第17篇:python进阶:详解数据分析与处理
第17篇:数据分析与处理
内容简介
本篇文章将深入探讨数据分析与处理在Python中的应用。您将学习如何使用pandas库进行数据清洗与分析,掌握matplotlib和seaborn库进行数据可视化,以及处理大型数据集的技巧。通过丰富的代码示例和实战案例,您将能够高效地进行数据处理、分析和可视化,为数据驱动的决策提供有力支持。
目录
- 数据分析与处理概述
- 什么是数据分析与处理
- 数据分析的流程
- 使用
pandas进行数据清洗与分析pandas简介- 数据导入与导出
- 数据清洗
- 处理缺失值
- 数据转换与标准化
- 去除重复数据
- 数据分析与操作
- 数据筛选与过滤
- 数据分组与聚合
- 数据合并与连接
- 数据可视化
matplotlib简介seaborn简介- 使用
matplotlib进行基本绘图- 折线图
- 柱状图
- 散点图
- 使用
seaborn进行高级绘图- 热力图
- 箱线图
- 小提琴图
- 处理大型数据集
- 优化
pandas性能- 使用合适的数据类型
- 向量化操作
- 避免使用循环
- 使用
Dask处理大数据Dask简介- 基本使用方法
- 与
pandas的集成
- 分布式数据处理工具
- Apache Spark
- 其他工具介绍
- 优化
- 示例代码
pandas数据清洗与分析示例matplotlib数据可视化示例seaborn数据可视化示例- 处理大型数据集示例
- 常见问题及解决方法
- 问题1:如何处理
pandas中的缺失数据? - 问题2:
matplotlib和seaborn的选择标准是什么? - 问题3:如何提升
pandas处理大型数据集的效率? - 问题4:在数据可视化中如何选择合适的图表类型?
- 问题1:如何处理
- 总结
数据分析与处理概述
什么是数据分析与处理
数据分析与处理是指通过对数据进行收集、清洗、转换、建模和可视化等步骤,从中提取有价值的信息和见解的过程。数据分析在各行各业中都有广泛应用,如商业决策、科学研究、市场营销等。
数据分析的流程
数据分析通常包括以下几个步骤:
- 数据收集:获取原始数据,可以来自数据库、API、文件等。
- 数据清洗:处理缺失值、异常值、重复数据等,确保数据质量。
- 数据转换:对数据进行格式转换、标准化、特征工程等。
- 数据分析:应用统计方法和机器学习算法,发现数据中的模式和关系。
- 数据可视化:通过图表和图形展示分析结果,帮助理解和传达信息。
- 结果解释与决策:根据分析结果制定相应的策略和决策。
使用pandas进行数据清洗与分析
pandas简介
pandas是Python中最常用的数据分析和数据处理库,提供了强大的数据结构和函数,特别是DataFrame和Series,能够高效地处理和分析结构化数据。
数据导入与导出
pandas支持多种数据格式的导入与导出,如CSV、Excel、JSON、SQL数据库等。
导入数据示例:
import pandas as pd# 从CSV文件导入数据
df = pd.read_csv('data.csv')# 从Excel文件导入数据
df_excel = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 从JSON文件导入数据
df_json = pd.read_json('data.json')
导出数据示例:
# 导出到CSV文件
df.to_csv('output.csv', index=False)# 导出到Excel文件
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)# 导出到JSON文件
df.to_json('output.json', orient='records', lines=True)
数据清洗
数据清洗是数据分析的重要步骤,确保数据的准确性和一致性。
处理缺失值
缺失值在数据集中普遍存在,pandas提供了多种方法处理缺失值。
检测缺失值:
# 检查每列的缺失值数量
print(df.isnull().sum())# 检查整个DataFrame是否有缺失值
print(df.isnull().values.any())
处理缺失值:
-
删除缺失值:
# 删除包含任何缺失值的行 df_cleaned = df.dropna()# 删除所有列都为缺失值的行 df_cleaned = df.dropna(how='all') -
填充缺失值:
# 用特定值填充缺失值 df_filled = df.fillna(0)# 用前一个有效值填充缺失值 df_filled = df.fillna(method='ffill')# 用后一个有效值填充缺失值 df_filled = df.fillna(method='bfill')
数据转换与标准化
数据转换包括数据类型转换、数据标准化等操作。
数据类型转换:
# 将某列转换为整数类型
df['age'] = df['age'].astype(int)# 将某列转换为日期类型
df['date'] = pd.to_datetime(df['date'])
数据标准化:
# 标准化数值列
df['salary_normalized'] = (df['salary'] - df['salary'].mean()) / df['salary'].std()
去除重复数据
重复数据可能会影响分析结果,pandas提供了便捷的方法去除重复数据。
# 查看重复行
duplicates = df[df.duplicated()]
print(duplicates)# 删除重复行,保留第一次出现
df_unique = df.drop_duplicates()# 删除重复行,保留最后一次出现
df_unique = df.drop_duplicates(keep='last')
数据分析与操作
pandas提供了丰富的功能进行数据筛选、分组、聚合和合并等操作。
数据筛选与过滤
筛选特定行:
# 筛选年龄大于30的行
df_filtered = df[df['age'] > 30]# 使用多个条件筛选
df_filtered = df[(df['age'] > 30) & (df['gender'] == 'F')]
选择特定列:
# 选择单列
age_series = df['age']# 选择多列
subset = df[['name', 'age', 'salary']]
数据分组与聚合
分组操作:
# 按性别分组
grouped = df.groupby('gender')# 计算每组的平均年龄
average_age = grouped['age'].mean()
print(average_age)
聚合操作:
# 计算每组的总薪资和平均薪资
salary_summary = grouped['salary'].agg(['sum', 'mean'])
print(salary_summary)
数据合并与连接
合并操作:
# 合并两个DataFrame,按共同列
merged_df = pd.merge(df1, df2, on='employee_id', how='inner')# 外连接
