Java8_StreamAPI
Stream

1.创建流
1.1 集合创建流
List<String> list = List.of("a", "b", "c");
Stream<String> stream = list.stream();
stream.forEach(System.out::println);
1.2 数组创建流
String[] array = {"a","b","c"};
Stream<String> stream = Arrays.stream(array);
stream.forEach(System.out::println);
1.3 Stream.of()
Stream<String> stream = Stream.of("a", "b", "c");
stream.forEach(System.out::println);
合并流:
Stream<String> stream1 = Stream.of("a", "b", "c");
Stream<String> stream2 = Stream.of("e", "f", "g");
Stream<String> concat = Stream.concat(stream1, stream2);
concat.forEach(System.out::println);
1.4 创建一个能动态加入元素的流
Stream.Builder<String> stringBuilder = Stream.builder();
stringBuilder.add("a");
stringBuilder.add("b");
if (Math.random() > 0.5) {stringBuilder.add("c");
}
Stream<String> stream = stringBuilder.build();
stream.forEach(System.out::println);
注: build() 以后就不能再往stream中添加元素, 否则会报IllegalStateException

1.5 从文件创建流
Path path = Paths.get("file.txt");
try (Stream<String> lines = Files.lines(path)){lines.forEach(System.out::println);
} catch (IOException e) {throw new RuntimeException(e);
}
每行文本是一个元素

1.6 创建基本类型的流
以IntStream为例
- IntStream.of
IntStream intStream = IntStream.of(1, 2, 3);
intStream.forEach(System.out::println);
- 创建指定范围的IntStream
IntStream intStream = IntStream.range(1,4);
intStream.forEach(System.out::println);// 1 2 3
IntStream intStream = IntStream.rangeClosed(1,4);
intStream.forEach(System.out::println);// 1 2 3 4
- 创建n个包含随机数的流
IntStream intStream = IntStream.rangeClosed(1,4);
new Random().ints(5).forEach(System.out::println);// 1555978888
// 1191117249
// -1175853188
// 249139444
// -1230944054
- 基本类型的流转为对象流
IntStream intStream = IntStream.rangeClosed(1,4);
Stream<Integer> integerStream = intStream.boxed();
1.7 创建无限流
generate:
- 生个n个相同元素的流
Stream<String> stream = Stream.generate(() -> "kiddkid").limit(4);
// 防止无限流生成, 限制个数
stream.forEach(System.out::println);
// kiddkid
// kiddkid
// kiddkid
// kiddkid
- 生成含n个随机数的流
Stream.generate(Math::random).limit(5).forEach(System.out::println);
// 0.9578029464950379
// 0.03290878021143662
// 0.7683317134743166
// 0.7188884787961349
// 0.8739307746551834
iterate生成数学序列或实现迭代算法
// // (起始元素, 生成条件)
Stream<Integer> stream = Stream.iterate(0, n -> n + 2).limit(10);
stream.forEach(System.out::println);
0
2
4
6
8
// (起始元素, 结束条件, 生成条件)
Stream<Integer> stream = Stream.iterate(0,n -> n <= 10, n -> n + 2);
stream.forEach(System.out::println);
1.8 创建并行流
- 在已有流的基础上创建并行流
Stream<Integer> stream = Stream.iterate(0,n -> n <= 10, n -> n + 2);
Stream<Integer> parallel = stream.parallel();
- 集合直接创建并行流
List.of("a","b","c").parallelStream().forEach(System.out::println);// b c a
2.流的中间操作

