【2024年华为OD机试】 (C卷,200分)- 机器人走迷宫(JavaScriptJava PythonC/C++)

一、问题描述
题目描述
房间由X * Y的方格组成,每个方格用坐标(x, y)描述。机器人从(0, 0)出发,只能向东或向北前进,出口在(X-1, Y-1)。房间中有一些墙壁,机器人不能经过。有些方格是陷阱(B),一旦到达就无法走到出口。有些方格是不可达的(A),机器人无法到达这些方格。要求计算陷阱方格和不可达方格的数量。
输入描述
- 第一行:房间的X和Y(0 < X, Y <= 1000)
- 第二行:墙壁的个数N(0 <= N < X*Y)
- 接下来N行:每行一个墙壁的坐标
输出描述
- 陷阱方格与不可达方格的数量,两个信息在一行中输出,以一个空格隔开。
题目解析
1. 初始化地图
- 用1标记墙壁,0标记非墙壁。
- 地图的x轴为行数,y轴为列数。
2. 深度优先搜索(DFS)
- 从起点(0, 0)开始DFS,标记可达的方格。
- 对于每个方格,检查其东边和北边的方格是否可达。
- 如果东边和北边的方格都是死路(墙壁或越界),则当前方格是陷阱。
- 如果只有一边是死路,继续DFS。
3. 处理终点
- 在DFS之前,将终点(X-1, Y-1)标记为活路(2),以避免错误判断终点为死路。
4. 统计结果
- 陷阱方格:标记为-1的方格数量。
- 不可达方格:标记为0的方格数量。
示例
示例1
输入:
6 4
5
0 2
1 2
2 2
4 1
5 1
输出:
2 3
说明:
- 陷阱方格有2个,不可达方格有3个。
示例2
输入:
6 4
4
2 0
2 1
3 0
3 1
输出:
0 4
说明:
- 没有陷阱方格,不可达方格有4个。
注意事项
- Python代码可能会出现递归过深的问题,可以适当增大递归的最大深度限制。
import sys
sys.setrecursionlimit(2500)
通过以上步骤,可以有效地计算出陷阱方格和不可达方格的数量。
二、JavaScript算法源码
以下是代码的详细注释和讲解,帮助理解每一部分的功能和实现逻辑:
代码结构
-
输入处理部分:
- 使用
readline模块读取控制台输入。 - 将输入数据解析为房间大小、墙壁数量以及墙壁坐标。
- 使用
-
核心逻辑部分:
- 初始化地图矩阵,标记墙壁和终点。
- 使用深度优先搜索(DFS)从起点开始遍历,标记可达点和陷阱点。
- 统计陷阱点和不可达点的数量。
-
DFS 函数:
- 递归检查当前点的东边和北边是否可达。
- 根据可达性标记当前点的状态。
代码详细注释
/* JavaScript Node ACM模式 控制台输入获取 */
const readline = require("readline");// 创建 readline 接口,用于从控制台读取输入
const rl = readline.createInterface({input: process.stdin,output: process.stdout,
});// 存储输入的行数据
const lines = [];
let x, y, n, poses; // x: 房间的行数,y: 房间的列数,n: 墙壁数量,poses: 墙壁坐标// 监听每一行输入
rl.on("line", (line) => {lines.push(line); // 将输入的行数据存入 lines 数组// 当输入行数为 2 时,解析房间大小和墙壁数量if (lines.length === 2) {[x, y] = lines[0].split(" ").map(Number); // 解析房间大小n = lines[1] - 0; // 解析墙壁数量}// 当输入行数等于 n + 2 时,解析墙壁坐标并计算结果if (n !== undefined && lines.length === n + 2) {poses = lines.slice(2).map((line) => line.split(" ").map(Number)); // 解析墙壁坐标console.log(getResult()); // 调用 getResult 函数计算结果并输出lines.length = 0; // 清空 lines 数组,准备下一次输入}
});// 计算陷阱点和不可达点的数量
function getResult() {// 初始化地图矩阵,大小为 x 行 y 列,初始值为 0(非墙)const matrix = new Array(x).fill(0).map(() => new Array(y).fill(0));// 标记墙壁位置为 1for (let [i, j] of poses) {matrix[i][j] = 1; // 墙标记为 1}// 标记终点为 2(可达点)matrix[x - 1][y - 1] = 2;// 从起点 (0, 0) 开始 DFS 遍历dfs(0, 0, matrix);let trap = 0; // 陷阱数量let unreach = 0; // 不可达点数量// 遍历整个矩阵,统计陷阱点和不可达点的数量for (let i = 0; i < x; i++) {for (let j = 0; j < y; j++) {if (matrix[i][j] == 0) unreach++; // 值为 0 表示不可达点else if (matrix[i][j] == -1) trap++; // 值为 -1 表示陷阱点}}// 返回结果,格式为 "陷阱数量 不可达点数量"return `${trap} ${unreach}`;
}// 深度优先搜索(DFS)函数
function dfs(cx, cy, matrix) {// 如果当前点越界,则不可达if (cx >= x || cy >= y) return false;// 如果当前点是墙(1),则不可达if (matrix[cx][cy] == 1) return false;// 如果当前点已经是陷阱点(-1),则不可达if (matrix[cx][cy] == -1) return false;// 如果当前点已经是可达点(2),则可达if (matrix[cx][cy] == 2) return true;// 如果当前点是未标记点(0),则进行 DFS 检查if (matrix[cx][cy] == 0) {// 向东走一步,检查东边点是否可达const east = dfs(cx + 1, cy, matrix);// 向北走一步,检查北边点是否可达const north = dfs(cx, cy + 1, matrix);// 如果东边或北边有一个可达,则当前点可达,标记为 2if (east || north) {matrix[cx][cy] = 2;} else {// 如果东边和北边都不可达,则当前点是陷阱点,标记为 -1matrix[cx][cy] = -1;}}// 返回当前点是否可达return matrix[cx][cy] == 2;
