蓝桥杯python基础算法(2-1)——排序
目录
一、排序
二、例题 P3225——宝藏排序Ⅰ
三、各种排序比较
四、例题 P3226——宝藏排序Ⅱ
一、排序
(一)冒泡排序
基本思想:比较相邻的元素,如果顺序错误就把它们交换过来。
(二)选择排序
基本思想:在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾
(三)插入排序
基本思想:将未排序数据插入到已排序序列的合适位置。
(四)快速排序
基本思想:选择一个基准值,将数组分为两部分,小于基准值的放在左边,大于基准值的放在右边,然后对左右两部分分别进行排序。
(五)归并排序
基本思想:将数组分成两个子数组,对两个子数组分别进行排序,然后将排序好的子数组合并成一个有序的数组。
(七)桶排序
基本思想:将待排序的数据元素,按照一定的规则划分到不同的“桶”中。每个桶内的数据元素再根据具体情况进行单独排序(通常可以使用其他简单排序算法,如插入排序),最后将各个桶中排好序的数据元素依次取出,就得到了一个有序的序列。
应用要点
时间复杂度:不同排序算法时间复杂度不同,如冒泡排序、选择排序、插入排序平均时间复杂度为 O(n^2),快速排序平均时间复杂度为 O(nlogn),归并排序时间复杂度稳定在 O(nlogn)。蓝桥杯题目对时间限制严格,大数据量下应优先选择 O(nlogn) 级别的排序算法。
空间复杂度:有些题目对空间也有限制。例如归并排序空间复杂度为 O(n),而快速排序如果实现合理(如原地分区)空间复杂度可以为 O(logn)。
稳定性:排序稳定性指相等元素在排序前后相对位置是否改变。例如插入排序、冒泡排序是稳定的,选择排序、快速排序是不稳定的。如果题目要求保持相等元素相对顺序,要选择稳定排序算法。
二、例题 P3225——宝藏排序Ⅰ
在一个神秘的岛屿上,有一支探险队发现了一批宝藏,这批宝藏是以整数数组的形式存在的。每个宝藏上都标有一个数字,代表了其珍贵程度。然而,由于某种神奇的力量,这批宝藏的顺序被打乱了,探险队需要将宝藏按照珍贵程度进行排序,以便更好地研究和保护它们。作为探险队的一员,肖恩需要设计合适的排序算法来将宝藏按照珍贵程度进行从小到大排序。请你帮帮肖恩。
输入描述
输入第一行包括一个数字 n ,表示宝藏总共有 n 个。
输入的第二行包括 n 个数字,第 ii 个数字 a[i] 表示第 i 个宝藏的珍贵程度。
数据保证 1≤n≤1000,1≤a[i]≤10^6 。
输出描述
输出 n 个数字,为对宝藏按照珍贵程度从小到大排序后的数组。
# 冒泡排序 def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n - i - 1):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]return arr# 选择排序 def selection_sort(arr):n = len(arr)for i in range(n):min_index = ifor j in range(i + 1, n):if arr[j] < arr[min_index]:min_index = jarr[i], arr[min_index] = arr[min_index], arr[i]return arr# 插入排序 def insertion_sort(arr):n = len(arr)for i in range(1, n):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:arr[j + 1] = arr[j]j = j - 1arr[j + 1] = keyreturn arr# 快速排序 def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)# 归并排序 def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left_half = arr[:mid]right_half = arr[mid:]left_half = merge_sort(left_half)right_half = merge_sort(right_half)return merge(left_half, right_half)def merge(left, right):result = []left_index = 0right_index = 0while left_index < len(left) and right_index < len(right):if left[left_index] < right[right_index]:result.append(left[left_index])left_index += 1else:result.append(right[right_index])right_index += 1result.extend(left[left_index:])result.extend(right[right_index:])return result# 桶排序 def bucket_sort(arr):max_val = max(arr)min_val = min(arr)bucket_size = 1000bucket_count = (max_val - min_val) // bucket_size + 1buckets = [[] for _ in range(bucket_count)]for num in arr:index = (num - min_val) // bucket_sizebuckets[index].append(num)for i in range(bucket_count):buckets[i].sort()sorted_arr = []for bucket in buckets:sorted_arr.extend(bucket)return sorted_arrn = int(input()) treasures = list(map(int, input().split()))print("冒泡排序结果:") print(bubble_sort(treasures[:]))print("选择排序结果:") print(selection_sort(treasures[:]))print("插入排序结果:") print(insertion_sort(treasures[:]))print("快速排序结果:") print(quick_sort(treasures[:]))print("归并排序结果:") print(merge_sort(treasures[:]))print("桶排序结果:") print(bucket_sort(treasures[:]))

