【单层神经网络】基于MXNet的线性回归实现(底层实现)
写在前面
- 刚开始先从普通的寻优算法开始,熟悉一下学习训练过程
- 下面将使用梯度下降法寻优,但这大概只能是局部最优,它并不是一个十分优秀的寻优算法
整体流程
- 生成训练数据集(实际工程中,需要从实际对象身上采集数据)
- 确定模型及其参数(输入输出个数、阶次,偏置等)
- 确定学习方式(损失函数、优化算法,学习率,训练次数,终止条件等)
- 读取数据集(不同的读取方式会影响最终的训练效果)
- 训练模型
完整程序及注释
from IPython import display
from matplotlib import pyplot as plt
from mxnet import autograd, nd
import random'''
获取(生成)训练集
'''
input_num = 2 # 输入个数
examples_num = 1000 # 生成样本个数
# 确定真实模型参数
real_W = [10.9, -8.7]
real_bias = 6.5 features = nd.random.normal(scale=1, shape=(examples_num, input_num)) # 标准差=1,均值缺省=0
labels = real_W[0]*features[:,0] + real_W[1]*features[:,1] + real_bias # 根据特征和参数生成对应标签
labels_noise = labels + nd.random.normal(scale=0.1, shape=labels.shape) # 为标签附加噪声,模拟真实情况# 绘制标签和特征的散点图(矢量图)
# def use_svg_display():
# display.set_matplotlib_formats('svg')# def set_figure_size(figsize=(3.5,2.5)):
# use_svg_display()
# plt.rcParams['figure.figsize'] = figsize# set_figure_size()
# plt.scatter(features[:,0].asnumpy(), labels_noise.asnumpy(), 1)
# plt.scatter(features[:,1].asnumpy(), labels_noise.asnumpy(), 1)
# plt.show()# 创建一个迭代器(确定从数据集获取数据的方式)
def data_iter(batch_size, features, labels):num = len(features)indices = list(range(num)) # 生成索引数组random.shuffle(indices) # 打乱indices# 该遍历方式同时确保了随机采样和无遗漏for i in range(0, num, batch_size):j = nd.array(indices[i: min(i+batch_size, num)]) # 对indices从i开始取,取batch_size个样本,并转换为列表yield features.take(j), labels.take(j) # take方法使用索引数组,从features和labels提取所需数据"""
训练的基础准备
"""
# 声明训练变量,并赋高斯随机初始值
w = nd.random.normal(scale=0.01, shape=(input_num))
b = nd.zeros(shape=(1,))
# b = nd.zeros(1) # 不同写法,等价于上面的
w.attach_grad() # 为需要迭代的参数申请求梯度空间
b.attach_grad()# 定义模型
def linreg(X, w, b):return nd.dot(X,w)+b# 定义损失函数
def squared_loss(y_hat, y):return (y_hat - y.reshape(y_hat.shape)) **2 /2# 定义寻优算法
def sgd(params, learning_rate, batch_size):for param in params:# 新参数 = 原参数 - 学习率*当前批量的参数梯度/当前批量的大小param[:] = param - learning_rate * param.grad / batch_size# 确定超参数和学习方式
lr = 0.03
num_iterations = 5
net = linreg # 目标模型
loss = squared_loss # 代价函数(损失函数)
batch_size = 10 # 每次随机小批量的大小'''
开始训练
'''
for iteration in range(num_iterations): # 确定迭代次数for x, y in data_iter(batch_size, features, labels):with autograd.record():l = loss(net(x,w,b), y) # 求当前小批量的总损失l.backward() # 求梯度sgd([w,b], lr, batch_size) # 梯度更新参数train_l = loss(net(features,w,b), labels)print("iteration %d, loss %f" % (iteration+1, train_l.mean().asnumpy()))
# 打印比较真实参数和训练得到的参数
print("real_w " + str(real_W) + "\n train_w " + str(w))
print("real_w " + str(real_bias) + "\n train_b " + str(b))
具体程序解释
param[:] = param - learning_rate * param.grad / batch_size:
将batch_size与参数调整相关联的原因,是为了使得每次更新的步长不受批次大小的影响
具体来说,当计算一批数据的损失函数的梯度时,实际上是将这批数据中每个样本对损失函数的贡献累加起来。这意味着如果批次较大,梯度的模也会相应增大
故更新权值时,使用的是数据集的平均梯度,而不是总和
相关文章:
)
【单层神经网络】基于MXNet的线性回归实现(底层实现)
写在前面 刚开始先从普通的寻优算法开始,熟悉一下学习训练过程下面将使用梯度下降法寻优,但这大概只能是局部最优,它并不是一个十分优秀的寻优算法 整体流程 生成训练数据集(实际工程中,需要从实际对象身上采集数据…...

