深度剖析 PyTorch框架:从基础概念到高级应用的深度学习之旅!
目录
一、引言
二、PyTorch 简介
(一)诞生背景与发展历程
(二)核心特点
三、PyTorch 基础概念
(一)张量(Tensor):数据的基石
(二)自动微分(Autograd):梯度计算的利器
(三)计算图(Computational Graph):模型计算的脉络
四、PyTorch 操作使用
(一)安装与配置:开启 PyTorch 之旅
(二)神经网络构建模块:搭建模型的基石
(三)优化算法:驱动模型训练的引擎
(四)数据加载与预处理:模型训练的保障
(五)模型训练、评估与推理:完整的模型生命周期
五、PyTorch 进阶应用
(一)模型保存与加载
(二)使用 GPU 加速
(三)自定义层和模块
(四)分布式训练
(五)量化
六、PyTorch 生态圈
(一)torchvision
(二)torchaudio
(三)torchtext
七、总结
一、引言
在深度学习领域,PyTorch 以其简洁易用、动态计算图等特性脱颖而出,深受开发者和研究人员的喜爱。本文将深入探讨 PyTorch 深度学习框架,从基础概念到实际操作,再到高级应用,结合丰富的实际案例,帮助读者全面掌握这一强大工具,无论是初学者还是有一定基础的读者,都能从中获得有价值的知识和实践经验。
二、PyTorch 简介
(一)诞生背景与发展历程
PyTorch 由 Facebook 人工智能研究实验室(FAIR)开发,于 2017 年开源。它基于 Torch 框架,借助 Python 语言的优势,迅速在深度学习社区中传播开来。随着不断的更新迭代,PyTorch 功能日益丰富,社区也越发活跃,成为了深度学习领域的重要框架之一。
(二)核心特点
- 动态计算图:与静态计算图不同,PyTorch 的动态计算图在运行时构建,这使得开发者能够像编写普通 Python 代码一样进行调试和修改,大大提高了开发效率。例如,在开发一个图像分类模型时,我们可以在运行过程中随时修改网络结构,实时观察模型的变化。
- 简洁易用的 API:PyTorch 的 API 设计简洁直观,符合 Python 的编程习惯。这使得初学者能够快速上手,而有经验的开发者也能高效地构建复杂模型。
- 强大的 GPU 支持:PyTorch 能够充分利用 GPU 的并行计算能力,显著加速模型的训练和推理过程。对于大规模数据集和复杂模型,GPU 加速尤为重要。
- 丰富的生态系统:PyTorch 拥有庞大的开源社区,开发者可以在社区中获取大量的代码示例、教程、预训练模型等资源。同时,torchvision、torchaudio、torchtext 等扩展库,为不同领域的应用提供了有力支持。
三、PyTorch 基础概念
(一)张量(Tensor):数据的基石
张量是 PyTorch 中处理数据的基本单元,是向量和矩阵在高维空间的泛化。在深度学习中,无论是输入数据、模型参数还是中间计算结果,都以张量的形式存在。
创建张量的方式多种多样,例如:
import torch# 从Python列表创建张量
tensor_from_list = torch.tensor([1, 2, 3])# 使用内置函数创建张量
zeros_tensor = torch.zeros(2, 3)
ones_tensor = torch.ones(2, 3)
rand_tensor = torch.rand(2, 3)# 从已有张量创建
new_tensor = torch.ones_like(rand_tensor)# 从NumPy数组创建
import numpy as np
numpy_array = np.array([1, 2, 3])
tensor_from_numpy = torch.from_numpy(numpy_array)PyTorch 提供了丰富的张量操作函数,包括算术操作、形状操作、索引切片、数学函数和统计函数等。
# 算术操作
sum_tensor = torch.add(tensor_from_list, tensor_from_list)# 形状操作
reshaped_tensor = tensor_from_list.view(3, 1)# 索引、切片和连接
sliced_tensor = tensor_from_list[:2]# 数学函数
sqrt_tensor = torch.sqrt(tensor_from_list)# 统计函数
max_value = torch.max(tensor_from_list)(二)自动微分(Autograd):梯度计算的利器
在深度学习模型训练中,计算损失函数相对于模型参数的梯度是关键步骤。PyTorch 的autograd包提供了强大的自动微分功能,能够自动追踪张量的运算历史,实现高效的梯度计算。
# 创建一个需要计算梯度的张量
x = torch.ones(2, 2, requires_grad=True)# 进行张量操作
y = x + 2
z = y * y * 3
out = z.mean()# 反向传播计算梯度
out.backward()# 查看梯度
print(x.grad)在某些情况下,我们可能需要停止梯度追踪,以节省计算资源或避免不必要的梯度计算。可以使用detach()方法或with torch.no_grad():代码块来实现。
# 使用detach()方法停止梯度追踪
x_detached = x.detach()# 使用with torch.no_grad()代码块停止梯度追踪
with torch.no_grad():y = x + 2对于高级用户,还可以自定义梯度函数。例如,自定义 ReLU 函数的梯度:
import torchclass MyReLU(torch.autograd.Function):@staticmethoddef forward(ctx, input_tensor):ctx.save_for_backward(input_tensor)output_tensor = input_tensor.clamp(min=0)return output_tensor@staticmethoddef backward(ctx, grad_output):input_tensor, = ctx.saved_tensorsgrad_input = grad_output.clone()grad_input[input_tensor < 0] = 0return grad_input# 使用自定义的ReLU函数
relu = MyReLU.apply
x = torch.randn(5, 5, requires_grad=True)
y = relu(x)# 计算梯度
z = y.sum()
z.backward()# 查看梯度
print(x.grad)(三)计算图(Computational Graph):模型计算的脉络
计算图是一种有向图,用于描述从输入数据和初始参数到输出结果的计算流程,在深度学习中对梯度计算和模型优化起着关键作用。
PyTorch 主要采用动态计算图,每一次前向传播都会构建一个新的计算图。这种动态特性使得模型构建更加灵活,但也可能会消耗更多的内存和计算资源。
四、PyTorch 操作使用
(一)安装与配置:开启 PyTorch 之旅
安装 PyTorch 可以根据自己的系统环境和需求选择不同的方式。推荐使用conda或pip进行安装。
# 使用pip安装CPU版本
pip install torch torchvision# 使用pip安装GPU版本(需先安装对应CUDA版本)
pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/cu102/torch_stable.html# 使用conda安装CPU版本
conda install pytorch torchvision cpuonly -c pytorch# 使用conda安装GPU版本
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch安装完成后,可以通过运行以下代码验证安装是否成功:
import torch
print(torch.__version__)(二)神经网络构建模块:搭建模型的基石
1. 模块(nn.Module):模型的架构核心
在 PyTorch 中,nn.Module是构建神经网络的基础类。自定义网络层或整个神经网络都需要继承该类,并实现__init__和forward方法。
例如,定义一个简单的线性回归模型:
import torch