2.1 筛选和切片
- 根据条件筛选
List<Person> people = List.of(new Person("Neo",45, "USA"),new Person("Stan",10,"USA"),new Person("Grace",16, "UK"),new Person("Alex",20,"UK"),new Person("Sebastian",40,"FR")
);
people.stream().filter(person -> person.getAge() > 18).forEach(System.out::println);
Person{name=‘Neo’, age=45, country=‘USA’}
Person{name=‘Alex’, age=20, country=‘UK’}
Person{name=‘Sebastian’, age=40, country=‘FR’}
- 元素去重
Stream.of("apple","orange","apple","orange","cherry").distinct().forEach(System.out::println);
apple
orange
cherry
对自定义类要重写equals 和 hashCode:
List<Person> people = List.of(new Person("Neo",45, "USA"),new Person("Stan",10,"USA"),new Person("Grace",16, "UK"),new Person("Alex",20,"UK"),new Person("Alex",20,"UK"),new Person("Sebastian",40,"FR"),new Person("Sebastian",40,"FR")
);
people.stream().distinct().forEach(System.out::println);
Person{name=‘Neo’, age=45, country=‘USA’}
Person{name=‘Stan’, age=10, country=‘USA’}
Person{name=‘Grace’, age=16, country=‘UK’}
Person{name=‘Alex’, age=20, country=‘UK’}
Person{name=‘Sebastian’, age=40, country=‘FR’}
- limit 截取流中指定个数的元素
List<Person> people = List.of(new Person("Neo",45, "USA"),new Person("Stan",10,"USA"),new Person("Grace",16, "UK"),new Person("Alex",20,"UK"),new Person("Sebastian",40,"FR")
);
people.stream().limit(2).forEach(System.out::println);
Person{name=‘Neo’, age=45, country=‘USA’}
Person{name=‘Stan’, age=10, country=‘USA’}
注: 若指定元素个数大于整个流的长度, 将会返回整个流
- skip 省略流中指定个数的元素
List<Person> people = List.of(new Person("Neo",45, "USA"),new Person("Stan",10,"USA"),new Person("Grace",16, "UK"),new Person("Alex",20,"UK"),new Person("Sebastian",40,"FR")
);
people.stream().skip(2).forEach(System.out::println);
Person{name=‘Grace’, age=16, country=‘UK’}
Person{name=‘Alex’, age=20, country=‘UK’}
Person{name=‘Sebastian’, age=40, country=‘FR’}
- map 改变流中元素的类型
List<Person> people = List.of(new Person("Neo",45, "USA"),new Person("Stan",10,"USA"),new Person("Grace",16, "UK"),new Person("Alex",20,"UK"),new Person("Sebastian",40,"FR")
);
Stream<Person> stream = people.stream();
Stream<String> nameStream = stream.map(person -> person.getName());
nameStream.forEach(System.out::println);
Neo
Stan
Grace
Alex
Sebastian
2.2 映射
- flatMap实现单层流

List<List<Person>> peopleGroup = List.of(List.of(new Person("Neo",45, "USA"),new Person("Stan",10,"USA")),List.of(new Person("Grace",16, "UK"),new Person("Alex",20,"UK")),List.of(new Person("Sebastian",40,"FR"))
);
Stream<List<Person>> peopleGroupStream = peopleGroup.stream();
peopleGroupStream.forEach(System.out::println);
[Person{name=‘Neo’, age=45, country=‘USA’}, Person{name=‘Stan’, age=10, country=‘USA’}]
[Person{name=‘Grace’, age=16, country=‘UK’}, Person{name=‘Alex’, age=20, country=‘UK’}]
[Person{name=‘Sebastian’, age=40, country=‘FR’}]
修改:
peopleGroupStream.flatMap(people -> people.stream()).forEach(System.out::println);
Person{name=‘Neo’, age=45, country=‘USA’}
Person{name=‘Stan’, age=10, country=‘USA’}
Person{name=‘Grace’, age=16, country=‘UK’}
Person{name=‘Alex’, age=20, country=‘UK’}
Person{name=‘Sebastian’, age=40, country=‘FR’}
注: 流的操作应该是链式操作, 不能对同一个流进行多次操作
Stream<List<Person>> peopleGroupStream = peopleGroup.stream();
Stream<Person> personStream = peopleGroupStream.flatMap(Collection::stream);
peopleGroupStream.limit(1);

链式操作如下:
peopleGroup.stream().flatMap(Collection::stream).map(Person::getName).forEach(System.out::println);
// or 两者实现效果相同
peopleGroup.stream().flatMap(people -> people.stream().map(Person::getName)).forEach(System.out::println);
Neo
Stan
Grace
Alex
Sebastian
flatMap可以实现任何map的操作, 同时将流转为单层流
- 将流映射为指定类型的流
List<Person> people = List.of(new Person("Neo", 45, "USA"),new Person("Stan", 10, "USA"),new Person("Grace", 16, "UK"),new Person("Alex", 20, "UK"),new Person("Sebastian", 40, "FR")
);
IntStream intStream = people.stream().mapToInt(Person::getAge);
intStream.forEach(System.out::println);
45
10
16
20
40
2.3 排序
排序分为自然排序和自定义排序。
- 当流中的元素类型实现了Comparable接口的时候,可以直接调用无参数的sorted(), 按照自然顺序进行排序。
Stream.of("blueberry","cherry","apple","pear").sorted().forEach(System.out::println);
apple
blueberry
cherry
pear
- 可以定义一个比较器去自定义比较规则。
Stream.of("blueberry","cherry","apple","pear").sorted(Comparator.comparingInt(String::length)).forEach(System.out::println);
pear
apple
cherry
blueberry
Stream.of("blueberry","cherry","apple","pear").sorted(Comparator.comparingInt(String::length).reversed()).forEach(System.out::println);
blueberry
cherry
apple
pear
2.4 综合实践
List<List<Person>> peopleGroup = List.of(List.of(new Person("Neo",45, "USA"),new Person("Stan",10,"USA")),List.of(new Person("Grace",16, "UK"),new Person("Alex",20,"UK"),new Person("Alex",20,"UK")),List.of(new Person("Sebastian",40,"FR"),new Person("Sebastian",40,"FR"))
);peopleGroup.stream().flatMap(people -> people.stream()).filter(person -> person.getAge() > 18).distinct().sorted(Comparator.comparingInt(Person::getAge).reversed()).map(Person::getName).limit(3).skip(1).forEach(System.out::println);
Sebastian
Alex