}
代码逻辑讲解
-
输入处理:
- 使用
readline模块逐行读取输入。 - 解析房间大小
x和y,以及墙壁数量n。 - 解析墙壁坐标并存储在
poses数组中。
- 使用
-
地图初始化:
- 创建一个大小为
x * y的二维数组matrix,初始值为0(表示非墙)。 - 将墙壁位置标记为
1。 - 将终点
(x-1, y-1)标记为2(表示可达点)。
- 创建一个大小为
-
DFS 遍历:
- 从起点
(0, 0)开始递归遍历。 - 对于每个点,检查其东边和北边的点是否可达。
- 如果东边或北边有一个可达,则当前点可达,标记为
2。 - 如果东边和北边都不可达,则当前点是陷阱点,标记为
-1。
- 从起点
-
统计结果:
- 遍历整个矩阵,统计值为
-1的陷阱点数量和值为0的不可达点数量。 - 返回结果,格式为
陷阱数量 不可达点数量。
- 遍历整个矩阵,统计值为
关键点总结
- DFS 递归:通过递归检查每个点的东边和北边,确定当前点的可达性。
- 标记规则:
0:未标记点(不可达点)。1:墙壁。2:可达点。-1:陷阱点。
- 终点处理:终点
(x-1, y-1)初始标记为2,确保其可达性影响前面的点。
通过以上注释和讲解,可以清晰地理解代码的实现逻辑和每一步的作用。
三、Java算法源码
以下是代码的详细注释和讲解,帮助理解每一部分的功能和实现逻辑:
代码结构
-
输入处理部分:
- 使用
Scanner读取输入数据。 - 解析房间大小、墙壁数量以及墙壁坐标。
- 使用
-
核心逻辑部分:
- 初始化地图矩阵,标记墙壁和终点。
- 使用深度优先搜索(DFS)从起点开始遍历,标记可达点和陷阱点。
- 统计陷阱点和不可达点的数量。
-
DFS 函数:
- 递归检查当前点的东边和北边是否可达。
- 根据可达性标记当前点的状态。
代码详细注释
import java.util.Scanner;public class Main {static int x; // 房间的行数static int y; // 房间的列数static int n; // 墙壁的数量static int[][] poses; // 墙壁的坐标static int[][] matrix; // 地图矩阵public static void main(String[] args) {Scanner sc = new Scanner(System.in);// 读取房间大小x = sc.nextInt(); // 行数y = sc.nextInt(); // 列数// 读取墙壁数量n = sc.nextInt();// 读取墙壁坐标poses = new int[n][2]; // 墙壁坐标数组for (int i = 0; i < n; i++) {poses[i][0] = sc.nextInt(); // 墙壁的行坐标poses[i][1] = sc.nextInt(); // 墙壁的列坐标}// 调用核心逻辑函数getResult();}// 核心逻辑函数public static void getResult() {// 初始化地图矩阵,大小为 x 行 y 列,初始值为 0(非墙)matrix = new int[x][y];// 标记墙壁位置为 1for (int[] pos : poses) {int i = pos[0]; // 墙壁的行坐标int j = pos[1]; // 墙壁的列坐标matrix[i][j] = 1; // 墙标记为 1}// 标记终点为 2(可达点)matrix[x - 1][y - 1] = 2;// 从起点 (0, 0) 开始 DFS 遍历dfs(0, 0);int trap = 0; // 陷阱数量int unreach = 0; // 不可达点数量// 遍历整个矩阵,统计陷阱点和不可达点的数量for (int i = 0; i < x; i++) {for (int j = 0; j < y; j++) {if (matrix[i][j] == 0) unreach++; // 值为 0 表示不可达点else if (matrix[i][j] == -1) trap++; // 值为 -1 表示陷阱点}}// 输出结果,格式为 "陷阱数量 不可达点数量"System.out.println(trap + " " + unreach);}// 深度优先搜索(DFS)函数public static boolean dfs(int cx, int cy) {// 如果当前点越界,则不可达if (cx >= x || cy >= y) return false;// 如果当前点是墙(1),则不可达if (matrix[cx][cy] == 1) return false;// 如果当前点已经是陷阱点(-1),则不可达if (matrix[cx][cy] == -1) return false;// 如果当前点已经是可达点(2),则可达if (matrix[cx][cy] == 2) return true;// 如果当前点是未标记点(0),则进行 DFS 检查if (matrix[cx][cy] == 0) {// 向东走一步,检查东边点是否可达boolean east = dfs(cx + 1, cy);// 向北走一步,检查北边点是否可达boolean north = dfs(cx, cy + 1);// 如果东边或北边有一个可达,则当前点可达,标记为 2if (east || north) {matrix[cx][cy] = 2;} else {// 如果东边和北边都不可达,则当前点是陷阱点,标记为 -1matrix[cx][cy] = -1;}}// 返回当前点是否可达return matrix[cx][cy] == 2;}
}
代码逻辑讲解
-
输入处理:
- 使用
