【leetcode练习·二叉树拓展】快速排序详解及应用
本文参考labuladong算法笔记[拓展:快速排序详解及应用 | labuladong 的算法笔记]
1、算法思路
首先我们看一下快速排序的代码框架:
def sort(nums: List[int], lo: int, hi: int):if lo >= hi:return# 对 nums[lo..hi] 进行切分# 使得 nums[lo..p-1] <= nums[p] < nums[p+1..hi]p = partition(nums, lo, hi)# 去左右子数组进行切分sort(nums, lo, p - 1)sort(nums, p + 1, hi)其实你对比之后可以发现,快速排序就是一个二叉树的前序遍历:
# 二叉树遍历框架
def traverse(root: TreeNode):if not root:return# 前序位置print(root.val)traverse(root.left)traverse(root.right)另外,前文 归并排序详解 用一句话总结了归并排序:先把左半边数组排好序,再把右半边数组排好序,然后把两半数组合并。
同时我提了一个问题,让你一句话总结快速排序,这里说一下我的答案:
快速排序是先将一个元素排好序,然后再将剩下的元素排好序。
为什么这么说呢,且听我慢慢道来。
快速排序的核心无疑是 partition 函数, partition 函数的作用是在 nums[lo..hi] 中寻找一个切分点 p,通过交换元素使得 nums[lo..p-1] 都小于等于 nums[p],且 nums[p+1..hi] 都大于 nums[p]:

一个元素左边的元素都比它小,右边的元素都比它大,啥意思?不就是它自己已经被放到正确的位置上了吗?
所以 partition 函数干的事情,其实就是把 nums[p] 这个元素排好序了。
一个元素被排好序了,然后呢?你再把剩下的元素排好序不就得了。
剩下的元素有哪些?左边一坨,右边一坨,去吧,对子数组进行递归,用 partition 函数把剩下的元素也排好序。
从二叉树的视角,我们可以把子数组 nums[lo..hi] 理解成二叉树节点上的值,sort 函数理解成二叉树的遍历函数。
参照二叉树的前序遍历顺序,快速排序的运行过程如下 GIF:

你注意最后形成的这棵二叉树是什么?是一棵二叉搜索树:

这应该不难理解吧,因为 partition 函数每次都将数组切分成左小右大两部分,恰好和二叉搜索树左小右大的特性吻合。
你甚至可以这样理解:快速排序的过程是一个构造二叉搜索树的过程。
但谈到二叉搜索树的构造,那就不得不说二叉搜索树不平衡的极端情况,极端情况下二叉搜索树会退化成一个链表,导致操作效率大幅降低。
快速排序的过程中也有类似的情况,比如我画的图中每次 partition 函数选出的切分点都能把 nums[lo..hi] 平分成两半,但现实中你不见得运气这么好。
如果你每次运气都特别背,有一边的元素特别少的话,这样会导致二叉树生长不平衡:

这样的话,时间复杂度会大幅上升,后面分析时间复杂度的时候再细说。
我们为了避免出现这种极端情况,需要引入随机性。
常见的方式是在进行排序之前对整个数组执行 洗牌算法 进行打乱,或者在 partition 函数中随机选择数组元素作为切分点,本文会使用前者。
2、代码实现
import randomclass Quick:@staticmethoddef sort(nums: List[int]):# 为了避免出现耗时的极端情况,先随机打乱random.shuffle(nums)# 排序整个数组(原地修改)Quick.sort_(nums, 0, len(nums) - 1)@staticmethoddef sort_(nums: List[int], lo: int, hi: int):if lo >= hi:return# 对 nums[lo..hi] 进行切分# 使得 nums[lo..p-1] <= nums[p] < nums[p+1..hi]p = Quick.partition(nums, lo, hi)Quick.sort_(nums, lo, p - 1)Quick.sort_(nums, p + 1, hi)# 对 nums[lo..hi] 进行切分@staticmethoddef partition(nums: List[int], lo: int, hi: int) -> int:pivot = nums[lo]# 关于区间的边界控制需格外小心,稍有不慎就会出错# 我这里把 i, j 定义为开区间,同时定义:# [lo, i) <= pivot;(j, hi] > pivot# 之后都要正确维护这个边界区间的定义i, j = lo + 1, hi# 当 i > j 时结束循环,以保证区间 [lo, hi] 都被覆盖while i <= j:while i < hi and nums[i] <= pivot:i += 1# 此 while 结束时恰好 nums[i] > pivotwhile j > lo and nums[j] > pivot:j -= 1# 此 while 结束时恰好 nums[j] <= pivotif i >= j:break# 此时 [lo, i) <= pivot && (j, hi] > pivot# 交换 nums[j] 和 nums[i]nums[i], nums[j] = nums[j], nums[i]# 此时 [lo, i] <= pivot && [j, hi] > pivot# 最后将 pivot 放到合适的位置,即 pivot 左边元素较小,右边元素较大nums[lo], nums[j] = nums[j], nums[lo]return j上面代码里partition采用的是左右双指针法,也可用快慢双指针,更易理解:
选最后一个元素作为分区点,指针 i 表示比分区值小的元素应该放的位置,指针 j 只用来遍历。当 j 遍历到比分区值小的元素时,放到指针 i 的位置(通过交换实现)。当 j 遍历完时,[lo, i - 1] 都是比分区值小的元素,[i, hi - 1] 都是比分区值大的元素,最后交换一下分区值和 i 所指向的元素便实现了 pivot 左边都是比它小的元素,右边都是比它大的元素。
# 快慢双指针def partition(nums, lo, hi):pivot = nums[hi]i = j = lowhile j < hi:if nums[j] < pivot:nums[i], nums[j] = nums[j], nums[i]i += 1j += 1nums[i], nums[hi] = nums[hi], nums[i]return i 想要正确寻找切分点非常考验你对边界条件的控制,稍有差错就会产生错误的结果。
处理边界细节的一个技巧就是,你要明确每个变量的定义以及区间的开闭情况。具体的细节看代码注释,建议自己动手实践。
3、复杂度分析
接下来分析一下快速排序的时间复杂度。
显然,快速排序的时间复杂度主要消耗在 partition 函数上,因为这个函数中存在循环。
所以 partition 函数到底执行了多少次?每次执行的时间复杂度是多少?总的时间复杂度是多少?
和归并排序类似,需要结合之前画的这幅图来从整体上分析:

partition 执行的次数是二叉树节点的个数,每次执行的复杂度就是每个节点代表的子数组 nums[lo..hi] 的长度,所以总的时间复杂度就是整棵树中「数组元素」的个数。
假设数组元素个数为 N,那么二叉树每一层的元素个数之和就是 O(N)O(N);切分点 p 每次都落在数组正中间的理想情况下,树的层数为 O(logN)O(logN),所以理想的总时间复杂度为 O(NlogN)O(NlogN)。
由于快速排序没有使用任何辅助数组,所以空间复杂度就是递归堆栈的深度,也就是树高 O(logN)O(logN)。
当然,我们之前说过快速排序的效率存在一定随机性,如果每次 partition 切分的结果都极不均匀:

快速排序就退化成选择排序了,树高为 O(N)O(N),每层节点的元素个数从 N 开始递减,总的时间复杂度为:
N + (N - 1) + (N - 2) + ... + 1 = O(N^2)所以我们说,快速排序理想情况的时间复杂度是 O(NlogN)O(NlogN),空间复杂度 O(logN)O(logN),极端情况下的最坏时间复杂度是 O(N2)O(N2),空间复杂度是 O(N)O(N)。
不过大家放心,经过随机化的 partition 函数很难出现极端情况,所以快速排序的效率还是非常高的。
还有一点需要注意的是,快速排序是「不稳定排序」,与之相对的,前文讲的 归并排序 是「稳定排序」。
对于序列中的相同元素,如果排序之后它们的相对位置没有发生改变,则称该排序算法为「稳定排序」,反之则为「不稳定排序」。
如果单单排序 int 数组,那么稳定性没有什么意义。但如果排序一些结构比较复杂的数据,那么稳定排序就有更大的优势了。
比如说你有若干订单数据,已经按照订单号排好序了,现在你想对订单的交易日期再进行排序:
如果用稳定排序算法(比如归并排序),那么这些订单不仅按照交易日期排好了序,而且相同交易日期的订单的订单号依然是有序的。
但如果你用不稳定排序算法(比如快速排序),那么虽然排序结果会按照交易日期排好序,但相同交易日期的订单的订单号会丧失有序性。
在实际工程中我们经常会将一个复杂对象的某一个字段作为排序的 key,所以应该关注编程语言提供的 API 底层使用的到底是什么排序算法,是稳定的还是不稳定的,这很可能影响到代码执行的效率甚至正确性。
912. 排序数组
给你一个整数数组 nums,请你将该数组升序排列。
你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。
示例 1:
输入:nums = [5,2,3,1] 输出:[1,2,3,5]
示例 2:
输入:nums = [5,1,1,2,0,0] 输出:[0,0,1,1,2,5]
提示:
1 <= nums.length <= 5 * 104-5 * 104 <= nums[i] <= 5 * 104
class Solution:def sortArray(self, nums: List[int]) -> List[int]:# 归并排序对数组进行原地排序Quick.sort(nums)return numsclass Quick:# 见上文以上代码重点在于对快速排序代码框架的理解,但遇到极端情况还是会超时,下面是通常的快排算法代码:
class Solution:def sortArray(self, nums: List[int]) -> List[int]:def partition(arr, low, high):# 随机选择pivotpivot_idx = random.randint(low, high) # pivot放置到最左边 arr[low], arr[pivot_idx] = arr[pivot_idx], arr[low] # 选取最左边为pivot pivot = arr[low] left, right = low, high # 双指针while left < right:# 找到右边第一个<pivot的元素while left < right and arr[right] >= pivot: right -= 1# 并将其移动到left处arr[left] = arr[right] # 找到左边第一个>pivot的元素while left < right and arr[left] <= pivot: left += 1# 并将其移动到right处arr[right] = arr[left] # pivot放置到中间left=right处arr[left] = pivot return leftdef quick_sort(arr, low, high):if low >= high: # 递归结束return mid = partition(arr, low, high) # 以mid为分割点quick_sort(arr, low, mid-1) # 递归对mid两侧元素进行排序quick_sort(arr, mid+1, high)quick_sort(nums, 0, len(nums)-1) # 调用快排函数对nums进行排序return nums
4、快速选择算法
不仅快速排序算法本身很有意思,而且它还有一些有趣的变体,最有名的就是快速选择算法(Quick Select)。
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
提示:
1 <= k <= nums.length <= 105-104 <= nums[i] <= 104
题目要求我们寻找第 k 个最大的元素,稍微有点绕,意思是去寻找 nums 数组降序排列后排名第 k 的那个元素。
比如输入 nums = [2,1,5,4], k = 2,算法应该返回 4,因为 4 是 nums 中第 2 个最大的元素。
快速选择算法是快速排序的变体,效率更高,面试中如果能够写出快速选择算法,肯定是加分项。
首先,题目问「第 k 个最大的元素」,相当于数组升序排序后「排名第 n - k 的元素」,为了方便表述,后文另 k' = n - k。