我们通常用变量来保存中间操作的结果,以便在需要的时候触发执行.
3.终端操作

Stream 的终结操作通常会返回单个值,一旦一个 Stream 实例上的终结操作被调用,流内部元素的迭代以及流处理调用链上的中间操作就会开始执行,当迭代结束后,终结操作的返回值将作为整个流处理的返回值被返回。
anyMatch
anyMatch() 方法以一个 Predicate (java.util.function.Predicate 接口,它代表一个接收单个参数并返回参数是否匹配的函数)作为参数,启动 Stream 的内部迭代,并将 Predicate 参数应用于每个元素。如果 Predicate 对任何元素返回了 true(表示满足匹配),则 anyMatch() 方法的结果返回 true。如果没有元素匹配 Predicate,anyMatch() 将返回 false。
public class StreamAnyMatchExample {public static void main(String[] args) {List<String> stringList = new ArrayList<String>();stringList.add("One flew over the cuckoo's nest");stringList.add("To kill a muckingbird");stringList.add("Gone with the wind");Stream<String> stream = stringList.stream();boolean anyMatch = stream.anyMatch((value) -> value.startsWith("One"));System.out.println(anyMatch);}
}
上面例程的运行结果是 true , 因为流中第一个元素就是以 “One” 开头的,满足 anyMatch 设置的条件。
allMatch
allMatch() 方法同样以一个 Predicate 作为参数,启动 Stream 中元素的内部迭代,并将 Predicate 参数应用于每个元素。如果 Predicate 为 Stream 中的所有元素都返回 true,则 allMatch() 的返回结果为 true。如果不是所有元素都与 Predicate 匹配,则 allMatch() 方法返回 false。
public class StreamAllMatchExample {public static void main(String[] args) {List<String> stringList = new ArrayList<String>();stringList.add("One flew over the cuckoo's nest");stringList.add("To kill a muckingbird");stringList.add("Gone with the wind");Stream<String> stream = stringList.stream();boolean allMatch = stream.allMatch((value) -> value.startsWith("One"));System.out.println(allMatch);}
}
上面的例程我们把流上用的 anyMatch 换成了 allMatch ,结果可想而知会返回 false,因为并不是所有元素都是以 “One” 开头的。
noneMatch
Match 系列里还有一个 noneMatch 方法,顾名思义,如果流中的所有元素都与作为 noneMatch 方法参数的 Predicate 不匹配,则方法会返回 true,否则返回 false。
public class StreamNoneExample {public static void main(String[] args) {List<String> stringList = new ArrayList<>();stringList.add("abc");stringList.add("def");Stream<String> stream = stringList.stream();boolean noneMatch = stream.noneMatch((element) -> {return "xyz".equals(element);});System.out.println("noneMatch = " + noneMatch); //输出 noneMatch = true}
}
collect
collect() 方法被调用后,会启动元素的内部迭代,并将流中的元素收集到集合或对象中。
public class StreamCollectExample {public static void main(String[] args) {List<String> stringList = new ArrayList<>();stringList.add("One flew over the cuckoo's nest");stringList.add("To kill a muckingbird");stringList.add("Gone with the wind");Stream<String> stream = stringList.stream();List<String> stringsAsUppercaseList = stream.map(value -> value.toUpperCase()).collect(Collectors.toList());System.out.println(stringsAsUppercaseList);}
}
collect() 方法将收集器 – Collector (java.util.stream.Collector) 作为参数。在上面的示例中,使用的是 Collectors.toList() 返回的 Collector 实现。这个收集器把流中的所有元素收集到一个 List 中去。
count
count() 方法调用后,会启动 Stream 中元素的迭代,并对元素进行计数。
public class StreamExamples {public static void main(String[] args) {List<String> stringList = new ArrayList<String>();stringList.add("One flew over the cuckoo's nest");stringList.add("To kill a muckingbird");stringList.add("Gone with the wind");Stream<String> stream = stringList.stream();long count = stream.flatMap((value) -> {String[] split = value.split(" ");return Arrays.asList(split).stream();}).count();System.out.println("count = " + count); // count = 14}
}
上面的例程中,首先创建一个字符串 List ,然后获取该 List 的 Stream,为其添加了 flatMap() 和 count() 操作。 count() 方法调用后,流处理将开始迭代 Stream 中的元素,处理过程中字符串元素在 flatMap() 操作中被拆分为单词、合并成一个由单词组成的 Stream,然后在 count() 中进行计数。所以最终打印出的结果是 count = 14。
findAny
findAny() 方法可以从 Stream 中找到单个元素。找到的元素可以来自 Stream 中的任何位置。且它不提供从流中的哪个位置获取元素的保证。
public class StreamFindAnyExample {public static void main(String[] args) {List<String> stringList = new ArrayList<>();stringList.add("one");stringList.add("two");stringList.add("three");stringList.add("one");Stream<String> stream = stringList.stream();Optional<String> anyElement = stream.findAny();if (anyElement.isPresent()) {System.out.println(anyElement.get());} else {System.out.println("not found");}}
}
findAny() 方法会返回一个 Optional,意味着 Stream 可能为空,因此没有返回任何元素。我们可以通过 Optional 的 isPresent() 方法检查是否找到了元素。