import torch.nn as nnclass LinearRegressionModel(nn.Module):def __init__(self, input_dim, output_dim):super(LinearRegressionModel, self).__init__()self.linear = nn.Linear(input_dim, output_dim)def forward(self, x):out = self.linear(x)return out# 创建模型实例
model = LinearRegressionModel(1, 1)nn.Module能够自动跟踪可训练参数,我们可以使用parameters()或named_parameters()方法来获取模型中的所有参数。
# 打印模型的参数
for name, param in model.named_parameters():print(name, param.data)nn.Module支持嵌套结构,这为构建复杂网络架构提供了便利。例如,构建一个简单的多层神经网络:
2. 激活函数:引入非线性的桥梁
激活函数在神经网络中起着至关重要的作用,它为模型引入非线性特性,使神经网络能够逼近复杂的函数关系。
常见的激活函数有 ReLU、Sigmoid、Tanh、Leaky ReLU 和 Softmax 等。在 PyTorch 中,可以方便地使用这些激活函数。
import torch.nn as nn# 使用ReLU激活函数
relu = nn.ReLU()# 使用Sigmoid激活函数
sigmoid = nn.Sigmoid()# 使用Tanh激活函数
tanh = nn.Tanh()# 使用Leaky ReLU激活函数
leaky_relu = nn.LeakyReLU(0.01)# 使用Softmax激活函数
softmax = nn.Softmax(dim=1)在实际应用中,通常在定义网络结构时将激活函数作为一个层添加到nn.Sequential容器中,或者在forward方法中直接调用。
3. nn.Sequential:快速搭建模型的便捷工具
nn.Sequential是 PyTorch 提供的一个容器模块,用于快速堆叠不同的层,构建顺序执行的模型结构。
import torch
import torch.nn as nn# 使用nn.Sequential构建简单多层感知机
model = nn.Sequential(nn.Linear(64, 128),nn.ReLU(),nn.Linear(128, 10)
)# 随机生成一个输入张量
input_tensor = torch.randn(16, 64)# 使用模型进行前向传播
output_tensor = model(input_tensor)nn.Sequential支持嵌套使用,并且可以使用OrderedDict为每一层命名。
4. 损失函数:衡量模型性能的标尺
损失函数用于量化模型预测结果与真实数据之间的差异,是模型训练的关键要素之一。
PyTorch 提供了多种内置的损失函数,如均方误差损失(MSE)、交叉熵损失等。
import torch
import torch.nn as nn# 均方误差损失(用于回归问题)
criterion_mse = nn.MSELoss()
prediction_mse = torch.randn(3, 5, requires_grad=True)
target_mse = torch.randn(3, 5)
loss_mse = criterion_mse(prediction_mse, target_mse)# 交叉熵损失(用于分类问题)
criterion_ce = nn.CrossEntropyLoss()
prediction_ce = torch.randn(3, 5, requires_grad=True)
target_ce = torch.empty(3, dtype=torch.long).random_(5)
loss_ce = criterion_ce(prediction_ce, target_ce)我们还可以自定义损失函数,例如:
class MyCustomLoss(nn.Module):def __init__(self):super(MyCustomLoss, self).__init__()def forward(self, prediction, target):loss = (prediction - target).abs().mean()return loss# 使用自定义损失函数
criterion_custom = MyCustomLoss()
prediction_custom = torch.randn(3, 5, requires_grad=True)
target_custom = torch.randn(3, 5)
loss_custom = criterion_custom(prediction_custom, target_custom)(三)优化算法:驱动模型训练的引擎
1. 梯度下降(Gradient Descent)及其变体
梯度下降是优化模型的基本算法,其核心原理是沿着目标函数梯度的反方向逐步更新参数,以寻找使函数值最小化的参数值。
在 PyTorch 中,梯度下降的变体如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent,SGD)和小批量梯度下降(Mini - batch Gradient Descent)都有相应的实现。
例如,使用小批量梯度下降训练一个简单的线性模型:
2. 其他优化算法(如 Adam, RMSProp 等)
除了梯度下降及其变体,PyTorch 还支持多种其他优化算法。
例如,使用 Adam 优化器:
import torch.optim as optim# 创建模型(假设已定义好模型结构)
model = nn.Linear(2, 1)# 定义损失函数和Adam优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)使用 RMSProp 优化器:
import torch.optim as optim# 创建模型(假设已定义好模型结构)
model = nn.Linear(2, 1)# 定义损失函数和RMSProp优化器
criterion = nn.MSELoss()
optimizer = optim.RMSprop(model.parameters(), lr=0.01)(四)数据加载与预处理:模型训练的保障
在深度学习中,数据加载和预处理是非常重要的环节。PyTorch 提供了torch.utils.data模块来方便地处理数据加载和预处理。
1. 数据集(Dataset)
自定义数据集需要继承torch.utils.data.Dataset类,并实现__len__和__getitem__方法。
例如,创建一个简单的自定义数据集:
2. 数据加载器(DataLoader)
DataLoader用于将数据集按批次加载到模型中进行训练。
from torch.utils.data import DataLoader# 创建数据加载器,设置batch_size为2
data_loader = DataLoader(my_dataset, batch_size=2, shuffle=True)for batch_data, batch_labels in data_loader:print(batch_data)print(batch_labels)
3. 数据预处理
在实际应用中,通常需要对数据进行预处理。可以在__getitem__方法内部实现预处理逻辑,或者使用torchvision.transforms等工具。
例如,对图像数据进行预处理:
from torchvision import transforms# 定义图像预处理步骤
transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((128, 128)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])(五)模型训练、评估与推理:完整的模型生命周期
-
模型训练
以 MNIST 手写数字识别为例,展示完整的模型训练过程:
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim# 数据预处理
