React中useState()钩子和函数式组件底层渲染流程详解
useState()钩子底层渲染流程
React中
useState的底层渲染机理。首先,我知道useState是React
Hooks的一部分,用于在函数组件中添加状态。但底层是如何工作的呢?可能涉及到React的调度器、Fiber架构以及闭包等概念。首先,React使用Fiber架构来管理组件的渲染过程。每个组件对应一个Fiber节点,Fiber节点保存了组件的状态、副作用等信息。当使用
useState时,React会在Fiber节点中维护一个状态链表,每个Hook对应链表中的一个节点。当组件首次渲染时,React会依次调用组件函数中的Hooks,并将它们的初始值存储在对应的Fiber节点中。后续的更新渲染中,React会根据Hooks在组件中的调用顺序来复用这些状态。这就是为什么Hooks必须在组件的顶层调用,且不能在条件语句或循环中调用的原因。
useState返回的状态更新函数(例如setCount)会将新的状态值加入更新队列。React在协调阶段(Reconciliation)会处理这些状态更新,并安排重新渲染。这个过程是异步的,React可能会批量处理多个状态更新以提高性能。此外,闭包在Hooks的实现中起到了关键作用。每个状态值在函数组件的每次渲染中都是独立的闭包,确保了状态的隔离性。但是,这也可能导致在某些异步操作中捕获到旧的状态值,需要开发者注意。
React 中 useState 的底层渲染机理基于 Fiber 架构和 状态链表,其核心流程如下:
一、底层数据结构
-
Fiber 节点
每个组件对应一个 Fiber 节点,存储组件的状态、副作用、子节点等信息。// 简化的 Fiber 结构 const fiber = {memoizedState: null, // 存储 Hooks 链表stateNode: Component, // 组件实例或函数// 其他 Fiber 相关字段... }; -
Hooks 链表
- 每个 Hook(如
useState)作为链表节点存储在fiber.memoizedState中。 - 通过 调用顺序 确定 Hook 的归属,因此 Hooks 必须在顶层调用。
// Hook 节点结构 const hook = {memoizedState: null, // 当前状态值(如 useState 的初始值)queue: null, // 更新队列(存储 setState 触发的更新)next: null, // 指向下一个 Hook }; - 每个 Hook(如
二、首次渲染流程
-
组件初始化
- 调用
useState(initialValue)时,创建 Hook 节点并挂载到 Fiber 的memoizedState链表。 - 将初始值存入
hook.memoizedState。
- 调用
-
返回状态与更新函数
const [state, setState] = useState(initialValue);state:直接取自hook.memoizedState。setState:绑定到当前 Hook 的更新队列(hook.queue),触发重新渲染。
三、更新渲染流程
-
触发更新
- 调用
setState(newValue)时,将更新操作加入hook.queue。 - React 调度器(Scheduler)将组件标记为待更新。
- 调用
-
协调阶段(Reconciliation)
- React 遍历 Fiber 树,找到需要更新的组件。
- 处理 Hook 的更新队列:根据更新函数计算新状态(支持函数式更新)。
// 函数式更新示例 setState(prev => prev + 1);
-
提交阶段(Commit)
- 将新状态写入
hook.memoizedState。 - 触发 DOM 更新和副作用执行。
- 将新状态写入
四、关键机制
-
闭包隔离
- 每次渲染时,组件函数会重新执行,但 Hook 的状态通过 Fiber 持久化。
- 闭包陷阱:异步操作可能捕获旧状态,需用
useRef或函数式更新解决。
// 闭包陷阱示例 const [count, setCount] = useState(0); useEffect(() => {setTimeout(() => {console.log(count); // 可能输出旧值}, 1000); }, []); -
批量更新(Batching)
- React 自动合并多次
setState调用,减少渲染次数(React 18+ 默认所有更新批量处理)。
// 多次更新合并为一次渲染 const handleClick = () => {setCount(1);setName("DeepSeek"); // 仅触发一次重新渲染 }; - React 自动合并多次
-
优先级调度
- 通过并发模式(Concurrent Mode),React 可根据交互优先级中断或延迟渲染。
五、源码简析(React 18+)
// 简化的 useState 实现逻辑
function useState(initialState) {const fiber = currentlyRenderingFiber;let hook;if (isMount) {// 首次渲染:创建 Hook 节点hook = {memoizedState: typeof initialState === 'function' ? initialState() : initialState,queue: null,next: null,};fiber.memoizedState = hook;} else {// 更新渲染:获取当前 Hookhook = fiber.memoizedState;}// 处理队列中的更新let baseState = hook.memoizedState;if (hook.queue) {let update = hook.queue.pending;while (update) {const action = update.action;baseState = typeof action === 'function' ? action(baseState) : action;update = update.next;}hook.queue.pending = null;}hook.memoizedState = baseState;// 返回状态和更新函数const dispatch = (action) => {const update = { action, next: null };hook.queue.pending = update; // 将更新加入队列scheduleUpdateOnFiber(fiber); // 触发重新渲染};return [baseState, dispatch];