Optional 类是一个可以为 null 的容器对象。如果值存在则 isPresent() 方法会返回true,调用get()方法会返回容器中的对象,否则抛出异常:NoSuchElementException
findFirst
findFirst() 方法将查找 Stream 中的第一个元素,跟 findAny() 方法一样,也是返回一个 Optional,我们可以通过 Optional 的 isPresent() 方法检查是否找到了元素。
public class StreamFindFirstExample {public static void main(String[] args) {List<String> stringList = new ArrayList<>();stringList.add("one");stringList.add("two");stringList.add("three");stringList.add("one");Stream<String> stream = stringList.stream();Optional<String> anyElement = stream.findFirst();if (anyElement.isPresent()) {System.out.println(anyElement.get());} else {System.out.println("not found");}}
}
forEach
forEach() 方法我们在介绍 Collection 的迭代时介绍过,当时主要是拿它来迭代 List 的元素。它会启动 Stream 中元素的内部迭代,并将 Consumer (java.util.function.Consumer, 一个函数式接口,上面介绍过) 应用于 Stream 中的每个元素。 注意 forEach() 方法的返回值是 void。
public class StreamExamples {public static void main(String[] args) {List<String> stringList = new ArrayList<String>();stringList.add("one");stringList.add("two");stringList.add("three");Stream<String> stream = stringList.stream();stream.forEach(System.out::println);}
}
注意,上面例程中 forEach 的参数我们直接用了Lambda 表达式引用方法的简写形式。
min
min() 方法返回 Stream 中的最小元素。哪个元素最小是由传递给 min() 方法的 Comparator 接口实现来确定的。
public class StreamMinExample {public static void main(String[] args) {List<String> stringList = new ArrayList<>();stringList.add("abc");stringList.add("def");Stream<String> stream = stringList.stream();// 作为 min 方法参数的Lambda 表达式可以简写成 String::compareTo// Optional<String> min = stream.min(String::compareTo);Optional<String> min = stream.min((val1, val2) -> {return val1.compareTo(val2);});String minString = min.get();System.out.println(minString); // abc}
}
min() 方法返回的是一个 Optional ,也就是它可能不包含结果。如果为空,直接调用 Optional 的 get() 方法将抛出 异常–NoSuchElementException。比如我们把上面的 List 添加元素的两行代码注释掉后,运行程序就会报
Exception in thread "main" java.util.NoSuchElementException: No value presentat java.util.Optional.get(Optional.java:135)at com.example.StreamMinExample.main(StreamMinExample.java:21)
所以最好先用 Optional 的 ifPresent() 判断一下是否包含结果,再调用 get() 获取结果。
max
与 min() 方法相对应,max() 方法会返回 Stream 中的最大元素,max() 方法的参数和返回值跟 min() 方法的也都一样,这里就不再过多阐述了,只需要把上面求最小值的方法替换成求最大值的方法 max() 即可。
Optional<String> min = stream.max(String::compareTo);
reduce
reduce() 方法,是 Stream 的一个聚合方法,它可以把一个 Stream 的所有元素按照聚合函数聚合成一个结果。reduce()方法接收一个函数式接口 BinaryOperator 的实现,它定义的一个apply()方法,负责把上次累加的结果和本次的元素进行运算,并返回累加的结果。
public class StreamReduceExample {public static void main(String[] args) {List<String> stringList = new ArrayList<>();stringList.add("One flew over the cuckoo's nest");stringList.add("To kill a muckingbird");stringList.add("Gone with the wind");Stream<String> stream = stringList.stream();Optional<String> reduced = stream.reduce((value, combinedValue) -> combinedValue + " + " + value);// 写程序的时候记得别忘了 reduced.ifPresent() 检查结果里是否有值System.out.println(reduced.get());}
}
reduce() 方法的返回值同样是一个 Optional 类的对象,所以在获取值前别忘了使用 ifPresent() 进行检查。
stream 实现了多个版本的reduce() 方法,还有可以直接返回元素类型的版本,比如使用 reduce 实现整型Stream的元素的求和
public class IntegerStreamReduceSum {public static void main(String[] args) {List<Integer> intList = new ArrayList<>();intList.add(10);intList.add(9);intList.add(8);intList.add(7);Integer sum = intList.stream().reduce(0, Integer::sum);System.out.printf("List 求和,总和为%s\n", sum);}
}
toArray
toArray() 方法是一个流的终结操作,它会启动流中元素的内部迭代,并返回一个包含所有元素的 Object 数组。
List<String> stringList = new ArrayList<String>();stringList.add("One flew over the cuckoo's nest");
stringList.add("To kill a muckingbird");
stringList.add("Gone with the wind");Stream<String> stream = stringList.stream();Object[] objects = stream.toArray();
不过 toArray 还有一个重载方法,允许传入指定类型数组的构造方法,比如我们用 toArray 把流中的元素收集到字符串数组中,可以这么写:
String[] strArray = stream.toArray(String[]::new);
相关文章:
Java8_StreamAPI
Stream 1.创建流 1.1 集合创建流 List<String> list List.of("a", "b", "c"); Stream<String> stream list.stream(); stream.forEach(System.out::println);1.2 数组创建流 String[] array {"a","b",&qu…...