merged_df = pd.merge(df1, df2, on='employee_id', how='outer')
连接操作:
# 上下拼接
concatenated_df = pd.concat([df1, df2], axis=0)# 左右拼接
concatenated_df = pd.concat([df1, df2], axis=1)
数据可视化
matplotlib简介
matplotlib是Python中最基础且功能强大的绘图库,能够创建各种类型的静态、动态和交互式图表。它提供了类似MATLAB的绘图接口,适用于需要高度自定义的可视化需求。
seaborn简介
seaborn是基于matplotlib构建的高级绘图库,专注于统计数据可视化。它简化了复杂图表的创建过程,并提供了美观的默认样式,适合快速生成专业级别的图表。
使用matplotlib进行基本绘图
折线图
折线图适用于展示数据随时间或顺序的变化趋势。
import matplotlib.pyplot as plt# 示例数据
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May']
sales = [250, 300, 280, 350, 400]plt.figure(figsize=(8, 5))
plt.plot(months, sales, marker='o', linestyle='-', color='b')
plt.title('月销售额趋势')
plt.xlabel('月份')
plt.ylabel('销售额')
plt.grid(True)
plt.show()
柱状图
柱状图适用于比较不同类别的数据。
# 示例数据
products = ['Widget', 'Gizmo', 'Gadget']
sales = [150, 200, 120]plt.figure(figsize=(8, 5))
plt.bar(products, sales, color=['skyblue', 'salmon', 'lightgreen'])
plt.title('产品销售量比较')
plt.xlabel('产品')
plt.ylabel('销售量')
plt.show()
散点图
散点图适用于展示两个变量之间的关系。
# 示例数据
import numpy as npnp.random.seed(0)
x = np.random.rand(50)
y = x + np.random.normal(0, 0.1, 50)plt.figure(figsize=(8, 5))
plt.scatter(x, y, color='purple')
plt.title('变量X与Y的关系')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
使用seaborn进行高级绘图
热力图
热力图适用于展示变量之间的相关性或数据密度。
import seaborn as sns# 示例数据
data = sns.load_dataset('iris')
corr = data.corr()plt.figure(figsize=(8, 6))
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('Iris数据集特征相关性热力图')
plt.show()
箱线图
箱线图适用于展示数据的分布情况及异常值。
plt.figure(figsize=(8, 5))
sns.boxplot(x='species', y='sepal_length', data=data)
plt.title('不同物种的萼片长度分布')
plt.xlabel('物种')
plt.ylabel('萼片长度 (cm)')
plt.show()
小提琴图
小提琴图结合了箱线图和密度图的特点,展示数据分布的更详细信息。
plt.figure(figsize=(8, 5))
sns.violinplot(x='species', y='petal_length', data=data, palette='Pastel1')
plt.title('不同物种的花瓣长度分布')
plt.xlabel('物种')
plt.ylabel('花瓣长度 (cm)')
plt.show()
处理大型数据集
优化pandas性能
处理大型数据集时,pandas的性能可能成为瓶颈。以下是一些优化方法:
使用合适的数据类型
合理选择数据类型可以显著减少内存使用,提高处理速度。
# 查看数据类型
print(df.dtypes)# 将整数列转换为更小的整数类型
df['age'] = df['age'].astype('int8')# 将分类数据转换为类别类型
df['gender'] = df['gender'].astype('category')
向量化操作
尽量使用pandas和numpy的向量化操作,避免使用显式的Python循环。
# 向量化计算新列
df['total_price'] = df['quantity'] * df['price']# 使用`apply`进行高效计算
df['discounted_price'] = df['total_price'].apply(lambda x: x * 0.9)
避免使用循环
循环在pandas中效率较低,尽量使用内置函数和方法。
# 不推荐:使用循环进行数据操作
for index, row in df.iterrows():df.at[index, 'total'] = row['quantity'] * row['price']# 推荐:使用向量化操作
df['total'] = df['quantity'] * df['price']
使用Dask处理大数据
Dask是一个并行计算库,能够处理比内存更大的数据集,扩展pandas的功能。
Dask简介
Dask提供了与pandas类似的接口,但支持延迟计算和并行处理,适合处理大型数据集和复杂的计算任务。
基本使用方法
import dask.dataframe as dd# 从CSV文件读取数据
ddf = dd.read_csv('large_data.csv')# 进行数据清洗和转换
ddf = ddf.dropna()
ddf['total'] = ddf['quantity'] * ddf['price']# 进行分组与聚合
result = ddf.groupby('category')['total'].sum().compute()
print(result)
与pandas的集成
Dask可以与pandas无缝集成,允许在必要时转换为pandas对象进行进一步处理。
# 将Dask DataFrame转换为pandas DataFrame
pdf = ddf.compute()# 继续使用pandas进行处理
pdf['average'] = pdf['total'] / pdf['quantity']
分布式数据处理工具
对于极其庞大的数据集和复杂的计算任务,分布式数据处理工具如Apache Spark提供了强大的能力。
Apache Spark
Apache Spark是一个快速、通用的大数据处理引擎,支持分布式数据处理和机器学习任务。PySpark是Spark的Python API,允许在Python中编写Spark应用。