}
六、面试高频问题
-
为什么 Hooks 不能写在条件语句中?
- Hook 的链表依赖稳定的调用顺序,条件语句会导致顺序变化,引发状态错乱。
-
useState和类组件的setState有何区别?useState直接替换状态(需手动合并对象),类组件的setState自动浅合并。
-
如何实现状态持久化?
- 通过 Fiber 的
memoizedState链表和闭包隔离,确保多次渲染间状态一致。
- 通过 Fiber 的
理解 useState 的底层原理,有助于避免常见陷阱(如闭包问题)并编写高性能 React 代码。
函数式组件底层渲染流程
React函数式组件底层渲染流程详解”。我需要仔细想想怎么回答这个问题。首先,用户可能已经对React有一定的了解,但想深入理解其内部工作原理,特别是在函数式组件的情况下。
首先,我应该回顾一下React的基本渲染流程。React的核心是虚拟DOM和协调算法(Reconciliation)。当组件的状态或props发生变化时,React会重新渲染组件,并通过Diff算法找出需要更新的部分,最终高效地更新真实DOM。
对于函数式组件,特别是使用Hooks的情况,底层机制可能更复杂。用户可能想知道函数式组件是如何被调用的,状态是如何被保存和更新的,以及Hooks是如何在多次渲染中保持状态的。
接下来,我需要考虑React的Fiber架构。Fiber是React
16引入的新协调引擎,它允许React将渲染工作分割成多个小块,并支持暂停、中止和复用这些工作,从而提高了性能,尤其是对于大型应用来说。在函数式组件中,Fiber节点如何管理组件的状态和生命周期?
Hooks的实现也是一个关键点。例如,useState是如何在函数式组件中保持状态的?每次组件渲染时,函数会被重新调用,但状态却能保持不变,这背后的机制是什么?可能需要解释闭包和Fiber节点的数据结构,比如每个组件实例对应的Fiber节点如何存储Hooks的状态链表。
另
外,用户可能关心React的渲染阶段和提交阶段。在渲染阶段,React会生成新的虚拟DOM树,并与旧的进行比较,找出差异。而在提交阶段,才会将这些差异应用到真实DOM上。函数式组件在这些阶段中的具体行为是什么?
还需要提到副作用(Effects)的处理,比如useEffect是如何在组件渲染后调度副作用的,以及React如何清理这些副作用。这部分内容能帮助用户理解函数式组件的生命周期管理。
可能还需要对比类组件和函数式组件的底层机制差异,比如类组件依赖实例和生命周期方法,而函数式组件依赖Hooks和闭包。这有助于用户全面理解两种组件类型的优劣和适用场景。
最后,应该用通俗易懂的语言总结整个流程,确保用户能够清晰地理解函数式组件从状态变化到DOM更新的整个过程,以及React内部是如何高效管理这些变化的。
React 函数式组件的底层渲染流程基于 Fiber 架构 和 Hooks 机制,其核心流程可分为 初始化渲染 和 更新渲染 两个阶段。以下是详细步骤:
一、初始化渲染流程(Mount Phase)
1. 组件调用与 Fiber 节点创建
- 当组件首次渲染时,React 创建对应的 Fiber 节点,用于跟踪组件状态、副作用和子节点信息。
- Fiber 节点包含以下关键字段:
{tag: FunctionComponent, // 标识组件类型memoizedState: null, // 存储 Hooks 链表(如 useState、useEffect)stateNode: ComponentFunc,// 指向组件函数本身return: ParentFiber, // 父节点child: ChildFiber, // 子节点// ...其他调度相关字段 }
2. Hooks 初始化
- 执行函数组件代码时,依次调用
useState、useEffect等 Hooks:- 构建 Hooks 链表:每个 Hook 被创建为一个链表节点,存储在
fiber.memoizedState中。 - 状态初始化:
useState(initialValue)将初始值存入 Hook 节点的memoizedState。
// Hook 节点结构 const hook = {memoizedState: initialState, // 状态值queue: null, // 更新队列(用于 setState)next: null, // 下一个 Hook }; - 构建 Hooks 链表:每个 Hook 被创建为一个链表节点,存储在
3. 生成虚拟 DOM
- 执行组件函数,返回 JSX 元素,转换为虚拟 DOM 树:
// JSX 代码 return <div>{count}</div>;// 编译为 React.createElement: return React.createElement("div", null, count);
4. 协调(Reconciliation)
- React 对比新生成的虚拟 DOM 与当前 DOM 的差异(Diff 算法),生成 更新计划(Effect List)。
- Fiber 树构建:将组件树转换为 Fiber 树,标记需要新增、更新或删除的节点。