【架构面试】二、消息队列和MySQL和Redis
MQ MQ消息中间件 问题引出与MQ作用 常见面试问题:面试官常针对项目中使用MQ技术的候选人提问,如如何确保消息不丢失,该问题可考察候选人技术能力。MQ应用场景及作用:以京东系统下单扣减京豆为例,MQ用于交易服和京豆服…...

OpenEuler学习笔记(十六):搭建postgresql高可用数据库环境
以下是在OpenEuler系统上搭建PostgreSQL高可用数据环境的一般步骤,通常可以使用流复制(Streaming Replication)或基于Patroni等工具来实现高可用,以下以流复制为例: 安装PostgreSQL 配置软件源:可以使用O…...

Vue.js路由管理与自定义指令深度剖析
Vue.js 是一个强大的前端框架,提供了丰富的功能来帮助开发者构建复杂的单页应用(SPA)。本文将详细介绍 Vue.js 中的自定义指令和路由管理及导航守卫。通过这些功能,你可以更好地控制视图行为和应用导航,从而提升用户体验和开发效率。 1 自定义指令详解 1.1 什么是自定义…...

skynet 源码阅读 -- 核心概念服务 skynet_context
本文从 Skynet 源码层面深入解读 服务(Service) 的创建流程。从最基础的概念出发,逐步深入 skynet_context_new 函数、相关数据结构(skynet_context, skynet_module, message_queue 等),并通过流程图、结构…...

论文阅读(十一):基因-表型关联贝叶斯网络模型的评分、搜索和评估
1.论文链接:Scoring, Searching and Evaluating Bayesian Network Models of Gene-phenotype Association 摘要: 全基因组关联研究(GWAS)的到来为识别常见疾病的遗传变异(单核苷酸多态性(SNP)&…...