三、各种排序比较
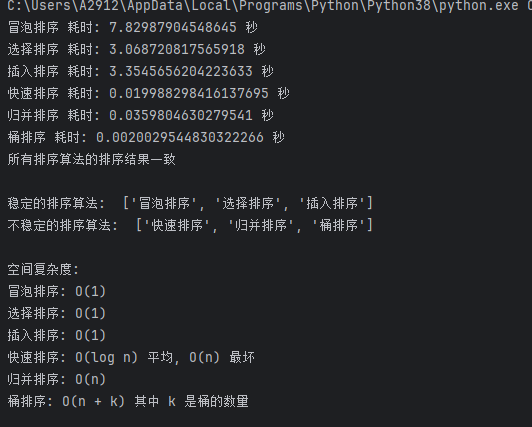
import time import random# 冒泡排序 def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n - i - 1):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]return arr# 选择排序 def selection_sort(arr):n = len(arr)for i in range(n):min_index = ifor j in range(i + 1, n):if arr[j] < arr[min_index]:min_index = jarr[i], arr[min_index] = arr[min_index], arr[i]return arr# 插入排序 def insertion_sort(arr):n = len(arr)for i in range(1, n):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:arr[j + 1] = arr[j]j = j - 1arr[j + 1] = keyreturn arr# 快速排序 def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)# 归并排序 def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left_half = arr[:mid]right_half = arr[mid:]left_half = merge_sort(left_half)right_half = merge_sort(right_half)return merge(left_half, right_half)def merge(left, right):result = []left_index = 0right_index = 0while left_index < len(left) and right_index < len(right):if left[left_index] < right[right_index]:result.append(left[left_index])left_index += 1else:result.append(right[right_index])right_index += 1result.extend(left[left_index:])result.extend(right[right_index:])return result# 桶排序 def bucket_sort(arr):max_val = max(arr)min_val = min(arr)bucket_size = 1000bucket_count = (max_val - min_val) // bucket_size + 1buckets = [[] for _ in range(bucket_count)]for num in arr:index = (num - min_val) // bucket_sizebuckets[index].append(num)for i in range(bucket_count):buckets[i].sort()sorted_arr = []for bucket in buckets:sorted_arr.extend(bucket)return sorted_arr# —————————————————————————————————————————————— # 生成测试数据 test_array = [random.randint(1, 10000) for _ in range(10000)]# 记录每种排序的时间 sorting_methods = [("冒泡排序", bubble_sort),("选择排序", selection_sort),("插入排序", insertion_sort),("快速排序", quick_sort),("归并排序", merge_sort),("桶排序", bucket_sort) ]# 比较排序结果 sorted_results = {} for name, sort_func in sorting_methods:start_time = time.time()sorted_array = sort_func(test_array[:])end_time = time.time()sorted_results[name] = sorted_arrayprint(f"{name} 耗时: {end_time - start_time} 秒")# 比较排序结果是否一致 base_result = sorted_results[sorting_methods[0][0]] is_consistent = True for name, result in sorted_results.items():if result != base_result:is_consistent = Falseprint(f"{name} 的排序结果与基准排序结果不一致")if is_consistent:print("所有排序算法的排序结果一致")# 比较稳定性 # 稳定性定义: 排序后相同元素的相对顺序不变 # 生成包含重复元素的测试数据 test_stability_array = [5, 3, 8, 3, 6] stable_sorts = [] unstable_sorts = []for name, sort_func in sorting_methods:original_array = test_stability_array[:]sorted_array = sort_func(original_array)original_indices = [i for i, x in enumerate(original_array) if x == 3]sorted_indices = [i for i, x in enumerate(sorted_array) if x == 3]if original_indices == sorted_indices:stable_sorts.append(name)else:unstable_sorts.append(name)print("\n稳定的排序算法: ", stable_sorts) print("不稳定的排序算法: ", unstable_sorts)space_complexity = {"冒泡排序": "O(1)","选择排序": "O(1)","插入排序": "O(1)","快速排序": "O(log n) 平均, O(n) 最坏","归并排序": "O(n)","桶排序": "O(n + k) 其中 k 是桶的数量" }print("\n空间复杂度:") for name, complexity in space_complexity.items():print(f"{name}: {complexity}")
四、例题 P3226——宝藏排序Ⅱ
问题描述
注意:这道题于宝藏排序Ⅰ的区别仅是数据范围在一个神秘的岛屿上,有一支探险队发现了一批宝藏,这批宝藏是以整数数组的形式存在的。每个宝藏上都标有一个数字,代表了其珍贵程度。然而,由于某种神奇的力量,这批宝藏的顺序被打乱了,探险队需要将宝藏按照珍贵程度进行排序,以便更好地研究和保护它们。作为探险队的一员,肖恩需要设计合适的排序算法来将宝藏按照珍贵程度进行从小到大排序。请你帮帮肖恩。
输入描述
输入第一行包括一个数字 n ,表示宝藏总共有 n 个。
输入的第二行包括 n 个数字,第 i 个数字 a[i] 表示第 i 个宝藏的珍贵程度。
数据保证 1≤n≤10^5,1≤a[i]≤10^9。
输出描述
输出 n 个数字,为对宝藏按照珍贵程度从小到大排序后的数组。
list.sort():是Python标准库中已经实现好的方法,它是基于优化的C语言代码实现的,内部实现经过了高度优化,以确保在各种情况下都能高效运行。n = int(input()) treasures = list(map(int, input().split()))# 使用Python内置的排序函数进行排序 sorted_treasures = sorted(treasures)for treasure in sorted_treasures:print(treasure, end=" ")
相关文章:
蓝桥杯python基础算法(2-1)——排序
目录 一、排序 二、例题 P3225——宝藏排序Ⅰ 三、各种排序比较 四、例题 P3226——宝藏排序Ⅱ 一、排序 (一)冒泡排序 基本思想:比较相邻的元素,如果顺序错误就把它们交换过来。 (二)选择排序 基本思想…...