如何知道「排名第 k' 的元素」呢?其实在快速排序算法 partition 函数执行的过程中就可以略见一二。
我们刚说了,partition 函数会将 nums[p] 排到正确的位置,使得 nums[lo..p-1] < nums[p] < nums[p+1..hi]:
这时候,虽然还没有把整个数组排好序,但我们已经让 nums[p] 左边的元素都比 nums[p] 小了,也就知道 nums[p] 的排名了。
那么我们可以把 p 和 k' 进行比较,如果 p < k' 说明第 k' 大的元素在 nums[p+1..hi] 中,如果 p > k' 说明第 k' 大的元素在 nums[lo..p-1] 中。
进一步,去 nums[p+1..hi] 或者 nums[lo..p-1] 这两个子数组中执行 partition 函数,就可以进一步缩小排在第 k' 的元素的范围,最终找到目标元素。
这样就可以写出解法代码:
import randomclass Solution:def findKthLargest(self, nums: List[int], k: int) -> int:# 首先随机打乱数组random.shuffle(nums)lo, hi = 0, len(nums) - 1# 转化成「排名第 k 的元素」k = len(nums) - kwhile lo <= hi:# 在 nums[lo..hi] 中选一个切分点p = self.partition(nums, lo, hi)if p < k:# 第 k 大的元素在 nums[p+1..hi] 中lo = p + 1elif p > k:# 第 k 大的元素在 nums[lo..p-1] 中hi = p - 1else:# 找到第 k 大元素return nums[p]return -1# 对 nums[lo..hi] 进行切分def partition(self, nums: List[int], lo: int, hi: int) -> int:# 见前文pass这个代码框架其实非常像我们前文 二分搜索框架 的代码,这也是这个算法高效的原因,但是时间复杂度为什么是 O(N) 呢?
显然,这个算法的时间复杂度也主要集中在 partition 函数上,我们需要估算 partition 函数执行了多少次,每次执行的时间复杂度是多少。
最好情况下,每次 partition 函数切分出的 p 都恰好是正中间索引 (lo + hi) / 2(二分),且每次切分之后会到左边或者右边的子数组继续进行切分,那么 partition 函数执行的次数是 logN,每次输入的数组大小缩短一半。
所以总的时间复杂度为:
// 等比数列
N + N/2 + N/4 + N/8 + ... + 1 = 2N = O(N)当然,类似快速排序,快速选择算法中的 partition 函数也可能出现极端情况,最坏情况下 p 一直都是 lo + 1 或者一直都是 hi - 1,这样的话时间复杂度就退化为 O(N^2)了:
N + (N - 1) + (N - 2) + ... + 1 = O(N^2)这也是我们在代码中使用 shuffle 函数的原因,通过引入随机性来避免极端情况的出现,让算法的效率保持在比较高的水平。随机化之后的快速选择算法的复杂度可以认为是 O(N)。
其他解法:
class Solution:def findKthLargest(self, nums, k):def quick_select(nums, k):# 随机选择基准数pivot = random.choice(nums)big, equal, small = [], [], []# 将大于、小于、等于 pivot 的元素划分至 big, small, equal 中for num in nums:if num > pivot:big.append(num)elif num < pivot:small.append(num)else:equal.append(num)if k <= len(big):# 第 k 大元素在 big 中,递归划分return quick_select(big, k)if len(big) + len(equal) < k:# 第 k 大元素在 small 中,递归划分return quick_select(small, k - len(nums) + len(small))# 第 k 大元素在 equal 中,直接返回 pivotreturn pivotreturn quick_select(nums, k)
到这里,快速排序算法和快速选择算法就讲完了,从二叉树的视角来理解思路应该是不难的,但 partition 函数对细节的把控需要你多花心思去理解和记忆。
最后你可以比较一下快速排序和前文讲的 归并排序 并且可以说说你的理解:为什么快速排序是不稳定排序,而归并排序是稳定排序?
相关文章:
【leetcode练习·二叉树拓展】快速排序详解及应用
本文参考labuladong算法笔记[拓展:快速排序详解及应用 | labuladong 的算法笔记] 1、算法思路 首先我们看一下快速排序的代码框架: def sort(nums: List[int], lo: int, hi: int):if lo > hi:return# 对 nums[lo..hi] 进行切分# 使得 nums[lo..p-1]…...