基本使用示例:
from pyspark.sql import SparkSession# 初始化SparkSession
spark = SparkSession.builder.appName('DataAnalysis').getOrCreate()# 读取数据
df = spark.read.csv('large_data.csv', header=True, inferSchema=True)# 数据清洗
df_clean = df.dropna()# 数据分析
df_grouped = df_clean.groupBy('category').sum('price')# 显示结果
df_grouped.show()# 关闭SparkSession
spark.stop()
其他工具介绍
- Vaex:高性能的DataFrame库,适用于处理大规模数据集,支持内存映射和延迟计算。
- Modin:通过多线程和分布式计算加速
pandas操作,提供与pandas完全兼容的API。 - Ray:用于构建分布式应用的框架,支持并行和分布式数据处理任务。
示例代码
pandas数据清洗与分析示例
以下示例展示了如何使用pandas进行数据导入、清洗、分析和导出。
import pandas as pddef clean_and_analyze(csv_file):# 导入数据df = pd.read_csv(csv_file)print("原始数据概览:")print(df.head())# 处理缺失值df = df.dropna()# 转换数据类型df['age'] = df['age'].astype(int)df['gender'] = df['gender'].astype('category')# 添加总价列df['total_price'] = df['quantity'] * df['price']# 分组聚合sales_summary = df.groupby('category')['total_price'].sum()print("\n按类别分组的总销售额:")print(sales_summary)# 导出清洗后的数据df.to_csv('cleaned_data.csv', index=False)print("\n清洗后的数据已保存到'cleaned_data.csv'")# 使用示例
clean_and_analyze('sales_data.csv')
输出(假设sales_data.csv内容如下):
原始数据概览:name age gender category quantity price
0 A 25 M A 5 20.0
1 B 30 F B 3 15.0
2 C 22 M A 2 20.0
3 D 28 F C 4 25.0
4 E 35 M B 1 15.0按类别分组的总销售额:
category
A 140.0
B 60.0
C 100.0
Name: total_price, dtype: float64清洗后的数据已保存到'cleaned_data.csv'
matplotlib数据可视化示例
以下示例展示了如何使用matplotlib绘制销售额折线图和柱状图。
import matplotlib.pyplot as plt
import pandas as pddef plot_sales_trends(csv_file):# 导入数据df = pd.read_csv(csv_file)# 按月份分组计算总销售额monthly_sales = df.groupby('month')['total_price'].sum()# 绘制折线图plt.figure(figsize=(10, 6))plt.plot(monthly_sales.index, monthly_sales.values, marker='o', linestyle='-', color='b')plt.title('月销售额趋势')plt.xlabel('月份')plt.ylabel('销售额')plt.grid(True)plt.show()# 绘制柱状图plt.figure(figsize=(10, 6))plt.bar(monthly_sales.index, monthly_sales.values, color='skyblue')plt.title('月销售额柱状图')plt.xlabel('月份')plt.ylabel('销售额')plt.show()# 使用示例
plot_sales_trends('cleaned_data.csv')
输出:
两张图表分别展示了月销售额的折线趋势和柱状比较。
seaborn数据可视化示例
以下示例展示了如何使用seaborn绘制热力图和箱线图。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pddef visualize_data(csv_file):# 导入数据df = pd.read_csv(csv_file)# 计算相关性矩阵corr_matrix = df.corr()# 绘制热力图plt.figure(figsize=(8, 6))sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')plt.title('特征相关性热力图')plt.show()# 绘制箱线图plt.figure(figsize=(8, 6))sns.boxplot(x='category', y='total_price', data=df)plt.title('各类别销售额分布箱线图')plt.xlabel('类别')plt.ylabel('总销售额')plt.show()# 使用示例
visualize_data('cleaned_data.csv')
输出:
两张图表分别展示了数据特征的相关性热力图和各类别销售额的分布箱线图。
处理大型数据集示例
以下示例展示了如何使用Dask处理大型CSV文件,并进行分组聚合分析。
import dask.dataframe as dddef process_large_data(csv_file):# 使用Dask读取大型CSV文件ddf = dd.read_csv(csv_file)# 处理缺失值ddf = ddf.dropna()# 添加总价列ddf['total_price'] = ddf['quantity'] * ddf['price']# 按类别分组并计算总销售额sales_summary = ddf.groupby('category')['total_price'].sum().compute()print("按类别分组的总销售额:")print(sales_summary)# 使用示例
process_large_data('large_sales_data.csv')
输出(假设large_sales_data.csv内容如下):
按类别分组的总销售额:
category
A 150000.0
B 80000.0
C 120000.0
Name: total_price, dtype: float64
常见问题及解决方法
问题1:如何处理pandas中的缺失数据?