20250204将Ubuntu22.04的默认Dash的shell脚本更换为bash
20250204将Ubuntu22.04的默认Dash的shell脚本更换为bash 2025/2/4 23:45 百度:dash bash https://blog.csdn.net/2201_75772333/article/details/136955776 【Linux基础】dash和bash简介 Dash(Debian Almquist Shell)和 Bash(Bou…...

Golang 并发机制-3:通道(channels)机制详解
并发编程是一种创建性能优化且响应迅速的软件的强大方法。Golang(也称为 Go)通过通道(channels)这一特性,能够可靠且优雅地实现并发通信。本文将揭示通道的概念,解释其在并发编程中的作用,并提供…...

Python处理数据库:MySQL与SQLite详解
Python处理数据库:MySQL与SQLite详解 在数据处理和存储方面,数据库扮演着至关重要的角色。Python提供了多种与数据库交互的方式,其中pymysql库用于连接和操作MySQL数据库,而SQLite则是一种轻量级的嵌入式数据库,Pytho…...

可视化大屏在石油方面的应用。
可视化大屏通过整合石油工业全链条数据,构建数字孪生驱动的运营监控体系,显著提升油气勘探、开采、储运及炼化的管理效能。其技术架构依托工业物联网(IIoT)实时采集钻井参数、管道压力、储罐液位等数据,通过OPC UA协议…...

【学术投稿-2025年计算机视觉研究进展与应用国际学术会议 (ACVRA 2025)】从计算机基础到HTML开发:Web开发的第一步
会议官网:www.acvra.org 简介 2025年计算机视觉研究进展与应用(ACVRA 2025)将于2025年2月28-3月2日在中国广州召开,将汇聚世界各地的顶尖学者、研究人员和行业专家,聚焦计算机视觉领域的最新研究动态与应用成就。本次…...
)
【 AI agents】letta:2024年代理堆栈演进(中英文翻译)
The AI agents stack AI 代理堆栈 November 14, 2024 11月 14, 2024原文: The AI agents stack官方教程教程学习笔记: 【memgpt】letta 课程1/2:从头实现一个自我编辑、记忆和多步骤推理的代理Understanding the AI agents landscape 了解 AI 代理环境 Although we see a …...

Axure PR 9 旋转效果 设计交互
大家好,我是大明同学。 这期内容,我们将学习Axure中的旋转效果设计与交互技巧。 旋转 创建旋转效果所需的元件 1.打开一个新的 RP 文件并在画布上打开 Page 1。 2.在元件库中拖出一个按钮元件。 创建交互 创建按钮交互状态 1.选中按钮元件…...

Docker 部署教程jenkins
Docker 部署 jenkins 教程 Jenkins 官方网站 Jenkins 是一个开源的自动化服务器,主要用于持续集成(CI)和持续交付(CD)过程。它帮助开发人员自动化构建、测试和部署应用程序,显著提高软件开发的效率和质量…...