transform = transforms.Compose([transforms.ToTensor()])# 加载MNIST数据集
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)test_dataset = datasets.MNIST('./data', train=False, download=True, transform=transform)
test_loader = DataLoader
# 定义模型
class SimpleMLP(nn.Module):def __init__(self):super(SimpleMLP, self).__init__()self.fc1 = nn.Linear(28*28, 128)self.fc2 = nn.Linear(128, 64)self.fc3 = nn.Linear(64, 10)def forward(self, x):x = x.view(-1, 28*28)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return F.log_softmax(x, dim=1)model = SimpleMLP()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()# 模型训练
for epoch in range(5):model.train()for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print('Epoch: {} [{}/{}]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset), loss.item()))-
模型评估
训练完成后,使用测试集对模型进行评估:
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():for data, target in test_loader:output = model(data)test_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))-
模型推理
使用训练好的模型对新数据进行预测:
# 假设有新的数据
new_data = torch.randn(1, 28*28)
with torch.no_grad():output = model(new_data)_, predicted = torch.max(output.data, 1)print(f'Predicted label: {predicted.item()}')五、PyTorch 进阶应用
(一)模型保存与加载
1. 保存模型
可以使用torch.save方法保存模型的参数或整个模型。例如,保存模型参数:
torch.save(model.state_dict(),'model_params.pth')保存整个模型:
torch.save(model,'model.pth')2. 加载模型
加载模型参数:
loaded_model = SimpleMLP()
loaded_model.load_state_dict(torch.load('model_params.pth'))加载整个模型:
loaded_full_model = torch.load('model.pth')(二)使用 GPU 加速
1. 检查 GPU 是否可用
import torch
print(torch.cuda.is_available())2. 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")3. 将模型和数据移动到 GPU
model.to(device)
for data, target in train_loader:data, target = data.to(device), target.to(device)# 训练步骤optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()4. 多 GPU 使用
如果有多个 GPU,可以使用nn.DataParallel进行数据并行处理:
if torch.cuda.device_count() > 1:model = nn.DataParallel(model)
model.to(device)(三)自定义层和模块
在实际应用中,可能需要自定义一些特殊的层或模块。例如,定义一个自定义的卷积层:
class MyConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(MyConv2d, self).__init__()self.weight = nn.Parameter(torch.randn(out_channels, in_channels, kernel_size, kernel_size))self.bias = nn.Parameter(torch.zeros(out_channels))self.stride = strideself.padding = paddingdef forward(self, x):return nn.functional.conv2d(x, self.weight, self.bias, stride=self.stride, padding=self.padding)
(四)分布式训练
分布式训练可以使用多个计算节点来加速深度学习模型的训练。在 PyTorch 中,分布式训练通常通过torch.distributed API 来实现。
1. 初始化分布式环境
import torch.distributed as dist
dist.init_process_group(backend='nccl', init_method='tcp://localhost:23456', rank=0, world_size=1)2.分布式数据并行
from torch.nn.parallel import DistributedDataParallel
model.to(device)
model = DistributedDataParallel(model)3.示例代码
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel# 初始化分布式环境
dist.init_process_group(backend='nccl')# 设备设置
device = torch.device("cuda")# 创建模型和数据
model = SimpleMLP()
model = model.to(device)
model = DistributedDataParallel(model)data_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)# 损失和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练循环
for epoch in range(5):for batch in data_loader:inputs, targets = batch[0].to(device), batch[1].to(device)# 前向传播outputs = model(inputs)# 计算损失loss = criterion(outputs, targets)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()(五)量化
模型量化是一种减小模型大小和提高推理速度的技术,通常以牺牲一定量的模型准确性为代价。PyTorch 提供了一整套的量化工具,支持多种量化方法。
1. 静态量化示例
import torch
import torch.quantization# 准备模型和数据
model = torch.load('model.pth')
model.eval()# 指定量化配置并量化模型
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8
)# 保存量化后的模型
torch.save(quantized_model.state_dict(), 'quantized_model.pth')2. 动态量化示例
import torch
import torch.quantization# 准备模型和数据