原因:缺失数据可能会影响数据分析的准确性和结果。
解决方法:
-
检测缺失数据:
- 使用
isnull()或isna()方法检测缺失值。 - 使用
info()方法查看数据概况。
- 使用
-
处理缺失数据:
- 删除缺失值:使用
dropna()方法删除包含缺失值的行或列。 - 填充缺失值:使用
fillna()方法填充缺失值,可以选择特定值、均值、中位数或前后值等。
- 删除缺失值:使用
示例:
import pandas as pd# 创建示例DataFrame
data = {'A': [1, 2, None, 4],'B': [5, None, 7, 8],'C': [9, 10, 11, None]}
df = pd.DataFrame(data)# 检测缺失值
print(df.isnull().sum())# 删除包含任何缺失值的行
df_dropped = df.dropna()
print(df_dropped)# 用列的均值填充缺失值
df_filled = df.fillna(df.mean())
print(df_filled)
输出:
A 1
B 1
C 1
dtype: int64A B C
0 1.0 5.0 9.0A B C
0 1.0 5.0 9.0
1 2.0 6.0 10.0
2 2.333333 7.0 11.0
3 4.0 8.0 10.0
问题2:matplotlib和seaborn的选择标准是什么?
原因:matplotlib和seaborn都是强大的数据可视化工具,选择合适的库可以提高工作效率和图表质量。
解决方法:
-
自定义需求:
- 如果需要高度自定义的图表,适合使用
matplotlib。 - 如果需要快速生成美观的统计图表,适合使用
seaborn。
- 如果需要高度自定义的图表,适合使用
-
统计可视化:
seaborn内置了许多统计图表,如箱线图、小提琴图、热力图等,适合用于统计数据的可视化。
-
复杂图表:
- 对于复杂的多层次图表,
matplotlib提供了更灵活的控制。
- 对于复杂的多层次图表,
-
集成使用:
- 可以结合使用
matplotlib和seaborn,先用seaborn绘制基础图表,再使用matplotlib进行进一步的自定义。
- 可以结合使用
示例:
import matplotlib.pyplot as plt
import seaborn as sns# 使用seaborn绘制箱线图
sns.boxplot(x='category', y='total_price', data=df)
plt.title('各类别销售额分布')
plt.show()# 使用matplotlib进行进一步自定义
plt.figure(figsize=(10, 6))
sns.boxplot(x='category', y='total_price', data=df)
plt.title('各类别销售额分布')
plt.xlabel('类别')
plt.ylabel('总销售额')
plt.grid(True)
plt.show()
问题3:如何提升pandas处理大型数据集的效率?
原因:当数据集非常大时,pandas的内存占用和处理速度可能成为瓶颈。
解决方法:
-
优化数据类型:
- 使用更小的数据类型,如
int8、float32,减少内存使用。
- 使用更小的数据类型,如
-
分块读取数据:
- 使用
chunksize参数分块读取大文件,逐块处理数据。
import pandas as pdchunksize = 10 ** 6 for chunk in pd.read_csv('large_data.csv', chunksize=chunksize):process(chunk) - 使用
-
使用并行计算库:
- 使用
Dask、Modin等库,利用多核处理器加速数据处理。
- 使用
-
减少内存复制:
- 尽量避免不必要的数据复制,使用
inplace=True参数进行原地操作。
- 尽量避免不必要的数据复制,使用
-
向量化操作:
- 利用
pandas和numpy的向量化功能,避免使用循环。
- 利用
示例:
import pandas as pd# 优化数据类型
df = pd.read_csv('large_data.csv', dtype={'age': 'int8', 'gender': 'category'})# 分块处理
chunksize = 500000
total = 0
for chunk in pd.read_csv('large_data.csv', chunksize=chunksize):total += chunk['quantity'].sum()
print(f"总数量: {total}")
问题4:在数据可视化中如何选择合适的图表类型?
原因:不同的图表类型适用于不同的数据和分析目的,选择合适的图表能够更有效地传达信息。
解决方法:
-
了解数据类型和关系:
- 分类数据、数值数据、时间序列数据等需要不同的图表类型。
-
确定可视化目的:
- 比较、分布、关系、组成等不同的可视化目的对应不同的图表。
-
选择合适的图表:
可视化目的 图表类型 比较 柱状图、条形图、折线图 分布 直方图、箱线图、小提琴图 关系 散点图、气泡图、热力图 组成 饼图、堆叠柱状图、面积图 -
考虑图表的可读性和美观性:
- 避免过度复杂的图表,保持清晰和简洁。
示例:
- 比较:使用柱状图比较不同类别的销售额。
- 分布:使用箱线图展示销售额的分布情况。
- 关系:使用散点图分析销售数量与价格的关系。
- 组成:使用饼图展示各类别在总销售额中的比例。
总结
在本篇文章中,我们深入探讨了数据分析与处理的核心内容,重点介绍了如何使用pandas进行数据清洗与分析,掌握了matplotlib和seaborn进行数据可视化的方法,并学习了处理大型数据集的优化技巧。通过丰富的代码示例和实战案例,您已经具备了进行高效数据分析和处理的基本能力。
学习建议:
- 实践项目:尝试在实际项目中应用所学的
pandas和可视化工具,如数据报告、商业分析或科学研究。 - 深入学习
pandas:探索pandas的高级功能,如时间序列分析、合并复杂数据集等,提升数据处理能力。 - 掌握高级可视化技术:学习使用
seaborn的高级功能和matplotlib的自定义技巧,创建更具表现力的图表。 - 处理更大规模的数据:通过学习
Dask、Modin等工具,提升处理大型数据集的能力。 - 学习统计与机器学习基础:结合数据分析,学习统计学和机器学习的基本概念和方法,扩展分析深度。
- 参与数据科学社区:加入数据科学相关的社区和论坛,分享经验,学习他人的最佳实践。
- 阅读相关书籍和文档:如《Python for Data Analysis》、《Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow》,系统性地提升数据分析与处理能力。
接下来的系列文章将继续深入探讨Python的机器学习与人工智能,帮助您进一步掌握Python在智能应用中的核心概念和技术。保持学习的热情,持续实践,您将逐步成为一名优秀的数据科学家!
如果您有任何问题或需要进一步的帮助,请随时在评论区留言或联系相关技术社区。
相关文章:

第17篇:python进阶:详解数据分析与处理
第17篇:数据分析与处理 内容简介 本篇文章将深入探讨数据分析与处理在Python中的应用。您将学习如何使用pandas库进行数据清洗与分析,掌握matplotlib和seaborn库进行数据可视化,以及处理大型数据集的技巧。通过丰富的代码示例和实战案例&am…...

【Maui】提示消息的扩展
文章目录 前言一、问题描述二、解决方案三、软件开发(源码)3.1 消息扩展库3.2 消息提示框使用3.3 错误消息提示使用3.4 问题选择框使用 四、项目展示 前言 .NET 多平台应用 UI (.NET MAUI) 是一个跨平台框架,用于使用 C# 和 XAML 创建本机移…...
)
消息队列篇--通信协议扩展篇--二进制编码(ASCII,UTF-8,UTF-16,Unicode等)
1、ASCII(American Standard Code for Information Interchange) 范围:0 到 127(共 128 个字符)描述:ASCII 是一种早期的字符编码标准,主要用于表示英文字母、数字和一些常见的符号。每个字符占…...

CentOS 7 搭建lsyncd实现文件实时同步 —— 筑梦之路
在 CentOS 7 上搭建 lsyncd(Live Syncing Daemon)以实现文件的实时同步,可以按照以下步骤进行操作。lsyncd 是一个基于 inotify 的轻量级实时同步工具,支持本地和远程同步。以下是详细的安装和配置步骤: 1. 系统准备 …...