5. 提交(Commit)
- 将更新计划应用到真实 DOM:
- DOM 操作:创建新节点、更新属性、删除旧节点。
- 副作用执行:调度
useEffect的回调函数(异步执行)。
二、更新渲染流程(Update Phase)
1. 触发更新
- 通过
setState、props 变化或父组件渲染触发更新:const [count, setCount] = useState(0); setCount(1); // 触发更新
2. 调度更新
- React 将更新任务加入 调度队列,根据优先级决定何时处理(并发模式特性)。
3. 处理 Hooks 更新队列
- 遍历 Hooks 链表,处理
useState的更新队列:// 例如:多次调用 setCount(c => c+1) while (updateQueue !== null) {newState = update.action(newState); // 按顺序执行更新函数update = update.next; }
4. 重新执行组件函数
- 基于最新状态重新调用组件函数,生成新的虚拟 DOM。
- Hooks 顺序一致性:依赖调用顺序的 Hooks 链表必须与首次渲染完全一致(禁止条件语句中声明 Hooks)。
5. 协调与 Diff 算法
- 对比新旧虚拟 DOM,生成最小化的 DOM 更新操作:
- 复用 Fiber 节点:若组件类型和 key 未变,复用现有 DOM 节点。
- 标记更新类型:如
Placement(新增)、Update(更新)、Deletion(删除)。
6. 提交更新
- 分阶段提交变更:
- BeforeMutation 阶段:执行
getSnapshotBeforeUpdate(类组件)。 - Mutation 阶段:更新真实 DOM。
- Layout 阶段:同步执行
useLayoutEffect回调。 - Passive 阶段:异步执行
useEffect回调。
- BeforeMutation 阶段:执行
三、关键机制解析
1. 闭包与状态隔离
- 每次渲染时,组件函数重新执行,但 Hooks 状态通过 Fiber 节点持久化:
// 示例:useState 的闭包陷阱 const [count, setCount] = useState(0); useEffect(() => {setTimeout(() => {console.log(count); // 输出渲染时的快照值}, 1000); }, []);
2. 批量更新(Batching)
- React 自动合并多次
setState调用,减少渲染次数(React 18+ 默认所有更新批量处理):const handleClick = () => {setCount(1);setName("DeepSeek"); // 仅触发一次渲染 };
3. 并发模式(Concurrent Mode)
- 通过
startTransition或useDeferredValue标记非紧急更新,避免阻塞高优先级操作(如用户输入):const [isPending, startTransition] = useTransition(); startTransition(() => {setList(newList); // 低优先级更新 });
四、源码级流程(简化版)
// 伪代码:渲染流程核心逻辑
function renderRoot(root) {// 1. 构建 Fiber 树let workInProgress = root.current.alternate;workLoopSync(); // 同步渲染循环// 2. 提交更新commitRoot(root);
}function workLoopSync() {while (workInProgress !== null) {performUnitOfWork(workInProgress); // 处理单个 Fiber 节点}
}function performUnitOfWork(fiber) {// 执行组件函数,生成子节点if (fiber.tag === FunctionComponent) {const children = renderFunctionComponent(fiber);reconcileChildren(fiber, children);}// ...其他类型组件处理
}function commitRoot(root) {commitBeforeMutationEffects();commitMutationEffects(); // 更新 DOMcommitLayoutEffects(); // 同步执行 useLayoutEffectschedulePassiveEffects(); // 调度 useEffect
}
五、高频面试问题
-
为什么 Hooks 必须在顶层调用?
- Hooks 依赖调用顺序构建链表,条件语句或循环会破坏链表顺序。
-
函数组件如何避免重复渲染?
- 使用
React.memo包裹组件,或通过useMemo/useCallback缓存值和函数。
- 使用
-
useEffect 与 useLayoutEffect 的区别?
useEffect异步执行(不阻塞渲染),useLayoutEffect同步执行(在 DOM 更新后、浏览器绘制前触发)。
通过理解底层渲染流程,开发者能更好地优化性能、避免常见陷阱(如闭包问题),并深入掌握 React 的设计哲学。
相关文章:
钩子和函数式组件底层渲染流程详解)
React中useState()钩子和函数式组件底层渲染流程详解
useState()钩子底层渲染流程 React中useState的底层渲染机理。首先,我知道useState是React Hooks的一部分,用于在函数组件中添加状态。但底层是如何工作的呢?可能涉及到React的调度器、Fiber架构以及闭包等概念。 首先,React使用F…...

