓝牙电话集中维护
如何跨互联网adb连接到远程手机-蓝牙电话集中维护 --ADB连接专题 一、前言 随便找一个手机,安装一个App并简单设置一下,就可以跨互联网的ADB连接到这个手机,从而远程操控这个手机做各种操作。你敢相信吗?而这正是本篇想要描述的…...

【6】YOLOv8 训练自己的分割数据集
YOLOv8 训练自己的分割数据集:详细指南 引言 YOLOv8作为目标检测领域的佼佼者,其在实例分割任务上也表现出色。本文将详细介绍如何使用YOLOv8训练自己的分割数据集,从数据集准备、模型训练、评估到部署,全方位地进行阐述。 一、数据集准备 数据收集: 图像/视频来源: 与目…...
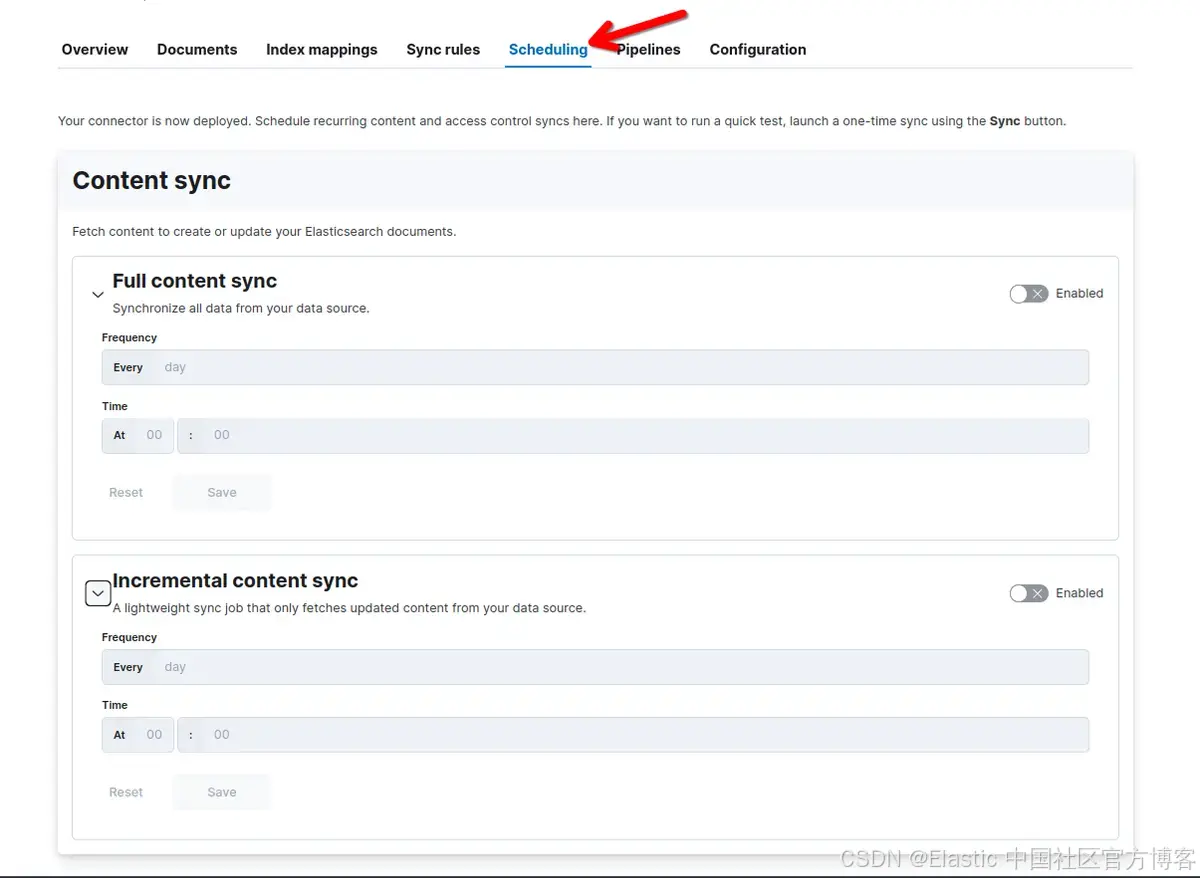
将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo 本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。 在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器…...

Android Studio:视图绑定的岁月变迁(2/100)
一、博文导读 本文是基于Android Studio真实项目,通过解析源码了解真实应用场景,写文的视角和读者是同步的,想到看到写到,没有上帝视角。 前期回顾,本文是第二期。 private Unbinder mUnbinder; 只是声明了一个 接口…...

私有包上传maven私有仓库nexus-2.9.2
一、上传 二、获取相应文件 三、最后修改自己的pom文件...

Qt监控系统辅屏预览/可以同时打开4个屏幕预览/支持5x64通道预览/onvif和rtsp接入/性能好
一、前言说明 在监控系统中,一般主界面肯定带了多个通道比如16/64通道的画面预览,随着电脑性能的增强和多屏幕的发展,再加上现在监控摄像头数量的增加,越来越多的用户希望在不同的屏幕预览不同的实时画面,一个办法是打…...

Vue.js 路由懒加载
Vue.js 路由懒加载 在 Vue.js 开发中,随着应用规模的扩大,打包后的 JavaScript 文件可能会变得相当庞大,影响页面的加载速度和性能。为了解决这个问题,Vue Router 提供了路由懒加载功能,可以将不同路由对应的组件分割…...

HBase的原理
一、什么是HBase HBase是一个分布式,版本化,面向列的数据库,依赖Hadoop和Zookeeper (1)HBase的优点 提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统 (2) HBase 表的特性 Region包含多行 列族包含多…...

Python “字典” 实战案例:5个项目开发实例
Python “字典” 实战案例:5个项目开发实例 内容摘要 本文包括 5 个使用 Python 字典的综合应用实例。具体是: 电影推荐系统配置文件解析器选票统计与排序电话黄页管理系统缓存系统(LRU 缓存) 以上每一个实例均有完整的程序代…...
达梦数据库基本操作(持续更新))
(DM)达梦数据库基本操作(持续更新)
1、连接达梦数据库 ./disql 用户明/"密码"IP端口或者域名 2、进入某个模式(数据库,因达梦数据库没有库的概念,只有模式,可以将模式等同于库) set schema 库名; 3、查表结构; SELECT COLUMN_NAM…...