企业微信远程一直显示正在加载
企业微信远程一直显示正在加载 1.问题描述2.问题解决 系统:Win10 1.问题描述 某天使用企业微信给同事进行远程协助的时候,发现一直卡在正在加载的页面,如下图所示 2.问题解决 经过一番查找资料后,我发现可能是2个地方出了问题…...

人工智能 - 1
深度强化学习(Deep Reinforcement Learning) 图神经网络(Graph Neural Networks, GNNs) Transformer 一种深度学习模型 大语言模型(Large Language Models, LLMs) 人工智能 • Marvin Minsky 将其定义…...

留学生scratch计算机haskell函数ocaml编程ruby语言prolog作业VB
您列出了一系列编程语言和技术,这些可能是您在留学期间需要学习或完成作业的内容。以下是对每个项目的简要说明和它们可能涉及的领域或用途: Scratch: Scratch是一种图形化编程语言,专为儿童和初学者设计,用于教授编程…...

LeetCode题练习与总结:最长和谐子序列--594
一、题目描述 和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。 给你一个整数数组 nums ,请你在所有可能的 子序列 中找到最长的和谐子序列的长度。 数组的 子序列 是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素…...
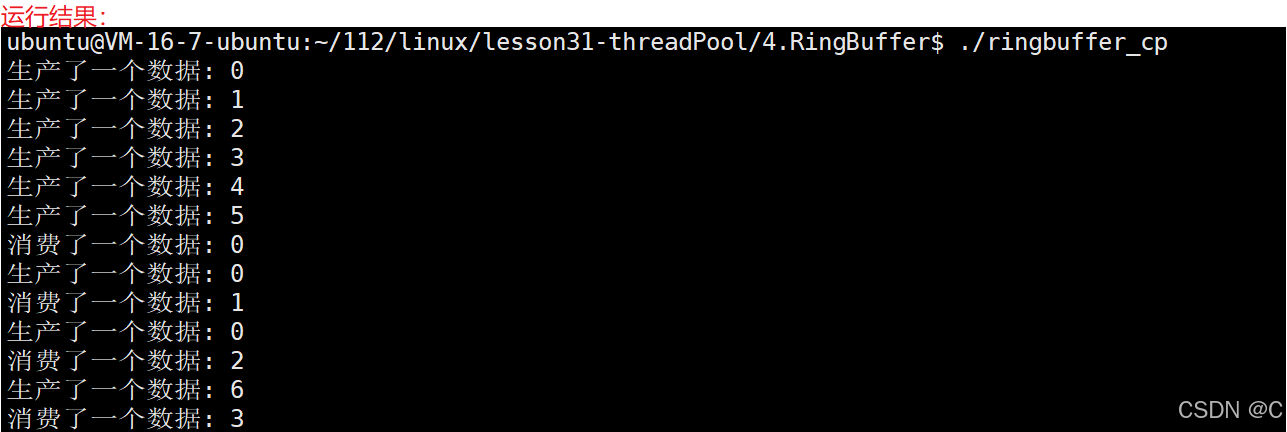
Linux_线程同步生产者消费者模型
同步的相关概念 同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。 同步的…...

Github 2025-01-30 Go开源项目日报 Top10
根据Github Trendings的统计,今日(2025-01-30统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Go项目10Ollama: 本地大型语言模型设置与运行 创建周期:248 天开发语言:Go协议类型:MIT LicenseStar数量:42421 个Fork数量:2724 次关注人…...
)
FortiOS 存在身份验证绕过导致命令执行漏洞(CVE-2024-55591)
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...

【Rust自学】17.2. 使用trait对象来存储不同值的类型
喜欢的话别忘了点赞、收藏加关注哦(加关注即可阅读全文),对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 17.2.1. 需求 这篇文章以一个例子来介绍如何在Rust中使用trait对象来存储不同值的类型。 …...

毛选原文-实践论
实践论 论认识和实践的关系——知和行的关系 (一九三七年七月) 马克思以前的唯物论,离开人的社会性,离开人的历史发展,去观察认识问题,因此不能了解认识对社会实践的依赖关系,即认识对生产…...
)
PPT自动化 python-pptx -7: 占位符(placeholder)
占位符(placeholder)是演示文稿中用于容纳内容的预格式化容器。它们通过让模板设计者定义格式选项,简化了创建视觉一致幻灯片的过程,同时让最终用户专注于添加内容。这加快了演示文稿的开发速度,并确保幻灯片之间的外观…...