Scanner读取房间大小x和y,以及墙壁数量n。 - 解析墙壁坐标并存储在
poses数组中。
- 使用
-
地图初始化:
- 创建一个大小为
x * y的二维数组matrix,初始值为0(表示非墙)。 - 将墙壁位置标记为
1。 - 将终点
(x-1, y-1)标记为2(表示可达点)。
- 创建一个大小为
-
DFS 遍历:
- 从起点
(0, 0)开始递归遍历。 - 对于每个点,检查其东边和北边的点是否可达。
- 如果东边或北边有一个可达,则当前点可达,标记为
2。 - 如果东边和北边都不可达,则当前点是陷阱点,标记为
-1。
- 从起点
-
统计结果:
- 遍历整个矩阵,统计值为
-1的陷阱点数量和值为0的不可达点数量。 - 输出结果,格式为
陷阱数量 不可达点数量。
- 遍历整个矩阵,统计值为
关键点总结
- DFS 递归:通过递归检查每个点的东边和北边,确定当前点的可达性。
- 标记规则:
0:未标记点(不可达点)。1:墙壁。2:可达点。-1:陷阱点。
- 终点处理:终点
(x-1, y-1)初始标记为2,确保其可达性影响前面的点。
通过以上注释和讲解,可以清晰地理解代码的实现逻辑和每一步的作用。
四、Python算法源码
以下是代码的详细注释和讲解,帮助理解每一部分的功能和实现逻辑:
代码结构
-
输入处理部分:
- 使用
input()读取输入数据。 - 解析房间大小、墙壁数量以及墙壁坐标。
- 使用
-
核心逻辑部分:
- 初始化地图矩阵,标记墙壁和终点。
- 使用深度优先搜索(DFS)从起点开始遍历,标记可达点和陷阱点。
- 统计陷阱点和不可达点的数量。
-
DFS 函数:
- 递归检查当前点的东边和北边是否可达。
- 根据可达性标记当前点的状态。
代码详细注释
import sys
sys.setrecursionlimit(2500) # 设置递归深度限制,防止递归过深报错# 输入获取
x, y = map(int, input().split()) # 读取房间大小 x(行数)和 y(列数)
n = int(input()) # 读取墙壁数量
poses = [list(map(int, input().split())) for _ in range(n)] # 读取墙壁坐标# 深度优先搜索(DFS)函数
def dfs(cx, cy, matrix):# 如果当前点越界,则不可达if cx >= x or cy >= y:return False# 如果当前点是墙(1),则不可达if matrix[cx][cy] == 1:return False# 如果当前点已经是陷阱点(-1),则不可达if matrix[cx][cy] == -1:return False# 如果当前点已经是可达点(2),则可达if matrix[cx][cy] == 2:return True# 如果当前点是未标记点(0),则进行 DFS 检查if matrix[cx][cy] == 0:# 向东走一步,检查东边点是否可达east = dfs(cx + 1, cy, matrix)# 向北走一步,检查北边点是否可达north = dfs(cx, cy + 1, matrix)# 如果东边或北边有一个可达,则当前点可达,标记为 2if east or north:matrix[cx][cy] = 2else:# 如果东边和北边都不可达,则当前点是陷阱点,标记为 -1matrix[cx][cy] = -1# 返回当前点是否可达return matrix[cx][cy] == 2# 算法入口
def getResult():# 初始化地图矩阵,大小为 x 行 y 列,初始值为 0(非墙)matrix = [[0 for _ in range(y)] for _ in range(x)]# 标记墙壁位置为 1for i, j in poses:matrix[i][j] = 1 # 墙标记为 1# 标记终点为 2(可达点)matrix[x - 1][y - 1] = 2# 从起点 (0, 0) 开始 DFS 遍历dfs(0, 0, matrix)trap = 0 # 陷阱数量unreach = 0 # 不可达点数量# 遍历整个矩阵,统计陷阱点和不可达点的数量for i in range(x):for j in range(y):if matrix[i][j] == 0:unreach += 1 # 值为 0 表示不可达点elif matrix[i][j] == -1:trap += 1 # 值为 -1 表示陷阱点# 返回结果,格式为 "陷阱数量 不可达点数量"return f"{trap} {unreach}"# 算法调用
print(getResult())
代码逻辑讲解
-
输入处理:
- 使用
input()读取房间大小x和y,以及墙壁数量n。 - 解析墙壁坐标并存储在
poses列表中。
- 使用
-
地图初始化:
- 创建一个大小为
x * y的二维列表matrix,初始值为0(表示非墙)。 - 将墙壁位置标记为
1。 - 将终点
(x-1, y-1)标记为2(表示可达点)。
- 创建一个大小为
-
DFS 遍历:
- 从起点
(0, 0)开始递归遍历。 - 对于每个点,检查其东边和北边的点是否可达。
- 如果东边或北边有一个可达,则当前点可达,标记为
2。 - 如果东边和北边都不可达,则当前点是陷阱点,标记为
-1。
- 从起点
-
统计结果:
- 遍历整个矩阵,统计值为
-1的陷阱点数量和值为0的不可达点数量。 - 输出结果,格式为
陷阱数量 不可达点数量。
- 遍历整个矩阵,统计值为
关键点总结
- DFS 递归:通过递归检查每个点的东边和北边,确定当前点的可达性。
- 标记规则:
0:未标记点(不可达点)。1:墙壁。2:可达点。-1:陷阱点。
- 终点处理:终点
(x-1, y-1)初始标记为2,确保其可达性影响前面的点。
通过以上注释和讲解,可以清晰地理解代码的实现逻辑和每一步的作用。
五、C/C++算法源码:
以下是 C++ 和 C语言 版本的代码实现,包含详细的中文注释和代码讲解。
C++ 版本
代码实现
#include <iostream>
#include <vector>
using namespace std;int x, y; // 房间的行数和列数
int n; // 墙壁的数量
vector<vector<int>> matrix; // 地图矩阵// 深度优先搜索(DFS)函数