model = torch.load('model.pth')
model.eval()# 量化模型
quantized_model = torch.quantization.quantize_dynamic(model)# 保存量化后的模型
torch.save(quantized_model.state_dict(), 'quantized_model.pth')3. 量化感知训练示例
import torch
import torch.quantization# 准备模型
model = SimpleMLP()
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)# 模型训练
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
for epoch in range(5):for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 转换为量化模型
torch.quantization.convert(model, inplace=True)六、PyTorch 生态圈
(一)torchvision
torchvision 是一个与 PyTorch 配合使用的库,用于处理计算机视觉任务。
1. 预训练模型
torchvision 包含了许多预训练的模型,如 VGG、ResNet、MobileNet 等。这些模型可以用于迁移学习或直接用于推理。
import torchvision.models as modelsresnet18 = models.resnet18(pretrained=True)2. 数据集
torchvision 包括常用的计算机视觉数据集,如 CIFAR-10、MNIST、ImageNet 等。
from torchvision.datasets import CIFAR10train_dataset = CIFAR10(root='./data', train=True, transform=None, download=True)3. 数据转换
提供了多种用于图像处理和增强的转换方法。
from torchvision import transformstransform = transforms.Compose([transforms.RandomSizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])4. 示例
使用 torchvision 加载预训练模型并进行图像分类:
import torch
import torchvision.models as models
from torchvision import transforms
from PIL import Image# 加载预训练模型
model = models.resnet18(pretrained=True)
model.eval()# 图像预处理
input_image = Image.open("your_image.jpg")
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)# 推理
with torch.no_grad():output = model(input_batch)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(predicted_idx)(二)torchaudio
torchaudio 是一个专门用于处理音频数据和音频信号处理任务的库。
1. 主要功能
包括数据加载和保存、音频变换、预训练模型和数据集等。
import torchaudio# 读取音频文件
waveform, sample_rate = torchaudio.load('audio_file.wav')# 保存音频文件
torchaudio.save('output_audio_file.wav', waveform, sample_rate)import torchaudio.transforms as T# 创建声谱图
spectrogram = T.Spectrogram()(waveform)# 计算MFCC
mfcc = T.MFCC()(waveform)2. 示例
使用 torchaudio 加载音频文件并计算其 MFCC:
import torchaudio
import torchaudio.transforms as T# 加载音频文件
waveform, sample_rate = torchaudio.load('audio_file.wav')# 计算MFCC
mfcc_transform = T.MFCC(sample_rate=sample_rate,n_mfcc=12,melkwargs={'n_fft': 400,'hop_length': 160,'center': False,'pad_mode':'reflect','power': 2.0,'norm':'slaney','onesided': True}
)
mfcc = mfcc_transform(waveform)print("MFCC Shape:", mfcc.shape)(三)torchtext
torchtext 是一个用于文本处理的库,为自然语言处理(NLP)任务提供了一组工具。
1. 主要功能
涵盖数据加载、文本预处理、词汇表管理、批处理与数据迭代和预训练词向量等。
from torchtext.data import TabularDatasettrain_data, test_data = TabularDataset.splits(path='./data', train='train.csv', test='test.csv', format='csv',fields=[('text', TEXT), ('label', LABEL)]
)from torchtext.data import FieldTEXT = Field(tokenize=custom_tokenize, lower=True)TEXT.build_vocab(train_data, vectors="glove.6B.100d")from torchtext.data import Iterator, BucketIteratortrain_iter, test_iter = BucketIterator.splits((train_data, test_data), batch_size=32, sort_key=lambda x: len(x.text)
)2. 示例
使用 torchtext 进行数据预处理:
from torchtext.data import Field, TabularDataset, BucketIterator# 定义字段
TEXT = Field(sequential=True, tokenize='spacy', lower=True)
LABEL = Field(sequential=False, use_vocab=False)# 创建数据集
fields = {'text': ('text', TEXT), 'label': ('label', LABEL)}
train_data, test_data = TabularDataset.splits(path='./data',train='train.json',test='test.json',format='json',fields=fields
)# 构建词汇表
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')# 创建数据迭代器
train_iterator, test_iterator = BucketIterator.splits((train_data, test_data),batch_size=32,device='cuda'
)七、总结
本文全面介绍了 PyTorch 深度学习框架,从基础概念到实际操作,再到进阶应用和其丰富的生态圈。通过实际案例,读者可以更直观地理解和掌握 PyTorch 的使用方法。无论是深度学习的初学者还是有一定经验的开发者,都可以通过不断实践和学习,深入挖掘 PyTorch 的强大功能,为自己的深度学习项目提供有力支持。随着深度学习技术的不断发展,PyTorch 也将持续更新和完善,为开发者带来更多的便利和创新。
相关文章:

深度剖析 PyTorch框架:从基础概念到高级应用的深度学习之旅!
目录 一、引言 二、PyTorch 简介 (一)诞生背景与发展历程 (二)核心特点 三、PyTorch 基础概念 (一)张量(Tensor):数据的基石 (二)自动微分&…...

【Pandas】pandas Series cumsum
Pandas2.2 Series Computations descriptive stats 方法描述Series.abs()用于计算 Series 中每个元素的绝对值Series.all()用于检查 Series 中的所有元素是否都为 True 或非零值(对于数值型数据)Series.any()用于检查 Series 中是否至少有一个元素为 T…...

EtherCAT主站IGH-- 23 -- IGH之fsm_slave.h/c文件解析
EtherCAT主站IGH-- 23 -- IGH之fsm_slave.h/c文件解析 0 预览一 该文件功能`fsm_slave.c` 文件功能函数预览二 函数功能介绍`fsm_slave.c` 中主要函数的作用1. `ec_fsm_slave_init`2. `ec_fsm_slave_clear`3. `ec_fsm_slave_exec`4. `ec_fsm_slave_set_ready`5. `ec_fsm_slave_…...
:让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路)
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新 ——从DeepSeek看下一代语言模型的高效之路 大模型的“内存焦虑” 当ChatGPT等大语言模型(LLM)惊艳世界时,很少有人意识到它们背后隐藏的“内存焦虑”…...