VLLM性能调优
1. 抢占 显存不够的时候,某些request会被抢占。其KV cache被清除,腾退给其他request,下次调度到它,重新计算KV cache。 报这条消息,说明已被抢占: WARNING 05-09 00:49:33 scheduler.py:1057 Sequence gr…...
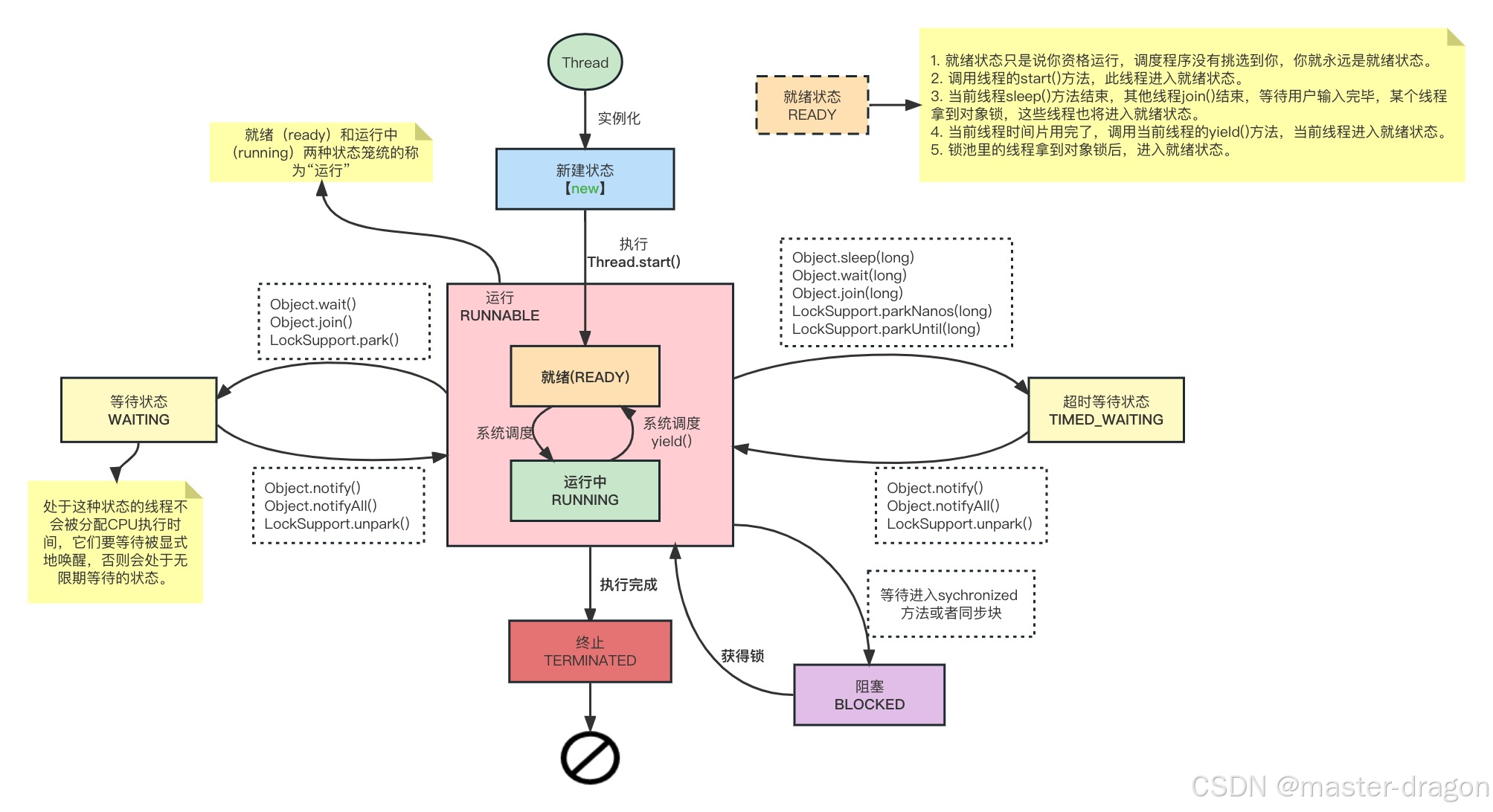
Java线程认识和Object的一些方法
本文目标: 要对Java线程有整体了解,深入认识到里面的一些方法和Object对象方法的区别。认识到Java对象的ObjectMonitor,这有助于后面的Synchronized和锁的认识。利用Synchronized wait/notify 完成一道经典的多线程题目:实现ABC…...