bool dfs(int cx, int cy) {// 如果当前点越界,则不可达if (cx >= x || cy >= y) return false;// 如果当前点是墙(1),则不可达if (matrix[cx][cy] == 1) return false;// 如果当前点已经是陷阱点(-1),则不可达if (matrix[cx][cy] == -1) return false;// 如果当前点已经是可达点(2),则可达if (matrix[cx][cy] == 2) return true;// 如果当前点是未标记点(0),则进行 DFS 检查if (matrix[cx][cy] == 0) {// 向东走一步,检查东边点是否可达bool east = dfs(cx + 1, cy);// 向北走一步,检查北边点是否可达bool north = dfs(cx, cy + 1);// 如果东边或北边有一个可达,则当前点可达,标记为 2if (east || north) {matrix[cx][cy] = 2;} else {// 如果东边和北边都不可达,则当前点是陷阱点,标记为 -1matrix[cx][cy] = -1;}}// 返回当前点是否可达return matrix[cx][cy] == 2;
}// 算法入口
void getResult() {// 初始化地图矩阵,大小为 x 行 y 列,初始值为 0(非墙)matrix = vector<vector<int>>(x, vector<int>(y, 0));// 标记墙壁位置为 1for (int i = 0; i < n; i++) {int cx, cy;cin >> cx >> cy;matrix[cx][cy] = 1;}// 标记终点为 2(可达点)matrix[x - 1][y - 1] = 2;// 从起点 (0, 0) 开始 DFS 遍历dfs(0, 0);int trap = 0; // 陷阱数量int unreach = 0; // 不可达点数量// 遍历整个矩阵,统计陷阱点和不可达点的数量for (int i = 0; i < x; i++) {for (int j = 0; j < y; j++) {if (matrix[i][j] == 0) unreach++; // 值为 0 表示不可达点else if (matrix[i][j] == -1) trap++; // 值为 -1 表示陷阱点}}// 输出结果,格式为 "陷阱数量 不可达点数量"cout << trap << " " << unreach << endl;
}int main() {// 读取房间大小cin >> x >> y;// 读取墙壁数量cin >> n;// 调用核心逻辑函数getResult();return 0;
}
C++ 代码讲解
-
输入处理:
- 使用
cin读取房间大小x和y,以及墙壁数量n。 - 使用二维向量
matrix存储地图信息。
- 使用
-
地图初始化:
- 将墙壁位置标记为
1。 - 将终点
(x-1, y-1)标记为2(表示可达点)。
- 将墙壁位置标记为
-
DFS 遍历:
- 从起点
(0, 0)开始递归遍历。 - 对于每个点,检查其东边和北边的点是否可达。
- 如果东边或北边有一个可达,则当前点可达,标记为
2。 - 如果东边和北边都不可达,则当前点是陷阱点,标记为
-1。
- 从起点
-
统计结果:
- 遍历整个矩阵,统计值为
-1的陷阱点数量和值为0的不可达点数量。 - 输出结果,格式为
陷阱数量 不可达点数量。
- 遍历整个矩阵,统计值为
C语言版本
代码实现
#include <stdio.h>
#include <stdbool.h>int x, y; // 房间的行数和列数
int n; // 墙壁的数量
int matrix[1000][1000]; // 地图矩阵(假设最大大小为 1000x1000)// 深度优先搜索(DFS)函数
bool dfs(int cx, int cy) {// 如果当前点越界,则不可达if (cx >= x || cy >= y) return false;// 如果当前点是墙(1),则不可达if (matrix[cx][cy] == 1) return false;// 如果当前点已经是陷阱点(-1),则不可达if (matrix[cx][cy] == -1) return false;// 如果当前点已经是可达点(2),则可达if (matrix[cx][cy] == 2) return true;// 如果当前点是未标记点(0),则进行 DFS 检查if (matrix[cx][cy] == 0) {// 向东走一步,检查东边点是否可达bool east = dfs(cx + 1, cy);// 向北走一步,检查北边点是否可达bool north = dfs(cx, cy + 1);// 如果东边或北边有一个可达,则当前点可达,标记为 2if (east || north) {matrix[cx][cy] = 2;} else {// 如果东边和北边都不可达,则当前点是陷阱点,标记为 -1matrix[cx][cy] = -1;}}// 返回当前点是否可达return matrix[cx][cy] == 2;
}// 算法入口
void getResult() {// 初始化地图矩阵,大小为 x 行 y 列,初始值为 0(非墙)for (int i = 0; i < x; i++) {for (int j = 0; j < y; j++) {matrix[i][j] = 0;}}// 标记墙壁位置为 1for (int i = 0; i < n; i++) {int cx, cy;scanf("%d %d", &cx, &cy);matrix[cx][cy] = 1;}// 标记终点为 2(可达点)matrix[x - 1][y - 1] = 2;// 从起点 (0, 0) 开始 DFS 遍历dfs(0, 0);int trap = 0; // 陷阱数量int unreach = 0; // 不可达点数量// 遍历整个矩阵,统计陷阱点和不可达点的数量for (int i = 0; i < x; i++) {for (int j = 0; j < y; j++) {if (matrix[i][j] == 0) unreach++; // 值为 0 表示不可达点else if (matrix[i][j] == -1) trap++; // 值为 -1 表示陷阱点}}// 输出结果,格式为 "陷阱数量 不可达点数量"printf("%d %d\n", trap, unreach);