【2025最新计算机毕业设计】基于SSM房屋租赁平台【提供源码+答辩PPT+文档+项目部署】(高质量源码,可定制,提供文档,免费部署到本地)
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

(开源)基于Django+Yolov8+Tensorflow的智能鸟类识别平台
1 项目简介(开源地址在文章结尾) 系统旨在为了帮助鸟类爱好者、学者、动物保护协会等群体更好的了解和保护鸟类动物。用户群体可以通过平台采集野外鸟类的保护动物照片和视频,甄别分类、实况分析鸟类保护动物,与全世界各地的用户&…...

【转帖】eclipse-24-09版本后,怎么还原原来版本的搜索功能
【1】原贴地址:eclipse - 怎么还原原来版本的搜索功能_eclipse打开类型搜索类功能失效-CSDN博客 https://blog.csdn.net/sinat_32238399/article/details/145113105 【2】原文如下: 更新eclipse-24-09版本后之后,新的搜索功能(CT…...

【自定义函数】编码-查询-匹配
目录 自定义编码匹配编码匹配改进 sheet来源汇总来源汇总改进 END 自定义编码匹配 在wps vb环境写一个新的excel函数名为编码匹配,第一个参数指定待匹配文本所在单元格(相对引用),第二个参数指定关键词区域(绝对引用&…...