深度学习中常用的评价指标方法
深度学习中常用的评价指标方法因任务类型(如分类、回归、分割等)而异。以下是一些常见的评价指标: 1. 分类任务 准确率(Accuracy) 定义:正确预测的样本数占总样本数的比例。 公式:AccuracyTPT…...

linux 进程补充
环境变量 基本概念 环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数 如:我们在编写C/C代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪 里,但是照样可以链接成功&#…...

Django框架的全面指南:从入门到高级
Django框架的全面指南:从入门到高级 目录 引言Django简介安装与配置创建第一个Django项目Django的MVT架构模型(Model)视图(View)模板(Template)URL路由表单处理用户认证与权限Django Admin高级…...

C基础寒假练习(8)
一、终端输入10个学生成绩,使用冒泡排序对学生成绩从低到高排序 #include <stdio.h> int main(int argc, const char *argv[]) {int arr[10]; // 定义一个长度为10的整型数组,用于存储学生成绩int len sizeof(arr) / sizeof(arr[0]); // 计算数组…...

Python爬虫:1药城店铺爬虫(完整代码)
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

【贪心算法篇】:“贪心”之旅--算法练习题中的智慧与策略(一)
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:贪心算法篇–CSDN博客 文章目录 一.贪心算法1.什么是贪心算法2.贪心算法的特点 二.例题1.柠…...

Rust 变量特性:不可变、和常量的区别、 Shadowing
Rust 变量特性:不可变、和常量的区别、 Shadowing Rust 是一门以安全性和性能著称的系统编程语言,其变量系统设计独特且强大。本文将从三个角度介绍 Rust 变量的核心特性:可变性(Mutability)、变量与常量的区别&#…...

基于Springboot框架的学术期刊遴选服务-项目演示
项目介绍 本课程演示的是一款 基于Javaweb的水果超市管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统 3.该项目附…...

方法一:将私钥存入环境变量,环境变量指什么//spring中,rsa私钥应该怎么处置
环境变量(Environment Variables)是操作系统提供的一种机制,用于存储和传递配置信息或敏感数据(如密钥、密码等)。每个进程都可以访问一组环境变量,这些变量在操作系统级别定义,可以被应用程序读…...
钩子和函数式组件底层渲染流程详解)
React中useState()钩子和函数式组件底层渲染流程详解
useState()钩子底层渲染流程 React中useState的底层渲染机理。首先,我知道useState是React Hooks的一部分,用于在函数组件中添加状态。但底层是如何工作的呢?可能涉及到React的调度器、Fiber架构以及闭包等概念。 首先,React使用F…...

Cocos Creator 3.8 2D 游戏开发知识点整理
目录 Cocos Creator 3.8 2D 游戏开发知识点整理 1. Cocos Creator 3.8 概述 2. 2D 游戏核心组件 (1) 节点(Node)与组件(Component) (2) 渲染组件 (3) UI 组件 3. 动画系统 (1) 传统帧动画 (2) 动画编辑器 (3) Spine 和 …...

