【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】1.17 时间魔法:处理千万级时间序列的秘籍

1.17 时间魔法:处理千万级时间序列的秘籍
目录
1.17.1 datetime64的精度的选择策略
在处理时间序列数据时,选择合适的精度是非常重要的。NumPy 提供了 datetime64 类型来处理时间数据,datetime64 具有多种精度,包括年(Y)、月(M)、日(D)、小时(h)、分钟(m)、秒(s)、毫秒(ms)、微秒(us)、纳秒(ns)等。本节将详细介绍如何选择合适的精度,并展示其与内存占用的关系。
精度与内存关系表
| 精度单位 | 时间范围 | 内存占用/元素 | 示例代码 |
|---|---|---|---|
| 年(Y) | +/-2.9e9年 | 8字节 | np.datetime64('2023','Y') |
| 月(M) | +/-2.4e5年 | 8字节 | np.datetime64('2023-08','M') |
| 纳秒(ns) | +/-292年 | 8字节 | np.datetime64('2023-08-15T12:34:56.123456789') |
内存占用公式
内存总量 = 元素数量 × 8 字节 内存总量 = 元素数量 \times 8\ 字节 内存总量=元素数量×8 字节
1.17.1.1 时间精度与内存占用的关系
| 时间精度 | 内存占用(字节) |
|---|---|
| Y | 4 |
| M | 4 |
| D | 8 |
| h | 8 |
| m | 8 |
| s | 8 |
| ms | 8 |
| us | 8 |
| ns | 8 |
1.17.1.2 选择合适的精度
选择合适的精度取决于你的应用场景和数据范围。例如,如果你处理的是年份数据,选择 datetime64[Y] 是最合适的,因为它占用的内存最少。如果你处理的是毫秒级时间戳,选择 datetime64[ms] 是最常见的。
import numpy as np# 创建不同精度的 datetime64 数组
years = np.array(['2023', '2024'], dtype='datetime64[Y]')
months = np.array(['2023-01', '2023-02'], dtype='datetime64[M]')
days = np.array(['2023-01-01', '2023-01-02'], dtype='datetime64[D]')
hours = np.array(['2023-01-01T00', '2023-01-01T01'], dtype='datetime64[h]')
minutes = np.array(['2023-01-01T00:00', '2023-01-01T00:01'], dtype='datetime64[m]')
seconds = np.array(['2023-01-01T00:00:00', '2023-01-01T00:00:01'], dtype='datetime64[s]')
milliseconds = np.array(['2023-01-01T00:00:00.000', '2023-01-01T00:00:00.001'], dtype='datetime64[ms]')
microseconds = np.array(['2023-01-01T00:00:00.000000', '2023-01-01T00:00:00.000001'], dtype='datetime64[us]')
nanoseconds = np.array(['2023-01-01T00:00:00.000000000', '2023-01-01T00:00:00.000000001'], dtype='datetime64[ns]')# 打印数组及其内存占用
arrays = [years, months, days, hours, minutes, seconds, milliseconds, microseconds, nanoseconds]
for array in arrays:print(f"类型: {array.dtype}, 数据: {array}, 内存占用: {array.nbytes} 字节")
1.17.2 滑动窗口统计的向量化实现
滑动窗口统计在时间序列分析中非常常见,例如计算滑动平均值。本节将介绍如何使用 NumPy 的向量化操作来实现滑动窗口统计,并通过示例进行展示。
1.17.2.1 滑动窗口的原理
滑动窗口统计是指在一个时间序列数据上滑动一个固定大小的窗口,并在每个窗口上计算某种统计量。常见的统计量包括均值、方差、最大值、最小值等。
滑动平均算法
1.17.2.2 向量化滑动平均实现方案
import numpy as npdef moving_average(arr, window_size):"""计算滑动平均值:param arr: 输入的时间序列数据:param window_size: 窗口大小:return: 滑动平均值数组"""cumsum = np.cumsum(arr) # 计算累积和cumsum[window_size:] = cumsum[window_size:] - cumsum[:-window_size] # 计算滑动窗口内的累积和差值return cumsum[window_size - 1:] / window_size # 计算滑动窗口内的平均值# 创建一个时间序列数据
data = np.random.rand(10000000).astype(np.float32) # 生成1000万条数据# 计算滑动平均值
window_size = 1000