Cocos Creator 3.8 2D 游戏开发知识点整理
目录 Cocos Creator 3.8 2D 游戏开发知识点整理 1. Cocos Creator 3.8 概述 2. 2D 游戏核心组件 (1) 节点(Node)与组件(Component) (2) 渲染组件 (3) UI 组件 3. 动画系统 (1) 传统帧动画 (2) 动画编辑器 (3) Spine 和 …...

Java创建对象有几种方式?
大家好,我是锋哥。今天分享关于【Java创建对象有几种方式?】面试题。希望对大家有帮助; Java创建对象有几种方式? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Java 中,创建对象有几种常见的方式,具体如下&…...

R 字符串:深入理解与高效应用
R 字符串:深入理解与高效应用 引言 在R语言中,字符串是数据处理和编程中不可或缺的一部分。无论是数据清洗、数据转换还是数据分析,字符串的处理都是基础技能。本文将深入探讨R语言中的字符串概念,包括其基本操作、常见函数以及高效应用方法。 字符串基本概念 字符串定…...

基于Flask的全国星巴克门店可视化分析系统的设计与实现
【FLask】基于Flask的全国星巴克门店可视化分析系统的设计与实现(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统采用Python作为主要开发语言,结合Flask框架进行后端开发&…...

pytorch实现半监督学习
人工智能例子汇总:AI常见的算法和例子-CSDN博客 半监督学习(Semi-Supervised Learning,SSL)结合了有监督学习和无监督学习的特点,通常用于部分数据有标签、部分数据无标签的场景。其主要步骤如下: 1. 数…...