数据库管理-第287期 Oracle DB 23.7新特性一览(20250124)
数据库管理287期 2025-01-24 数据库管理-第287期 Oracle DB 23.7新特性一览(20250124)1 AI向量搜索:算术和聚合运算2 更改Compatible至23.6.0,以使用23.6或更高版本中的新AI向量搜索功能3 Cloud Developer包4 DBMS_DEVELOPER.GET_…...

LruCache实现
LRU最近最少使用算法 一、LRU算法 1.简介 LRU(Least Recently Used,最近最少使用)算法是一种常用的缓存淘汰策略,当缓存达到其容量上限时,它会移除那些最久没有被访问的数据项。这种策略基于这样一个假设࿱…...

DDD架构实战第五讲总结:将领域模型转化为代码
云架构师系列课程之DDD架构实战第五讲总结:将领域模型转化为代码 一、引言 在前几讲中,我们讨论了领域模型的重要性及其在业务分析中的渐进获得方法。本讲将聚焦于如何将领域模型转化为代码,使得开发人员能够更轻松地实现用户的领域模型。 二、从模型到代码:领域驱动设计…...

【MySQL】MySQL客户端连接用 localhost和127.0.0.1的区别
# systemctl status mysqld # ss -tan | grep 3306 # mysql -V localhost与127.0.0.1的区别是什么? 相信有人会说是本地IP,曾有人说,用127.0.0.1比localhost好,可以减少一次解析。 看来这个入门问题还有人不清楚,其实…...

蓝桥杯例题五
无论你面对多大的困难和挑战,都要保持坚定的信念和积极的态度。相信自己的能力和潜力,努力不懈地追求自己的目标和梦想。不要害怕失败,因为失败是成功的垫脚石。相信自己的选择和决策,不要被他人的意见和批评左右。坚持不懈地努力…...

DeepSeek R1本地部署详细指南
DeepSeek R1 是由中国 AI 初创公司深度求索开发的先进推理模型,其性能在数学、编码和逻辑推理等任务上表现出色。在本地部署该模型可以带来更低的延迟、更高的隐私性以及对 AI 应用的更大控制权。本文将详细介绍如何在本地环境中部署 DeepSeek R1 模型。 前提条件 …...

MySQL(高级特性篇) 14 章——MySQL事务日志
事务有4种特性:原子性、一致性、隔离性和持久性 事务的隔离性由锁机制实现事务的原子性、一致性和持久性由事务的redo日志和undo日志来保证(1)REDO LOG称为重做日志,用来保证事务的持久性(2)UNDO LOG称为回…...
爬虫基本原理)
爬虫基础(五)爬虫基本原理
目录 一、爬虫是什么 二、爬虫过程 (1)获取网页 (2)提取信息 (3)保存数据 三、爬虫可爬的数据 四、爬虫问题 一、爬虫是什么 互联网,后面有个网字,我们可以把它看成一张蜘蛛网…...

【Block总结】HWD,小波下采样,适用分类、分割、目标检测等任务|即插即用
论文信息 Haar wavelet downsampling (HWD) 是一项针对语义分割的创新模块,旨在通过减少特征图的空间分辨率来提高深度卷积神经网络(DCNNs)的性能。该论文的主要贡献在于提出了一种新的下采样方法,能够在下采样阶段有效地减少信息…...

【解决方案】MuMu模拟器移植系统进度条卡住98%无法打开
之前在Vmware虚拟机里配置了mumu模拟器,现在想要移植到宿主机中 1、虚拟机中的MuMu模拟器12-1是目标系统,对应的目录如下 C:\Program Files\Netease\MuMu Player 12\vms\MuMuPlayer-12.0-1 2、Vmware-虚拟机-设置-选项,启用共享文件夹 3、复…...

力扣面试150 快乐数 循环链表找环 链表抽象 哈希
Problem: 202. 快乐数 👩🏫 参考题解 Code public class Solution {public int squareSum(int n) {int sum 0;while(n > 0){int digit n % 10;sum digit * digit;n / 10;}return sum;}public boolean isHappy(int n) {int slow n, fast squa…...

安卓(android)实现注册界面【Android移动开发基础案例教程(第2版)黑马程序员】
一、实验目的(如果代码有错漏,可查看源码) 1.掌握LinearLayout、RelativeLayout、FrameLayout等布局的综合使用。 2.掌握ImageView、TextView、EditText、CheckBox、Button、RadioGroup、RadioButton、ListView、RecyclerView等控件在项目中的…...