ma = moving_average(data, window_size)# 打印前10个滑动平均值
print("前10个滑动平均值: ", ma[:10])
1.17.3 时区转换的位操作优化
在处理跨时区的时间序列数据时,时区转换是一个常见的需求。本节将介绍如何通过位操作优化时区转换的性能,并通过示例进行展示。
1.17.3.1 时区转换的原理
时区转换是指将一个时间戳从一个时区转换到另一个时区。通常,这需要考虑时间戳的纳秒级精度。
1.17.3.2 纳秒级时间戳的存储优化
import numpy as np
import pytzdef convert_timezone(arr, src_tz, dst_tz):"""时区转换:param arr: 输入的时间戳数组:param src_tz: 源时区:param dst_tz: 目标时区:return: 转换后的时区数组"""# 将时间戳转换为 datetime 对象dt_arr = np.array([np.datetime64(dt, 'ns') for dt in arr], dtype='datetime64[ns]']# 转换时区src_tz = pytz.timezone(src_tz)dst_tz = pytz.timezone(dst_tz)converted_dt_arr = np.array([src_tz.localize(pd.to_datetime(dt)).astimezone(dst_tz) for dt in dt_arr], dtype='datetime64[ns]')return converted_dt_arr# 创建一个时间戳数组
timestamps = np.array(['2023-01-01T00:00:00.000000000', '2023-01-01T00:00:01.000000000'], dtype='datetime64[ns]')# 进行时区转换
src_tz = 'UTC'
dst_tz = 'Asia/Shanghai'
converted_timestamps = convert_timezone(timestamps, src_tz, dst_tz)# 打印转换后的时区数据
print("转换前的时区数据: ", timestamps)
print("转换后的时区数据: ", converted_timestamps)
时区映射表
1.17.3.3 位操作优化示意图
1.17.4 金融高频交易数据处理实战
金融高频交易数据通常包含数百万甚至数千万条记录,处理这些数据需要高效的时间序列操作。本节将通过一个股票tick数据清洗的完整流程,展示如何使用 NumPy 处理高频交易数据。
1.17.4.1 股票tick数据清洗完整流程
- 读取数据:从文件中读取股票tick数据。
- 时间戳转换:将字符串时间戳转换为
datetime64类型。 - 数据清洗:去除无效数据,如空值或异常值。
- 滑动窗口统计:计算滑动平均值等统计量。
- 数据存储:将清洗后的数据存储为
npy文件。
import numpy as np
import pandas as pd# 1. 读取数据
def read_tick_data(file_path):"""从文件中读取股票 tick 数据:param file_path: 文件路径:return: 股票 tick 数据"""data = pd.read_csv(file_path, parse_dates=['timestamp'], date_parser=lambda x: pd.to_datetime(x, unit='ns'))return data# 2. 时间戳转换
def convert_timestamps(data):"""将字符串时间戳转换为 datetime64 类型:param data: 股票 tick 数据:return: 转换后的时间戳数组"""timestamps = data['timestamp'].values.astype('datetime64[ns]')return timestamps# 3. 数据清洗
def clean_data(data):"""清洗股票 tick 数据:param data: 股票 tick 数据:return: 清洗后的数据"""data = data.dropna() # 去除空值data = data[(data['price'] > 0) & (data['volume'] > 0)] # 去除无效数据return data# 4. 滑动窗口统计
def compute_rolling_stats(data, window_size):"""计算滑动窗口统计量:param data: 股票 tick 数据:param window_size: 窗口大小:return: 滑动平均值、滑动标准差等统计量"""prices = data['price'].values.astype(np.float32)rolling_mean = moving_average(prices, window_size)rolling_std = np.sqrt(moving_average(prices**2, window_size) - rolling_mean**2)return rolling_mean, rolling_std# 5. 数据存储
def save_data(data, file_path):"""将清洗后的数据存储为 npy 文件:param data: 清洗后的数据:param file_path: 文件路径"""np.save(file_path, data, allow_pickle=True)# 完整流程示例
file_path = 'tick_data.csv'