Golang :用Redis构建高效灵活的应用程序
在当前的应用程序开发中,高效的数据存储和检索的必要性已经变得至关重要。Redis是一个快速的、开源的、内存中的数据结构存储,为各种应用场景提供了可靠的解决方案。在这个完整的指南中,我们将学习什么是Redis,通过Docker Compose…...

deepseek+vscode自动化测试脚本生成
近几日Deepseek大火,我这里也尝试了一下,确实很强。而目前vscode的AI toolkit插件也已经集成了deepseek R1,这里就介绍下在vscode中利用deepseek帮助我们完成自动化测试脚本的实践分享 安装AI ToolKit并启用Deepseek 微软官方提供了一个针对AI辅助的插件,也就是 AI Toolk…...

49【服务器介绍】
服务器和你的电脑可以说是一模一样的,只不过用途不一样,叫法就不一样了 物理服务器和云服务器的区别 整台设备眼睛能够看得到的,我们一般称之为物理服务器。所以物理服务器是比较贵的,不是每一个开发者都能够消费得起的。 …...

【大数据技术】Day07:本机DataGrip远程连接虚拟机MySQL/Hive
本机DataGrip远程连接虚拟机MySQL/Hive datagrip-2024.3.4VMware Workstation Pro 16CentOS-Stream-10-latest-x86_64-dvd1.iso写在前面 本文主要介绍如何使用本机的DataGrip连接虚拟机的MySQL数据库和Hive数据库,提高编程效率。 安装DataGrip 请按照以下步骤安装DataGrip软…...

大语言模型的个性化综述 ——《Personalization of Large Language Models: A Survey》
摘要: 本文深入解读了论文“Personalization of Large Language Models: A Survey”,对大语言模型(LLMs)的个性化领域进行了全面剖析。通过详细阐述个性化的基础概念、分类体系、技术方法、评估指标以及应用实践,揭示了…...

[论文学习]Adaptively Perturbed Mirror Descent for Learning in Games
[论文学习]Adaptively Perturbed Mirror Descent for Learning in Games 前言概述前置知识和问题约定单调博弈(monotone game)Nash均衡和Gap函数文章问题定义Mirror Descent 方法评价 前言 文章链接 我们称集合是紧的,则集合满足࿱…...

大语言模型概述
一、主流大语言模型(LLMs) GPT系列(OpenAI) 基于Transformer解码器架构,以生成能力著称,代表产品包括ChatGPT(GPT-3.5/4),支持多轮对话、文本生成和复杂推理。其优势在于…...

【Unity踩坑】Unity项目管理员权限问题(Unity is running as administrator )
问题描述: 使用Unity Hub打开或新建项目时会有下面的提示。 解决方法: 打开“本地安全策略”: 在Windows搜索栏中输入secpol.msc并回车,或者从“运行”对话框(Win R,然后输入secpol.msc)启…...

深入理解Node.js_架构与最佳实践
1. 引言 1.1 什么是Node.js Node.js简介:Node.js是一个基于Chrome V8引擎的JavaScript运行时,用于构建快速、可扩展的网络应用。Node.js的历史背景和发展:Node.js最初由Ryan Dahl在2009年发布,旨在解决I/O密集型应用的性能问题。随着时间的推移,Node.js社区不断壮大,提供…...

一文讲解Java中的ArrayList和LinkedList
ArrayList和LinkedList有什么区别? ArrayList 是基于数组实现的,LinkedList 是基于链表实现的。 二者用途有什么不同? 多数情况下,ArrayList更利于查找,LinkedList更利于增删 由于 ArrayList 是基于数组实现的&#…...