华为IoTDA平台两个设备之间通信的过滤条件如何设置
目录 引言 过滤规则 特定topic转发 特定设备转发 特定产品转发 特定数据转发 结语 参考资料 引言 前一篇博文介绍了如何在两个设备之间进行通信转发。和利用topic进行转发相比,华为的这种方法比较麻烦,但是它功能比较强,包括可以利用…...
Docker 安装详细教程(适用于CentOS 7 系统)
目录 步骤如下: 1. 卸载旧版 Docker 2. 配置 Docker 的 YUM 仓库 3. 安装 Docker 4. 启动 Docker 并验证安装 5. 配置 Docker 镜像加速 总结 前言 Docker 分为 CE 和 EE 两大版本。CE即社区版(免费,支持周期7个月)…...
-组合问题)
【LeetCode 刷题】回溯算法(1)-组合问题
此博客为《代码随想录》二叉树章节的学习笔记,主要内容为回溯算法组合问题相关的题目解析。 文章目录 77. 组合216.组合总和III17.电话号码的字母组合39. 组合总和40. 组合总和 II 77. 组合 题目链接 class Solution:def combinationSum3(self, k: int, n: int) …...

FreeRTOS从入门到精通 第十三章(信号量)
参考教程:【正点原子】手把手教你学FreeRTOS实时系统_哔哩哔哩_bilibili 一、信号量知识回顾 1、概述 (1)信号量是一种解决同步问题的机制,可以实现对共享资源的有序访问,FreeRTOS中使用的是二值信号量、计数型信号…...

pstricks PGFTikz 在CTeX套装中绘图Transparency或Opacity失效的问题
我在CTeX中画图的时候,习惯用Geogebra先画好,然后生成pstricks或PGFTikz代码: 这样不用插入eps或pdf之类的图片,也是一种偷懒的方法。以前往arXiv.org上面传论文也是这样:代码出图,就不用另外上传一幅eps或…...

FPGA学习篇——开篇之作
今天正式开始学FPGA啦,接下来将会编写FPGA学习篇来记录自己学习FPGA 的过程! 今天是大年初六,简单学一下FPGA的相关概念叭叭叭! 一:数字系统设计流程 一个数字系统的设计分为前端设计和后端设计。在我看来࿰…...

C++底层学习预备:模板初阶
文章目录 1.编程范式2.函数模板2.1 函数模板概念2.2 函数模板原理2.3 函数模板实例化2.3.1 隐式实例化2.3.2 显式实例化 2.4 模板参数的匹配原则 3.类模板希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力! 进入STL库学习之前我们要先了解有关模板的…...

llama.cpp LLM_CHAT_TEMPLATE_DEEPSEEK_3
llama.cpp LLM_CHAT_TEMPLATE_DEEPSEEK_3 1. LLAMA_VOCAB_PRE_TYPE_DEEPSEEK3_LLM2. static const std::map<std::string, llm_chat_template> LLM_CHAT_TEMPLATES3. LLM_CHAT_TEMPLATE_DEEPSEEK_3References 不宜吹捧中国大语言模型的同时,又去贬低美国大语言…...

【玩转 Postman 接口测试与开发2_014】第11章:测试现成的 API 接口(下)——自动化接口测试脚本实战演练 + 测试集合共享
《API Testing and Development with Postman》最新第二版封面 文章目录 3 接口自动化测试实战3.1 测试环境的改造3.2 对列表查询接口的测试3.3 对查询单个实例的测试3.4 对新增接口的测试3.5 对修改接口的测试3.6 对删除接口的测试 4 测试集合的共享操作4.1 分享 Postman 集合…...

Linux03——常见的操作命令
root用户以及权限 Linux系统的超级管理员用户是:root用户 su命令 可以切换用户,语法:su [-] [用户名]- 表示切换后加载环境变量,建议带上用户可以省略,省略默认切换到root su命令是用于账户切换的系统命令ÿ…...

w188校园商铺管理系统设计与实现
🙊作者简介:多年一线开发工作经验,原创团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文…...

leetcode——二叉树的最近公共祖先(java)
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的…...

基于FPGA的BT656编解码
概述 BT656全称为“ITU-R BT.656-4”或简称“BT656”,是一种用于数字视频传输的接口标准。它规定了数字视频信号的编码方式、传输格式以及接口电气特性。在物理层面上,BT656接口通常包含10根线(在某些应用中可能略有不同,但标准配置为10根)。这些线分别用于传输视频数据、…...

解锁数据结构密码:层次树与自引用树的设计艺术与API实践
1. 引言:为什么选择层次树和自引用树? 数据结构是编程中的基石之一,尤其是在处理复杂关系和层次化数据时,树形结构常常是最佳选择。层次树(Hierarchical Tree)和自引用树(Self-referencing Tree…...

本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程: 概述 DeepSeek模型 是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能…...