}int main() {// 读取房间大小scanf("%d %d", &x, &y);// 读取墙壁数量scanf("%d", &n);// 调用核心逻辑函数getResult();return 0;
}
C语言代码讲解
-
输入处理:
- 使用
scanf读取房间大小x和y,以及墙壁数量n。 - 使用二维数组
matrix存储地图信息。
- 使用
-
地图初始化:
- 将墙壁位置标记为
1。 - 将终点
(x-1, y-1)标记为2(表示可达点)。
- 将墙壁位置标记为
-
DFS 遍历:
- 从起点
(0, 0)开始递归遍历。 - 对于每个点,检查其东边和北边的点是否可达。
- 如果东边或北边有一个可达,则当前点可达,标记为
2。 - 如果东边和北边都不可达,则当前点是陷阱点,标记为
-1。
- 从起点
-
统计结果:
- 遍历整个矩阵,统计值为
-1的陷阱点数量和值为0的不可达点数量。 - 输出结果,格式为
陷阱数量 不可达点数量。
- 遍历整个矩阵,统计值为
通过以上代码和注释,可以清晰地理解 C++ 和 C语言 版本的实现逻辑和每一步的作用。
六、尾言
什么是华为OD?
华为OD(Outsourcing Developer,外包开发工程师)是华为针对软件开发工程师岗位的一种招聘形式,主要包括笔试、技术面试以及综合面试等环节。尤其在笔试部分,算法题的机试至关重要。
为什么刷题很重要?
-
机试是进入技术面的第一关:
华为OD机试(常被称为机考)主要考察算法和编程能力。只有通过机试,才能进入后续的技术面试环节。 -
技术面试需要手撕代码:
技术一面和二面通常会涉及现场编写代码或算法题。面试官会注重考察候选人的思路清晰度、代码规范性以及解决问题的能力。因此提前刷题、多练习是通过面试的重要保障。 -
入职后的可信考试:
入职华为后,还需要通过“可信考试”。可信考试分为三个等级:- 入门级:主要考察基础算法与编程能力。
- 工作级:更贴近实际业务需求,可能涉及复杂的算法或与工作内容相关的场景题目。
- 专业级:最高等级,考察深层次的算法以及优化能力,与薪资直接挂钩。
刷题策略与说明:
2024年8月14日之后,华为OD机试的题库转为 E卷,由往年题库(D卷、A卷、B卷、C卷)和全新题目组成。刷题时可以参考以下策略:
-
关注历年真题:
- 题库中的旧题占比较大,建议优先刷历年的A卷、B卷、C卷、D卷题目。
- 对于每道题目,建议深度理解其解题思路、代码实现,以及相关算法的适用场景。
-
适应新题目:
- E卷中包含全新题目,需要掌握全面的算法知识和一定的灵活应对能力。
- 建议关注新的刷题平台或交流群,获取最新题目的解析和动态。
-
掌握常见算法:
华为OD考试通常涉及以下算法和数据结构:- 排序算法(快速排序、归并排序等)
- 动态规划(背包问题、最长公共子序列等)
- 贪心算法
- 栈、队列、链表的操作
- 图论(最短路径、最小生成树等)
- 滑动窗口、双指针算法
-
保持编程规范:
- 注重代码的可读性和注释的清晰度。
- 熟练使用常见编程语言,如C++、Java、Python等。
如何获取资源?
-
官方参考:
- 华为招聘官网或相关的招聘平台会有一些参考信息。
- 华为OD的相关公众号可能也会发布相关的刷题资料或学习资源。
-
加入刷题社区:
- 找到可信的刷题交流群,与其他备考的小伙伴交流经验。
- 关注知名的刷题网站,如LeetCode、牛客网等,这些平台上有许多华为OD的历年真题和解析。
-
寻找系统性的教程:
- 学习一本经典的算法书籍,例如《算法导论》《剑指Offer》《编程之美》等。
- 完成系统的学习课程,例如数据结构与算法的在线课程。
积极心态与持续努力:
刷题的过程可能会比较枯燥,但它能够显著提升编程能力和算法思维。无论是为了通过华为OD的招聘考试,还是为了未来的职业发展,这些积累都会成为重要的财富。
考试注意细节
-
本地编写代码
- 在本地 IDE(如 VS Code、PyCharm 等)上编写、保存和调试代码,确保逻辑正确后再复制粘贴到考试页面。这样可以减少语法错误,提高代码准确性。
-
调整心态,保持冷静
- 遇到提示不足或实现不确定的问题时,不必慌张,可以采用更简单或更有把握的方法替代,确保思路清晰。
-
输入输出完整性
- 注意训练和考试时都需要编写完整的输入输出代码,尤其是和题目示例保持一致。完成代码后务必及时调试,确保功能符合要求。
-
快捷键使用
- 删除行可用
Ctrl+D,复制、粘贴和撤销分别为Ctrl+C,Ctrl+V,Ctrl+Z,这些可以正常使用。 - 避免使用
Ctrl+S,以免触发浏览器的保存功能。
- 删除行可用
-
浏览器要求
- 使用最新版的 Google Chrome 浏览器完成考试,确保摄像头开启并正常工作。考试期间不要切换到其他网站,以免影响考试成绩。
-
交卷相关
- 答题前,务必仔细查看题目示例,避免遗漏要求。
- 每完成一道题后,点击【保存并调试】按钮,多次保存和调试是允许的,系统会记录得分最高的一次结果。完成所有题目后,点击【提交本题型】按钮。
- 确保在考试结束前提交试卷,避免因未保存或调试失误而丢分。
-
时间和分数安排
- 总时间:150 分钟;总分:400 分。
- 试卷结构:2 道一星难度题(每题 100 分),1 道二星难度题(200 分)。及格分为 150 分。合理分配时间,优先完成自己擅长的题目。
-
考试环境准备
- 考试前请备好草稿纸和笔。考试中尽量避免离开座位,确保监控画面正常。
- 如需上厕所,请提前规划好时间以减少中途离开监控的可能性。
-
技术问题处理
- 如果考试中遇到断电、断网、死机等技术问题,可以关闭浏览器并重新打开试卷链接继续作答。
- 出现其他问题,请第一时间联系 HR 或监考人员进行反馈。
祝你考试顺利,取得理想成绩!
相关文章:
【2024年华为OD机试】 (C卷,200分)- 机器人走迷宫(JavaScriptJava PythonC/C++)
一、问题描述 题目描述 房间由X * Y的方格组成,每个方格用坐标(x, y)描述。机器人从(0, 0)出发,只能向东或向北前进,出口在(X-1, Y-1)。房间中有一些墙壁,机器人不能经过。有些方格是陷阱(B),…...