使用 DeepSeek-R1 与 AnythingLLM 搭建本地知识库
一、下载地址Download Ollama on macOS 官方网站:Ollama 官方模型库:library 二、模型库搜索 deepseek r1 deepseek-r1:1.5b 私有化部署deepseek,模型库搜索 deepseek r1 运行cmd复制命令:ollama run deepseek-r1:1.5b 私有化…...
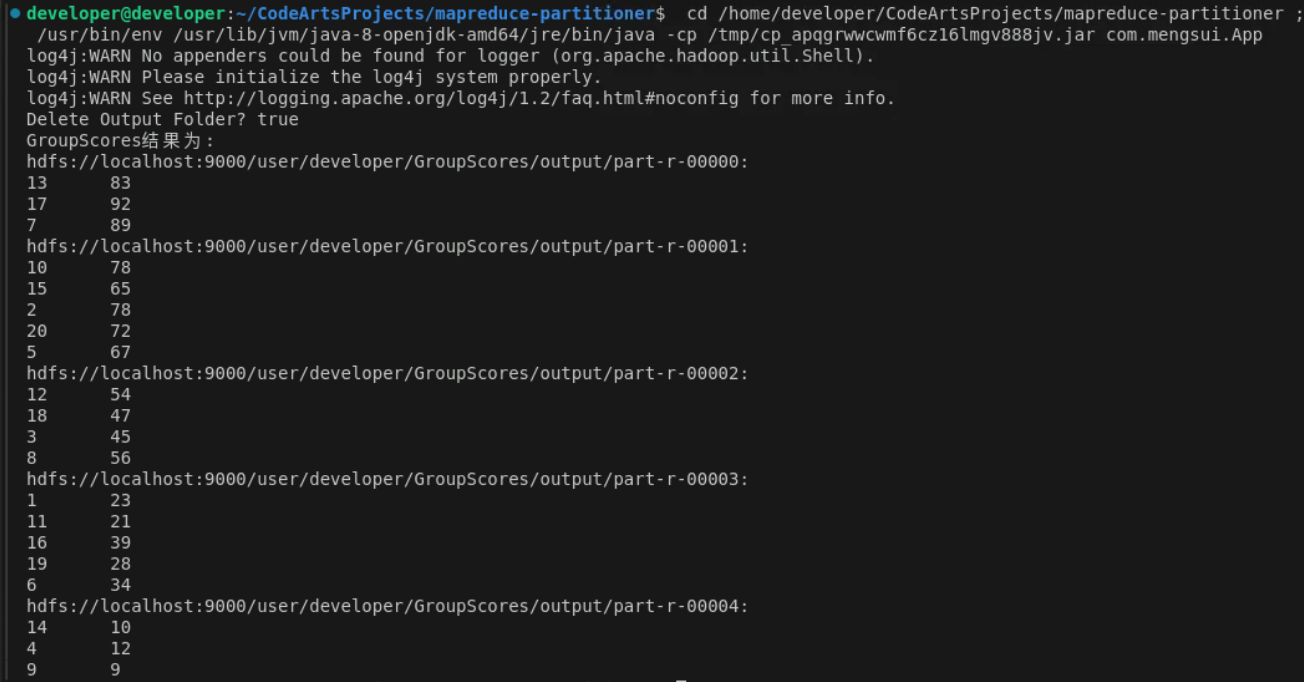
MapReduce分区
目录 1. MapReduce分区1.1 哈希分区1.2 自定义分区 2. 成绩分组2.1 Map2.2 Partition2.3 Reduce 3. 代码和结果3.1 pom.xml中依赖配置3.2 工具类util3.3 GroupScores3.4 结果 参考 本文引用的Apache Hadoop源代码基于Apache许可证 2.0,详情请参阅 Apache许可证2.0。…...

【Spring】Spring Cloud Alibaba 版本选择及项目搭建笔记
文章目录 前言1. 版本选择2. 集成 Nacos3. 服务间调用4. 集成 Sentinel5. 测试后记 前言 最近重新接触了 Spring Cloud 项目,为此参考多篇官方文档重新搭建一次项目,主要实践: 版本选择,包括 Spring Cloud Alibaba、Spring Clou…...