WAWA鱼2024年终总结,关键词:成长
前言 本来想着偷懒一下,不写2024年终总结了,因为24年上半年还在忙毕业,下半年在忙转正,其实没什么太多好写的。结果被an_da和学弟催更了,哈哈哈,感谢大家对我近况的关注,学校内容基本都忘的差不…...
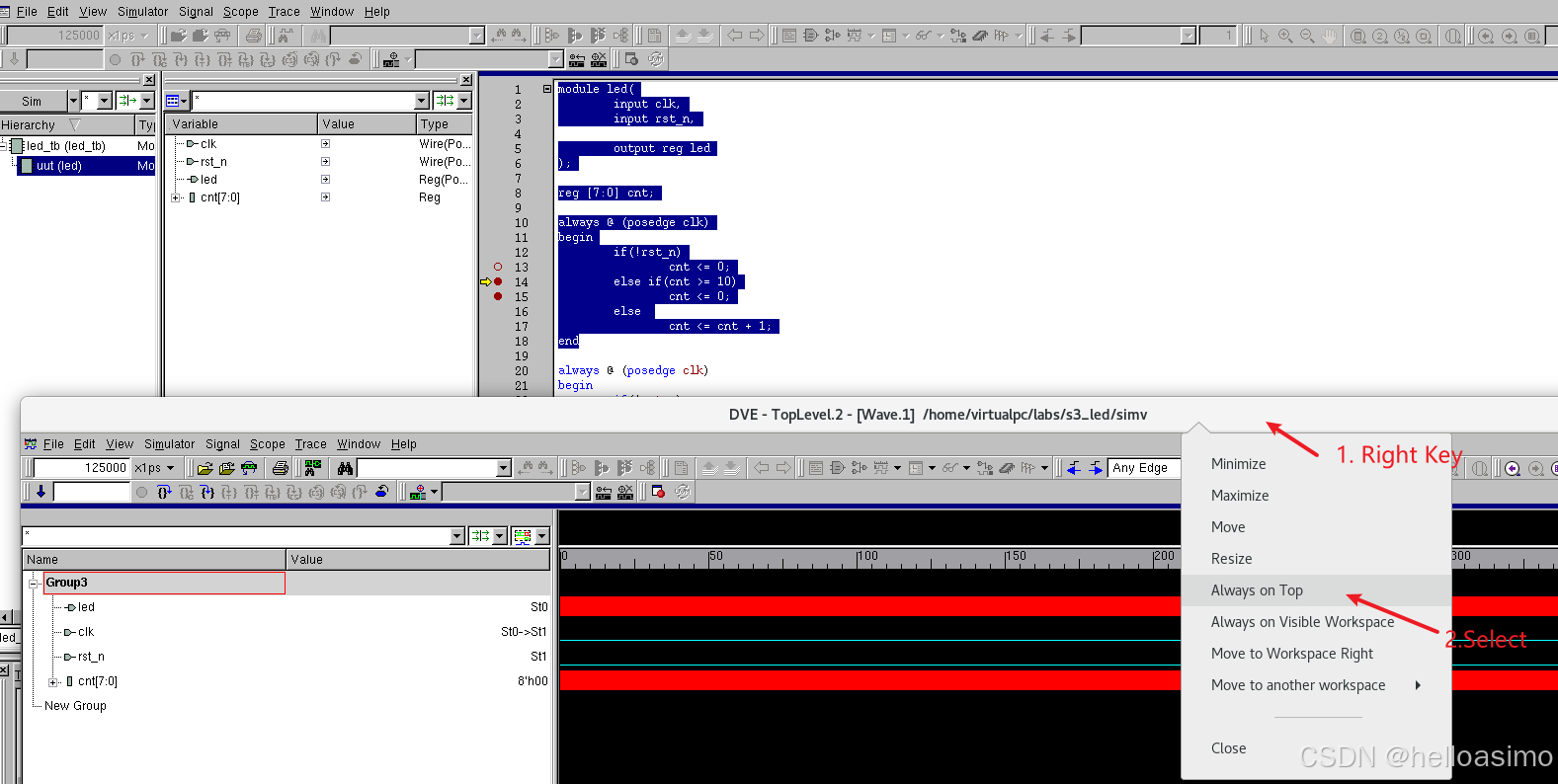
使用VCS进行单步调试的步骤
使用VCS对SystemVerilog进行单步调试的步骤如下: 1. 编译设计 使用-debug_all或-debug_pp选项编译设计,生成调试信息。 我的4个文件: 1.led.v module led(input clk,input rst_n,output reg led );reg [7:0] cnt;always (posedge clk) beg…...