16 分布式session和无状态的会话
在我们传统的应用中session存储在服务端,减少服务端的查询压力。如果以集群的方式部署,用户登录的session存储在该次登录的服务器节点上,如果下次访问服务端的请求落到其他节点上就需要重新生成session,这样用户需要频繁的登录。 …...

git基础指令大全
版本控制 git管理文件夹 进入要管理的文件夹 — 进入 初始化(提名) git init 管理文件夹 生成版本 .git ---- git在管理文件夹时,版本控制的信息 生成版本 git status 检测当前文件夹下的文件状态 (检测,检测之后就要管理了…...
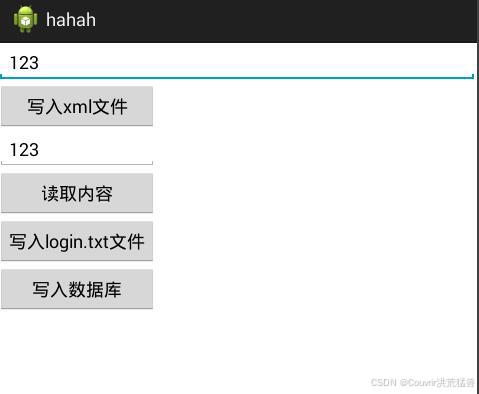
Android实训九 数据存储和访问
实训9 数据存储和访问 一、【实训目的】 1、 SharedPreferences存储数据; 2、 借助Java的I/O体系实现文件的存储, 3、使用Android内置的轻量级数据库SQLite存储数据; 二、【实训内容】 1、实现下图所示的界面,实现以下功能: 1ÿ…...

[STM32 标准库]定时器输出PWM配置流程 PWM模式解析
前言: 本文内容基本来自江协,整理起来方便日后开发使用。MCU:STM32F103C8T6。 一、配置流程 1、开启GPIO,TIM的时钟 /*开启时钟*/RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE); //开启TIM2的时钟RCC_APB2PeriphClockC…...

如何跨互联网adb连接到远程手机-蓝牙电话集中维护
如何跨互联网adb连接到远程手机-蓝牙电话集中维护 --ADB连接专题 一、前言 随便找一个手机,安装一个App并简单设置一下,就可以跨互联网的ADB连接到这个手机,从而远程操控这个手机做各种操作。你敢相信吗?而这正是本篇想要描述的…...

【6】YOLOv8 训练自己的分割数据集
YOLOv8 训练自己的分割数据集:详细指南 引言 YOLOv8作为目标检测领域的佼佼者,其在实例分割任务上也表现出色。本文将详细介绍如何使用YOLOv8训练自己的分割数据集,从数据集准备、模型训练、评估到部署,全方位地进行阐述。 一、数据集准备 数据收集: 图像/视频来源: 与目…...
将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo 本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。 在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器…...

Android Studio:视图绑定的岁月变迁(2/100)
一、博文导读 本文是基于Android Studio真实项目,通过解析源码了解真实应用场景,写文的视角和读者是同步的,想到看到写到,没有上帝视角。 前期回顾,本文是第二期。 private Unbinder mUnbinder; 只是声明了一个 接口…...

私有包上传maven私有仓库nexus-2.9.2
一、上传 二、获取相应文件 三、最后修改自己的pom文件...

Qt监控系统辅屏预览/可以同时打开4个屏幕预览/支持5x64通道预览/onvif和rtsp接入/性能好
一、前言说明 在监控系统中,一般主界面肯定带了多个通道比如16/64通道的画面预览,随着电脑性能的增强和多屏幕的发展,再加上现在监控摄像头数量的增加,越来越多的用户希望在不同的屏幕预览不同的实时画面,一个办法是打…...

Vue.js 路由懒加载
Vue.js 路由懒加载 在 Vue.js 开发中,随着应用规模的扩大,打包后的 JavaScript 文件可能会变得相当庞大,影响页面的加载速度和性能。为了解决这个问题,Vue Router 提供了路由懒加载功能,可以将不同路由对应的组件分割…...