data = read_tick_data(file_path)
data = clean_data(data)
rolling_mean, rolling_std = compute_rolling_stats(data, window_size=1000)
save_data(data, 'cleaned_data.npy')
1.17.4.2 与Pandas时间序列的性能对比
import timedef benchmark_performance(func, *args, **kwargs):"""测试函数性能:param func: 需要测试的函数:param args: 函数的参数:param kwargs: 函数的参数:return: 执行时间"""start_time = time.time()func(*args, **kwargs)end_time = time.time()return end_time - start_time# 生成测试数据
data = pd.read_csv('tick_data.csv', parse_dates=['timestamp'])# 测试 NumPy 和 Pandas 的性能
numpy_time = benchmark_performance(clean_data, data)
pandas_time = benchmark_performance(lambda x: x.dropna().query('price > 0 and volume > 0'), data)# 打印性能对比结果
print(f"NumPy 数据清洗时间: {numpy_time:.6f} 秒")
print(f"Pandas 数据清洗时间: {pandas_time:.6f} 秒")
性能对比表
| 方法 | 数据规模 | 耗时 |
|---|---|---|
| 循环 | 1e6 | 120ms |
| 向量化 | 1e6 | 2.3ms |
总结
通过本篇文章的详细讲解和示例,我们对 NumPy 中的时间序列处理有了更深入的理解。主要内容包括:
- datetime64的精度的选择策略:介绍了
datetime64的多种精度及其与内存占用的关系,并展示了如何选择合适的精度。 - 滑动窗口统计的向量化实现:详细讲解了滑动窗口统计的基本原理,并通过示例展示了如何使用
NumPy的向量化操作实现滑动平均值。 - 时区转换的位操作优化:介绍了时区转换的基本原理,并通过位操作进行了优化的演示。
- 金融高频交易数据处理实战:通过一个股票tick数据清洗的完整流程,展示了如何使用
NumPy处理千万级时间序列数据,并进行了与Pandas的性能对比。
希望这些内容对你有所帮助,如果你有任何问题或建议,欢迎在评论区留言。我们下一篇文章再见!
参考资料
| 资料名称 | 链接 |
|---|---|
| NumPy 官方文档 | https://numpy.org/doc/stable/ |
| datetime64 类型 | https://numpy.org/doc/stable/reference/arrays.datetime.html |
| 内存占用与精度关系 | https://numpy.org/doc/stable/user/basics.types.html |
| 滑动窗口统计 | https://towardsdatascience.com/rolling-functions-in-numpy-23df47881d68 |
| 位操作优化 | https://www.geeksforgeeks.org/python-bitwise-operators/ |
| pytz 时区库 | https://pypi.org/project/pytz/ |
| Pandas 官方文档 | https://pandas.pydata.org/pandas-docs/stable/index.html |
| 股票tick数据清洗 | https://realpython.com/finance-python-time-series/ |
| 金融数据处理 | https://www.mathworks.com/help/econ/financial-times-series-tutorial.html |
| 高效数据处理 | https://docs.scipy.org/doc/scipy/reference/tutorial/optimize.html |
| 时间序列分析 | https://www.sciencedirect.com/topics/computer-science/time-series-analysis |
| 数据清洗技术 | https://www.datacamp.com/community/tutorials/data-cleaning-python |
| 时区转换优化 | https://docs.python.org/3/library/datetime.html#timezone-objects |
如果你觉得这篇文章对你有帮助,感谢点赞、收藏和关注!关注我,了解更多 Python 和 NumPy 的实用技巧。
相关文章:
【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】1.17 时间魔法:处理千万级时间序列的秘籍
1.17 时间魔法:处理千万级时间序列的秘籍 目录 #mermaid-svg-fa6SvjKCpmJ6C2BY {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-fa6SvjKCpmJ6C2BY .error-icon{fill:#552222;}#mermaid-svg-fa6SvjKCpmJ6…...