DAY01 面向对象回顾、继承、抽象类
学习目标 能够写出类的继承格式public class 子类 extends 父类{}public class Cat extends Animal{} 能够说出继承的特点子类继承父类,就会自动拥有父类非私有的成员 能够说出子类调用父类的成员特点1.子类有使用子类自己的2.子类没有使用,继承自父类的3.子类父类都没有编译报…...

Leetcode — 罗马数字转整数
Leetcode — 罗马数字转整数 文章目录 Leetcode — 罗马数字转整数前言题目示例 1:示例 2:示例 3:示例 4:示例 5:提示: 实现CCJava 前言 虽入大厂好多年,但算法不刷还是不会。人到中年…...

leetcode刷题记录(八十一)——236. 二叉树的最近公共祖先
(一)问题描述 236. 二叉树的最近公共祖先 - 力扣(LeetCode)236. 二叉树的最近公共祖先 - 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。百度百科 [https://baike.baidu.com/item/%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B…...

PyTorch入门 - 为什么选择PyTorch?
PyTorch入门 - 为什么选择PyTorch? Entry to PyTorch - Why PyTorch? by JacksonML $ pip install pytorch安装完毕后,可以使用以下命令,导入第三方库。 $ import pytorch...
)
kafka-保姆级配置说明(consumer)
bootstrap.servers #deserializer应该与producer保持对应 #key.deserializer #value.deserializer ##fetch请求返回时,至少获取的字节数,默认值为1 ##当数据量不足时,客户端请求将会阻塞 ##此值越大,客户端请求阻塞的时间越长&…...