HBase的原理
一、什么是HBase HBase是一个分布式,版本化,面向列的数据库,依赖Hadoop和Zookeeper (1)HBase的优点 提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统 (2) HBase 表的特性 Region包含多行 列族包含多…...

Python “字典” 实战案例:5个项目开发实例
Python “字典” 实战案例:5个项目开发实例 内容摘要 本文包括 5 个使用 Python 字典的综合应用实例。具体是: 电影推荐系统配置文件解析器选票统计与排序电话黄页管理系统缓存系统(LRU 缓存) 以上每一个实例均有完整的程序代…...
达梦数据库基本操作(持续更新))
(DM)达梦数据库基本操作(持续更新)
1、连接达梦数据库 ./disql 用户明/"密码"IP端口或者域名 2、进入某个模式(数据库,因达梦数据库没有库的概念,只有模式,可以将模式等同于库) set schema 库名; 3、查表结构; SELECT COLUMN_NAM…...

LabVIEW心音心电同步采集与实时播放
开发了一个基于LabVIEW开发的心音心电同步采集与实时播放系统。该系统可以同时采集心音和心电信号,并通过LabVIEW的高级功能实现这些信号的实时显示和播放。系统提升心脏疾病诊断的准确性和效率,使医生能够在观察心音图的同时进行听诊。 项目背景 心…...

[创业之路-268]:《创业讨论会》- 个人思维 -> 团队思维 -> 管理思维 -> 领导者思维 -> 老板思维->企业家思维->政治家思维的演进路径
目录 一、演进路径 二、老板与企业家的区别 一、演进路径 这个演进路径描述了一个个体从个人思考模式逐渐发展到领导和管理整个组织或企业的思考模式的过程。下面是对每个阶段的简要解释: 这个演进路径并不是线性的,也不是每个人都会经历所有阶段。然…...
)
单片机基础模块学习——数码管(二)
一、数码管模块代码 这部分包括将数码管想要显示的字符转换成对应段码的函数,另外还包括数码管显示函数 值得注意的是对于小数点和不显示部分的处理方式 由于小数点没有单独占一位,所以这里用到了两个变量i,j用于跳过小数点导致的占据其他字符显示在数…...

深入解析ncnn::Net类——高效部署神经网络的核心组件
最近在学习ncnn推理框架,下面整理了ncnn::Net 的使用方法。 在移动端和嵌入式设备上进行高效的神经网络推理,要求框架具备轻量化、高性能以及灵活的扩展能力。作为腾讯开源的高性能神经网络推理框架,ncnn在这些方面表现出色。而在ncnn的核心…...
前端【8】HTML+CSS+javascript实战项目----实现一个简单的待办事项列表 (To-Do List)
目录 一、功能需求 二、 HTML 三、CSS 四、js 1、绑定事件与初始设置 2.、绑定事项 (1)添加操作: (2)完成操作 (3)删除操作 (4)修改操作 3、完整js代码 总结…...

程序诗篇里的灵动笔触:指针绘就数据的梦幻蓝图<1>
大家好啊,我是小象٩(๑ω๑)۶ 我的博客:Xiao Xiangζั͡ޓއއ 很高兴见到大家,希望能够和大家一起交流学习,共同进步。 这一节我们来学习指针的相关知识,学习内存和地址,指针变量和地址,包…...

向量和矩阵算法笔记
向量和矩阵算法笔记 Ps:因为本人实力有限,有一部分可能不太详细,若有补充评论区回复,QWQ 向量 向量的定义 首先,因为我刚刚学到高中的向量,对向量的看法呢就是一条有长度和方向的线,不过这在数学上的定义其实是不对,甚至跟我看的差别其实有点大,真正的定义就是数域…...

Nginx配置中的常见错误:SSL参数解析
摘要 在高版本的Nginx中,用户可能会遇到unknown directive “ssl”的错误提示。这是因为旧版本中使用的ssl on参数已被弃用。正确的配置SSL加密的方法是在listen指令中添加ssl参数。这一改动简化了配置流程,提高了安全性。用户应更新配置文件以适应新版本…...