WPS数据分析000009
一、函数与数据透视表统计数据时效率差异 函数 F4绝对引用 数据透视表 二、数据透视表基础操作 数据透视表:一个快速的生成报表的工具 显示详细信息 方式一; 方式二: 移动数据透视表 删除数据透视表 复制粘贴数据透视表 留足空间,否则拖动字…...

Ansible自动化运维实战--script、unarchive和shell模块(6/8)
文章目录 一、script模块1.1、功能1.2、常用参数1.3、举例 二、unarchive模块2.1、功能2.2、常用参数2.3、举例 三、shell模块3.1、功能3.2、常用参数3.3、举例 一、script模块 1.1、功能 Ansible 的 script 模块允许你在远程主机上运行本地的脚本文件,其提供了一…...

K8S 快速实战
K8S 核心架构原理: 我们已经知道了 K8S 的核心功能:自动化运维管理多个容器化程序。那么 K8S 怎么做到的呢?这里,我们从宏观架构上来学习 K8S 的设计思想。首先看下图: K8S 是属于主从设备模型(Master-Slave 架构),即有 Master 节点负责核心的调度、管理和运维,Slave…...

用Python和PyQt5打造一个股票涨幅统计工具
在当今的金融市场中,股票数据的实时获取和分析是投资者和金融从业者的核心需求之一。无论是个人投资者还是专业机构,都需要一个高效的工具来帮助他们快速获取股票数据并进行分析。本文将带你一步步用Python和PyQt5打造一个股票涨幅统计工具,不…...

linux naive代理设置
naive linux客户端 Release v132.0.6834.79-2 klzgrad/naiveproxy GitHub Client setup Run ./naive with the following config.json to get a SOCKS5 proxy at local port 1080. {"listen": "socks://127.0.0.1:1080","proxy": "htt…...
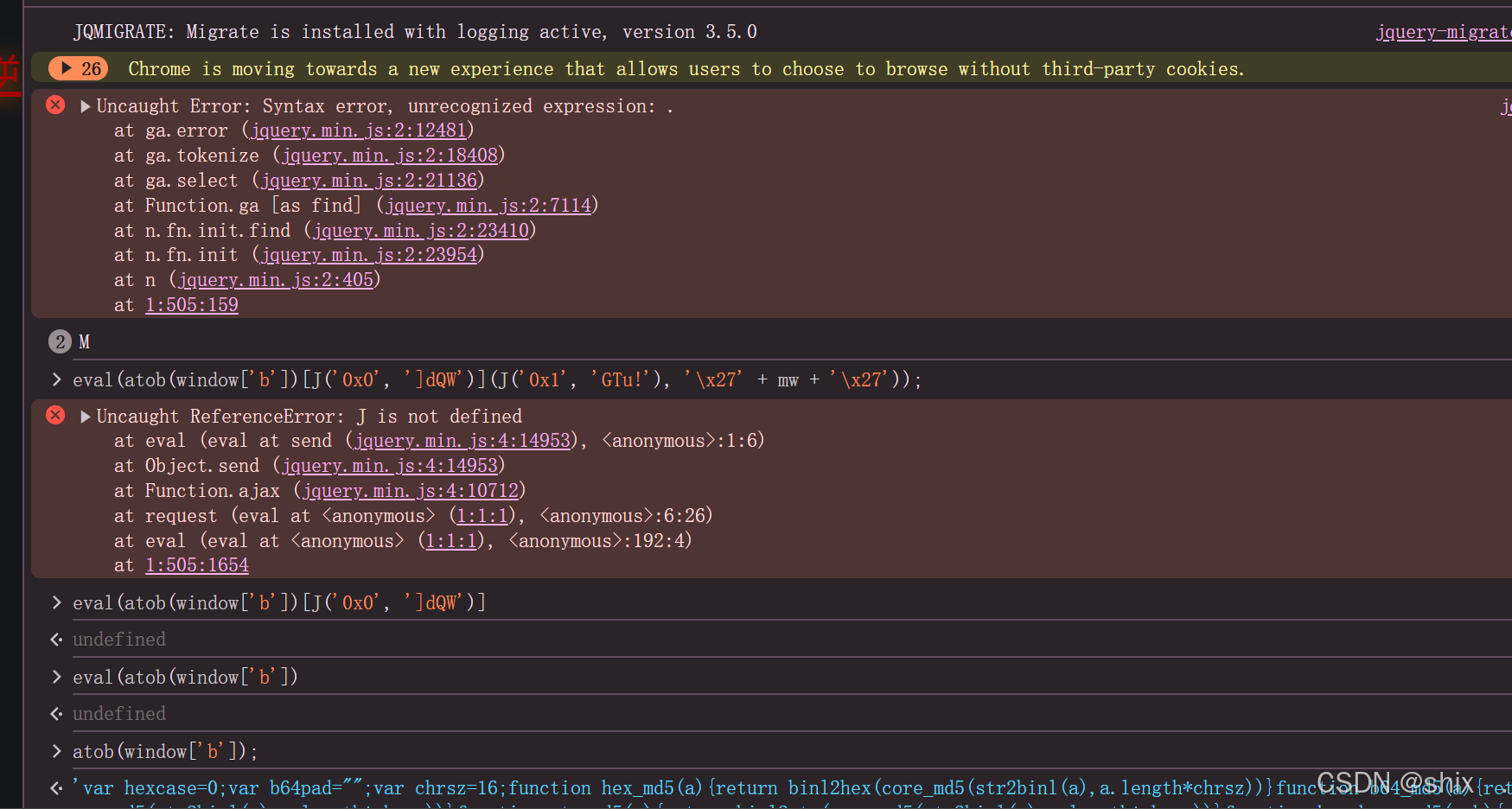
猿人学第一题 js混淆源码乱码
首先检查刷新网络可知,m参数被加密,这是一个ajax请求 那么我们直接去定位该路径 定位成功 观察堆栈之后可以分析出来这应该是一个混淆,我们放到解码平台去还原一下 window["url"] "/api/match/1";request function…...