【Elasticsearch】硬件资源优化
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

Elasticsearch 指南 [8.17] | Search APIs
Search API 返回与请求中定义的查询匹配的搜索结果。 http GET /my-index-000001/_search Request GET /<target>/_search GET /_search POST /<target>/_search POST /_search Prerequisites 如果启用了 Elasticsearch 安全功能,针对目标数据流…...

QT+mysql+python 效果:
# This Python file uses the following encoding: utf-8 import sysfrom PySide6.QtWidgets import QApplication, QWidget,QMessageBox from PySide6.QtGui import QStandardItemModel, QStandardItem # 导入需要的类# Important: # 你需要通过以下指令把 form.ui转为ui…...

Java 序列化和反序列化作用
Java 序列化和反序列化的核心作用是将对象转换为可存储或传输的字节流(序列化),以及从字节流恢复对象(反序列化)。以下是详细说明和示例: 作用 持久化存储 将对象保存到文件或数据库,重启后仍可…...

【4】阿里面试题整理
[1]. 介绍一下数据库死锁 数据库死锁是指两个或多个事务,由于互相请求对方持有的资源而造成的互相等待的状态,导致它们都无法继续执行。 死锁会导致事务阻塞,系统性能下降甚至应用崩溃。 比如:事务T1持有资源R1并等待R2&#x…...

回顾生化之父三上真司的游戏思想
1. 放养式野蛮成长路线,开创生存恐怖类型 三上进入capcom后,没有培训,没有师傅手把手的指导,而是每天摸索写策划书,老员工给出不行的评语后,扔掉旧的重写新的。 然后突然就成为游戏总监,进入开…...

Java循环操作哪个快
文章目录 Java循环操作哪个快一、引言二、循环操作性能对比1、普通for循环与增强for循环1.1、代码示例 2、for循环与while循环2.1、代码示例 3、循环优化技巧3.1、代码示例 三、循环操作的适用场景四、使用示例五、总结 Java循环操作哪个快 一、引言 在Java开发中,…...

Maven jar 包下载失败问题处理
Maven jar 包下载失败问题处理 1.配置好国内的Maven源2.重新下载3. 其他问题 1.配置好国内的Maven源 打开⾃⼰的 Idea 检测 Maven 的配置是否正确,正确的配置如下图所示: 检查项⼀共有两个: 确认右边的两个勾已经选中,如果没有请…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】1.25 视觉风暴:NumPy驱动数据可视化
1.25 视觉风暴:NumPy驱动数据可视化 目录 #mermaid-svg-i3nKPm64ZuQ9UcNI {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-i3nKPm64ZuQ9UcNI .error-icon{fill:#552222;}#mermaid-svg-i3nKPm64ZuQ9UcNI …...

Baklib推动数字化内容管理解决方案助力企业数字化转型
内容概要 在当今信息爆炸的时代,数字化内容管理成为企业提升效率和竞争力的关键。企业在面对大量数据时,如何高效地存储、分类与检索信息,直接关系到其经营的成败。数字化内容管理不仅限于简单的文档存储,更是整合了文档、图像、…...

读书笔记 | 《最小阻力之路》:用结构思维重塑人生愿景
一、核心理念:结构决定行为轨迹 橡皮筋模型:愿景张力的本质 书中提出:人类行为始终沿着"现状"与"愿景"之间的张力路径运动,如同橡皮筋拉伸产生的动力。 案例:音乐家每日练习的坚持,不…...

React中使用箭头函数定义事件处理程序
React中使用箭头函数定义事件处理程序 为什么使用箭头函数?1. 传递动态参数2. 避免闭包问题3. 确保每个方块的事件处理程序是独立的4. 代码可读性和维护性 示例代码总结 在React开发中,处理事件是一个常见的任务。特别是当我们需要传递动态参数时&#x…...