二、CSS笔记
(一)css概述 1、定义 CSS是Cascading Style Sheets的简称,中文称为层叠样式表,用来控制网页数据的表现,可以使网页的表现与数据内容分离。 2、要点 怎么找到标签怎么操作标签对象(element) 3、css的四种引入方式 3.1 行内式 在标签的style属性中设定CSS样式。这种方…...

计算图 Compute Graph 和自动求导 Autograd | PyTorch 深度学习实战
前一篇文章,Tensor 基本操作5 device 管理,使用 GPU 设备 | PyTorch 深度学习实战 本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started PyTorch 计算图和 Autograd 微积分之于机器学习Computational Graphs 计算图Autograd…...

基于 Java 开发的 MongoDB 企业级应用全解析
基于Java的MongoDB企业级应用开发实战 目录 背景与历史MongoDB的核心功能与特性企业级业务场景分析MongoDB的优缺点剖析开发环境搭建 5.1 JDK安装与配置5.2 MongoDB安装与集群配置5.3 开发工具选型 Java与MongoDB集成实战 6.1 项目依赖与驱动选择6.2 连接池与客户端配置6.3…...

构建一个测试助手Agent:提升测试效率的实践
在上一篇文章中,我们讨论了如何构建一个运维助手Agent。今天,我想分享另一个实际项目:如何构建一个测试助手Agent。这个项目源于我们一个大型互联网公司的真实需求 - 提升测试效率,保障产品质量。 从测试痛点说起 记得和测试团队讨论时的场景: 小张:每…...

ESXI虚拟机中部署docker会降低服务器性能
在 8 核 16GB 的 ESXi 虚拟机中部署 Docker 的性能影响分析 在 ESXi 虚拟机中运行 Docker 容器时,性能影响主要来自以下几个方面: 虚拟化开销:ESXi 虚拟化层和 Docker 容器化层的叠加。资源竞争:虚拟机与容器之间对 CPU、内存、…...
:条件期望)
基于“蘑菇书”的强化学习知识点(五):条件期望
条件期望 摘要一、条件期望的定义二、条件期望的关键性质三、条件期望的直观理解四、条件期望的应用场景五、简单例子离散情况连续情况 摘要 本系列知识点讲解基于蘑菇书EasyRL中的内容进行详细的疑难点分析!具体内容请阅读蘑菇书EasyRL! 对应蘑菇书Eas…...

Linux抢占式内核:技术演进与源码解析
一、引言 Linux内核作为全球广泛使用的开源操作系统核心,其设计和实现一直是计算机科学领域的研究热点。从早期的非抢占式内核到2.6版本引入的抢占式内核,Linux在实时性和响应能力上取得了显著进步。本文将深入探讨Linux抢占式内核的引入背景、技术实现以及与非抢占式内核的…...

接入DeepSeek大模型
接入DeepSeek 下载并安装Ollamachatbox 软件配置大模型 下载并安装Ollama 下载并安装Ollama, 使用参数ollama -v查看是否安装成功。 输入命令ollama list, 可以看到已经存在4个目录了。 输入命令ollama pull deepseek-r1:1.5b, 下载deepse…...

【论文复现】粘菌算法在最优经济排放调度中的发展与应用
目录 1.摘要2.黏菌算法SMA原理3.改进策略4.结果展示5.参考文献6.代码获取 1.摘要 本文提出了一种改进粘菌算法(ISMA),并将其应用于考虑阀点效应的单目标和双目标经济与排放调度(EED)问题。为提升传统粘菌算法…...
 SSM框架协同工作原理)
SSM开发(十) SSM框架协同工作原理
目录 一、Spring扮演了一个整合者的角色 二、SSM拆解来看 三、SSM框架的核心优势 注: SSM框架(Spring + Spring MVC + MyBatis) 一、Spring扮演了一个整合者的角色 SSM框架中,Spring扮演了一个整合者的角色,它将Spring MVC的Web层和MyBatis的数据持久层连接起来。在SS…...