Java创建对象有几种方式?
大家好,我是锋哥。今天分享关于【Java创建对象有几种方式?】面试题。希望对大家有帮助; Java创建对象有几种方式? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Java 中,创建对象有几种常见的方式,具体如下&…...

R 字符串:深入理解与高效应用
R 字符串:深入理解与高效应用 引言 在R语言中,字符串是数据处理和编程中不可或缺的一部分。无论是数据清洗、数据转换还是数据分析,字符串的处理都是基础技能。本文将深入探讨R语言中的字符串概念,包括其基本操作、常见函数以及高效应用方法。 字符串基本概念 字符串定…...

基于Flask的全国星巴克门店可视化分析系统的设计与实现
【FLask】基于Flask的全国星巴克门店可视化分析系统的设计与实现(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统采用Python作为主要开发语言,结合Flask框架进行后端开发&…...

pytorch实现半监督学习
人工智能例子汇总:AI常见的算法和例子-CSDN博客 半监督学习(Semi-Supervised Learning,SSL)结合了有监督学习和无监督学习的特点,通常用于部分数据有标签、部分数据无标签的场景。其主要步骤如下: 1. 数…...

Golang :用Redis构建高效灵活的应用程序
在当前的应用程序开发中,高效的数据存储和检索的必要性已经变得至关重要。Redis是一个快速的、开源的、内存中的数据结构存储,为各种应用场景提供了可靠的解决方案。在这个完整的指南中,我们将学习什么是Redis,通过Docker Compose…...

deepseek+vscode自动化测试脚本生成
近几日Deepseek大火,我这里也尝试了一下,确实很强。而目前vscode的AI toolkit插件也已经集成了deepseek R1,这里就介绍下在vscode中利用deepseek帮助我们完成自动化测试脚本的实践分享 安装AI ToolKit并启用Deepseek 微软官方提供了一个针对AI辅助的插件,也就是 AI Toolk…...

49【服务器介绍】
服务器和你的电脑可以说是一模一样的,只不过用途不一样,叫法就不一样了 物理服务器和云服务器的区别 整台设备眼睛能够看得到的,我们一般称之为物理服务器。所以物理服务器是比较贵的,不是每一个开发者都能够消费得起的。 …...

【大数据技术】Day07:本机DataGrip远程连接虚拟机MySQL/Hive
本机DataGrip远程连接虚拟机MySQL/Hive datagrip-2024.3.4VMware Workstation Pro 16CentOS-Stream-10-latest-x86_64-dvd1.iso写在前面 本文主要介绍如何使用本机的DataGrip连接虚拟机的MySQL数据库和Hive数据库,提高编程效率。 安装DataGrip 请按照以下步骤安装DataGrip软…...

大语言模型的个性化综述 ——《Personalization of Large Language Models: A Survey》
摘要: 本文深入解读了论文“Personalization of Large Language Models: A Survey”,对大语言模型(LLMs)的个性化领域进行了全面剖析。通过详细阐述个性化的基础概念、分类体系、技术方法、评估指标以及应用实践,揭示了…...

[论文学习]Adaptively Perturbed Mirror Descent for Learning in Games
[论文学习]Adaptively Perturbed Mirror Descent for Learning in Games 前言概述前置知识和问题约定单调博弈(monotone game)Nash均衡和Gap函数文章问题定义Mirror Descent 方法评价 前言 文章链接 我们称集合是紧的,则集合满足࿱…...

大语言模型概述
一、主流大语言模型(LLMs) GPT系列(OpenAI) 基于Transformer解码器架构,以生成能力著称,代表产品包括ChatGPT(GPT-3.5/4),支持多轮对话、文本生成和复杂推理。其优势在于…...

【Unity踩坑】Unity项目管理员权限问题(Unity is running as administrator )
问题描述: 使用Unity Hub打开或新建项目时会有下面的提示。 解决方法: 打开“本地安全策略”: 在Windows搜索栏中输入secpol.msc并回车,或者从“运行”对话框(Win R,然后输入secpol.msc)启…...

深入理解Node.js_架构与最佳实践
1. 引言 1.1 什么是Node.js Node.js简介:Node.js是一个基于Chrome V8引擎的JavaScript运行时,用于构建快速、可扩展的网络应用。Node.js的历史背景和发展:Node.js最初由Ryan Dahl在2009年发布,旨在解决I/O密集型应用的性能问题。随着时间的推移,Node.js社区不断壮大,提供…...

一文讲解Java中的ArrayList和LinkedList
ArrayList和LinkedList有什么区别? ArrayList 是基于数组实现的,LinkedList 是基于链表实现的。 二者用途有什么不同? 多数情况下,ArrayList更利于查找,LinkedList更利于增删 由于 ArrayList 是基于数组实现的&#…...