Brightness Controller-源码记录
Brightness Controller 亮度控制 一、概述二、ddcutil 与 xrandr1. ddcutil2. xrandr 三、部分代码解析1. icons2. ui3. utilinit.py 一、概述 项目:https://github.com/SunStorm2018/Brightness.git 原理:Brightness Controlle 是我在 Ubuntu 发现上调…...

Java8_StreamAPI
Stream 1.创建流 1.1 集合创建流 List<String> list List.of("a", "b", "c"); Stream<String> stream list.stream(); stream.forEach(System.out::println);1.2 数组创建流 String[] array {"a","b",&qu…...

【架构面试】二、消息队列和MySQL和Redis
MQ MQ消息中间件 问题引出与MQ作用 常见面试问题:面试官常针对项目中使用MQ技术的候选人提问,如如何确保消息不丢失,该问题可考察候选人技术能力。MQ应用场景及作用:以京东系统下单扣减京豆为例,MQ用于交易服和京豆服…...

OpenEuler学习笔记(十六):搭建postgresql高可用数据库环境
以下是在OpenEuler系统上搭建PostgreSQL高可用数据环境的一般步骤,通常可以使用流复制(Streaming Replication)或基于Patroni等工具来实现高可用,以下以流复制为例: 安装PostgreSQL 配置软件源:可以使用O…...

Vue.js路由管理与自定义指令深度剖析
Vue.js 是一个强大的前端框架,提供了丰富的功能来帮助开发者构建复杂的单页应用(SPA)。本文将详细介绍 Vue.js 中的自定义指令和路由管理及导航守卫。通过这些功能,你可以更好地控制视图行为和应用导航,从而提升用户体验和开发效率。 1 自定义指令详解 1.1 什么是自定义…...

skynet 源码阅读 -- 核心概念服务 skynet_context
本文从 Skynet 源码层面深入解读 服务(Service) 的创建流程。从最基础的概念出发,逐步深入 skynet_context_new 函数、相关数据结构(skynet_context, skynet_module, message_queue 等),并通过流程图、结构…...

论文阅读(十一):基因-表型关联贝叶斯网络模型的评分、搜索和评估
1.论文链接:Scoring, Searching and Evaluating Bayesian Network Models of Gene-phenotype Association 摘要: 全基因组关联研究(GWAS)的到来为识别常见疾病的遗传变异(单核苷酸多态性(SNP)&…...

企业微信远程一直显示正在加载
企业微信远程一直显示正在加载 1.问题描述2.问题解决 系统:Win10 1.问题描述 某天使用企业微信给同事进行远程协助的时候,发现一直卡在正在加载的页面,如下图所示 2.问题解决 经过一番查找资料后,我发现可能是2个地方出了问题…...

人工智能 - 1
深度强化学习(Deep Reinforcement Learning) 图神经网络(Graph Neural Networks, GNNs) Transformer 一种深度学习模型 大语言模型(Large Language Models, LLMs) 人工智能 • Marvin Minsky 将其定义…...

留学生scratch计算机haskell函数ocaml编程ruby语言prolog作业VB
您列出了一系列编程语言和技术,这些可能是您在留学期间需要学习或完成作业的内容。以下是对每个项目的简要说明和它们可能涉及的领域或用途: Scratch: Scratch是一种图形化编程语言,专为儿童和初学者设计,用于教授编程…...

LeetCode题练习与总结:最长和谐子序列--594
一、题目描述 和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。 给你一个整数数组 nums ,请你在所有可能的 子序列 中找到最长的和谐子序列的长度。 数组的 子序列 是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素…...
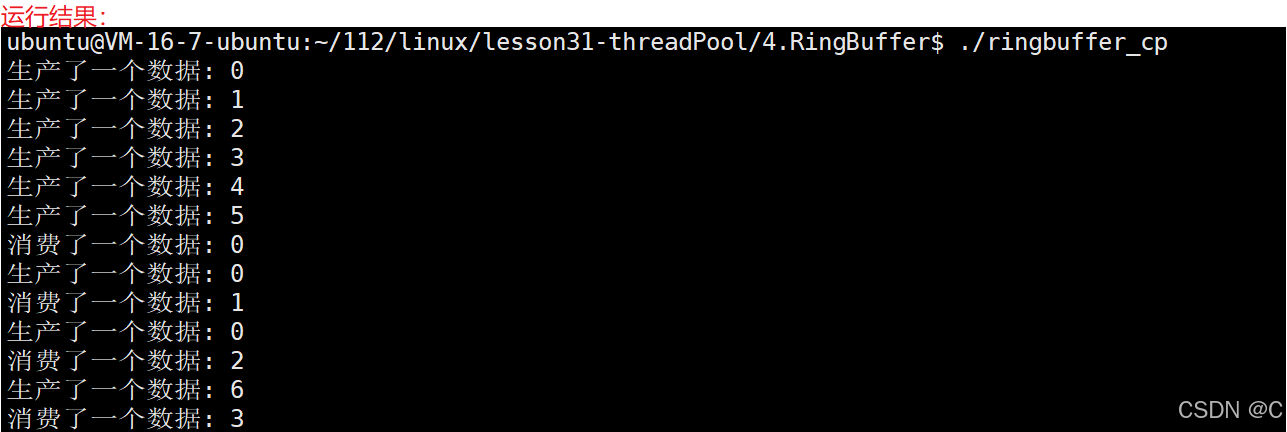
Linux_线程同步生产者消费者模型
同步的相关概念 同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。 同步的…...