UE Bridge混合材质工具
打开虚幻内置Bridge 随便点个材质点右下角图标 就能打开材质混合工具 可以用来做顶点绘制...

基于 yolov8_pyqt5 自适应界面设计的火灾检测系统 demo:毕业设计参考
基于 yolov8_pyqt5 自适应界面设计的火灾检测系统 demo:毕业设计参考 【毕业设计参考】基于yolov8-pyqt5自适应界面设计的火灾检测系统demo.zip资源-CSDN文库 【毕业设计参考】基于yolov8-pyqt5自适应界面设计的火灾检测系统demo.zip资源-CSDN文库 一、项目背景 …...

Linux 传输层协议 UDP 和 TCP
UDP 协议 UDP 协议端格式 16 位 UDP 长度, 表示整个数据报(UDP 首部UDP 数据)的最大长度如果校验和出错, 就会直接丢弃 UDP 的特点 UDP 传输的过程类似于寄信 . 无连接: 知道对端的 IP 和端口号就直接进行传输, 不需要建立连接不可靠: 没有确认机制, 没有重传机制; 如果因…...

Android开发EventBus
Android开发EventBus 分享一个EventBus 工具类,封装一下,让你少写些代码 直接上代码: public class BaseEventBusUtils {public static void register(Object subscriber) {EventBus eventBus EventBus.getDefault();if (!eventBus.isReg…...

chrome浏览器chromedriver下载
chromedriver 下载地址 https://googlechromelabs.github.io/chrome-for-testing/ 上面的链接有和当前发布的chrome浏览器版本相近的chromedriver 实际使用感受 chrome浏览器会自动更新,可以去下载最新的chromedriver使用,自动化中使用新的chromedr…...
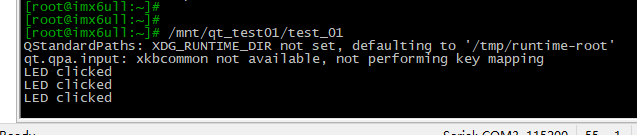
第一个Qt开发实例(一个Push Button按钮和两个Label)【包括如何在QtCreator中创建新工程、代码详解、编译、环境变量配置、测试程序运行等】
目录 Qt开发环境QtCreator的安装、配置在QtCreator中创建新工程在Forms→mainwindow.ui中拖曳出我们要的图形按钮查看拖曳出按钮后的代码为pushButton这个图形添加回调函数编译工程关闭开发板上QT的GUI(选做)禁止LCD黑屏(选做)设置Qt运行的环境变量运行Qt程序如何让程序在系统启…...

【react+redux】 react使用redux相关内容
首先说一下,文章中所提及的内容都是我自己的个人理解,是我理逻辑的时候,自我说服的方式,如果有问题有补充欢迎在评论区指出。 一、场景描述 为什么在react里面要使用redux,我的理解是因为想要使组件之间的通信更便捷…...

【435. 无重叠区间 中等】
题目: 给定一个区间的集合 intervals ,其中 intervals[i] [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。 注意 只在一点上接触的区间是 不重叠的。例如 [1, 2] 和 [2, 3] 是不重叠的。 示例 1: 输入: intervals …...

文献学习笔记:中风醒脑液(FYTF-919)临床试验解读:有效还是无效?
【中风醒脑液(FYTF-919)临床试验解读:有效还是无效?】 在发表于 The Lancet (2024 年 11 月 30 日,第 404 卷)的临床研究《Traditional Chinese medicine FYTF-919 (Zhongfeng Xingnao oral pr…...
:node.js环境)
4 前端前置技术(中):node.js环境
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 前言...

5.角色基础移动
能帮到你的话,就给个赞吧 😘 文章目录 角色的xyz轴与移动方向拌合输入轴值add movement inputget controller rotationget right vectorget forward vector 发现模型的旋转改变后,xyz轴也会改变,所以需要旋转值来计算xyz轴方向。 …...