使用 DeepSeek-R1 与 AnythingLLM 搭建本地知识库
一、下载地址Download Ollama on macOS 官方网站:Ollama 官方模型库:library 二、模型库搜索 deepseek r1 deepseek-r1:1.5b 私有化部署deepseek,模型库搜索 deepseek r1 运行cmd复制命令:ollama run deepseek-r1:1.5b 私有化…...
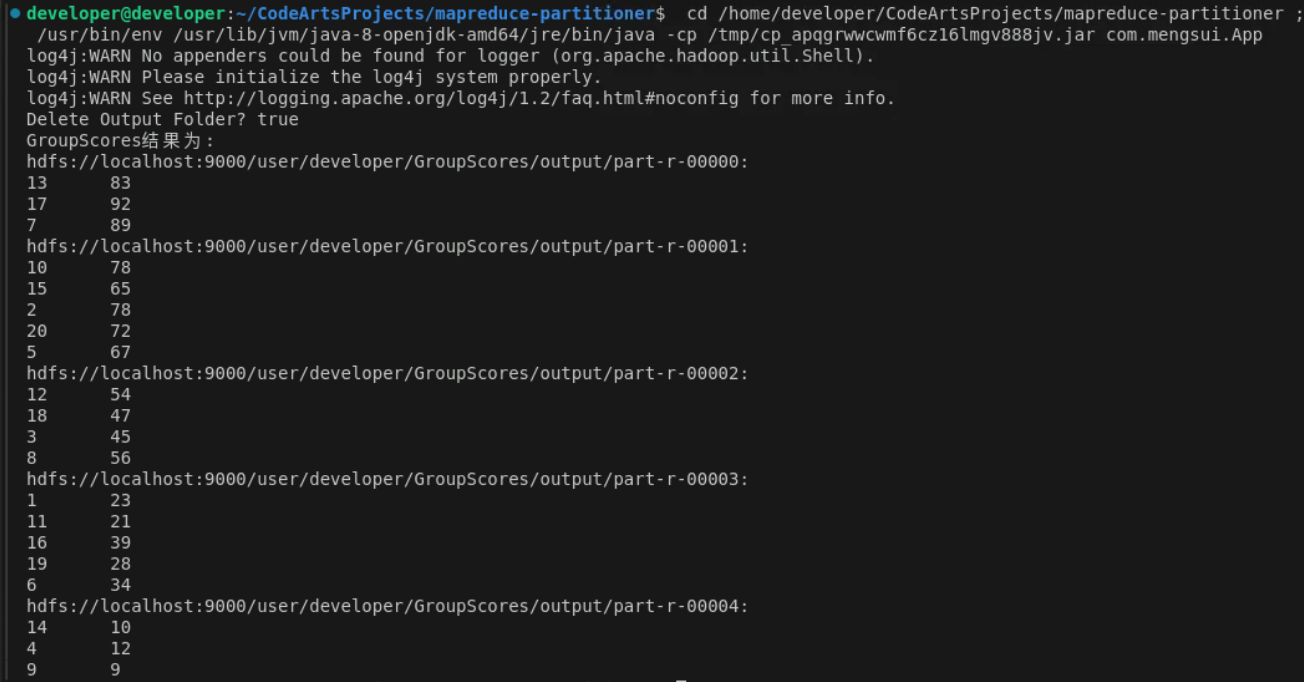
MapReduce分区
目录 1. MapReduce分区1.1 哈希分区1.2 自定义分区 2. 成绩分组2.1 Map2.2 Partition2.3 Reduce 3. 代码和结果3.1 pom.xml中依赖配置3.2 工具类util3.3 GroupScores3.4 结果 参考 本文引用的Apache Hadoop源代码基于Apache许可证 2.0,详情请参阅 Apache许可证2.0。…...

【Spring】Spring Cloud Alibaba 版本选择及项目搭建笔记
文章目录 前言1. 版本选择2. 集成 Nacos3. 服务间调用4. 集成 Sentinel5. 测试后记 前言 最近重新接触了 Spring Cloud 项目,为此参考多篇官方文档重新搭建一次项目,主要实践: 版本选择,包括 Spring Cloud Alibaba、Spring Clou…...

C语言实现统计字符串中不同ASCII字符个数
在C语言编程中,经常会遇到一些对字符串进行处理的需求,今天我们就来探讨如何统计给定字符串中ASCII码在0 - 127范围内不同字符的个数。这不仅是一个常见的算法问题,也有助于我们更好地理解C语言中数组和字符操作的相关知识。 问题描述 对于给…...