[创业之路-269]:《创业讨论会》- 系统之韵:从麻雀到5G系统的共通性探索
关键词: 从系统的角度,麻雀、人体系统、企业系统、软硬件系统、软件系统、通信系统、5G系统是类似的: 都有:内在看不见的规律、外在显性各种现象 都是:输入、处理、输出 都是:静态、要素、组成、结构、组织…...

Typesrcipt泛型约束详细解读
代码示例: // 如果我们直接对一个泛型参数取 length 属性, 会报错, 因为这个泛型根本就不知道它有这个属性 (() > {// 定义一个接口,用来约束将来的某个类型中必须要有length这个属性interface ILength{// 接口中有一个属性lengthlength:number}function getLen…...

2025春招 SpringCloud 面试题汇总
大家好,我是 V 哥。SpringCloud 在面试中属于重灾区,不仅是基础概念、组件细节,还有高级特性、性能优化,关键是项目实践经验的解决方案,都是需要掌握的内容,正所谓打有准备的仗,秒杀面试官&…...

STM32新建不同工程的方式
新建工程的方式 1. 安装开发工具 MDK5 / keil52. CMSIS 标准3. 新建工程3.1 寄存器版工程3.2 标准库版工程3.3 HAL/LL库版工程3.4 HAL库、LL库、标准库和寄存器对比3.5 库开发和寄存器的关系 4. STM32CubeMX工具的作用 1. 安装开发工具 MDK5 / keil5 MDK5 由两个部分组成&#…...

Linux相关概念和易错知识点(26)(命名管道、共享内存)
目录 1.命名管道 (1)匿名管道 -> 命名管道 ①匿名管道 ②命名管道 (2)命名管道的使用 ①创建和删除命名管道文件 ②命名管道文件的特性 ③命名管道和匿名管道的区别 (3)用命名管道实现进程间通信…...

K8S 启动探测、就绪探测、存活探测
先来思考一个问题: 在 Deployment 执行滚动更新 web 应用的时候,总会出现一段时间,Pod 对外提供网络访问,但是页面访问却发生404,这个问题要如何解决呢?学完今天的内容,相信你会有自己的答案。 …...

2024年度总结——理想的风,吹进现实
2024年悄然过去,留下了太多美好的回忆,不得不感慨一声时间过得真快啊!旧年风雪尽,新岁星河明。写下这篇博客,记录我独一无二的2024年。这一年,理想的风终于吹进现实! 如果用一句话总结这一年&am…...

Python从0到100(八十五):神经网络-使用迁移学习完成猫狗分类
前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能…...

hadoop==docker desktop搭建hadoop
hdfs map readuce yarn https://medium.com/guillermovc/setting-up-hadoop-with-docker-and-using-mapreduce-framework-c1cd125d4f7b 清理资源 docker-compose down docker system prune -f...

Linux下的编辑器 —— vim
目录 1.什么是vim 2.vim的模式 认识常用的三种模式 三种模式之间的切换 命令模式和插入模式的转化 命令模式和底行模式的转化 插入模式和底行模式的转化 3.命令模式下的命令集 光标移动相关的命令 复制粘贴相关命令 撤销删除相关命令 查找相关命令 批量化注释和去…...

C25.【C++ Cont】初识运算符的重载和sort函数
目录 1.为什么要引入运算符重载 2.运算符重载写法 格式 例子 示例代码 运行结果 3.sort函数 两种声明 声明1:默认情况 参数 示例代码1:排整型 示例代码2:排浮点数 编辑 示例代码3:排字符串 声明2:自定义情况 参数 comp比较函数的两种写法 写法1:创建比较函…...