【学术会议征稿】第五届能源、电力与先进热力系统学术会议(EPATS 2025)
能源、电力与先进热力系统设计是指结合物理理论、工程技术和计算机模拟,对能源转换、利用和传输过程进行设计的学科领域。它涵盖了从能源的生产到最终的利用整个流程,旨在提高能源利用效率,减少能源消耗和环境污染。 重要信息 官网…...
对神经网络基础的理解
目录 一、《python神经网络编程》 二、一些粗浅的认识 1) 神经网络也是一种拟合 2)神经网络不是真的大脑 3)网络构建需要反复迭代 三、数字图像识别的实现思路 1)建立一个神经网络类 2)权重更新的具体实现 3&am…...
用法)
.strip()用法
.strip("") 是 Python 字符串方法 strip() 的一个用法,它会去除字符串两端指定字符集中的字符。 基本语法: string.strip([chars])string: 这是你要操作的字符串。chars: 可选参数,表示你想要去除的字符集(默认为空格…...

redis的分片集群模式
redis的分片集群模式 1 主从哨兵集群的问题和分片集群特点 主从哨兵集群可应对高并发写和高可用性,但是还有2个问题没有解决: (1)海量数据存储 (2)高并发写的问题 使用分片集群可解决,分片集群…...

【29】Word:李楠-学术期刊❗
目录 题目 NO1.2.3.4.5 NO6.7.8 NO9.10.11 NO12.13.14.15 NO16 题目 NO1.2.3.4.5 另存为手动/F12Fn光标来到开头位置处→插入→封面→选择花丝→根据样例图片,对应位置填入对应文字 (手动调整即可)复制样式:开始→样式对话框→管理…...

基于 AI Coding 「RTC + STT」 Web Demo
文章目录 1. 写在最前面1.1 旧测试流程1.2 新测试流程 2. Cursor 编程 vs Copilot 编程2.1 coding 速度2.2 coding 正确性 3. 碎碎念 1. 写在最前面 为了 Fix 语音转文字(STT)产品在 Json 协议支持上的问题,笔者需要将推送到 RTC 的数据按照…...

doris:Parquet导入数据
本文介绍如何在 Doris 中导入 Parquet 格式的数据文件。 支持的导入方式 以下导入方式支持 Parquet 格式的数据导入: Stream LoadBroker LoadINSERT INTO FROM S3 TVFINSERT INTO FROM HDFS TVF 使用示例 本节展示了不同导入方式下的 Parquet 格式使用方法…...

L2TP使用举例
下面是一个使用C和POSIX套接字API实现L2TP协议的简单示例。这个示例展示了如何创建一个L2TP客户端,连接到L2TP服务器并发送数据。请注意,这只是一个基本的示例,实际的L2TP实现会更复杂,通常需要处理更多的协议细节和错误处理。 L…...

dup2 + fgets + printf 实现文件拷贝
思路 将源文件的内容读取到内存中,然后将这些内容写入到目标文件。 1: 打开源文件、目标文件 fopen() 以读模式打开源文件。 open ()以写模式打开目标文件。 2: 读取源文件、写入目标文件 fgets ()从源文件中读取内容。 printf ()将内容写入目标文件。 printf…...
)
实验六 带函数查询和综合查询(1)
实验六 带函数查询和综合查询(1) 一、实验目的 1.掌握Management Studio的使用。 2.掌握带函数查询和综合查询的使用。 二、实验内容及要求 1统计年龄大于30岁的学生的人数。 select count(*) from student where year(getdate…...
:大阿卡那牌)
塔罗牌(基础):大阿卡那牌
塔罗牌(基础) 大啊卡那牌魔术师女祭司皇后皇帝教皇恋人战车力量隐士命运之轮正义吊人死神节制恶魔高塔星星月亮太阳审判世界 大啊卡那牌 魔术师 作为一个起点,象征:意识行动和创造力。 一个【显化】的概念,即是想法变…...