Github 2025-01-30 Go开源项目日报 Top10
根据Github Trendings的统计,今日(2025-01-30统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Go项目10Ollama: 本地大型语言模型设置与运行 创建周期:248 天开发语言:Go协议类型:MIT LicenseStar数量:42421 个Fork数量:2724 次关注人…...
)
FortiOS 存在身份验证绕过导致命令执行漏洞(CVE-2024-55591)
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...

【Rust自学】17.2. 使用trait对象来存储不同值的类型
喜欢的话别忘了点赞、收藏加关注哦(加关注即可阅读全文),对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 17.2.1. 需求 这篇文章以一个例子来介绍如何在Rust中使用trait对象来存储不同值的类型。 …...

毛选原文-实践论
实践论 论认识和实践的关系——知和行的关系 (一九三七年七月) 马克思以前的唯物论,离开人的社会性,离开人的历史发展,去观察认识问题,因此不能了解认识对社会实践的依赖关系,即认识对生产…...
)
PPT自动化 python-pptx -7: 占位符(placeholder)
占位符(placeholder)是演示文稿中用于容纳内容的预格式化容器。它们通过让模板设计者定义格式选项,简化了创建视觉一致幻灯片的过程,同时让最终用户专注于添加内容。这加快了演示文稿的开发速度,并确保幻灯片之间的外观…...

VLLM性能调优
1. 抢占 显存不够的时候,某些request会被抢占。其KV cache被清除,腾退给其他request,下次调度到它,重新计算KV cache。 报这条消息,说明已被抢占: WARNING 05-09 00:49:33 scheduler.py:1057 Sequence gr…...
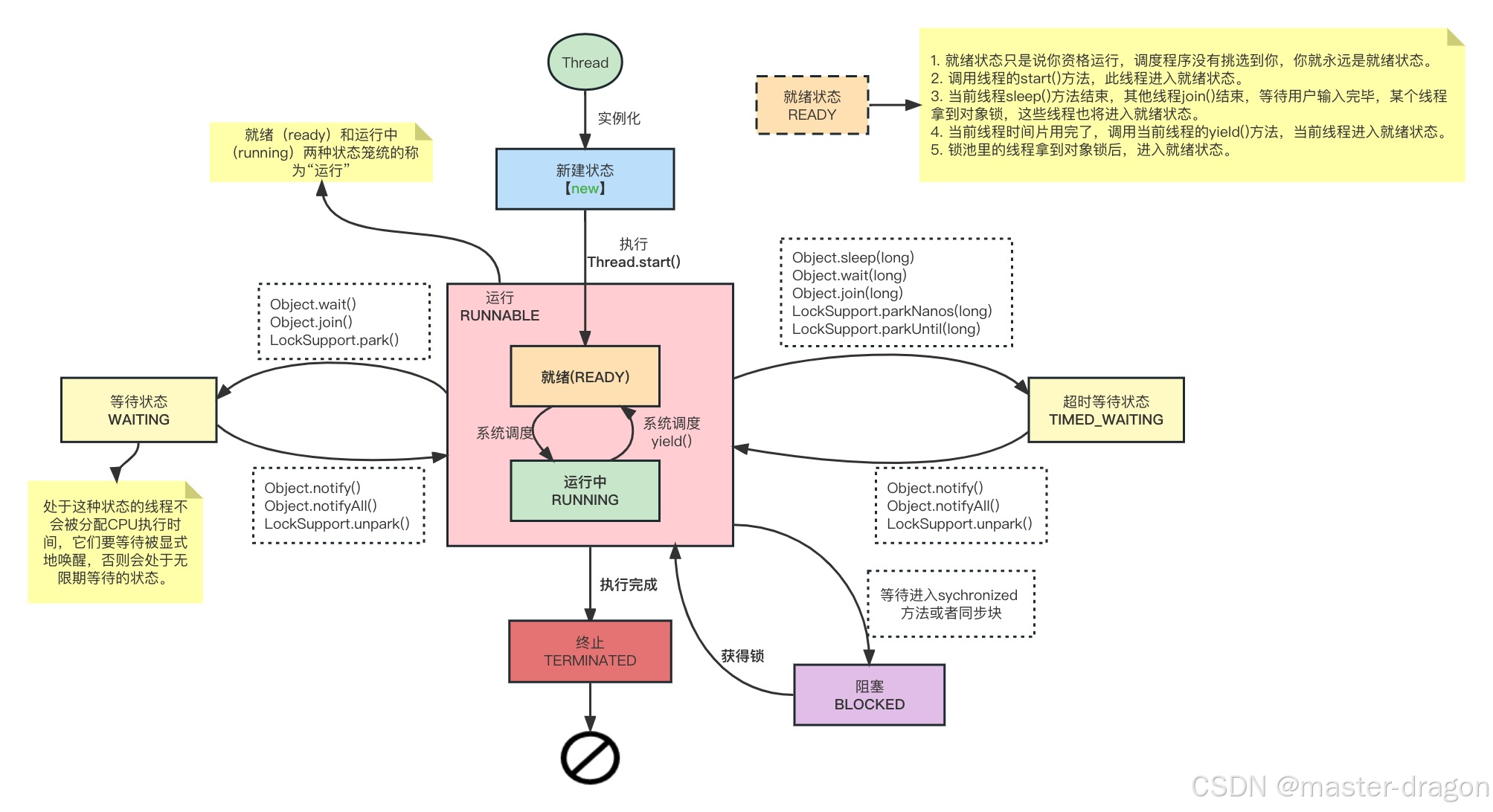
Java线程认识和Object的一些方法
本文目标: 要对Java线程有整体了解,深入认识到里面的一些方法和Object对象方法的区别。认识到Java对象的ObjectMonitor,这有助于后面的Synchronized和锁的认识。利用Synchronized wait/notify 完成一道经典的多线程题目:实现ABC…...