粒子群算法 笔记 数学建模
引入: 如何找到全局最大值:如果只是贪心的话,容易被局部最大解锁定 方法有:盲目搜索,启发式搜索 盲目搜索:枚举法和蒙特卡洛模拟,但是样例太多花费巨量时间 所以启发式算法就来了,通过经验和规…...

深入理解若依RuoYi-Vue数据字典设计与实现
深入理解若依数据字典设计与实现 一、Vue2版本主要文件目录 组件目录src/components:数据字典组件、字典标签组件 工具目录src/utils:字典工具类 store目录src/store:字典数据 main.js:字典数据初始化 页面使用字典例子…...

实战网络安全:渗透测试与防御指南
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 引言 在数字化时代,网络安全已成为企业和个人不可忽视的重要课题。网络攻击的复杂性与日俱增,从数据泄露…...

SpringBoot+Electron教务管理系统 附带详细运行指导视频
文章目录 一、项目演示二、项目介绍三、运行截图四、主要代码1.查询课程表代码2.保存学生信息代码3.用户登录代码 一、项目演示 项目演示地址: 视频地址 二、项目介绍 项目描述:这是一个基于SpringBootElectron框架开发的教务管理系统。首先ÿ…...
)
正在更新丨豆瓣电影详细数据的采集与可视化分析(scrapy+mysql+matplotlib+flask)
文章目录 豆瓣电影详细数据的采集与可视化分析(scrapy+mysql+matplotlib+flask)写在前面数据采集0.注意事项1.创建Scrapy项目`douban2025`2.用`PyCharm`打开项目3.创建爬虫脚本`douban.py`4.修改`items.py`的代码5.修改`pipelines.py`代码6.修改`settings.py`代码7.启动`doub…...

Ubuntu-手动安装 SBT
文章目录 前言Ubuntu-手动安装 SBT1. SBT是什么?1.1. SBT 的特点1.2. SBT 的基本功能1.3. SBT 的常用命令 2. 安装2.1. 下载2.2. 解压 sbt 二进制包2.3. 确认 sbt 可执行文件的位置2.4. 设置执行权限2.5. 创建符号链接2.6. 更新 PATH 环境变量2.7. 验证 sbt 安装 前言 如果您觉…...

详解最基本的数据顺序存储结构:顺序表
新的一年,我觉得这张图很合适!有梦想,敢拼,马上就是除夕了,希望新的一年我们逢考必过,事事顺心,看见朝阳的你是不是嘴角微微上扬! 本篇从0基础白话文讲述顺序表的概念、用法、注意事…...
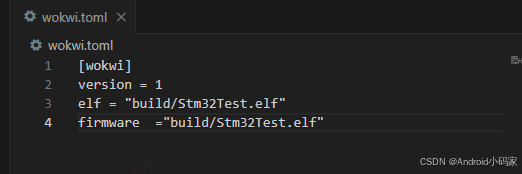
STM32使用VScode开发
文章目录 Makefile形式创建项目新建stm项目下载stm32cubemx新建项目IED makefile保存到本地arm gcc是编译的工具链G++配置编译Cmake +vscode +MSYS2方式bilibiliMSYS2 统一环境配置mingw32-make -> makewindows环境变量Cmake CmakeListnijia 编译输出elfCMAKE_GENERATOR查询…...

前端react后端java实现提交antd form表单成功即导出压缩包
前端(React Ant Design) 1. 创建表单:使用<Form>组件来创建你的表单。 2. 处理表单提交:在onFinish回调中发起请求到后端API,并处理响应。 import React from react; import { Form, Input, Button } from ant…...

vue2中trhee.js加载模型展示天空盒子
创建相机 this.camera new THREE.PerspectiveCamera(45,this.viewNode.clientWidth / t…...

安装Office自定义项,安装期间出错
个人博客地址:安装Office自定义项,安装期间出错 | 一张假钞的真实世界 卸载PowerDesigner后,打开“WPS文字”时出现下图错误: 解决方法: 按“WinR”快捷键,打开【运行】框,在对话框中输入“re…...

代码审查中的自动化与AI应用
代码审查(Code Review)作为软件开发中的一项重要实践,通常被认为是提高代码质量、减少bug和提升团队协作的重要手段。随着开发规模的不断扩大,手动代码审查在效率、准确性、以及可扩展性上都存在明显的局限性。尤其是在敏捷开发和…...

蓝桥杯模拟算法:蛇形方阵
P5731 【深基5.习6】蛇形方阵 - 洛谷 | 计算机科学教育新生态 我们只要定义两个方向向量数组,这种问题就可以迎刃而解了 比如我们是4的话,我们从左向右开始存,1,2,3,4 到5的时候y就大于4了就是越界了&…...