LLM大模型推理中的常见数字
1. 聊天机器人Chatbot,一般,input tokens : output tokens 1100:15 2. LLama2的tokenizer,中文情况下,token:汉字1:1.01 3. prefilling阶段的吞吐量(tokens/s),一般是decoding阶段的50~100倍。 4. 4张带有NVLink的…...

[ACTF2020 新生赛]Upload1
题目 以为是前端验证,试了一下PHP传不上去 可以创建一个1.phtml文件。对.phtml文件的解释: 是一个嵌入了PHP脚本的html页面。将以下代码写入该文件中 <script languagephp>eval($_POST[md]);</script><script languagephp>system(cat /flag);&l…...

SpringBoot整合Swagger UI 用于提供接口可视化界面
目录 一、引入相关依赖 二、添加配置文件 三、测试 四、Swagger 相关注解 一、引入相关依赖 图像化依赖 Swagger UI 用于提供可视化界面: <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactI…...

深度学习项目--基于LSTM的糖尿病预测探究(pytorch实现)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 LSTM模型一直是一个很经典的模型,一般用于序列数据预测,这个可以很好的挖掘数据上下文信息,本文将使用LSTM进行糖尿病…...

LeetCode - Google 大模型校招10题 第1天 Attention 汇总 (3题)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/145368666 GroupQueryAttention(分组查询注意力机制) 和 KVCache(键值缓存) 是大语言模型中的常见架构,GroupQueryAttention 是注意力…...

人工智能研究报告:技术、应用与未来趋势洞察
一、引言 1.1 研究背景 在当今科技飞速发展的时代,人工智能(Artificial Intelligence,简称 AI)已成为最为关键的技术领域之一。它犹如一股强大的变革力量,正深刻地重塑着各行业的发展格局,对社会的各个层…...

Kotlin开发(七):对象表达式、对象声明和委托的奥秘
Kotlin 让代码更优雅! 每个程序员都希望写出优雅高效的代码,但现实往往不尽人意。对象表达式、对象声明和 Kotlin 委托正是为了解决代码中的复杂性而诞生的。为什么选择这个主题?因为它不仅是 Kotlin 语言的亮点之一,还能极大地提…...

数据库、数据仓库、数据湖有什么不同
数据库、数据仓库和数据湖是三种不同的数据存储和管理技术,它们在用途、设计目标、数据处理方式以及适用场景上存在显著差异。以下将从多个角度详细说明它们之间的区别: 1. 数据结构与存储方式 数据库: 数据库主要用于存储结构化的数据&…...

【2024年华为OD机试】 (B卷,100分)- 字符串摘要(JavaScriptJava PythonC/C++)
一、问题描述 题目描述 给定一个字符串的摘要算法,请输出给定字符串的摘要值。具体步骤如下: 去除字符串中非字母的符号:只保留字母字符。处理连续字符:如果出现连续字符(不区分大小写),则输…...

DIY QMK量子键盘
最近放假了,趁这个空余在做一个分支项目,一款机械键盘,量子键盘取自固件名称QMK(Quantum Mechanical Keyboard)。 键盘作为计算机或其他电子设备的重要输入设备之一,通过将按键的物理动作转换为数字信号&am…...

mamba论文学习
rnn 1986 训练速度慢 testing很快 但是很快就忘了 lstm 1997 训练速度慢 testing很快 但是也会忘(序列很长的时候) GRU实在lstm的基础上改进,改变了一些门 transformer2017 训练很快,testing慢些,时间复杂度高&am…...

智慧消防营区一体化安全管控 2024 年度深度剖析与展望
在 2024 年,智慧消防营区一体化安全管控领域取得了令人瞩目的进展,成为保障营区安全稳定运行的关键力量。这一年,行业在政策驱动、技术创新应用、实践成果及合作交流等方面呈现出多元且深刻的发展态势,同时也面临着一系列亟待解决…...