C语言实现统计字符串中不同ASCII字符个数
在C语言编程中,经常会遇到一些对字符串进行处理的需求,今天我们就来探讨如何统计给定字符串中ASCII码在0 - 127范围内不同字符的个数。这不仅是一个常见的算法问题,也有助于我们更好地理解C语言中数组和字符操作的相关知识。 问题描述 对于给…...

保姆级教程Docker部署Zookeeper官方镜像
目录 1、安装Docker及可视化工具 2、创建挂载目录 3、运行Zookeeper容器 4、Compose运行Zookeeper容器 5、查看Zookeeper运行状态 6、验证Zookeeper是否正常运行 1、安装Docker及可视化工具 Docker及可视化工具的安装可参考:Ubuntu上安装 Docker及可视化管理…...

DeepSeek R1 简易指南:架构、本地部署和硬件要求
DeepSeek 团队近期发布的DeepSeek-R1技术论文展示了其在增强大语言模型推理能力方面的创新实践。该研究突破性地采用强化学习(Reinforcement Learning)作为核心训练范式,在不依赖大规模监督微调的前提下显著提升了模型的复杂问题求解能力。 技…...

Ollama教程:轻松上手本地大语言模型部署
Ollama教程:轻松上手本地大语言模型部署 在大语言模型(LLM)飞速发展的今天,越来越多的开发者希望能够在本地部署和使用这些模型,以便更好地控制数据隐私和计算资源。Ollama作为一个开源工具,旨在简化大语言…...
)
并行计算、分布式计算与云计算:概念剖析与对比研究(表格对比)
什么是并行计算?什么是分布计算?什么是云计算?我们如何更好理解这3个概念,我们采用概念之间的区别和联系的方式来理解,做到切实理解,深刻体会。 1、并行计算与分布式计算 并行计算、分布式计算都属于高性…...

Java牙科诊所管理系统web医院病例挂号预约平台springboot/ssm代码编写
Java牙科诊所管理系统web医院病例挂号预约平台springboot/ssm代码编写 基于springboot(可改ssm)htmlvue项目 开发语言:Java 框架:springboot/可改ssm vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库&…...

【Linux系统】信号:再谈OS与内核区、信号捕捉、重入函数与 volatile
再谈操作系统与内核区 1、浅谈虚拟机和操作系统映射于地址空间的作用 我们调用任何函数(无论是库函数还是系统调用),都是在各自进程的地址空间中执行的。无论操作系统如何切换进程,它都能确保访问同一个操作系统实例。换句话说&am…...

自定义数据集 使用paddlepaddle框架实现逻辑回归
导入必要的库 import numpy as np import paddle import paddle.nn as nn 数据准备: seed1 paddle.seed(seed)# 1.散点输入 定义输入数据 data [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6…...

LabVIEW图片识别逆向建模系统
本文介绍了一个基于LabVIEW的图片识别逆向建模系统的开发过程。系统利用LabVIEW的强大视觉处理功能,通过二维图片快速生成对应的三维模型,不仅降低了逆向建模的技术门槛,还大幅提升了建模效率。 项目背景 在传统的逆向建模过程中…...

MySQL(高级特性篇) 13 章——事务基础知识
一、数据库事务概述 事务是数据库区别于文件系统的重要特性之一 (1)存储引擎支持情况 SHOW ENGINES命令来查看当前MySQL支持的存储引擎都有哪些,以及这些存储引擎是否支持事务能看出在MySQL中,只有InnoDB是支持事务的 &#x…...

前端进阶:深度剖析预解析机制
一、预解析是什么? 在前端开发中,我们常常会遇到一些看似不符合常规逻辑的代码执行现象,比如为什么在变量声明之前访问它,得到的结果是undefined,而不是报错?为什么函数在声明之前就可以被调用?…...