数据库管理-第287期 Oracle DB 23.7新特性一览(20250124)
数据库管理287期 2025-01-24 数据库管理-第287期 Oracle DB 23.7新特性一览(20250124)1 AI向量搜索:算术和聚合运算2 更改Compatible至23.6.0,以使用23.6或更高版本中的新AI向量搜索功能3 Cloud Developer包4 DBMS_DEVELOPER.GET_…...

LruCache实现
LRU最近最少使用算法 一、LRU算法 1.简介 LRU(Least Recently Used,最近最少使用)算法是一种常用的缓存淘汰策略,当缓存达到其容量上限时,它会移除那些最久没有被访问的数据项。这种策略基于这样一个假设࿱…...

DDD架构实战第五讲总结:将领域模型转化为代码
云架构师系列课程之DDD架构实战第五讲总结:将领域模型转化为代码 一、引言 在前几讲中,我们讨论了领域模型的重要性及其在业务分析中的渐进获得方法。本讲将聚焦于如何将领域模型转化为代码,使得开发人员能够更轻松地实现用户的领域模型。 二、从模型到代码:领域驱动设计…...

【MySQL】MySQL客户端连接用 localhost和127.0.0.1的区别
# systemctl status mysqld # ss -tan | grep 3306 # mysql -V localhost与127.0.0.1的区别是什么? 相信有人会说是本地IP,曾有人说,用127.0.0.1比localhost好,可以减少一次解析。 看来这个入门问题还有人不清楚,其实…...

蓝桥杯例题五
无论你面对多大的困难和挑战,都要保持坚定的信念和积极的态度。相信自己的能力和潜力,努力不懈地追求自己的目标和梦想。不要害怕失败,因为失败是成功的垫脚石。相信自己的选择和决策,不要被他人的意见和批评左右。坚持不懈地努力…...

DeepSeek R1本地部署详细指南
DeepSeek R1 是由中国 AI 初创公司深度求索开发的先进推理模型,其性能在数学、编码和逻辑推理等任务上表现出色。在本地部署该模型可以带来更低的延迟、更高的隐私性以及对 AI 应用的更大控制权。本文将详细介绍如何在本地环境中部署 DeepSeek R1 模型。 前提条件 …...

MySQL(高级特性篇) 14 章——MySQL事务日志
事务有4种特性:原子性、一致性、隔离性和持久性 事务的隔离性由锁机制实现事务的原子性、一致性和持久性由事务的redo日志和undo日志来保证(1)REDO LOG称为重做日志,用来保证事务的持久性(2)UNDO LOG称为回…...